
Single Object Tracking in Satellite Videos: Deep Siamese Network Incorporating an Interframe Difference Centroid Inertia Motion Model

 ,
, 
 ,
,
Abstract
:1. Introduction
- Smaller object size. Some objects have only several pixels in satellite video, making it difficult for trackers in natural scenes to adapt the size changes.
- Strong interferences. The interferences come from the high similarity among multiple moving targets and the poor distinguishability between the objects and the background.
- We propose a method for generating training datasets suitable for satellite video single object tracking tasks. Through the introduction of a variety of small objects, such as airplane, ship, vehicle, and other categories, the tracker can adapt to the size and scale changes of the targets. The effectiveness was validated in experiments with two public datasets DOTA [26] and DIOR [27].
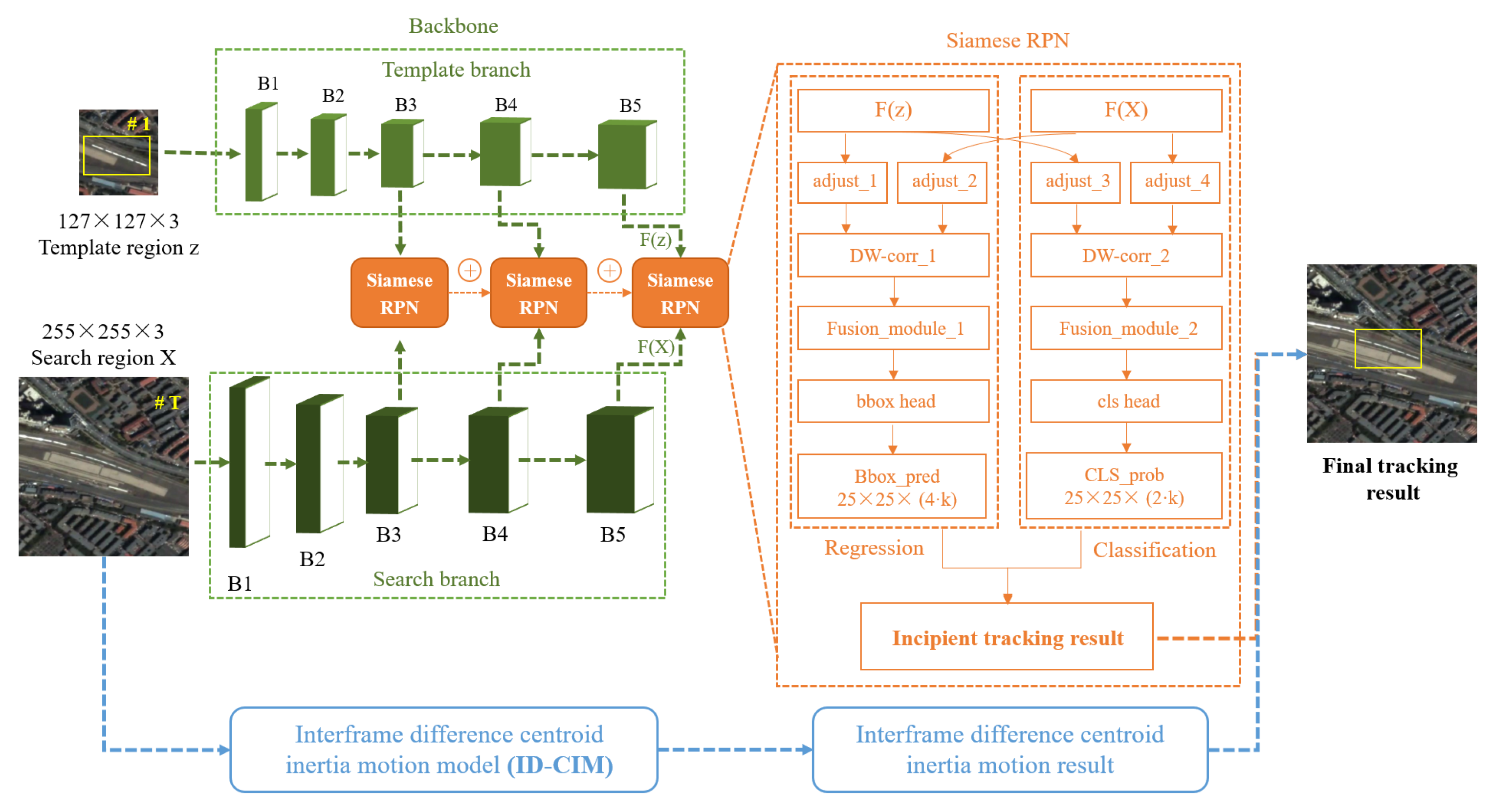
- We propose deep Siamese network (DSN) for real-time satellite video single object tracking. It is modified to adapt to different categories with large size differences in remote sensing images so as to train the datasets constructed in this paper. During testing, the template frame is only calculated once and can be considered as a one-shot local detection issue, which greatly accelerates the tracking speed.
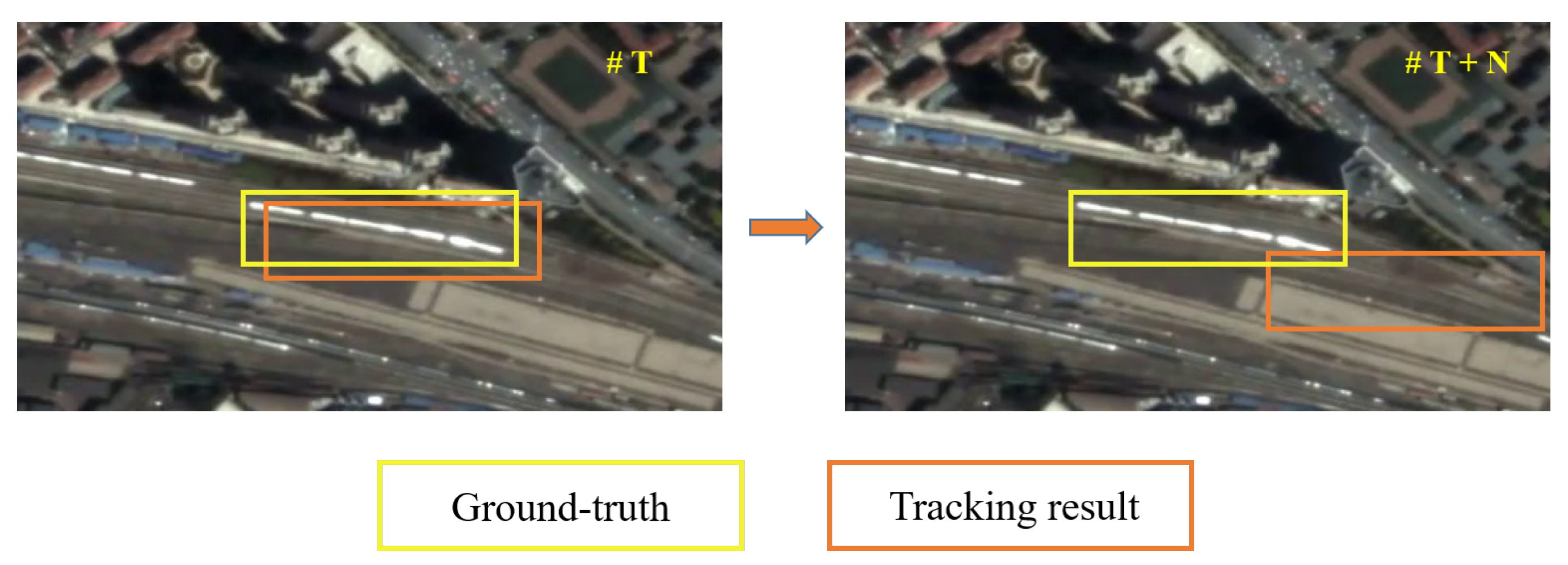
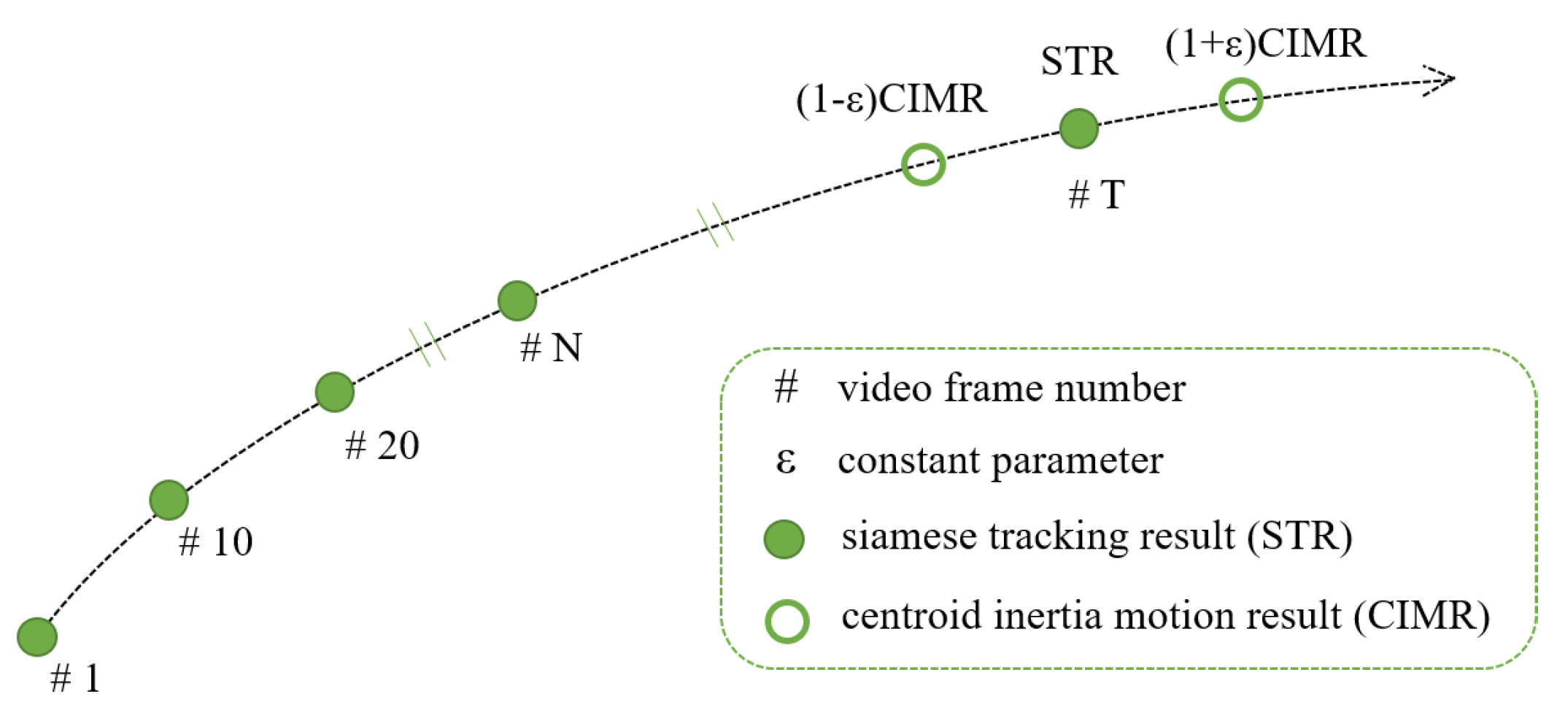
- We also propose the ID-CIM mechanism to alleviate model drift. By calculating the coordinates difference of centroid between the fixed interval frames in the first N frames, the mechanism can find the movement pattern of the target. It involves multiple frames, thus avoiding contingency and improving robustness.
2. Related Work
2.1. The Siamese Network-Based Trackers
2.2. Satellite Video Single Object Tracking Methods
2.3. The Mechanisms to Alleviate Model Drift
3. Methodology
3.1. The Structure of the DSN
3.2. Interframe Difference Centroid Inertia Motion Model
3.3. The Method of Generating Satellite Video Object Tracking Training Datasets
| Algorithm 1 The general procedure of ID-CIM. |
| Require: Variable frame number t, Fixed frame number N, and of frame t, Parameter ; |
| Ensure: Final tracking result of frame t (); |
| 1: if t < N then |
| 2: Set = |
| 3: else |
| 4: if (1-) < <(1+) then |
| 5: Set = |
| 6: else |
| 7: Set = |
| 8: end if |
| 9: end if |
4. Experiments and Result Analysis
4.1. Experimental Settings
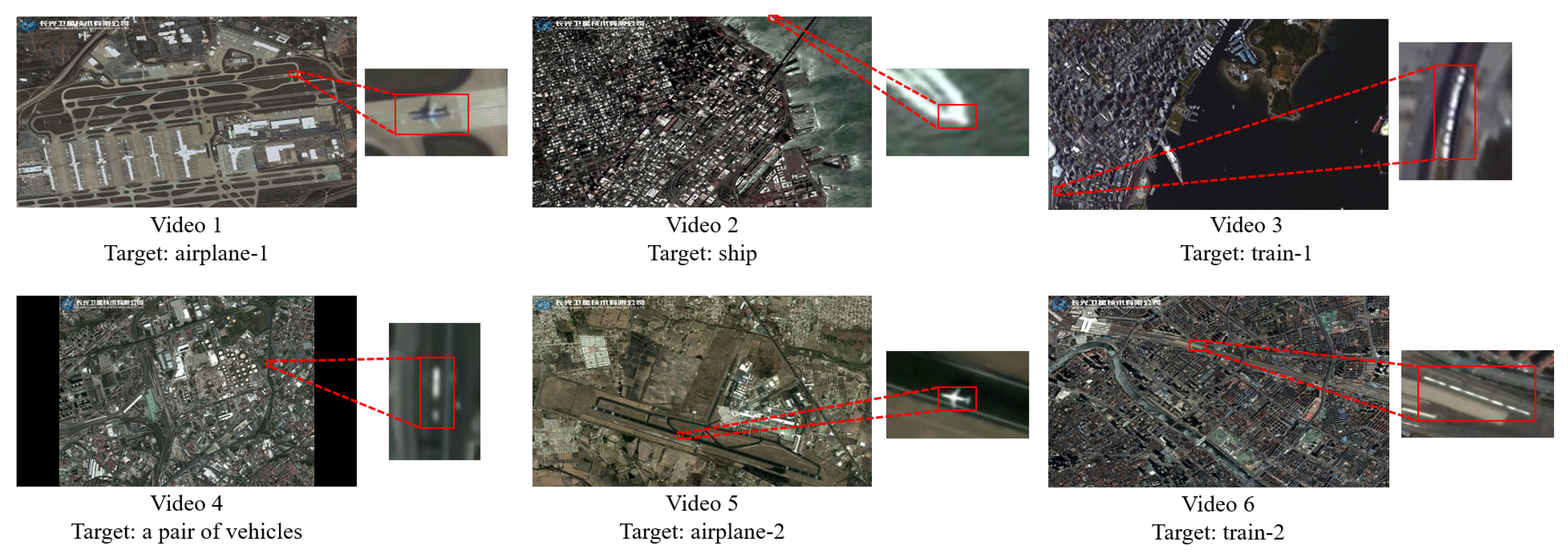
4.1.1. Experimental Datasets Description
4.1.2. Evaluation Criteria
4.1.3. Implementation Details
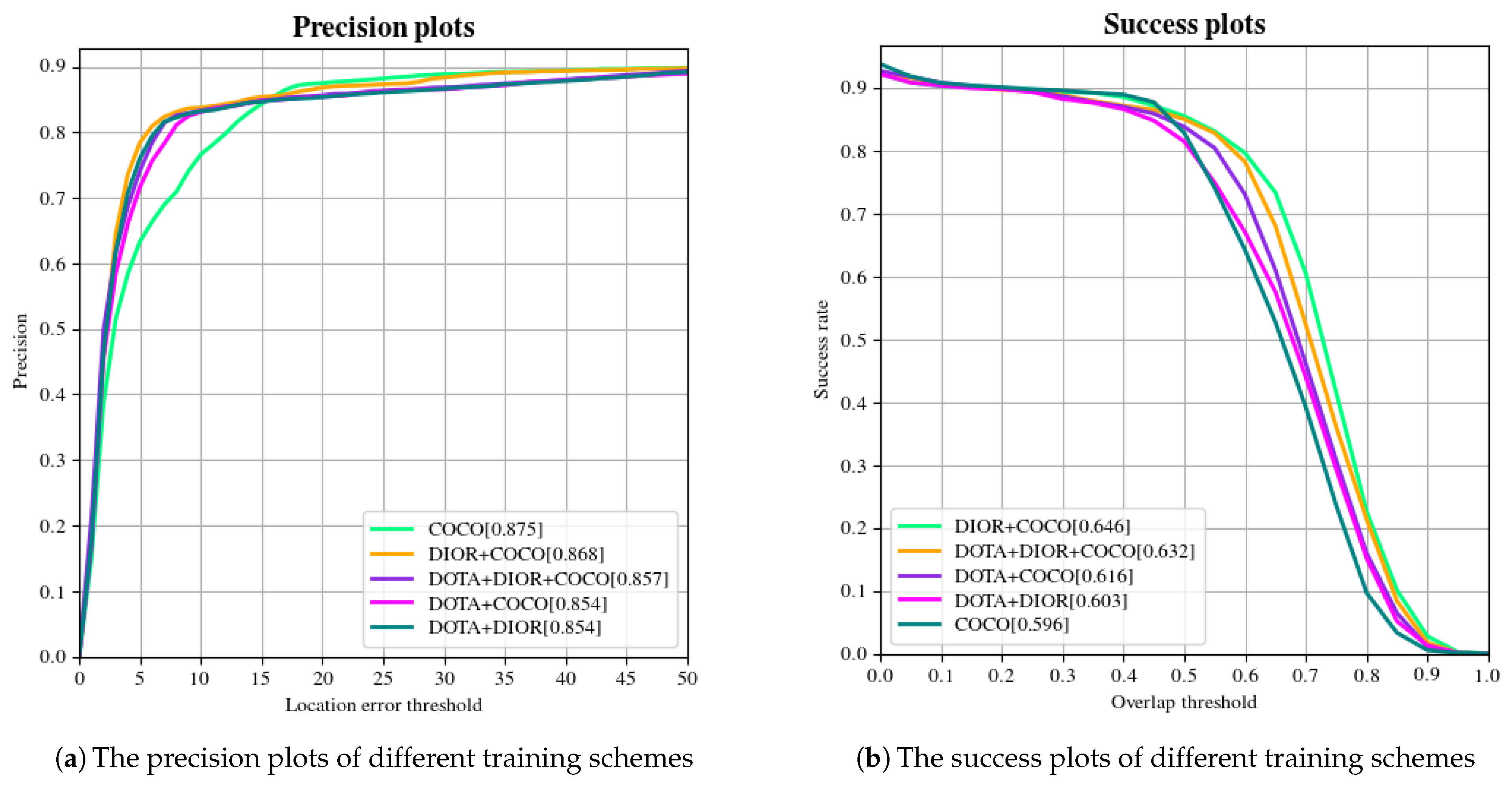
4.2. Ablation Experiment 1: The Validation of ID-DSN
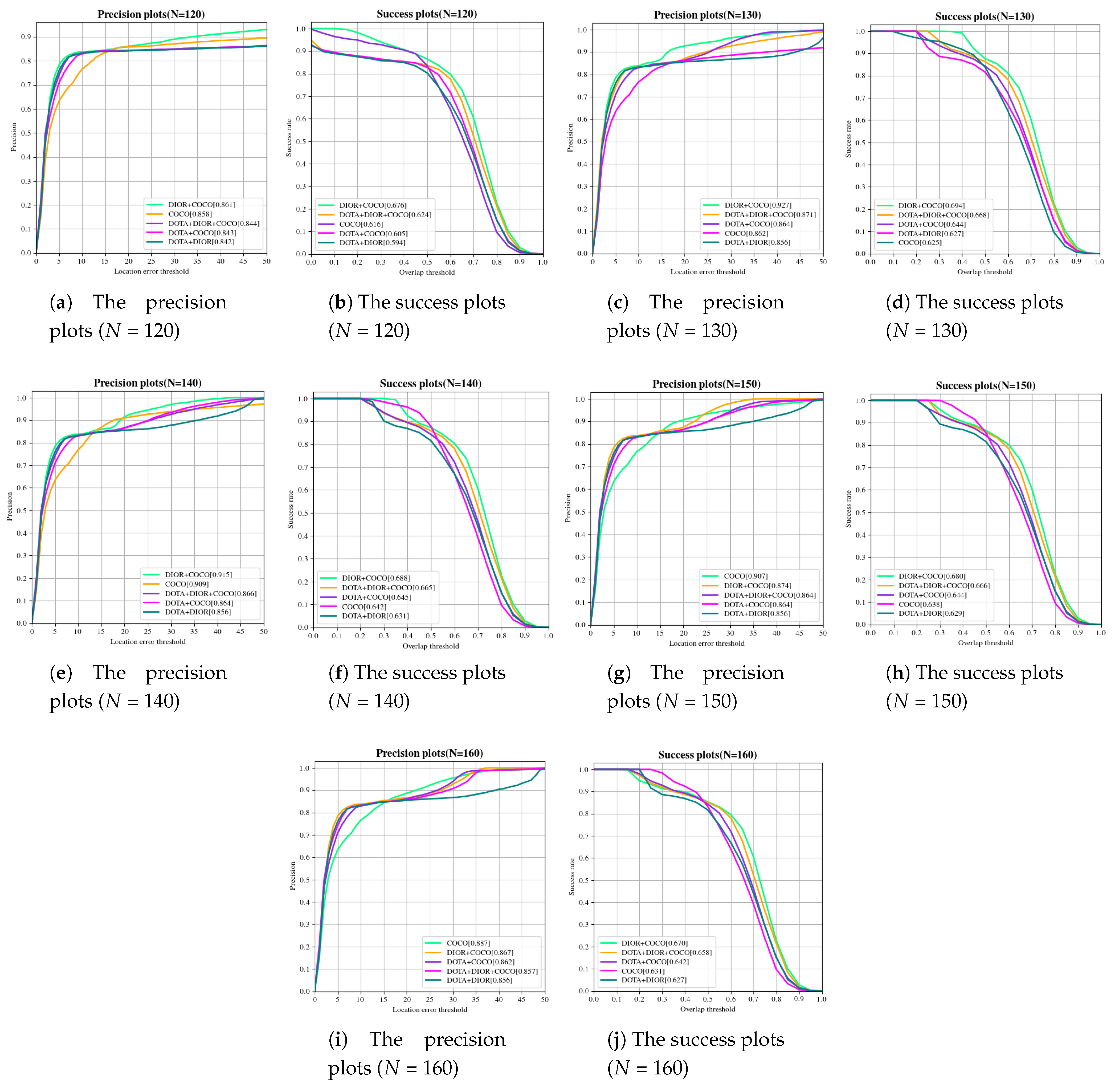
4.3. Ablation Experiment 2: The ID-CIM Mechanism for Alleviating Model Drift
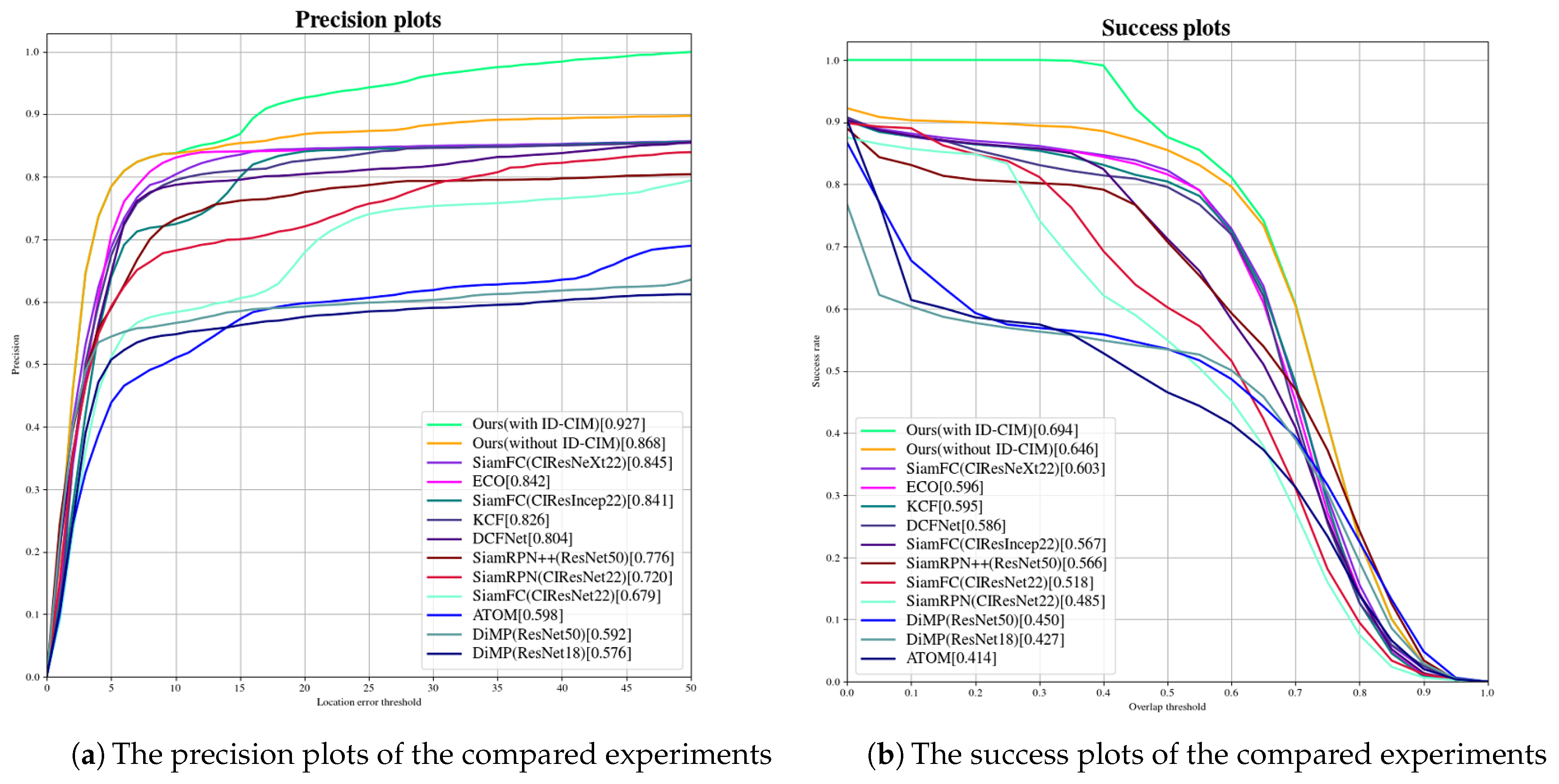
4.4. Ablation Experiment 3: Compared ID-DSN With the State-of-the-Art Trackers
5. Discussion
6. Conclusions
- Generalization of the tracker. The tracking performance in satellite videos from different sources under the same training mechanism will be studied.
- Domain adaption ability of the tracker. The tracking performance on target categories that are not present in the training datasets but present in the testing datasets will be studied.
- Improvement of network structure. We will pay more attention to features extracted from the shallow network and eliminate the impact of padding, and further will apply these two optimization strategies to satellite video single object tracking tasks. In addition, we will further improve the tracking speed to achieve high performance in both tracking accuracy and speed.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Lee, K.; Hwang, J. On-Road Pedestrian Tracking Across Multiple Driving Recorders. IEEE Trans. Multimed. 2015, 17, 1429–1438. [Google Scholar] [CrossRef]
- Liu, L.; Xing, J.; Ai, H.; Ruan, X. Hand posture recognition using finger geometric feature. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 565–568. [Google Scholar]
- Tang, S.; Andriluka, M.; Andres, B.; Schiele, B. Multiple People Tracking by Lifted Multicut and Person Re-identification. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3701–3710. [Google Scholar] [CrossRef]
- Zhang, G.; Vela, P.A. Good features to track for visual SLAM. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Du, B.; Cai, S.; Wu, C. Object Tracking in Satellite Videos Based on a Multiframe Optical Flow Tracker. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3043–3055. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking With Siamese Region Proposal Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhu, Z.; Wu, W.; Zou, W.; Yan, J. End-to-End Flow Correlation Tracking with Spatial-Temporal Attention. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 548–557. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Lim, J.; Yang, M.H. Object Tracking Benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Yang, D.; Chen, Z. Object Tracking on Satellite Videos: A Correlation Filter-Based Tracking Method With Trajectory Correction by Kalman Filter. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3538–3551. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar] [CrossRef]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Discriminative Scale Space Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1561–1575. [Google Scholar] [CrossRef] [Green Version]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Danelljan, M.; Khan, F.S.; Felsberg, M.; van de Weijer, J. Adaptive Color Attributes for Real-Time Visual Tracking. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014; pp. 1090–1097. [Google Scholar] [CrossRef] [Green Version]
- Danelljan, M.; Robinson, A.; Khan, F.S.; Felsberg, M. Beyond Correlation Filters: Learning Continuous Convolution Operators for Visual Tracking. arXiv 2016, arXiv:1608.03773. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ECO: Efficient Convolution Operators for Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 6931–6939. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking With Very Deep Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 4282–4291. [Google Scholar] [CrossRef] [Green Version]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-Convolutional Siamese Networks for Object Tracking. In Proceedings of the Computer Vision—ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–16 October 2016; pp. 850–865. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Wang, Q.; Li, B.; Wu, W.; Yan, J.; Hu, W. Distractor-aware Siamese Networks for Visual Object Tracking. arXiv 2018, arXiv:1808.06048. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Li, D.; Wang, M.; Dong, Z.; Shen, X.; Shi, L. Earth observation brain (EOB): An intelligent earth observation system. Geo-Spat. Inf. Sci. 2017, 20, 134–140. [Google Scholar] [CrossRef] [Green Version]
- d’Angelo, P.; Kuschk, G.; Reinartz, P. Evaluation of Skybox Video and Still Image products. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, XL1, 95–99. [Google Scholar] [CrossRef] [Green Version]
- Aoran, X.; Zhongyuan, W.; Lei, W.; Yexian, R. Super-Resolution for “Jilin-1” Satellite Video Imagery via a Convolutional Network. Sensors 2018, 18, 1194. [Google Scholar]
- Jiaqi, W.U.; Zhang, G.; Wang, T.; Jiang, Y. Satellite Video Point-target Tracking in Combination with Motion Smoothness Constraint and Grayscale Feature. Acta Geod. Cartogr. Sin. 2017, 46, 1135. [Google Scholar]
- Hu, Z.; Yang, D.; Zhang, K.; Chen, Z. Object Tracking in Satellite Videos Based on Convolutional Regression Network With Appearance and Motion Features. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 783–793. [Google Scholar] [CrossRef]
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.J.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar] [CrossRef] [Green Version]
- Shao, J.; Du, B.; Wu, C.; Zhang, L. Tracking Objects From Satellite Videos: A Velocity Feature Based Correlation Filter. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7860–7871. [Google Scholar] [CrossRef]
- Shao, J.; Du, B.; Wu, C.; Zhang, L. Can We Track Targets From Space? A Hybrid Kernel Correlation Filter Tracker for Satellite Video. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8719–8731. [Google Scholar] [CrossRef]
- Han, X.; Zhong, Y.; Zhang, L. An Efficient and Robust Integrated Geospatial Object Detection Framework for High Spatial Resolution Remote Sensing Imagery. Remote Sens. 2017, 9, 666. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Xia, G.S.; Lu, Q.; Shen, W.; Zhang, L. Visual object tracking by correlation filters and online learning. ISPRS J. Photogramm. Remote Sens. 2018, 140, 77–89. [Google Scholar] [CrossRef]
- Guan, M.; Wen, C.; Shan, M.; Ng, C.; Zou, Y. Real-Time Event-Triggered Object Tracking in the Presence of Model Drift and Occlusion. IEEE Trans. Ind. Electron. 2019, 66, 2054–2065. [Google Scholar] [CrossRef]
- Luo, S.; Li, B.; Yuan, X. An Anti-Drift Background-Aware Correlation Filter for Visual Tracking in Complex Scenes. IEEE Access 2019, 7, 185857–185867. [Google Scholar] [CrossRef]
- Huang, Z.; Yu, Y.; Xu, M. Bidirectional Tracking Scheme for Visual Object Tracking Based on Recursive Orthogonal Least Squares. IEEE Access 2019, 7, 159199–159213. [Google Scholar] [CrossRef]
- Basso, G.F.; De Amorim, T.G.S.; Brito, A.V.; Nascimento, T.P. Kalman Filter with Dynamical Setting of Optimal Process Noise Covariance. IEEE Access 2017, 5, 8385–8393. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Zhu, K.; Chen, G.; Tan, X.; Zhang, L.; Dai, F.; Liao, P.; Gong, Y. Geospatial Object Detection on High Resolution Remote Sensing Imagery Based on Double Multi-Scale Feature Pyramid Network. Remote Sens. 2019, 11, 755. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Doll’ar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- 2016 IEEE GRSS Data Fusion Contest. Available online: http://www.grss-ieee.org/community/technical-committees/data-fusion (accessed on 9 October 2019).
- Wang, Q.; Gao, J.; Xing, J.; Zhang, M.; Hu, W. DCFNet: Discriminant Correlation Filters Network for Visual Tracking. arXiv 2017, arXiv:1704.04057. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and Wider Siamese Networks for Real-Time Visual Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. ATOM: Accurate Tracking by Overlap Maximization. arXiv 2018, arXiv:1811.07628. [Google Scholar]
- Bhat, G.; Danelljan, M.; Gool, L.V.; Timofte, R. Learning Discriminative Model Prediction for Tracking. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea, 27 October–2 November 2019; pp. 6181–6190. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # Images | # Categories | # Instances | # Size | # Annotation Type | # Image Type |
|---|---|---|---|---|---|---|
| DOTA | 2806 | 15 | 188,282 | (800, 800)∼(4000, 4000) px | Oriented bounding box | Optical images |
| DIOR | 23,463 | 20 | 192,472 | (800, 800) px | Horizontal bounding box | Optical images |
| Frame Size (px) | Resolution (m) | Target Size (px) | Target Category | Frame Number | FPS | Source | Attributes | |
|---|---|---|---|---|---|---|---|---|
| video 1 | 3840 × 2160 | 0.92 | 48 × 35 | airplane | 568 | 25 | Jilin-1 | SS, RS PTBD, SD, PGFI |
| video 2 | 3840 × 2160 | 0.92 | 14 × 15 | ship | 500 | 25 | Jilin-1 | SS, PTBD, SD |
| video 3 | 3840 × 2160 | 1 | 29 × 79 | train | 362 | 30 | ISS | SD |
| video 4 | 3840 × 2160 | 0.92 | 10 × 30 | a pair of vehicles | 500 | 25 | Jilin-1 | SS, PO, SD |
| video 5 | 3840 × 2160 | 0.92 | 39 × 35 | airplane | 375 | 25 | Jilin-1 | SS, RS, SD, PGFI |
| video 6 | 3840 × 2160 | 0.92 | 154 × 63 | train | 625 | 25 | Jilin-1 | PTBD, SD |
| P | S | FPS | |
|---|---|---|---|
| COCO (a) | 0.875 | 0.596 | 30.467 |
| DOTA+COCO (b) | 0.854 | 0.616 | 30.583 |
| DIOR+COCO (c) | 0.868 | 0.646 | 32.117 |
| DOTA+DIOR (d) | 0.854 | 0.603 | 30.775 |
| DOTA+DIOR+COCO (e) | 0.857 | 0.632 | 30.7 |
| COCO | DOTA + COCO | DIOR + COCO | DOTA + DIOR | DOTA + DIOR COCO | ||
|---|---|---|---|---|---|---|
| NO ID-CIM (a) | P | 0.875 | 0.854 | 0.868 | 0.854 | 0.857 |
| S | 0.596 | 0.616 | 0.646 | 0.603 | 0.632 | |
| N = 120 (b) | P | 0.858 | 0.843 | 0.861 | 0.842 | 0.844 |
| S | 0.616 | 0.605 | 0.676 | 0.594 | 0.624 | |
| N = 130 (c) | P | 0.862 | 0.864 | 0.927 | 0.856 | 0.871 |
| S | 0.625 | 0.644 | 0.694 | 0.627 | 0.668 | |
| N = 140 (d) | P | 0.909 | 0.864 | 0.915 | 0.856 | 0.866 |
| S | 0.642 | 0.645 | 0.688 | 0.631 | 0.665 | |
| N = 150 (e) | P | 0.907 | 0.864 | 0.874 | 0.856 | 0.864 |
| S | 0.638 | 0.644 | 0.68 | 0.629 | 0.666 | |
| N = 160 (f) | P | 0.887 | 0.862 | 0.867 | 0.856 | 0.857 |
| S | 0.631 | 0.642 | 0.67 | 0.627 | 0.658 |
| Trackers | Methods | Features | Backbones | Scheme for Alleviating Model Drift | P | S | FPS |
|---|---|---|---|---|---|---|---|
| KCF [12] | CF-based | HOG Features | - | - | 0.826 | 0.595 | 18.231 |
| DCFNet [44] | CF-based | CNN Features | conv1 from VGG [44] | - | 0.804 | 0.586 | 12.383 |
| ECO [15] | CF-based | CNN Features | ResNet18 with VGG-m conv1 layer [15] | - | 0.842 | 0.596 | 4.904 |
| SiamFC [17] | DL-based | CNN Features | CIResNet22 [45] | - | 0.679 | 0.518 | 61.533 |
| CIResIncep22 [45] | - | 0.841 | 0.567 | 53.833 | |||
| CIResNeXt22 [45] | - | 0.845 | 0.603 | 46.45 | |||
| ATOM [46] | DL-based | CNN Features | ResNet18 [20] | - | 0.598 | 0.414 | 13.953 |
| DiMP [47] | DL-based | CNN Features | ResNet18 [20] | - | 0.576 | 0.427 | 16.689 |
| ResNet50 [20] | - | 0.592 | 0.45 | 14.822 | |||
| SiamRPN [6] | DL-based | CNN Features | CIResNet22 [45] | - | 0.72 | 0.485 | 114.867 |
| SiamRPN++ [16] | DL-based | CNN Features | ResNet50 [20] | - | 0.776 | 0.566 | 31.033 |
| Ours (without ID-CIM) | DL-based | CNN Features | ResNet50 [20] | - | 0.868 | 0.646 | 32.117 |
| Ours (with ID-CIM) | DL-based | CNN Features | ResNet50 [20] | ✓ | 0.927 | 0.694 | 32.117 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, K.; Zhang, X.; Chen, G.; Tan, X.; Liao, P.; Wu, H.; Cui, X.; Zuo, Y.; Lv, Z. Single Object Tracking in Satellite Videos: Deep Siamese Network Incorporating an Interframe Difference Centroid Inertia Motion Model. Remote Sens. 2021, 13, 1298. https://doi.org/10.3390/rs13071298
Zhu K, Zhang X, Chen G, Tan X, Liao P, Wu H, Cui X, Zuo Y, Lv Z. Single Object Tracking in Satellite Videos: Deep Siamese Network Incorporating an Interframe Difference Centroid Inertia Motion Model. Remote Sensing. 2021; 13(7):1298. https://doi.org/10.3390/rs13071298
Chicago/Turabian StyleZhu, Kun, Xiaodong Zhang, Guanzhou Chen, Xiaoliang Tan, Puyun Liao, Hongyu Wu, Xiujuan Cui, Yinan Zuo, and Zhiyong Lv. 2021. "Single Object Tracking in Satellite Videos: Deep Siamese Network Incorporating an Interframe Difference Centroid Inertia Motion Model" Remote Sensing 13, no. 7: 1298. https://doi.org/10.3390/rs13071298
APA StyleZhu, K., Zhang, X., Chen, G., Tan, X., Liao, P., Wu, H., Cui, X., Zuo, Y., & Lv, Z. (2021). Single Object Tracking in Satellite Videos: Deep Siamese Network Incorporating an Interframe Difference Centroid Inertia Motion Model. Remote Sensing, 13(7), 1298. https://doi.org/10.3390/rs13071298