
Deep Metric Learning with Online Hard Mining for Hyperspectral Classification




Abstract
:
1. Introduction
- (1)
- A model based on deep metric learning is proposed for hyperspectral classification. By utilizing the ability of the deep metric learning-based approach to maximize distances between classes and minimize distances within classes, one can effectively reduce the high dimensionality of hyperspectral data while achieving a high classification accuracy.
- (2)
- We introduce the idea of online hard mining for deep metric learning to mine the most discriminative triplets while improving the performance of triplet network. Triplets obtained through an online hard mining strategy are more effective with limited labeled data, significantly improving the classification accuracy.
- (3)
- The experimental results show that the proposed method is superior to other comparison methods for comparing multiple hyperspectral image datasets.
2. Related Work
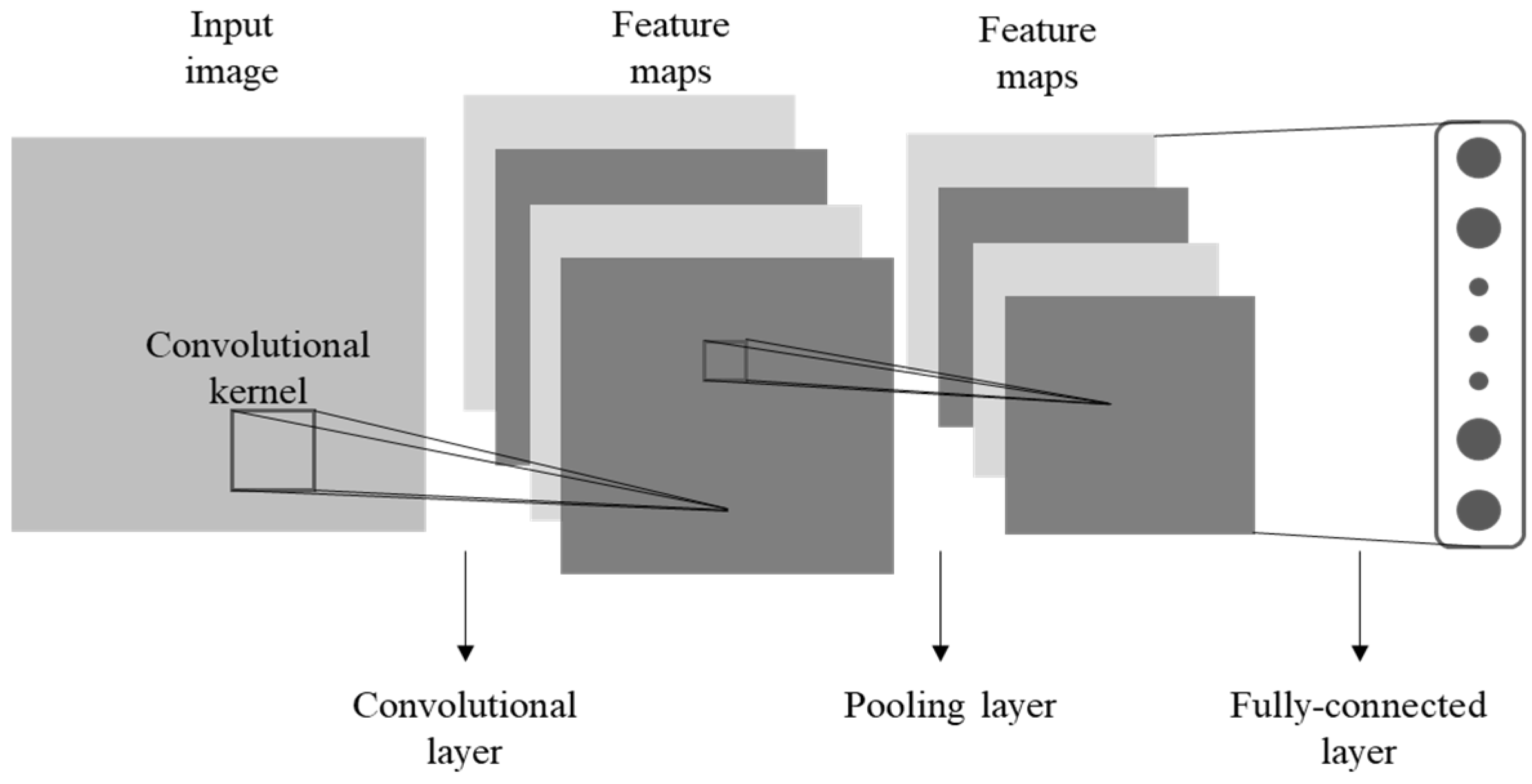
2.1. Convolutional Neural Network
2.1.1. Convolutional Layer
2.1.2. Pooling Layer
2.1.3. Fully Connected Layer
2.2. Deep Metric Learning
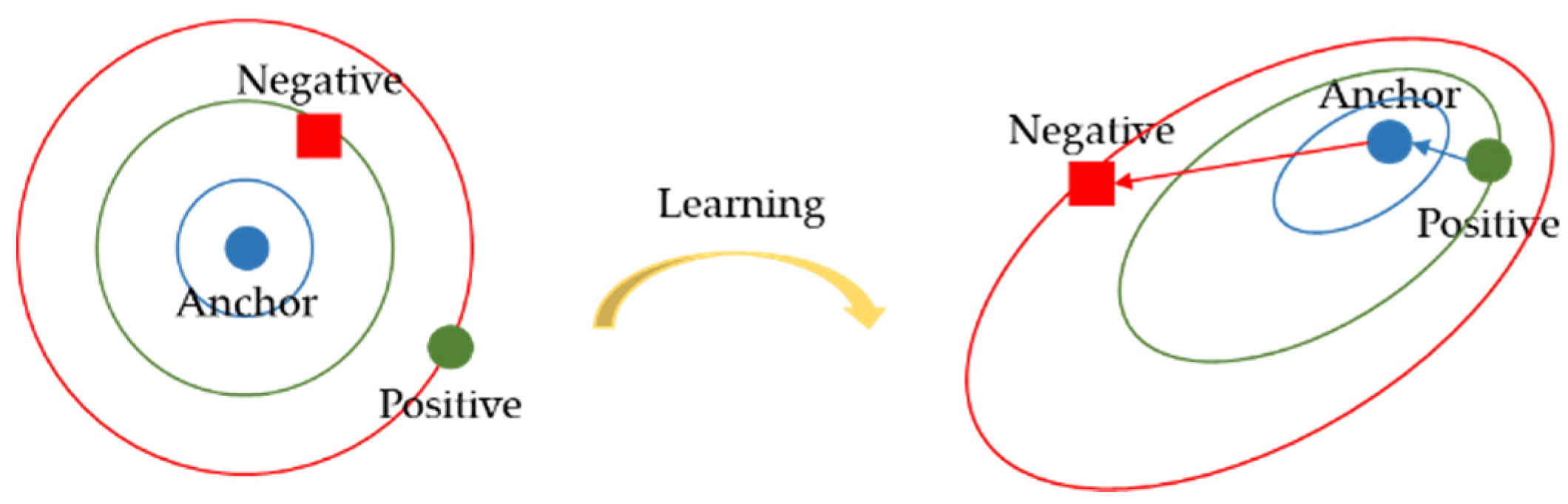
2.3. Sampling Mining Strategy
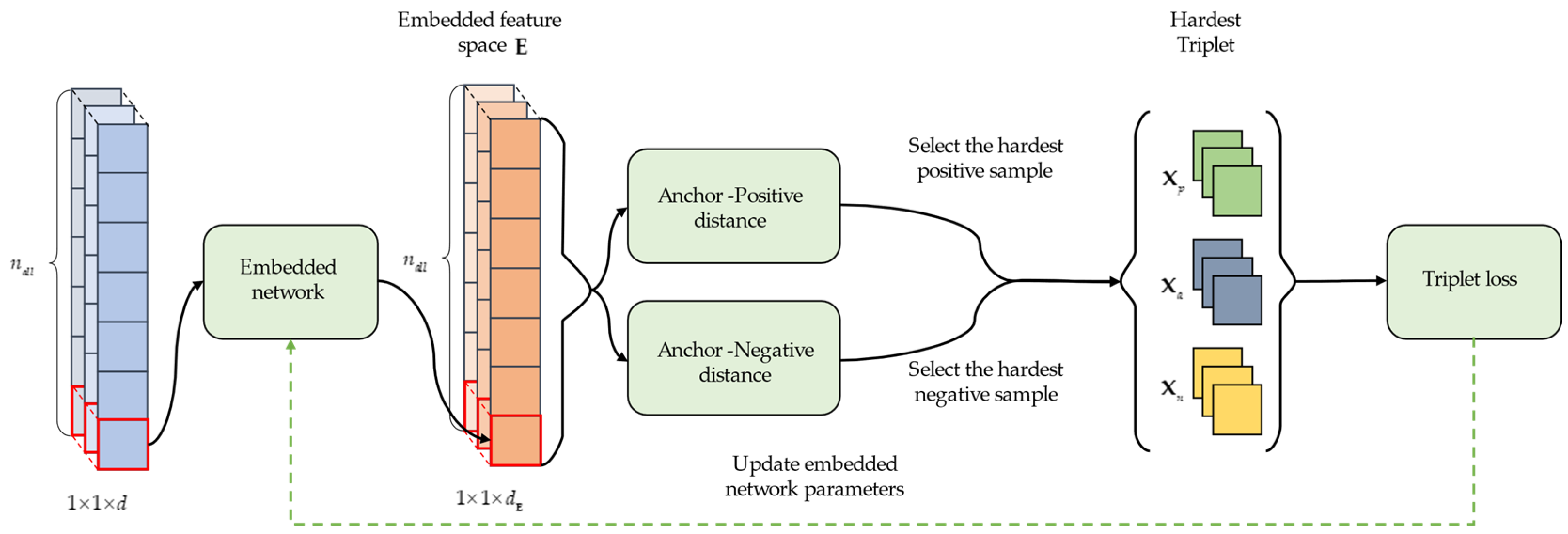
3. Deep Metric Learning with Online Hard Mining
3.1. Deep Metric Learning-Based Model
3.2. Deep Metric Learning for Online Hard Mining
| Algorithm 1 A single iteration for training the DMLOHM |
| Input: Model: The training set , where Parameter: the value of margin m (set as 0.1) Output: Updated model |
| Begin 1. Obtain the embedded features through the embedded net. 2. Utilize the random hardest negative sampling strategy to get the hardest positive samples and hardest negative samples from the embedded features . 3. Calculate the distance of anchor-positive samples and the distance of anchor-negative samples by (1). 4. Calculate the loss by (3) with margin m. 5. Update parameter sets by backpropagating through . End |
4. Experiments and Analysis
4.1. Dataset Description
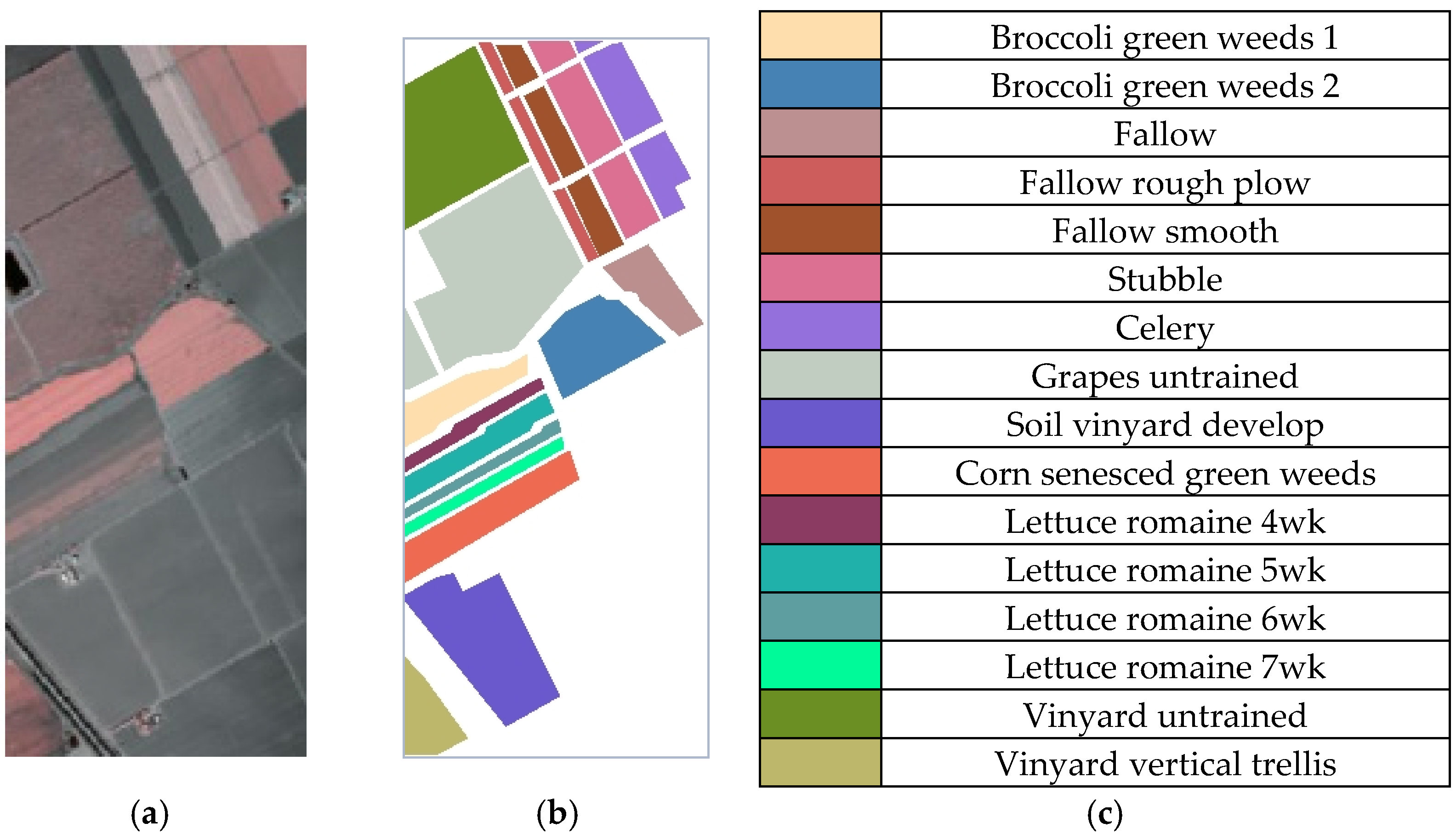
4.1.1. Salinas Dataset
4.1.2. Pavia University Dataset
4.1.3. HyRANK Dataset
4.2. Experimental Setting
4.3. Parameter Setting and Convergence Analysis
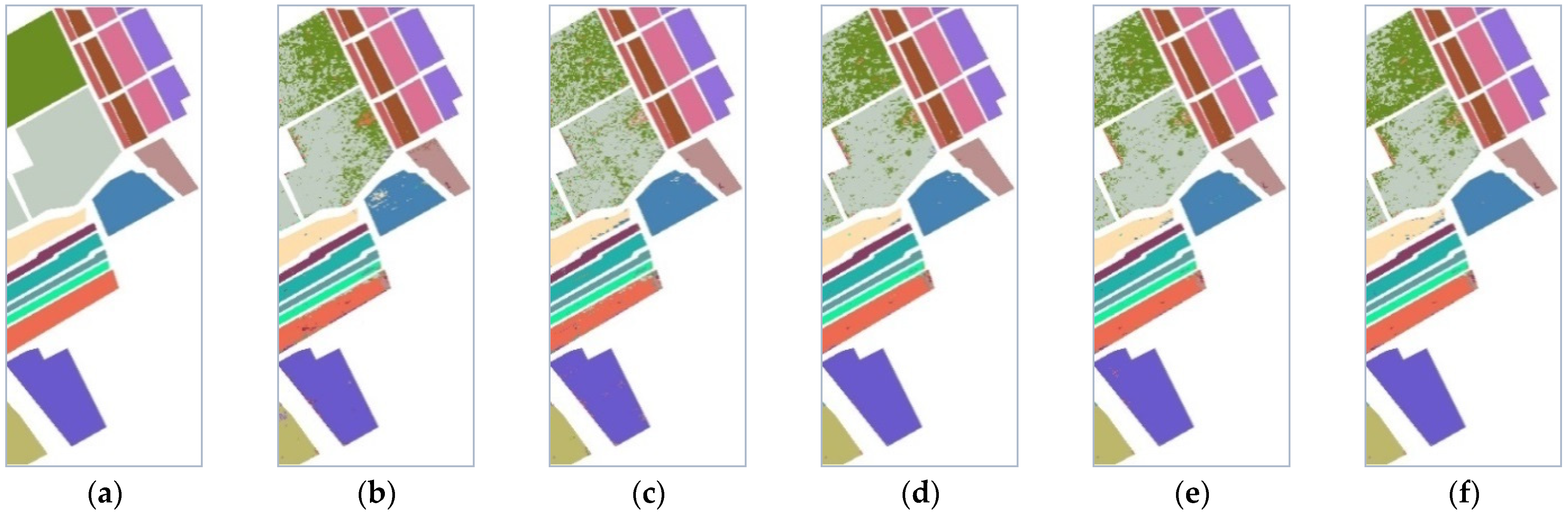
5. Results
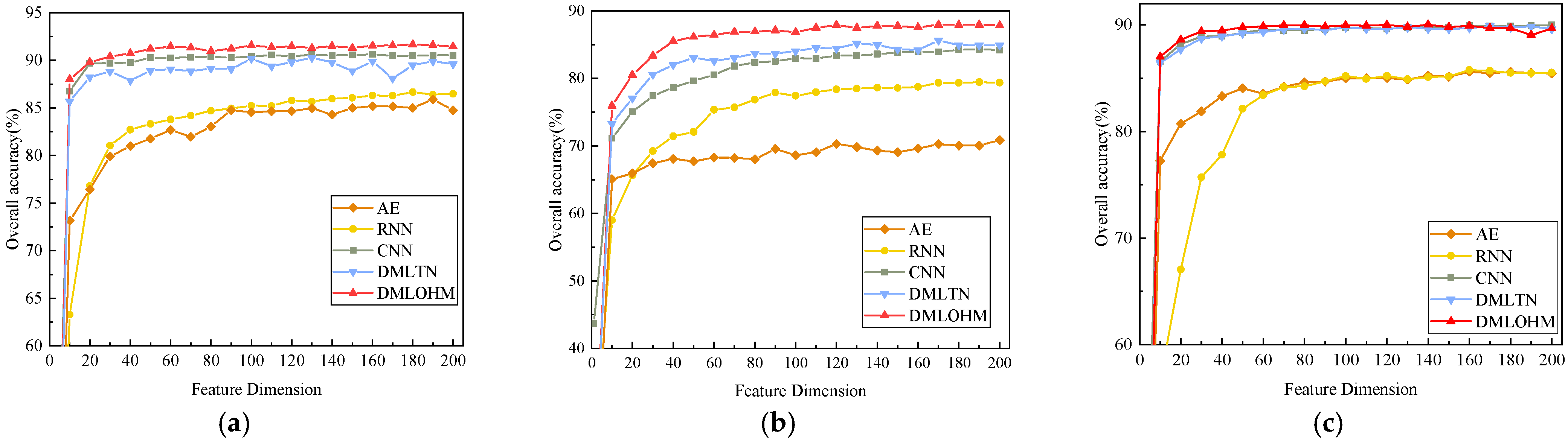
5.1. Dimensionality Reduction
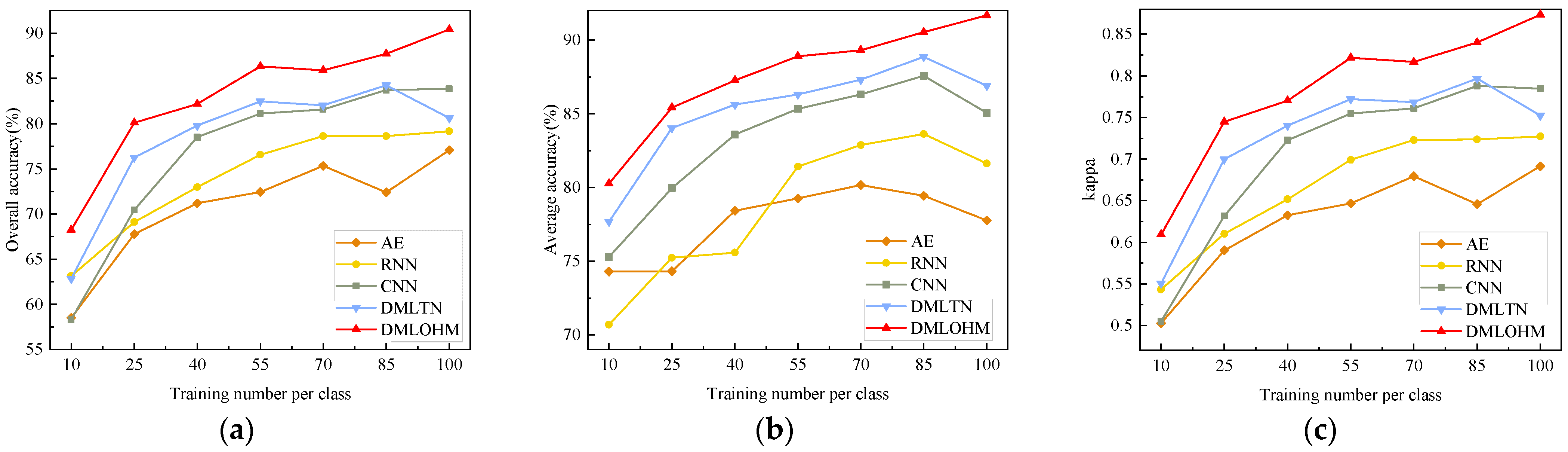
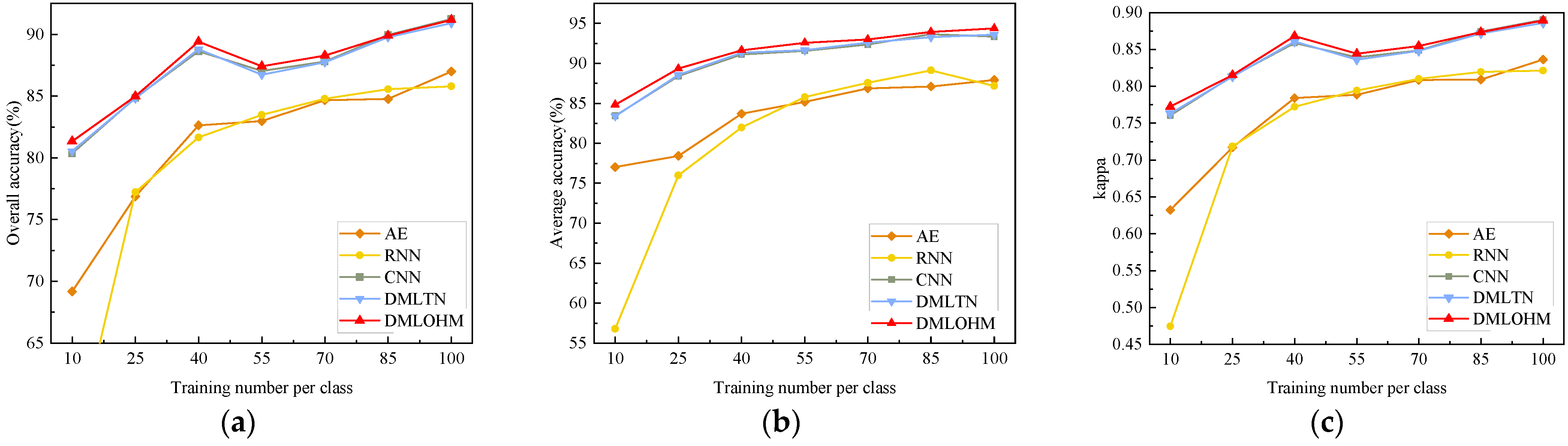
5.2. Limited Labeled Samples Classification
5.3. Other Experiments
5.4. Time Complexity
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Scherrer, B.; Sheppard, J.; Jha, P.; Shaw, J.A. Hyperspectral imaging and neural networks to classify herbicide-resistant weeds. J. Appl. Remote Sens. 2019, 13, 044516. [Google Scholar] [CrossRef]
- Tan, K.; Wang, H.; Chen, L.; Du, Q.; Du, P.; Pan, C. Estimation of the spatial distribution of heavy metal in agricultural soils using airborne hyperspectral imaging and random forest. J. Hazard. Mater. 2020, 382, 120987. [Google Scholar] [CrossRef]
- Tuşa, L.; Khodadadzadeh, M.; Contreras, C.; Rafiezadeh Shahi, K.; Fuchs, M.; Gloaguen, R.; Gutzmer, J. Drill-Core Mineral Abundance Estimation Using Hyperspectral and High-Resolution Mineralogical Data. Remote Sens. 2020, 12, 1218. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Huang, R.; Niu, S.; Cao, Z.; Zhao, L.; Li, J. Local similarity constraint-based sparse algorithm for hyperspectral target detection. J. Appl. Remote. Sens. 2019, 13, 046516. [Google Scholar] [CrossRef]
- Richards, J.A. Clustering and unsupervised classification. In Remote Sensing Digital Image Analysis; Springer: Berlin/Heidelberg, Germany, 2013; pp. 319–341. [Google Scholar]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [Green Version]
- Hyvärinen, A.; Oja, E. Independent component analysis: Algorithms and applications. Neural Netw. 2000, 13, 411–430. [Google Scholar] [CrossRef] [Green Version]
- Bennett, K.P.; Demiriz, A. Semi-supervised support vector machines. In Advances in Neural Information Processing Systems; Mitt Press: Cambridge, MA, USA, 1999; pp. 368–374. [Google Scholar]
- Casalino, G.; Gillis, N. Sequential dimensionality reduction for extracting localized features. Pattern Recognit. 2017, 63, 15–29. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Mika, S.; Ratsch, G.; Weston, J.; Scholkopf, B.; Mullers, K.-R. Fisher discriminant analysis with kernels. In Proceedings of the Neural Networks for Signal Processing IX: Proceedings of the IEEE Signal Processing Society Workshop (Cat. No. 98th8468), Madison, WI, USA, 25–25 August 1999; pp. 41–48. [Google Scholar]
- Baudat, G.; Anouar, F. Generalized Discriminant Analysis Using a Kernel Approach. Neural Comput. 2000, 12, 2385–2404. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.; Müller, K.-R. Nonlinear Component Analysis as a Kernel Eigenvalue Problem. Neural Comput. 1998, 10, 1299–1319. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Marpu, P.R.; Plaza, A.; Bioucas-Dias, J.M.; Benediktsson, J.A. Generalized composite kernel framework for hyperspectral image classification. IEEE Transact. Geosci. Remote Sens. 2013, 51, 4816–4829. [Google Scholar] [CrossRef]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Yao, X.; Cheng, G.; Feng, X.; Xu, D. P-CNN: Part-Based Convolutional Neural Networks for Fine-Grained Visual Categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1. [Google Scholar] [CrossRef]
- Wang, N.; Zha, W.; Li, J.; Gao, X. Back projection: An effective postprocessing method for GAN-based face sketch synthesis. Pattern Recognit. Lett. 2018, 107, 59–65. [Google Scholar] [CrossRef]
- Yuan, X.; Huang, B.; Wang, Y.; Yang, C.; Gui, W. Deep Learning-Based Feature Representation and Its Application for Soft Sensor Modeling With Variable-Wise Weighted SAE. IEEE Trans. Ind. Inform. 2018, 14, 3235–3243. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar] [CrossRef] [Green Version]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H.-C. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sens. 2015, 2015, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Li, Y.; Zhang, H.; Shen, Q. Spectral–Spatial Classification of Hyperspectral Imagery with 3D Convolutional Neural Network. Remote. Sens. 2017, 9, 67. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Wu, G.; Zhang, F.; Du, Q. Hyperspectral Image Classification Using Deep Pixel-Pair Features. IEEE Trans. Geosci. Remote. Sens. 2016, 55, 844–853. [Google Scholar] [CrossRef]
- Pan, B.; Shi, Z.; Xu, X. MugNet: Deep learning for hyperspectral image classification using limited samples. ISPRS J. Photogramm. Remote. Sens. 2018, 145, 108–119. [Google Scholar] [CrossRef]
- Wu, H.; Prasad, S. Semi-Supervised Deep Learning Using Pseudo Labels for Hyperspectral Image Classification. IEEE Trans. Image Process. 2018, 27, 1259–1270. [Google Scholar] [CrossRef]
- Cheng, G.; Xie, X.; Han, J.; Guo, L.; Xia, G.-S. Remote Sensing Image Scene Classification Meets Deep Learning: Challenges, Methods, Benchmarks, and Opportunities. arXiv 2020, arXiv:2005.01094. Available online: https://ieeexplore.ieee.org/document/9127795 (accessed on 30 March 2021). [CrossRef]
- Lu, X.; Sun, H.; Zheng, X. A Feature Aggregation Convolutional Neural Network for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote. Sens. 2019, 57, 7894–7906. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When Deep Learning Meets Metric Learning: Remote Sensing Image Scene Classification via Learning Discriminative CNNs. IEEE Trans. Geosci. Remote. Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Wang, Q.; Wan, J.; Yuan, Y. Locality constraint distance metric learning for traffic congestion detection. Pattern Recognit. 2018, 75, 272–281. [Google Scholar] [CrossRef]
- Weinberger, K.Q.; Saul, L.K. Distance metric learning for large margin nearest neighbor classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar]
- Sundermeyer, M.; Schlüter, R.; Ney, H. LSTM neural networks for language modeling. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Networks 2009, 20, 61–80. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; Mitt Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Hoffer, E.; Ailon, N. Deep metric learning using triplet network. In International Workshop on Similarity-Based Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2015; pp. 84–92. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality reduction by learning an invariant mapping. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1735–1742. [Google Scholar]
- Deng, B.; Jia, S.; Shi, D. Deep Metric Learning-Based Feature Embedding for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote. Sens. 2020, 58, 1422–1435. [Google Scholar] [CrossRef]
- Kaya, M.; Bilge, H. Şakir Deep Metric Learning: A Survey. Symmetry 2019, 11, 1066. [Google Scholar] [CrossRef] [Green Version]
- Bell, S.; Bala, K. Learning visual similarity for product design with convolutional neural networks. ACM Trans. Graph. 2015, 34, 1–10. [Google Scholar] [CrossRef]
- Wang, N.; Gao, X.; Li, J. Random sampling for fast face sketch synthesis. Pattern Recognit. 2018, 76, 215–227. [Google Scholar] [CrossRef] [Green Version]
- Simo-Serra, E.; Trulls, E.; Ferraz, L.; Kokkinos, I.; Fua, P.; Moreno-Noguer, F. Discriminative learning of deep convolutional feature point descriptors. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 118–126. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Manmatha, R.; Wu, C.; Smola, A.J.; Krahenbuhl, P. Sampling Matters in Deep Embedding Learning. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2859–2867. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In Defense of the Triplet Loss for Person Re-Identification. arXiv 2017, arXiv:abs/1703.07737. Available online: https://arxiv.org/abs/1703.07737 (accessed on 30 March 2021).
- Dong, Y.; Du, B.; Zhang, L.; Zhang, L. Dimensionality reduction and classification of hyperspectral images using ensemble discriminative local metric learning. IEEE Transact. Geosci. Remote Sens. 2017, 55, 2509–2524. [Google Scholar] [CrossRef]
- Li, J.; Huang, X.; Gamba, P.; Bioucas-Dias, J.M.B.; Zhang, L.; Benediktsson, J.A.; Plaza, A. Multiple Feature Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1592–1606. [Google Scholar] [CrossRef] [Green Version]
- Cao, X.; Ge, Y.; Li, R.; Zhao, J.; Jiao, L. Hyperspectral imagery classification with deep metric learning. Neurocomputing 2019, 356, 217–227. [Google Scholar] [CrossRef]
- Lennon, R. Remote Sensing Digital Image Analysis: An Introduction; Esa/Esrin: Frascati, Italy, 2002. [Google Scholar]
- Dong, Y.; Liang, T.; Zhang, Y.; Du, B. Spectral-Spatial Weighted Kernel Manifold Embedded Distribution Alignment for Remote Sensing Image Classification. IEEE Trans. Cybern. 2020, 1–13. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Color | Name | Total Number of Samples |
|---|---|---|---|
| C1 | Broccoli green weeds 1 | 2009 | |
| C2 | Broccoli green weeds 2 | 3726 | |
| C3 | Fallow | 1976 | |
| C4 | Fallow rough plow | 1394 | |
| C5 | Fallow smooth | 2678 | |
| C6 | Stubble | 3959 | |
| C7 | Celery | 3579 | |
| C8 | Grapes untrained | 11,271 | |
| C9 | Soil vinyard develop | 6203 | |
| C10 | Corn senesced green weeds | 3278 | |
| C11 | Lettuce romaine 4wk | 1068 | |
| C12 | Lettuce romaine 5wk | 1927 | |
| C13 | Lettuce romaine 6wk | 916 | |
| C14 | Lettuce romaine 7wk | 1070 | |
| C15 | Vinyard untrained | 7268 | |
| C16 | Vinyard vertical trellis | 1807 | |
| Total | 54,129 |
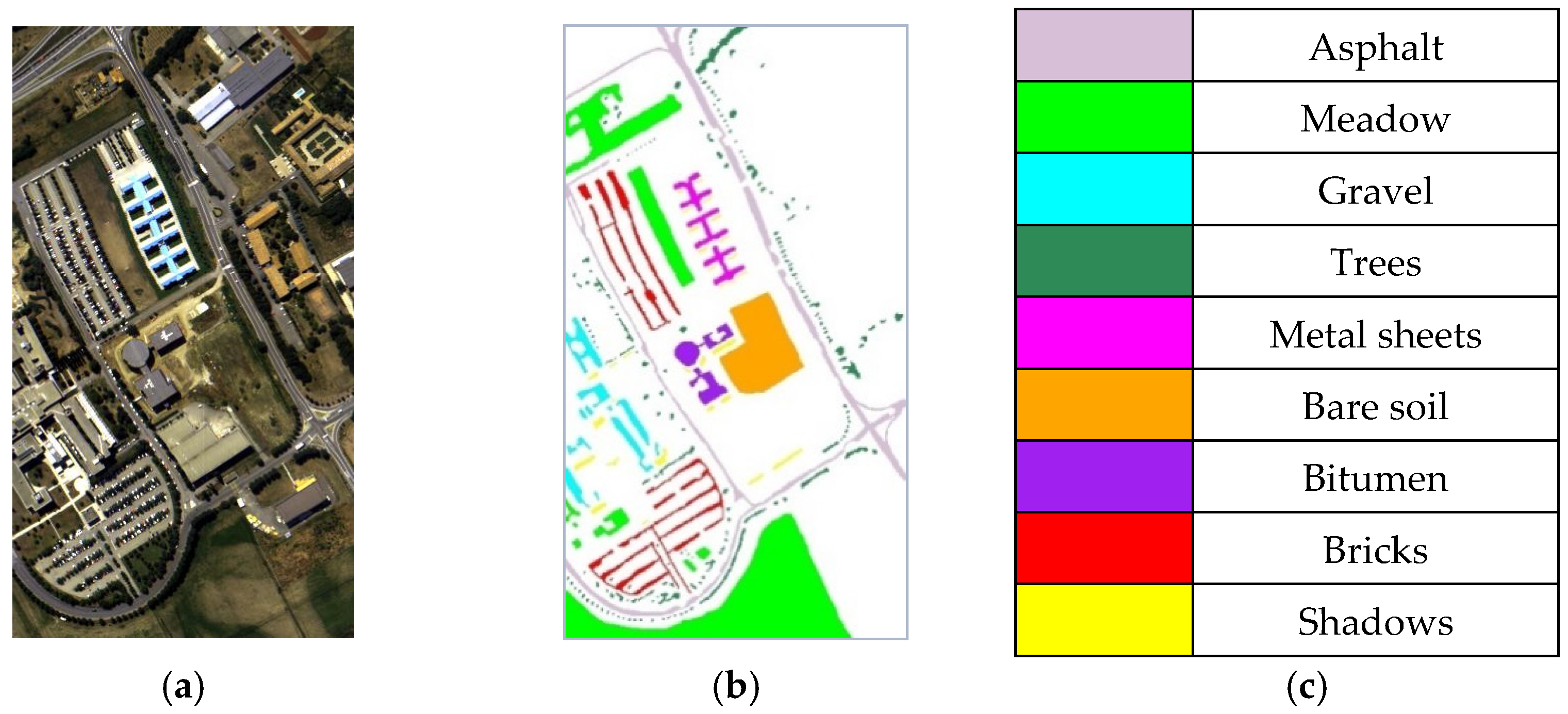
| Class | Color | Name | Total Number of Samples |
|---|---|---|---|
| C1 | Asphalt | 6631 | |
| C2 | Meadow | 18,649 | |
| C3 | Gravel | 2099 | |
| C4 | Trees | 3064 | |
| C5 | Metal sheets | 1345 | |
| C6 | Bare soil | 5029 | |
| C7 | Bitumen | 1330 | |
| C8 | Bricks | 3682 | |
| C9 | Shadows | 947 | |
| Total | 42,776 |
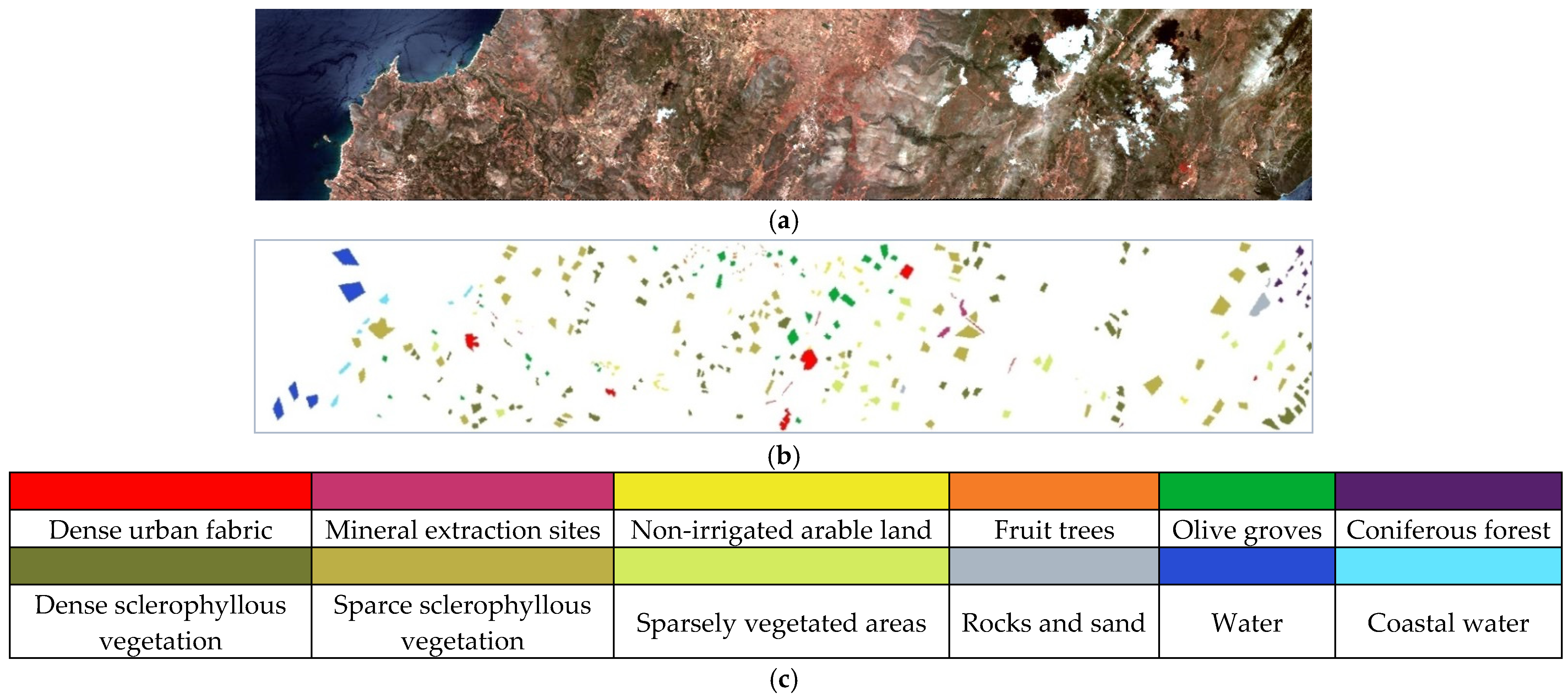
| Class | Color | Name | Total Number of Samples |
|---|---|---|---|
| C1 | Dense urban fabric | 1262 | |
| C2 | Mineral extraction sites | 204 | |
| C3 | Non-irrigated arable land | 614 | |
| C4 | Fruit trees | 150 | |
| C5 | Olive groves | 1768 | |
| C6 | Coniferous forest | 361 | |
| C7 | Dense sclerophyllous vegetation | 5035 | |
| C8 | Sparce sclerophyllous vegetation | 6374 | |
| C9 | Sparcely vegetated areas | 1754 | |
| C10 | Rocks and sand | 492 | |
| C11 | Water | 1612 | |
| C12 | Coastal water | 398 | |
| Total | 20,024 |
| AE | RNN | CNN | DMLTN | DMLOHM | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Class | Mean | Std | Mean | Std | Mean | Std | Mean | Std | Mean | Std |
| C1 | 97.22 | 1.3627 | 98.65 | 1.2857 | 98.65 | 0.6453 | 98.53 | 1.8467 | 99.77 | 0.0483 |
| C2 | 99.34 | 0.9468 | 98.78 | 0.5281 | 99.66 | 0.3874 | 99.07 | 1.1015 | 99.89 | 0.0276 |
| C3 | 95.09 | 2.2834 | 96.93 | 0.9080 | 99.24 | 0.4368 | 99.15 | 0.4288 | 99.92 | 0.1227 |
| C4 | 99.66 | 0.1069 | 99.54 | 0.2178 | 99.71 | 0.0337 | 99.69 | 0.0354 | 99.72 | 0.0538 |
| C5 | 97.67 | 0.7972 | 96.77 | 0.3585 | 98.19 | 0.2418 | 97.13 | 4.2324 | 98.71 | 0.2078 |
| C6 | 99.71 | 0.0832 | 99.58 | 0.3136 | 99.81 | 0.0258 | 99.74 | 0.0493 | 99.79 | 0.0063 |
| C7 | 98.62 | 1.8405 | 99.19 | 0.1535 | 99.48 | 0.0579 | 99.48 | 0.1080 | 99.59 | 0.0658 |
| C8 | 72.35 | 2.3715 | 71.04 | 6.4577 | 80.32 | 2.1563 | 69.80 | 15.0745 | 76.65 | 5.5246 |
| C9 | 98.84 | 0.5185 | 98.80 | 0.3933 | 99.38 | 0.2161 | 99.51 | 0.4952 | 99.89 | 0.0462 |
| C10 | 88.78 | 1.2900 | 86.23 | 1.3433 | 91.33 | 0.5655 | 92.11 | 0.9608 | 96.63 | 0.4062 |
| C11 | 93.61 | 1.4996 | 97.05 | 1.0173 | 97.24 | 0.3975 | 98.34 | 0.7326 | 98.57 | 0.2012 |
| C12 | 98.75 | 1.3655 | 97.34 | 1.5305 | 98.91 | 0.4584 | 99.11 | 0.7789 | 99.90 | 0.0583 |
| C13 | 98.46 | 0.1872 | 98.28 | 0.7329 | 99.23 | 0.2783 | 99.27 | 0.2909 | 99.66 | 0.0759 |
| C14 | 92.86 | 0.9391 | 93.00 | 1.5808 | 97.29 | 0.7526 | 97.52 | 0.5400 | 98.77 | 0.1197 |
| C15 | 63.12 | 3.3930 | 53.36 | 9.3126 | 69.19 | 3.5673 | 74.19 | 16.5001 | 78.20 | 4.5129 |
| C16 | 95.37 | 3.3747 | 96.27 | 1.0644 | 98.43 | 0.1059 | 98.35 | 0.0983 | 98.68 | 0.0705 |
| AA | 93.09 | 0.4580 | 92.54 | 0.3131 | 95.37 | 0.2045 | 95.06 | 0.5061 | 96.52 | 0.0751 |
| OA | 87.27 | 0.0515 | 85.61 | 0.559 | 90.58 | 0.0264 | 89.02 | 1.4321 | 91.63 | 0.0548 |
| Kappa | 0.8582 | 0.0057 | 0.8396 | 0.0061 | 0.8950 | 0.0029 | 0.8779 | 0.0155 | 0.9068 | 0.0059 |
| AE | RNN | CNN | DMLTN | DMLOHM | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Class | Mean | Std | Mean | Std | Mean | Std | Mean | Std | Mean | Std |
| C1 | 67.88 | 3.1520 | 79.21 | 4.0860 | 81.14 | 0.9982 | 81.73 | 3.4160 | 84.15 | 1.4853 |
| C2 | 71.50 | 3.8101 | 76.78 | 3.7735 | 82.94 | 0.9966 | 81.26 | 3.1677 | 86.69 | 1.1915 |
| C3 | 60.87 | 22.9224 | 70.75 | 7.6683 | 78.58 | 6.2574 | 79.49 | 7.7648 | 79.18 | 5.7180 |
| C4 | 91.26 | 2.9592 | 90.90 | 3.2136 | 93.15 | 0.9456 | 94.79 | 1.6010 | 96.63 | 0.3333 |
| C5 | 99.67 | 0.1191 | 99.46 | 0.1206 | 99.88 | 0.0566 | 99.83 | 0.0454 | 99.88 | 0.0566 |
| C6 | 54.00 | 3.8511 | 67.12 | 4.5458 | 76.04 | 1.6330 | 83.66 | 2.9837 | 88.58 | 1.4022 |
| C7 | 90.77 | 1.2038 | 86.57 | 5.4623 | 90.43 | 0.7575 | 91.74 | 2.2630 | 92.87 | 0.9842 |
| C8 | 79.00 | 13.3296 | 81.85 | 3.8278 | 86.08 | 3.3800 | 87.24 | 4.3455 | 86.98 | 6.1821 |
| C9 | 99.99 | 0.0379 | 100.00 | 0.0000 | 99.94 | 0.0632 | 99.98 | 0.0506 | 99.96 | 0.0580 |
| AA | 79.44 | 1.7345 | 83.63 | 1.0873 | 87.58 | 0.3755 | 88.86 | 0.6873 | 90.55 | 0.3262 |
| OA | 72.41 | 0.1329 | 78.61 | 0.1020 | 83.70 | 0.0340 | 84.25 | 1.2638 | 87.73 | 0.5049 |
| Kappa | 0.6459 | 0.0151 | 0.7235 | 0.0114 | 0.7879 | 0.0040 | 0.7967 | 0.0150 | 0.8402 | 0.0062 |
| AE | RNN | CNN | DMLTN | DMLOHM | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Class | Mean | Std | Mean | Std | Mean | Std | Mean | Std | Mean | Std |
| C1 | 61.15 | 6.4555 | 69.48 | 2.0579 | 83.64 | 2.0224 | 80.60 | 2.7210 | 84.15 | 1.6429 |
| C2 | 92.78 | 0.7084 | 93.70 | 1.4948 | 96.56 | 0.6198 | 96.64 | 0.7920 | 97.56 | 0.2656 |
| C3 | 85.99 | 4.3622 | 87.07 | 3.9504 | 93.33 | 0.9224 | 94.08 | 1.2981 | 93.93 | 0.7888 |
| C4 | 97.69 | 2.2052 | 96.92 | 1.9180 | 99.85 | 0.4870 | 100.00 | 0.0000 | 100.00 | 0.0000 |
| C5 | 73.23 | 3.6589 | 72.68 | 4.0310 | 82.90 | 0.8875 | 81.98 | 1.9504 | 84.43 | 0.6411 |
| C6 | 99.35 | 1.1036 | 98.41 | 0.7690 | 100.00 | 0.0000 | 99.93 | 0.1518 | 100.00 | 0.0000 |
| C7 | 89.91 | 0.7151 | 90.31 | 0.9047 | 92.60 | 0.3768 | 91.49 | 0.4103 | 91.22 | 0.3840 |
| C8 | 86.04 | 1.7030 | 84.02 | 1.6785 | 86.47 | 0.8296 | 88.05 | 1.2872 | 86.76 | 0.4438 |
| C9 | 74.09 | 3.8638 | 80.32 | 2.7080 | 90.09 | 0.8269 | 90.20 | 2.6676 | 90.01 | 1.7745 |
| C10 | 94.13 | 2.3209 | 98.60 | 0.7511 | 99.56 | 0.1539 | 99.75 | 0.2310 | 99.68 | 0.2834 |
| C11 | 96.80 | 1.7678 | 98.58 | 1.3699 | 99.91 | 0.1198 | 97.51 | 5.8051 | 99.97 | 0.0827 |
| C12 | 94.15 | 4.1062 | 99.55 | 0.8950 | 98.88 | 0.4588 | 98.91 | 0.8560 | 99.62 | 0.4475 |
| AA | 87.11 | 0.6105 | 89.14 | 0.5744 | 93.65 | 0.1526 | 93.26 | 0.4684 | 93.94 | 0.1763 |
| OA | 84.76 | 0.0624 | 85.56 | 0.0470 | 89.95 | 0.0263 | 89.76 | 0.5770 | 89.89 | 0.2216 |
| Kappa | 0.8091 | 0.0074 | 0.8196 | 0.0057 | 0.8743 | 0.0032 | 0.8718 | 0.0070 | 0.8736 | 0.0027 |
| Dataset | AE | RNN | CNN | DMLTN | DMLOHM |
|---|---|---|---|---|---|
| Salinas | 251.8425 | 239.5069 | 12.6026 | 19.9895 | 76.5048 |
| Pavia University | 196.8264 | 92.3627 | 7.6125 | 11.8698 | 74.8602 |
| HyRANK | 95.9221 | 90.6688 | 7.2823 | 15.3791 | 74.5944 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, Y.; Yang, C.; Zhang, Y. Deep Metric Learning with Online Hard Mining for Hyperspectral Classification. Remote Sens. 2021, 13, 1368. https://doi.org/10.3390/rs13071368
Dong Y, Yang C, Zhang Y. Deep Metric Learning with Online Hard Mining for Hyperspectral Classification. Remote Sensing. 2021; 13(7):1368. https://doi.org/10.3390/rs13071368
Chicago/Turabian StyleDong, Yanni, Cong Yang, and Yuxiang Zhang. 2021. "Deep Metric Learning with Online Hard Mining for Hyperspectral Classification" Remote Sensing 13, no. 7: 1368. https://doi.org/10.3390/rs13071368
APA StyleDong, Y., Yang, C., & Zhang, Y. (2021). Deep Metric Learning with Online Hard Mining for Hyperspectral Classification. Remote Sensing, 13(7), 1368. https://doi.org/10.3390/rs13071368