
An EEMD-BiLSTM Algorithm Integrated with Boruta Random Forest Optimiser for Significant Wave Height Forecasting along Coastal Areas of Queensland, Australia



Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area and Data
2.2. Data Preparation
2.3. Data Normalisation
2.4. Data Decomposition by Ensemble Empirical Mode Decomposition (EEMD)
- The n-dimensional length either has an equal number of extrema and zero crossings, or they differ at most by one.
- The mean value at any point which is defined by local maxima and the envelope defined by the local minima are zero.
- The white noise series are added to the wave data;
- Wave dataset is then decomposed with added white noise into its IMFs (see Figure 2);
- Steps 1 and 2 are repeated with different Gaussian white noise series.
- Since the mean value of added noise is zero, the average over all corresponding IMFs will be the final decomposition.
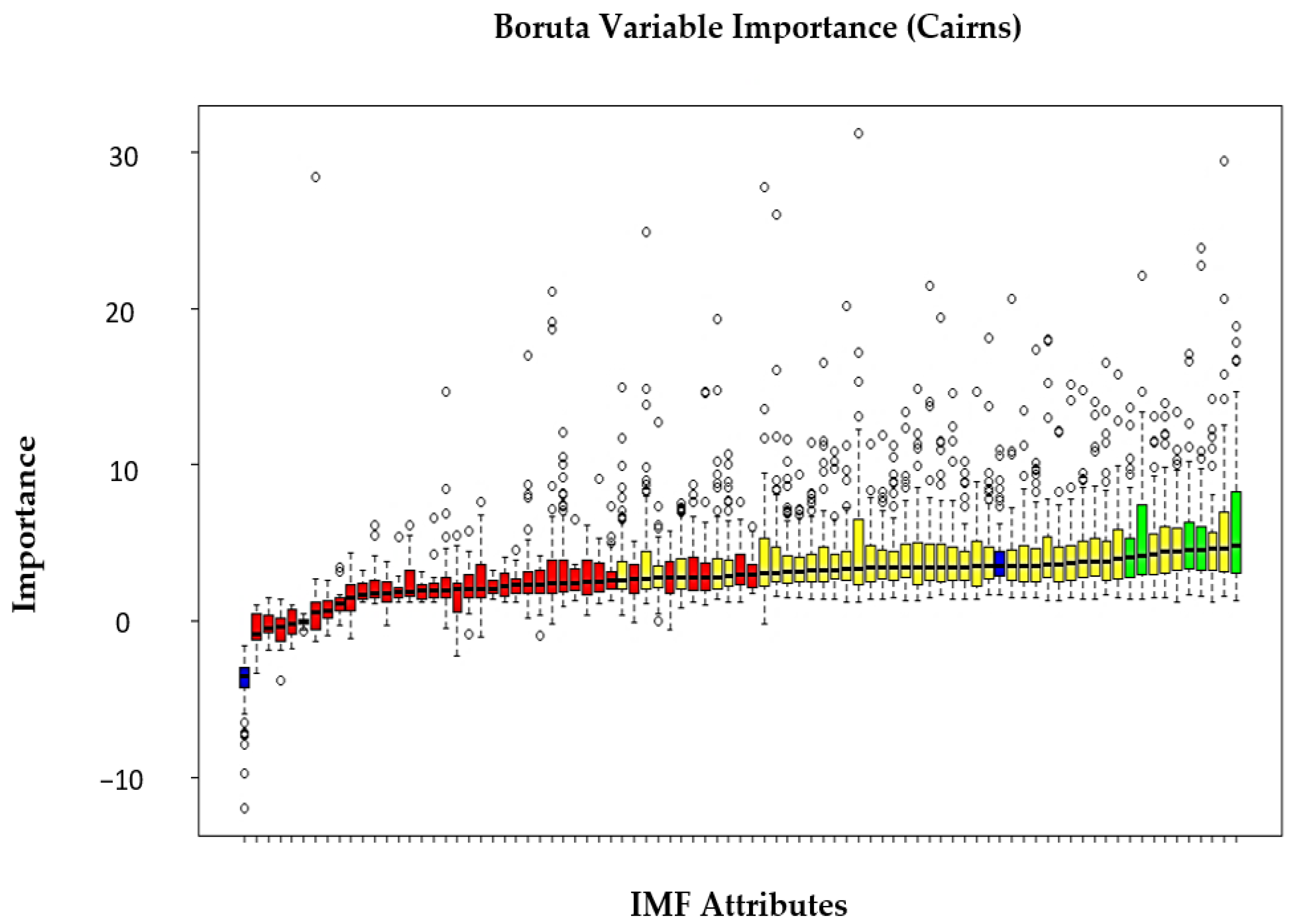
2.5. Feature Selection by Boruta Random Forest Optimiser (BRF)
- the information system is extended by the addition of all variables in consideration, minimum of five shadow attributes are added;
- the added attributes are shuffled so that their correlation with the response are removed;
- the random forest classifier is applied to gather the z-scores;
- the maximum z-score among the shadow attributes is found and every attribute that has a better score than this is taken as a hit;
- a two-sided test of equality is performed with attributes that attained an undetermined importance;
- the attributes that have significantly lower z-score than the maximum z-score among the shadow attributes are removed;
- the attributes that have significantly higher z-score are selected;
- all shadow attributes are then removed.
2.6. Modal Development
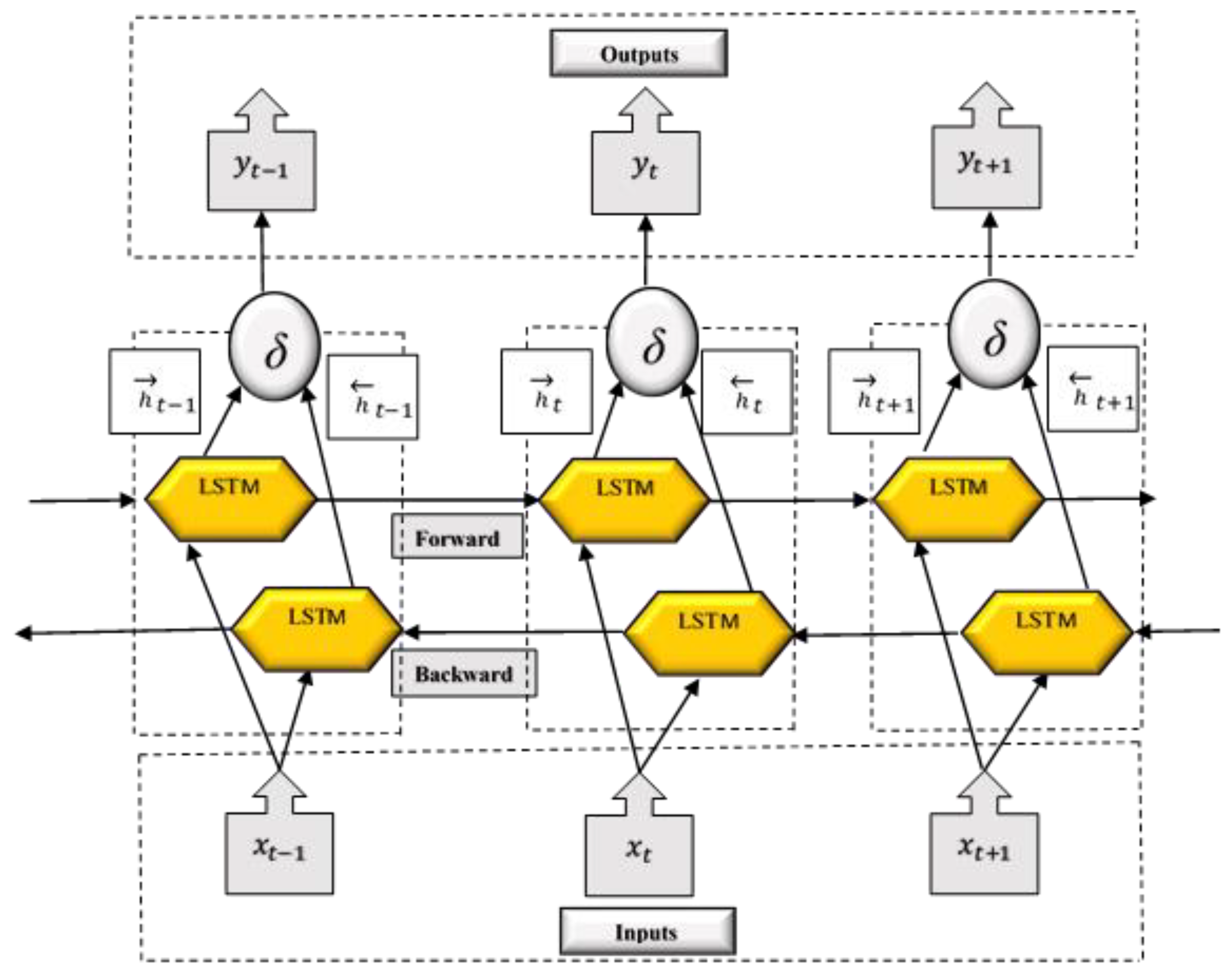
2.6.1. Bidirectional Long Short-Term Memory (BiLSTM) Model Development
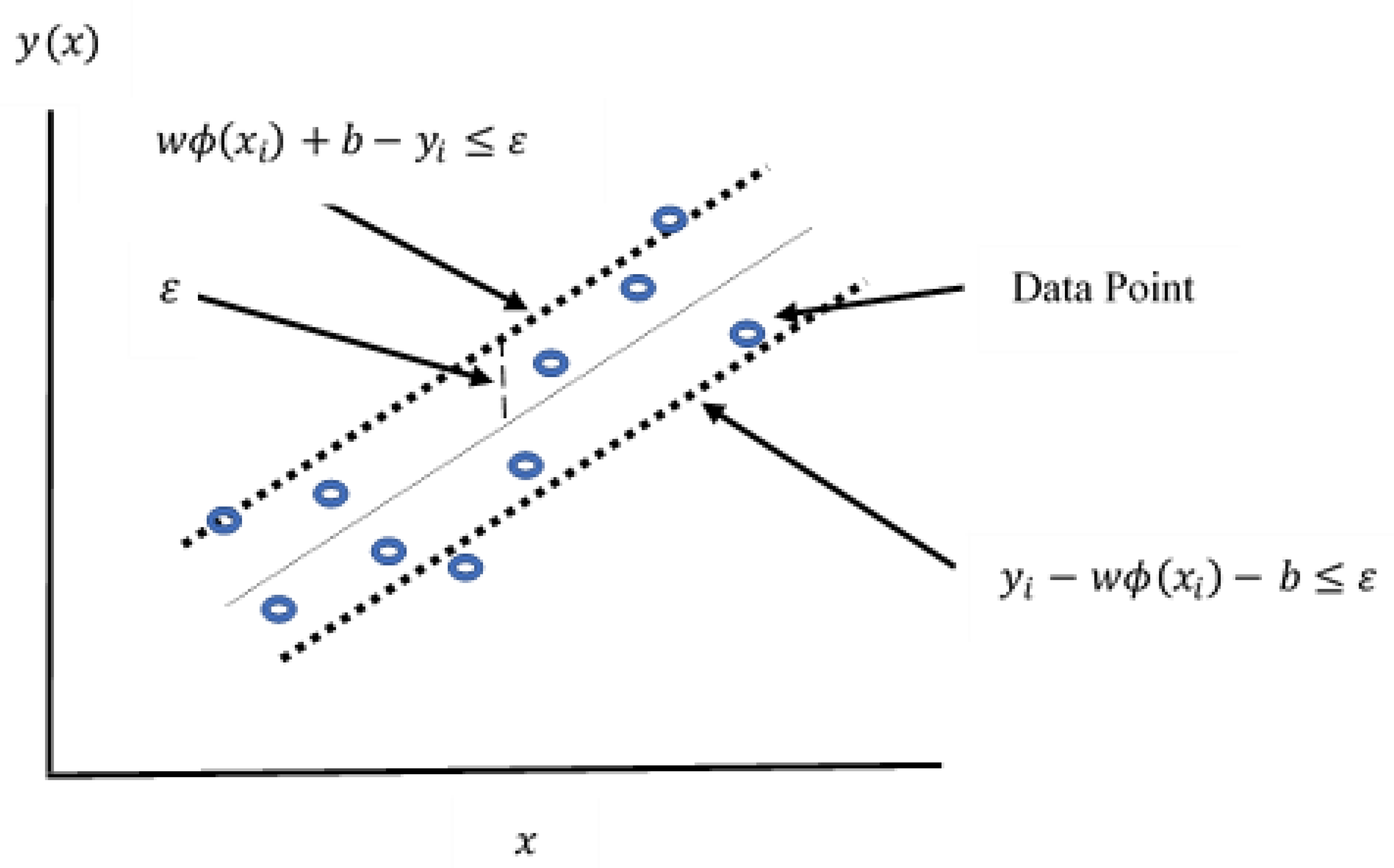
2.6.2. Support Vector Regression (SVR) Model Development
2.6.3. Bi-Directional Long Short-Term Memory (BiLSTM) Architecture
3. Results and Discussion
- Pearson’s Correlation Coefficient (R)
- 2
- Nash-Sutcliffe Coefficient (NS)
- 3
- Willmott’s Index of agreement (WI)
- 4
- Root Mean Square Error (RMSE)
- 5
- Mean Absolute Error (MAE)
- 6
- Mean Absolute Percentage Error (MAPE)
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Doukakis, E. Coastal vulnerability and risk parameters. Eur. Water 2005, 11, 3–7. [Google Scholar]
- Mimura, N. Vulnerability of island countries in the South Pacific to sea level rise and climate change. Clim. Res. 1999, 12, 137–143. [Google Scholar] [CrossRef]
- Aung, T.H.; Singh, A.M.; Prasad, U.W. Sea level threat in Tuvalu. Am. J. Appl. Sci. 2009, 6, 1169–1174. [Google Scholar] [CrossRef] [Green Version]
- Hopley, D.; Smithers, S.G.; Parnell, K. The Geomorphology of the Great Barrier Reef: Development, Diversity and Change; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Hardy, T.A.; Mason, L.B.; McConochie, J.D. A wave model for the Great Barrier Reef. Ocean Eng. 2001, 28, 45–70. [Google Scholar] [CrossRef]
- Hench, J.L.; Leichter, J.J.; Monismith, S.G. Episodic circulation and exchange in a wave-driven coral reef and lagoon system. Limnol. Oceanogr. 2008, 53, 2681–2694. [Google Scholar] [CrossRef] [Green Version]
- Young, I.R. Wave transformation over coral reefs. J. Geophys. Res. Ocean. 1989, 94, 9779–9789. [Google Scholar] [CrossRef]
- Hardy, T.; Young, I. Modelling spectral wave transformation on a coral reef flat. In Coastal Engineering: Climate for Change, Proceedings of the 10th Australasian Conference on Coastal and Ocean Engineering 1991, Auckland, New Zealand, 2–6 December 1991; Water Quality Centre, DSIR Marine and Freshwater: Hamilton, New Zealand, 1991. [Google Scholar]
- Wu, N.; Wang, Q.; Xie, X. Ocean wave energy harvesting with a piezoelectric coupled buoy structure. Appl. Ocean Res. 2015, 50, 110–118. [Google Scholar] [CrossRef]
- McCormick, M.E. Ocean Wave Energy Conversion; Courier Corporation: Chelmsford, MA, USA, 2013. [Google Scholar]
- Pecher, A.; Kofoed, J.P. Handbook of Ocean Wave Energy; Springer: London, UK, 2017. [Google Scholar]
- Thomsen, K. Offshore Wind: A Comprehensive Guide to Successful Offshore Wind Farm Installation; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Wang, H.; Wang, J.; Yang, J.; Ren, L.; Zhu, J.; Yuan, X.; Xie, C. Empirical algorithm for significant wave height retrieval from wave mode data provided by the Chinese satellite Gaofen-3. Remote Sens. 2018, 10, 363. [Google Scholar] [CrossRef] [Green Version]
- Ibarra-Berastegi, G.; Saénz, J.; Esnaola, G.; Ezcurra, A.; Ulazia, A. Short-term forecasting of the wave energy flux: Analogues, random forests, and physics-based models. Ocean Eng. 2015, 104, 530–539. [Google Scholar] [CrossRef]
- Cornejo-Bueno, L.; Nieto-Borge, J.; García-Díaz, P.; Rodríguez, G.; Salcedo-Sanz, S. Significant wave height and energy flux prediction for marine energy applications: A grouping genetic algorithm–Extreme Learning Machine approach. Renew. Energy 2016, 97, 380–389. [Google Scholar] [CrossRef]
- Deo, M.; Naidu, C.S. Real time wave forecasting using neural networks. Ocean Eng. 1998, 26, 191–203. [Google Scholar] [CrossRef]
- Savitha, R.; Al Mamun, A. Regional ocean wave height prediction using sequential learning neural networks. Ocean Eng. 2017, 129, 605–612. [Google Scholar]
- Zhang, Y.; Xiong, R.; He, H.; Pecht, M.G. Long short-term memory recurrent neural network for remaining useful life prediction of lithium-ion batteries. IEEE Trans. Veh. Technol. 2018, 67, 5695–5705. [Google Scholar] [CrossRef]
- Cui, Z.; Ke, R.; Pu, Z.; Wang, Y. Deep bidirectional and unidirectional LSTM recurrent neural network for network-wide traffic speed prediction. arXiv 2018, arXiv:1801.02143. [Google Scholar]
- Carballo, J.A.; Bonilla, J.; Berenguel, M.; Fernández-Reche, J.; García, G. New approach for solar tracking systems based on computer vision, low cost hardware and deep learning. Renew. Energy 2019, 133, 1158–1166. [Google Scholar] [CrossRef] [Green Version]
- Wen, L.; Zhou, K.; Yang, S.; Lu, X. Optimal load dispatch of community microgrid with deep learning based solar power and load forecasting. Energy 2019, 171, 1053–1065. [Google Scholar] [CrossRef]
- Feng, C.; Cui, M.; Hodge, B.-M.; Zhang, J. A data-driven multi-model methodology with deep feature selection for short-term wind forecasting. Appl. Energy 2017, 190, 1245–1257. [Google Scholar] [CrossRef] [Green Version]
- Qolipour, M.; Mostafaeipour, A.; Saidi-Mehrabad, M.; Arabnia, H.R. Prediction of wind speed using a new Grey-extreme learning machine hybrid algorithm: A case study. Energy Environ. 2019, 30, 44–62. [Google Scholar] [CrossRef]
- Qin, Y.; Wang, X.; Zou, J. The optimized deep belief networks with improved logistic Sigmoid units and their application in fault diagnosis for planetary gearboxes of wind turbines. IEEE Trans. Ind. Electron. 2019, 66, 3814–3824. [Google Scholar] [CrossRef]
- Jiang, G.; He, H.; Yan, J.; Xie, P. Multiscale convolutional neural networks for fault diagnosis of wind turbine gearbox. IEEE Trans. Ind. Electron. 2019, 66, 3196–3207. [Google Scholar] [CrossRef]
- Zhang, C.-Y.; Chen, C.P.; Gan, M.; Chen, L. Predictive deep Boltzmann machine for multiperiod wind speed forecasting. IEEE Trans. Sustain. Energy 2015, 6, 1416–1425. [Google Scholar] [CrossRef]
- Wang, H.; Wang, G.; Li, G.; Peng, J.; Liu, Y. Deep belief network based deterministic and probabilistic wind speed forecasting approach. Appl. Energy 2016, 182, 80–93. [Google Scholar] [CrossRef]
- Dalto, M.; Matuško, J.; Vašak, M. Deep neural networks for ultra-short-term wind forecasting. In Proceedings of the Industrial Technology (ICIT), Seville, Spain, 17–19 March 2015; pp. 1657–1663. [Google Scholar]
- Hu, Q.; Zhang, R.; Zhou, Y. Transfer learning for short-term wind speed prediction with deep neural networks. Renew. Energy 2016, 85, 83–95. [Google Scholar] [CrossRef]
- Ghimire, S.; Deo, R.C.; Raj, N.; Mi, J. Deep solar radiation forecasting with convolutional neural network and long short-term memory network algorithms. Appl. Energy 2019, 253, 113541. [Google Scholar] [CrossRef]
- Wang, K.; Qi, X.; Liu, H.; Song, J. Deep belief network based k-means cluster approach for short-term wind power forecasting. Energy 2018, 165, 840–852. [Google Scholar] [CrossRef]
- Sun, J.; Shi, W.; Yang, Z.; Yang, J.; Gui, G. Behavioral modeling and linearization of wideband RF power amplifiers using BiLSTM networks for 5G wireless systems. IEEE Trans. Veh. Technol. 2019, 68, 10348–10356. [Google Scholar] [CrossRef]
- Zeng, Y.; Yang, H.; Feng, Y.; Wang, Z.; Zhao, D. A convolution BiLSTM neural network model for Chinese event extraction. In Natural Language Understanding and Intelligent Applications; Springer: Cham, Switzerland, 2016; pp. 275–287. [Google Scholar]
- Luo, L.; Yang, Z.; Yang, P.; Zhang, Y.; Wang, L.; Lin, H.; Wang, J. An attention-based BiLSTM-CRF approach to document-level chemical named entity recognition. Bioinformatics 2018, 34, 1381–1388. [Google Scholar] [CrossRef] [Green Version]
- Greenberg, N.; Bansal, T.; Verga, P.; McCallum, A. Marginal likelihood training of bilstm-crf for biomedical named entity recognition from disjoint label sets. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2824–2829. [Google Scholar]
- Wang, W.-C.; Chau, K.-W.; Qiu, L.; Chen, Y.-B. Improving forecasting accuracy of medium and long-term runoff using artificial neural network based on EEMD decomposition. Environ. Res. 2015, 139, 46–54. [Google Scholar] [CrossRef]
- Wang, W.-C.; Xu, D.-M.; Chau, K.-W.; Chen, S. Improved annual rainfall-runoff forecasting using PSO–SVM model based on EEMD. J. Hydroinform. 2013, 15, 1377–1390. [Google Scholar] [CrossRef]
- Zhao, H.; Sun, M.; Deng, W.; Yang, X. A new feature extraction method based on EEMD and multi-scale fuzzy entropy for motor bearing. Entropy 2017, 19, 14. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.-X.; Wu, Q.-B.; Zhu, J.-Q. Improved EEMD-based crude oil price forecasting using LSTM networks. Phys. A Stat. Mech. Appl. 2019, 516, 114–124. [Google Scholar] [CrossRef]
- Huang, Y.; Liu, S.; Yang, L. Wind speed forecasting method using EEMD and the combination forecasting method based on GPR and LSTM. Sustainability 2018, 10, 3693. [Google Scholar] [CrossRef] [Green Version]
- Javaid, N.; Naz, A.; Khalid, R.; Almogren, A.; Shafiq, M.; Khalid, A. ELS-Net: A New Approach to Forecast Decomposed Intrinsic Mode Functions of Electricity Load. IEEE Access 2020, 8, 198935–198949. [Google Scholar] [CrossRef]
- Kursa, M.B.; Rudnicki, W.R. Feature selection with the Boruta package. J. Stat. Softw. 2010, 36, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, A.M.; Deo, R.C.; Ghahramani, A.; Raj, N.; Feng, Q.; Yin, Z.; Yang, L. LSTM integrated with Boruta-random forest optimiser for soil moisture estimation under RCP4. 5 and RCP8. 5 global warming scenarios. Stoch. Environ. Res. Risk Assess. 2021, 1–31. [Google Scholar] [CrossRef]
- Prasad, R.; Deo, R.C.; Li, Y.; Maraseni, T. Weekly soil moisture forecasting with multivariate sequential, ensemble empirical mode decomposition and Boruta-random forest hybridizer algorithm approach. Catena 2019, 177, 149–166. [Google Scholar] [CrossRef]
- Qu, J.; Ren, K.; Shi, X. Binary Grey Wolf Optimization-Regularized Extreme Learning Machine Wrapper Coupled with the Boruta Algorithm for Monthly Streamflow Forecasting. Water Resour. Manag. 2021, 35, 1029–1045. [Google Scholar] [CrossRef]
- Hadi, A.S.; Imon, A.R.; Werner, M. Detection of outliers. Wiley Interdiscip. Rev. Comput. Stat. 2009, 1, 57–70. [Google Scholar] [CrossRef]
- Cook, R.D. Detection of Influential Observation in Linear Regression. Technometrics 1977, 19, 15–18. [Google Scholar]
- Jagadeeswari, T.; Harini, N.; Satya Kumar, C.; Tech, M. Identification of outliers by cook’s distance in agriculture datasets. Int. J. Eng. Comput. Sci. 2013, 2, 2319–7242. [Google Scholar]
- Metcalfe, A.V.; Cowpertwait, P.S. Introductory Time Series with R; Springer: Berlin, Germany, 2009. [Google Scholar]
- Kotsiantis, S.; Kanellopoulos, D.; Pintelas, P. Data preprocessing for supervised leaning. Int. J. Comput. Sci. 2006, 1, 111–117. [Google Scholar]
- Deo, R.C.; Ghimire, S.; Downs, N.J.; Raj, N. Optimization of windspeed prediction using an artificial neural network compared with a genetic programming model. In Handbook of Research on Predictive Modeling and Optimization Methods in Science and Engineering; IGI Global: Hershey, PA, USA, 2018; pp. 328–359. [Google Scholar]
- Ghimire, S.; Deo, R.C.; Downs, N.J.; Raj, N. Self-adaptive differential evolutionary extreme learning machines for long-term solar radiation prediction with remotely-sensed MODIS satellite and Reanalysis atmospheric products in solar-rich cities. Remote Sens. Environ. 2018, 212, 176–198. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.-C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E.; Chen, X. The multi-dimensional ensemble empirical mode decomposition method. Adv. Adapt. Data Anal. 2009, 1, 339–372. [Google Scholar] [CrossRef]
- Lei, Y.; He, Z.; Zi, Y. Application of the EEMD method to rotor fault diagnosis of rotating machinery. Mech. Syst. Signal Process. 2009, 23, 1327–1338. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. In Proceedings of the 9th International Conference on Artificial Neural Networks (ICANN ’99), Edinburgh, UK, 7–10 September 1999. [Google Scholar]
- Breuel, T.M.; Ul-Hasan, A.; Al-Azawi, M.A.; Shafait, F. High-performance OCR for printed English and Fraktur using LSTM networks. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 683–687. [Google Scholar]
- Troiano, L.; Villa, E.M.; Loia, V. Replicating a trading strategy by means of LSTM for financial industry applications. IEEE Trans. Ind. Inform. 2018, 14, 3226–3234. [Google Scholar] [CrossRef]
- Chen, Y.; Zhong, K.; Zhang, J.; Sun, Q.; Zhao, X. Lstm networks for mobile human activity recognition. In Proceedings of the 2016 International Conference on Artificial Intelligence: Technologies and Applications, Bangkok, Thailand, 24–25 January 2016. [Google Scholar]
- Mauch, L.; Yang, B. A new approach for supervised power disaggregation by using a deep recurrent LSTM network. In Proceedings of the 2015 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Orlando, FL, USA, 14–16 December 2015; pp. 63–67. [Google Scholar]
- Tsoi, A.C.; Back, A. Discrete time recurrent neural network architectures: A unifying review. Neurocomputing 1997, 15, 183–223. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory based recurrent neural network architectures for large vocabulary speech recognition. arXiv 2014, arXiv:1402.1128. [Google Scholar]
- Zhang, S.; Zheng, D.; Hu, X.; Yang, M. Bidirectional long short-term memory networks for relation classification. In Proceedings of the 29th Pacific Asia Conference on Language, Information and Computation, Shanghai, China, 30 October–1 November 2015; pp. 73–78. [Google Scholar]
- Sun, S.; Xie, Z. Bilstm-based models for metaphor detection. In Proceedings of the National CCF Conference on Natural Language Processing and Chinese Computing, Dalian, China, 8–12 November 2017; pp. 431–442. [Google Scholar]
- Basak, D.; Pal, S.; Patranabis, D.C. Support vector regression. Neural Inf. Process. Lett. Rev. 2007, 11, 203–224. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Vapnik, V.; Golowich, S.E.; Smola, A.J. Support vector method for function approximation, regression estimation and signal processing. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1997. [Google Scholar]
- Liu, Y.; Wang, R. Study on network traffic forecast model of SVR optimized by GAFSA. Chaos Solitons Fractals 2016, 89, 153–159. [Google Scholar] [CrossRef]
- Willmott, C.J. On the evaluation of model performance in physical geography. In Spatial Statistics and Models; Springer: Dordrecht, The Netherlands, 1984; pp. 443–460. [Google Scholar]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Legates, D.R.; McCabe, G.J. Evaluating the use of “goodness-of-fit” measures in hydrologic and hydroclimatic model validation. Water Resour. Res. 1999, 35, 233–241. [Google Scholar] [CrossRef]
- Willmott, C.J. On the validation of models. Phys. Geogr. 1981, 2, 184–194. [Google Scholar] [CrossRef]
- McCuen, R.H.; Knight, Z.; Cutter, A.G. Evaluation of the Nash–Sutcliffe efficiency index. J. Hydrol. Eng. 2006, 11, 597–602. [Google Scholar] [CrossRef]
- Jain, S.K.; Sudheer, K. Fitting of hydrologic models: A close look at the Nash–Sutcliffe index. J. Hydrol. Eng. 2008, 13, 981–986. [Google Scholar] [CrossRef]
- Coffey, M.E.; Workman, S.R.; Taraba, J.L.; Fogle, A.W. Statistical procedures for evaluating daily and monthly hydrologic model predictions. Trans. ASAE 2004, 47, 59. [Google Scholar] [CrossRef] [Green Version]
- Lian, Y.; Chan, I.-C.; Singh, J.; Demissie, M.; Knapp, V.; Xie, H. Coupling of hydrologic and hydraulic models for the Illinois River Basin. J. Hydrol. 2007, 344, 210–222. [Google Scholar] [CrossRef]
- Kumar, T.S.; Mahendra, R.; Nayak, S.; Radhakrishnan, K.; Sahu, K. Coastal vulnerability assessment for Orissa State, east coast of India. J. Coast. Res. 2010, 26, 523–534. [Google Scholar] [CrossRef]
- Queensland Government. Queensland Government Open Data Portal. 2019. Available online: https://www.data.qld.gov.au/dataset/coastal-data-system-historical-wave-data (accessed on 1 January 2020).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Site | Geographical Location |
|---|---|
| Gold Coast | 27°57′53.9319″ S, 153°20′58.1543″ E |
| Cairns | 16°55′34.4124″ S, 145°46′27.0667″ E |
| Partition | Training (60%) | Validation (20%) | Testing (20%) |
|---|---|---|---|
| Dataset | January 2014–July 2017 | August 2017–July 2018 | August 2018–August 2019 |
| ADF Statistic: −17.44 | KPSS Statistic: 0.29 |
|---|---|
| Critical Values: | Critical Values |
| 5%: −2.862 | 5%: 0.463 |
| 10%: −2.567 | 10%: 0.347 |
| Input Wave Features | Description |
|---|---|
| Hmax | Wave Height |
| Tz | Zero up crossing wave period |
| Tp | Peak energy wave period |
| SST | Sea surface temperature |
| Optimizer | Activation Function | Weight Regularization | Dropout | Early Stopping |
|---|---|---|---|---|
| Adam | Rectified Linear Unit | L1 = 0, L2 = 0.01 | 0.1 | Mode = Minimum, Patience = 20 |
| Epsilon (ε) | Gamma (γ) | Parameter (C) | Kernel |
|---|---|---|---|
| 0.1 | 1 × 10−7 | 1.0 | Radial Basis Function |
| Model | Cairns | Gold Coast | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R | WI | NS | RMSE | MAE | MAPE | R | WI | NS | RMSE | MAE | MAPE | |
| EEMD-BiLSTM | 0.9961 | 0.9979 | 0.9912 | 0.0214 | 0.0133 | 2.8609 | 0.9965 | 0.9983 | 0.9931 | 0.0413 | 0.0293 | 2.5258 |
| BiLSTM | 0.9911 | 0.9873 | 0.9873 | 0.0248 | 0.0187 | 3.3921 | 0.9903 | 0.9945 | 0.9772 | 0.075 | 0.0553 | 5.5633 |
| EEMD-SVR | 0.9852 | 0.9913 | 0.9647 | 0.043 | 0.0313 | 8.6412 | 0.9953 | 0.9976 | 0.9906 | 0.0481 | 0.034 | 3.0422 |
| SVR | 0.9801 | 0.9879 | 0.9508 | 0.0507 | 0.0357 | 9.8301 | 0.9935 | 0.9967 | 0.9868 | 0.057 | 0.042 | 3.9214 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raj, N.; Brown, J. An EEMD-BiLSTM Algorithm Integrated with Boruta Random Forest Optimiser for Significant Wave Height Forecasting along Coastal Areas of Queensland, Australia. Remote Sens. 2021, 13, 1456. https://doi.org/10.3390/rs13081456
Raj N, Brown J. An EEMD-BiLSTM Algorithm Integrated with Boruta Random Forest Optimiser for Significant Wave Height Forecasting along Coastal Areas of Queensland, Australia. Remote Sensing. 2021; 13(8):1456. https://doi.org/10.3390/rs13081456
Chicago/Turabian StyleRaj, Nawin, and Jason Brown. 2021. "An EEMD-BiLSTM Algorithm Integrated with Boruta Random Forest Optimiser for Significant Wave Height Forecasting along Coastal Areas of Queensland, Australia" Remote Sensing 13, no. 8: 1456. https://doi.org/10.3390/rs13081456
APA StyleRaj, N., & Brown, J. (2021). An EEMD-BiLSTM Algorithm Integrated with Boruta Random Forest Optimiser for Significant Wave Height Forecasting along Coastal Areas of Queensland, Australia. Remote Sensing, 13(8), 1456. https://doi.org/10.3390/rs13081456