1. Introduction
Underwater source localization is a relevant and challenging task in underwater acoustics. The most popular method for source localization is matched-field processing (MFP) [
1], which has inspired several works [
2,
3,
4,
5]. One of the major drawbacks of the MFP method is the need to compute many “replica” acoustic fields with different environmental parameters via numerical simulations based on the acoustic propagation model. Accuracy of the results is heavily affected by the amount of prior information about the marine environment (e.g., sound speed profile, geoacoustic parameters, etc.), which unfortunately is often hard to acquire in real scenarios.
Artificial intelligence (AI), and primarily data-driven approaches based on machine learning (ML), has become pervasive in many research fields [
6,
7]. ML-techniques are commonly divided into supervised and unsupervised learning. The former approach relies on the availability of labeled datasets, i.e., when measurements are paired with ground truth information. The latter refers to the case when unlabeled data are available [
8].
Recently, there have been several studies on underwater source localization based on ML using the supervised learning scheme [
9,
10,
11,
12,
13,
14,
15,
16,
17]. The general approach of underwater source localization by supervised learning scheme is through the use of acoustic propagation simulation models to create a huge simulation dataset for covering the real scenario. This approach has two main limitations: firstly, creating such a huge simulation dataset is time consuming and requires large computer storage resources; secondly, the set of environmental parameters to create a simulation dataset may not be able to account and adapt for environmental changes in a real-world scenario. The latter aspect requires a new simulation process, which may often be unrealistic.
Apparently, data-driven ML approaches rely on information extracted from available data, then the need of being able to exploit both labeled and unlabeled data is crucial in many applications, including underwater source localization. Semi-supervised learning has been proposed to face this issue in computer vision [
18] and room acoustics [
19,
20].
Deep learning is famous for its brilliant performance for many tasks; however, the huge computation is the price. In the study of Niu et al. [
15], the training time was six days for their ResNet50-1 model and three days for each of the ResNet50-2-x-D models. Each ResNet50-2-x-R model took 15 days to train.
In real scenarios, the speed of training is vital for real-time localization. To accelerate the training speed, some feature selection (FS) methods have been applied in underwater acoustics [
21,
22,
23,
24]. Feature selection aims to find the optimal feature subspace that can express the systematic structure of the raw dataset [
21]. Principal component analysis (PCA) is a well-known method which can maximize the variance in each principal direction and remove the correlations among the features of the raw dataset [
21,
25]. Furthermore, the latent relationship between features can be interpreted by studying the correlation loading plot of PCA [
26]. Principal component regression (PCR) is a PCA-based method, which can find out the significant variables for the target of regression by analyzing the absolute value of the regression coefficients [
27,
28].
In our study, an interpretable FS method for underwater source localization based on PCR is proposed. To make the situation closer to the real scenario, a two-step semi-supervised framework, and the data collected by a single hydrophone are used to build and train the neural network, respectively.
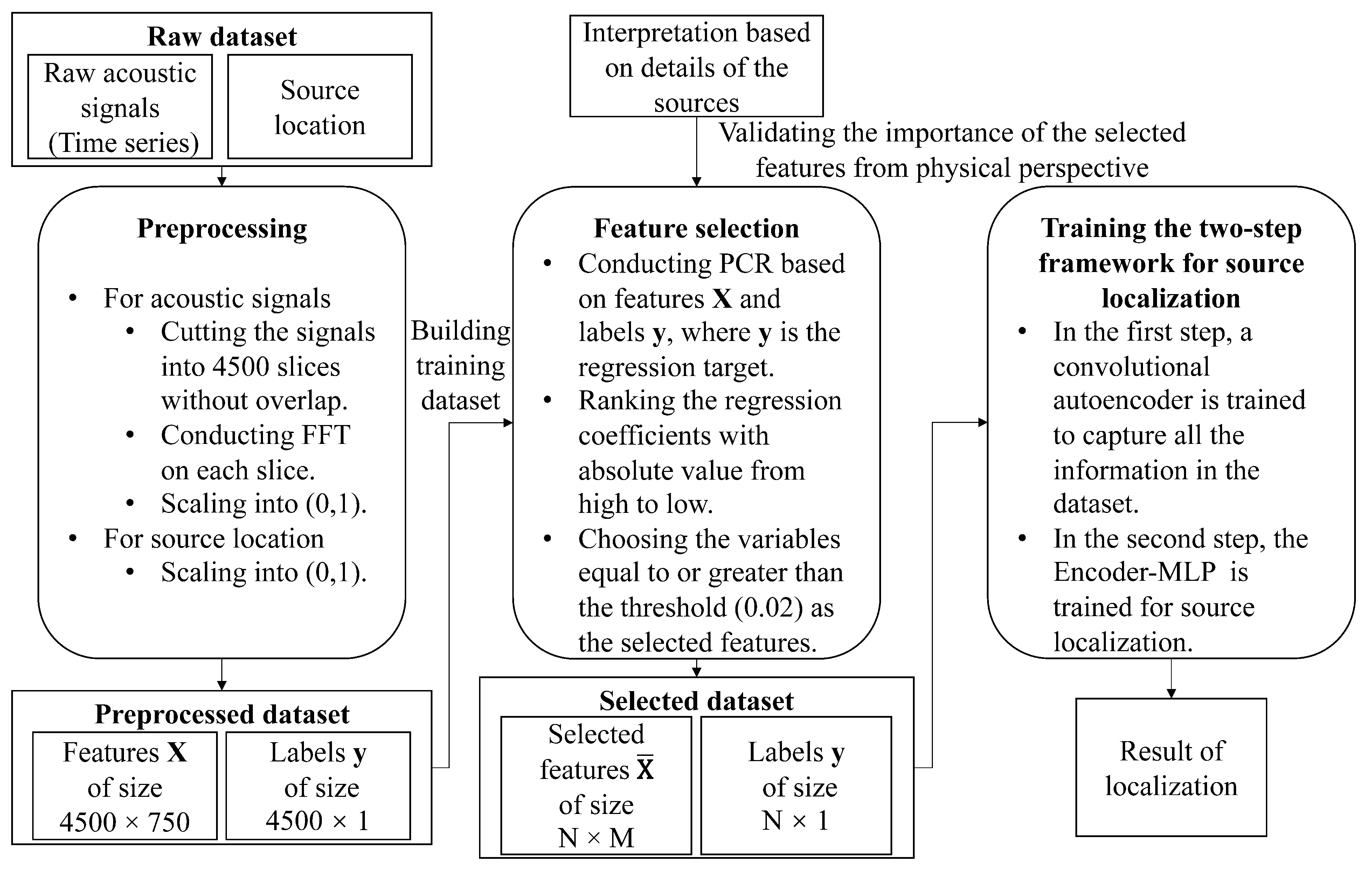
Figure 1 shows the workflow to illustrate our approach. The raw data is firstly preprocessed by discrete Fourier transform and min-max scaling. To select the important features for source localization, the PCR is conducted. Based on the absolute value of the regression coefficients of PCR, the important features are selected. Finally, the selected features are fed into the two-step semi-supervised framework for source localization. The structure of the framework is built on the encoder of a convolutional autoencoder which is trained in unsupervised-learning mode, and a 4-layer multi-layer perceptron (MLP) which is trained in supervised-learning mode.
The performance of our approach is assessed on the public dataset SWellEx-96 Event S5 [
29].
The objectives of this paper are:
Mitigating the problem related to the low number of labeled datasets in many real scenarios.
Reducing the training time of the neural network and keeping the localization performance as much as possible.
More specifically, the contributions of our work are:
An interpretable approach of FS for underwater acoustic source localization is proposed. This approach can reveal the important features related to sources by only introducing the source location without other prior information.
By using the selected features, the training time of the neural networks is significantly reduced with a slight loss of the performance of localization.
A semi-supervised two-step framework is used for underwater source localization exploiting both unlabeled and labeled data. The performance of the framework is assessed showing appealing behavior in terms of good performance combined with simple implementation and large flexibility.
The paper is organized as follows:
Section 2 describes the theories of PCA and PCR, as well as the method of FS;
Section 3 presents the two-step framework for underwater source localization; the public dataset SWellEx-96 Event S5, the data preprocessing, and the schemes of building the training and test datasets are given in
Section 4; in
Section 5, a comprehensive analysis of the localization performance between our framework based on the FS method and the control groups are described; the selected features are interpreted from both physical and data-science perspective in
Section 6; and, finally, the conclusion is given in
Section 7.
3. The Two-Step Framework for Underwater Source Localization
In many real scenarios, a whole dataset will often consist of a small portion of labeled data and a large portion of unlabeled data (purely acoustic signals). To make the experiment condition closer to real scenarios, in the following, we assume that a large-size dataset is available with most of the data being unlabeled and only a small fraction labeled.
3.1. Step-One: Training a Convolutional Autoencoder
The autoencoder is an unsupervised learning machine, which can be trained based on the unlabeled dataset [
31]. The first step of the framework is to train a convolutional autoencoder (CAE) [
32]. The role of the CAE is to conduct unsupervised learning since training the CAE does not need labels, which means that the whole dataset can be covered.
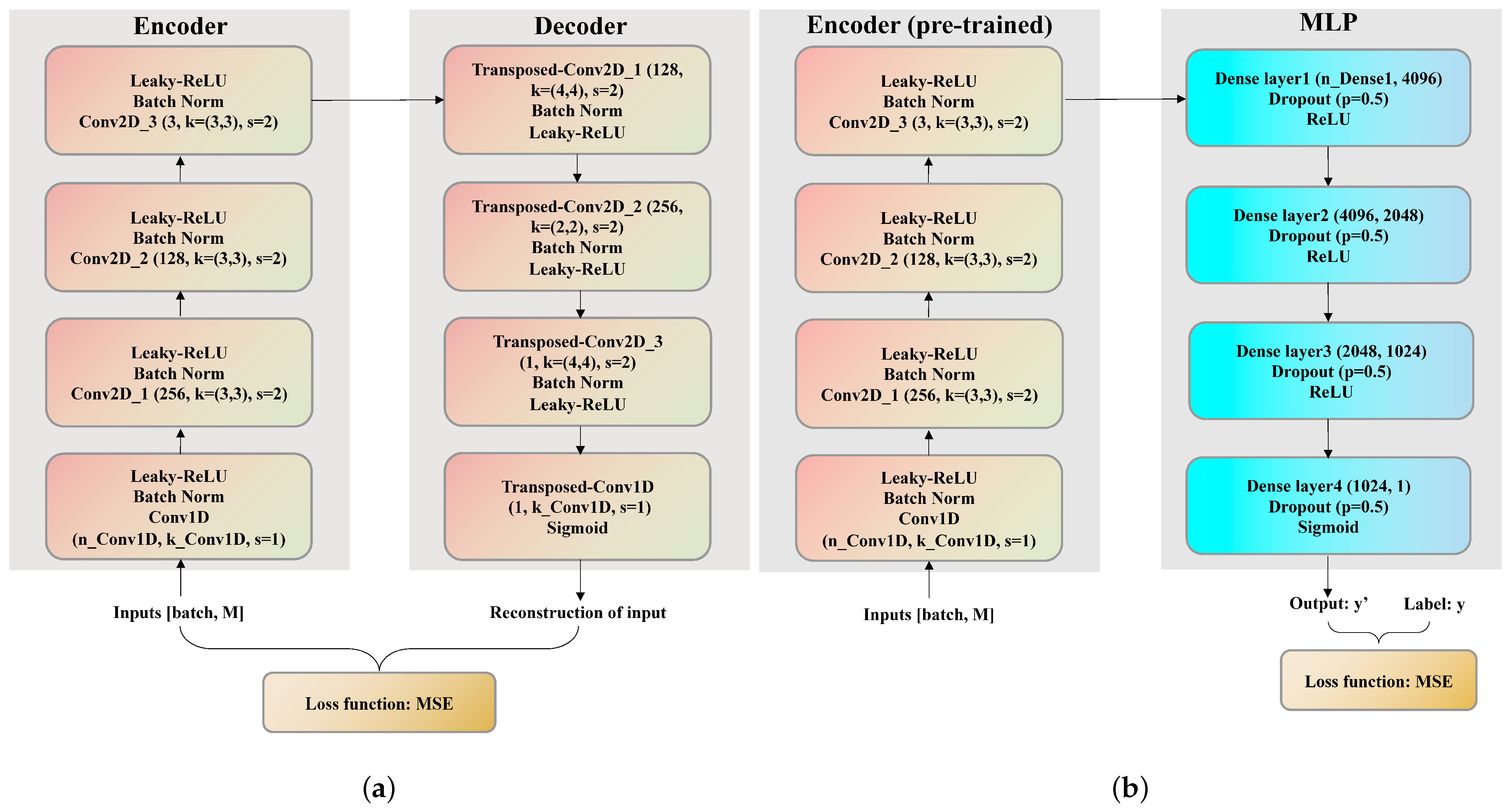
The structure of CAE is shown in
Figure 2a, where the network consists of an encoder and a decoder. The arrows indicate the direction of the data stream.
The encoder, made of 4 blocks, is used to extract the compressed features from the input data. Each block contains a convolution layer (for extracting features), a batch norm layer (for speeding up training), and a leaky-ReLU layer (for operating a non-linear transform on the data stream). Additionally, the decoder has a dual-symmetric structure as the encoder and is used to create the reconstruction of the input data from the compressed features. After creating the reconstructed input, the mean squared error (MSE) is the selected loss function to measure the difference between the input and the reconstruction.
It is worth noticing that, in this step, the whole dataset (both the labeled and unlabeled portions) is used to train the network, but only the purely acoustic signals are involved as described later in the paper.
3.2. Step-Two: Training the Encoder-MLP Localizer Based on the Semi-Supervised Learning Scheme
After training the CAE, the second step requires training the Encoder-MLP for localization based on the semi-supervised learning scheme. The structure of this model is shown in
Figure 2b, which consists of a pre-trained encoder extracting the compressed features from input data and a 4-layer-MLP estimating the location of the acoustic source based on the compressed features. The MLP consists of four blocks, with each block containing a dense layer followed by a dropout layer (for regularization) and a non-linear transform function. The sigmoid function is an appropriate choice for the non-linear transform since, during the data preprocessing stage, the regression target, i.e., the horizontal distance between source and receiver, is scaled into the interval
.
Similarly, the arrows in
Figure 2b indicate the direction of the data stream. Since the encoder has been trained, its parameters will be frozen during the training stage of the second step. After the encoder, the compressed features are fed in the MLP, which will provide the estimated source location as output. Finally, the same loss function, i.e., MSE, is used since the localization task is a regression problem.
4. Dataset and Preprocessing
In this section, SWellEx-96 Event S5 is introduced. The preprocessing method and the schemes for building the training and test datasets are used. Finally, to illustrate the performance of our framework and the proposed FS method, the control groups are created.
4.1. SWellEx-96 Event S5
Vertical linear array (VLA) data from SWellEx-96 Event S5 are used to illustrate the localization performance of our framework. The event was conducted near San Diego, CA, where the acoustic source started its track of all arrays and proceeded northward at a speed of 5 knots (2.5 m/s). The source had two sub-sources, a shallow one was at a depth of 9 m and a deep one at 54 m. The sampling rate of the data was 1500 Hz and the recording time of the data was 75 min. The VLA contained 21 receivers equally spaced between 94.125 m and 212.25 m. The water depth was 216.5 m. Additionally, the horizontal distance between the source and the VLA is also provided in the dataset. More detailed information of this event can be found in Reference [
29].
4.2. Preprocessing and FS
In this paper, the underwater acoustic signals collected by a single receiver are transformed into the frequency domain. We calculate the spectrum without overlap for each 1 s slice of the signal and arrange it in a matrix (namely, features) format with the shape of , where each row is related to one slice. More specifically, 4500 is the total number of time-steps (75 min = 4500 s) and 750 is the number of frequencies. In the matrix, each row corresponds to one single time-step, and each column corresponds to one single frequency.
Besides the acoustic signals, the horizontal distance between the source and the VLA was provided in the original dataset, which can be expressed as a vector (namely, labels) with the shape of , where 4500 indicates the total number of time-steps, and 1 indicates the distance at each time-step.
For the training stability of our framework, the features
and labels
are scaled into interval
by the min-max scaling method:
After preprocessing, the FS is conducted following the steps in
Section 2 based on
and
. Note that the systems with/without min-max scaling before FS have been compared showing that pre-scaling improves the performance.
4.3. Schemes for Building the Dataset
For step-one, the dataset for CAE is expressed as:
where
is the features in matrix form,
is a row-vector with the length of M (the number of selected features), corresponding to the
ith row of the features matrix
, and
N is the number of time-steps.
For step-two, the dataset for Encoder-MLP localizer is expressed as:
where
and
are the features and labels in matrix form. And
is the
ith element in labels vector
.
4.4. Schemes of Separating Training and Test Datasets
To illustrate the performance of the semi-supervised framework as the number of labeled datasets decreases, 50%, 25%, and 12.5% of the whole labeled dataset are chosen, respectively, as the training dataset of step-two.
Since source localization is a regression task, the labels in the training dataset of step-two should cover the whole interval of the horizontal distance between the source and receiver. As described above, the total number of time-steps is 4500, which can be expressed by the index . The schemes of separating training and test datasets for step-two are:
4.4.1. Using 50% Data to Build Training Dataset
4.4.2. Using 25% Data to Build Training Dataset
4.4.3. Using 12.5% Data to Build Training Dataset
To show the influence of different depths, receivers no. 1 (top), no. 10 (middle), and no. 21 (bottom) are chosen to build the dataset, respectively. For each receiver, there are 3 choices of the percentage to build the training dataset. Totally, there are training datasets are built.
4.5. Control Group
4.5.1. Control Group for the Semi-Supervised Framework
To make a fair comparison, we trained a neural network with the same structure as the framework by the purely supervised learning scheme.
4.5.2. Control Group for the FS Method
To show the performance of our FS method, a framework without FS is trained in the same way. The matrix containing the whole features
of size
is calculated from Equation (
7) and used to build the dataset following the schemes described in
Section 4.3 and
Section 4.4.
5. Performance of Source Localization
In this section, the hyperparameters of the two-step framework are introduced. After that, several experiments are conducted to exam the performance of source localization. Finally, a comprehensive comparison of the localization performance is shown, which demonstrates the benefit of our approach.
5.1. Hyperparameters of the Framework
In
Figure 2, the output channel (n_Conv1D) and the kernel size (k_Conv1D) of the 1D-convolutional layer, as well as the input channel (n_Dense1) of the first dense layer, are not fixed. This is because the size of input features varies between datasets collected by different receivers.
For the training dataset without FS,
n_Conv1D = 738;
k_Conv1D = 13;
n_Dense1 = 24,843.
For the training dataset with FS,
n_Conv1D = 114;
k_Conv1D = ;
n_Dense1 = 507.
After FS, the number of selected features
M is shown in
Table 1.
To train the framework, the learning rates for step-one and step-two are 1 × 10 and 5 × 10, respectively. The optimization scheme is Adam. The epoch and the batch-size are 100 and 5 for each step, respectively.
All the networks mentioned in this paper are trained using one NVIDIA RTX 2080Ti GPU card.
5.2. Examining the Performance When Removing Some 2D-Convolutional Layers of the Framework after FS
The function of the encoder is to compress the original dataset and create its compressed expression, which is similar to our manual FS method. To find the best structure for the framework using FS, the number of 2D-convolutional layers of the encoder, and the corresponding number of transposed 2D-convolutional layers of the decoder are gradually decreased. After re-training the modified CAE, step-two is conducted as before. The structures of CAE after removing one and two 2D-convolutional layers are shown in
Table 2 and
Table 3, respectively. The performance will be discussed in
Section 5.3.
5.3. Overall Analysis of the Localization Performance
To make a comprehensive comparison, 4 pairs of networks are tested on the data collected by all receivers and trained separately based on the data collected by receivers no. 1, no. 10, and no. 21. One pair is trained without FS, the rest are all trained with the FS method proposed by this paper. For the rest 3 pairs of networks, one has the same number of layers as the networks trained without FS; others have the structures shown in
Table 2 and
Table 3, respectively. Additionally, each pair of networks consists of the framework trained by the semi-supervised learning scheme and the same network of step-two trained by the purely supervised learning scheme.
5.3.1. Comparison between the Framework and the Purely Supervised Learning Scheme after FS
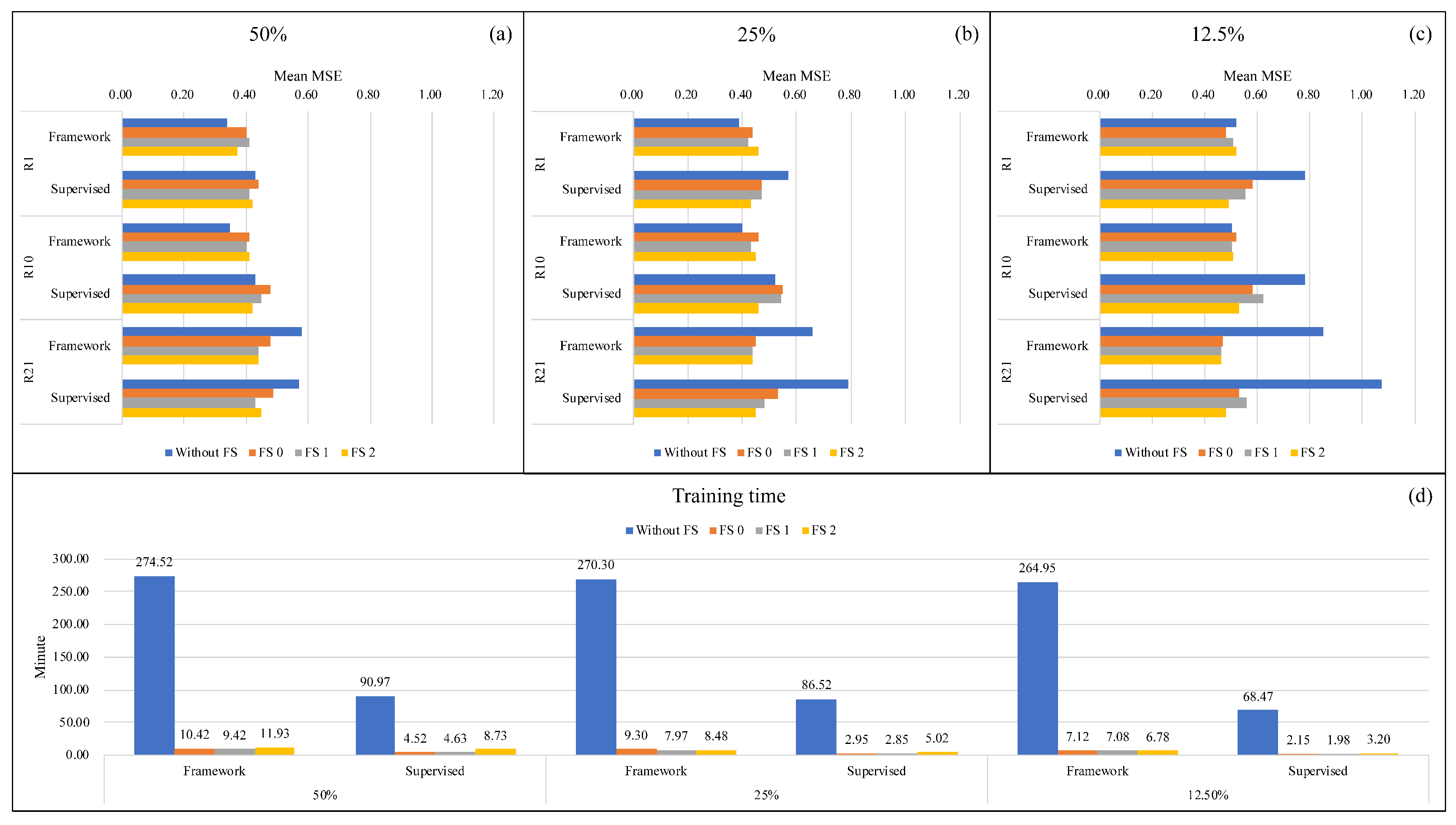
After FS and tested on all receivers, the performance of our framework and the purely supervised learning scheme is shown in
Table 4. In the Table, the first row indicates the percentage of the data used to build the training dataset. In the first column, R1 to R21 indicate receivers no. 1 to no. 21, respectively. Additionally, the mean indicates the average of MSE on all receivers. The bold numbers indicate the lower values of MSE in every pair of our framework and the purely supervised learning scheme, which means the model has a better performance on source localization.
Observing
Table 4, interesting phenomena can be found:
Performance of the purely supervised learning scheme:
The network trained by the supervised learning scheme can attain the lower MSE only when the test dataset is chosen near the receiver used to build the training dataset. When the test dataset is far from the receiver used to train, its performance is getting worse dramatically. This trend is more obvious when the percentage of data used to train decreases. This shows the limitation of the purely supervised learning scheme: when the labeled training dataset is limited, the generalization ability of the model is poor.
Performance of our framework:
Compared to the purely supervised learning scheme, our framework is more robust and has much lower MSE on the data collected by those receivers which are far from the receiver used to build the training dataset, even though its performance on the data collected by the receivers near the receiver used to train is a bit poorer. This trend is more obvious when the percentage of data used to train decreases.
Comparison of the different percentages used to train:
When the percentage of the data used to build the training dataset decreases, the performance of both schemes becomes worse. However, the degree of performance degradation of our framework is smaller than that of the purely supervised learning scheme.
5.3.2. Comparison of the Mean MSE and the Training Time between the Networks with and without FS
The performance between the networks with and without FS is shown in
Table 5. In the table, the residual illustrates the difference of the mean MSE between networks, and the percentage of the residual illustrates the performance improvement (positive value) and degradation (negative value) by FS. They are calculated by
Observing
Table 5, phenomena can be found:
When the percentage of data used to train is 50% and 25%, respectively, the performance of the framework trained on R1 and R10 has some degradation (12.82% to 17.65%). However, when the percentage of data used to train is 12.5%, the performance of the framework trained on R1 and R10 has a slight improvement (7.69%) and degradation (4%), respectively.
Trained on R21, the framework’s performance has significant improvements, which are 17.24%, 31.82%, and 44.71% when the percentage of data used to train is 50%, 25%, and 12.5%, respectively.
Compared to the framework, the performance of the purely supervised learning scheme gains more improvement (14.04% to 50.47%) after FS. The performance degradation only happens when it is trained on 50% R1, 50% R10, and 25% R10.
The training time of the networks is shown in
Table 6. This table illustrates that the training time is reduced significantly after FS for both framework and the purely supervised learning scheme.
5.3.3. The Best Structure for the Framework after the FS
As mentioned in
Section 5.2, the comparison of the mean MSE and the training time between different structures of networks is shown in
Table 7 and
Table 8, respectively.
According to the Tables, interesting phenomena can be found:
For the framework, Structure 1 attains the lowest MSE except for trained on 50% R1 and 12.5% R1.
For the purely supervised learning scheme, Structure 2 attains the lowest MSE with a slight improvement compared to Structure 1 when the percentages of data used to train are 25% and 12.5%.
Structure 1 shows the best performance for training time reduction. Considering both MSE and training time, the best structure after the FS is Structure 1.
5.3.4. Conclusions of the Performance Analysis
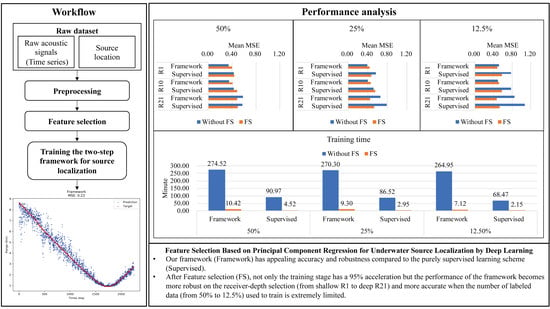
In
Figure 3, the conclusion of the performance analysis is illustrated. The legend used in all the sub-figures is the same. The blue bar is related to the network without FS. The orange, yellow, and gray bars are related to the ’Original structure’, ’Structure 1’, and ’Structure 2’ in
Table 7 and
Table 8, respectively.
From
Figure 3, interesting phenomena can be found:
When the number of labeled data is gradually decreasing, the power of the framework with the semi-supervised learning scheme is revealed.
The FS method is beneficial for both the framework and the purely supervised learning scheme, which can significantly decrease the training time with a slight loss of the performance of localization.
After FS, the difference in performance between different receiver-depth is not significant, which means it can increase the robustness of the receiver-depth selection.
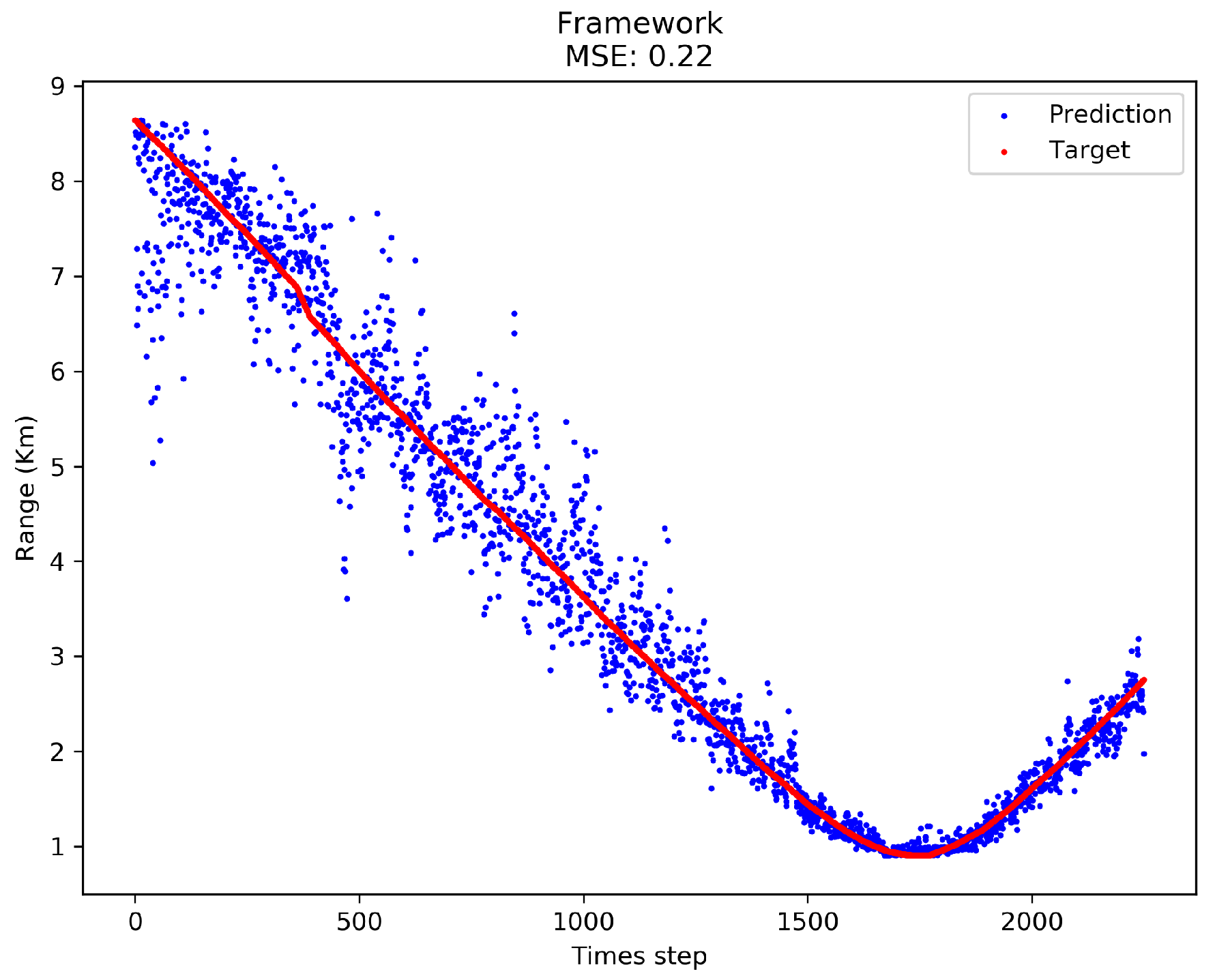
To have an intuitive view of the performance,
Figure 4 shows the localization result of our framework trained on 50% R1 after FS.
6. Discussion of FS
In this section, the discussion of the selected features is given, which demonstrates that the most significant portion of the original features for source localization has been selected by performing the FS. The training dataset using 50% data collected by receiver no. 21 is used in this section for illustration.
6.1. Details of the Sources in SWellEx-96 Event S5
According to the details on the website of SWellEx-96 Event S5 [
29], the deep source (J-15) transmitted 5 sets of 13 tones between 49 Hz and 400 Hz. The first set of tones was projected at maximum transmitted levels of 158 dB. The second set of tones was projected with levels of 132 dB. The subsequent sets (3rd, 4th, and 5th) were each projected 4 dB down from the previous set. The shallow source transmitted only one set containing 9 tones between 109 Hz and 385 Hz. According to Du et al. [
33], 500–700 Hz is related to the noise radiated by the ship towing the sources in the experiment, which is also an important contribution for source localization.
6.2. Interpretation of the Selected Features
After the FS described in
Section 2.3, the matrix
of size
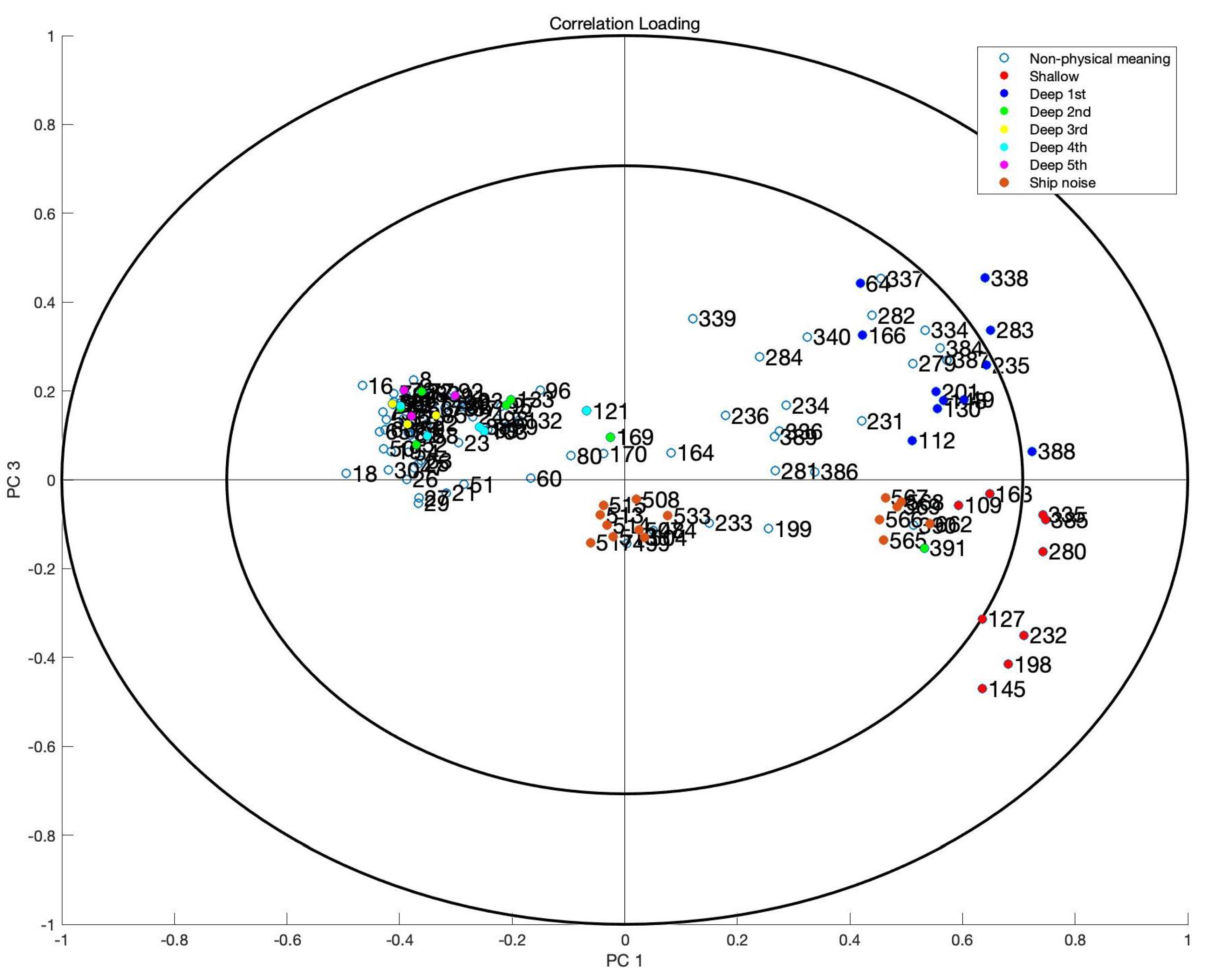
containing selected features is created. To interpret the selected features, another PCA is conducted on this matrix. To investigate the correlation structure between the features and the PCs, correlation loading is calculated based on the method proposed by Frank Westad et al. [
26].
As shown in
Figure 5, the abscissa is PC 1 and the ordinate is PC 3. There are 2 circles in the plot, in which the inner and outer ones indicate 50% and 100% explained variance, respectively. The points between the two circles are the significant features that can explain at least a 50% variance of the data. And the legend with different colors illustrates different sets of tones and the ship noise.
From the correlation loading plot in
Figure 5, phenomena with physical meanings can be found:
1. Along PC 1, the frequencies related to the high transmitted signal level are in the positive half-axis. The frequencies related to lower energy levels are in the negative half-axis. For more details:
7 frequencies (127, 145, 198, 232, 280, 335, 385 Hz) of the shallow source and 3 frequencies (238, 338, 388 Hz) of the deep source are in the area between two circles, which means that they are significant features.
The rest frequencies of the shallow source and the highest transmitted level (and also the tone with 391 Hz related to the second transmitted level) of the deep source are also close to the boundary of the inner circle, which means that they still have some importance for the data.
Expect for frequencies of the highest transmitted level and 391 Hz of the second transmitted level, the rest frequencies are closer to the origin, which means that they are less significant from the statistical perspective.
2. Along PC 3, the frequencies related to the shallow source are in the negative half-axis (except for the tone with 391 Hz). Furthermore, the frequencies related to the ship noise are also in the negative half-axis, since the ship can be treated as a shallow noise source. The frequencies related to the deep source are in the positive half-axis.
More specifically, the numbers of selected features among the different subsets of tones and ship noise are:
Deep 1st: 11 (13 in total);
Deep 2nd: 7 (13 in total);
Deep 3rd: 3 (13 in total);
Deep 4st: 5 (13 in total);
Deep 5st: 3 (13 in total);
Shallow: 9 (9 in total);
Ship noise (500–700 Hz): 15.
According to the discussion above, the frequencies related to the shallow source, deep source, and the ship noise are selected by applying the FS, which are the most important features for source localization. The FS process does not need any prior information.
6.3. Different Roles of the FS and the Autoencoder
Autoencoders are often used as feature extractors; thus, the considered feature-selection stage might seem redundant. However, the PCR adapted for FS is a linear method that can select the most important subset of variables for the regression target (i.e., source localization in this paper). The effect is that the non-linear processing of the autoencoder becomes easier to train (i.e., significantly reduced training time) while keeping approximately the same performance.
After the FS stage, the most important subset of the original features is gained.
More specifically, the roles of the FS and the autoencoder in our framework are:
The FS: Selecting the most important subset of the original features for reducing the training time of our framework and providing a nice starting point for the framework.
The autoencoder: Conducting the unsupervised learning to cover all the information in the dataset.
7. Conclusions
In this paper, we utilize a two-step semi-supervised framework for source localization to deal with the condition of the limited amount of labeled data in many real scenarios. To accelerate the training stage of the framework for the real-time operation, a FS method based on PCR is proposed.
Based on a public dataset, SWellEx-96 Event S5, the performances of our FS method and the two-step framework have been demonstrated. The results show that the framework is more robust on the unseen data, especially when the number of labeled data used to train gradually decreases. After FS, the training time is significantly reduced (by an average of 95%). The localization performance has a slight degradation when 50% and 25% of data are used to train. However, when the percentage of data used to train is 12.5%, this condition is closer to the real scenario, the FS method can improve the performance of both semi-supervised learning and purely supervised learning.
It needs to be mentioned that the structure of the network used in this paper is just a demo for showing the performance of our framework. More complex and powerful networks can be applied in this framework, and, based on our anticipation, the performance of source localization will be better as long as the network has been trained appropriately and well.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}