
Improving Land Cover Classification Using Genetic Programming for Feature Construction

 , , ,
, , ,  and
and
Abstract
:
1. Introduction
2. Related Work
2.1. Feature Construction with Genetic Programming
2.2. Feature Construction and Genetic Programming in Remote Sensing
3. Materials and Methods
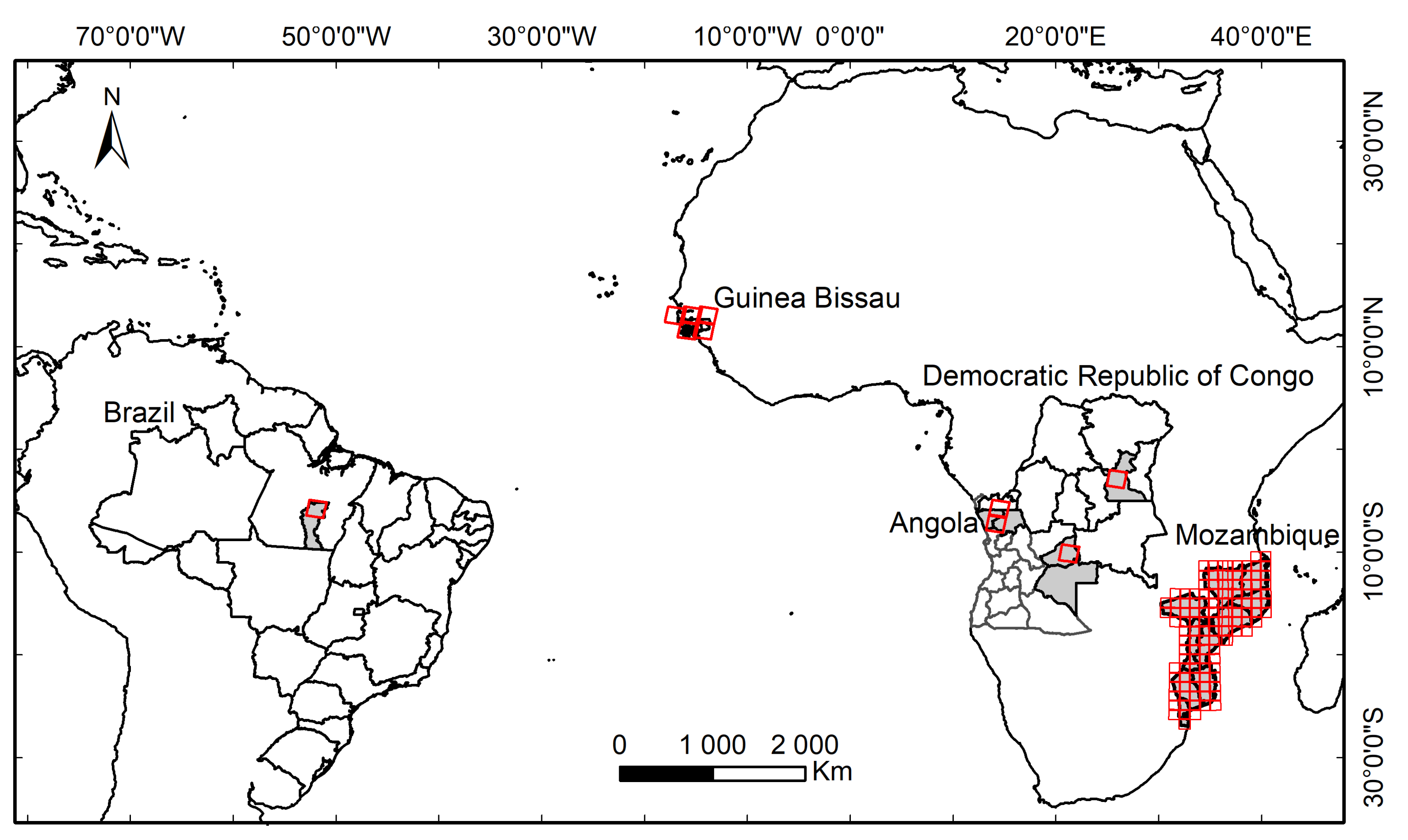
3.1. Datasets and Study Areas
3.1.1. Datasets
3.1.2. Study Areas
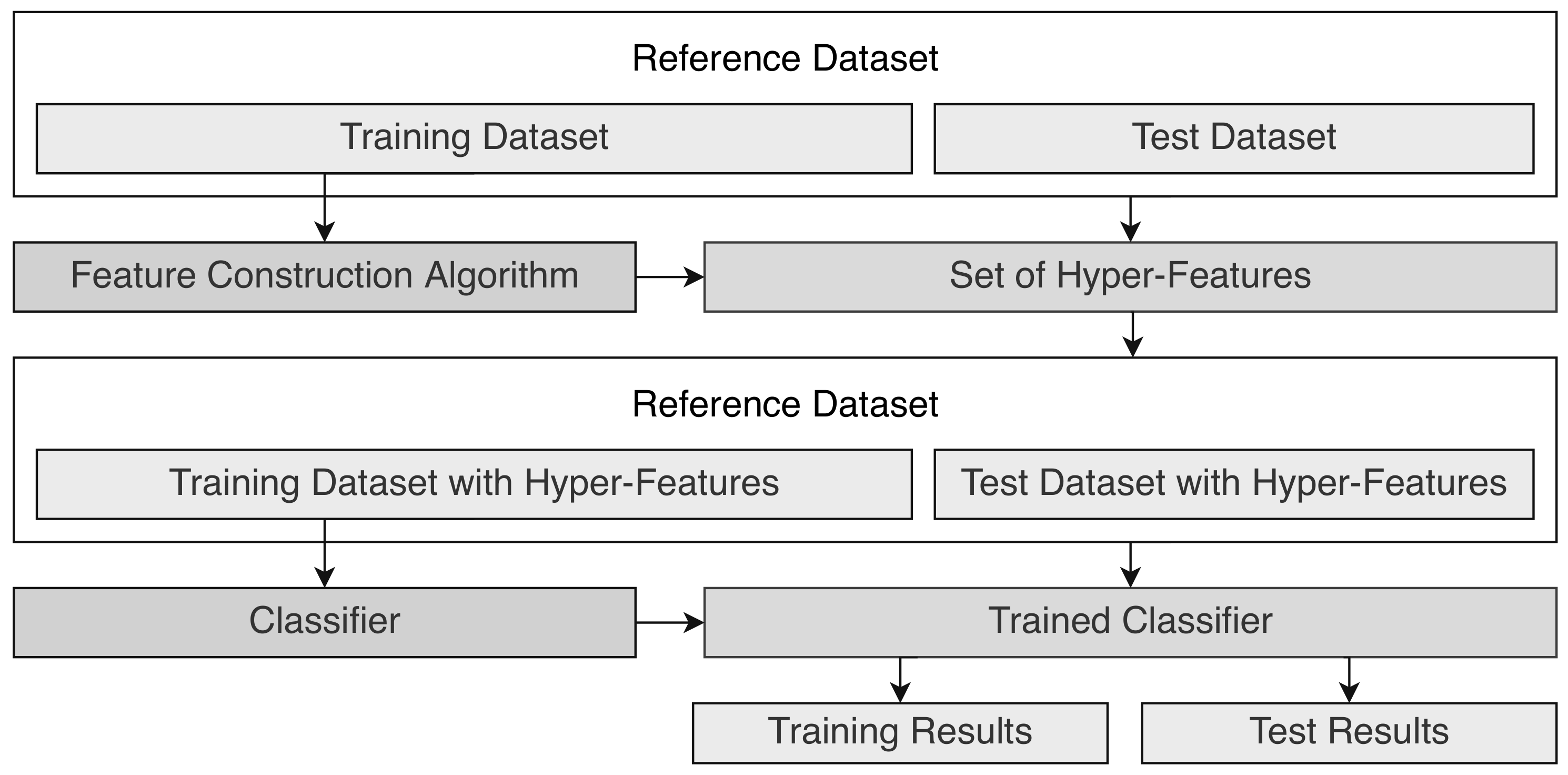
3.2. Methodology
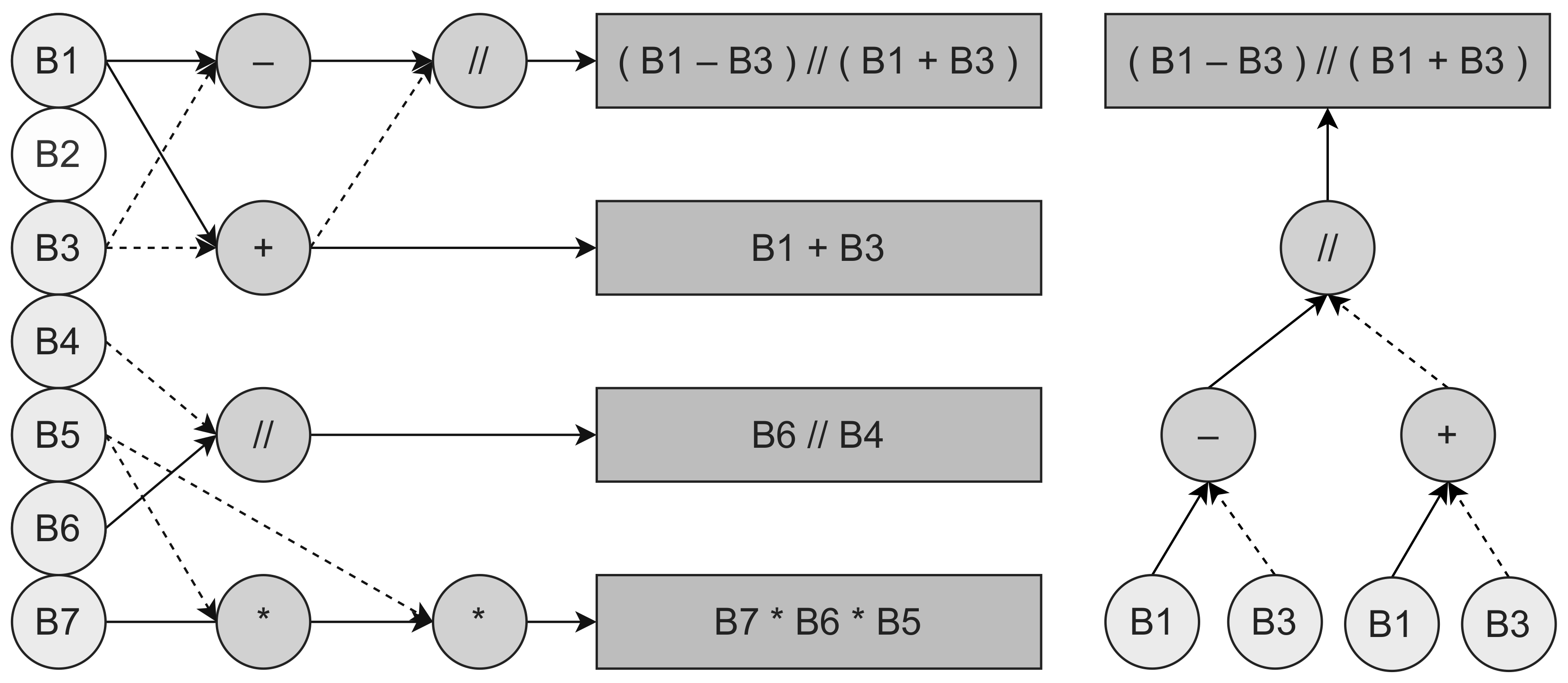
3.3. Feature Construction Algorithms
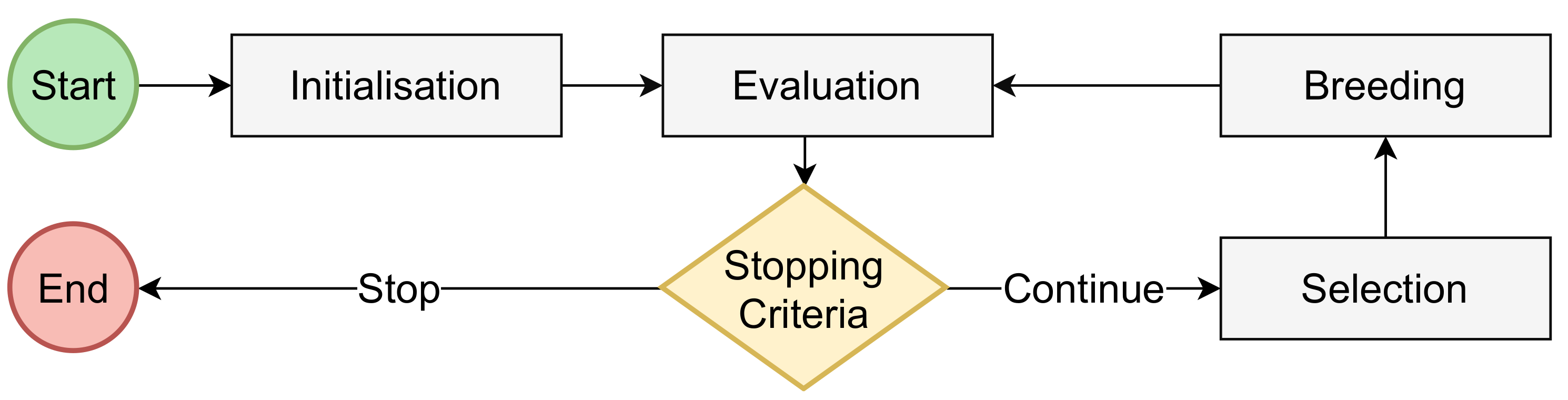
3.3.1. The M3GP Algorithm
3.4. Classification Algorithms
3.5. Tools and Parameters
4. Results and Discussion
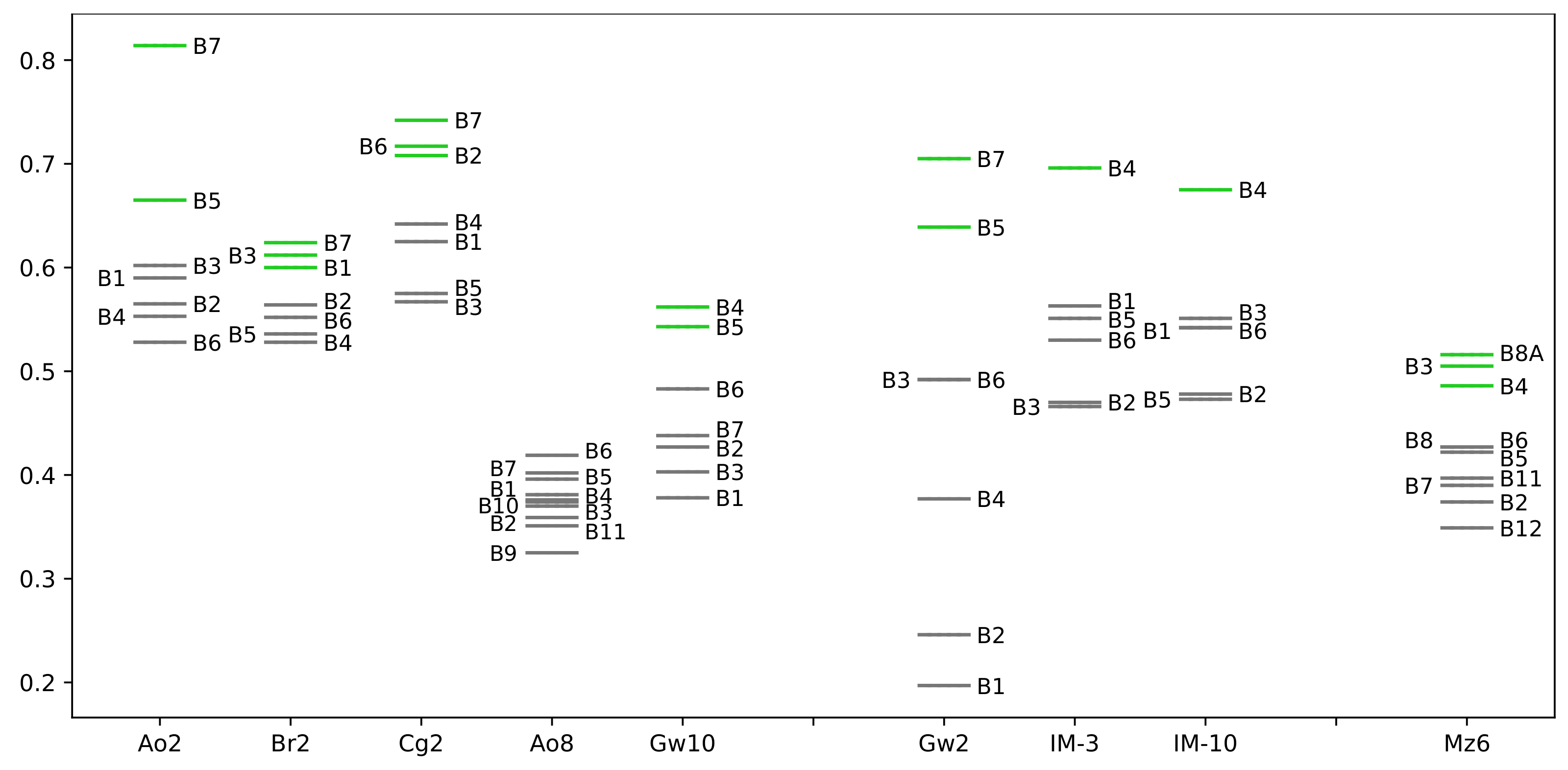
4.1. M3GP Performance and Hyperfeature Analysis
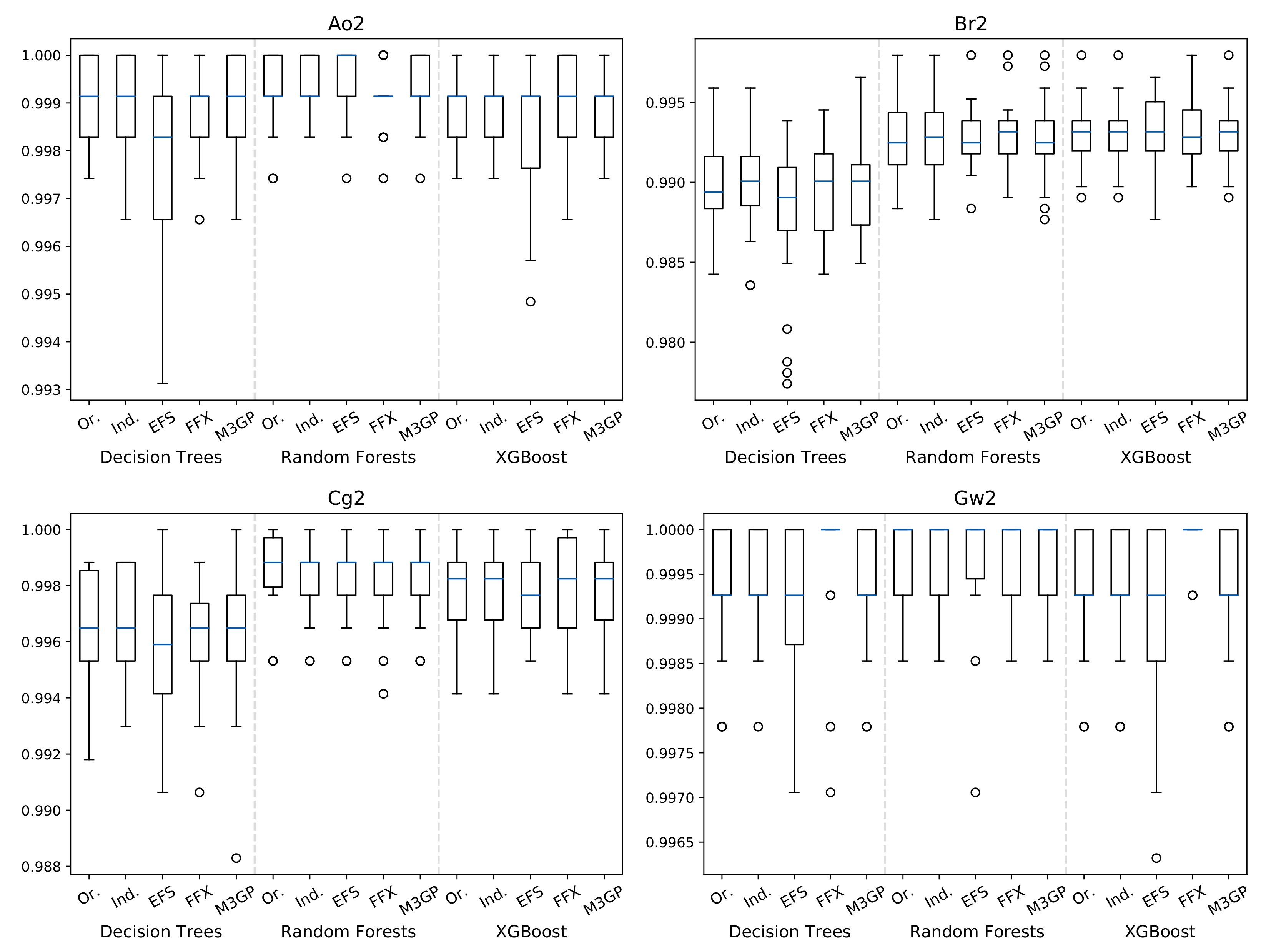
4.2. Hyperfeatures in Binary Classification Datasets
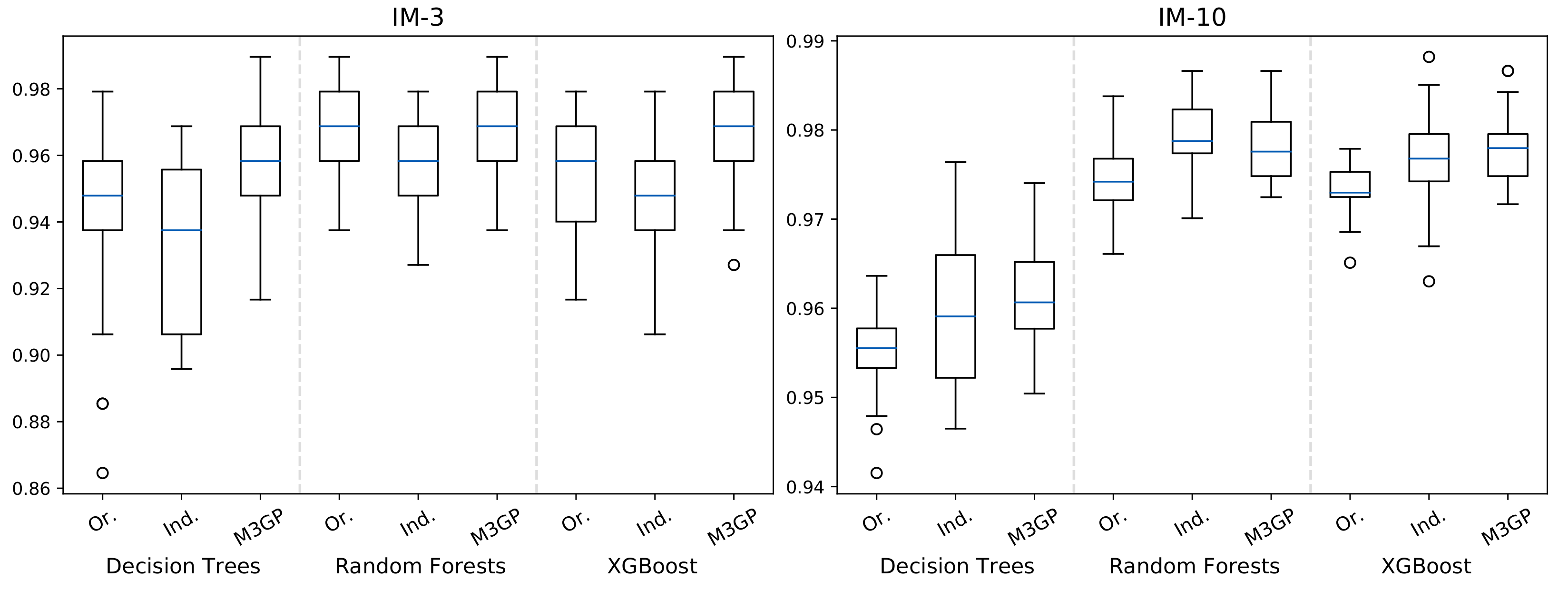
4.3. Hyperfeatures to Discriminate Similar Classes in a Multiclass Classification Dataset
4.4. Hyperfeatures to Discriminate All Classes in Multiclass Classification Datasets
4.5. Impact on the MRV Performance
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Af | Equatorial rainforest, fully humid |
| Am | Equatorial monsoon |
| Ao | Angola |
| Aw | Equatorial savanna with dry winter |
| Bx | Band x |
| Br | Brazil |
| BSh | Hot semiarid |
| Bwh | Hot desert |
| CCDC | Continuous change detection and classification |
| Cd | Democratic Republic of the Congo |
| Cwa | Warm temperate climate with dry winter and hot summer |
| Cwb | Warm temperate climate with dry winter and warm summer |
| DT | Decision tree |
| EC | Evolutionary computation |
| EFS | Evolutionary feature synthesis (algorithm) |
| FFX | Fast function extraction (algorithm) |
| GLCM | Gray level co-occurrence matrix |
| Gw | Guinea-Bissau |
| GP | Genetic programming |
| KGCS | Köpper–Geiger classification system |
| LS-7 | Landsat 7 |
| LS-8 | Landsat 8 |
| M3GP | Multidimensional multiclass GP with multidimensional populations |
| (algorithm or classifier) | |
| MD | Mahalanobis distance (classifier) |
| ML | Machine learning |
| MRV | Measure, report, and verify |
| Mz | Mozambique |
| NBR | Normalized burn ratio |
| NDVI | Normalized difference vegetation index |
| NDWI | Normalized difference water index |
| PCA | Principal component analysis |
| REDD+ | Reducing emissions from deforestation and forest degradation |
| RF | Random forest |
| RS | Remote sensing |
| S-2A | Sentinel-2A |
| UNFCCC | United Nations Framework Convention on Climate Change |
| XGB | XGBoost |
| WAF | Weighted average of F-measures |
References
- Weier, J.; Herring, D. Measuring Vegetation (NDVI & EVI): Feature Articles; NASA Earth Observatory: Washington, DC, USA, 2020; Volume 20. [Google Scholar]
- Mcfeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Key, C.; Benson, N. Landscape Assessment: Ground Measure of Severity, the Composite Burn Index; Remote sensing of severity; The Normalized Burn Ratio. In FIREMON: Fire Effects Monitoring and Inventory System; US Department of Agriculture: Fort Collins, CO, USA, 2006; pp. 1–51. [Google Scholar]
- Jinru, X.; Su, B. Significant Remote Sensing Vegetation Indices: A Review of Developments and Applications. J. Sens. 2017, 2017, 1–17. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2016, 55. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, F.; Roberts, D.; Hess, L.; Davis, F.; Caylor, K.; Daldegan, G. Geographic Object-Based Image Analysis Framework for Mapping Vegetation Physiognomic Types at Fine Scales in Neotropical Savannas. Remote Sens. 2020, 12, 1721. [Google Scholar] [CrossRef]
- Dragozi, E.; Gitas, I.; Stavrakoudis, D.; Theocharis, J. Burned area mapping using support vector machines and the FuzCoC feature selection method on VHR IKONOS imagery. Remote Sens. 2014, 6, 12005–12036. [Google Scholar] [CrossRef] [Green Version]
- Solano Correa, Y.; Bovolo, F.; Bruzzone, L. A Semi-Supervised Crop-Type Classification Based on Sentinel-2 NDVI Satellite Image Time Series And Phenological Parameters. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019. [Google Scholar] [CrossRef]
- Orynbaikyzy, A.; Gessner, U.; Mack, B.; Conrad, C. Crop Type Classification Using Fusion of Sentinel-1 and Sentinel-2 Data: Assessing the Impact of Feature Selection, Optical Data Availability, and Parcel Sizes on the Accuracies. Remote Sens. 2020, 12, 2779. [Google Scholar] [CrossRef]
- Carrao, H.; Gonçalves, P.; Caetano, M. Contribution of multispectral and multitemporal information from MODIS images to land cover classification. Remote Sens. Environ. 2008, 112, 986–997. [Google Scholar] [CrossRef]
- Batista, J.E.; Silva, S. Improving the Detection of Burnt Areas in Remote Sensing using Hyper-features Evolved by M3GP. In Proceedings of the 2020 IEEE Congress on Evolutionary Computation (CEC), Glasgow, UK, 19–24 July 2020. [Google Scholar] [CrossRef]
- Poli, R.; Langdon, W.B.; Mcphee, N. A Field Guide to Genetic Programming; Lulu Enterprises: London, UK, 2008. [Google Scholar]
- Muñoz, L.; Silva, S.; Trujillo, L. M3GP—Multiclass Classification with GP. In European Conference on Genetic Programming; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9025, pp. 78–91. [Google Scholar]
- Muñoz, L.; Trujillo, L.; Silva, S.; Castelli, M.; Vanneschi, L. Evolving multidimensional transformations for symbolic regression with M3GP. Memetic Comput. 2019, 11, 111–126. [Google Scholar] [CrossRef]
- Muñoz, L.; Trujillo, L.; Silva, S. Transfer learning in constructive induction with Genetic Programming. Genet. Program. Evol. Mach. 2019, 21, 529–569. [Google Scholar] [CrossRef]
- Bastarrika, A.; Chuvieco, E.; Martín, M.P. Mapping burned areas from Landsat TM/ETM+ data with a two-phase algorithm: Balancing omission and commission errors. Remote Sens. Environ. 2011, 115, 1003–1012. [Google Scholar] [CrossRef]
- Chen, W.; Moriya, K.; Sakai, T.; Koyama, L.; Cao, C. Mapping a burned forest area from Landsat TM data by multiple methods. Geomat. Nat. Hazards Risk 2016, 7, 384–402. [Google Scholar] [CrossRef] [Green Version]
- Daldegan, G.; de Carvalho, O.; Guimarães, R.; Gomes, R.; Ribeiro, F.; McManus, C. Spatial Patterns of Fire Recurrence Using Remote Sensing and GIS in the Brazilian Savanna: Serra do Tombador Nature Reserve, Brazil. Remote Sens. 2014, 6, 9873–9894. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Heiskanen, J.; Maeda, E.E.; Pellikka, P.K. Burned area detection based on Landsat time series in savannas of southern Burkina Faso. Int. J. Appl. Earth Obs. Geoinf. 2018, 64, 210–220. [Google Scholar] [CrossRef] [Green Version]
- Silva, J.M.N.; Pereira, J.M.C.; Cabral, A.I.; Sá, A.C.L.; Vasconcelos, M.J.P.; Mota, B.; Grégoire, J.M. An estimate of the area burned in southern Africa during the 2000 dry season using SPOT-VEGETATION satellite data. J. Geophys. Res. Atmos. 2003, 108. [Google Scholar] [CrossRef] [Green Version]
- Stroppiana, D.; Bordogna, G.; Carrara, P.; Boschetti, M.; Boschetti, L.; Brivio, P. A method for extracting burned areas from Landsat TM/ETM images by soft aggregation of multiple Spectral Indices and a region growing algorithm. ISPRS J. Photogramm. Remote Sens. 2012, 69, 88–102. [Google Scholar] [CrossRef]
- Trisakti, B.; Nugroho, U.C.; Zubaidah, A. Technique for identifying burned vegetation area using Landsat 8 data. Int. J. Remote Sens. Earth Sci. 2017, 13, 121. [Google Scholar] [CrossRef] [Green Version]
- Cabral, A.I.R.; vasconcelos, M.J.P.; Pereira, J.M.C.; Martins, E.; Bartholomé, É. A land cover map of southern hemisphere Africa based on SPOT-4 Vegetation data. Int. J. Remote Sens. 2006, 27, 1053–1074. [Google Scholar] [CrossRef]
- Cabral, A.; Vasconcelos, M.; Oom, D.; Sardinha, R. Spatial dynamics and quantification of deforestation in the central-plateau woodlands of Angola (1990–2009). Appl. Geogr. 2011, 31, 1185–1193. [Google Scholar] [CrossRef]
- Ceccarelli, T.; Smiraglia, D.; Bajocco, S.; Rinaldo, S.; Angelis, A.D.; Salvati, L.; Perini, L. Land cover data from Landsat single-date imagery: An approach integrating pixel-based and object-based classifiers. Eur. J. Remote Sens. 2013, 46, 699–717. [Google Scholar] [CrossRef]
- Midekisa, A.; Holl, F.; Savory, D.J.; Andrade-Pacheco, R.; Gething, P.W.; Bennett, A.; Sturrock, H.J.W. Mapping land cover change over continental Africa using Landsat and Google Earth Engine cloud computing. PLoS ONE 2017, 12, e0184926. [Google Scholar] [CrossRef]
- Phiri, D.; Morgenroth, J. Developments in Landsat Land Cover Classification Methods: A Review. Remote Sens. 2017, 9, 967. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef] [Green Version]
- Arnaldo, I.; O’Reilly, U.M.; Veeramachaneni, K. Building Predictive Models via Feature Synthesis. In Proceedings of the 2015 Annual Conference on Genetic and Evolutionary Computation, Dublin, Ireland, 12–16 July 2015; pp. 983–990. [Google Scholar] [CrossRef]
- Mcconaghy, T. FFX: Fast, Scalable, Deterministic Symbolic Regression Technology; Springer: New York, NY, USA, 2011; pp. 235–260. [Google Scholar]
- Liu, H.; Motoda, H. Feature Extraction, Construction and Selection: A Data Mining Perspective; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1998. [Google Scholar]
- Sondhi, P. Feature construction methods: A survey. Sifaka. CS Uiuc. Educ. 2009, 69, 70–71. [Google Scholar]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the 2014 Science and Information Conference, London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar]
- Rasan, N.; Mani, D. A Survey on Feature Extraction Techniques. Int. J. Innov. Res. Comput. Commun. Eng. 2015, 3, 52–55. [Google Scholar] [CrossRef]
- Dong, G.; Liu, H. Feature Engineering for Machine Learning and Data Analytics, 1st ed.; CRC Press, Inc.: Boca Raton, FL, USA, 2018. [Google Scholar]
- Swesi, I.M.A.O.; Bakar, A.A. Recent Developments on Evolutionary Computation Techniques to Feature Construction. In Intelligent Information and Database Systems: Recent Developments; Huk, M., Maleszka, M., Szczerbicki, E., Eds.; Springer: New York, NY, USA, 2020; pp. 109–122. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M. Evolutionary computation for feature manipulation: Key challenges and future directions. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 3061–3067. [Google Scholar]
- Espejo, P.G.; Ventura, S.; Herrera, F. A Survey on the Application of Genetic Programming to Classification. IEEE Trans. Syst. Man Cybern. C 2010, 40, 121–144. [Google Scholar] [CrossRef]
- Krawiec, K. Genetic Programming-based Construction of Features for Machine Learning and Knowledge Discovery Tasks. Genet. Program. Evol. Mach. 2002, 3, 329–343. [Google Scholar] [CrossRef]
- Krawiec, K.; Bhanu, B. Coevolutionary Feature Learning for Object Recognition. In Machine Learning and Data Mining in Pattern Recognition; Perner, P., Rosenfeld, A., Eds.; Springer: New York, NY, USA, 2003; pp. 224–238. [Google Scholar]
- Krawiec, K.; Włodarski, L. Coevolutionary feature construction for transformation of representation of machine learners. In Intelligent Information Processing and Web Mining; Kłopotek, M.A., Wierzchoń, S.T., Trojanowski, K., Eds.; Springer: New York, NY, USA, 2004; pp. 139–150. [Google Scholar]
- Neshatian, K.; Zhang, M.; Johnston, M. Feature Construction and Dimension Reduction Using Genetic Programming. In Proceedings of the 20th Australian Joint Conference on Advances in Artificial Intelligence, Melbourne, VIC, Australia, 19–20 August 2017; Springer: New York, NY, USA, 2017; pp. 160–170. [Google Scholar]
- Tran, B.; Xue, B.; Zhang, M. Genetic programming for feature construction and selection in classification on high-dimensional data. Memetic Comput. 2016, 8, 3–15. [Google Scholar] [CrossRef]
- Tran, C.T.; Zhang, M.; Andreae, P.; Xue, B. Genetic Programming Based Feature Construction for Classification with Incomplete Data. In Proceedings of the Genetic and Evolutionary Computation Conference, Berlin, Germany, 15–19 July 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 1033–1040. [Google Scholar] [CrossRef]
- Chen, Q.; Zhang, M.; Xue, B. Genetic Programming with Embedded Feature Construction for High-Dimensional Symbolic Regression. In Intelligent and Evolutionary Systems; Leu, G., Singh, H.K., Elsayed, S., Eds.; Springer: New York, NY, USA, 2017; pp. 87–102. [Google Scholar]
- Tran, B.; Xue, B.; Zhang, M. Genetic programming for multiple-feature construction on high-dimensional classification. Pattern Recognit. 2019, 93, 404–417. [Google Scholar] [CrossRef]
- Lin, J.Y.; Ke, H.R.; Chien, B.C.; Yang, W.P. Designing a classifier by a layered multi-population genetic programming approach. Pattern Recognit. 2007, 40, 2211–2225. [Google Scholar] [CrossRef]
- Kishore, J.K.; Patnaik, L.M.; Mani, V.; Agrawal, V.K. Application of genetic programming for multicategory pattern classification. IEEE Trans. Evol. Comput. 2000, 4, 242–258. [Google Scholar] [CrossRef] [Green Version]
- Smith, M.; Bull, L. Feature Construction and Selection Using Genetic Programming and a Genetic Algorithm. In European Conference on Genetic Programming; Springer: New York, NY, USA, 2003. [Google Scholar] [CrossRef]
- Guo, H.; Nandi, A.K. Breast cancer diagnosis using genetic programming generated feature. Pattern Recognit. 2006, 39, 980–987. [Google Scholar] [CrossRef]
- Ahmed, S.; Zhang, M.; Peng, L.; Xue, B. Multiple Feature Construction for Effective Biomarker Identification and Classification Using Genetic Programming. In Proceedings of the 2014 Annual Conference on Genetic and Evolutionary Computation, GECCO’14, Vancouver, BC, Canada, 12 July 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 249–256. [Google Scholar] [CrossRef]
- Virgolin, M.; Alderliesten, T.; Bel, A.; Witteveen, C.; Bosman, P.A.N. Symbolic Regression and Feature Construction with GP-GOMEA Applied to Radiotherapy Dose Reconstruction of Childhood Cancer Survivors. In Proceedings of the Genetic and Evolutionary Computation Conference, Kyoto, Japan, 15–19 July 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1395–1402. [Google Scholar] [CrossRef] [Green Version]
- Ain, Q.U.; Xue, B.; Al-Sahaf, H.; Zhang, M. Genetic Programming for Multiple Feature Construction in Skin Cancer Image Classification. In Proceedings of the 2019 International Conference on Image and Vision Computing New Zealand (IVCNZ), Dunedin, New Zealand, 2–4 December 2019; pp. 1–6. [Google Scholar]
- Cherrier, N.; Poli, J.; Defurne, M.; Sabatié, F. Consistent Feature Construction with Constrained Genetic Programming for Experimental Physics. In Proceedings of the IEEE Congress on Evolutionary Computation, CEC 2019, Wellington, New Zealand, 10–13 June 2019; pp. 1650–1658. [Google Scholar] [CrossRef]
- Gong, P.; Marceau, D.J.; Howarth, P.J. A comparison of spatial feature extraction algorithms for land-use classification with SPOT HRV data. Remote Sens. Environ. 1992, 40, 137–151. [Google Scholar] [CrossRef]
- Romero, A.; Gatta, C.; Camps-Valls, G. Unsupervised Deep Feature Extraction for Remote Sensing Image Classification. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1349–1362. [Google Scholar] [CrossRef] [Green Version]
- Ren, J.; Zabalza, J.; Marshall, S.; Zheng, J. Effective Feature Extraction and Data Reduction in Remote Sensing Using Hyperspectral Imaging [Applications Corner]. IEEE Sign. Proc. Mag. 2014, 31, 149–154. [Google Scholar] [CrossRef] [Green Version]
- Pasquarella, V.J.; Holden, C.E.; Woodcock, C.E. Improved mapping of forest type using spectral-temporal Landsat features. Remote Sens. Environ. 2018, 210, 193–207. [Google Scholar] [CrossRef]
- Puente, C.; Olague, G.; Smith, S.; Bullock, S.; González-Botello, M.; Hinojosa, A. A Genetic Programming Approach to Estimate Vegetation Cover in the Context of Soil Erosion Assessment. Photogramm. Eng. Remote Sens. 2011, 77, 363–375. [Google Scholar] [CrossRef] [Green Version]
- Makkeasorn, A.; Chang, N.B.; Li, J. Seasonal change detection of riparian zones with remote sensing images and genetic programming in a semi-arid watershed. J. Environ. Manag. 2009, 90, 1069–1080. [Google Scholar] [CrossRef]
- Makkeasorn, A.; Chang, N.B.; Beaman, M.; Wyatt, C.; Slater, C. Soil moisture estimation in a semiarid watershed using RADARSAT-1 satellite imagery and genetic programming. Water Resour. Res. 2006, 42. [Google Scholar] [CrossRef] [Green Version]
- Chion, C.; Landry, J.A.; Costa, L. A Genetic-Programming-Based Method for Hyperspectral Data Information Extraction: Agricultural Applications. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2446–2457. [Google Scholar] [CrossRef]
- Chen, L. A study of applying genetic programming to reservoir trophic state evaluation using remote sensor data. Int. J. Remote Sens. 2003, 24, 2265–2275. [Google Scholar] [CrossRef]
- Taghizadeh-Mehrjardi, R.; Ayoubi, S.; Namazi, Z.; Malone, B.; Zolfaghari, A.; Roustaiee-Sadrabadi, F. Prediction of soil surface salinity in arid region of central Iran using auxiliary variables and genetic programming. Arid Land Res. Manag. 2016, 30. [Google Scholar] [CrossRef]
- Lary, D.J.; Alavi, A.H.; Gandomi, A.H.; Walker, A.L. Machine learning in geosciences and remote sensing. Geosci. Front. 2016, 7, 3–10. [Google Scholar] [CrossRef] [Green Version]
- Costa, L.; Nunes, L.; Ampatzidis, Y. A new visible band index (vNDVI) for estimating NDVI values on RGB images utilizing genetic algorithms. Comput. Electron. Agric. 2020, 172, 105334. [Google Scholar] [CrossRef]
- Kabiri, P.; Pandi, M.H.; Nejat, S.K.; Ghaderi, H. NDVI Optimization Using Genetic Algorithm. In Proceedings of the 2011 7th Iranian Conference on Machine Vision and Image Processing, Tehran, Iran, 16–17 November 2011; pp. 1–5. [Google Scholar]
- Cabral, A.I.; Silva, S.; Silva, P.C.; Vanneschi, L.; Vasconcelos, M.J. Burned area estimations derived from Landsat ETM+ and OLI data: Comparing Genetic Programming with Maximum Likelihood and Classification and Regression Trees. ISPRS J. Photogramm. Remote Sens. 2018, 142, 94–105. [Google Scholar] [CrossRef]
- Vasconcelos, M.; Cabral, A.B.; Melo, J.; Pearson, T.; Pereira, H.; Cassamá, V.; Yudelman, T. Can blue carbon contribute to clean development in West Africa? The case of Guinea-Bissau. Mitig. Adapt. Strateg. Glob. Chang. 2014, 20. [Google Scholar] [CrossRef]
- Temudo, M.; Cabral, A.; Talhinhas, P. Petro-Landscapes: Urban Expansion and Energy Consumption in Mbanza Kongo City, Northern Angola. Hum. Ecol. 2019, 47, 565–575. [Google Scholar] [CrossRef]
- Lopes, C.; Leite, A.; Vasconcelos, M.J. Open-access cloud resources contribute to mainstream REDD+: The case of Mozambique. Land Use Policy 2019, 82, 48–60. [Google Scholar] [CrossRef]
- Kottek, M.; Grieser, J.; Beck, C.; Rudolf, B.; Rubel, F. World Map of the Köppen-Geiger climate classification updated. Meteorol. Z. 2006, 15, 259–263. [Google Scholar] [CrossRef]
- Temudo, M.P.; Cabral, A.I.; Talhinhas, P. Urban and rural household energy consumption and deforestation patterns in Zaire province, Northern Angola: A landscape approach. Appl. Geogr. 2020, 119, 102207. [Google Scholar] [CrossRef]
- Dinis, A.C. Características Mesológicas de Angola: Descrição e Correlação dos Aspectos Fisiográficos, dos Solos e da Vegetação das Zonas Agrícolas Angolanas; IPAD—Instituto Português de Apoio ao Desenvolvimento: Lisboa, Portugal, 2006. [Google Scholar]
- Climate Risk and Adaptation Country Profile: Mozambique. Available online: https://www.gfdrr.org/en/publication/climate-risk-and-adaptation-country-profile-mozambique (accessed on 17 November 2020).
- Climate Analysis Mozambique. Available online: https://fscluster.org/mozambique/document/climate-analysis-mozambique (accessed on 17 November 2020).
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Softw. 2010, 33. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Landsat 8 Bands. Available online: https://landsat.gsfc.nasa.gov/landsat-8/landsat-8-bands (accessed on 17 November 2020).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Ref. | Country | Scene Identifier Path/Row | Acq. Date DD/MM/YYYY | No. Images | Satellite | KGCS |
|---|---|---|---|---|---|---|---|
| Ao2 | Angola | 177/67 | 09/07/2013 | 1 | LS-8 | Cwa | |
| Br2 | [70] | Brazil | 225/64 | 28/02/2015 | 1 | LS-8 | Af, Am |
| Cd2 | [70] | DR Congo | 175/62 | 08/06/2013 | 1 | LS-8 | Aw |
| Gw2 | [70] | Guinea-Bissau | 204/52 | 13/05/2002 | 1 | LS-7 | Am, Aw |
| IM-3 IM-10 | [71] | Guinea-Bissau | 203/51, 52 204/51, 52 205/51 | From: 02/01/2010 To: 01/04/2010 | 17 | LS-7 | Am, Aw |
| Ao8 | [72] | Angola | 182/64, 65 | 18/06/2016 | 2 | LS-8 | Aw |
| Gw10 | Guinea-Bissau | 204/51, 52 205/51 | 01/03/2019 24/03/2019 | 3 | LS-8 | Am, Aw | |
| Mz6 | [73] | Mozambique | Entire Country ( 122 S-2A tiles ) | From: 19/02/2016 To: 06/10/2016 | 2806 | S-2A | Am, Aw, BSh, Cwa, Cwb, Cfa |
| Dataset | Classes (No. Pixels) | No. Classes | No. Bands No. Features | Total Pixels | ||
|---|---|---|---|---|---|---|
| Ao2 | Burnt (1573) | Non-Burnt (2309) | 2 | 7 | 3882 | |
| Br2 | Burnt (2033) | Non-Burnt (2839) | 2 | 7 | 4872 | |
| Cd2 | Burnt (877) | Non-Burnt (1972) | 2 | 7 | 2849 | |
| Gw2 | Burnt (1101) | Non-Burnt (3430) | 2 | 7 | 4531 | |
| IM-3 | Savanna Woodland (114) | Dense Forest (68) | Open Forest (140) | 3 | 6 | 322 |
| IM-10 | Agriculture/Bare Soil (950) | Burnt (77) | Dense Forest (524) | 10 | 6 | 6798 |
| Grassland (75) | Mangrove (1240) | Open Forest (723) | ||||
| Savanna Woodland (1626) | Sand (166) | Mud (509) | ||||
| Water (908) | ||||||
| Ao8 | Agriculture/Bare Soil (73) | Burnt (301) | Clouds (332) | 8 | 10 | 2183 |
| Forest (662) | Grassland (12) | Urban (53) | ||||
| Savanna Woodland (598) | Water (152) | |||||
| Gw10 | Agriculture/Bare Soil (449) | Burnt (157) | Dense Forest (62) | 10 | 7 | 5080 |
| Grassland (16) | Mangrove (1383) | Open Forest (646) | ||||
| Savanna Woodland (1308) | Sand (50) | Water (620) | ||||
| Wetland (389) | ||||||
| Mz6 | Agriculture/Bare Soil (33611) | Forest (63190) | Grassland (28406) | 6 | 10 | 190202 |
| Urban (4194) | Wetland (35673) | Other (25128) | ||||
| General: | |
| Runs | 30 |
| Training Set | 70% of the samples of each class |
| Statistical Significance | p-value < 0.01 (Kruskal–Wallis H-test) |
| M3GP: | |
| Stopping Criteria | 50 generations or 100% training accuracy |
| Fitness | WAF (Weighted Average of F-measures) |
| Pruning | Final individual |
| XGBoost: | |
| Maximum Depth | 20 in the Mz6 dataset and 6 (default) in the other datasets |
| Ao2 | Br2 | Cg2 | Gw2 | IM-3 | IM-10 | Ao8 | Gw10 | Mz6 | |
|---|---|---|---|---|---|---|---|---|---|
| Accuracy | |||||||||
| Training | 1.000 | 0.992 | 0.993 | 1.000 | 0.996 | 0.932 | 1.000 | 0.988 | 0.620 |
| Test | 0.999 | 0.990 | 0.993 | 1.000 | 0.948 | 0.916 | 0.983 | 0.971 | 0.620 |
| Hyperfeatures | |||||||||
| Number | 5 (3–8) | 8 (1–15) | 4 (3–8) | 2 (1–3) | 8.5 (5–13) | 23 (17–29) | 18 (14–21) | 21 (15–23) | 14.5 (12–17) |
| Avg. Size | 14 (9–28) | 14 (6–39) | 23 (6–40) | 11 (2–43) | 11 (5–22) | 10 (8–13) | 10 (5–14) | 8 (6–12) | 11 (5–17) |
| Decision Trees | Random Forests | XGBoost | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Ao2 | Br2 | Cd2 | Gw2 | Ao2 | Br2 | Cd2 | Gw2 | Ao2 | Br2 | Cd2 | Gw2 |
| Orig. Dataset | ||||||||||||
| Test Accuracy | 0.999 | 0.989 | 0.996 | 0.999 | 0.999 | 0.992 | 0.999 | 1.000 | 0.999 | 0.993 | 0.998 | 0.999 |
| Indices | ||||||||||||
| Test Accuracy | 0.999 | 0.990 | 0.996 | 0.999 | 0.999 | 0.993 | 0.999 | 1.000 | 0.999 | 0.993 | 0.998 | 0.999 |
| p-value vs. Orig. | 0.694 | 0.678 | 0.909 | 0.669 | 0.675 | 0.917 | 0.436 | 0.871 | 1.000 | 1.000 | 1.000 | 1.000 |
| EFS | ||||||||||||
| Test Accuracy | 0.998 | 0.989 | 0.996 | 0.999 | 1.000 | 0.992 | 0.999 | 1.000 | 0.999 | 0.993 | 0.998 | 0.999 |
| p-value vs. Orig. | 0.012 | 0.226 | 0.143 | 0.735 | 0.091 | 0.777 | 0.137 | 0.619 | 0.256 | 0.682 | 0.489 | 0.127 |
| FFX | ||||||||||||
| Test Accuracy | 0.999 | 0.990 | 0.996 | 1.000 | 0.999 | 0.993 | 0.999 | 1.000 | 0.999 | 0.993 | 0.998 | 1.000 |
| p-value vs. Orig. | 0.224 | 0.941 | 0.294 | 0.000 | 0.363 | 0.988 | 0.148 | 0.730 | 0.739 | 0.794 | 0.886 | 0.000 |
| M3GP | ||||||||||||
| Test Accuracy | 0.999 | 0.990 | 0.996 | 0.999 | 0.999 | 0.992 | 0.999 | 1.000 | 0.999 | 0.993 | 0.998 | 0.999 |
| p-value vs. Orig. | 0.908 | 0.947 | 0.672 | 0.813 | 0.500 | 0.846 | 0.688 | 0.871 | 1.000 | 1.000 | 1.000 | 1.000 |
| p-value vs. Ind. | 0.782 | 0.761 | 0.598 | 0.849 | 0.780 | 0.982 | 0.738 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| p-value vs. FFX | 0.276 | 0.830 | 0.525 | 0.001 | 0.095 | 0.905 | 0.319 | 0.868 | 0.739 | 0.794 | 0.886 | 0.000 |
| p-value vs. EFS | 0.017 | 0.272 | 0.291 | 0.572 | 0.286 | 0.682 | 0.309 | 0.757 | 0.256 | 0.682 | 0.489 | 0.127 |
| XGB—Original | Ao2 | Br2 | Cg2 | Gw2 | IM-3 | IM-10 | Gw10 | Ao8 | Mz6 |
|---|---|---|---|---|---|---|---|---|---|
| Agriculture/Bare Soil | — | — | — | — | — | 98.96% | 96.34% | 83.02% | 72.59% |
| Burnt | 99.81% | 99.51% | 99.63% | 99.80% | — | 93.19% | 98.72% | 99.22% | — |
| Clouds | — | — | — | — | — | — | — | 100.00% | — |
| Forest | — | — | — | — | — | — | — | 99.87% | 88.05% |
| - Dense Forest | — | — | — | — | 92.67% | 87.67% | 79.81% | — | — |
| - Open Forest | — | — | — | — | 93.02% | 93.65% | 98.41% | — | — |
| Grassland | — | — | — | — | — | 92.73% | 81.67% | 85.56% | 64.02% |
| Mangrove | — | — | — | — | — | 99.12% | 98.41% | — | — |
| Mud | — | — | — | — | — | 96.07% | — | — | — |
| Sand | — | — | — | — | — | 95.78% | 90.22% | — | — |
| Savanna Woodland | — | — | — | — | 99.71% | 84.41% | 98.66% | 98.66% | — |
| Urban | — | — | — | — | — | — | — | 87.78% | 56.82% |
| Water | — | — | — | — | — | 97.33% | 99.48% | 99.48% | — |
| Wetland | — | — | — | — | — | — | 95.29% | — | 80.34% |
| Other | 99.97% | 99.16% | 99.88% | 99.98% | — | — | — | — | 76.07% |
| Decision Trees | Random Forests | XGBoost | ||||
|---|---|---|---|---|---|---|
| Dataset | IM-3 | IM-10 | IM-3 | IM-10 | IM-3 | IM-10 |
| Original Dataset | ||||||
| Test Accuracy | 0.948 | 0.956 | 0.969 | 0.974 | 0.958 | 0.973 |
| Indices | ||||||
| Test Accuracy | 0.938 | 0.959 | 0.958 | 0.979 | 0.948 | 0.977 |
| p-value vs. Original | 0.151 | 0.051 | 0.062 | 0.000 | 0.178 | 0.001 |
| M3GP | ||||||
| Test Accuracy | 0.958 | 0.961 | 0.969 | 0.978 | 0.969 | 0.978 |
| p-value vs. Original | 0.020 | 0.000 | 0.844 | 0.000 | 0.009 | 0.000 |
| p-value vs. Indices | 0.000 | 0.407 | 0.055 | 0.218 | 0.000 | 0.711 |
| XGB IM−3 | Dense Forest | Open Forest | Savanna Woodland | Original Accuracy |
|---|---|---|---|---|
| Dense Forest | 2.83% | −2.83% | 0.00% | 92.67% |
| Open Forest | −3.33% | 2.46% | 0.87% | 93.02% |
| Savanna Woodland | 0.00% | 1.57% | −1.57% | 99.71% |
| XGB IM-10 | Water | Burnt | Sand | Agriculture /Bare soil | Open Forest | Dense Forest | Grassland | Mangrove | Savanna Woodland | Mud | Original Accuracy |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Water | 0.00% | −0.05% | 0.00% | 0.02% | 0.00% | 0.00% | 0.00% | −0.01% | 0.00% | 0.04% | 97.33% |
| Burnt | 0.87% | 0.29% | 0.00% | −0.29% | 0.00% | 0.00% | 0.14% | −0.87% | −0.58% | 0.43% | 93.19% |
| Sand | 0.00% | 0.00% | 0.95% | −0.95% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | 95.78% |
| Agriculture /Bare soil | 0.00% | 0.00% | −0.15% | 0.19% | 0.00% | 0.00% | −0.01% | −0.18% | 0.13% | 0.02% | 98.96% |
| Open Forest | 0.00% | 0.00% | 0.00% | −0.08% | 1.03% | −1.83% | −0.08% | 0.79% | 0.16% | 0.00% | 93.65% |
| Dense Forest | 0.00% | 0.00% | 0.00% | 0.00% | −2.50% | 4.33% | 0.00% | −1.83% | 0.00% | 0.00% | 87.67% |
| Grassland | −0.15% | 0.15% | 0.00% | −0.15% | −0.45% | 0.00% | 0.15% | 0.61% | −0.15% | 0.00% | 92.73% |
| Mangrove | −0.15% | 0.00% | 0.00% | −0.03% | −0.03% | 0.00% | 0.00% | 0.23% | −0.04% | 0.01% | 99.12% |
| Savanna Woodland | 0.00% | −0.29% | 0.00% | −2.55% | 0.10% | 0.00% | −1.27% | −1.18% | 5.49% | −0.29% | 84.41% |
| Mud | −1.29% | 0.09% | 0.00% | −0.02% | 0.00% | 0.00% | 0.00% | 0.07% | 0.00% | 1.16% | 96.07% |
| Decision Trees | Random Forests | XGBoost | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Dataset | Ao8 | Gw10 | Mz6 | Ao8 | Gw10 | Mz6 | Ao8 | Gw10 | Mz6 |
| Original Dataset | |||||||||
| Test Accuracy | 0.977 | 0.964 | 0.662 | 0.988 | 0.981 | 0.773 | 0.985 | 0.979 | 0.780 |
| Indices | |||||||||
| Test Accuracy | 0.978 | 0.968 | 0.662 | 0.989 | 0.980 | 0.769 | 0.986 | 0.980 | 0.781 |
| p-value vs. Original | 0.291 | 0.000 | 0.371 | 0.213 | 0.824 | 0.000 | 0.645 | 0.335 | 0.003 |
| M3GP | |||||||||
| Test Accuracy | 0.980 | 0.970 | 0.665 | 0.988 | 0.982 | 0.775 | 0.987 | 0.983 | 0.786 |
| p-value vs. Original | 0.125 | 0.000 | 0.000 | 0.923 | 0.054 | 0.006 | 0.389 | 0.000 | 0.000 |
| p-value vs. Indices | 0.693 | 0.847 | 0.000 | 0.228 | 0.038 | 0.000 | 0.650 | 0.002 | 0.000 |
| XGB Gw10 | Agriculture /Bare soil | Burnt | Dense Forest | Grassland | Mangrove | Open Forest | Sand | Savanna Woodland | Water | Wetland | Original Accuracy |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Agriculture /Bare soil | 0.77% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | −0.62% | −0.17% | 0.00% | 0.02% | 96.34% |
| Burnt | −0.14% | 0.28% | 0.00% | 0.00% | −0.43% | −0.07% | 0.00% | 0.21% | 0.00% | 0.14% | 98.72% |
| Dense Forest | 0.00% | 0.00% | 0.93% | 0.00% | 0.93% | −1.85% | 0.00% | 0.00% | 0.00% | 0.00% | 79.81% |
| Grassland | 0.00% | 0.00% | 0.00% | −2.50% | 0.00% | 0.00% | 0.00% | 2.50% | 0.00% | 0.00% | 81.67% |
| Mangrove | 0.00% | 0.00% | −0.03% | 0.00% | 0.40% | −0.02% | 0.00% | −0.08% | −0.08% | −0.19% | 98.41% |
| Open Forest | 0.00% | 0.00% | −0.19% | 0.00% | −0.03% | 0.31% | 0.00% | −0.09% | 0.00% | 0.00% | 98.41% |
| Sand | 0.67% | 0.00% | 0.00% | 0.00% | 0.00% | 0.00% | −0.67% | 0.00% | 0.00% | 0.00% | 90.22% |
| Savanna Woodland | −0.09% | 0.00% | 0.00% | 0.00% | −0.02% | −0.14% | 0.00% | 0.29% | 0.00% | −0.04% | 98.66% |
| Water | 0.00% | 0.00% | 0.00% | 0.00% | −0.05% | 0.00% | 0.00% | 0.00% | 0.16% | −0.11% | 99.48% |
| Wetland | −0.11% | 0.06% | 0.00% | 0.00% | 0.34% | 0.00% | 0.00% | 0.00% | 0.06% | 0.34% | 95.29% |
| XGB-Mz6 | Agriculture /Bare soil | Forest | Grassland | Urban | Wetland | Other | Original Accuracy |
|---|---|---|---|---|---|---|---|
| Agriculture /Bare soil | 0.87% | −0.24% | −0.28% | −0.01% | −0.01% | −0.32% | 72.59% |
| Forest | −0.00% | 0.34% | −0.29% | 0.00% | −0.04% | −0.01% | 88.05% |
| Grassland | −0.26% | −0.32% | 0.51% | 0.00% | 0.14% | −0.08% | 64.02% |
| Urban | −0.03% | −0.02% | −0.25% | 1.82% | −0.06% | −1.48% | 56.82% |
| Wetland | −0.15% | −0.19% | −0.39% | 0.02% | 0.84% | −0.12% | 80.34% |
| Other | −0.26% | −0.04% | −0.18% | −0.04% | −0.08% | 0.60% | 76.07% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Batista, J.E.; Cabral, A.I.R.; Vasconcelos, M.J.P.; Vanneschi, L.; Silva, S. Improving Land Cover Classification Using Genetic Programming for Feature Construction. Remote Sens. 2021, 13, 1623. https://doi.org/10.3390/rs13091623
Batista JE, Cabral AIR, Vasconcelos MJP, Vanneschi L, Silva S. Improving Land Cover Classification Using Genetic Programming for Feature Construction. Remote Sensing. 2021; 13(9):1623. https://doi.org/10.3390/rs13091623
Chicago/Turabian StyleBatista, João E., Ana I. R. Cabral, Maria J. P. Vasconcelos, Leonardo Vanneschi, and Sara Silva. 2021. "Improving Land Cover Classification Using Genetic Programming for Feature Construction" Remote Sensing 13, no. 9: 1623. https://doi.org/10.3390/rs13091623
APA StyleBatista, J. E., Cabral, A. I. R., Vasconcelos, M. J. P., Vanneschi, L., & Silva, S. (2021). Improving Land Cover Classification Using Genetic Programming for Feature Construction. Remote Sensing, 13(9), 1623. https://doi.org/10.3390/rs13091623