
LIME-Based Data Selection Method for SAR Images Generation Using GAN



Abstract
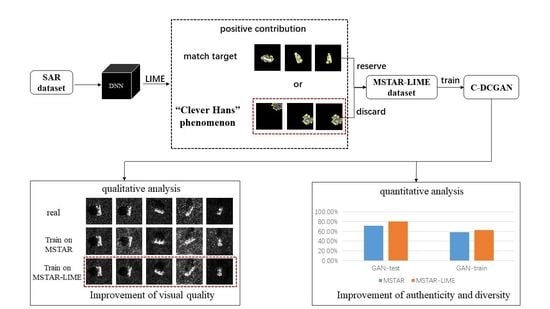
:
1. Introduction
2. Materials and Methods
2.1. Conditional Deep Convolutional GAN
2.2. Local Interpretable Mode-Agnostic Explanation
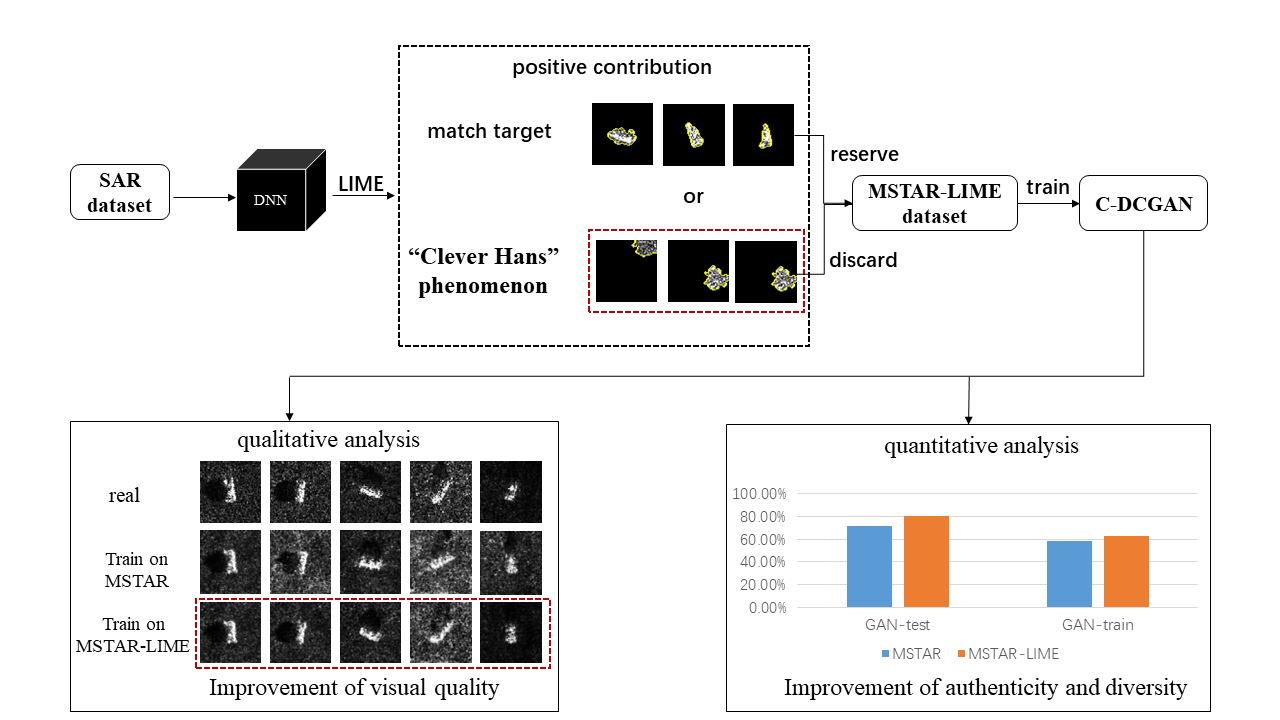
3. Our Method
- A CNN is trained on the MSTAR dataset. All the SAR images are converted to pseudo RGB images by repeatedly copying the monochromatic image in three channels. The input size of the SAR image is ;
- The LIME is adopted to provide the positive contribution to the CNN’s classification result of each SAR image;
- The original SAR images are selected according to the distribution of the positive contribution. The SAR images with the positive contribution in the background are discarded; The SAR images with the positive contribution coincident with targets are selected to form a new dataset;
- Two C-DCGANs are trained on the MSTAR dataset and the selected dataset, respectively, to generate two labeled SAR image datasets;
- Evaluate the two C-DCGANs based on different metrics. The evaluation results are presented in Section 4.3.
4. Experimental Results
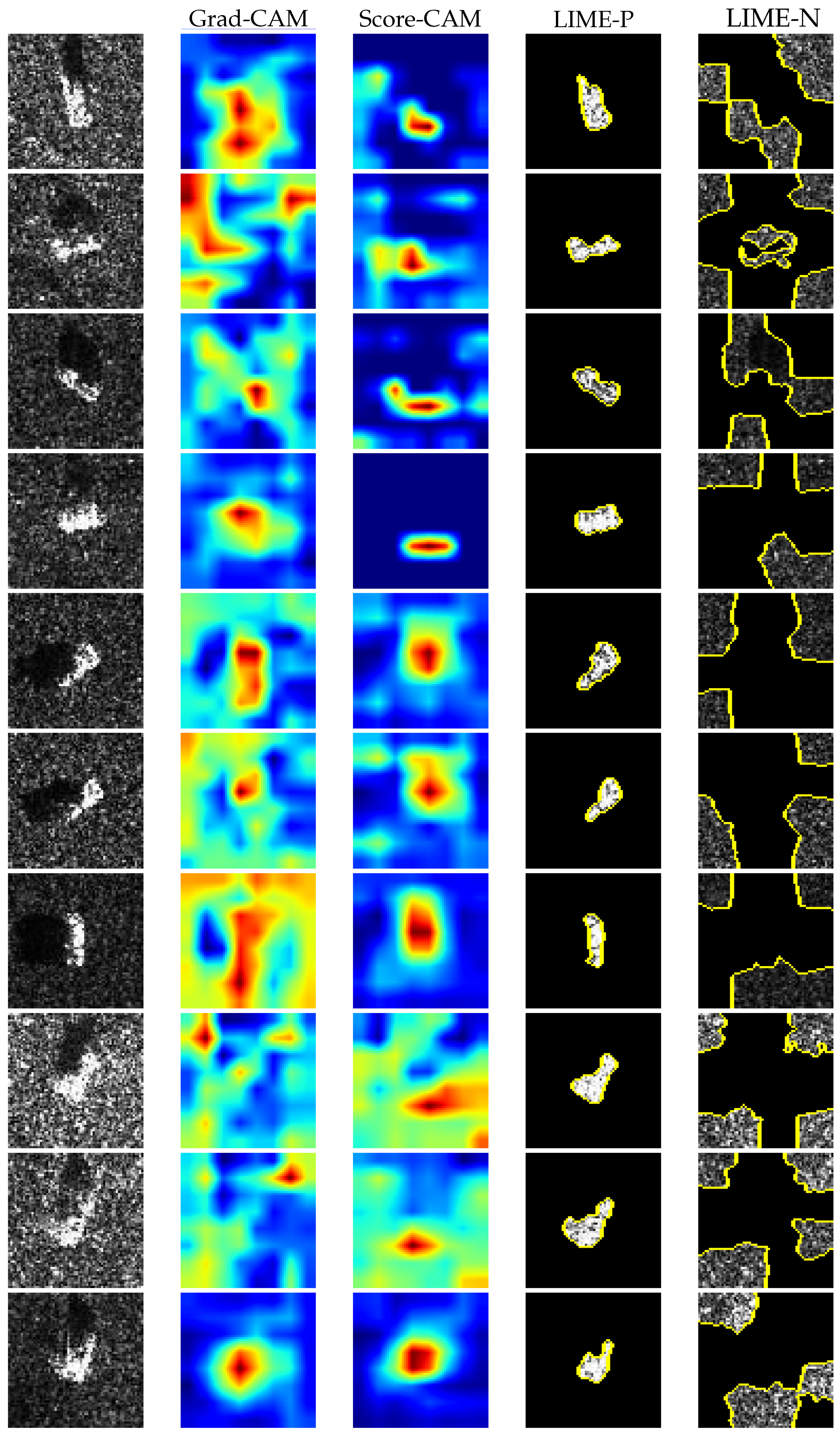
4.1. LIME Versus CAM Methods
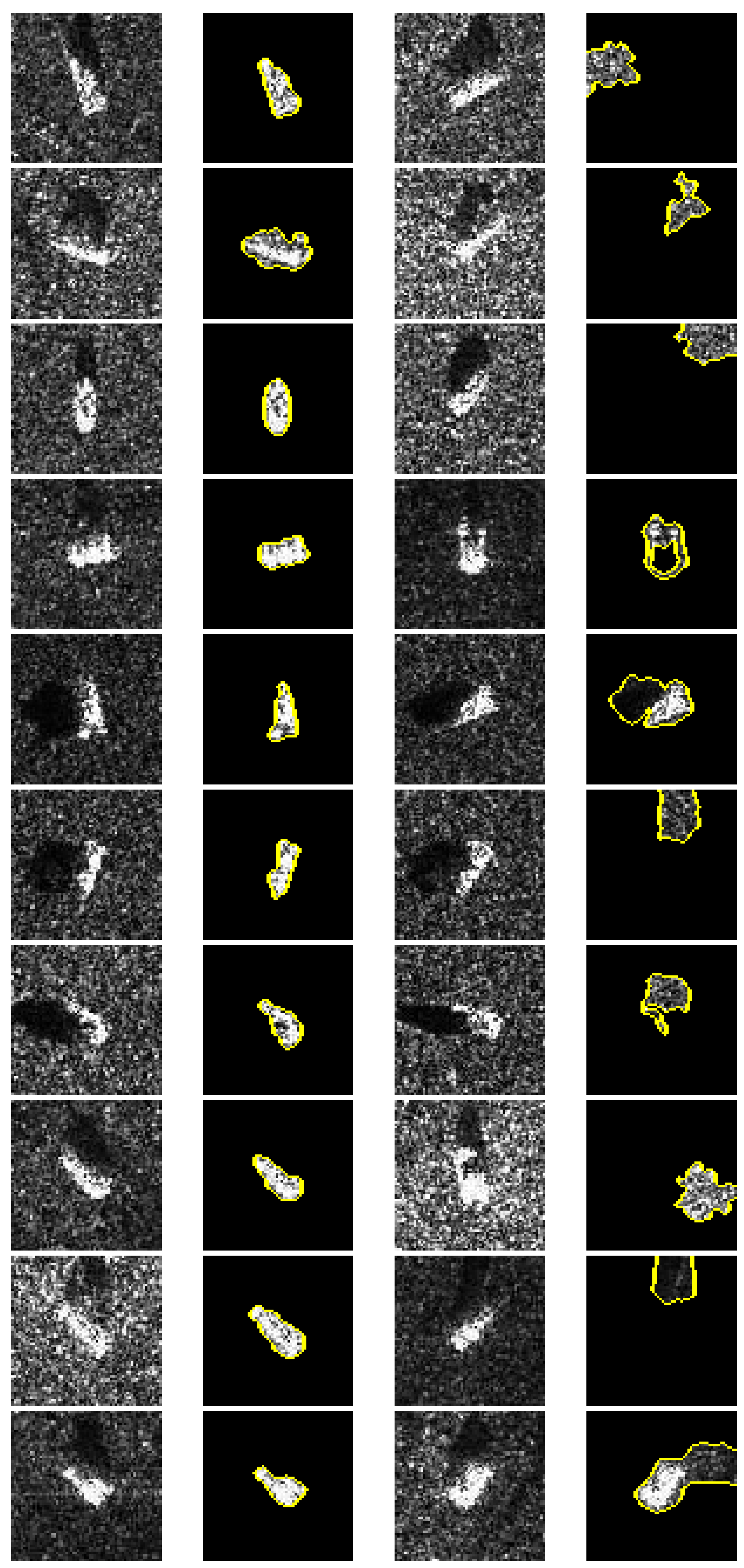
4.2. “Clever Hans” Phenomenon in SAR Image Classification Task
4.3. Quality Analysis of Generated Images
4.3.1. Visual Quality
4.3.2. Independence Analysis
4.3.3. Authenticity
4.3.4. Diversity
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kong, L.; Xu, X. A MIMO-SAR Tomography Algorithm Based on Fully-Polarimetric Data. Sensors 2019, 19, 4839. [Google Scholar] [CrossRef] [Green Version]
- Lin, M.; Chen, S.; Lu, F.; Xing, M.; Wei, J. Realizing Target Detection in SAR Images Based on Multiscale Superpixel Fusion. Sensors 2021, 21, 1643. [Google Scholar] [CrossRef] [PubMed]
- Mohsenzadegan, K.; Tavakkoli, V.; Kyamakya, K. A Deep-Learning Based Visual Sensing Concept for a Robust Classification of Document Images under Real-World Hard Conditions. Sensors 2021, 21, 6763. [Google Scholar] [CrossRef] [PubMed]
- Ding, B.; Wen, G.; Huang, X.; Ma, C.; Yang, X. Data augmentation by multilevel reconstruction using attributed scattering center for SAR target recognition. IEEE Geosci. Remote Sens. Lett. 2017, 14, 979–983. [Google Scholar] [CrossRef]
- Franceschetti, G.; Guida, R.; Iodice, A.; Riccio, D.; Ruello, G. Efficient simulation of hybrid stripmap/spotlight SAR raw signals from extended scenes. IEEE Trans. Geosci. Remote Sens. 2004, 42, 2385–2396. [Google Scholar] [CrossRef]
- Martino, G.; Lodice, A.; Natale, A.; Riccio, D. Time-Domain and Monostatic-like Frequency-Domain Methods for Bistatic SAR Simulation. Sensors 2021, 21, 5012. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Cambridge, MA, USA, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Represention Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 214–223. [Google Scholar]
- Shaham, U.; Yamada, Y.; Negahban, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Cao, C.; Cao, Z.; Cui, Z. LDGAN: A Synthetic Aperture Radar Image Generation Method for Automatic Target Recognition. IEEE Trans. Geosci. Remote Sens. 2019, 99, 1–14. [Google Scholar] [CrossRef]
- Du, S.; Hong, J.; Wang, Y.; Qi, Y. A High-Quality Multicategory SAR Images Generation Method With Multiconstraint GAN for ATR. IEEE Geosci. Remote Sens. Lett. 2021, 99, 1–5. [Google Scholar] [CrossRef]
- Huang, H.; Zhang, F.; Zhou, Y.; Yin, Q.; Hu, W. High Resolution SAR Image Synthesis with Hierarchical Generative Adversarial Networks. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 2782–2785. [Google Scholar]
- Pfungst, O.; Stumpf, C.; Rahn, C.; Angell, J. Clever Hans: Contribution to experimental animal and human psychology. Philos. Psychol. Sci. Methods 1911, 8, 663–666. [Google Scholar]
- Lapuschkin, S.; Wäldchen, S.; Binder, A.; Montavon, G.; Samek, W.; Müller, K. Unmasking Clever Hans predictors and assessing what machines really learn. Nat. Commun. 2019, 10, 1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLoS ONE 2014, 10, e0130140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Montavon, G.; Lapuschkin, S.; Binder, A.; Samek, K.; Müller, K. Explaining NonLinear Classification Decisions with Deep Taylor Decomposition. Pattern Recognit. 2016, 65, 211–222. [Google Scholar] [CrossRef]
- Ramprasaath, R.S.; Michael, C.; Abhishek, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Fu, H.; Hu, Q.; Dong, X.; Guo, Y.; Gao, Y.; Li, B. Axiom-based Grad-CAM: Towards Accurate Visualization and Explanation of CNNs. In Proceedings of the 2020 31th British Machine Vision Conference (BMVC), Manchester, UK, 7–10 September 2020. [Google Scholar]
- Saurabh, D.; Harish, G.R. Ablation-CAM: Visual Explanations for Deep Convolutional Network via Gradient-free Localization. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass, CO, USA, 1–5 March 2020. [Google Scholar]
- Feng, Z.; Zhu, M.; Stanković, L.; Ji, H. Self-Matching CAM: A Novel Accurate Visual Explanation of CNNs for SAR Image Interpretation. Remote Sens. 2021, 13, 1772. [Google Scholar] [CrossRef]
- Wang, H.F.; Wang, Z.F.; Du, M.N. Methods for Interpreting and Understanding Deep Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Fong, R.; Vedaldi, A. Interpretable Explanations of Black Boxes by Meaningful Perturbation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3429–3437. [Google Scholar]
- Agarwal, C.; Schonfeld, D.; Nguyen, A. Removing input features via a generative model to explain their attributions to classifier’s decisions. arXiv 2019, arXiv:1910.04256. [Google Scholar]
- Ribeiro, M.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.; Lee, S. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4768–4777. [Google Scholar]
- Levinshtein, A.; Stere, A.; Kutulakos, K.N.; Fleet, D.J.; Dickinson, S.J.; Siddiqi, K. TurboPixels: Fast Superpixels Using Geometric Flows. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2290–2297. [Google Scholar] [CrossRef] [Green Version]
- Salem, M.; Ibrahim, A.F.; Ali, H.A. Automatic quick-shift method for color image segmentation. In Proceedings of the 8th International Conference on Computer Engineering & Systems (ICCES), Cairo, Egypt, 26–28 November 2013; pp. 245–251. [Google Scholar]
- Zhang, L.; Han, C.; Cheng, Y. Improved SLIC superpixel generation algorithm and its application in polarimetric SAR images classification. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 4578–4581. [Google Scholar]
- Shmelkon, K.; Schmid, C.; Alahari, K. How good is my GAN? In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 213–229. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2S1 | BRDM_2 | BTR_60 | D7 | SN_132 | SN_9563 | SN_C71 | T62 | ZIL131 | ZSU_23_4 | |
|---|---|---|---|---|---|---|---|---|---|---|
| MSTAR | 573 | 572 | 452 | 573 | 428 | 486 | 427 | 572 | 573 | 573 |
| MSTAR-LIME | 520 | - | - | 567 | 425 | 393 | - | 568 | 487 | 567 |
| Before Selection | After Selection | |
|---|---|---|
| 2S1 | 1.96 | 1.78 |
| D7 | 1.41 | 1.39 |
| SN_132 | 1.37 | 1.15 |
| SN_9563 | 1.74 | 1.41 |
| T62 | 1.41 | 1.09 |
| ZIL131 | 1.31 | 1.10 |
| ZSU_23_4 | 1.53 | 1.41 |
| Before Selection | After Selection |
|---|---|
| 71.67% | 80.62% |
| Before Selection | After Selection |
|---|---|
| 58.73% | 62.56% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, M.; Zang, B.; Ding, L.; Lei, T.; Feng, Z.; Fan, J. LIME-Based Data Selection Method for SAR Images Generation Using GAN. Remote Sens. 2022, 14, 204. https://doi.org/10.3390/rs14010204
Zhu M, Zang B, Ding L, Lei T, Feng Z, Fan J. LIME-Based Data Selection Method for SAR Images Generation Using GAN. Remote Sensing. 2022; 14(1):204. https://doi.org/10.3390/rs14010204
Chicago/Turabian StyleZhu, Mingzhe, Bo Zang, Linlin Ding, Tao Lei, Zhenpeng Feng, and Jingyuan Fan. 2022. "LIME-Based Data Selection Method for SAR Images Generation Using GAN" Remote Sensing 14, no. 1: 204. https://doi.org/10.3390/rs14010204
APA StyleZhu, M., Zang, B., Ding, L., Lei, T., Feng, Z., & Fan, J. (2022). LIME-Based Data Selection Method for SAR Images Generation Using GAN. Remote Sensing, 14(1), 204. https://doi.org/10.3390/rs14010204