
A Bidirectional Deep-Learning-Based Spectral Attention Mechanism for Hyperspectral Data Classification


Abstract
:1. Introduction
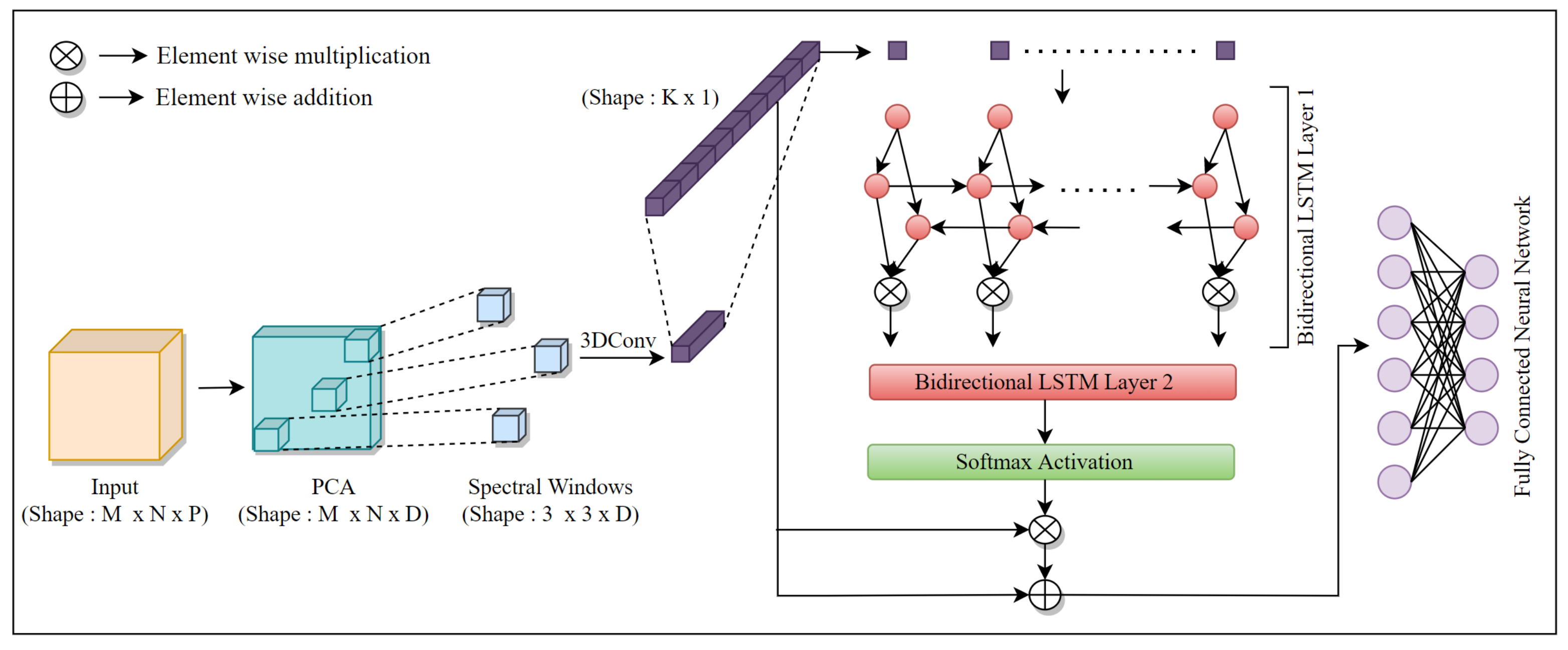
- A lightweight spectral feature extraction methodology for hyperspectral data analysis is proposed using 3D-convolutions in conjunction to an effective dimensionality reduction technique using PCA.
- The acquired spectral features, which are now a better representation of the temporal information in a lower dimensional subspace, are fed into a bidirectional LSTM-based attention framework, followed by an FNN-based supervised classification.
- Hence, the proposed spectral-attention-driven classification framework is driven towards improved automated hyperspectral data analysis, while also addressing big data challenges such as high computational and memory overhead.
- This work also presents variations of the proposed deep-learning-based feature extraction and classification frameworks to include the spectral-only, spatial-only, and spectral–spatial information extraction models. A comprehensive performance study of the several spatial–spectral-information-based hyperspectral data analysis frameworks is also conducted.
2. Proposed Classification Methodology
BI-DI-SPEC-ATTN
3. Methodologies for Comparison
3.1. PCA-3D-CNN
3.2. SPEC-3D-CNN
3.3. SPAT-2D-CNN
3.4. SVM-CK
4. Experimental Results
4.1. Datasets
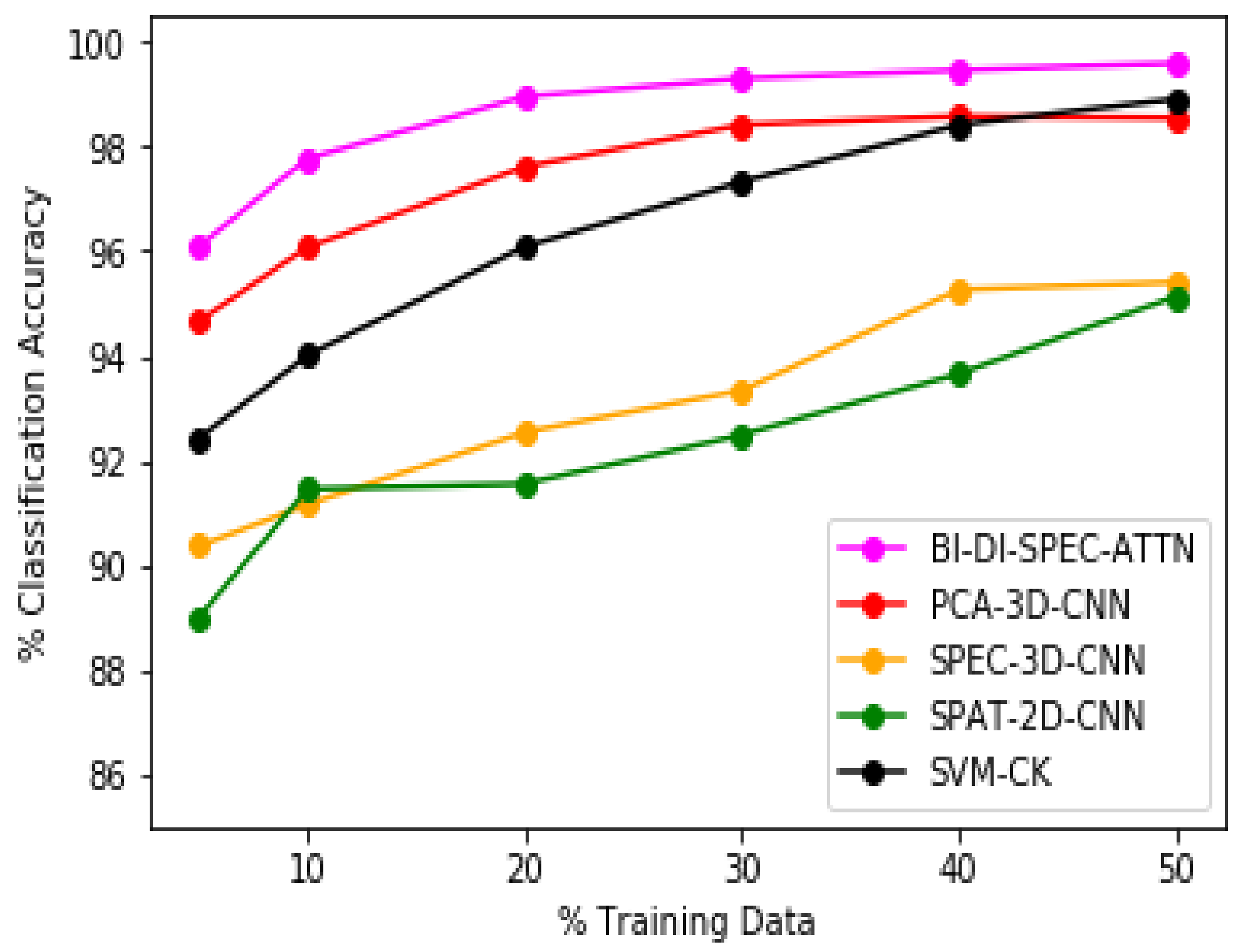
4.2. Parameter Tuning and Experimental Setup
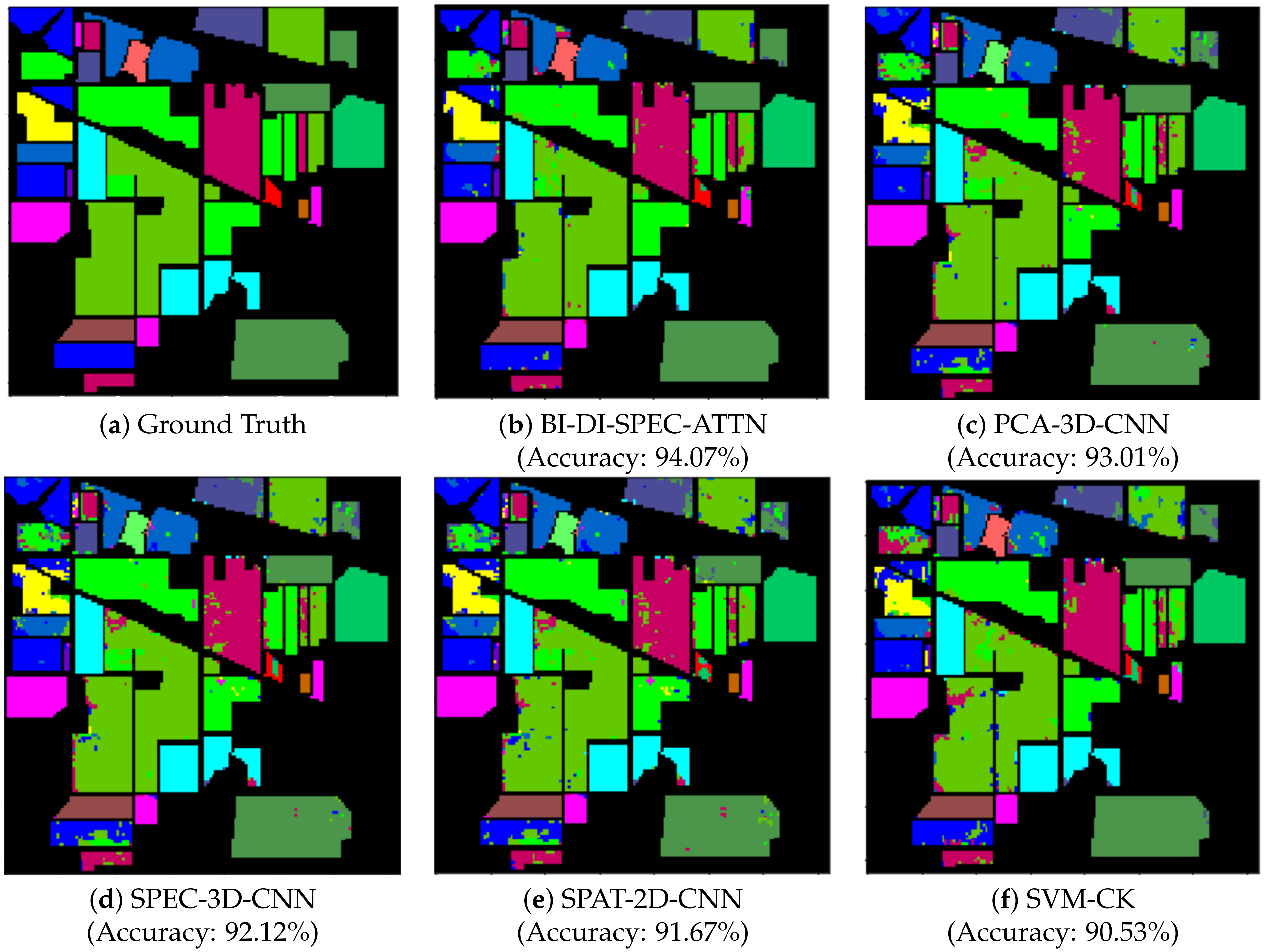
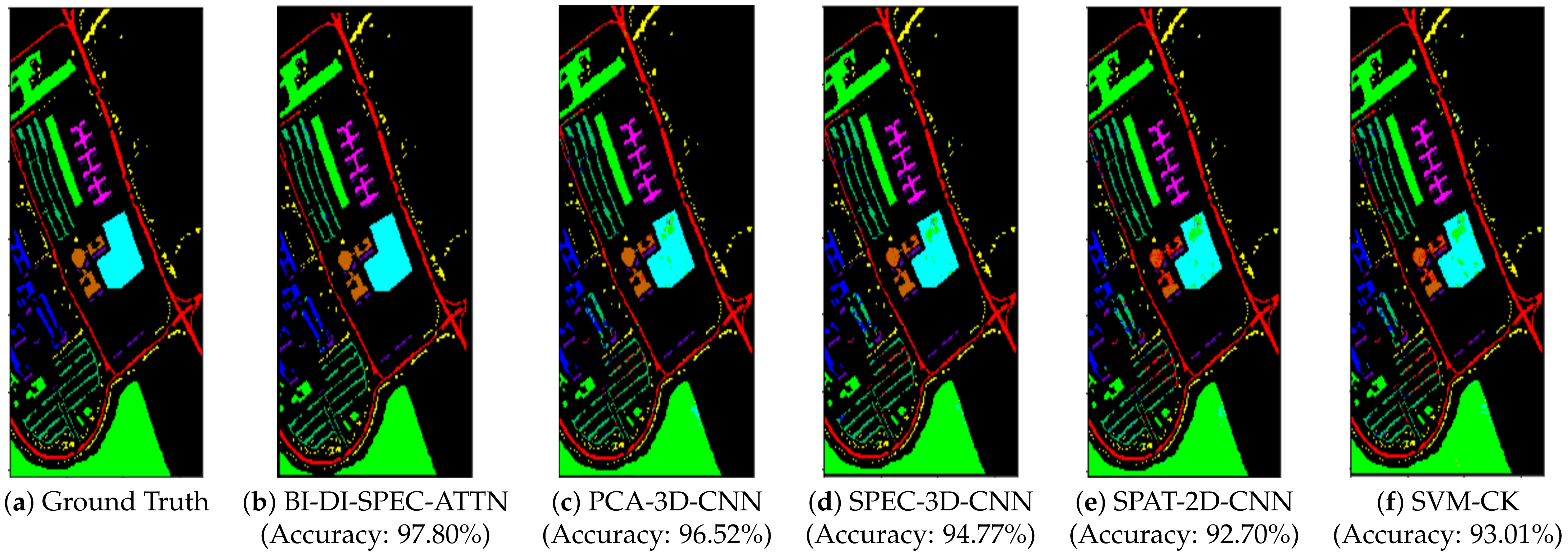
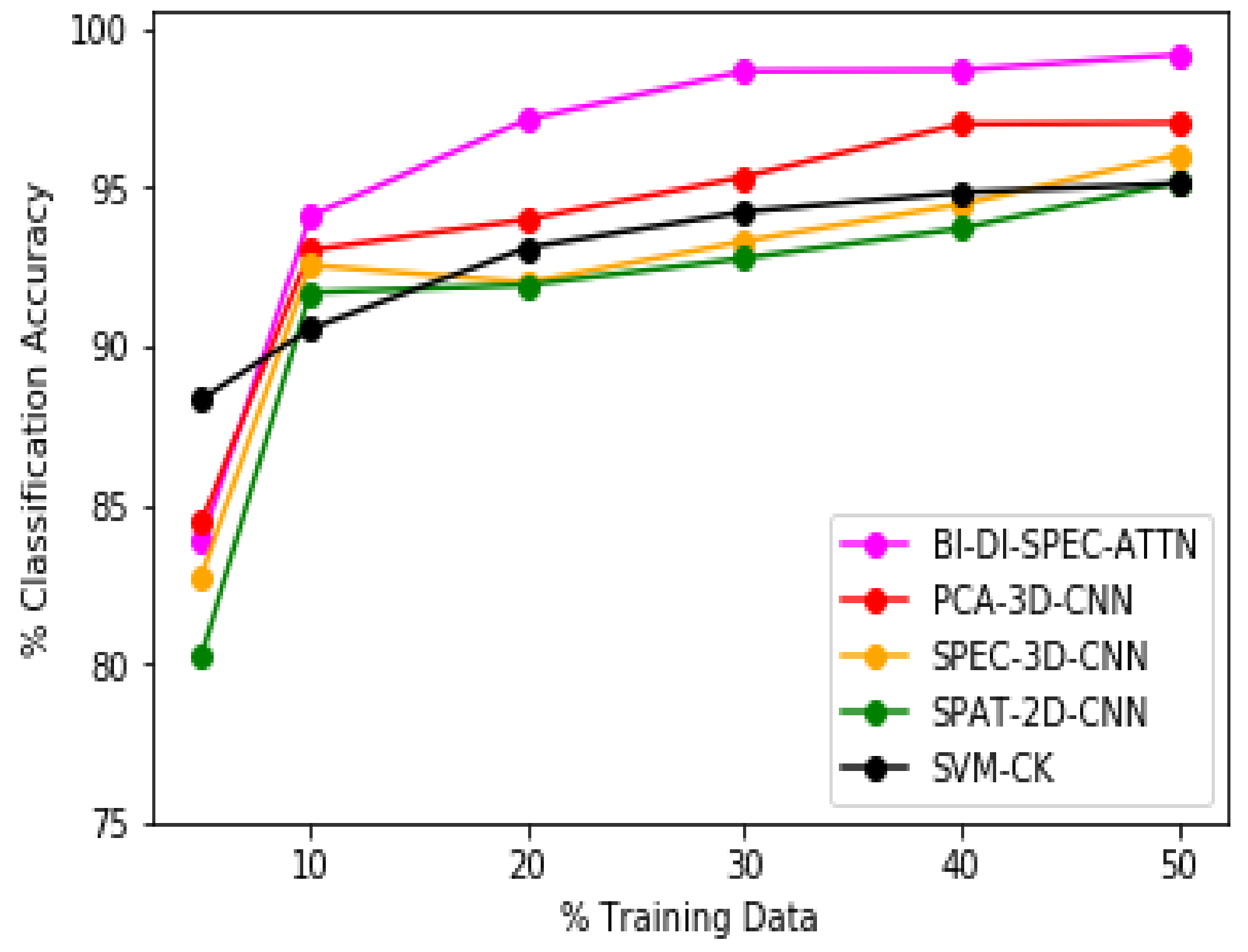
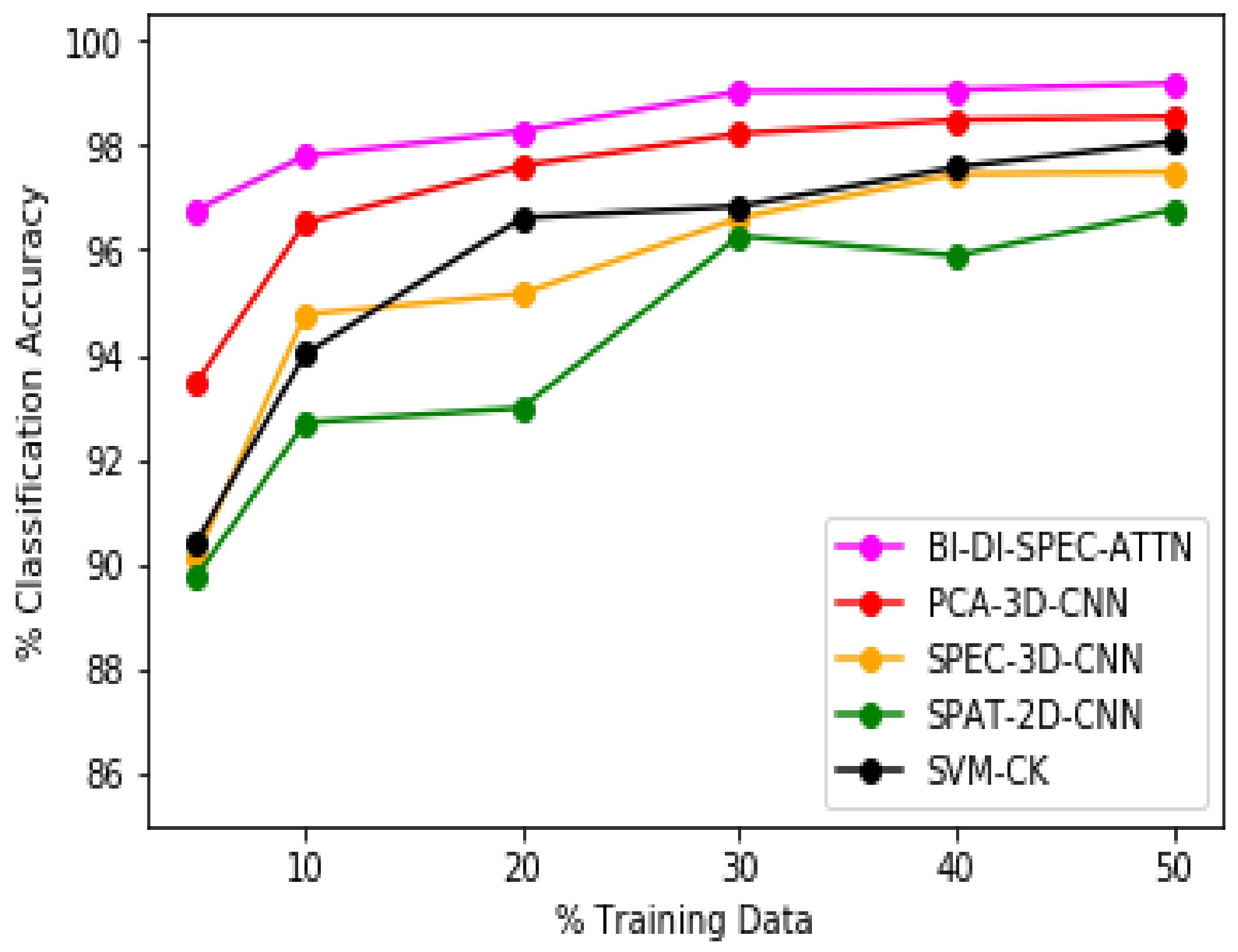
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Weng, Q. (Ed.) Advances in Environmental Remote Sensing: Sensors, Algorithms, and Applications; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar]
- Gao, Q.; Lim, S.; Jia, X. Hyperspectral Image Classification using Convolutional Neural Networks and Multiple Feature Learning. Remote Sens. 2018, 10, 299. [Google Scholar]
- Praveen, B.; Menon, V. Novel deep-learning-based spatial-spectral feature extraction for hyperspectral remote sensing applications. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 5444–5452. [Google Scholar]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Deep recurrent neural networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3639–3655. [Google Scholar]
- Praveen, B.; Menon, V. A Study of Spatial-Spectral Feature Extraction frameworks with 3D Convolutional Neural Network for Robust Hyperspectral Imagery Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 1717–1727. [Google Scholar]
- Foster, K.; Menon, V. A Study of Spatial-Spectral Information Fusion Methods in the Artificial Neural Network Paradigm for Hyperspectral Data Analysis in Swarm Robotics Applications. In Proceedings of the 2019 SoutheastCon, Huntsville, AL, USA, 11–14 April 2019; pp. 1–8. [Google Scholar]
- Huo, H.; Guo, J.; Li, Z.L. Hyperspectral image classification for land cover based on an improved interval type-II fuzzy C-means approach. Sensors 2018, 18, 363. [Google Scholar]
- Chen, Z.; Jiang, J.; Jiang, X.; Fang, X.; Cai, Z. Spectral-spatial feature extraction of hyperspectral images based on propagation filter. Sensors 2018, 18, 1978. [Google Scholar]
- Bui, Q.T.; Nguyen, Q.H.; Pham, V.M.; Pham, V.D.; Tran, M.H.; Tran, T.T.; Nguyen, H.D.; Nguyen, X.L.; Pham, H.M. A novel method for multispectral image classification by using social spider optimization algorithm integrated to fuzzy C-mean clustering. Can. J. Remote Sens. 2019, 45, 42–53. [Google Scholar]
- Hsu, P.H.; Tseng, Y.H.; Gong, P. Spectral feature extraction of hyperspectral images using wavelet transform. ISPRS J. Photogramm. Remote Sens. 2006, 11, 93–109. [Google Scholar]
- Sun, H.; Ren, J.; Zhao, H.; Sun, G.; Liao, W.; Fang, Z.; Zabalza, J. Adaptive distance-based band hierarchy (ADBH) for effective hyperspectral band selection. IEEE Trans. Cybern. 2020, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Huang, K.; Li, S.; Kang, X.; Fang, L. Spectral–spatial hyperspectral image classification based on KNN. Sens. Imaging 2016, 17, 1. [Google Scholar]
- Peng, J.; Li, L.; Tang, Y.Y. Maximum likelihood estimation-based joint sparse representation for the classification of hyperspectral remote sensing images. IEEE Trans. Neural Netwo. Learn. Syst. 2018, 30, 1790–1802. [Google Scholar]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Semisupervised hyperspectral image segmentation using multinomial logistic regression with active learning. IEEE Trans. Geosci. Remote Sens. 2010, 48, 4085–4098. [Google Scholar]
- Ham, J.; Chen, Y.; Crawford, M.M.; Ghosh, J. Investigation of the random forest framework for classification of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 492–501. [Google Scholar]
- Li, L.; Wang, C.; Li, W.; Chen, J. Hyperspectral image classification by AdaBoost weighted composite kernel extreme learning machines. Neurocomputing 2018, 275, 1725–1733. [Google Scholar]
- Köppen, M. The curse of dimensionality. In Proceedings of the 5th Online World Conference on Soft Computing in Industrial Applications, Online, 4–18 September 2000; Volume 1, pp. 4–8. [Google Scholar]
- Khodr, J.; Younes, R. Dimensionality reduction on hyperspectral images: A comparative review based on artificial datas. In Proceedings of the 2011 4th International Congress on Image and Signal Processing, Shanghai, China, 15–17 October 2011; Volume 4, pp. 1875–1883. [Google Scholar]
- Jolliffe, I.T. Principal Component Analysis; Springer: New York, NY, USA, 1986; pp. 129–155. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; John Wiley and Sons: New York, NY, USA, 2001; pp. 517–598. [Google Scholar]
- Menon, V.; Du, Q.; Christopher, S. Improved Random Projection with K-Means Clustering for Hyperspectral Image Classification. In Proceedings of the 2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4768–4771. [Google Scholar]
- Menon, V.; Prasad, S.; Fowler, J.E. Hyperspectral classification using a composite kernel driven by nearest-neighbor spatial features. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 2100–2104. [Google Scholar]
- Li, J.; Marpu, P.R.; Plaza, A.; Bioucas-Dias, J.M.; Benediktsson, J.A. Generalized composite kernel framework for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2013, 51, 4816–4829. [Google Scholar]
- Valero, O.; Salembier, P.; Chanussot, J. Object recognition in urban hyperspectral images using Binary PartitionTree representation. In Proceedings of the IEEE International Geoscience and RemoteSensing Symposium—IGARSS, Melbourne, Australia, 21–26 July 2013; pp. 4098–4101. [Google Scholar]
- Li, R.; Zheng, S.; Duan, C.; Yang, Y.; Wang, X. Classification of Hyperspectral Image Based on Double-Branch Dual-Attention Mechanism Network. Remote Sens. 2020, 12, 582. [Google Scholar]
- Mou, L.; Zhu, X.X. Learning to Pay Attention on Spectral Domain: A Spectral Attention Module-Based Convolutional Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 110–122. [Google Scholar]
- Gao, L.R.; Zhang, B.; Zhang, X.; Zhang, W.J.; Tong, Q.X. A new operational method for estimating noise in hyperspectral images. IEEE Geosci. Remote Sens. Lett. 2008, 5, 83–87. [Google Scholar]
- Uddin, M.P.; Mamun, M.A.; Hossain, M.A. Feature extraction for hyperspectral image classification. In Proceedings of the IEEE Region 10 Humanitarian Technology Conference, Dhaka, Bangladesh, 21–23 December 2017; pp. 379–382. [Google Scholar]
- Ardakani, A.; Condo, C.; Ahmadi, M.; Gross, W.J. An architecture to accelerate convolution in deep neural networks. IEEE Trans. Circuits Syst. I Regul. Pap. 2017, 65, 1349–1362. [Google Scholar]
- Graves, A.; Fernández, S.; Schmidhuber, J. Bidirectional LSTM networks for improved phoneme classification and recognition. In Proceedings of the International Conference on Artificial Neural Networks, Palma de Mallorca, Spain, 10–12 June 2005; pp. 799–804. [Google Scholar]
- Fine, T.L. Feedforward Neural Network Methodology; Springer Science and Business Media: Berlin, Germany, 2006. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar]
- Gamba, P. A collection of data for urban area characterization. In Proceedings of the IEEE International Geo-science and Remote Sensing Symposium, Anchorage, AK, USA, 20–24 September 2004. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Class Name | # of Training Samples | # of Testing Samples |
|---|---|---|---|
| 1 | Brocoli-green-weeds-1 | 200 | 1809 |
| 2 | Brocoli-green-weeds-2 | 372 | 3354 |
| 3 | Fallow | 198 | 1778 |
| 4 | Fallow-rough-plow | 140 | 1254 |
| 5 | Fallow-smooth | 268 | 2410 |
| 6 | Stubble | 396 | 3563 |
| 7 | Celery | 358 | 3221 |
| 8 | Grapes-untrained | 1128 | 10,143 |
| 9 | Soil-vinyard-develop | 620 | 5583 |
| 10 | Corn-senesced-green-weeds | 328 | 2950 |
| 11 | Lettuce-romaine-4wk | 106 | 962 |
| 12 | Lettuce-romaine-5wk | 192 | 1735 |
| 13 | Lettuce-romaine-6wk | 92 | 824 |
| 14 | Lettuce-romaine-7wk | 108 | 962 |
| 15 | Vinyard-untrained | 726 | 6542 |
| 16 | Vinyard-vertical-trellis | 180 | 1627 |
| Total | 5412 | 48,717 |
| # | Class Name | # of Training Samples | # of Testing Samples |
|---|---|---|---|
| 1 | Alfalfa | 5 | 41 |
| 2 | Corn-notill | 140 | 1288 |
| 3 | Corn-mintill | 81 | 749 |
| 4 | Corn | 24 | 213 |
| 5 | Grass-pasture | 48 | 435 |
| 6 | Grass-trees | 72 | 658 |
| 7 | Grass-pasture-mowed | 3 | 25 |
| 8 | Hay-Windrowed | 47 | 431 |
| 9 | Oats | 2 | 18 |
| 10 | Soybean-notill | 95 | 877 |
| 11 | Soybean-mintill | 232 | 2223 |
| 12 | Soybean-clean | 58 | 535 |
| 13 | Wheat | 21 | 184 |
| 14 | Woods | 124 | 1141 |
| 15 | Buildings-Grass-Trees-Drives | 38 | 348 |
| 16 | Stone-Steel-Towers | 10 | 83 |
| Total | 1000 | 9249 |
| # | Class Name | # of Training Samples | # of Testing Samples |
|---|---|---|---|
| 1 | Asphalt | 663 | 5968 |
| 2 | Meadows | 1865 | 16,784 |
| 3 | Gravel | 210 | 1889 |
| 4 | Trees | 306 | 2758 |
| 5 | Painted Metal Sheets | 134 | 1211 |
| 6 | Bare Soil | 503 | 4526 |
| 7 | Bitumen | 133 | 1197 |
| 8 | Self-Blocking Bricks | 368 | 3314 |
| 9 | Shadows | 95 | 852 |
| Total | 4277 | 38,499 |
| # | Class Name | BI-DI-SPEC-ATTN | PCA-3D-CNN | SPEC-3D-CNN | SPAT-2D-CNN | SVM-CK |
|---|---|---|---|---|---|---|
| 1 | Alfalfa | 86.1 | 54.9 | 98.8 | 83.8 | 92.6 |
| 2 | Corn-notill | 94.2 | 93.6 | 93.2 | 81.7 | 92.4 |
| 3 | Corn-mintill | 83.3 | 93.0 | 85.6 | 79.3 | 92.5 |
| 4 | Corn | 92.1 | 82.8 | 86.9 | 78.4 | 91.0 |
| 5 | Grass-pasture | 94.3 | 92.7 | 93.7 | 95.8 | 92.3 |
| 6 | Grass-trees | 97.8 | 99.5 | 96.1 | 97.7 | 83.1 |
| 7 | Grass-pasture-mowed | 57.8 | 79.1 | 95.8 | 88.9 | 95.4 |
| 8 | Hay-Windrowed | 99.4 | 95.2 | 94.3 | 97.5 | 90.0 |
| 9 | Oats | 68.3 | 75.9 | 72.2 | 53.6 | 89.1 |
| 10 | Soybean-notill | 95.8 | 93.9 | 92.0 | 82.4 | 92.4 |
| 11 | Soybean-mintill | 92.1 | 96.8 | 93.2 | 84.8 | 94.3 |
| 12 | Soybean-clean | 95.6 | 89.2 | 95.8 | 95.7 | 87.5 |
| 13 | Wheat | 98.4 | 98.1 | 94.1 | 95.6 | 96.0 |
| 14 | Woods | 97.8 | 95.7 | 94.8 | 86.1 | 92.2 |
| 15 | Buildings-Grass-Trees-Drives | 98.3 | 93.2 | 92.0 | 82.4 | 93.7 |
| 16 | Stone-Steel-Towers | 93.6 | 92.7 | 88.4 | 95.6 | 93.9 |
| OA (%) | 94.07 | 93.01 | 92.12 | 91.67 | 90.53 | |
| (%) | 94.03 | 92.87 | 91.54 | 90.88 | 90.17 |
| # | Class Name | BI-DI-SPEC-ATTN | PCA-3D-CNN | SPEC-3D-CNN | SPAT-2D-CNN | SVM-CK |
|---|---|---|---|---|---|---|
| 1 | Asphalt | 98.0 | 96.1 | 93.1 | 90.2 | 93.6 |
| 2 | Meadows | 98.9 | 97.8 | 97.0 | 88.1 | 96.4 |
| 3 | Gravel | 94.8 | 89.3 | 80.2 | 77.3 | 88.9 |
| 4 | Trees | 97.7 | 95.1 | 96.5 | 94.7 | 92.7 |
| 5 | Painted Metal Sheets | 99.0 | 97.8 | 98.2 | 88.9 | 98.3 |
| 6 | Bare Soil | 98.7 | 97.5 | 91.8 | 95.3 | 97.4 |
| 7 | Bitumen | 95.5 | 96.4 | 90.5 | 91.5 | 96.1 |
| 8 | Self-Blocking Bricks | 94.4 | 92.4 | 83.5 | 90.6 | 91.4 |
| 9 | Shadows | 95.8 | 94.2 | 97.8 | 94.9 | 95.3 |
| OA (%) | 97.80 | 96.52 | 94.77 | 92.70 | 93.01 | |
| (%) | 96.55 | 95.71 | 93.66 | 91.49 | 92.88 |
| # | Class Name | BI-DI-SPEC-ATTN | PCA-3D-CNN | SPEC-3D-CNN | SPAT-2D-CNN | SVM-CK |
|---|---|---|---|---|---|---|
| 1 | Brocoli-green-weeds-1 | 89.4 | 60.9 | 96.3 | 82.9 | 95.6 |
| 2 | Brocoli-green-weeds-2 | 97.5 | 96.9 | 92.1 | 82.1 | 94.3 |
| 3 | Fallow | 86.6 | 96.3 | 83.4 | 80.1 | 94.7 |
| 4 | Fallow-rough-plow | 95.4 | 85.0 | 84.6 | 79.5 | 95.2 |
| 5 | Fallow-smooth | 97.6 | 95.1 | 91.5 | 93.6 | 93.5 |
| 6 | Stubble | 99.1 | 99.8 | 94.7 | 95.1 | 86.8 |
| 7 | Celery | 60.2 | 83.4 | 93.6 | 85.7 | 96.5 |
| 8 | Grapes-untrained | 99.9 | 98.5 | 92.1 | 98.2 | 93.9 |
| 9 | Soil-vinyard-develop | 69.9 | 78.2 | 70.1 | 58.9 | 92.6 |
| 10 | Corn-senesced-green-weeds | 96.4 | 96.1 | 90.8 | 81.1 | 92.8 |
| 11 | Lettuce-romaine-4wk | 96.6 | 99.9 | 91.4 | 83.9 | 95.7 |
| 12 | Lettuce-romaine-5wk | 98.9 | 92.7 | 93.5 | 94.6 | 90.3 |
| 13 | Lettuce-romaine-6wk | 99.7 | 98.8 | 92.7 | 95.0 | 98.4 |
| 14 | Lettuce-romaine-7wk | 99.1 | 98.3 | 92.5 | 85.5 | 95.8 |
| 15 | Vinyard-untrained | 99.9 | 96.3 | 90.0 | 84.7 | 96.8 |
| 16 | Vinyard-vertical-trellis | 96.3 | 95.6 | 86.4 | 96.2 | 91.9 |
| OA (%) | 97.78 | 96.08 | 91.16 | 91.45 | 94.01 | |
| (%) | 96.92 | 95.66 | 91.02 | 90.97 | 93.75 |
| Dataset (10% Training) | BI-DI-SPEC-ATTN | PCA-3D-CNN | SPEC-3D-CNN | SPAT-2D-CNN | SVM-CK |
|---|---|---|---|---|---|
| Time: 28.64 | Time: 7.51 | Time: 12.47 | Time: 6.19 | Time: 22.76 | |
| Salinas | # of Parameters: 179,118 | # of Parameters: 120,272 | # of Parameters: 135,340 | # of Parameters: 115,388 | |
| Epochs: 100 | Epochs: 80 | Epochs: 80 | Epochs: 80 | ||
| Time: 36.20 | Time: 5.27 | Time: 10.39 | Time: 6.55 | Time: 21.54 | |
| Pavia University | # of Parameters: 96,841 | # of Parameters: 80,569 | # of Parameters: 100,264 | # of Parameters: 89,128 | |
| Epochs: 120 | Epochs: 80 | Epochs: 80 | Epochs: 80 | ||
| Time: 15.94 | Time: 9.63 | Time: 14.98 | Time: 7.21 | Time: 27.11 | |
| Indian Pines | # of Parameters: 179,118 | # of Parameters: 120,272 | # of Parameters: 135,340 | # of Parameters: 115,388 | |
| Epochs: 100 | Epochs: 80 | Epochs: 80 | Epochs: 80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Praveen, B.; Menon, V. A Bidirectional Deep-Learning-Based Spectral Attention Mechanism for Hyperspectral Data Classification. Remote Sens. 2022, 14, 217. https://doi.org/10.3390/rs14010217
Praveen B, Menon V. A Bidirectional Deep-Learning-Based Spectral Attention Mechanism for Hyperspectral Data Classification. Remote Sensing. 2022; 14(1):217. https://doi.org/10.3390/rs14010217
Chicago/Turabian StylePraveen, Bishwas, and Vineetha Menon. 2022. "A Bidirectional Deep-Learning-Based Spectral Attention Mechanism for Hyperspectral Data Classification" Remote Sensing 14, no. 1: 217. https://doi.org/10.3390/rs14010217
APA StylePraveen, B., & Menon, V. (2022). A Bidirectional Deep-Learning-Based Spectral Attention Mechanism for Hyperspectral Data Classification. Remote Sensing, 14(1), 217. https://doi.org/10.3390/rs14010217