
Pair-Wise Similarity Knowledge Distillation for RSI Scene Classification




Abstract
:
1. Introduction
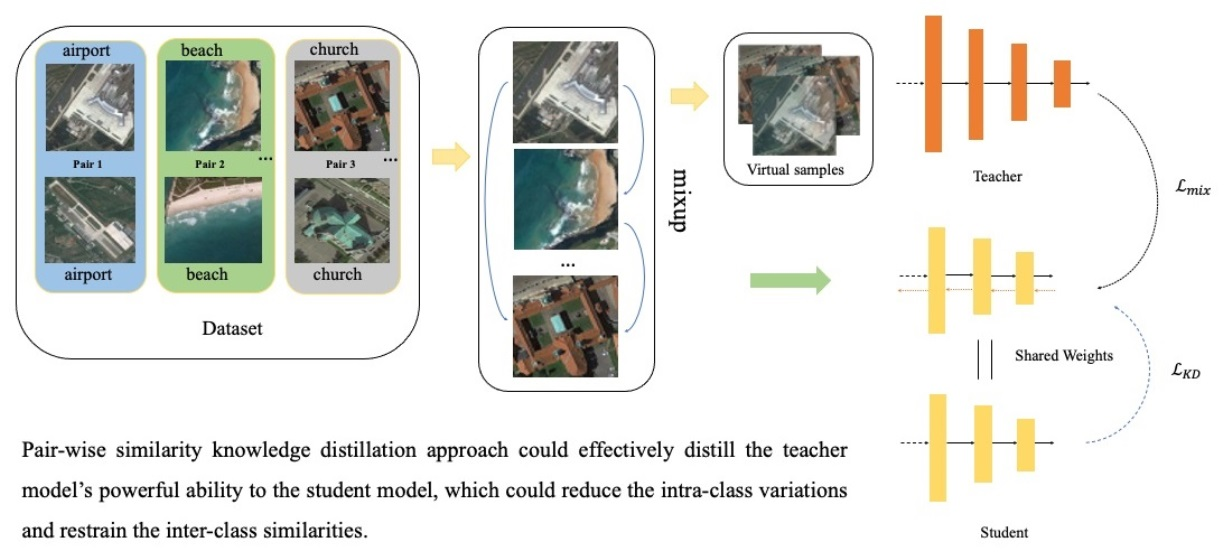
- We introduce a pair-wise similarity knowledge distillation approach to obtain a lightweight model with high performance for RSI scene classification. It could effectively distill the teacher model’s powerful ability to the student model, which could reduce the intra-class variations and restrain the inter-class similarities;
- We employ the sample pairs and virtual samples as the training data. We reduce the intra-class variations and restrain the inter-class similarities by forcing similar incorrect outputs and matching the outputs, causing the student model to well absorb the discriminative knowledge from the teacher model;
- We verify the proposed pair-wise similarity knowledge distillation framework on AID, UCMerced and NWPU-RESISC datasets. The experimental results show that the proposed approach can significantly improve the lightweight model’s performance in terms of RSI scene classification.
2. Related Work
2.1. Remote Sensing Image Scene Classification
2.2. Knowledge Distillation
3. Materials and Methods
3.1. The Standard Teacher–Student Distillation
3.2. Pair-Wise Similarity Knowledge Distillation
3.3. Training Procedure
| Algorithm 1 Pair-wise Similarity Knowledge Distillation |
| Input: Teacher network T, Student network S with the parameters , is a fixed copy of parameters , training samples . |
| Output: parameters . |
| Initialize:T, S and the hyper-parameters. |
Stage 1: Train the teacher model.
|
Stage 2: Distilling the student via pair-wise similarity KD.
|
4. Results
4.1. Datasets
- NWPU-RESISC45. The NWPU-RESISC45 dataset is currently the largest RSI scene classification dataset. It has 31,500 samples chosen from more than 100 countries and regions. It contains 45 scene categories and each category has 700 samples with a size of pixels in the RGB space. Each pixel has a spatial resolution ranging from 300 to 20 cm/pixel. It is a challenging dataset due to the large inter-class similarities.
- AID. The aerial image dataset (AID) comprises 10,000 images with 30 categories of scene samples. Each category consists of approximately 200 to 400 images with a size of pixels in RGB space. Each pixel has a spatial resolution ranging from 800 to 50 cm/pixel.
- UC Merced Land-Use. The UC Merced Land-Use dataset has 2100 images and consists of 21 scene categories. Each category has 100 images with a size of pixels. Each pixel has a spatial solution of 30 cm in the RGB color space.
4.2. Experimental Settings
- Network architecture. In the following experiments, we employ the ResNet [42] as our base architecture for the teacher and student networks. The ResNet series model achieves the state-of-the-art performance by stacking the basic residual blocks. We employ ResNet-101 as the teacher network and ResNet-34 as the student network. Note that, the residual block is two layers deep in ResNet-34 and three layers deep in ResNet-101. The residual block could greatly increase the depth and easily gain accuracy in remote sensing image scene classification. For the NWPU-RESISC45 dataset, we employ the ResNet-101 as the teacher network and the ResNet as the student network. For the other two datasets, we adopt the ResNet-34/ResNet-18 as the teacher/student model pair.
- Implementation details. We first conduct experiments on the NWPU-RESISC45 dataset, which has RGB images. For the training phase, we adopt data augmentations such as horizontal flips and random crops. The original testing data are used for the testing phase. Due to the high number of scene images in the NWPU-RESISC45 dataset, we employ ResNet-101 and ResNet-34 as the teacher model and student model, respectively. We set the mini-batch as 32. We set the training epochs as 200 and initial learning rate as 0.1, which is reduced by a factor of 0.1 on epoch 60, 120, and 160, respectively. We adopt the stochastic gradient descent (SGD) with momentum 0.9. We set the hyper-parameter as follows: , , .
5. Discussion
- Evaluation Criteria. Overall accuracy (OA) aims to evaluate the performance of the classifiers on the testing dataset. It is formulated as the number of correctly classified images divided by the whole number of testing images. OA is the most used criterion for measuring the effectivity of the methods for RSI scene classification. Thus, we also use the OA as our evaluation criteria for all experiments. In addition, we also adopt the confusion matrix table in the ablation study to show the detailed classification results, which visualizes the accuracy of each class.
- Performance Comparison. We verify the effectiveness of our proposed pair-wise similarity knowledge distillation approach on three RSI scene classification datasets. For the baselines, we employ several popular state-of-the-art methods for knowledge distillation. To be specific, we compare our pair-wise similarity KD method with knowledge distillation (KD) [8], attention transfer (AT) [33], similarity-preserving (SP) [36], and relational knowledge distillation (RKD) [35] for all RSI scene classification datasets.
- The training curves and confusion matrix. We present the student model’s testing accuracy using different methods. It is trained on the NWPU-RESISC45 dataset with an 80% training ratio. As can be seen from Figure 4, we observe that our method (purple line) achieves a significant improvement compared with the student model, trained individually (blue line). Moreover, the proposed approach outperforms the traditional distillation loss (yellow line), as shown in Figure 4.
Ablation Study
- Visualization. To demonstrate the effectiveness of the proposed method, we further visualize the features extracted from our method using the t-SNE algorithm [44]. We employ the t-SNE algorithm to embed high-dimensional features into two-dimensional space. It is convenient for us to measure the superiority of our approach by inspecting the derived clusters from the outputs of t-SNE.
- Trade-off between compression ratio and accuracy. We present the FLOPs and Params of the model in Table 3. We find that the proposed approach not only obtains a 0.279% improvement compared with the teacher model, but also achieves a ×2.03 compression rate. Thus, we obtain an efficient and compact student model for RSI scene classification.
- Multiple model series for comparison.Table 4 summarizes the teacher and student networks’ configuration. In addition to the ResNet series models, we use multiple models for comparison to further illustrate the generalization ability of the method. For the NWPU-RESISC45 dataset, we employ the Wide Residual Network (WRN) as the network architecture. Furthermore, WRN-40-1/WRN-16-1 is used for the teacher/student combination. For the UC Merced Land-Use dataset, we employ the VGG as the network architecture. VGG-13/VGG-8 is used for the teacher/student combination. As can be seen from Table 5, the proposed approach achieves 96.05% and 94.86% performances on these two datasets, respectively. It can also verify the generalization ability of the method.
- Impact of hyper-parameters on the training.Table 6 illustrates the impact of hyper-parameters , , and on the training process. We conduct the experiments on the NWPU-RESISC45 dataset. We employ ResNet-101 as the teacher network and ResNet-34 as the student network. The default values of , , and are 0.1, 1, and 0.8, respectively. In case of , the other two hyper-parameters maintain their default values. We observed that the large value of causes the overall accuracy to deteriorate rapidly. Overall, the OA is insensitive when the hyper-parameters change within an appropriate range.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ghazouani, F.; Farah, I.R.; Solaiman, B. A Multi-Level Semantic Scene Interpretation Strategy for Change Interpretation in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8775–8795. [Google Scholar] [CrossRef]
- Longbotham, N.; Chaapel, C.; Bleiler, L.; Padwick, C.; Emery, W.J.; Pacifici, F. Very High Resolution Multiangle Urban Classification Analysis. IEEE Trans. Geosci. Remote Sens. 2012, 50, 1155–1170. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When Deep Learning Meets Metric Learning: Remote Sensing Image Scene Classification via Learning Discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L. Scene Classification via a Gradient Boosting Random Convolutional Network Framework. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1793–1802. [Google Scholar] [CrossRef]
- Minetto, R.; Pamplona Segundo, M.; Sarkar, S. Hydra: An Ensemble of Convolutional Neural Networks for Geospatial Land Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6530–6541. [Google Scholar] [CrossRef] [Green Version]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning both Weights and Connections for Efficient Neural Network. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 1135–1143. [Google Scholar]
- Novikov, A.; Podoprikhin, D.; Osokin, A.; Vetrov, D.P. Tensorizing Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 442–450. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. Comput. Sci. 2015, 14, 38–39. [Google Scholar]
- Buciluǎ, C.; Caruana, R.; Niculescu-Mizil, A. Model Compression. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 535–541. [Google Scholar]
- Lei, J.B.; Caruana, R. Do Deep Nets Really Need to be Deep? Adv. Neural Inf. Process. Syst. 2013, 27, 2654–2662. [Google Scholar]
- Tian, L.; Wang, Z.; He, B.; He, C.; Wang, D.; Li, D. Knowledge Distillation of Grassmann Manifold Network for Remote Sensing Scene Classification. Remote Sens. 2021, 13, 4537. [Google Scholar] [CrossRef]
- Zhang, R.; Chen, Z.; Zhang, S.; Song, F.; Zhang, G.; Zhou, Q.; Lei, T. Remote Sensing Image Scene Classification with Noisy Label Distillation. Remote Sens. 2020, 12, 2376. [Google Scholar] [CrossRef]
- Liu, B.Y.; Chen, H.X.; Huang, Z.; Liu, X.; Yang, Y.Z. ZoomInNet: A Novel Small Object Detector in Drone Images with Cross-Scale Knowledge Distillation. Remote Sens. 2021, 13, 1198. [Google Scholar] [CrossRef]
- Chai, Y.; Fu, K.; Sun, X.; Diao, W.; Yan, Z.; Feng, Y.; Wang, L. Compact Cloud Detection with Bidirectional Self-Attention Knowledge Distillation. Remote Sens. 2020, 12, 2770. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the Sigspatial International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; p. 270. [Google Scholar]
- Zhu, Q.; Zhong, Y.; Zhao, B.; Xia, G.S.; Zhang, L. Bag-of-Visual-Words Scene Classifier with Local and Global Features for High Spatial Resolution Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 747–751. [Google Scholar] [CrossRef]
- Zhao, L.J.; Tang, P.; Huo, L.Z. Land-Use Scene Classification Using a Concentric Circle-Structured Multiscale Bag-of-Visual-Words Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4620–4631. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L. Saliency-guided unsupervised feature learning for scene classification. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2175–2184. [Google Scholar] [CrossRef]
- Lu, X.; Zheng, X.; Yuan, Y. Remote sensing scene classification by unsupervised representation learning. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5148–5157. [Google Scholar] [CrossRef]
- Fan, J.; Chen, T.; Lu, S. Unsupervised feature learning for land-use scene recognition. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2250–2261. [Google Scholar] [CrossRef]
- Romero, A.; Gatta, C.; Camps-Valls, G. Unsupervised deep feature extraction for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2015, 54, 1349–1362. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1155–1167. [Google Scholar] [CrossRef]
- Hua, Y.; Mou, L.; Zhu, X.X. Relation Network for Multilabel Aerial Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4558–4572. [Google Scholar] [CrossRef] [Green Version]
- Chen, G.; Zhang, X.; Tan, X.; Cheng, Y.; Dai, F.; Zhu, K.; Gong, Y.; Wang, Q. Training Small Networks for Scene Classification of Remote Sensing Images via Knowledge Distillation. Remote Sens. 2018, 10, 719. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Shen, X.; Xing, J.; Tian, X.; Li, H.; Deng, B.; Huang, J.; Hua, X. Quantization Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 7308–7316. [Google Scholar]
- Ba, J.; Caruana, R. Do Deep Nets Really Need to be Deep? In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 2654–2662. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Bengio, Y. FitNets: Hints for Thin Deep Nets. In Proceedings of the 3rd International Conference on Learning Representations, ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer. In Proceedings of the 5th International Conference on Learning Representations, ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Zhang, H.; Hu, Z.; Qin, W.; Xu, M.; Wang, M. Adversarial co-distillation learning for image recognition. Pattern Recognit. 2021, 111, 107659. [Google Scholar] [CrossRef]
- Park, W.; Kim, D.; Lu, Y.; Cho, M. Relational knowledge distillation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3967–3976. [Google Scholar]
- Tung, F.; Mori, G. Similarity-preserving knowledge distillation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1365–1374. [Google Scholar]
- Peng, B.; Jin, X.; Li, D.; Zhou, S.; Wu, Y.; Liu, J.; Zhang, Z.; Liu, Y. Correlation Congruence for Knowledge Distillation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea, 27 October–2 November 2019; pp. 5006–5015. [Google Scholar]
- Zhao, H.; Sun, X.; Dong, J.; Dong, Z.; Li, Q. Knowledge distillation via instance-level sequence learning. Knowl. Based Syst. 2021, 233, 107519. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A Benchmark Data Set for Performance Evaluation of Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep Learning Based Feature Selection for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chen, L.; Wang, D.; Gan, Z.; Liu, J.; Henao, R.; Carin, L. Wasserstein Contrastive Representation Distillation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; pp. 16296–16305. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Resolution | Size | Categories | Entire Dataset | Train Subset | Test Images |
|---|---|---|---|---|---|---|
| NWPU-RESISC45 | 0.2–3 m | 256 × 256 | 45 | 31,500 | 25,200 | 6300 |
| AID | 0.5–8 m | 600 × 600 | 30 | 10,000 | 8000 | 2000 |
| UC Merced Land-Use | 0.3 m | 256 × 256 | 21 | 2100 | 1680 | 420 |
| Dataset | Training Ratio | Baselines | KD [8] | AT [33] | SP [36] | RKD [35] | WRD [43] | Ours | Teacher |
|---|---|---|---|---|---|---|---|---|---|
| NWPU-RESISC45 | 70% | 93.619 | 94.604 | 94.127 | 94.794 | 94.801 | 94.813 | 95.069 | 94.772 |
| 80% | 94.021 | 94.576 | 94.924 | 95.313 | 95.297 | 95.301 | 95.673 | 95.394 | |
| AID | 50% | 91.100 | 91.208 | 91.302 | 91.381 | 91.394 | 91.328 | 91.571 | 91.360 |
| 80% | 94.350 | 94.401 | 94.483 | 94.494 | 94.572 | 94.032 | 94.850 | 94.550 | |
| UC Merced Land-Use | 50% | 90.195 | 90.328 | 90.496 | 90.805 | 90.890 | 90.916 | 91.237 | 91.062 |
| 80% | 93.095 | 93.409 | 93.380 | 94.076 | 94.340 | 94.091 | 94.903 | 94.524 |
| Method | Model | FLOPs | Params | NWPU-RESISC45 |
|---|---|---|---|---|
| Student | ResNet-34 | 36.64 | 2.18 | 94.021 ± 0.27 |
| KD | ResNet-34 | 36.64 | 2.18 | 94.576 ± 0.32 |
| AT | ResNet-34 | 36.64 | 2.18 | 94.024 ± 0.16 |
| SP | ResNet-34 | 36.64 | 2.18 | 95.313 ± 0.22 |
| RKD | ResNet-34 | 36.64 | 2.18 | 95.297 ± 0.66 |
| Ours | ResNet-34 | 36.64 | 2.18 | 95.673 ± 0.28 |
| Teacher | Resnet-101 | 78.01 | 4.44 | 95.394 ± 0.21 |
| Layer Type | Output Size | ResNet-34 | ResNet-101 |
|---|---|---|---|
| Conv1 | , 64, stride 2 | , 64, stride 2 | |
| Conv2 | |||
| Conv3 | |||
| Conv4 | |||
| Conv5 | |||
| average pool, 1000-d fc, softmax | |||
| Dataset | Model (S/T) | Training Ratio | Baseline | KD [8] | AT [33] | SP [36] | RKD [35] | Ours | Teacher |
|---|---|---|---|---|---|---|---|---|---|
| NWPU-RESISC45 | WRN-16-1 WRN-40-1 | 80% | 94.41 | 94.81 | 94.97 | 94.91 | 95.03 | 96.05 | 95.67 |
| UC Merced Land-Use | VGG-8 VGG-13 | 80% | 93.58 | 93.84 | 93.93 | 94.05 | 93.98 | 94.86 | 94.45 |
| Hyper-parameter | |||||
| 0.01 | 0.05 | 0.1 | 0.2 | 0.3 | |
| Overall Accuracy (%) | 93.962 | 94.187 | 95.673 | 93.143 | 90.067 |
| Hyper-parameter | |||||
| 0.1 | 0.5 | 1 | 1.25 | 1.5 | |
| Overall Accuracy (%) | 91.087 | 93.269 | 95.673 | 93.641 | 92.013 |
| Hyper-parameter | |||||
| 0.1 | 0.5 | 0.8 | 1 | 1.5 | |
| Overall Accuracy (%) | 90.187 | 92.732 | 95.673 | 92.450 | 91.813 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, H.; Sun, X.; Gao, F.; Dong, J. Pair-Wise Similarity Knowledge Distillation for RSI Scene Classification. Remote Sens. 2022, 14, 2483. https://doi.org/10.3390/rs14102483
Zhao H, Sun X, Gao F, Dong J. Pair-Wise Similarity Knowledge Distillation for RSI Scene Classification. Remote Sensing. 2022; 14(10):2483. https://doi.org/10.3390/rs14102483
Chicago/Turabian StyleZhao, Haoran, Xin Sun, Feng Gao, and Junyu Dong. 2022. "Pair-Wise Similarity Knowledge Distillation for RSI Scene Classification" Remote Sensing 14, no. 10: 2483. https://doi.org/10.3390/rs14102483
APA StyleZhao, H., Sun, X., Gao, F., & Dong, J. (2022). Pair-Wise Similarity Knowledge Distillation for RSI Scene Classification. Remote Sensing, 14(10), 2483. https://doi.org/10.3390/rs14102483