
A Mask-Guided Transformer Network with Topic Token for Remote Sensing Image Captioning





Abstract
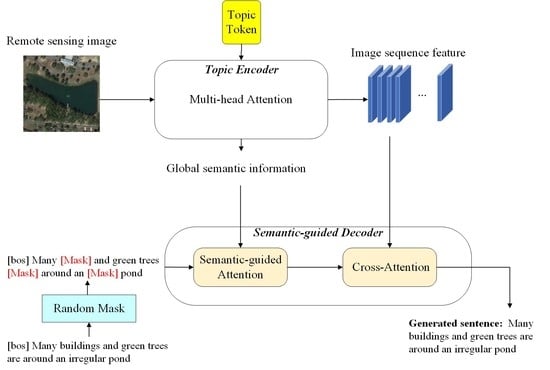
:
1. Introduction
- We propose a full Transformer network to improve the accuracy of generated captioning, which can better represent the remote sensing features of large-scale and crowded objects in contrast with the common CNN and LSTM framework;
- To better express the global semantic information in the image, a topic token is proposed, which can interact with the image features and can be directly used in the decoder to guide sentence generation;
- A new Mask–Cross-Entropy training strategy is proposed in order to reduce the model training time, and enables the generated descriptions to have high accuracy and diversity.
2. Related Work
2.1. Natural Image Captioning
2.2. Remote Sensing Image Captioning
2.3. Training Strategy and Improve Diversity
3. Method
3.1. Topic Encoder
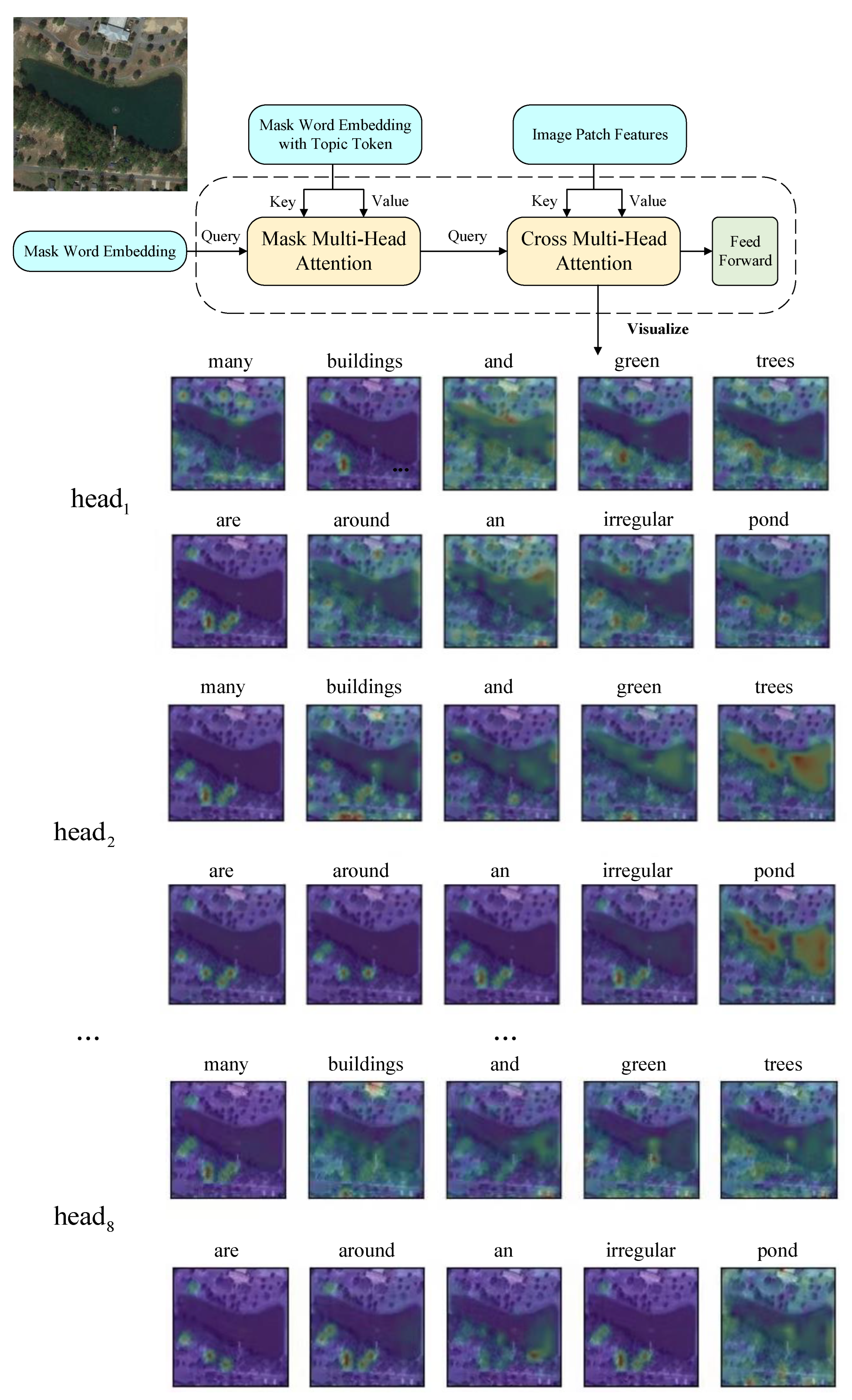
3.2. Semantic-Guided Decoder
3.3. Mask–Cross-Entropy Training Strategy
4. Experiments and Analysis
4.1. Data Set and Setting
4.1.1. Data Set
- (1)
- The Sydney data set [6] contains 613 images with a size of 500 × 500 pixels. The images are from Australia, obtained from Google Earth, and comprise seven categories.
- (2)
- (3)
- The RSICD data set [27] contains 10,921 images in 30 categories, where the size of each image is 224 × 224 pixels. Compared with other data sets, RSICD has a larger number of images and richer descriptions.Each image in these three data sets has five corresponding human-annotated descriptions.
4.1.2. Evaluation Metrics
4.1.3. Training Details
4.1.4. Compared Models
- (1)
- Soft attention and Hard attention [27]: The basic framework is VGG-16 + LSTM for both of these models. The soft attention gives weights to different image feature parts, according to the hidden state, while the hard attention samples different image parts and optimizes them by reinforcement learning.
- (2)
- (3)
- AttrAttention [53]: An attribute attention mechanism is proposed to obtain the high-level attributes from VGG-16, while the encoded features are a combination of image features and the attribute features.
- (4)
- MLA [30]: In MLA (Multi-level attention model), a multi-level attention mechanism is set to choose whether to apply the image or the sequence as the main information to generate the new word.
- (5)
- (6)
- VRTMM [31]: In VRTMM, image features are captured by a variational auto-encoder model. Furthermore, VRTMM replaces the LSTM with Transformer as the decoder, thus achieving better performance.
4.2. Experimental Results
4.3. Discussion and Analysis
4.4. Ablation Experiments
- To find the effect of the topic token, we removed it from the topic encoder and kept other configurations unchanged.
- The MLP layer was removed in order to evaluate the importance of this fine-tuning layer, and the parameters of topic encoder were set to be frozen at the same time.
- We trained the model using an ordinary strategy and compared it with the performance obtained when trained with Mask–Cross-Entropy.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional neural networks. |
| Faster-R-CNN | Faster region convolutional neural networks. |
| LSTM | Long- and short-term memory. |
| ResNet | Residual network. |
| VGG | Visual geometry group. |
| RSICD | Remote sensing image captioning data set. |
| CE | Cross-entropy. |
| SC | Self-critical. |
| Mask-CE | Mask–Cross-Entropy |
| NIC | Neural image caption. |
| AOA | Attention on attention. |
| UCM | UC Merced. |
| VRTMM | Variational autoencoder and reinforcement learning. |
| based two-stage multitask learning model. | |
| RASG | recurrent attention and semantic gate. |
| GAN | Generative adversarial network. |
| VAE | Variational auto encoder. |
| SLL-SLE | Sequence-level learning via sequence level exploration. |
| Vit | Vision Transformer. |
| Bert | Bidirectional rncoder representations from Transformers. |
| MLP | Multilayer perceptron. |
| MAE | Masked autoencoders. |
| BEIT | Bidirectional encoder representation from image Transformers. |
| BLEU | Biingual evaluation understudy. |
| Rouge-L | Recall-oriented understudy for gisting evaluation—Longest. |
| Meteor | Metric for Evaluation of translation with explicit ordering. |
| CIDEr | Consensus-based image description evaluation. |
| MLA | Multi-level attention model. |
| h | The height of the image. |
| w | The width of the image. |
| s | The height and width of the image patch. |
| N | The number of image patches. |
| Input of the topic encoder. | |
| T | The proposed topic token. |
| The position encoding. | |
| The image patch. | |
| The number of encoder layers. | |
| The number of decoder layers. | |
| MHA | The multi-head attention mechanism. |
| The query, key, and value vector of attention mechanism. | |
| W | Weight matrix. |
| d | The scale factor of attention mechanism. |
| The topic feature. | |
| The image feature. | |
| The output of topic encoder. | |
| AddNorm | Residual connection and layer normalization. |
| X | The output of the previous decoder. |
| MaskMHA | The mask multi-head attention mechanism. |
| L | The length of ground-truth sentence. |
| t | Current time step. |
| y | The ground-truth sentence. |
| The model parameter. | |
| The mask sentence. | |
| The probability of generating specific word. |
References
- Zhang, L.; Zhang, L.; Tao, D.; Huang, X.; Du, B. Hyperspectral remote sensing image subpixel target detection based on supervised metric learning. IEEE Trans. Geosci. Remote Sens. 2013, 52, 4955–4965. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, L. Multi-source remote sensing data classification via fully convolutional networks and post-classification processing. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 3852–3855. [Google Scholar]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Baumgartner, J.; Gimenez, J.; Scavuzzo, M.; Pucheta, J. A new approach to segmentation of multispectral remote sensing images based on mrf. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1720–1724. [Google Scholar] [CrossRef]
- Wang, Q.; Gao, J.; Li, X. Weakly supervised adversarial domain adaptation for semantic segmentation in urban scenes. IEEE Trans. Image Process. 2019, 28, 4376–4386. [Google Scholar] [CrossRef] [Green Version]
- Qu, B.; Li, X.; Tao, D.; Lu, X. Deep semantic understanding of high resolution remote sensing image. In Proceedings of the 2016 International Conference on Computer, Information and Telecommunication Systems (Cits), Istanbul, Turkey, 16–18 December 2016; pp. 1–5. [Google Scholar]
- Shi, Z.; Zou, Z. Can a machine generate humanlike language descriptions for a remote sensing image? IEEE Trans. Geosci. Remote Sens. 2017, 55, 3623–3634. [Google Scholar] [CrossRef]
- Lu, X.; Zheng, X.; Li, X. Latent semantic minimal hashing for image retrieval. IEEE Trans. Image Process. 2016, 26, 355–368. [Google Scholar] [CrossRef]
- Liu, Y.; Wu, L. Geological disaster recognition on optical remote sensing images using deep learning. Procedia Comput. Sci. 2016, 91, 566–575. [Google Scholar] [CrossRef] [Green Version]
- Ordonez, V.; Han, X.; Kuznetsova, P.; Kulkarni, G.; Mitchell, M.; Yamaguchi, K.; Stratos, K.; Goyal, A.; Dodge, J.; Mensch, A.; et al. Large scale retrieval and generation of image descriptions. Int. J. Comput. Vis. 2016, 119, 46–59. [Google Scholar] [CrossRef]
- Kuznetsova, P.; Ordonez, V.; Berg, A.; Berg, T.; Choi, Y. Collective generation of natural image descriptions. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, Jeju Island, Korea, 8–14 July 2012; Volume 1, pp. 359–368. [Google Scholar]
- Kulkarni, G.; Premraj, V.; Ordonez, V.; Dhar, S.; Li, S.; Choi, Y.; Berg, A.C.; Berg, T.L. Babytalk: Understanding and generating simple image descriptions. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2891–2903. [Google Scholar] [CrossRef] [Green Version]
- Gupta, A.; Mannem, P. From image annotation to image description. In Proceedings of the International Conference on Neural Information Processing, Doha, Qatar, 12–15 November 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 196–204. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advance in Neural Information Processing Systems (NIPS), Montreal, QC, USA, 7–12 December 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Rennie, S.J.; Marcheret, E.; Mroueh, Y.; Ross, J.; Goel, V. Self-critical sequence training for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7008–7024. [Google Scholar]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Ranzato, M.; Chopra, S.; Auli, M.; Zaremba, W. Sequence level training with recurrent neural networks. arXiv 2015, arXiv:1511.06732. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Huang, L.; Wang, W.; Chen, J.; Wei, X.Y. Attention on attention for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4634–4643. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Cucchiara, R. Meshed-memory transformer for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10578–10587. [Google Scholar]
- Herdade, S.; Kappeler, A.; Boakye, K.; Soares, J. Image captioning: Transforming objects into words. In Proceedings of the Conference on Neural Information Processing Systems (NIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Lu, X.; Wang, B.; Zheng, X.; Li, X. Exploring models and data for remote sensing image caption generation. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2183–2195. [Google Scholar] [CrossRef] [Green Version]
- Zhao, R.; Shi, Z.; Zou, Z. High-resolution remote sensing image captioning based on structured attention. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Huang, W.; Wang, Q.; Li, X. Denoising-based multiscale feature fusion for remote sensing image captioning. IEEE Geosci. Remote. Sens. Lett. 2020, 18, 436–440. [Google Scholar] [CrossRef]
- Li, Y.; Fang, S.; Jiao, L.; Liu, R.; Shang, R. A multi-level attention model for remote sensing image captions. Remote Sens. 2020, 12, 939. [Google Scholar] [CrossRef] [Green Version]
- Shen, X.; Liu, B.; Zhou, Y.; Zhao, J.; Liu, M. Remote sensing image captioning via Variational Autoencoder and Reinforcement Learning. Knowl.-Based Syst. 2020, 203, 105920. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Gu, J.; Li, C.; Wang, X.; Tang, X.; Jiao, L. Recurrent Attention and Semantic Gate for Remote Sensing Image Captioning. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Dai, B.; Fidler, S.; Urtasun, R.; Lin, D. Towards diverse and natural image descriptions via a conditional gan. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2970–2979. [Google Scholar]
- Wang, L.; Schwing, A.; Lazebnik, S. Diverse and accurate image description using a variational auto-encoder with an additive gaussian encoding space. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Conference on Neural Information Processing Systems (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Chen, J.; Jin, Q. Better captioning with sequence-level exploration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10890–10899. [Google Scholar]
- Wang, Q.; Chan, A.B. Describing like humans: On diversity in image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4195–4203. [Google Scholar]
- Shi, J.; Li, Y.; Wang, S. Partial Off-Policy Learning: Balance Accuracy and Diversity for Human-Oriented Image Captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 2187–2196. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Ramchoun, H.; Ghanou, Y.; Ettaouil, M.; Janati Idrissi, M.A. Multilayer perceptron: Architecture optimization and training. IJIMAI 2016, 4, 26–30. [Google Scholar] [CrossRef]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. arXiv 2021, arXiv:2111.06377. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F. Beit: Bert pre-training of image transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Graves, A. Sequence transduction with recurrent neural networks. arXiv 2012, arXiv:1211.3711. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Wang, X.; Tang, X.; Zhou, H.; Li, C. Description generation for remote sensing images using attribute attention mechanism. Remote Sens. 2019, 11, 612. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGEL | CIDEr |
|---|---|---|---|---|---|---|---|
| Soft-attention [27] | 74.54 | 65.45 | 58.55 | 52.50 | 38.86 | 72.37 | 261.24 |
| Hard-attention [27] | 81.57 | 73.12 | 67.02 | 61.82 | 42.63 | 76.98 | 299.47 |
| Struct-attention [28] | 85.38 | 80.35 | 75.72 | 71.49 | 46.32 | 81.41 | 334.89 |
| AttrAttention [53] | 81.54 | 75.75 | 69.36 | 64.58 | 42.40 | 76.32 | 318.64 |
| MLA [30] | 84.06 | 78.03 | 73.33 | 69.16 | 53.30 | 81.96 | 311.93 |
| RASG [32] | 85.18 | 79.25 | 74.32 | 69.76 | 45.71 | 80.72 | 338.87 |
| VRTMM [31] | 83.94 | 77.85 | 72.83 | 68.28 | 45.27 | 80.26 | 349.48 |
| Ours | 89.36 | 84.82 | 80.57 | 76.50 | 50.81 | 85.86 | 389.92 |
| Method | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGEL | CIDEr |
|---|---|---|---|---|---|---|---|
| Soft-attention [27] | 73.22 | 66.74 | 62.23 | 58.20 | 39.42 | 71.27 | 249.93 |
| Hard-attention [27] | 75.91 | 66.10 | 58.89 | 52.58 | 38.98 | 71.89 | 218.19 |
| Struct-attention [28] | 77.95 | 70.19 | 63.92 | 58.61 | 39.54 | 72.99 | 237.91 |
| AttrAttention [53] | 81.43 | 73.51 | 65.86 | 58.06 | 41.11 | 71.95 | 230.21 |
| MLA [30] | 81.52 | 74.44 | 67.55 | 61.39 | 45.60 | 70.62 | 199.24 |
| RASG [32] | 80.00 | 72.17 | 65.31 | 59.09 | 39.08 | 72.18 | 263.11 |
| VRTMM [31] | 74.43 | 67.23 | 61.72 | 56.99 | 37.48 | 66.98 | 252.85 |
| Ours | 83.38 | 75.72 | 67.72 | 59.80 | 43.46 | 76.60 | 269.82 |
| Method | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGEL | CIDEr |
|---|---|---|---|---|---|---|---|
| Soft-attention [27] | 67.53 | 53.08 | 43.33 | 36.17 | 32.55 | 61.09 | 196.43 |
| Hard-attention [27] | 66.69 | 51.82 | 41.64 | 34.07 | 32.01 | 60.84 | 179.25 |
| Struct-attention [28] | 70.16 | 56.14 | 46.48 | 39.34 | 32.91 | 57.06 | 170.31 |
| AttrAttention [53] | 75.71 | 63.36 | 53.85 | 46.12 | 35.13 | 64.58 | 235.63 |
| MLA [30] | 77.25 | 62.90 | 53.28 | 46.08 | 34.71 | 69.10 | 236.37 |
| RASG [32] | 77.29 | 66.51 | 57.82 | 50.62 | 36.26 | 66.91 | 275.49 |
| VRTMM [31] | 78.13 | 67.21 | 56.45 | 51.23 | 37.37 | 67.13 | 271.50 |
| Ours | 80.42 | 69.96 | 61.36 | 54.14 | 39.37 | 70.58 | 298.39 |
| Topic | MLP | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | METEOR | ROUGEL | CIDEr |
|---|---|---|---|---|---|---|---|---|
| × | × | 79.38 | 67.58 | 58.50 | 51.82 | 38.13 | 68.68 | 287.97 |
| × | 79.12 | 68.05 | 59.03 | 51.77 | 38.35 | 68.99 | 293.22 | |
| × | 79.47 | 69.28 | 60.33 | 52.86 | 38.53 | 69.31 | 295.73 | |
| 80.40 | 69.95 | 61.34 | 54.12 | 39.36 | 70.51 | 298.39 |
| Dataset | Strategy | B-1 | B-2 | B-3 | B-4 | M | R | C | Self-C |
|---|---|---|---|---|---|---|---|---|---|
| UCM | CE | 88.39 | 83.59 | 79.09 | 74.82 | 48.72 | 83.69 | 365.66 | 59.94 |
| CE and SC | 87.48 | 83.06 | 78.71 | 74.16 | 48.32 | 82.95 | 377.85 | 15.80 | |
| Mask-CE | 89.36 | 85.17 | 80.57 | 76.50 | 51.38 | 85.85 | 389.92 | 59.86 | |
| Sydney | CE | 81.55 | 73.15 | 65.17 | 57.96 | 41.95 | 74.42 | 261.60 | 63.94 |
| CE and SC | 82.19 | 75.23 | 69.02 | 63.57 | 43.61 | 75.43 | 272.90 | 8.33 | |
| Mask-CE | 83.38 | 75.72 | 67.72 | 59.80 | 43.46 | 76.60 | 269.82 | 60.61 | |
| RSICD | CE | 79.31 | 68.74 | 59.60 | 51.31 | 38.78 | 69.00 | 292.31 | 69.28 |
| CE and SC | 79.46 | 68.34 | 59.74 | 52.63 | 38.87 | 69.33 | 301.76 | 13.12 | |
| Mask-CE | 80.42 | 69.96 | 61.36 | 54.14 | 39.37 | 70.58 | 298.39 | 60.41 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, Z.; Gou, S.; Guo, Z.; Mao, S.; Li, R. A Mask-Guided Transformer Network with Topic Token for Remote Sensing Image Captioning. Remote Sens. 2022, 14, 2939. https://doi.org/10.3390/rs14122939
Ren Z, Gou S, Guo Z, Mao S, Li R. A Mask-Guided Transformer Network with Topic Token for Remote Sensing Image Captioning. Remote Sensing. 2022; 14(12):2939. https://doi.org/10.3390/rs14122939
Chicago/Turabian StyleRen, Zihao, Shuiping Gou, Zhang Guo, Shasha Mao, and Ruimin Li. 2022. "A Mask-Guided Transformer Network with Topic Token for Remote Sensing Image Captioning" Remote Sensing 14, no. 12: 2939. https://doi.org/10.3390/rs14122939
APA StyleRen, Z., Gou, S., Guo, Z., Mao, S., & Li, R. (2022). A Mask-Guided Transformer Network with Topic Token for Remote Sensing Image Captioning. Remote Sensing, 14(12), 2939. https://doi.org/10.3390/rs14122939