
RSSGG_CS: Remote Sensing Image Scene Graph Generation by Fusing Contextual Information and Statistical Knowledge

 , , ,
, , ,
Abstract
:
1. Introduction
1.1. Background of Scene Graph Generation
1.1.1. Classical Methods for Scene Graph Generation
1.1.2. High-Level Understanding of Remote Sensing Image
1.2. Challenges of Scene Graph Generation
1.3. Contributions of the Paper
- We propose a novel model, RSSGG_CS, for remote sensing image scene graph generation;
- We fuse contextual information for each object by the FiM to enhance the feature extraction ability of the model and suppress object pairs without semantic relationships when generating remote sensing image scene graphs;
- We import statistical knowledge for the RSSGG_CS model to reduce the blindness of predicting the relationships between objects in remote sensing images;
- We combine the visual features and category semantic embeddings of objects to enhance the semantic expressiveness of the RSSGG_CS model.
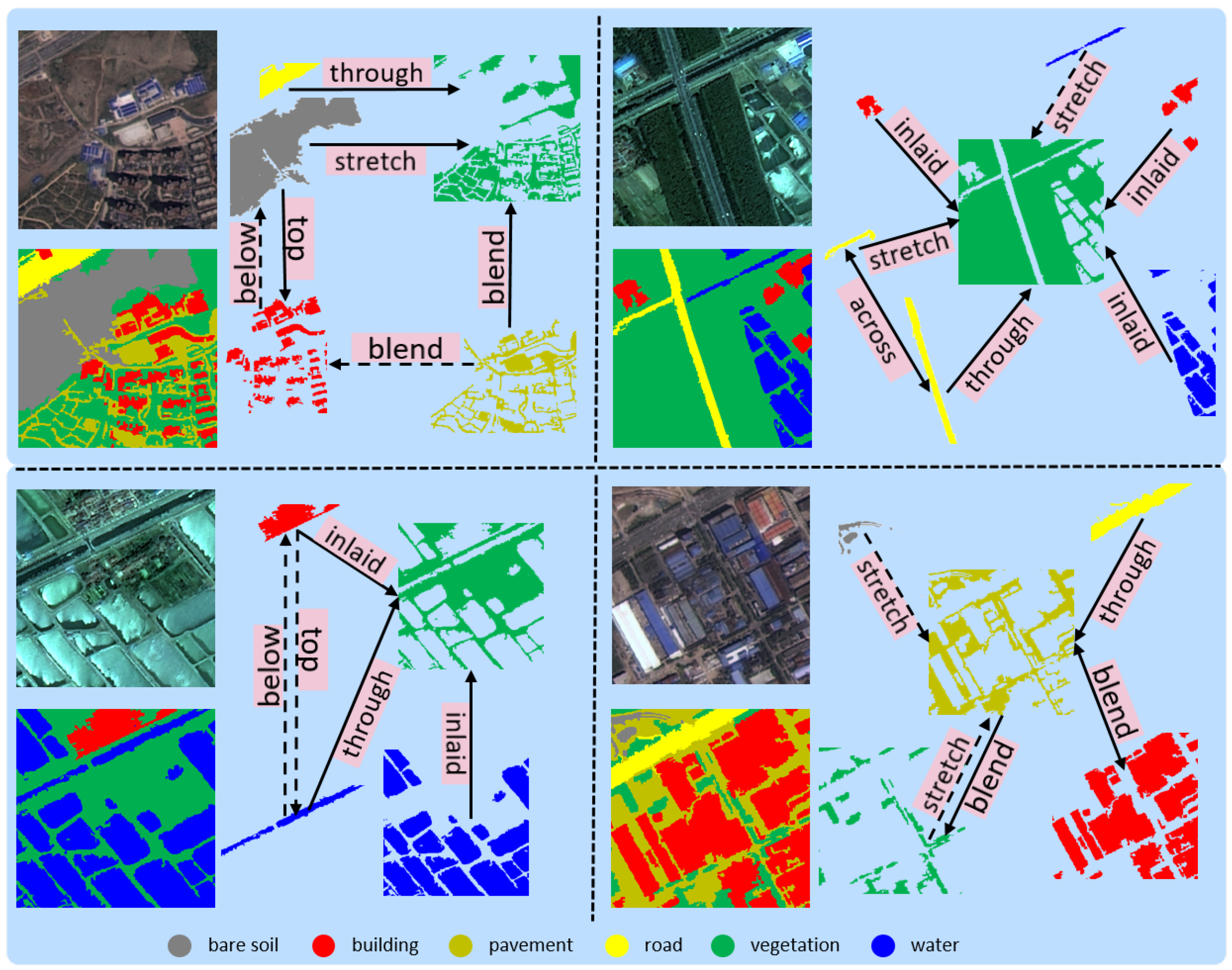
2. Materials and Methods
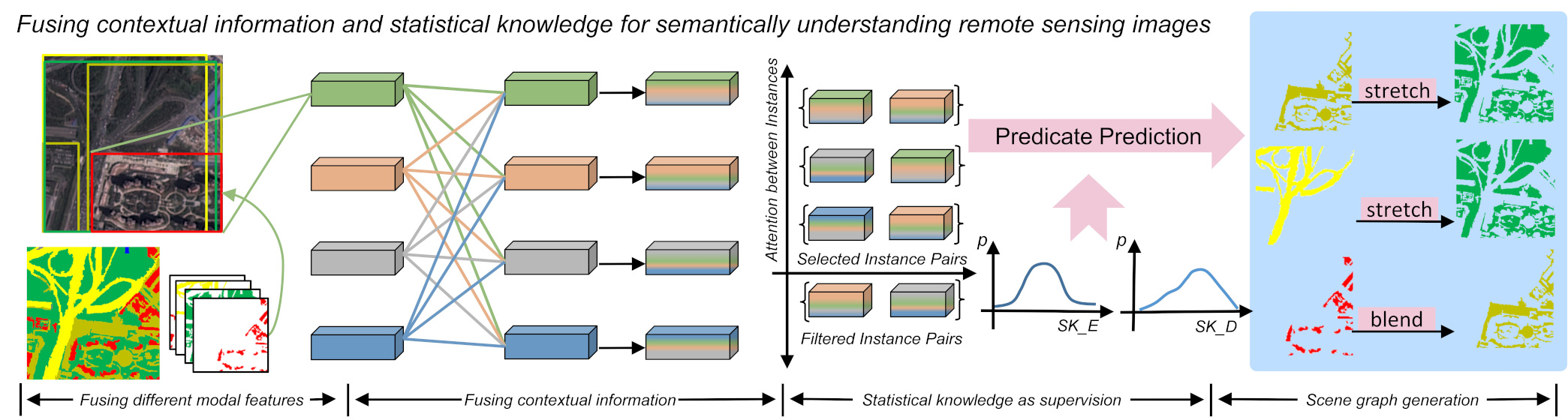
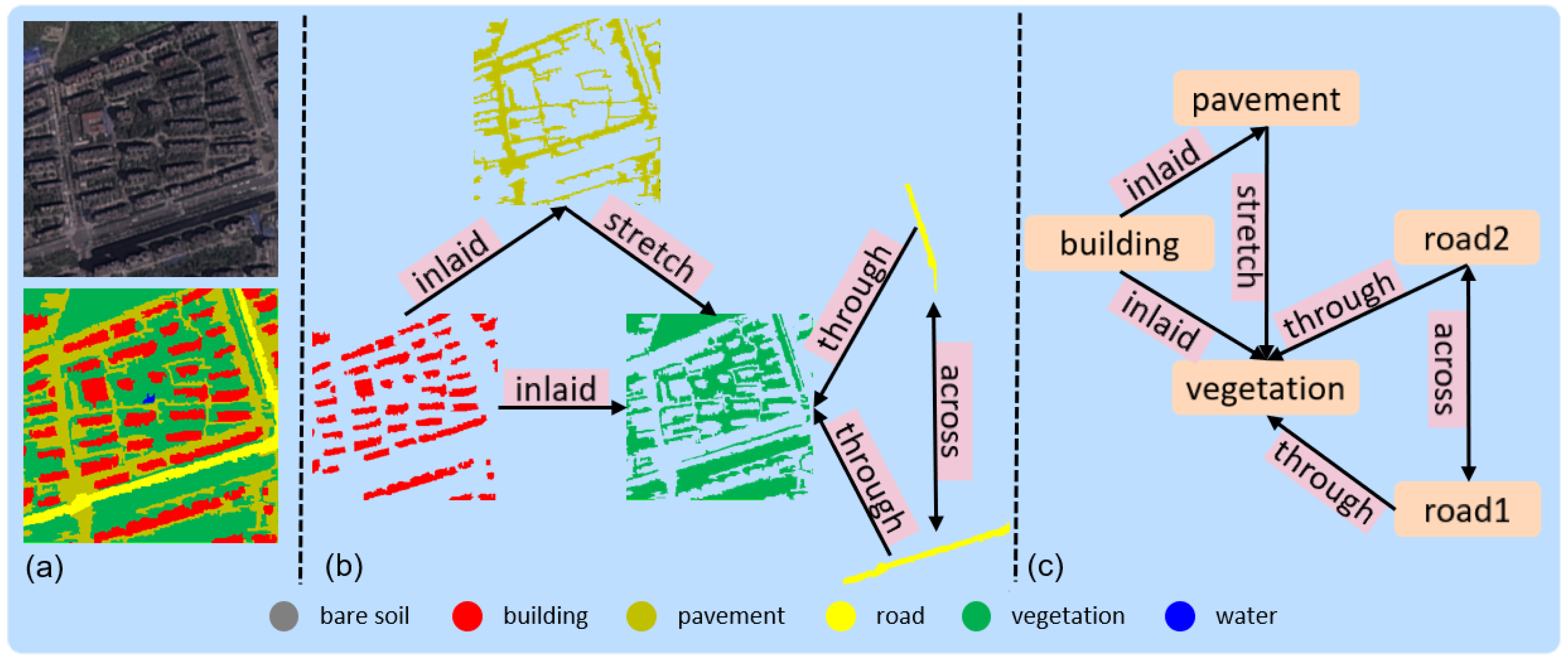
2.1. The Structure of RSSGG_CS
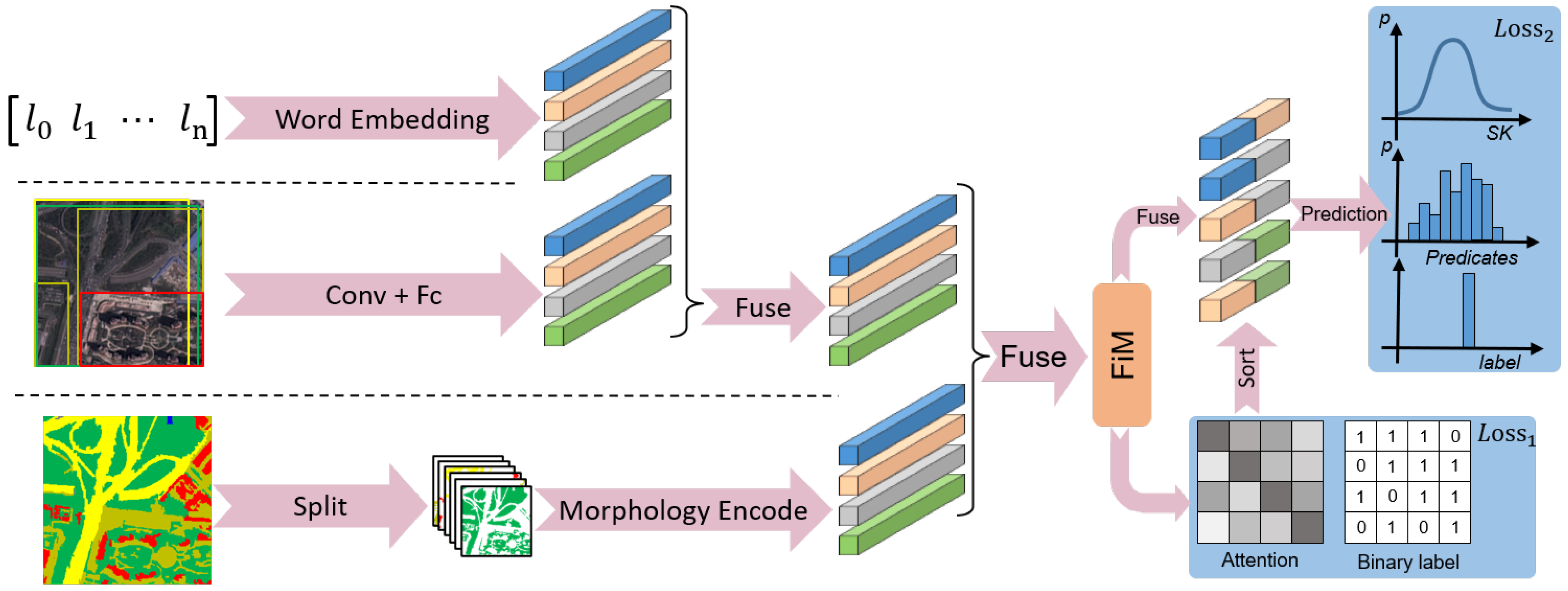
2.2. The Three Parallel Feature Extraction Branches
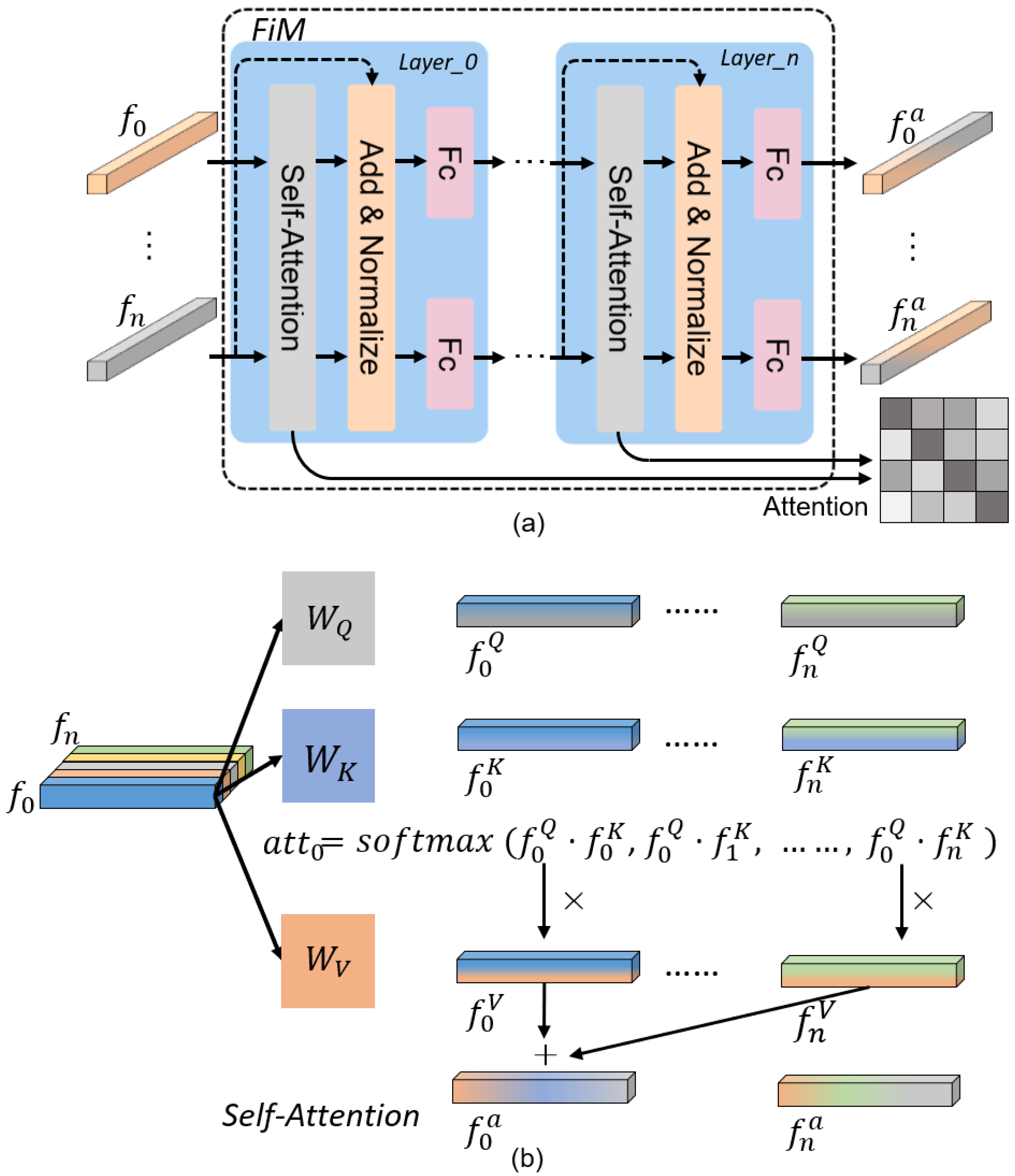
2.3. The FiM Module
2.4. Importing Statistical Knowledge as Supervision
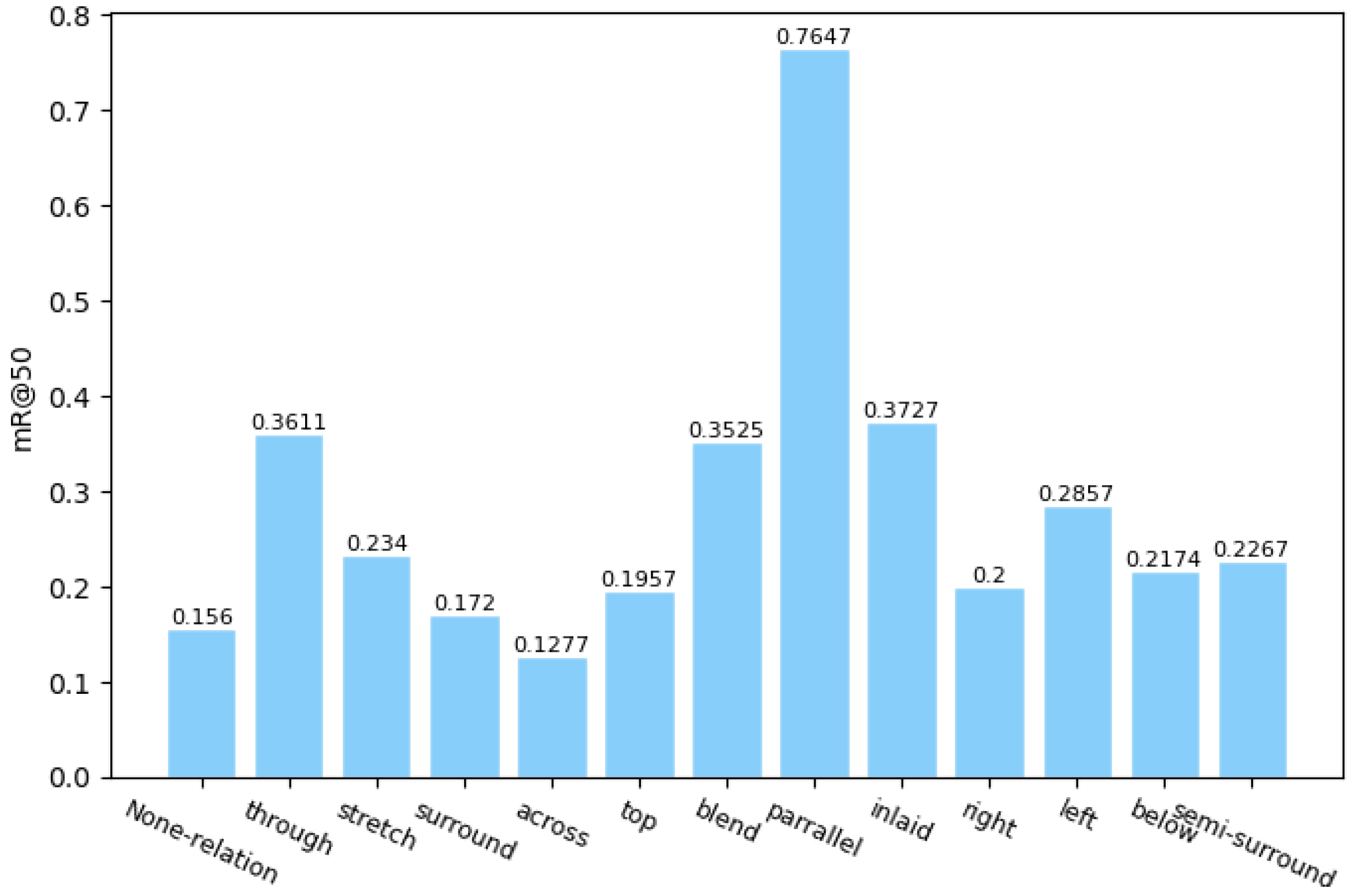
3. Experimental Results and Discussion
3.1. Implementation Details
3.2. Ablation Studies
3.3. Comparison Experiments
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Qi, M.; Li, W.; Yang, Z.; Wang, Y.; Luo, J. Attentive relational networks for mapping images to scene graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27 October–2 November 2019; pp. 3957–3966. [Google Scholar]
- Lu, C.; Krishna, R.; Bernstein, M.; Fei-Fei, L. Visual relationship detection with language priors. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 852–869. [Google Scholar]
- Li, Y.; Ouyang, W.; Zhou, B.; Wang, K.; Wang, X. Scene graph generation from objects, phrases and region captions. In Proceedings of the IEEE International Conference on Computer Vision, Glasgow, UK, 23–28 August 2017; pp. 1261–1270. [Google Scholar]
- Mi, L.; Chen, Z. Hierarchical graph attention network for visual relationship detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 13886–13895. [Google Scholar]
- Wei, M.; Yuan, C.; Yue, X.; Zhong, K. Hose-net: Higher order structure embedded network for scene graph generation. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1846–1854. [Google Scholar]
- Gu, J.; Zhao, H.; Lin, Z.; Li, S.; Cai, J.; Ling, M. Scene graph generation with external knowledge and image reconstruction. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1969–1978. [Google Scholar]
- Wang, W.; Wang, R.; Shan, S.; Chen, X. Sketching image gist: Human-mimetic hierarchical scene graph generation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 222–239. [Google Scholar]
- Lin, X.; Ding, C.; Zeng, J.; Tao, D. Gps-net: Graph property sensing network for scene graph generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3746–3753. [Google Scholar]
- Chen, S.; Jin, Q.; Wang, P.; Wu, Q. Say as you wish: Fine-grained control of image caption generation with abstract scene graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 9962–9971. [Google Scholar]
- Cornia, M.; Baraldi, L.; Cucchiara, R. Show, control and tell: A framework for generating controllable and grounded captions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 8307–8316. [Google Scholar]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. Vqa: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 2425–2433. [Google Scholar]
- Norcliffe-Brown, W.; Vafeias, S.; Parisot, S. Learning conditioned graph structures for interpretable visual question answering. Adv. Neural Inf. Process. Syst. 2018, 31, 8343–8443. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef] [Green Version]
- Xu, P.; Chang, X.; Guo, L.; Huang, P.Y.; Chen, X.; Hauptmann, A. A Survey of Scene Graph: Generation and Application. EasyChair Preprint 2020, arXiv:submit/3111057. [Google Scholar]
- Yu, R.; Li, A.; Morariu, V.I.; Davis, L.S. Visual relationship detection with internal and external linguistic knowledge distillation. In Proceedings of the IEEE International Conference on Computer Vision, Glasgow, UK, 23–28 August 2017; pp. 1974–1982. [Google Scholar]
- Sun, X.; Zi, Y.; Ren, T.; Tang, J.; Wu, G. Hierarchical visual relationship detection. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 94–102. [Google Scholar]
- Zhou, Y.; Sun, S.; Zhang, C.; Li, Y.; Ouyang, W. Exploring the Hierarchy in Relation Labels for Scene Graph Generation. arXiv 2020, arXiv:2009.05834. [Google Scholar]
- Newell, A.; Deng, J. Pixels to graphs by associative embedding. Adv. Neural Inf. Process. Syst. 2017, 30, 2171–2180. [Google Scholar]
- Ren, G.; Ren, L.; Liao, Y.; Liu, S.; Li, B.; Han, J.; Yan, S. Scene graph generation with hierarchical context. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 909–915. [Google Scholar] [CrossRef] [PubMed]
- Xu, D.; Zhu, Y.; Choy, C.B.; Fei-Fei, L. Scene graph generation by iterative message passing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5410–5419. [Google Scholar]
- Zareian, A.; Karaman, S.; Chang, S.F. Bridging knowledge graphs to generate scene graphs. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 606–623. [Google Scholar]
- Tang, K.; Zhang, H.; Wu, B.; Luo, W.; Liu, W. Learning to compose dynamic tree structures for visual contexts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6619–6628. [Google Scholar]
- Zellers, R.; Yatskar, M.; Thomson, S.; Choi, Y. Neural motifs: Scene graph parsing with global context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5831–5840. [Google Scholar]
- Plesse, F.; Ginsca, A.; Delezoide, B.; Prêteux, F. Visual relationship detection based on guided proposals and semantic knowledge distillation. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Wang, W.; Wang, R.; Chen, X. Topic Scene Graph Generation by Attention Distillation from Caption. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 15900–15910. [Google Scholar]
- Zhu, Z.; Luo, Y.; Wei, H.; Li, Y.; Qi, G.; Mazur, N.; Li, Y.; Li, P. Atmospheric light estimation based remote sensing image dehazing. Remote Sens. 2021, 13, 2432. [Google Scholar] [CrossRef]
- Zhu, Z.; Luo, Y.; Qi, G.; Meng, J.; Li, Y.; Mazur, N. Remote sensing image defogging networks based on dual self-attention boost residual octave convolution. Remote Sens. 2021, 13, 3104. [Google Scholar] [CrossRef]
- Cui, W.; Wang, F.; He, X.; Zhang, D.; Xu, X.; Yao, M.; Wang, Z.; Huang, J. Multi-scale semantic segmentation and spatial relationship recognition of remote sensing images based on an attention model. Remote Sens. 2019, 11, 1044. [Google Scholar] [CrossRef] [Green Version]
- Li, P.; Zhang, D.; Wulamu, A.; Liu, X.; Chen, P. Semantic Relation Model and Dataset for Remote Sensing Scene Understanding. ISPRS Int. J.-Geo-Inf. 2021, 10, 488. [Google Scholar] [CrossRef]
- Zhu, Z.; Wei, H.; Hu, G.; Li, Y.; Qi, G.; Mazur, N. A Novel Fast Single Image Dehazing Algorithm Based on Artificial Multiexposure Image Fusion. IEEE Trans. Instrum. Meas. 2021, 70, 1–23. [Google Scholar] [CrossRef]
- Liu, Y.; Han, J.; Zhang, Q.; Shan, C. Deep Salient Object Detection With Contextual Information Guidance. IEEE Trans. Image Process. 2020, 29, 360–374. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Chen, T.; Yu, W.; Chen, R.; Lin, L. Knowledge-embedded routing network for scene graph generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6163–6171. [Google Scholar]
- Su, W.; Zhu, X.; Cao, Y.; Li, B.; Lu, L.; Wei, F.; Dai, J. Vl-bert: Pre-training of generic visual-linguistic representations. arXiv 2019, arXiv:1908.08530. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; pp. 253–256. [Google Scholar] [CrossRef] [Green Version]
- Lecun, Y.; Bottou, L. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Řehůřek, R. Scalability of Semantic Analysis in Natural Language Processing. Ph.D. Thesis, Masaryk University, Brno, Czech Republic, 2011. [Google Scholar]
- Shao, Z.; Zhou, W.; Deng, X.; Zhang, M.; Cheng, Q. Multilabel Remote Sensing Image Retrieval Based on Fully Convolutional Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 318–328. [Google Scholar] [CrossRef]
- Tang, K.; Niu, Y.; Huang, J.; Shi, J.; Zhang, H. Unbiased scene graph generation from biased training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 3716–3725. [Google Scholar]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local attention embedding to improve the semantic segmentation of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 426–435. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sub_Module | R@50 | mR@50 | R@20 | mR@20 |
|---|---|---|---|---|
| VF | 0.2499 | 0.2355 | 0.1837 | 0.1332 |
| + WE | 0.2642 | 0.2450 | 0.1900 | 0.1396 |
| + WE + MF | 0.3131 | 0.2682 | 0.2257 | 0.1838 |
| + WE + MF + FiM | 0.3074 | 0.2745 | 0.2281 | 0.1469 |
| + WE + MF + FiM + SK_D | 0.3044 | 0.2795 | 0.2256 | 0.1639 |
| + WE + MF + FiM + SK_E | 0.3248 | 0.2666 | 0.2412 | 0.1579 |
| + WE + MF + FiM + SK_DE | 0.2915 | 0.2820 | 0.2204 | 0.1894 |
| + WE + MF + FiM + SK_DE_SEG | 0.3040 | 0.2386 | 0.2260 | 0.1707 |
| PreCl | PhaCl | SGG | |||
|---|---|---|---|---|---|
| mR@50 | mR@20 | mR@50 | mR@20 | mR@50 | mR@20 |
| 0.2820 | 0.1894 | 0.2769 | 0.1566 | 0.2419 | 0.1489 |
| Model | mR@50 | mR@20 |
|---|---|---|
| VCTree | 0.1261 | 0.0915 |
| MOTIFS | 0.0707 | 0.0447 |
| IMP | 0.0628 | 0.0480 |
| SRSG | 0.2561 | 0.1602 |
| RSSGG_CS | 0.2820 | 0.1894 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Z.; Zhu, F.; Wang, Q.; Kong, Y.; Wang, J.; Huang, L.; Hao, Y. RSSGG_CS: Remote Sensing Image Scene Graph Generation by Fusing Contextual Information and Statistical Knowledge. Remote Sens. 2022, 14, 3118. https://doi.org/10.3390/rs14133118
Lin Z, Zhu F, Wang Q, Kong Y, Wang J, Huang L, Hao Y. RSSGG_CS: Remote Sensing Image Scene Graph Generation by Fusing Contextual Information and Statistical Knowledge. Remote Sensing. 2022; 14(13):3118. https://doi.org/10.3390/rs14133118
Chicago/Turabian StyleLin, Zhiyuan, Feng Zhu, Qun Wang, Yanzi Kong, Jianyu Wang, Liang Huang, and Yingming Hao. 2022. "RSSGG_CS: Remote Sensing Image Scene Graph Generation by Fusing Contextual Information and Statistical Knowledge" Remote Sensing 14, no. 13: 3118. https://doi.org/10.3390/rs14133118
APA StyleLin, Z., Zhu, F., Wang, Q., Kong, Y., Wang, J., Huang, L., & Hao, Y. (2022). RSSGG_CS: Remote Sensing Image Scene Graph Generation by Fusing Contextual Information and Statistical Knowledge. Remote Sensing, 14(13), 3118. https://doi.org/10.3390/rs14133118