
Attention-Based Multi-Level Feature Fusion for Object Detection in Remote Sensing Images



Abstract
:1. Introduction
- (1)
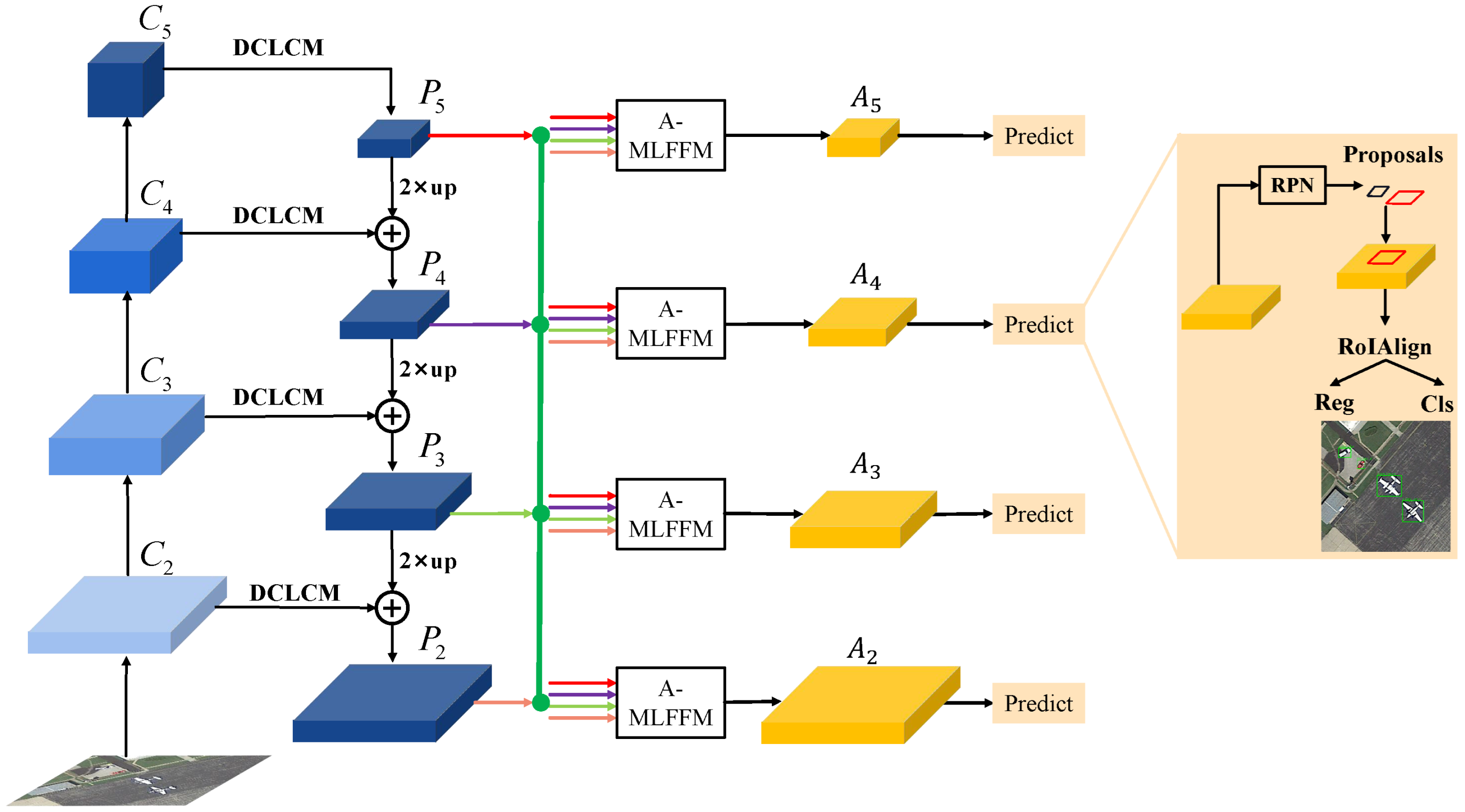
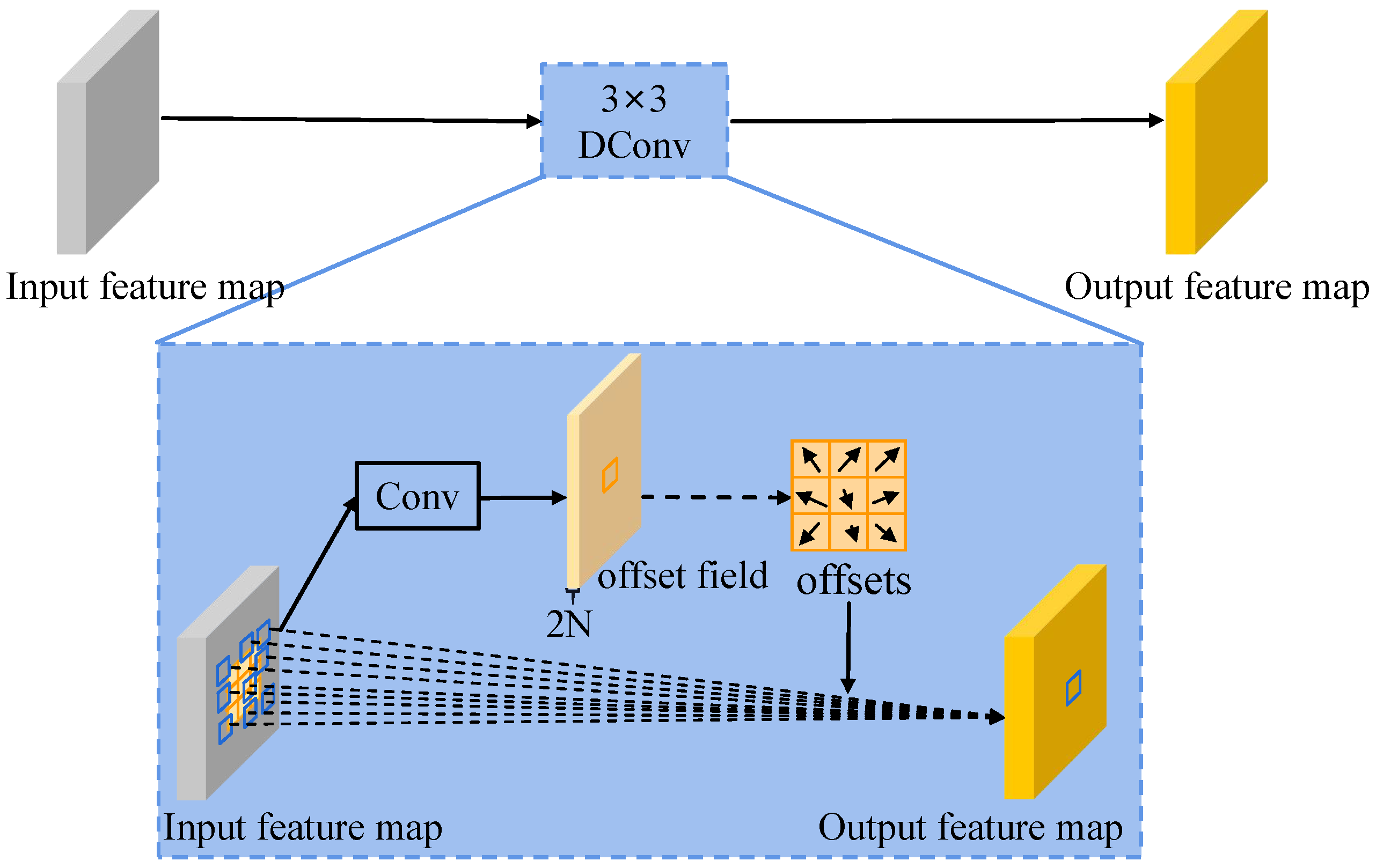
- We replace the original lateral connections in FPN ( Convs) with the proposed DCLCM, which aims to generate feature maps having deformable receptive fields, so as to effectively detect remote sensing objects with various shapes and orientations.
- (2)
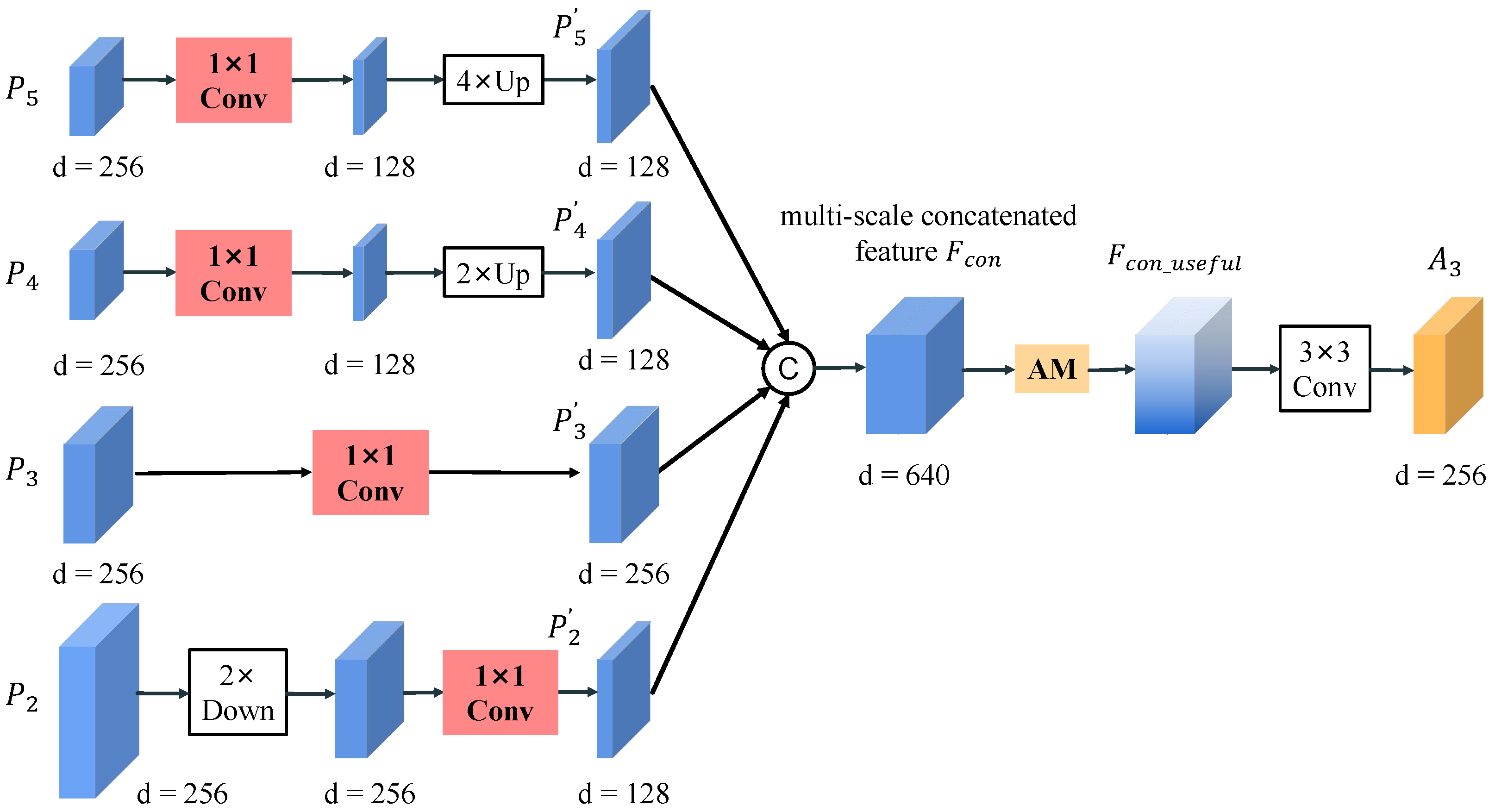
- Several A-MLFFMs, each of which contains a novel attention module, are proposed to adaptively fuse multi-level features and generate more powerful pyramidal features for object detection.
- (3)
- Experimental results on the DIOR dataset validate the state-of-the-art performance of the proposed method.
2. Related Work
2.1. Object Detection in Remote Sensing Images
2.2. Multi-Level Feature Fusion
2.3. Attention Mechanism
3. Materials and Methods
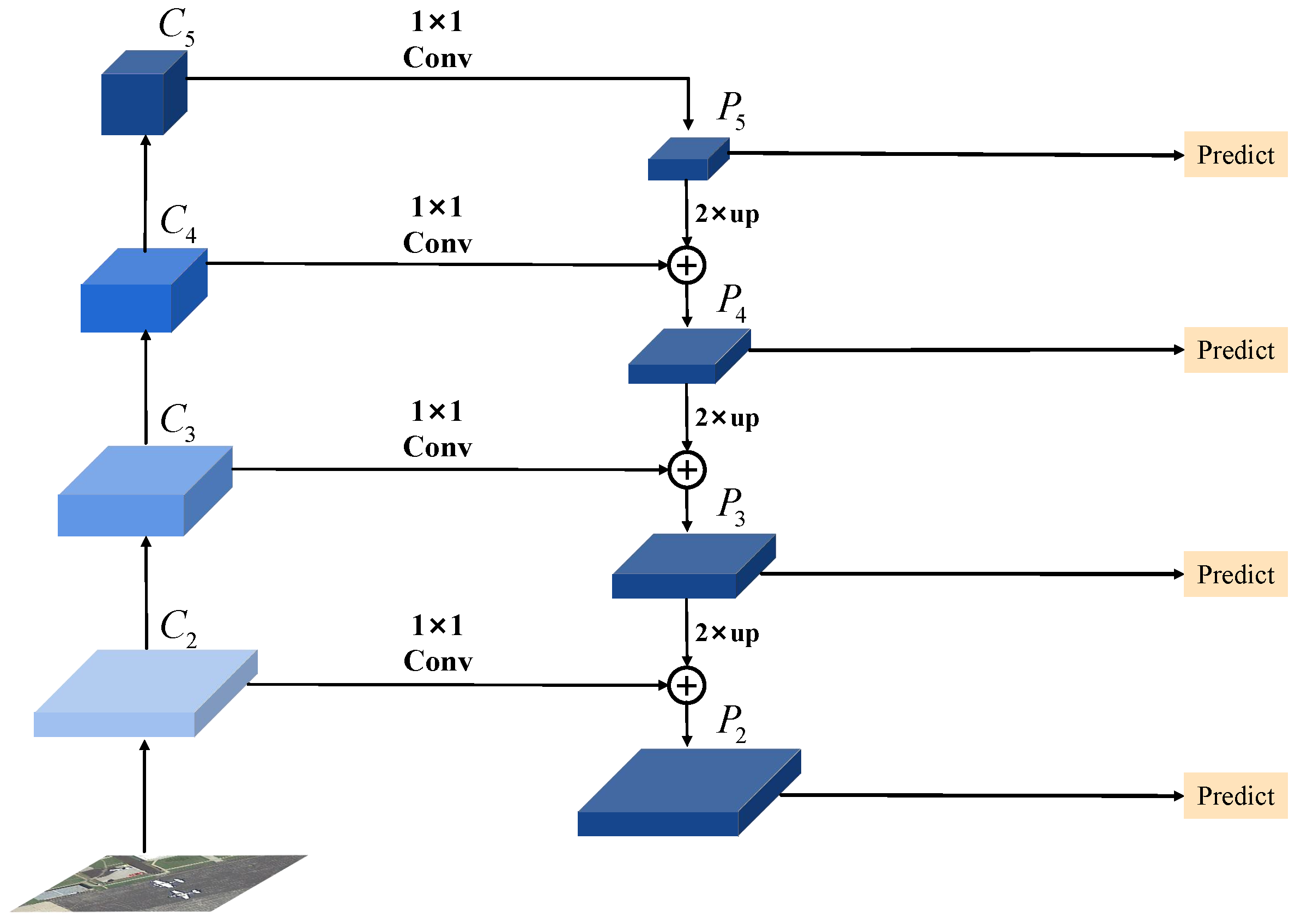
3.1. Overview of the Proposed Method
3.2. Deformable Convolution Lateral Connection Module (DCLCM)
3.3. Attention-Based Multi-Level Feature Fusion Module (A-MLFFM)
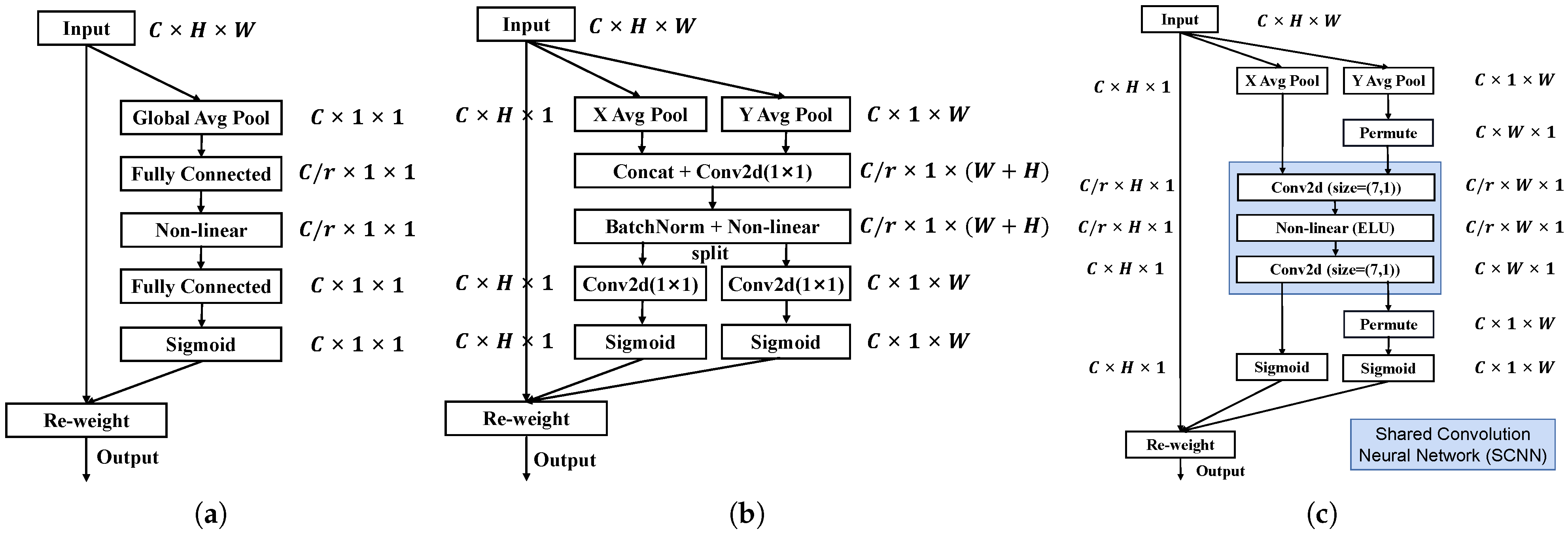
The Proposed Attention Module (AM)
4. Experiments and Results
4.1. Dataset
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Ablation Study and Analysis
- DCLCM Only. After we replace the original lateral connections of FPN with the proposed DCLCMs, 2.3% mAP improvement can be achieved on the DIOR dataset. The objects in remote sensing images have variable shapes and orientations, which may seriously affect the detection performance of FPN. By integrating the DCLCM into FPN, more precise feature maps with deformable receptive fields can be generated to detect these remote sensing objects well.
- A-MLFFM Only. When we insert the proposed A-MLFFMs into FPN, the detection mAP is improved by 72.1% on the DIOR dataset. Each A-MLFFM contains a novel attention module to fuse the multi-level outputs of FPN adaptively. In this way, the complementary information contained in different outputs of FPN can be fully exploited to detect remote sensing objects with various sizes better.
- Both DCLCM and A-MLFFM. By introducing both of the proposed DCLCM and A-MLFFM into FPN simultaneously, the detection mAP can be further increased to 73.6% on the DIOR dataset, which demonstrates that DCLCM and A-MLFFM are two complementary modules, and the utilization of them allows the proposed method to achieve the best detection accuracy.
4.5. Effectiveness of the Attention Module in A-MLFFM
4.6. Comparison with Other Multi-Level Feature Fusion Modules
4.7. Comparison with Other State-of-the-Art Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ahmad, K.; Pogorelov, K.; Riegler, M.; Conci, N.; Halvorsen, P. Social media and satellites. Multimed Tools Appl. 2019, 78, 2837–2875. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Chen, X.; Xiang, S.; Liu, C.L.; Pan, C.H. Vehicle detection in satellite images by hybrid deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1797–1801. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Learning semantic segmentation of large-scale point clouds with random sampling. IEEE Trans. Pattern Anal. Mach. Intell. 2021; in press. [Google Scholar] [CrossRef]
- Hu, Q.; Yang, B.; Khalid, S.; Xiao, W.; Trigoni, N.; Markham, A. Sensaturban: Learning semantics from urban-scale photogrammetric point clouds. Int. J. Comput. Vis. 2022, 130, 316–343. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–27 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE/CVF International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE/CVF International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Wu, Y.; Chen, Y.; Yuan, L.; Liu, Z.; Wang, L.; Li, H.; Fu, Y. Rethinking classification and localization for object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10186–10195. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra r-cnn: Towards balanced learning for object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 821–830. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Qiao, S.; Chen, L.C.; Yuille, A. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10213–10224. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the 2016 European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Redmon, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE/CVF International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Malisiewicz, T.; Gupta, A.; Efros, A.A. Ensemble of exemplar-svms for object detection and beyond. In Proceedings of the 2011 IEEE/CVF International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 89–96. [Google Scholar]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Sun, X.; Wang, P.; Yan, Z.; Xu, F.; Wang, R.; Diao, W.; Chen, J.; Li, J.; Feng, Y.; Xu, T.; et al. FAIR1M: A benchmark dataset for fine-grained object recognition in high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2022, 184, 116–130. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate object localization in remote sensing images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Dong, X.; Fu, R.; Gao, Y.; Qin, Y.; Ye, Y.; Li, B. Remote Sensing Object Detection Based on Receptive Field Expansion Block. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, K.; Wang, J.; Wang, Y.; Wang, Q.; Li, Q. CDD-net: A context-driven detection network for multiclass object detection. IEEE Geosci. Remote Sens. Lett. 2020; in press. [Google Scholar] [CrossRef]
- Ye, Y.; Ren, X.; Zhu, B.; Tang, T.; Tan, X.; Gui, Y.; Yao, Q. An Adaptive Attention Fusion Mechanism Convolutional Network for Object Detection in Remote Sensing Images. Remote Sens. 2022, 14, 516. [Google Scholar] [CrossRef]
- Chen, L.; Liu, C.; Chang, F.; Li, S.; Nie, Z. Adaptive multi-level feature fusion and attention-based network for arbitrary-oriented object detection in remote sensing imagery. Neurocomputing 2021, 451, 67–80. [Google Scholar] [CrossRef]
- Dong, X.; Qin, Y.; Fu, R.; Gao, Y.; Liu, S.; Ye, Y.; Li, B. Multi-Scale Deformable Attention and Multi-Level Features Aggregation for Remote Sensing Object Detection. IEEE Geosci. Remote Sens. Lett. 2022; in press. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake CityUT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the 33th AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 9259–9266. [Google Scholar]
- Cheng, G.; Si, Y.; Hong, H.; Yao, X.; Guo, L. Cross-scale feature fusion for object detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 431–435. [Google Scholar] [CrossRef]
- Huang, W.; Li, G.; Chen, Q.; Ju, M.; Qu, J. CF2PN: A cross-scale feature fusion pyramid network based remote sensing target detection. Remote Sens. 2021, 13, 847. [Google Scholar] [CrossRef]
- Zhai, S.; Shang, D.; Wang, S.; Dong, S. DF-SSD: An improved SSD object detection algorithm based on DenseNet and feature fusion. IEEE Access 2020, 8, 24344–24357. [Google Scholar] [CrossRef]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8232–8241. [Google Scholar]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef] [Green Version]
- Yao, Q.; Hu, X.; Lei, H. Multiscale convolutional neural networks for geospatial object detection in VHR satellite images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 23–27. [Google Scholar] [CrossRef]
- Qian, X.; Lin, S.; Cheng, G.; Yao, X.; Ren, H.; Wang, W. Object detection in remote sensing images based on improved bounding box regression and multi-level features fusion. Remote Sens. 2020, 12, 143. [Google Scholar] [CrossRef] [Green Version]
- Lu, X.; Ji, J.; Xing, Z.; Miao, Q. Attention and feature fusion SSD for remote sensing object detection. IEEE Trans. Instrum. Meas. 2021, 70, 1–9. [Google Scholar] [CrossRef]
- LaLonde, R.; Zhang, D.; Shah, M. Clusternet: Detecting small objects in large scenes by exploiting spatio-temporal information. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4003–4012. [Google Scholar]
- Zhou, Y.; Maskell, S. Detecting and tracking small moving objects in wide area motion imagery (wami) using convolutional neural networks (cnns). In Proceedings of the 22th International Conference on Information Fusion, Ottawa, ON, Canada, 2–5 July 2019; pp. 1–8. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7036–7045. [Google Scholar]
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural architecture search: A survey. J. Mach. Learn. Res. 2019, 20, 1997–2017. [Google Scholar]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention augmented convolutional networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3286–3295. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Vedaldi, A. Gather-excite: Exploiting feature context in convolutional neural networks. In Proceedings of the 32th International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the 2016 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. A simple and light-weight attention module for convolutional neural networks. Int. J. Comput. Vis. 2020, 128, 783–798. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Hou, Q.; Zhang, L.; Cheng, M.M.; Feng, J. Strip pooling: Rethinking spatial pooling for scene parsing. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4003–4012. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv 2015, arXiv:1511.07289. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Yu, D.; Ji, S. A new spatial-oriented object detection framework for remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the 2017 IEEE/CVF International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Liu, Y.; Li, Q.; Yuan, Y.; Du, Q.; Wang, Q. ABNet: Adaptive Balanced Network for Multiscale Object Detection in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | FPN [9] | FPN + DCLCM | FPN + A-MLFFM | FPN + DCLCM + A-MLFFM |
|---|---|---|---|---|
| airplane | 70.2 | 70.6 | 70.3 | 70.7 |
| airport | 75.2 | 83.0 | 79.2 | 83.1 |
| BF | 71.5 | 71.6 | 71.8 | 71.9 |
| BC | 86.1 | 86.6 | 86.8 | 86.5 |
| bridge | 46.8 | 49.0 | 50.5 | 49.3 |
| chimney | 76.9 | 79.0 | 78.0 | 78.2 |
| dam | 64.4 | 68.8 | 69.2 | 70.3 |
| ESA | 76.4 | 78.8 | 82.0 | 83.7 |
| ETS | 69.7 | 73.4 | 74.3 | 76.7 |
| GF | 75.3 | 76.6 | 75.7 | 76.0 |
| GTF | 79.6 | 80.6 | 78.6 | 80.2 |
| harbor | 56.6 | 57.5 | 52.8 | 55.9 |
| overpass | 60.8 | 62.2 | 61.3 | 62.7 |
| ship | 88.5 | 88.7 | 88.9 | 89.0 |
| stadium | 60.7 | 69.8 | 69.5 | 71.3 |
| ST | 70.6 | 71.4 | 78.0 | 79.1 |
| TC | 81.4 | 81.3 | 81.2 | 81.4 |
| TS | 54.9 | 61.2 | 57.0 | 60.1 |
| vehicle | 54.4 | 54.8 | 55.5 | 55.6 |
| windmill | 88.5 | 88.2 | 88.6 | 89.4 |
| mAP | 70.4 | 72.7 | 72.5 | 73.6 |
| Category | FPN + MLFFM | FPN + A-MLFFM (SE Attention [62]) | FPN + A-MLFFM (CA Block [63]) | FPN + A-MLFFM (the Proposed Attention) |
|---|---|---|---|---|
| airplane | 70.4 | 70.2 | 70.3 | 70.3 |
| airport | 75.8 | 78.3 | 78.5 | 79.2 |
| BF | 71.4 | 71.7 | 71.8 | 71.8 |
| BC | 86.3 | 86.1 | 86.4 | 86.8 |
| bridge | 48.2 | 48.2 | 48.6 | 50.5 |
| chimney | 78.1 | 78.0 | 77.5 | 78.0 |
| dam | 65.0 | 66.0 | 66.5 | 69.2 |
| ESA | 79.4 | 80.6 | 78.8 | 82.0 |
| ETS | 69.8 | 73.9 | 73.3 | 74.3 |
| GF | 76.3 | 76.4 | 76.4 | 75.7 |
| GTF | 80.5 | 78.6 | 80.9 | 78.6 |
| harbor | 54.7 | 53.3 | 53.3 | 52.8 |
| overpass | 61.5 | 61.8 | 61.6 | 61.3 |
| ship | 88.9 | 88.5 | 88.7 | 88.9 |
| stadium | 71.3 | 69.7 | 71.6 | 69.5 |
| ST | 71.0 | 71.3 | 71.4 | 78.0 |
| TC | 81.4 | 81.4 | 81.5 | 81.2 |
| TS | 55.1 | 56.4 | 55.6 | 57.0 |
| vehicle | 55.0 | 55.2 | 55.3 | 55.5 |
| windmill | 88.6 | 89.0 | 88.6 | 88.6 |
| mAP | 71.4 | 71.7 | 71.8 | 72.5 |
| Category | FPN + CSFF [42] | FPN + AFP [40] | FPN + BFP [18] | FPN + A-MLFFM |
|---|---|---|---|---|
| airplane | 69.9 | 69.6 | 70.5 | 70.3 |
| airport | 74.4 | 75.4 | 78.1 | 79.2 |
| BF | 71.6 | 71.7 | 71.7 | 71.8 |
| BC | 86.3 | 86.4 | 86.3 | 86.8 |
| bridge | 47.0 | 47.1 | 47.4 | 50.5 |
| chimney | 78.1 | 77.8 | 77.9 | 78.0 |
| dam | 63.8 | 66.3 | 64.8 | 69.2 |
| ESA | 76.3 | 76.3 | 75.9 | 82.0 |
| ETS | 73.0 | 70.1 | 72.8 | 74.3 |
| GF | 75.4 | 74.3 | 75.3 | 75.7 |
| GTF | 80.8 | 80.5 | 80.7 | 78.6 |
| harbor | 53.9 | 52.8 | 55.9 | 52.8 |
| overpass | 61.0 | 61.1 | 60.3 | 61.3 |
| ship | 88.6 | 88.7 | 88.8 | 88.9 |
| stadium | 71.5 | 72.4 | 69.9 | 69.5 |
| ST | 71.1 | 71.0 | 70.8 | 78.0 |
| TC | 81.4 | 81.4 | 81.5 | 81.2 |
| TS | 55.1 | 56.6 | 56.3 | 57.0 |
| vehicle | 54.5 | 54.7 | 54.8 | 55.5 |
| windmill | 88.7 | 88.3 | 88.6 | 88.6 |
| mAP | 71.1 | 71.1 | 71.4 | 72.5 |
| Category | FPN * [9] | Libra R-CNN * [18] | RSADet [67] | DCNs * [68] | Double-Head R-CNN * [17] | ABNet [69] | FPN with RFEB [35] | Ours |
|---|---|---|---|---|---|---|---|---|
| airplane | 70.2 | 70.9 | 73.6 | 70.2 | 70.4 | 66.8 | 70.0 | 70.9 |
| arport | 75.2 | 76.5 | 86.0 | 81.7 | 80.2 | 84.0 | 83.9 | 83.1 |
| BF | 71.5 | 71.4 | 72.6 | 71.7 | 71.9 | 74.9 | 77.1 | 71.9 |
| BC | 86.1 | 86.0 | 89.6 | 86.2 | 86.9 | 87.7 | 86.9 | 86.5 |
| bridge | 46.8 | 47.4 | 43.6 | 48.0 | 49.3 | 50.3 | 47.8 | 49.3 |
| chimney | 76.9 | 77.4 | 75.3 | 75.7 | 78.5 | 78.2 | 77.6 | 78.2 |
| dam | 64.4 | 66.0 | 62.3 | 67.1 | 65.9 | 67.8 | 71.3 | 70.3 |
| ESA | 76.4 | 76.9 | 79.5 | 78.8 | 77.6 | 85.9 | 79.5 | 83.7 |
| ETS | 69.7 | 73.6 | 68.7 | 73.5 | 73.2 | 74.2 | 70.6 | 76.7 |
| GF | 75.3 | 76.1 | 78.6 | 75.5 | 76.2 | 79.7 | 77.3 | 76.0 |
| GTF | 79.6 | 80.4 | 79.1 | 79.6 | 81.5 | 81.2 | 78.7 | 80.2 |
| harbor | 56.6 | 55.9 | 57.9 | 57.2 | 56.2 | 55.4 | 57.7 | 55.9 |
| overpass | 60.8 | 61.2 | 59.2 | 61.2 | 61.8 | 61.6 | 60.4 | 62.7 |
| ship | 88.5 | 89.0 | 90.0 | 88.4 | 88.8 | 75.1 | 88.4 | 89.0 |
| stadium | 60.7 | 70.0 | 55.8 | 69.4 | 73.6 | 74.0 | 67.7 | 71.3 |
| ST | 70.6 | 71.2 | 77.0 | 77.1 | 71.3 | 66.7 | 76.2 | 79.1 |
| TC | 81.4 | 88.0 | 87.8 | 81.3 | 87.9 | 87.0 | 86.9 | 81.4 |
| TS | 54.9 | 55.3 | 65.3 | 60.4 | 58.7 | 62.2 | 63.7 | 60.1 |
| vehicle | 54.4 | 54.6 | 55.3 | 54.7 | 54.9 | 53.6 | 54.5 | 55.6 |
| windmill | 88.5 | 88.7 | 86.5 | 88.9 | 89.0 | 89.1 | 88.2 | 89.4 |
| mAP | 70.4 | 71.8 | 72.2 | 72.3 | 72.7 | 72.8 | 73.2 | 73.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, X.; Qin, Y.; Gao, Y.; Fu, R.; Liu, S.; Ye, Y. Attention-Based Multi-Level Feature Fusion for Object Detection in Remote Sensing Images. Remote Sens. 2022, 14, 3735. https://doi.org/10.3390/rs14153735
Dong X, Qin Y, Gao Y, Fu R, Liu S, Ye Y. Attention-Based Multi-Level Feature Fusion for Object Detection in Remote Sensing Images. Remote Sensing. 2022; 14(15):3735. https://doi.org/10.3390/rs14153735
Chicago/Turabian StyleDong, Xiaohu, Yao Qin, Yinghui Gao, Ruigang Fu, Songlin Liu, and Yuanxin Ye. 2022. "Attention-Based Multi-Level Feature Fusion for Object Detection in Remote Sensing Images" Remote Sensing 14, no. 15: 3735. https://doi.org/10.3390/rs14153735
APA StyleDong, X., Qin, Y., Gao, Y., Fu, R., Liu, S., & Ye, Y. (2022). Attention-Based Multi-Level Feature Fusion for Object Detection in Remote Sensing Images. Remote Sensing, 14(15), 3735. https://doi.org/10.3390/rs14153735