
Supervised Machine Learning Algorithms for Ground Motion Time Series Classification from InSAR Data

 , , , ,
, , , , 
Abstract
:1. Introduction
- We tailor KNN, RF, XGB, SVM, and a deep Artificial Neural Network (ANN) to classify five deformation trends (e.g., Stable, Linear, Quadratic, Bilinear, and PUE) within three DInSAR datasets.
- Twenty-nine customized features are computed to distinguish the temporal properties of the five deformation trends, including autocorrelation, decomposition, and TS-based statistical metrics. Moreover, more effective features are introduced using a feature importance method based on the RF model.
- We assess the performance of algorithms based on False Alarm Rate (FAR) values in 99% confidence intervals to assess the impact of misclassifications in big DInSAR data analysis.
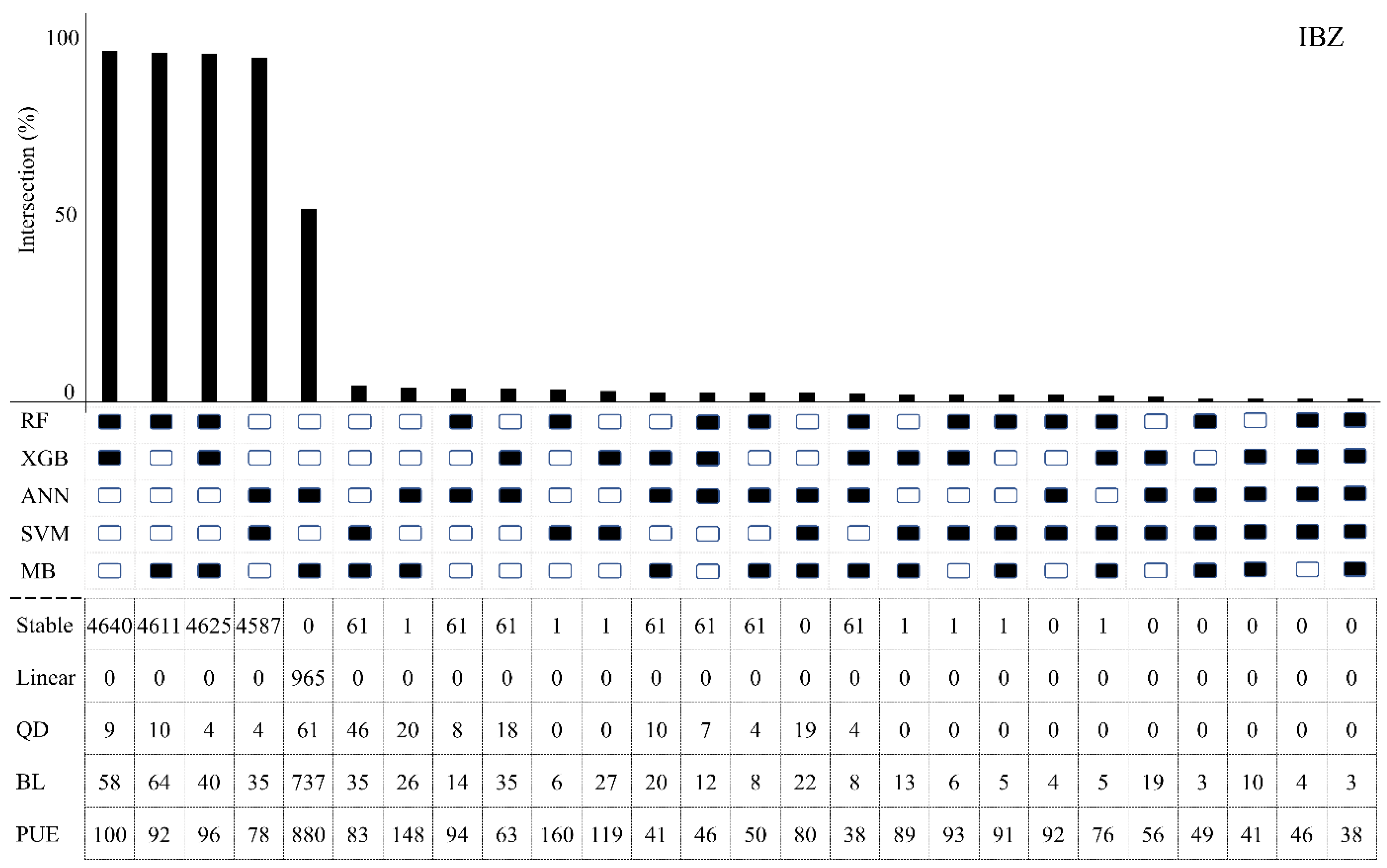
- Two validation steps are evaluated to examine the reliability of the proposed models, consisting of two deformation case studies in Spain and analysing the intersection of the proposed models and a benchmark classifier (the Model-Based (MB) method) classification results.
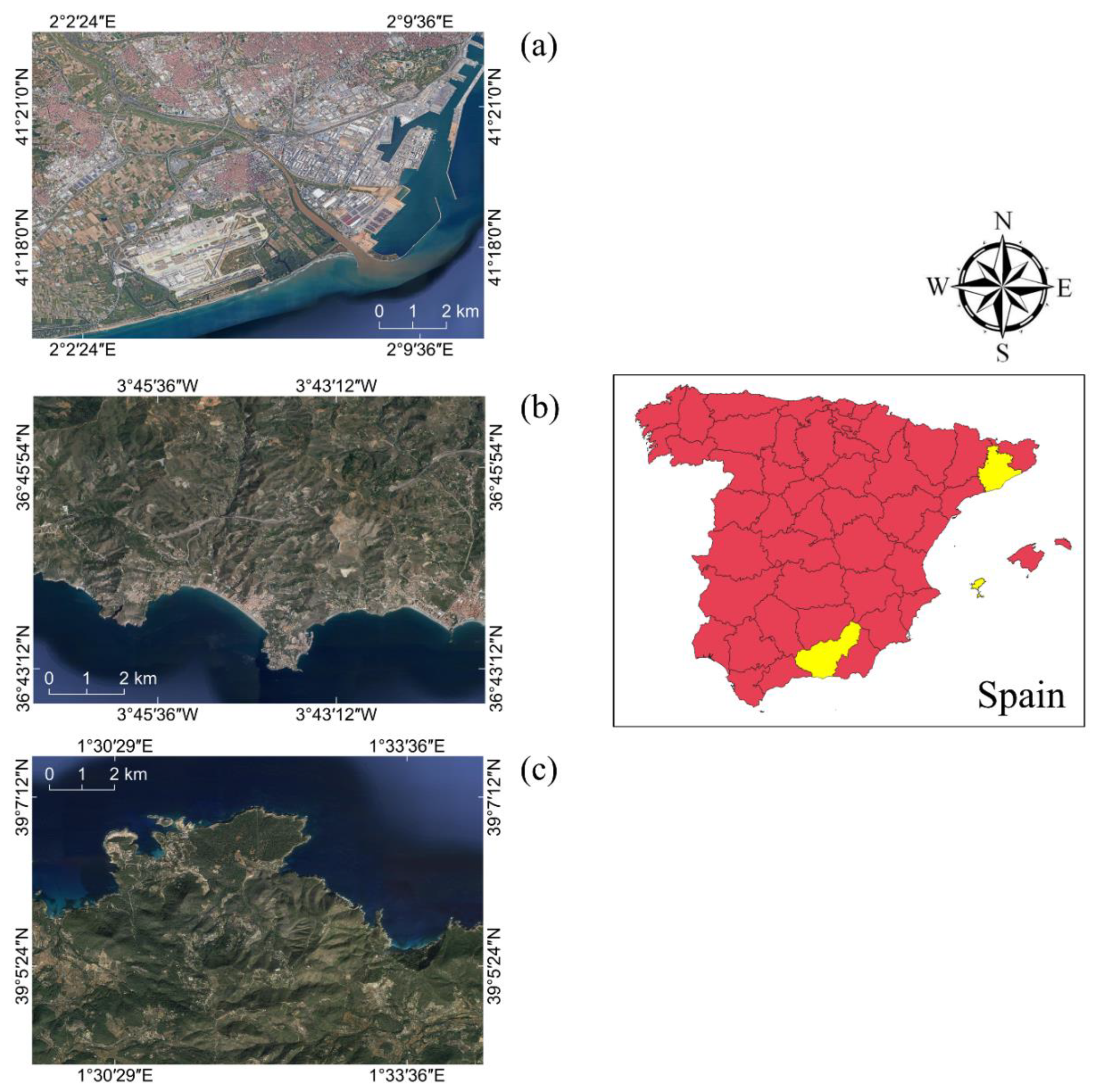
2. Dataset
2.1. Deformation Time Series
2.2. Reference Samples
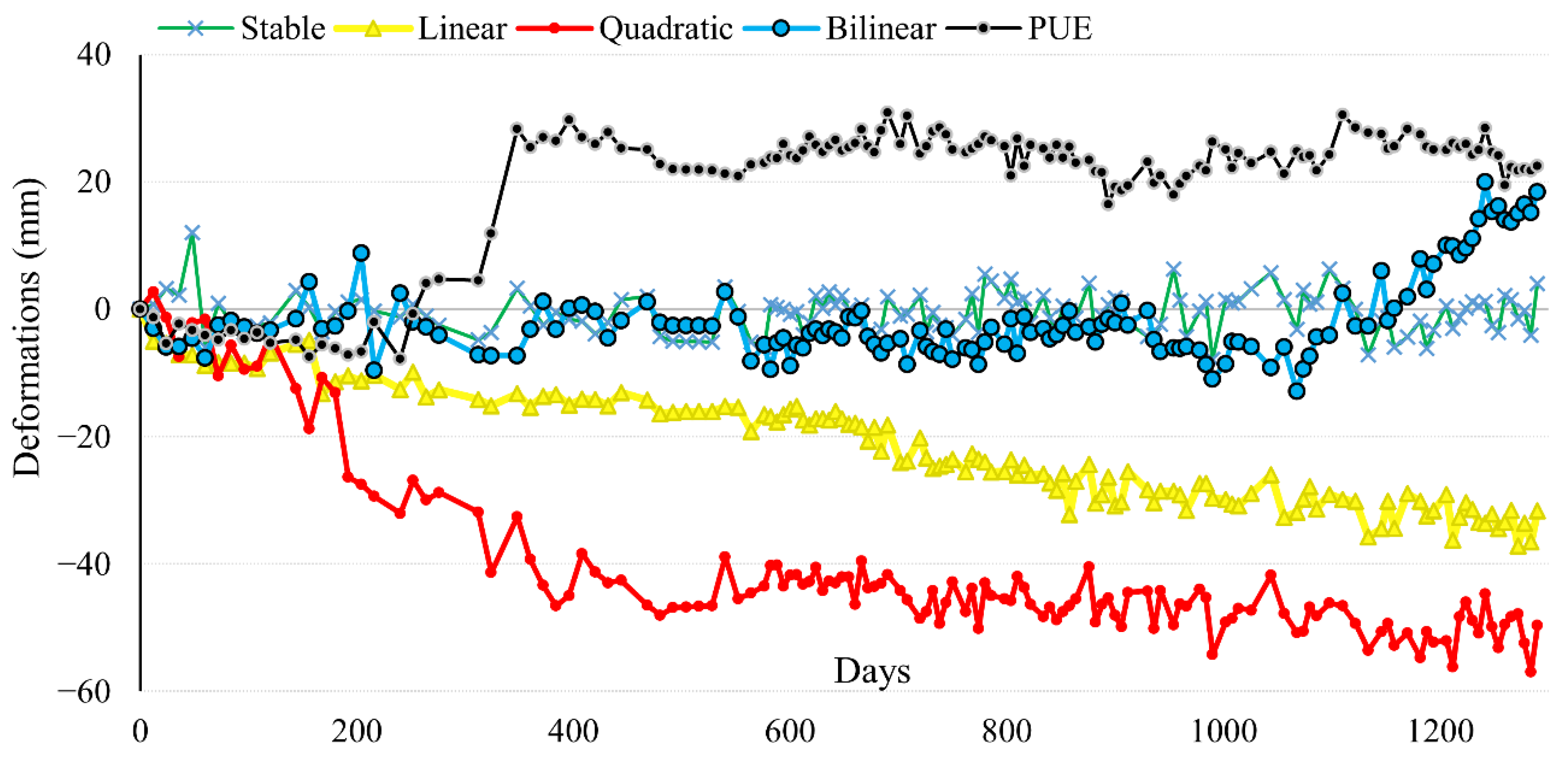
- Stable: The Stable class includes the nonmoving targets (see the green trend in Figure 2), i.e., the TS is dominantly characterized by random fluctuations included approximately between −5 and +5 mm. This class contains points for which significant deformation phenomena have not been detected during the observation period.
- Linear: A constant velocity (i.e., a slope) characterizes the TS, meaning that the deformation constantly increases or decreases over time (yellow trend in Figure 2).
- Quadratic: The deformation TS can be approximated by a second-order polynomial function, which demonstrates displacements characterized by continuous movements (red trend in Figure 2).
- Bilinear: The second nonlinear class includes two linear subperiods separated by a breakpoint (blue trend in Figure 2). This class mainly reflects an increasing deformation rate after a breakpoint, as in the case of collapse of a landslide or an infrastructure failure.
- PUE: Despite two steps of PUE removal in the PSIG procedure, there may still be TS affected by deformation jumps (see the black trend in Figure 2). Considering the C-band wavelength of Sentinel-1, the PUE value is about 28 mm (i.e., half the wavelength). Since the PUE value may change depending on the noise source [5], those TSs affected by vertical jumps of −15 to 28 mm (and greater than 28 mm) are classified as PUE. Indeed, the TS is divided into two or more segments by jumps, where separated segments are characterized by stable behaviour with different observation values (i.e., y-intercept). For example, the segment before the jump in the black trend of Figure 2 has values of approximately zero, while it is close to 30 mm in the second segment.
3. Method
3.1. Models
3.1.1. Support Vector Machine (SVM)
3.1.2. Random Forest (RF)
3.1.3. Extreme Gradient Boosting (XGB)
3.1.4. Artificial Neural Network (ANN)
3.1.5. K-Nearest Neighbour (KNN)
3.1.6. Model-Based (MB)
3.2. Time Series Features
3.2.1. General Features
3.2.2. Autocorrelation Function (ACF) and Partial Autocorrelation Function (PACF) Features
3.2.3. Seasonal and Trend Decomposition Using the LOESS (STL) Features
3.2.4. Other Features
3.3. Accuracy and Validation Assessments
4. Results and Discussion
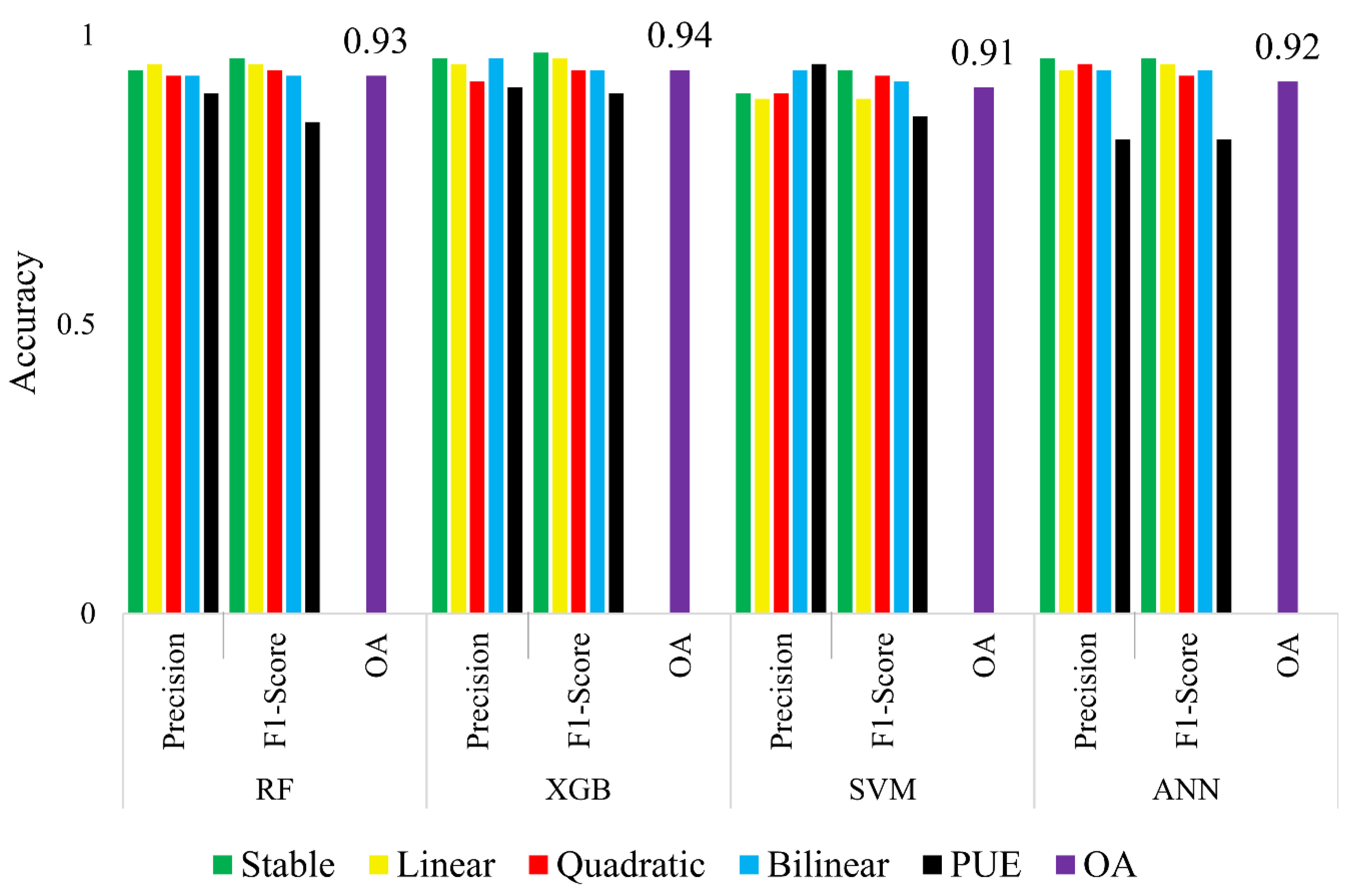
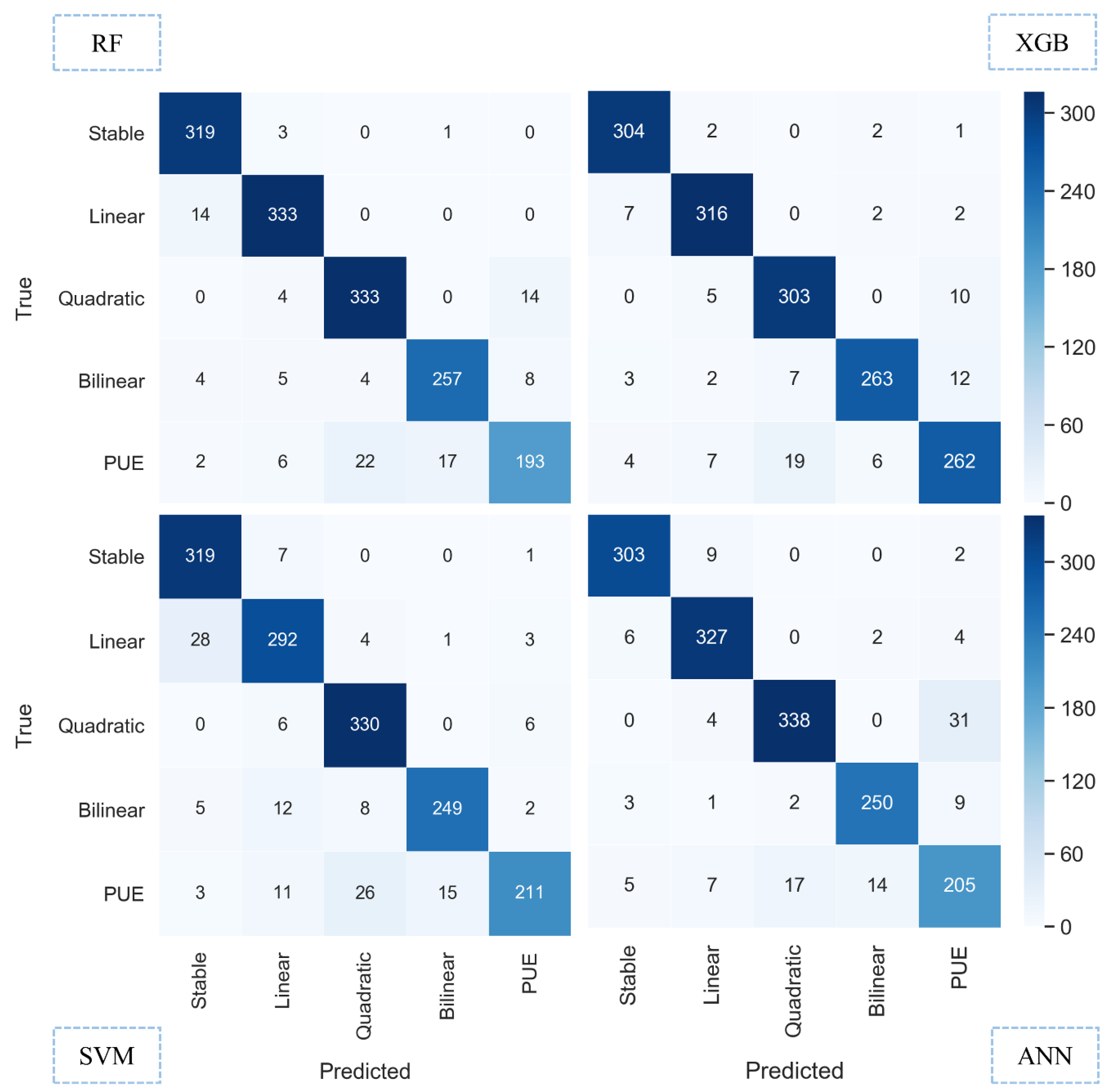
4.1. Classification Performance
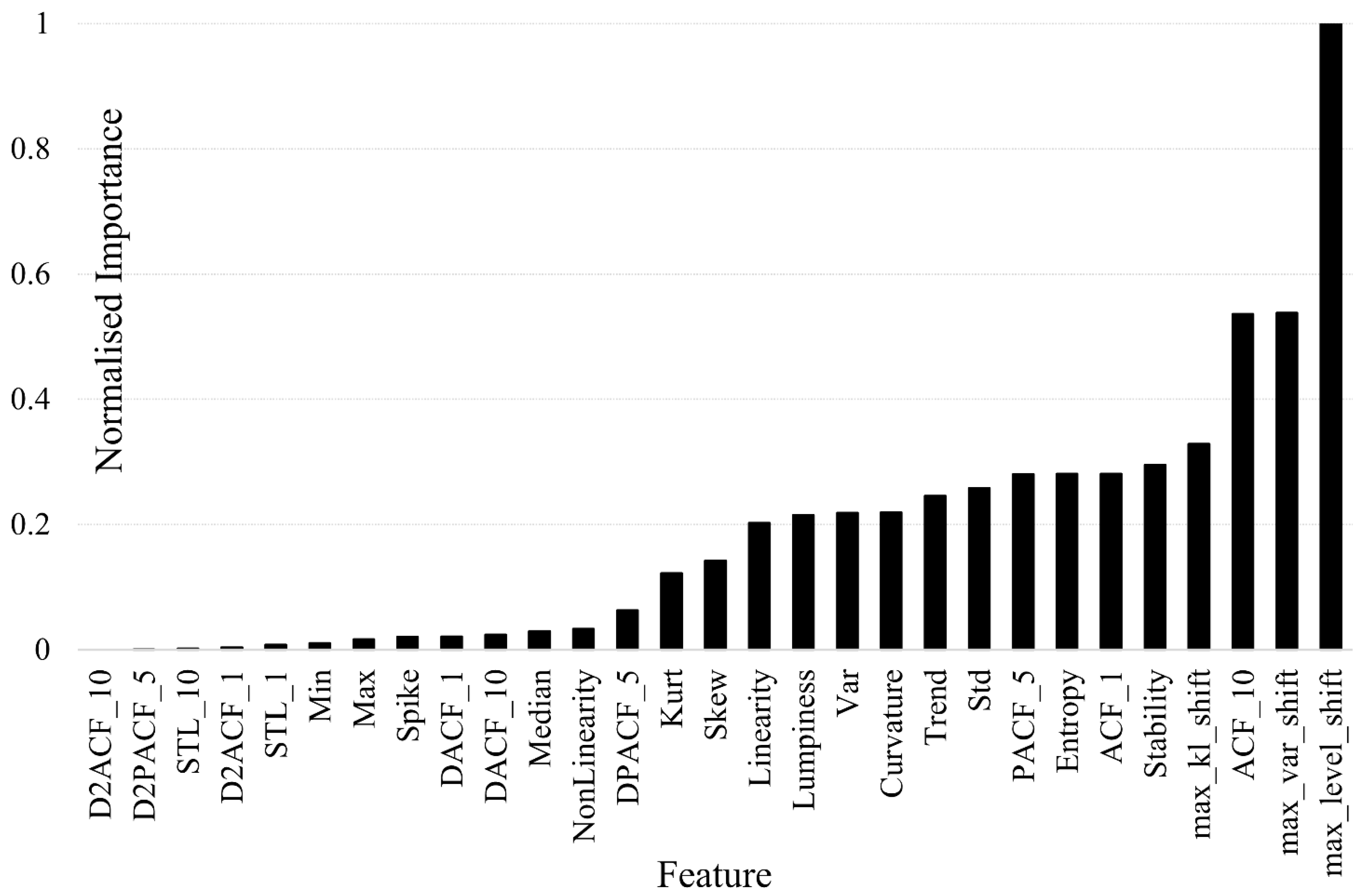
4.2. Feature Importance
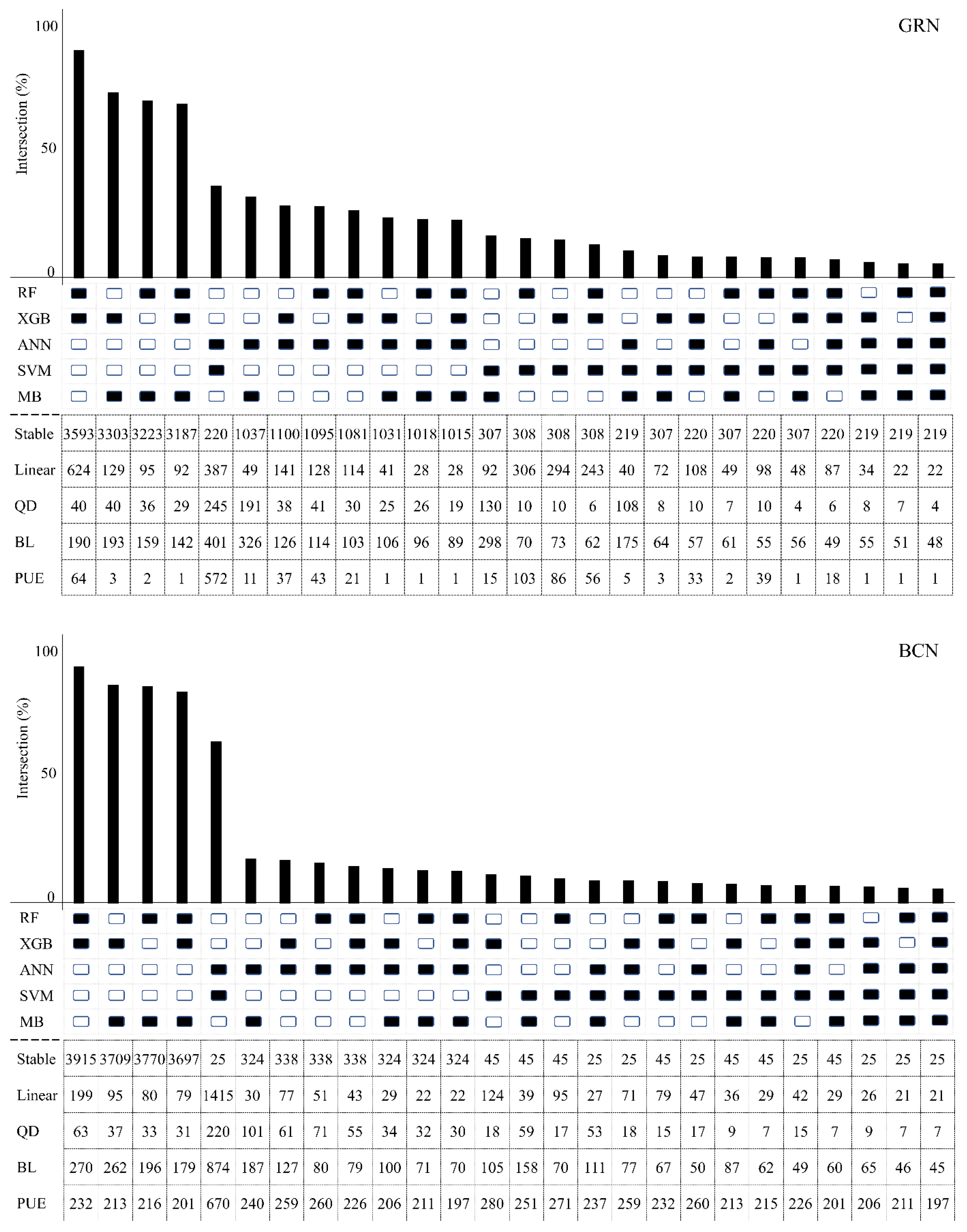
4.3. Validation of Proposed Algorithms
4.4. Comparison of Machine Learning Algorithms with the Model-Based Method
5. Limitations and Future Works
- Only a 1% misclassification may negatively affect the interpretation and decision-making based on the classification outcomes. For this reason, it is recommended to decrease these false alarms using a larger source of reference samples, which enables a more robust classification. Data refinement is also suggested to clean the TSs in terms of noise and errors.
- An unsupervised learning approach is recommended to (1) supply more reference samples for the subsequent supervised classification. This enables the improvement of deformation detection for supervised classifiers by decreasing misclassification. (2) This approach is also recommended for exploring further classes. DInSAR experts proposed the five trends of this study based on their experience. Thus, unsupervised learning will be considered to obtain further information on deformation TS classes.
- Despite the proposed five classes, the adopted algorithms can be used to classify particular cases of TS. Although the prevalent trends (including uncorrelated, linear, and nonlinear) were used in this research, a different trend can be detected by the proposed models. For instance, TS with specific anomalies may provide interesting case studies that illustrate significant movements in the final sections of TSs, enabling a continuous monitoring framework with fast update times to detect changes in the analysed TSs.
- Further improvements may be achieved by utilizing more advanced algorithms, such as CNN and Recurrent Neural Network (RNN). Although the neural networks have longer computational times and greater complexity, more accurate results may be derived for small-scale regions. On the other hand, the RF and XGB algorithms are proposed for deformation identification over wide areas due to the efficient performance in terms of computational time, complexity, and reasonable accuracy.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Crosetto, M.; Solari, L.; Mróz, M.; Balasis-Levinsen, J.; Casagli, N.; Frei, M.; Oyen, A.; Moldestad, D.A.; Bateson, L.; Guerrieri, L.; et al. The Evolution of Wide-Area DInSAR: From Regional and National Services to the European Ground Motion Service. Remote Sens. 2020, 12, 2043. [Google Scholar] [CrossRef]
- European Ground Motion Service. Available online: https://land.copernicus.eu/pan-european/european-ground-motion-service (accessed on 30 May 2022).
- Cigna, F.; Del Ventisette, C.; Liguori, V.; Casagli, N. Advanced Radar-Interpretation of InSAR Time Series for Mapping and Characterization of Geological Processes. Nat. Hazards Earth Syst. Sci. 2011, 11, 865–881. [Google Scholar] [CrossRef]
- Berti, M.; Corsini, A.; Franceschini, S.; Iannacone, J.P. Automated Classification of Persistent Scatterers Interferometry Time Series. Nat. Hazards Earth Syst. Sci. 2013, 13, 1945–1958. [Google Scholar] [CrossRef] [Green Version]
- Mirmazloumi, S.M.; Wassie, Y.; Navarro, J.A.; Palamà, R.; Krishnakumar, V.; Barra, A.; Cuevas-González, M.; Crosetto, M.; Monserrat, O. Classification of Ground Deformation Using Sentinel-1 Persistent Scatterer Interferometry Time Series. GISci. Remote Sens. 2022, 59, 374–392. [Google Scholar] [CrossRef]
- Intrieri, E.; Raspini, F.; Fumagalli, A.; Lu, P.; Del Conte, S.; Farina, P.; Allievi, J.; Ferretti, A.; Casagli, N. The Maoxian Landslide as Seen from Space: Detecting Precursors of Failure with Sentinel-1 Data. Landslides 2018, 15, 123–133. [Google Scholar] [CrossRef] [Green Version]
- Raspini, F.; Bianchini, S.; Ciampalini, A.; Del Soldato, M.; Montalti, R.; Solari, L.; Tofani, V.; Casagli, N. Persistent Scatterers Continuous Streaming for Landslide Monitoring and Mapping: The Case of the Tuscany Region (Italy). Landslides 2019, 16, 2033–2044. [Google Scholar] [CrossRef] [Green Version]
- Brengman, C.M.J.; Barnhart, W.D. Identification of Surface Deformation in InSAR Using Machine Learning. Geochem. Geophys. Geosystems 2021, 22, e2020GC009204. [Google Scholar] [CrossRef]
- Zheng, X.; He, G.; Wang, S.; Wang, Y.; Wang, G.; Yang, Z.; Yu, J.; Wang, N. Comparison of Machine Learning Methods for Potential Active Landslide Hazards Identification with Multi-Source Data. ISPRS Int. J. Geo-Inf. 2021, 10, 253. [Google Scholar] [CrossRef]
- Fadhillah, M.F.; Achmad, A.R.; Lee, C.W. Integration of Insar Time-Series Data and GIS to Assess Land Subsidence along Subway Lines in the Seoul Metropolitan Area, South Korea. Remote Sens. 2020, 12, 3505. [Google Scholar] [CrossRef]
- Novellino, A.; Cesarano, M.; Cappelletti, P.; Di Martire, D.; Di Napoli, M.; Ramondini, M.; Sowter, A.; Calcaterra, D. Slow-Moving Landslide Risk Assessment Combining Machine Learning and InSAR Techniques. Catena 2021, 203, 105317. [Google Scholar] [CrossRef]
- Nava, L.; Monserrat, O.; Catani, F. Improving Landslide Detection on SAR Data through Deep Learning. IEEE Geosci. Remote Sens. Lett. 2021, 19, 4020405. [Google Scholar] [CrossRef]
- Lu, P.; Casagli, N.; Catani, F.; Tofani, V. Persistent Scatterers Interferometry Hotspot and Cluster Analysis (PSI-HCA) for Detection of Extremely Slow-Moving Landslides. Int. J. Remote Sens. 2012, 33, 466–489. [Google Scholar] [CrossRef]
- Liu, Q.; Zhang, Y.; Wei, J.; Wu, H.; Deng, M. HLSTM: Heterogeneous Long Short-Term Memory Network for Large-Scale InSAR Ground Subsidence Prediction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8679–8688. [Google Scholar] [CrossRef]
- Fiorentini, N.; Maboudi, M.; Leandri, P.; Losa, M.; Gerke, M. Surface Motion Prediction and Mapping for Road Infrastructures Management by PS-InSAR Measurements and Machine Learning Algorithms. Remote Sens. 2020, 12, 3976. [Google Scholar] [CrossRef]
- Li, J.; Gao, F.; Lu, J.; Tao, T. Deformation Monitoring and Prediction for Residential Areas in the Panji Mining Area Based on an InSAR Time Series Analysis and the GM-SVR Model. Open Geosci. 2019, 11, 738–749. [Google Scholar] [CrossRef]
- Rouet-Leduc, B.; Jolivet, R.; Dalaison, M.; Johnson, P.A.; Hulbert, C. Autonomous Extraction of Millimeter-Scale Deformation in InSAR Time Series Using Deep Learning. Nat. Commun. 2021, 12, 6480. [Google Scholar] [CrossRef]
- Hakim, W.L.; Achmad, A.R.; Lee, C.W. Land Subsidence Susceptibility Mapping in Jakarta Using Functional and Meta-ensemble Machine Learning Algorithm Based on Time-series Insar Data. Remote Sens. 2020, 12, 3627. [Google Scholar] [CrossRef]
- Bui, D.T.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Pradhan, B.; Chen, W.; Khosravi, K.; Panahi, M.; Ahmad, B.B.; Saro, L. Land Subsidence Susceptibility Mapping in South Korea Using Machine Learning Algorithms. Sensors 2018, 18, 2464. [Google Scholar] [CrossRef] [Green Version]
- Nefeslioglu, H.A.; Tavus, B.; Er, M.; Ertugrul, G.; Ozdemir, A.; Kaya, A.; Kocaman, S. Integration of an InSAR and ANN for Sinkhole Susceptibility Mapping: A Case Study from Kirikkale-Delice (Turkey). ISPRS Int. J. Geo-Inf. 2021, 10, 119. [Google Scholar] [CrossRef]
- Fadhillah, M.F.; Achmad, A.R.; Lee, C.W. Improved Combined Scatterers Interferometry with Optimized Point Scatterers (ICOPS) for Interferometric Synthetic Aperture Radar (InSAR) Time-Series Analysis. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5220014. [Google Scholar] [CrossRef]
- Anantrasirichai, N.; Biggs, J.; Albino, F.; Bull, D. A Deep Learning Approach to Detecting Volcano Deformation from Satellite Imagery Using Synthetic Datasets. Remote Sens. Environ. 2019, 230, 111179. [Google Scholar] [CrossRef] [Green Version]
- Anantrasirichai, N.; Biggs, J.; Albino, F.; Hill, P.; Bull, D. Application of Machine Learning to Classification of Volcanic Deformation in Routinely Generated InSAR Data. J. Geophys. Res. Solid Earth 2018, 123, 6592–6606. [Google Scholar] [CrossRef] [Green Version]
- Jones, L.; Hobbs, P. The Application of Terrestrial LiDAR for Geohazard Mapping, Monitoring and Modelling in the British Geological Survey. Remote Sens. 2021, 13, 395. [Google Scholar] [CrossRef]
- Van Veen, M.; Jean Hutchinson, D.; Bonneau, D.A.; Sala, Z.; Ondercin, M.; Lato, M. Combining Temporal 3-D Remote Sensing Data with Spatial Rockfall Simulations for Improved Understanding of Hazardous Slopes within Rail Corridors. Nat. Hazards Earth Syst. Sci. 2018, 18, 2295–2308. [Google Scholar] [CrossRef] [Green Version]
- Ge, Y.; Tang, H.; Gong, X.; Zhao, B.; Lu, Y.; Chen, Y.; Lin, Z.; Chen, H.; Qiu, Y. Deformation Monitoring of Earth Fissure Hazards Using Terrestrial Laser Scanning. Sens. 2019, 19, 1463. [Google Scholar] [CrossRef] [Green Version]
- Gailler, L.; Labazuy, P.; Régis, E.; Bontemps, M.; Souriot, T.; Bacques, G.; Carton, B. Validation of a New UAV Magnetic Prospecting Tool for Volcano Monitoring and Geohazard Assessment. Remote Sens. 2021, 13, 894. [Google Scholar] [CrossRef]
- Ge, Y.; Cao, B.; Tang, H. Rock Discontinuities Identification from 3D Point Clouds Using Artificial Neural Network. Rock Mech. Rock Eng. 2022, 55, 1705–1720. [Google Scholar] [CrossRef]
- Gaddes, M.E.; Hooper, A.; Bagnardi, M. Using Machine Learning to Automatically Detect Volcanic Unrest in a Time Series of Interferograms. J. Geophys. Res. Solid Earth 2019, 124, 12304–12322. [Google Scholar] [CrossRef] [Green Version]
- Van De Kerkhof, B.; Pankratius, V.; Chang, L.; Van Swol, R.; Hanssen, R.F. Individual Scatterer Model Learning for Satellite Interferometry. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1273–1280. [Google Scholar] [CrossRef]
- Ansari, H.; Rubwurm, M.; Ali, M.; Montazeri, S.; Parizzi, A.; Zhu, X.X. InSAR Displacement Time Series Mining: A Machine Learning Approach. In Proceedings of the IGARSS 2021 IEEE International Geoscience and Remote Sensing Symposium, German Aerospace Center, Brussels, Belgium, 11–16 July 2021; pp. 3301–3304. [Google Scholar]
- Shahabi, H.; Rahimzad, M.; Piralilou, S.T.; Ghorbanzadeh, O.; Homayouni, S.; Blaschke, T.; Lim, S.; Ghamisi, P. Unsupervised Deep Learning for Landslide Detection from Multispectral Sentinel-2 Imagery. Remote Sens. 2021, 13, 4698. [Google Scholar] [CrossRef]
- Gagliardi, V.; Tosti, F.; Bianchini Ciampoli, L.; D’Amico, F.; Alani, A.M.; Battagliere, M.L.; Benedetto, A. Monitoring of Bridges by MT-InSAR and Unsupervised Machine Learning Clustering Techniques. Earth Resour. Environ. Remote Sens./GIS Appl. XII 2021, 11863, 132140. [Google Scholar]
- Zhang, Y.; Tang, J.; He, Z.Y.; Tan, J.; Li, C. A Novel Displacement Prediction Method Using Gated Recurrent Unit Model with Time Series Analysis in the Erdaohe Landslide. Nat. Hazards 2021, 105, 783–813. [Google Scholar] [CrossRef]
- Lattari, F.; Rucci, A.; Matteucci, M. A Deep Learning Approach for Change Points Detection in InSAR Time Series. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5223916. [Google Scholar] [CrossRef]
- Ma, P.; Zhang, F.; Lin, H. Prediction of InSAR Time-Series Deformation Using Deep Convolutional Neural Networks. Remote Sens. Lett. 2020, 11, 137–145. [Google Scholar] [CrossRef]
- Radman, A.; Akhoondzadeh, M.; Hosseiny, B. Integrating InSAR and Deep-Learning for Modeling and Predicting Subsidence over the Adjacent Area of Lake Urmia, Iran. GISci. Remote Sens. 2021, 58, 1413–1433. [Google Scholar] [CrossRef]
- Hill, P.; Biggs, J.; Ponce-López, V.; Bull, D. Time-Series Prediction Approaches to Forecasting Deformation in Sentinel-1 InSAR Data. J. Geophys. Res. Solid Earth 2021, 126, e2020JB020176. [Google Scholar] [CrossRef]
- Kulshrestha, A.; Chang, L.; Stein, A. Use of LSTM for Sinkhole-Related Anomaly Detection and Classification of InSAR Deformation Time Series. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4559–4570. [Google Scholar] [CrossRef]
- Devanthéry, N.; Crosetto, M.; Monserrat, O.; Cuevas-González, M.; Crippa, B. An Approach to Persistent Scatterer Interferometry. Remote Sens. 2014, 6, 6662–6679. [Google Scholar] [CrossRef] [Green Version]
- Xing, Z.; Pei, J.; Keogh, E. A Brief Survey on Sequence Classification. ACM SIGKDD Explor. Newsl. 2010, 12, 40–48. [Google Scholar] [CrossRef]
- Ding, X.; Liu, J.; Yang, F.; Cao, J. Random Radial Basis Function Kernel-Based Support Vector Machine. J. Frankl. Inst. 2021, 358, 10121–10140. [Google Scholar] [CrossRef]
- Bagheri, M.A.; Gao, Q.; Escalera, S. Support Vector Machines with Time Series Distance Kernels for Action Classification. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV 2016), Lake Placid, NY, USA, 7–10 March 2016. [Google Scholar]
- Newberg, L.A. Memory-Efficient Dynamic Programming Backtrace and Pairwise Local Sequence Alignment. Bioinformatics 2008, 24, 1772–1778. [Google Scholar] [CrossRef] [Green Version]
- Cuturi, M.; Vert, J.P.; Birkenes, Ø.; Matsui, T. A Kernel for Time Series Based on Global Alignments. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing—Proceedings, Honolulu, HI, USA, 15–20 April 2007; Volume 2. [Google Scholar]
- Needleman, S.B.; Wunsch, C.D. A General Method Applicable to the Search for Similarities in the Amino Acid Sequence of Two Proteins. J. Mol. Biol. 1970, 48, 443–453. [Google Scholar] [CrossRef]
- González, S.; García, S.; Del Ser, J.; Rokach, L.; Herrera, F. A Practical Tutorial on Bagging and Boosting Based Ensembles for Machine Learning: Algorithms, Software Tools, Performance Study, Practical Perspectives and Opportunities. Inf. Fusion 2020, 64, 205–237. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Jain, A.K.; Mao, J.; Mohiuddin, K.M. Artificial Neural Networks: A Tutorial. Comput. (Long. Beach. Calif). 1996, 29, 31–44. [Google Scholar] [CrossRef] [Green Version]
- Graupe, D. Principles of Artificial Neural Networks; World Scientific: Singapore, 2013; Volume 7. [Google Scholar]
- Goldberger, J.; Roweis, S.; Hinton, G.; Salakhutdinov, R. Neighbourhood Components Analysis. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 13 December 2004. [Google Scholar]
- Hyndman, R.; Athanasopoulos, G. Forecasting: Principles and Practice, 3rd ed.; OTexts: Melbourne, Australia, 2021. [Google Scholar]
- Box, G.; Jenkins, G.; Reinsel, G.; Ljung, G. Time Series Analysis: Forecasting and Control, 5th ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2015. [Google Scholar]
- Cleveland, R.; Cleveland, W.; McRae, J.; Stat, I.T. STL: A Seasonal-Trend Decomposition. J. Off. Stat. 1990, 6, 3–73. [Google Scholar]
- Kang, Y.; Hyndman, R.J.; Smith-Miles, K. Visualising Forecasting Algorithm Performance Using Time Series Instance Spaces. Int. J. Forecast. 2017, 33, 345–358. [Google Scholar] [CrossRef] [Green Version]
- Teräsvirta, T. Specification, Estimation, and Evaluation of Smooth Transition Autoregressive Models. J. Am. Stat. Assoc. 1994, 89, 208–218. [Google Scholar] [CrossRef]
- Lex, A.; Gehlenborg, N.; Strobelt, H.; Vuillemot, R.; Pfister, H. UpSet: Visualization of Intersecting Sets. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1983–1992. [Google Scholar] [CrossRef]
- Notti, D.; Galve, J.P.; Mateos, R.M.; Monserrat, O.; Lamas-Fernández, F.; Fernández-Chacón, F.; Roldán-García, F.J.; Pérez-Peña, J.V.; Crosetto, M.; Azañón, J.M. Human-Induced Coastal Landslide Reactivation. Monitoring by PSInSAR Techniques and Urban Damage Survey (SE Spain). Landslides 2015, 12, 1007–1014. [Google Scholar] [CrossRef]
- Mateos, R.M.; Azañón, J.M.; Roldán, F.J.; Notti, D.; Pérez-Peña, V.; Galve, J.P.; Pérez-García, J.L.; Colomo, C.M.; Gómez-López, J.M.; Montserrat, O.; et al. The Combined Use of PSInSAR and UAV Photogrammetry Techniques for the Analysis of the Kinematics of a Coastal Landslide Affecting an Urban Area (SE Spain). Landslides 2017, 14, 743–754. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Satellite | #Observations in TS | Acquisition Span | Duration (Days) | Average Interval (Days) |
|---|---|---|---|---|---|
| GRN | Sentinel-1 | 138 | 10 March 2015–26 September 2018 | 1296 | 9.4 |
| BCN | Sentinel-1 | 249 | 06 March 2015–19 June 2020 | 1926 | 7.7 |
| IBZ | Sentinel-1 | 171 | 01 January 2017–27 February 2020 | 1152 | 6.7 |
| Category | #Features | Features |
|---|---|---|
| General | 7 | var, std, median, min, max, skewness, kurtosis |
| Autocorrelation Function (ACF) | 6 | ACF_1, ACF_10, DACF_1, DACF_10, D2ACF_1, D2ACF_10 |
| Partial Autocorrelation Function (PACF) | 3 | PACF_5, DPACF_5, D2PACF_5 |
| Seasonal and Trend Decomposition Using LOESS (STL) | 6 | trend, spike, linearity, curvature, STL_1, STL_10 |
| Other | 7 | nonlinearity, entropy, lumpiness, stability, max_level_shift, max_var_shift, max_kl_shift |
| Algorithm | Parameters | Description |
|---|---|---|
| SVM | c = 1 | regularisation parameter |
| kernel = rbf | Radial Basis Function (RBF) maps input data | |
| gamma = auto | kernel coefficient | |
| SVM-DTW | c = 1 | regularisation parameter |
| kernel = gak | Radial Basis Function (RBF) maps the input data | |
| gamma = auto | GAK function for mapping input data | |
| RF | n_estimators = 150 | number of trees |
| criterion = gini | a function to measure the quality of a split | |
| max_depth = none | maximum depth of trees | |
| random_state = 10 | controls the randomness of input samples | |
| XGB | learning_rate = 0.3 booster = gbtree | shrinks the contribution of trees tree-based model to run at each iteration |
| ANN | hidden_layer_sizes = 3 | number of hidden layers apart from input and output layers |
| hidden_layer_neurons= [0,100] | number of neurons in each hidden layer | |
| activation = relu | the rectified linear unit function, returns f(x) = max (0, x) | |
| solver = adam | the solver for weight optimisation | |
| learning_rate = 0.001 | controls the step-size in updating the weights | |
| alpha = 0.0001 | regularisation term | |
| KNN | n_neighbours = 5 | number of neighbours for queries. |
| weights = distance | weight points by the inverse of their distance | |
| metric = minkowski | the distance metric to use for the tree |
| Model | ||||||
|---|---|---|---|---|---|---|
| SVM | SVM-DTW | RF | XGB | ANN | KNN | |
| OA | 0.82 | 0.83 | 0.84 | 0.83 | 0.9 | 0.78 |
| Computational Speed | 190 | 37 | 296 | 288 | 218 | 152 |
| Model | ||||
|---|---|---|---|---|
| Class | RF | XGB | SVM | ANN |
| Stable | ||||
| Linear | ||||
| Quadratic | ||||
| Bilinear | ||||
| PUE | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mirmazloumi, S.M.; Gambin, A.F.; Palamà, R.; Crosetto, M.; Wassie, Y.; Navarro, J.A.; Barra, A.; Monserrat, O. Supervised Machine Learning Algorithms for Ground Motion Time Series Classification from InSAR Data. Remote Sens. 2022, 14, 3821. https://doi.org/10.3390/rs14153821
Mirmazloumi SM, Gambin AF, Palamà R, Crosetto M, Wassie Y, Navarro JA, Barra A, Monserrat O. Supervised Machine Learning Algorithms for Ground Motion Time Series Classification from InSAR Data. Remote Sensing. 2022; 14(15):3821. https://doi.org/10.3390/rs14153821
Chicago/Turabian StyleMirmazloumi, S. Mohammad, Angel Fernandez Gambin, Riccardo Palamà, Michele Crosetto, Yismaw Wassie, José A. Navarro, Anna Barra, and Oriol Monserrat. 2022. "Supervised Machine Learning Algorithms for Ground Motion Time Series Classification from InSAR Data" Remote Sensing 14, no. 15: 3821. https://doi.org/10.3390/rs14153821
APA StyleMirmazloumi, S. M., Gambin, A. F., Palamà, R., Crosetto, M., Wassie, Y., Navarro, J. A., Barra, A., & Monserrat, O. (2022). Supervised Machine Learning Algorithms for Ground Motion Time Series Classification from InSAR Data. Remote Sensing, 14(15), 3821. https://doi.org/10.3390/rs14153821