1. Introduction
The multimodal remote sensing image matching is a critical and challenging prerequisite in computer vision and remote sensing applications [
1] such as UAV positioning [
2], image mosaic, image fusion [
3,
4], object detection, and environment surveillance. The primary goal of multimodal remote sensing image matching is the process to obtain the accurate correspondences between the reference image and sensed image with overlapping regions, and to geometrically align these images. However, it is still an ill-posed problem that suffers from many uncertainties due to the differences in sensor devices, viewpoints, and imaging conditions [
5]. Thus, for the same scene, the multimodal remote sensing images have quite different expressions, especially nonlinear radiation distortions (NRD), and this issue seriously affects image matching reliability and accuracy.
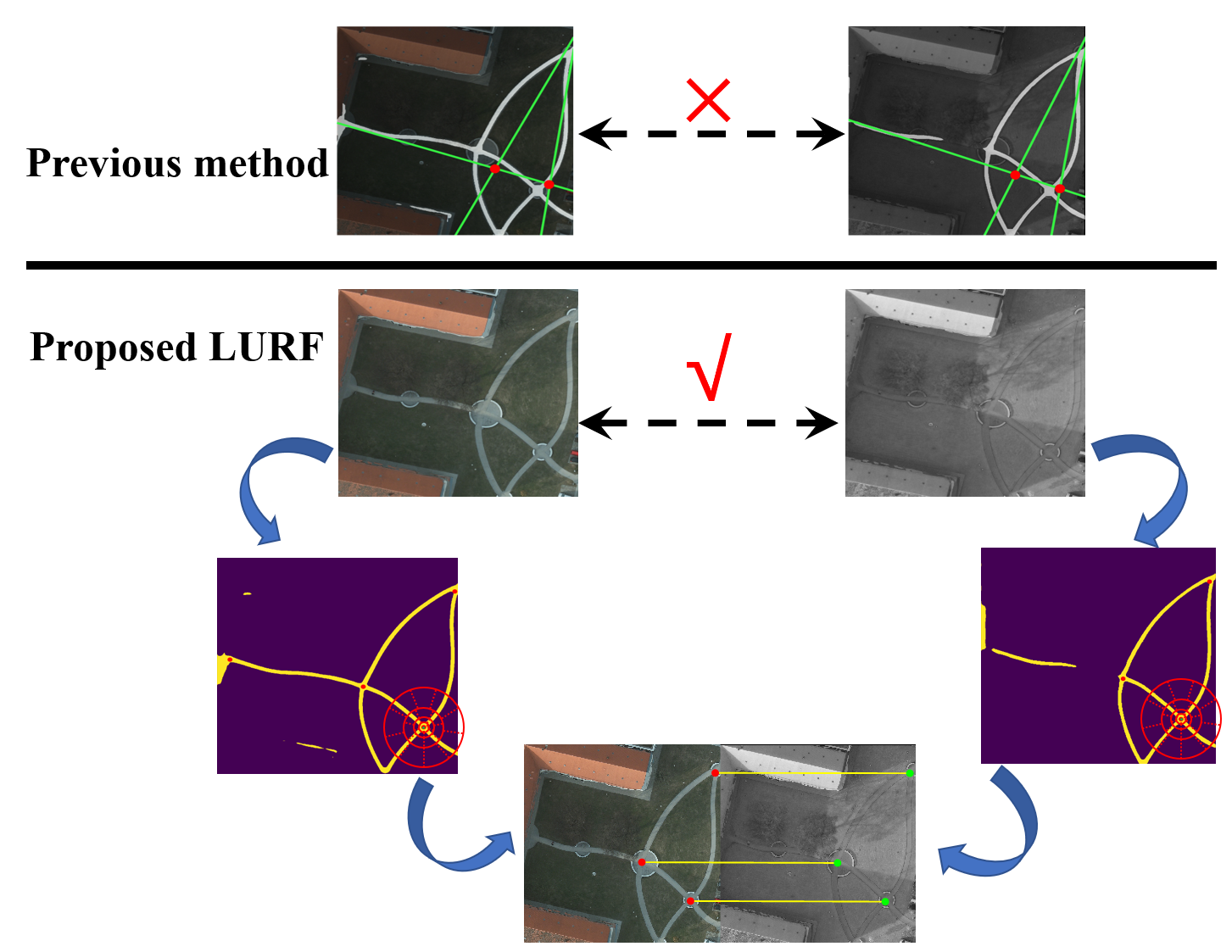
To alleviate the difficulty mentioned above, in our previous work, the triangular features have been proposed [
6] for multimodal urban remote sensing image matching and has good robustness and efficienc based on semantic road features. On the contrary, its application limitations are obvious, which are embodied in the following aspects:
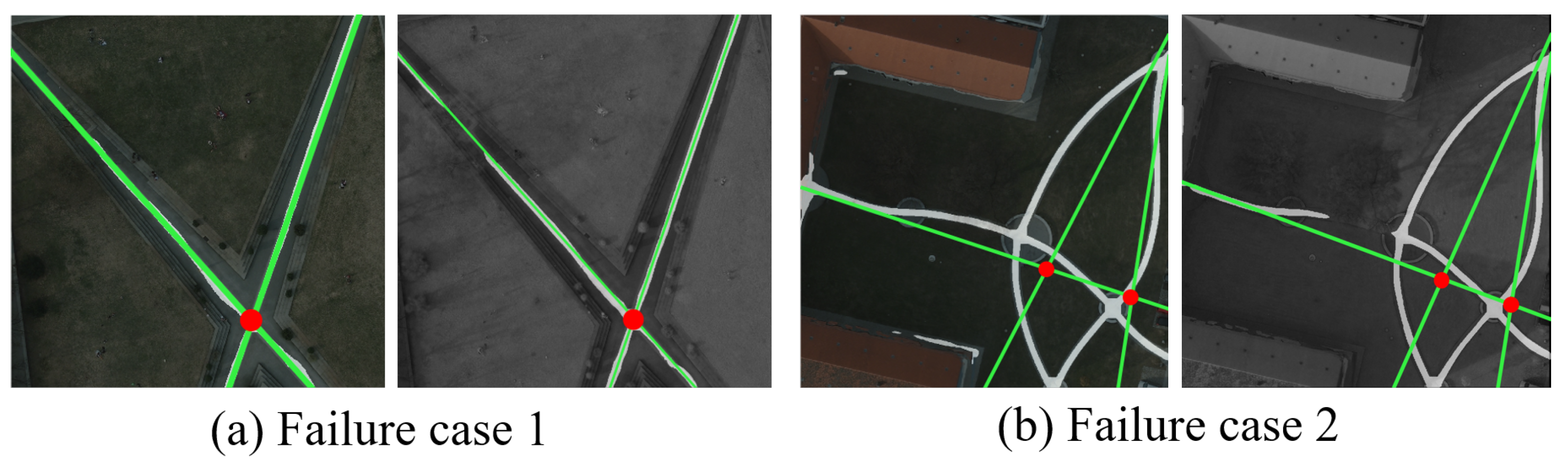
(1) The triangular feature construction and matching needs more than three road intersection points. When the number of detected road intersection points is only one or two, the method cannot construct and describe the feature information, resulting in a complete matching failure as seen in
Figure 1a.
(2) When fitting the straight-line features of semantic road information, the performance of curve fitting is poor which directly affects the matching success and accuracy as seen in
Figure 1b.
To address these issues, in this paper we propose a novel matching method named LURF via learned unstructured road features for multimodal remote sensing images. This article is an extension of our earlier published work [
6]. The proposed method, LURF, is general and efficient, which can handle both very few feature points (even just one feature point) and road curve information with poor linear fitting. LURF also has good robustness for parameter estimation of nonlinear roads. The main contributions of this paper can be listed as follows:
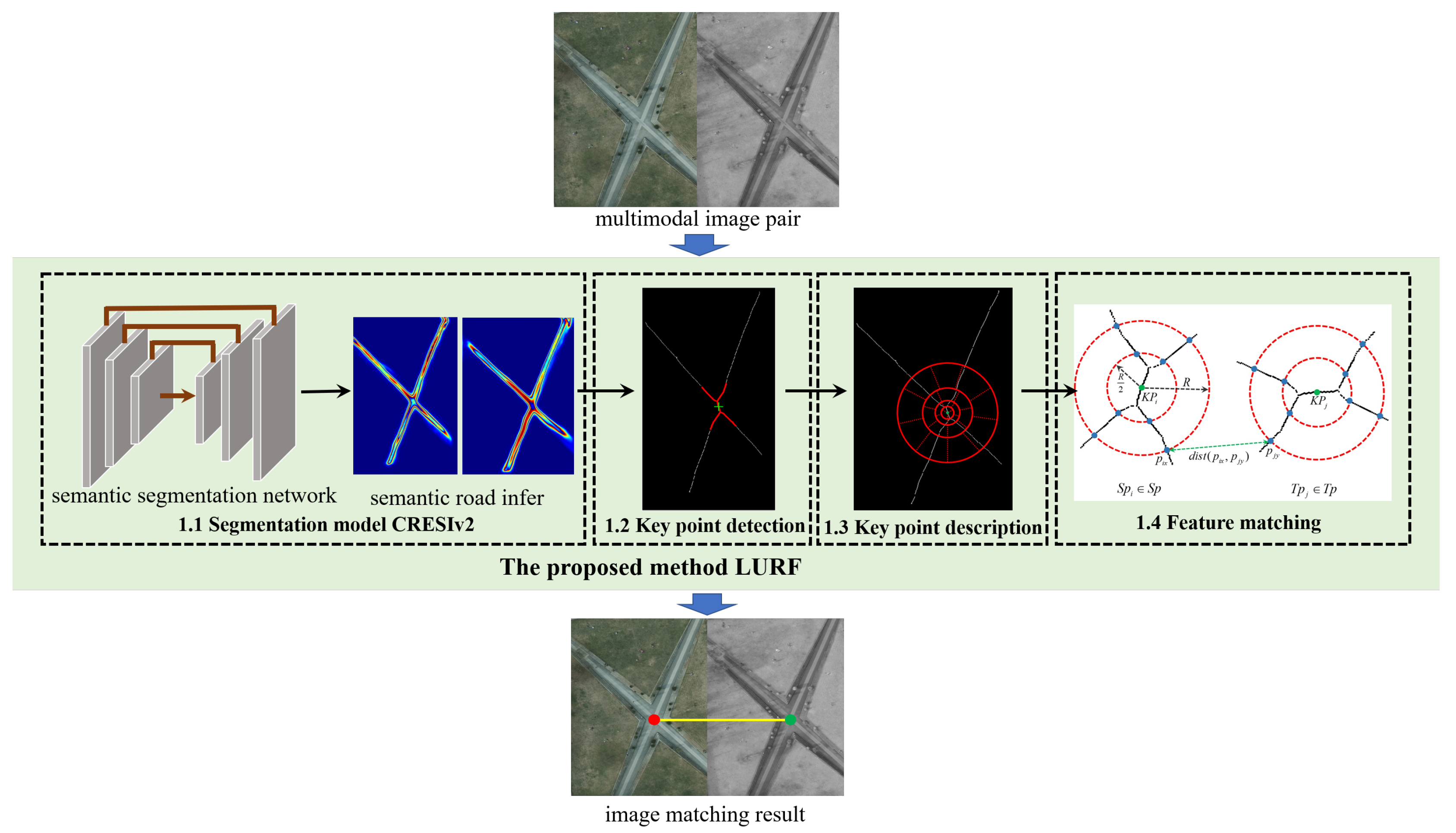
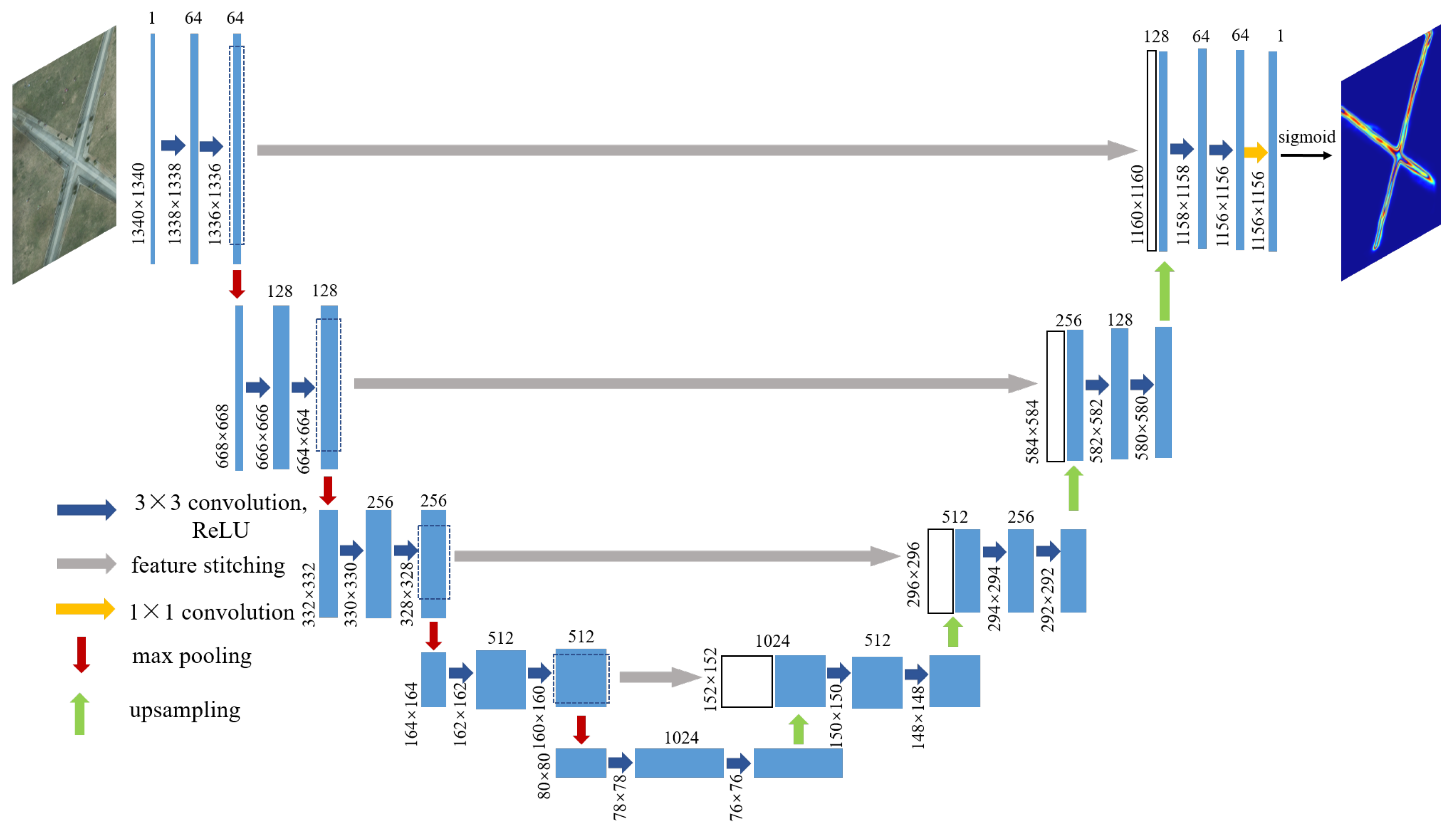
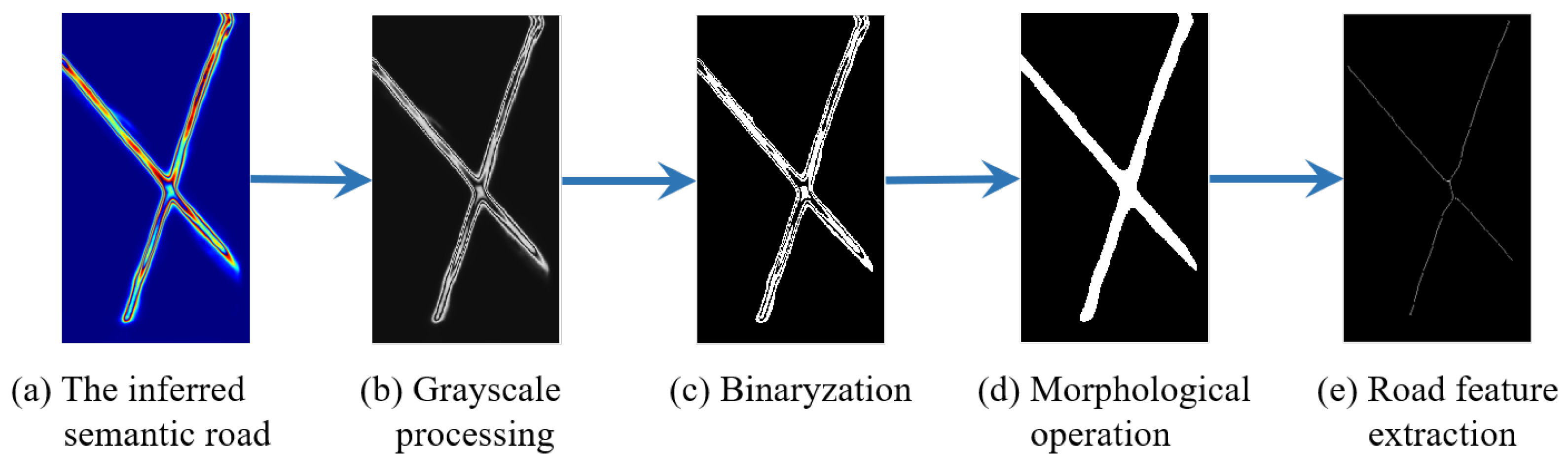
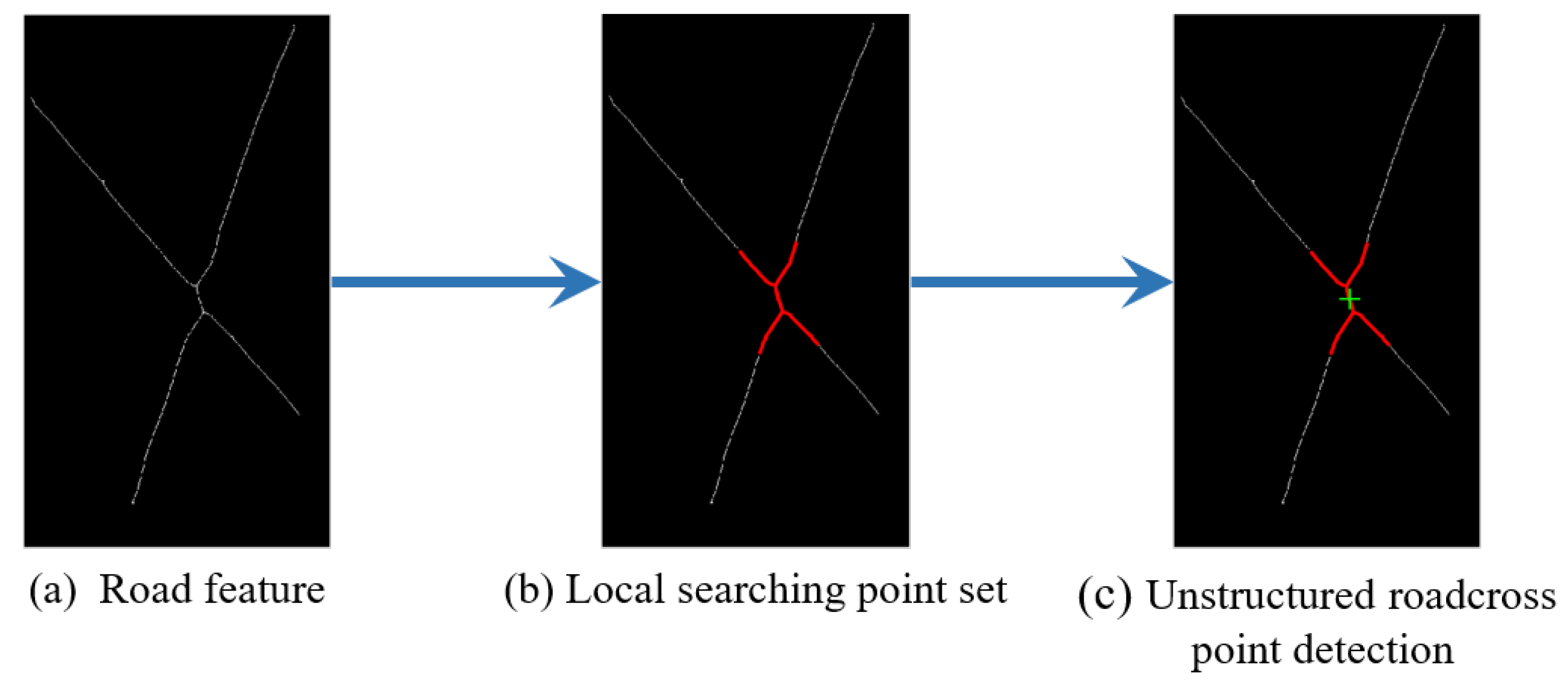
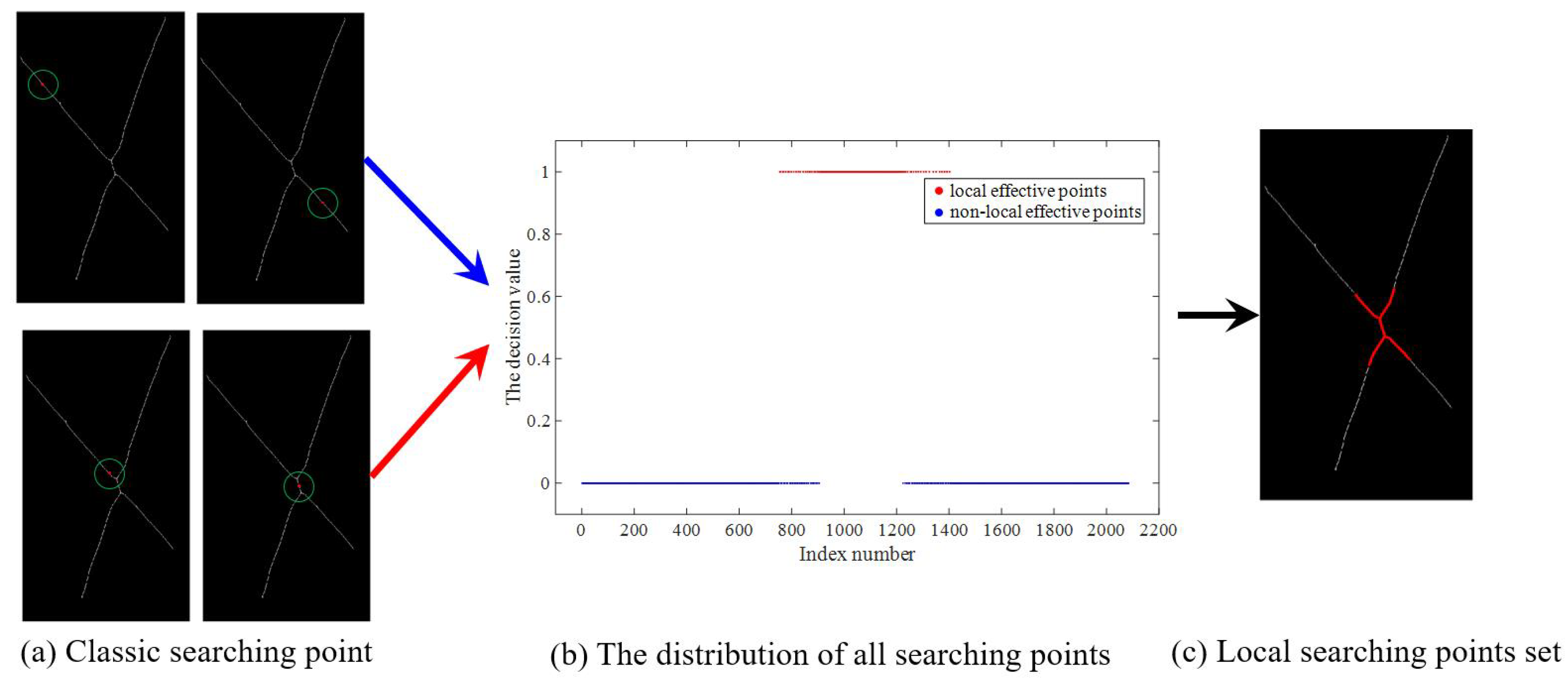
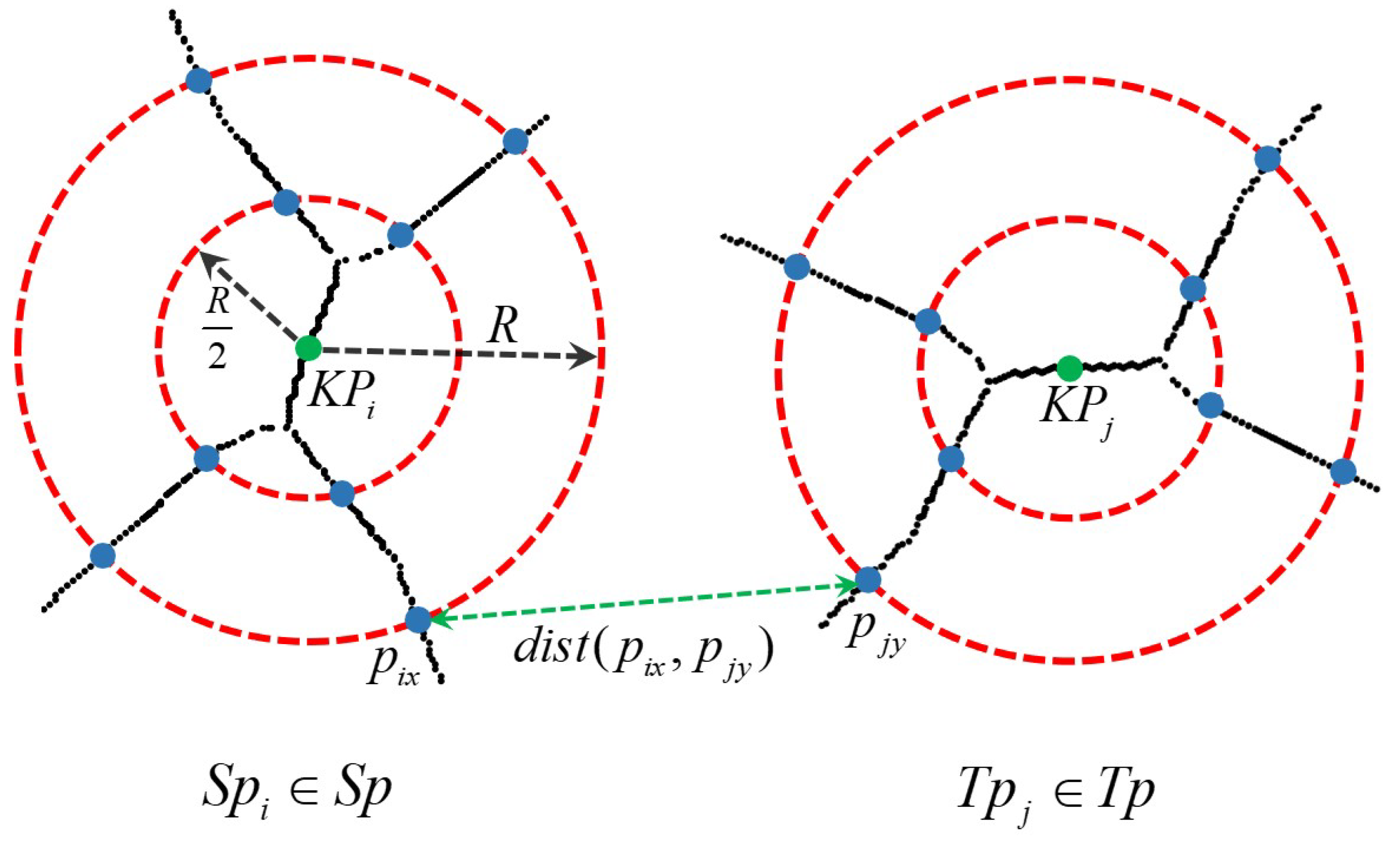
(1) The semantic road features were extracted from multimodal remote sensing images based on the segmentation model CRESIv2. Based on semantic road features, a stable and reliable intersection point detector has been proposed to detect unstructured key points.
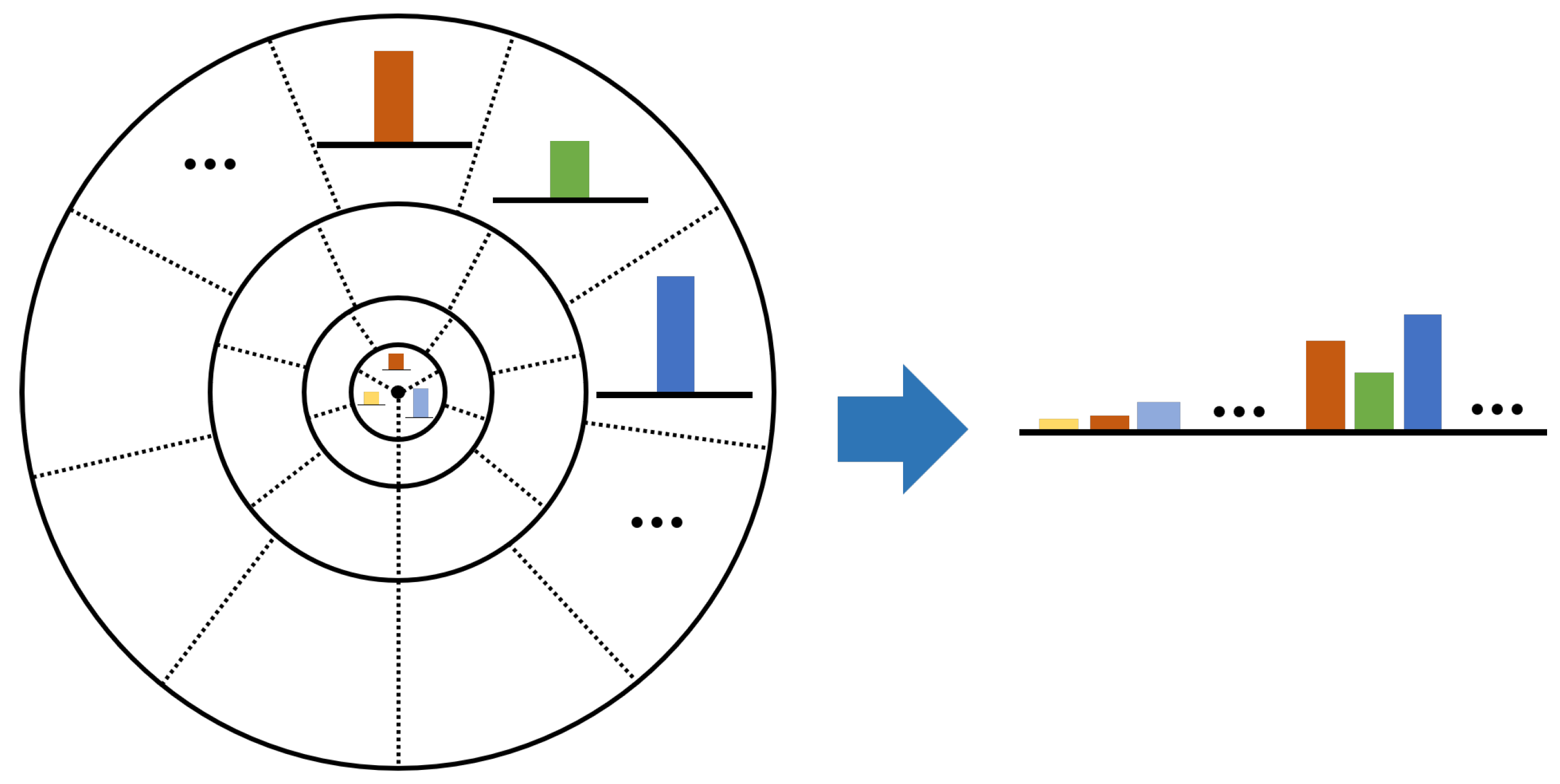
(2) A local binary entropy descriptor has been designed to describe key points with the local skeleton feature. The local binary entropy descriptor dimension is smaller, but its efficiency is higher.
(3) A global optimization strategy is adopted to achieve the correct matching.
(4) Our proposed method LURF has been validated on publicly available datasets, and LURF obtains better results than other state-of-the-art methods in terms of both accuracy and efficiency.
The remainder of this article is organized as follows: The related works of image matching for multimodal remote sensing images are reviewed in
Section 1.
Section 2 introduces the proposed matching method LURF. In
Section 3, the experimental results and corresponding analyses are exhibited. Finally,
Section 4 discusses the experiments and concludes this article.
2. Related Works
Multi-modal image matching has always been a hot research issue and many scholars involved in the study of multimodal remote sensing image matching problems in the past few decades [
7]. Generally, the multimodal remote sensing image matching methods can be mainly divided into two categories [
8]: area-based methods and feature-based methods. Area-based methods [
9,
10] usually attempt to search for the optimal geometric transform with a specified similarity metric and depend on an appropriate patch similarity measurement for pixel-level matching parameter estimation between the multimodal image pairs, and the distinctive information is provided by pixel intensities rather than by structure features. These methods generally can be classified into three types: correlation-like methods [
11], Fourier methods [
12], and mutual information methods [
13]. Correlation-like methods such as cross-correlation are classical area-based methods [
14]. The main idea of correlation-like methods is to compute the similarities of an overlapping region in the reference image and sensed image pairs, and consider the largest similarity as a correspondence. However, correlation-like methods have some drawbacks such as high computational complexity and the flatness of the similarity measure in textureless areas. Fourier methods adopt the Fourier representation of the multimodal image in the frequency domain. In Fourier methods, a commonly used technique is the phase correlation method based on the Fourier shift theorem, which was later extended to account for rotation and scaling [
15]. These Fourier methods have some advantages such as computational efficiency and noise robustness than correlation-like methods. In addition, the mutual information (MI) methods can provide an attractive metric for maximizing the dependence, which is robust to NDR to a certain extent. However, MI method has a large amount of calculation, low efficiency, and is easy to fall into local extremum. Based on MI method, some improved methods have been proposed such as normalized mutual information (NMI) [
16], entropy correlation coefficient (ECC) [
17].
Compared with area-based methods, the feature-based methods have higher efficiency and better adaptability via point features, line features, contours features, or region features. The matching process of feature-based methods usually includes feature point detection, feature point description, and mismatching elimination [
18]. The classic and representative method is scale-invariant feature transform(SIFT) [
19]. SIFT can extract feature points in a DoG pyramid and filter feature points using the Hessian matrix of the local intensity values. On the basis of SIFT, the speed-up robust feature (SURF) [
20] has been proposed. By approximating the Hessian matrix-based detector using Haar wavelet calculation, SURF can accelerate the SIFT, significantly. In order to detect and extract more robust feature points, HOPC [
21] and DLSS [
22] are proposed based on phase congruency. However, HOPC relies on accurate geographic information which is essentially a template matching method. HOPC is only designed for a slight translation and it is very sensitive to scale and rotation transformations. Based on HOPC, Li [
23] proposed a feature matching method radiation-variation insensitive feature transform (RIFT). RIFT adopts phase congruency information instead of image intensity for feature point detection, and constructs a maximum index map (MIM) based on the log-Gabor convolution sequence for feature description. RIFT can detect and descript robust tie-points between multimodal remote sensing image pairs. However, RIFT does not build a scale space, and it cannot be applied to all scale scenes when the scales of the multimodal image are inconsistent. Chen [
24] proposed a partial intensity invariant feature descriptor (PIIED) method for multimodal remote sensing images via symmetrical gradient direction histogram. EHD [
25] adopts the edges orientation response of multioriented Sobel spatial filter. Based on the local EHD descriptor, the log-Gabor histogram descriptor(LGHD) [
26] is proposed by using a multi-scaled and multi-oriented log-Gabor filter to replace the multi-oriented spatial filter, but LGHD is easy to suffers from low efficiency and high dimensionality.
Different from the traditional feature-based multimodal remote sensing image matching methods, learning-based feature matching methods have developed rapidly [
27]. MatchNet [
28] uses the deep convolutional neural network to learn local patch feature description and feature comparison. LIFT [
29] uses the deep learning network to realize the complete image feature matching process and uses the Siamese network to realize the detection and description of feature points and direction estimation. An image matching method based on regularization generation adversarial network is proposed [
30]. This method designs a new generative adversarial network for image transformation, and then uses local features to establish multi-source image matching relationships.
Due to the differences in imaging sensors and imaging conditions in multi-modal images, the traditional method of directly detecting and describing key points on the original image has poor robustness and instability. Among them, semantic segmentation information is important feature in multimodal remote sensing image pairs. The corresponding semantic feature is the high-level structure with high similarity of multimodal remote sensing image pairs. The semantic feature has better detection stability and robustness such as semantic road, semantic building, and semantic water area. Although our previous published work has achieved good performance, there are still some limitations such as curved roads. Therefore, this paper proposes a method via learned unstructured road feature (LURF) for multimodal remote sensing image matching, which can effectively address the above limitations.
4. Experimental Results and Analyses
Here, to evaluate the multimodal remote sensing image matching performance of our proposed LURF we compare it with other five state-of-the-art feature matching methods such as SIFT [
19], SURF [
20], EHD [
25], LGHD [
26] and LPM [
39] on two different multimodal remote sensing image data sets. Throughout the qualitative and quantitative evaluation experiments, all six methods’ parameters are all fixed. The experiments are performed on a laptop with 3.4-GHz CPU, 4GB memory, and MATLAB code.
4.1. Data Sets and Evaluation Metrics
The data sets mainly include training data set and test data set. For the training data set, we use the SpaceNet 3 data set [
40] with road label to train our road semantic segmentation network CRESIv2. The data set includes the remote sensing images of Las Vegas, Paris, Shanghai, and Khartoum areas. To improve the generalization of our semantic segmentation network CRESIv2, the selected data sets with road labels contain some wide remote sensing geographic areas from 400 to 3600 square kilometers under different seasons and lighting conditions.
For the test data set, it contains two kinds of remote sensing image pairs with very different imaging styles as shown in
Figure 11. Optical-NIR (near-infrared) image pairs are from the Potsdam data set [
30] which contains 38 patches of equal size. The Potsdam data set mainly includes the multispectrum remote sensing images with a large number of ground repeatable structures and road feature information. Each patch image has the same size 6000 × 6000, and the resolution is about 5 cm/pixel. Furthermore, another test data set is the optical-Intensity image data set. The optical-Intensity image pair as aerial images contain optical spectral band and LiDAR intensity information on the Niagara city area in Canada. The intensity image refers to the echo intensity of laser pulse emitted by the LiDAR sensor, which is mainly related to laser incidence angle, ground reflectance, laser pulse transmission distance, and other factors. Under ideal conditions, the intensity value satisfies the Lambertian reflection model [
41]. Therefore, there are great differences between optical image and intensity image in imaging principle and imaging conditions, and there is serious nonlinear mapping distortion in the grayscale values of the corresponding pixels, this nonlinear mapping distortion will bring a great challenge to the matching methods.
For all image pairs, the optical-NIR image pairs have been strictly aligned to evaluate the accuracy of all methods. While the optical-Intensity image pairs have not been aligned, and there is no true geometric transformation between image pairs. Therefore, quantitative evaluation can only be carried out by using the approximate value as the true value. In the specific operation process, we can manually select multiple uniformly distributed correspondence point pairs in the image pair, and use the Linear Least Squares to estimate the transformation parameters that are close to the true value.
In order to evaluate the matching performance of our proposed method LURF, state-of-the-art methods including SIFT, SURF, LGHD, and LPM are used to compare with LURF on multimodal remote sensing image data sets for qualitative and quantitative evaluations. According to the homography matrix between the image pair, it can be calculated to determine whether the feature points are repetitive, the repeatability
as the evaluation metric can be defined as follows:
where
represents the number of repetitive correspondences,
and
represent the number of feature points in scene image
S and target image
T, respectively.
H is the ground truth transformation between image
S and
T.
and
are the homogeneous coordinates of a feature in
S and
T, respectively.
represents the number of corresponding feature points pairs whose re-projection error less than three pixels.
Moreover, the correct matches rate (CMR) can be chosen as another evaluation criterion. CMR is defined as follows:
where
and
represent the number of correct matching points and total matching point pairs, respectively.
In order to evaluate the registration alignment accuracy of the transformed image, the root mean square error (RMSE), mean error (ME), and the success rate can be adopted as the evaluation metrics.
4.2. Performance with Respect to Feature Point Detection
In this part, to evaluate the feature detection performance of the proposed LURF, a comparison of it with three state-of-the-art feature key point detectors is made, which are SIFT, SURF, and FAST [
42]. Among five comparison methods including SIFT, SURF, EHD, LGHD and LPM, SIFT, and SURF find extreme points as feature points in constructed Gaussian scale space. Both EHD and LGHD chose to use the FAST detector to detect the key points. LPM is used to remove the mismatching relationship when SIFT is usually adopted to establish putative feature correspondences, and its essence is still to use SIFT to detect key points. In order to evaluate the key point detection methods fairly and effectively, the parameters of each comparison method are fine-tuned to obtain the best performance and are consistent in all test image pairs. SIFT is implemented by the open-source VLFEAT toolbox, and other comparison methods are obtained from the authors’ website. The results of our proposed LURF and the comparison methods for detecting key points in test image pairs are shown in
Table 1.
Table 1 has shown the evaluation metrics
and
, the highest repeatability values are highlighted with boldface font. Through observation and comparison, it can be found that
of our LURF maintains a high feature point repetition rate in all test data set, and is more than twice that of other comparison methods. It is worth noting that the number of repetitive correspondences
,
of LURF is not so many and far less than other key point detection comparison methods. The essential reason is that our proposed LURF is closely related to the actual number of intersection points in each multimodal image. Although there are not many intersection points in the image, considering these stable intersection points as key points can greatly improve the repetition rate
of key points and reduce redundant descriptions of a large number of invalid key points. This consideration for key point extraction will greatly improve the matching efficiency.
4.3. Performance with Respect to Matching
To demonstrate the matching performance of our proposed LURF, we compare it with the above five state-of-the-art methods, and the qualitative evaluation of all six methods is shown in
Figure 12 and
Figure 13. To investigate the influence of rotation and scale changes, we test the proposed method on two groups simulated images with different rotation angles and scale factors. The NIR image has affine transformation with rotate transform (
) and scale transform (
s = 0.75), and the intensity image has affine transformation with rotate transform (
) and scale transform (
s = 0.75). In order to fairly compare the performance of all methods, the threshold value of Nearest Neighbor Distance Ratio (NNDR) for SIFT and SURF methods was been set as 0.7. SIFT, SURF, EHD, and LGHD these four comparison methods can adopt Ransac [
43] to remove mismatching point pairs. LPM can remove mismatching point pairs by preserving the local structure consistency of correct correspondences matching. The proposed LURF has a global optimization strategy to achieve the correct match.
4.3.1. Qualitative Comparisons
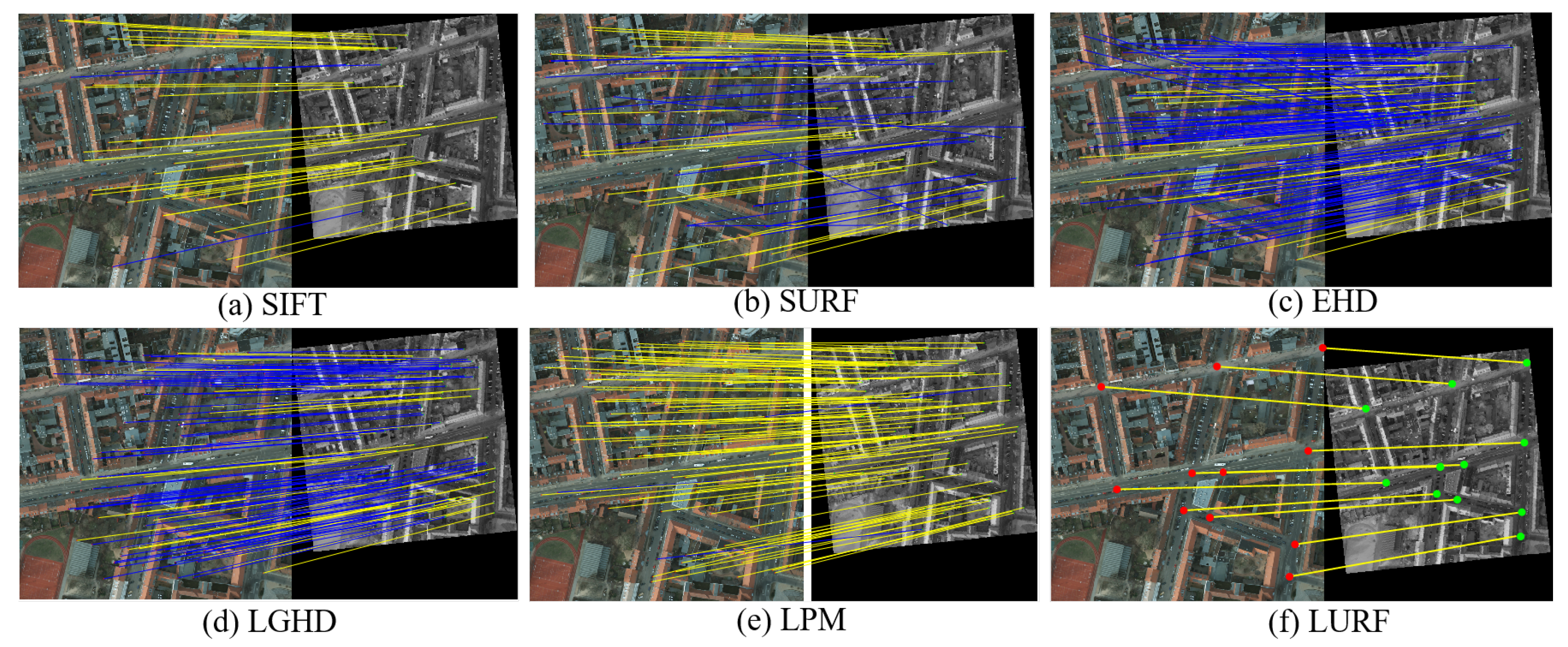
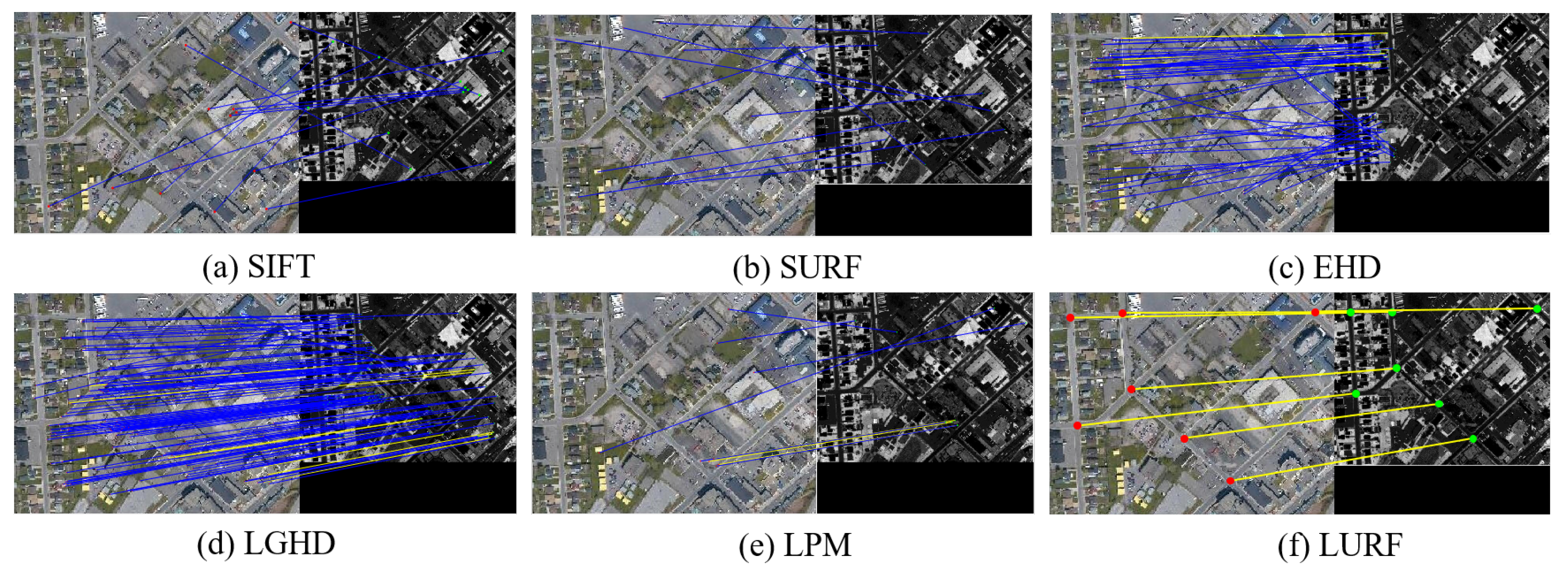
Figure 12 and
Figure 13 show the qualitative comparison results of SIFT, SURF, EHD, LGHD, LPM, and proposed LURF in the sample image pairs from different multimodal data sets. As seen, SIFT, SURF, EHD, LGHD, LPM, and LURF all methods have a certain matching effect on the optical-NIR image pair shown in
Figure 12, and the reason is that the spectrum of the near-infrared image is relatively close to that of optics, the grayscale value of the pixel corresponding to the image satisfies a certain linear mapping relationship, the nonlinear grayscale distortion is not obvious, and the details in the optical-NIR image pair have certain common characteristics. Among all methods, our proposed method LURF has obvious advantages and can accurately extract almost all intersection points as key points for matching. LURF has a high matching accuracy than the other five comparison methods. At the same time, we can also see that EHD has the least number of correct matches in all comparison methods, followed by the LGHD. The number of correct matches of LPM is significantly higher than other comparison methods, but there are still a small number of mismatching point pairs.
Due to the serious nonlinear grayscale distortion between the image pairs as seen in
Figure 13, the number of correct matching point pairs in the image pair by all comparison methods is less than four, so the transformation matrix cannot be effectively and accurately estimated, and the image matching task can be regarded as a failure. In contrast, our proposed method LURF still achieves a good matching performance, despite serious differences in optical-Intensity image styles. The comparison method such as SIFT seems powerless in this case, the robustness of comparison methods is greatly reduced.
The image registration results with checkerboard mosaic display obtained by the proposed method LURF are shown in
Figure 14. As seen, LURF can effectively overcome the different geometric transformation interferences of different image data sets to achieve the registration task.
Taken together, it can be seen from the qualitative evaluation experiments that our proposed method LURF is far superior to other state-of-the-art feature matching methods for multimodal remote sensing image matching. The reasons may be as follows: (1) Even though multimodal remote sensing image pairs may have a certain degree of nonlinear grayscale distortion, the deep semantic features will maintain a good consistency. (2) Compared with directly extracting feature key points from pixel grayscale, choosing more stable and reliable semantic intersection feature points with structural properties as key points undoubtedly is a better idea.
4.3.2. Quantitative Comparison
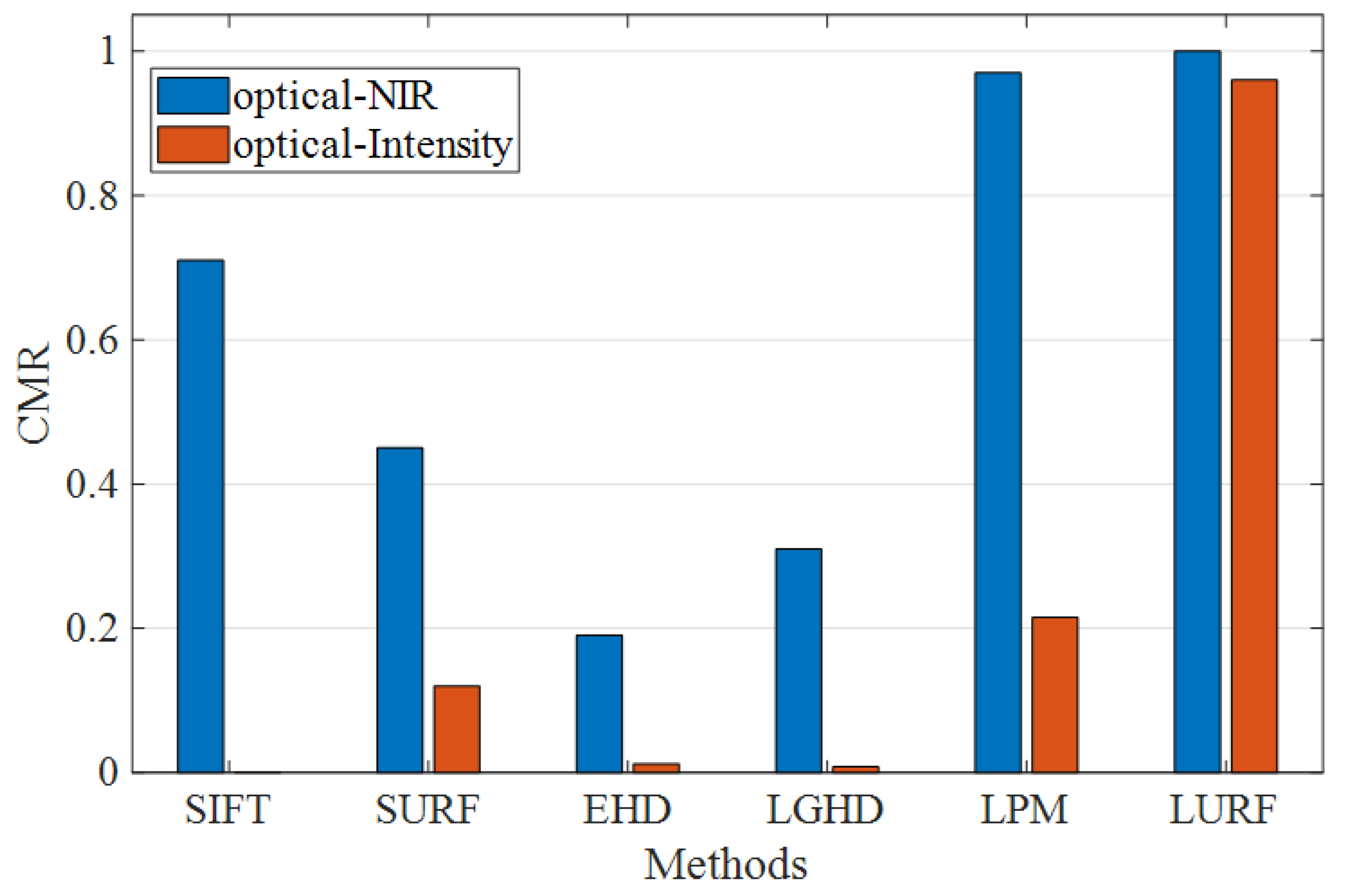
Figure 15 indicates the quantitative experiment results in terms of
values of all comparison methods and proposed method in different image pairs. As can be seen from
Figure 15, in the optical-NIR data set, our proposed method LURF and five comparison methods have an overall correct match rate of more than 15%, and the EHD has the lowest
value among all the comparison methods. Compared with other comparison methods, LPM has the highest
value, which is nearly five times that of EHD. The
of our proposed LURF is slightly higher than LPM, and the gap is not obvious. In the optical-Intensity data set, it can be clearly seen that all comparison methods perform poorly, even fail completely. At the same time, our proposed method has obvious advantages and achieves the best correct matching performance, and the
of LURF exceeds the best results of the comparative method by more than three times. Among five comparison methods, SURF and LPM have better results than SIFT, EHD and LGHD.
To verify the alignment accuracy of proposed method LURF,
Table 2 reports the evaluation metrics
,
and the success rate on all data sets. As seen, the proposed LURF has high accuracy, the
error is 1.32 and 1.88 pixels in the optical-NIR and optical-Intensity image data sets, respectively. The
error is only 1.27 and 1.57, respectively. The values of
and
are all less than the three-pixel error requirements. From the success rate evaluation metric, it can be seen that the proposed LURF achieves excellent performance on all datasets, with scores of 100% and 97.6%, respectively.
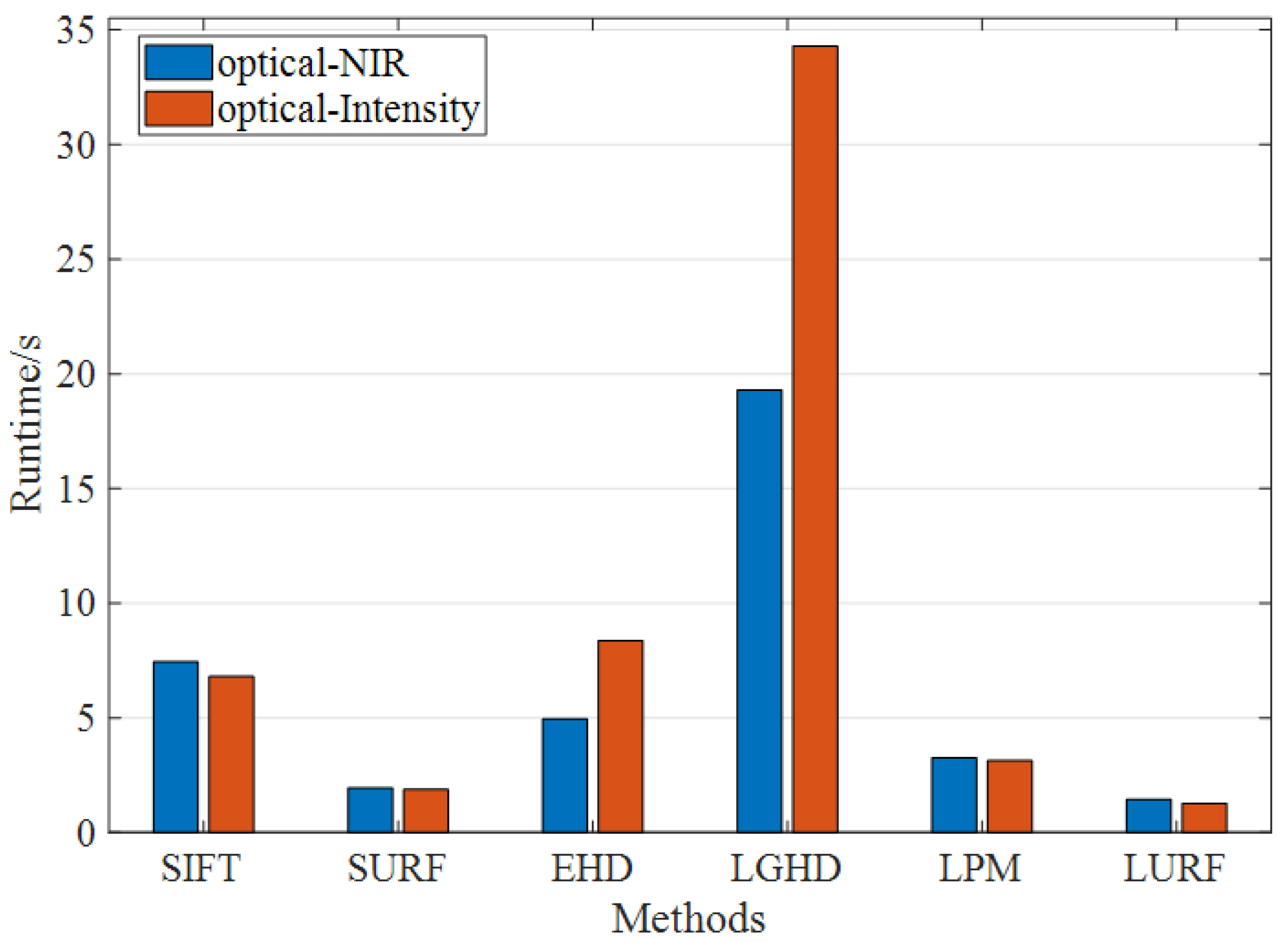
As well as the matching accuracy, the computational efficiency is another important metric for evaluating the matching performances.
Figure 16 represents the average running time of each compared method on the whole image pairs. The running time experiment has been implemented in Matlab using a PC equipped with a 3.4 GHz CPU and 4 GB memory. As can be seen, the running time of LURF costs the shortest running time than other compared methods, which is about twice that of LPM and five times that of SIFT. Among all comparison methods, LGHD has the lowest matching efficiency and takes an average of about 20 and 35 s on the data set, respectively. The proposed method can achieve excellent matching efficiency, the reason is that the adopted CRESIv2Res-Unet network can quickly infer and extract road semantic features from the multimodal image. Meanwhile, the traditional method builds descriptors for all candidate key points, which increases the computational complexity. To cope with this issue, the proposed LURF focuses on the few but stable intersection points and the dimension of the local binary entropy descriptor is smaller than others.
In general, the proposed method LURF can have a higher CMR value while maintaining a shorter running time. The number of detected key points is small, but these key points have excellent stability and robustness, and the key point repetition rate and matching efficiency is better than the other five compared methods.
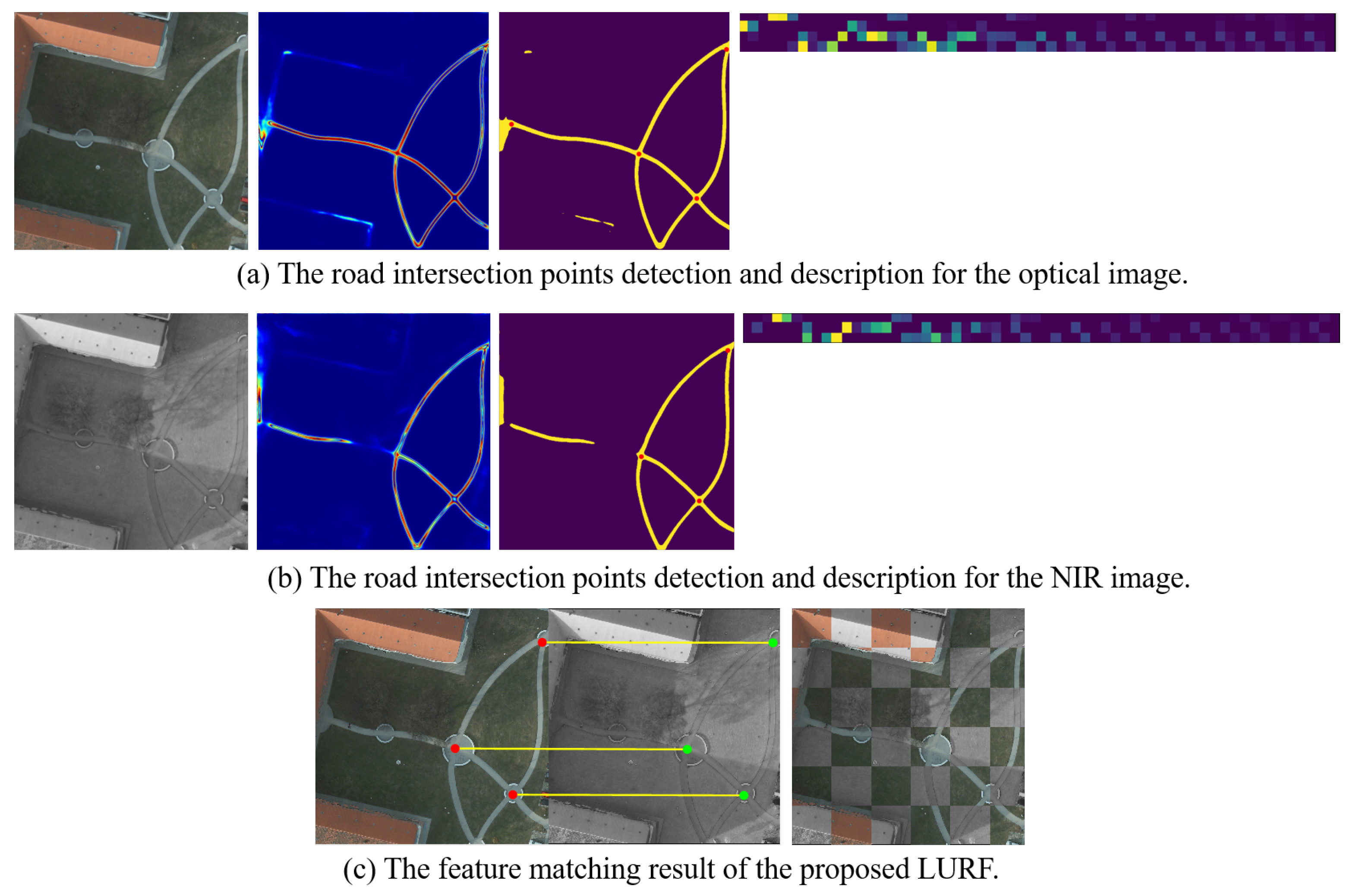
4.4. Performance with Respect to Curved Road Condition
Figure 17 shows the matching performance of the proposed LURF on multimodal image pair with curvy road information. Comparing
Figure 17 with
Figure 1, we can conclude that the proposed method LURF can effectively deal with the curvy road case for the multimodal image matching that the earlier method [
6] can not. As can be seen from
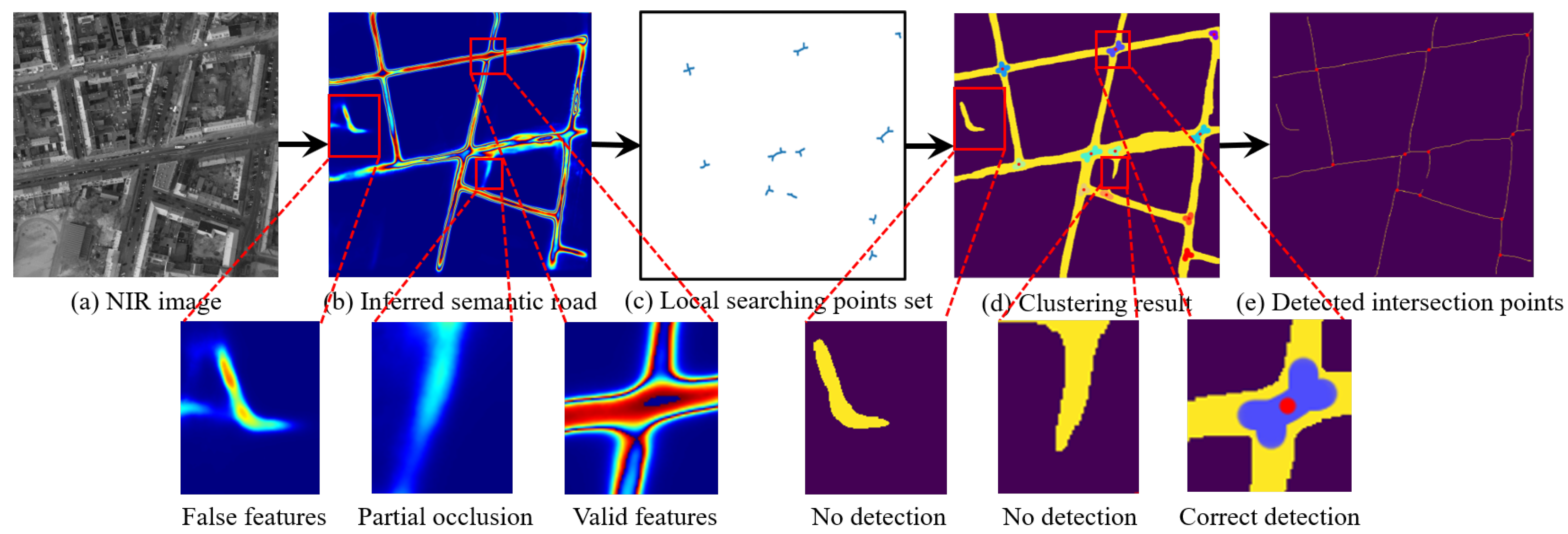
Figure 17, when the deep learning model CRESIv2 estimates road probability information, There are certain interfering factors such as false feature and partial occlusion, resulting in incomplete extraction of the semantic road features.
However, these issues can not prevent LURF from successfully achieving the feature matching task for multimodal images as seen in
Figure 17c. It can be seen in
Figure 17a,b, LURF can stably detect and accurately describe the road intersection points under the curved road condition, and the description values of the corresponding road intersection points are highly consistent, ensuring matching accuracy and reliability.
5. Conclusions
In this paper, we proposed a novel matching method named LURF via learned unstructured road feature for multimodal remote sensing image pairs. Firstly, the semantic road features were extracted from multimodal remote sensing images based on CRESIv2 network, which were invariant to nonlinear radiation distortions of multimodal image pair. Subsequently, based on semantic road features, a novel and accurate road intersection point detector has been proposed, and the detected unstructured intersection points can be considered as key points for matching. Then, a local binary entropy descriptor has been designed to represent key points with the local skeleton feature. Finally, for feature matching, a global optimization strategy is adopted to achieve the correct matching. The qualitative and quantitative experimental results on different multimodal remote sensing image data sets demonstrate that LURF is superior to other state-of-the-art methods, and has great efficiency and robustness for multimodal remote sensing image matching.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}