
A Multi-Temporal Network for Improving Semantic Segmentation of Large-Scale Landsat Imagery



Abstract
:1. Introduction
- We propose a multi-temporal network (MTNet) architecture that introduces the label information of the previous phase at the network’s input to provide prior constraint knowledge for the feature extraction of the latter phase. It avoids pseudo changes caused by differences in color distribution of multi-temporal images and improves the performance of semantic segmentation.
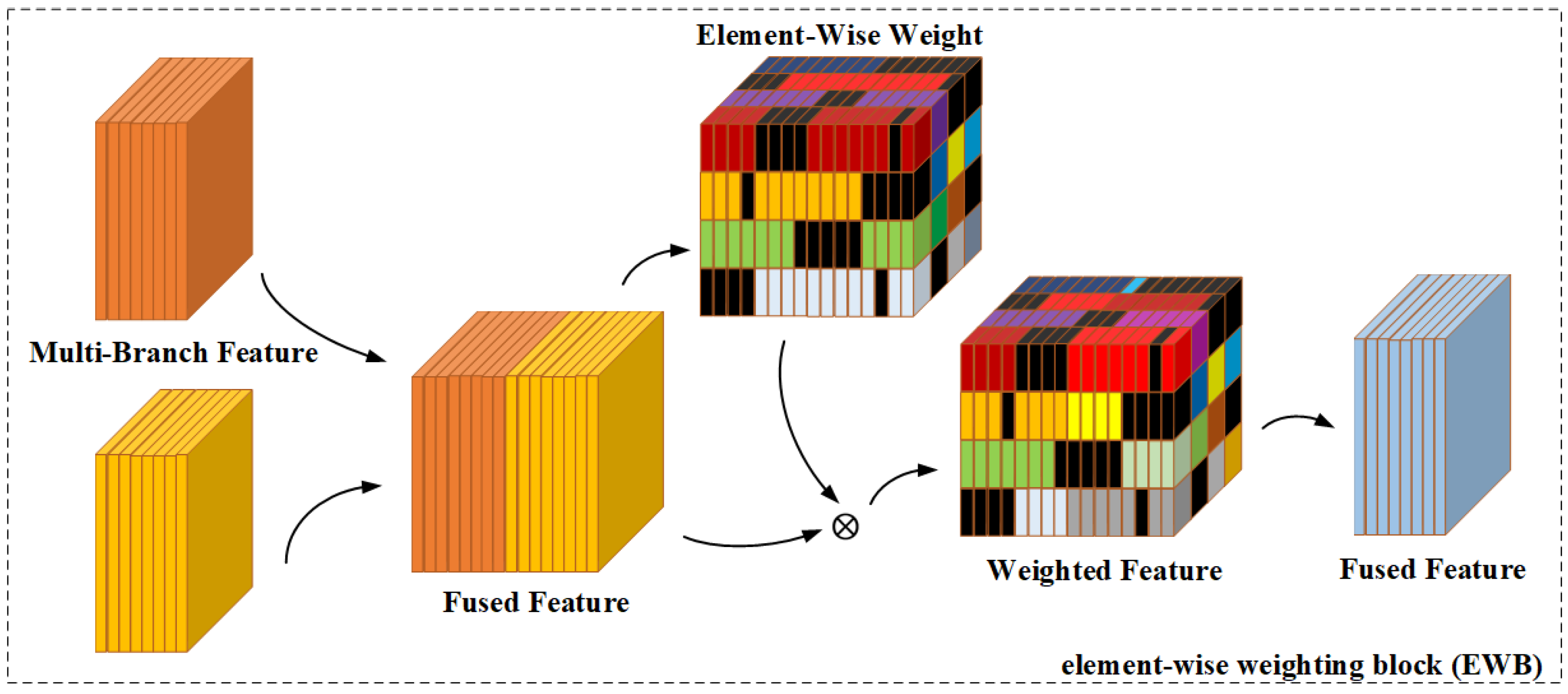
- We propose an element-wise weighting block (EWB) module to perform high-fine-grained feature enhancement and suppression on feature cubes, addressing the limitations of simple channel attention and spatial attention mechanisms with low fine-grainedness.
- We propose a chained deduced classification strategy (CDCS) to improve the overall accuracy of multi-temporal semantic segmentation tasks and ensure that the multi-temporal classification results are consistent with the real changes of ground objects.
- To validate our proposed method, we make a large-scale multi-temporal Landsat dataset. Extensive experiments demonstrate that our method achieves state-of-the-art performance on Landsat images. The classification accuracy of our proposed method is much higher than other mainstream semantic segmentation networks.
2. Methodology
2.1. Multi-Temporal Network
2.2. Element-Wise Weighting Block
2.3. Chained Deduced Classification Strategy
3. Experimental Results
3.1. Datasets
3.2. Implement Details
3.2.1. Data Preprocessing
3.2.2. Training Settings
3.2.3. Evaluation Metrics
3.3. Experiments on the Landsat Dataset I
3.3.1. Ablation Study
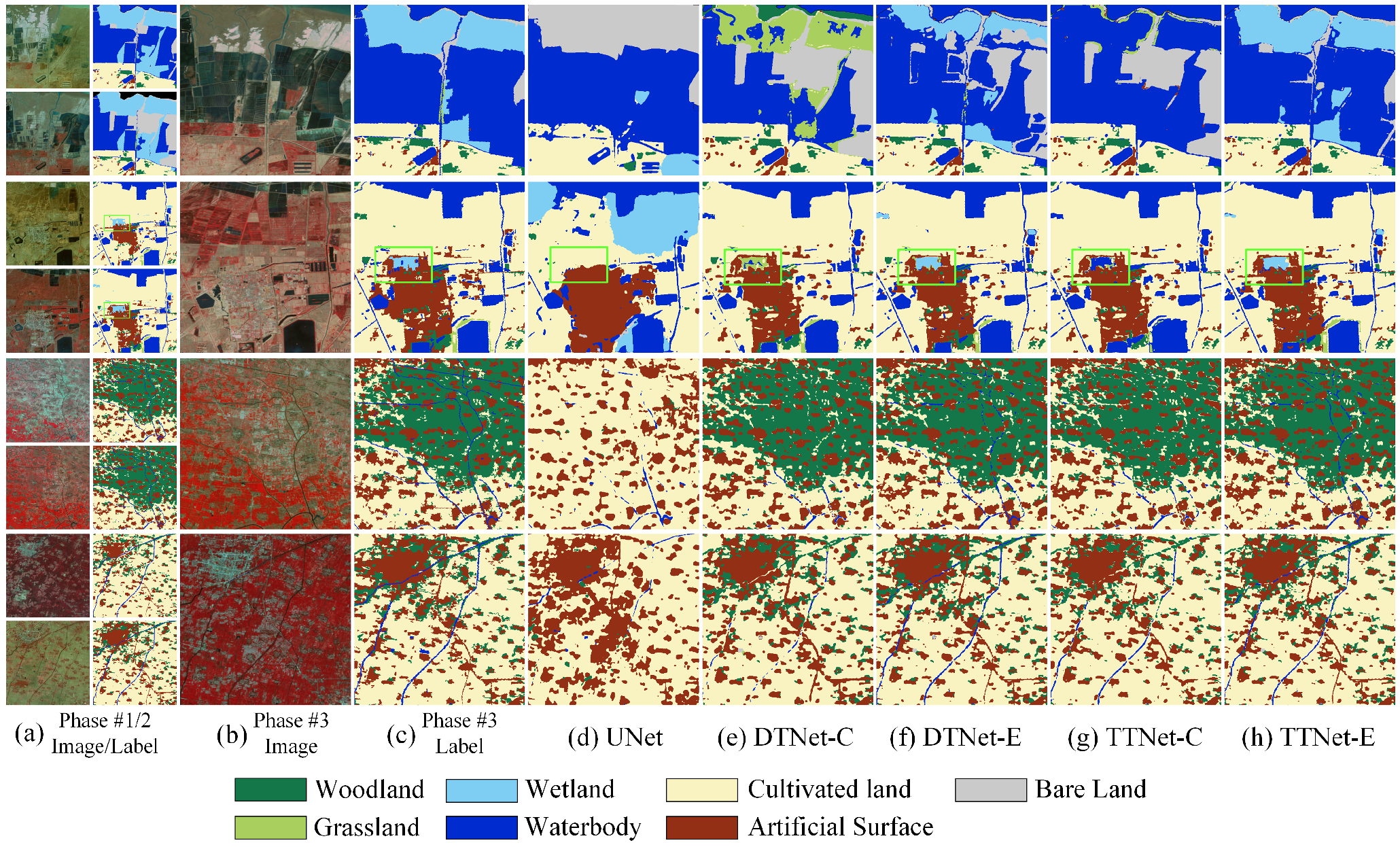
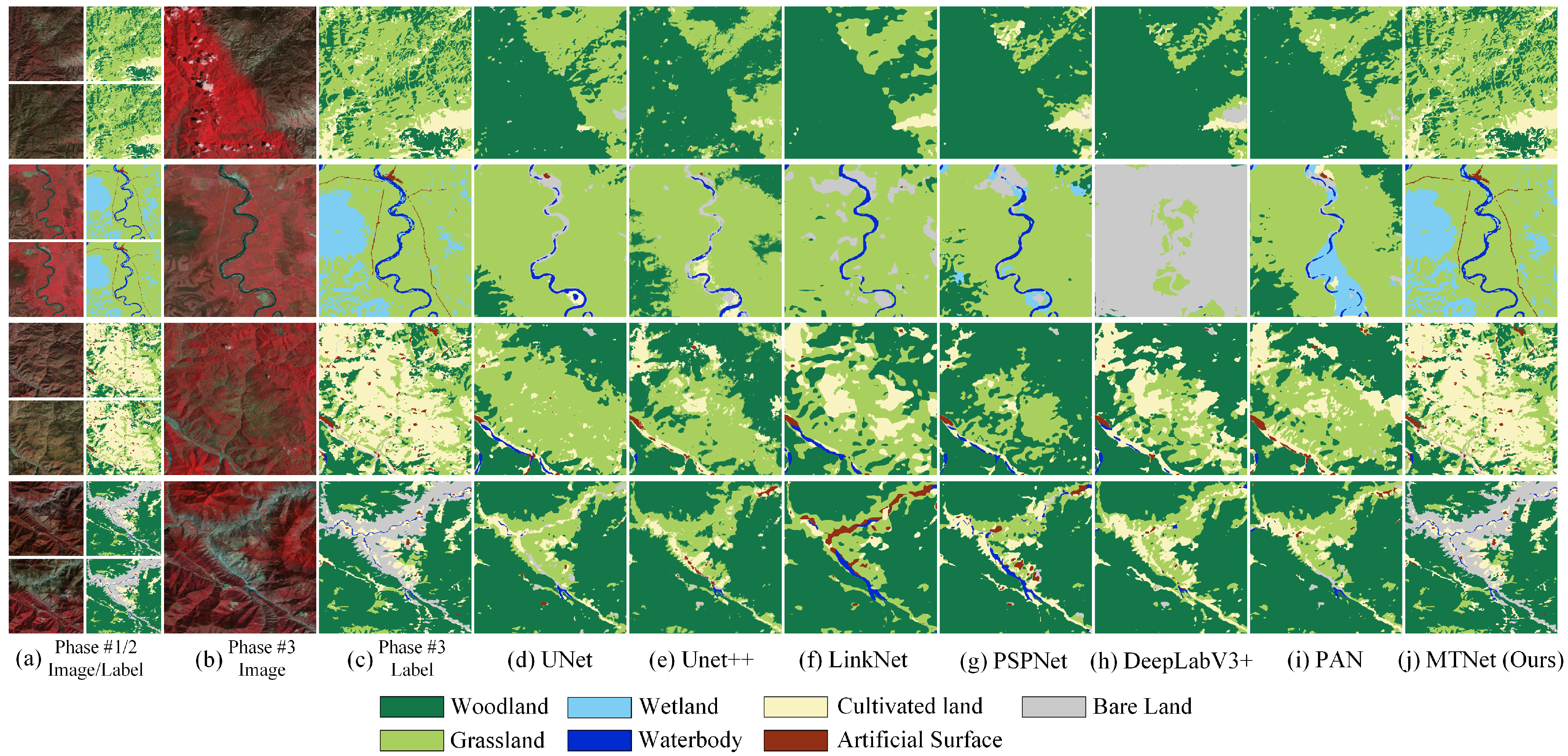
3.3.2. Comparing Methods
- (1)
- UNet [33]: UNet uses an encoder to extract each stage’s features as spatial feature information. The decoder gradually restores the original size of the pooled features and fuses them with the corresponding spatial feature information of the encoder.
- (2)
- UNet++ [49]: UNet++ adds more node modules in each stage of UNet’s decoder, making feature processing more intensive.
- (3)
- LinkNet [50]: LinkNet simplifies the network structure and accelerates the speed of network training and prediction while ensuring accuracy, thereby implementing real-time segmentation tasks.
- (4)
- PSPNet [31]: PSPNet replaces the ordinary convolution in the encoder with dilated convolution, which can maintain the resolution of the features. It uses the SPP module to extract features of different scales and perform multi-scale feature fusion.
- (5)
- DeepLabV3+ [51]: DeepLabV3+ is a hybrid-style network that integrates backbone style and encoder-decoder style. It replaces the ordinary convolution operation in the encoder with atrous convolution, which preserves the resolution of features. It uses the ASPP module to extract features of different scales and perform multi-scale feature fusion.
- (6)
- PAN [52]: PAN extracts multi-scale features by the feature pyramid attention (FPA) module, and progressively fuse the multi-scale features by the global attention upsample (GAU) module.
- (7)
- MTNet: Our MTNet is a network by adding the reference data of the previous two phases and the EWB module based on UNet, namely TTNet-E. Since TTNet-E is the best performer on LSDS-I in the MTNet member networks, we denote the TTNet-E in Section 3.3.1 as MTNet here.
3.4. Experiments on the Landsat Dataset II
3.4.1. Ablation Study
3.4.2. Comparing Methods
3.5. Experiments on the Landsat Dataset III
3.6. Experiments for Chained Deduced Classification Strategy
3.6.1. Experimental Settings
3.6.2. Ablation Study
3.6.3. Comparing Methods
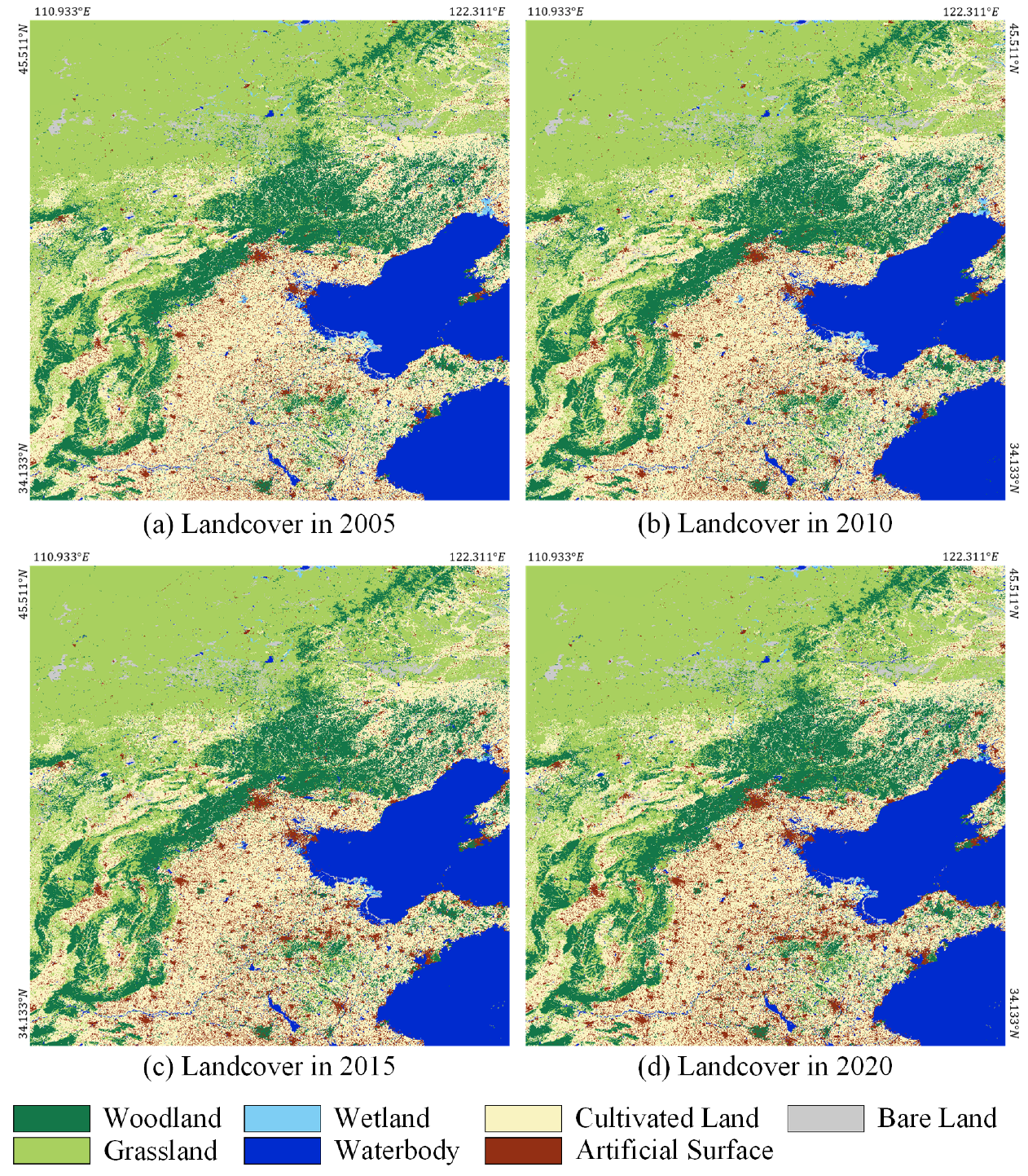
3.7. Large-Scale Multi-Temporal Landcover Mapping
4. Discussion
4.1. Trade-Off Problem
4.2. Implications and Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ASPP | atrous spatial pyramid pooling |
| CDCS | chained deduced classification strategy |
| DCNN | deep convolutional neural network |
| DTNet | dual temporal network |
| EWB | element-wise weighting block |
| score | |
| mean score | |
| FN | false negative |
| FP | false positive |
| FPA | feature pyramid attention |
| GAU | global attention upsample |
| GPU | graphics processing unit |
| LR | learning rate |
| LSDS-I | Landsat dataset I |
| LSDS-II | Landsat dataset II |
| LSDS-III | Landsat dataset III |
| MTNet | multi-temporal network |
| NDBI | normalized difference built-up index |
| NDVI | normalized difference vegetation index |
| NDWI | normalized difference water index |
| OA | overall accuracy |
| ReLU | rectified linear unit |
| SPP | spatial pooling pyramid |
| TP | true positive |
| TTNet | triple temporal network |
References
- Ma, Y.; Wu, H.; Wang, L.; Huang, B.; Ranjan, R.; Zomaya, A.; Jie, W. Remote sensing big data computing: Challenges and opportunities. Future Gener. Comput. Syst. 2015, 51, 47–60. [Google Scholar] [CrossRef] [Green Version]
- Zhang, B. Remotely sensed big data era and intelligent information extraction. Geomat. Inf. Sci. Wuhan Univ. 2018, 43, 1861–1871. [Google Scholar]
- Zhang, B.; Chen, Z.; Peng, D.; Benediktsson, J.A.; Liu, B.; Zou, L.; Li, J.; Plaza, A. Remotely sensed big data: Evolution in model development for information extraction [point of view]. Proc. IEEE 2019, 107, 2294–2301. [Google Scholar] [CrossRef]
- Karra, K.; Kontgis, C.; Statman-Weil, Z.; Mazzariello, J.C.; Mathis, M.; Brumby, S.P. Global land use/land cover with Sentinel 2 and deep learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 4704–4707. [Google Scholar]
- Li, L. Deep residual autoencoder with multiscaling for semantic segmentation of land-use images. Remote Sens. 2019, 11, 2142. [Google Scholar] [CrossRef] [Green Version]
- Qi, K.; Wu, H.; Shen, C.; Gong, J. Land-use scene classification in high-resolution remote sensing images using improved correlatons. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2403–2407. [Google Scholar]
- Costa, H.; Foody, G.M.; Boyd, D.S. Supervised methods of image segmentation accuracy assessment in land cover mapping. Remote Sens. Environ. 2018, 205, 338–351. [Google Scholar] [CrossRef] [Green Version]
- Somasunder, S.; Shih, F.Y. Land Cover Image Segmentation Based on Individual Class Binary Masks. Int. J. Pattern Recognit. Artif. Intell. 2021, 35, 2154034. [Google Scholar] [CrossRef]
- Zhou, K.; Ming, D.; Lv, X.; Fang, J.; Wang, M. CNN-based land cover classification combining stratified segmentation and fusion of point cloud and very high-spatial resolution remote sensing image data. Remote Sens. 2019, 11, 2065. [Google Scholar] [CrossRef] [Green Version]
- Chen, G.; Sui, X.; Kamruzzaman, M. Agricultural remote sensing image cultivated land extraction technology based on deep learning. Technology 2019, 9, 10. [Google Scholar]
- Lingwal, S.; Bhatia, K.K.; Singh, M. Semantic segmentation of landcover for cropland mapping and area estimation using Machine Learning techniques. Data Intell. 2022, 4, 552–569. [Google Scholar]
- Xu, W.; Lan, Y.; Li, Y.; Luo, Y.; He, Z. Classification method of cultivated land based on UAV visible light remote sensing. Int. J. Agric. Biol. Eng. 2019, 12, 103–109. [Google Scholar] [CrossRef] [Green Version]
- Gui, Y.; Li, W.; Wang, Y.; Yue, A.; Pu, Y.; Chen, X. Woodland Detection Using Most-Sure Strategy to Fuse Segmentation Results of Deep Learning. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 6724–6727. [Google Scholar]
- Gui, Y.; Li, W.; Zhang, M.; Yue, A. Woodland Segmentation of Gaofen-6 Remote Sensing Images Based on Deep Learning. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 5409–5412. [Google Scholar]
- Perumal, B.; Kalaiyarasi, M.; Deny, J.; Muneeswaran, V. Forestry land cover segmentation of SAR image using unsupervised ILKFCM. Mater. Today Proc. 2021, 1, 79. [Google Scholar] [CrossRef]
- Chen, Y.; Fan, R.; Yang, X.; Wang, J.; Latif, A. Extraction of urban water bodies from high-resolution remote-sensing imagery using deep learning. Water 2018, 10, 585. [Google Scholar] [CrossRef] [Green Version]
- Feng, W.; Sui, H.; Huang, W.; Xu, C.; An, K. Water body extraction from very high-resolution remote sensing imagery using deep U-Net and a superpixel-based conditional random field model. IEEE Geosci. Remote Sens. Lett. 2018, 16, 618–622. [Google Scholar] [CrossRef]
- Wang, Z.; Gao, X.; Zhang, Y.; Zhao, G. MSLWENet: A novel deep learning network for lake water body extraction of Google remote sensing images. Remote Sens. 2020, 12, 4140. [Google Scholar] [CrossRef]
- Li, W.; Liu, H.; Wang, Y.; Li, Z.; Jia, Y.; Gui, G. Deep learning-based classification methods for remote sensing images in urban built-up areas. IEEE Access 2019, 7, 36274–36284. [Google Scholar] [CrossRef]
- Park, J.; Li, S.; Li, Z.; Steven, X. A Novel Active-Learning Based Residential Area Segmentation Algorithm. In Proceedings of the 2021 IEEE 4th International Conference on Computer and Communication Engineering Technology (CCET), Beijing, China, 13–15 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 96–100. [Google Scholar]
- Zhang, L.; Ma, J.; Lv, X.; Chen, D. Hierarchical weakly supervised learning for residential area semantic segmentation in remote sensing images. IEEE Geosci. Remote Sens. Lett. 2019, 17, 117–121. [Google Scholar] [CrossRef]
- Phiri, D.; Morgenroth, J. Developments in Landsat land cover classification methods: A review. Remote Sens. 2017, 9, 967. [Google Scholar] [CrossRef] [Green Version]
- Bhandari, A.; Kumar, A.; Singh, G. Feature extraction using Normalized Difference Vegetation Index (NDVI): A case study of Jabalpur city. Procedia Technol. 2012, 6, 612–621. [Google Scholar] [CrossRef] [Green Version]
- Xing, D.P. One Method of Urban Land Covers Information Extraction. In Proceedings of the Applied Mechanics and Materials. Trans Tech. Publ. 2013, 380, 4011–4014. [Google Scholar]
- Xu, H. Modification of normalised difference water index (NDWI) to enhance open water features in remotely sensed imagery. Int. J. Remote Sens. 2006, 27, 3025–3033. [Google Scholar] [CrossRef]
- Wei, W.; Chen, X.; Ma, A. Object-oriented information extraction and application in high-resolution remote sensing image. In Proceedings of the 2005 IEEE International Geoscience and Remote Sensing Symposium, IGARSS’05, Seoul, Korea, 25–29 July 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 6, pp. 3803–3806. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Kawaguchi, K.; Kaelbling, L.P.; Bengio, Y. Generalization in deep learning. arXiv 2017, arXiv:1710.05468. [Google Scholar]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Yuan, X.; Shi, J.; Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2021, 169, 114417. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Sexton, J.O.; Urban, D.L.; Donohue, M.J.; Song, C. Long-term land cover dynamics by multi-temporal classification across the Landsat-5 record. Remote Sens. Environ. 2013, 128, 246–258. [Google Scholar] [CrossRef]
- Zhao, X.; Gao, L.; Chen, Z.; Zhang, B.; Liao, W. Large-scale Landsat image classification based on deep learning methods. APSIPA Trans. Signal Inf. Process. 2019, 8. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Chen, W.; Xie, S.M.; Azzari, G.; Lobell, D.B. Weakly supervised deep learning for segmentation of remote sensing imagery. Remote Sens. 2020, 12, 207. [Google Scholar] [CrossRef] [Green Version]
- Storie, C.D.; Henry, C.J. Deep learning neural networks for land use land cover mapping. In Proceedings of the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3445–3448. [Google Scholar]
- Zhong, L.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Chen, T.H.K.; Qiu, C.; Schmitt, M.; Zhu, X.X.; Sabel, C.E.; Prishchepov, A.V. Mapping horizontal and vertical urban densification in Denmark with Landsat time-series from 1985 to 2018: A semantic segmentation solution. Remote Sens. Environ. 2020, 251, 112096. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing, Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Yue, K.; Yang, L.; Li, R.; Hu, W.; Zhang, F.; Li, W. TreeUNet: Adaptive tree convolutional neural networks for subdecimeter aerial image segmentation. ISPRS J. Photogramm. Remote Sens. 2019, 156, 1–13. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Woodland | Grassland | Wetland | Waterbody | Cultivated Land | Artificial Surface | Bare Land | OA | |
|---|---|---|---|---|---|---|---|---|---|
| UNet | 78.0 | 61.5 | 58.2 | 63.1 | 84.3 | 70.2 | 30.7 | 63.7 | 81.1 |
| DTNet-C | 88.3 | 79.1 | 70.4 | 63.7 | 93.6 | 82.1 | 72.4 | 78.5 | 89.4 |
| DTNet-E | 89.7 | 83.8 | 87.5 | 77.0 | 94.9 | 86.7 | 76.9 | 85.2 | 91.3 |
| TTNet-C | 89.1 | 80.5 | 74.0 | 61.4 | 94.1 | 84.3 | 75.2 | 79.8 | 90.6 |
| TTNet-E | 91.8 | 84.7 | 91.1 | 81.6 | 95.3 | 88.7 | 81.1 | 87.7 | 93.2 |
| Method | Woodland | Grassland | Wetland | Waterbody | Cultivated Land | Artificial Surface | Bare Land | OA | |
|---|---|---|---|---|---|---|---|---|---|
| UNet | 78.2 | 61.4 | 58.0 | 63.1 | 84.4 | 70.5 | 30.4 | 63.7 | 81.1 |
| UNet++ | 78.1 | 60.3 | 54.1 | 60.7 | 83.8 | 71.3 | 27.4 | 62.2 | 80.4 |
| LinkNet | 78.0 | 60.6 | 52.5 | 60.7 | 83.5 | 69.2 | 26.4 | 61.5 | 80.1 |
| PSPNet | 77.6 | 59.3 | 49.4 | 58.0 | 83.0 | 65.5 | 28.0 | 60.1 | 79.6 |
| DeepLabV3+ | 78.0 | 59.3 | 57.4 | 61.9 | 83.9 | 68.6 | 28.7 | 62.5 | 80.4 |
| PAN | 77.7 | 59.7 | 60.7 | 61.6 | 83.9 | 69.1 | 28.0 | 62.9 | 80.4 |
| MTNet (Ours) | 91.8 | 84.7 | 91.1 | 81.6 | 95.3 | 88.7 | 81.1 | 87.7 | 93.2 |
| Method | Woodland | Grassland | Wetland | Waterbody | Cultivated Land | Artificial Surface | Bare Land | OA | |
|---|---|---|---|---|---|---|---|---|---|
| UNet | 69.2 | 79.7 | 32.6 | 59.5 | 81.5 | 64.8 | 22.9 | 58.6 | 78.2 |
| DTNet-C | 72.6 | 90.4 | 53.9 | 70.4 | 88.7 | 79.1 | 81.2 | 76.6 | 85.2 |
| DTNet-E | 85.1 | 91.2 | 80.1 | 79.1 | 90.5 | 80.2 | 83.7 | 84.2 | 90.1 |
| TTNet-C | 84.0 | 91.0 | 57.2 | 72.7 | 90.2 | 79.7 | 83.6 | 79.7 | 89.4 |
| TTNet-E | 87.2 | 92.3 | 81.5 | 81.4 | 92.1 | 83.5 | 86.0 | 86.2 | 91.3 |
| Method | Woodland | Grassland | Wetland | Waterbody | Cultivated Land | Artificial Surface | Bare Land | OA | |
|---|---|---|---|---|---|---|---|---|---|
| UNet | 69.3 | 79.9 | 32.6 | 59.7 | 81.3 | 64.5 | 22.9 | 58.6 | 78.2 |
| UNet++ | 68.9 | 79.4 | 24.1 | 58.4 | 81.4 | 65.5 | 19.0 | 56.6 | 77.7 |
| LinkNet | 69.1 | 79.5 | 25.8 | 59.5 | 80.9 | 63.9 | 21.7 | 57.2 | 77.9 |
| PSPNet | 67.4 | 78.9 | 15.6 | 54.8 | 80.2 | 59.3 | 15.3 | 53.0 | 76.6 |
| DeepLabV3+ | 67.5 | 79.3 | 21.2 | 61.3 | 81.2 | 62.9 | 23.3 | 56.6 | 77.5 |
| PAN | 68.4 | 79.8 | 36.6 | 60.4 | 81.4 | 63.9 | 22.9 | 59.0 | 78.2 |
| MTNet (Ours) | 87.2 | 92.3 | 81.5 | 81.4 | 92.1 | 83.5 | 86.0 | 86.2 | 91.3 |
| Method | Woodland | Grassland | Wetland | Waterbody | Cultivated Land | Artificial Surface | Bare Land | OA | |
|---|---|---|---|---|---|---|---|---|---|
| UNet | 72.4 | 66.4 | 33.7 | 57.1 | 72.7 | 73.6 | 22.2 | 56.8 | 67.3 |
| UNet++ | 71.3 | 65.8 | 32.3 | 55.8 | 70.6 | 72.9 | 21.3 | 55.7 | 66.4 |
| LinkNet | 70.2 | 67.3 | 28.2 | 53.7 | 69.5 | 69.5 | 20.1 | 54.0 | 65.1 |
| PSPNet | 72.9 | 64.1 | 30.4 | 50.4 | 68.4 | 70.2 | 21.0 | 53.9 | 64.9 |
| DeepLabV3+ | 72.5 | 66.1 | 33.0 | 52.4 | 71.9 | 69.1 | 22.6 | 55.3 | 65.9 |
| PAN | 74.4 | 62.0 | 32.5 | 54.5 | 70.1 | 71.4 | 22.1 | 55.2 | 65.9 |
| MTNet (Ours) | 86.5 | 91.7 | 80.2 | 81.1 | 90.9 | 83.7 | 84.4 | 85.5 | 90.1 |
| Region | Method | Woodland | Grassland | Wetland | Waterbody | Cultivated Land | Artificial Surface | Bare Land | OA | |
|---|---|---|---|---|---|---|---|---|---|---|
| Region-I | UNet | 70.9 | 66.5 | 10.2 | 67.4 | 73.4 | 62.7 | 23.7 | 53.5 | 68.7 |
| MTNet without CDCS | 88.7 | 92.3 | 76.8 | 80.1 | 92.0 | 80.4 | 82.5 | 84.6 | 90.4 | |
| MTNet with CDCS | 90.6 | 94.0 | 78.2 | 81.8 | 93.5 | 82.7 | 84.8 | 86.5 | 91.9 | |
| Region-II | UNet | 71.6 | 37.8 | 4.0 | 46.0 | 66.3 | 22.0 | 24.4 | 38.9 | 62.8 |
| MTNet without CDCS | 91.4 | 85.7 | 83.2 | 77.8 | 88.3 | 71.7 | 86.5 | 83.5 | 89.9 | |
| MTNet with CDCS | 93.0 | 87.9 | 84.1 | 79.6 | 89.7 | 73.0 | 87.2 | 84.9 | 90.6 |
| Region | Year | Method | Woodland | Grassland | Wetland | Waterbody | Cultivated Land | Artificial Surface | Bare Land | OA | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Region-I | 2005 | UNet | 76.0 | 76.6 | 45.2 | 70.5 | 80.4 | 65.1 | 25.5 | 62.8 | 75.7 |
| UNet++ | 75.7 | 79.1 | 44.5 | 70.4 | 80.1 | 65.7 | 29.6 | 63.6 | 76.9 | ||
| LinkNet | 76.0 | 77.1 | 44.9 | 70.2 | 80.4 | 65.1 | 28.5 | 63.2 | 75.8 | ||
| PSPNet | 74.5 | 79.1 | 40.6 | 68.7 | 79.6 | 61.0 | 26.2 | 61.4 | 75.9 | ||
| DeepLabV3+ | 75.6 | 80.1 | 49.4 | 71.3 | 80.8 | 64.2 | 32.2 | 64.8 | 77.4 | ||
| PAN | 75.5 | 79.6 | 50.9 | 70.8 | 80.1 | 64.3 | 32.1 | 64.8 | 77.2 | ||
| MTNet (Ours) | 92.9 | 95.2 | 84.8 | 84.2 | 94.1 | 83.6 | 88.0 | 89.0 | 93.2 | ||
| 2010 | UNet | 70.9 | 66.5 | 10.2 | 67.4 | 73.4 | 62.7 | 23.7 | 53.5 | 68.7 | |
| UNet++ | 72.4 | 72.8 | 7.8 | 68.6 | 75.4 | 62.2 | 18.3 | 53.9 | 71.8 | ||
| LinkNet | 71.3 | 69.4 | 8.8 | 67.3 | 75.3 | 61.7 | 30.3 | 54.9 | 70.0 | ||
| PSPNet | 70.7 | 74.7 | 7.0 | 66.1 | 74.4 | 58.8 | 28.3 | 54.3 | 71.6 | ||
| DeepLabV3+ | 71.7 | 75.4 | 8.5 | 69.2 | 76.1 | 60.8 | 25.4 | 55.3 | 72.9 | ||
| PAN | 72.1 | 74.7 | 10.0 | 68.1 | 76.1 | 61.0 | 18.0 | 54.3 | 72.8 | ||
| MTNet (Ours) | 90.6 | 94.0 | 78.2 | 81.8 | 93.5 | 82.7 | 84.8 | 86.5 | 91.9 | ||
| Region-II | 2005 | UNet | 70.1 | 27.5 | 1.6 | 44.7 | 63.5 | 21.2 | 11.7 | 34.3 | 59.4 |
| UNet++ | 71.3 | 32.9 | 7.4 | 48.1 | 70.0 | 27.4 | 22.8 | 40.0 | 63.9 | ||
| LinkNet | 72.6 | 25.0 | 3.1 | 39.0 | 63.1 | 20.3 | 21.6 | 35.0 | 59.2 | ||
| PSPNet | 72.9 | 23.1 | 4.3 | 44.1 | 69.2 | 32.3 | 34.7 | 40.1 | 65.5 | ||
| DeepLabV3+ | 74.4 | 27.4 | 0.4 | 46.1 | 71.2 | 29.8 | 22.6 | 38.8 | 66.6 | ||
| PAN | 75.4 | 32.1 | 2.1 | 48.7 | 69.4 | 25.7 | 11.4 | 37.8 | 66.9 | ||
| MTNet (Ours) | 93.1 | 88.5 | 85.1 | 70.7 | 90.2 | 71.2 | 88.6 | 83.9 | 90.9 | ||
| 2010 | UNet | 71.6 | 37.8 | 4.0 | 46.0 | 66.3 | 22.0 | 24.4 | 38.9 | 62.8 | |
| UNet++ | 71.2 | 43.0 | 6.3 | 50.5 | 66.6 | 23.2 | 27.7 | 41.2 | 63.2 | ||
| LinkNet | 71.6 | 33.4 | 7.7 | 44.8 | 65.9 | 21.4 | 29.7 | 39.2 | 61.3 | ||
| PSPNet | 72.0 | 31.5 | 10.2 | 42.6 | 66.9 | 25.4 | 38.1 | 41.0 | 63.7 | ||
| DeepLabV3+ | 73.2 | 41.8 | 0.3 | 50.3 | 70.0 | 29.1 | 31.7 | 42.3 | 66.5 | ||
| PAN | 74.9 | 42.8 | 2.3 | 50.7 | 65.7 | 19.0 | 19.9 | 39.3 | 64.8 | ||
| MTNet (Ours) | 93.0 | 87.9 | 84.1 | 79.6 | 89.7 | 73.0 | 87.2 | 84.9 | 90.6 |
| Method | #Phases | #Parameters | Training Time | Inference Time |
|---|---|---|---|---|
| UNet | 1 | 123.70 M | 142 min | 40 s |
| N | 123.70 M | 142 min | 40 s | |
| MTNet without CDCS | 1 | 257.06 M | 162 min | 42 s |
| N | 257.06 M | 162 min | 42 s | |
| MTNet with CDCS | 1 | 257.06 M | 162 min | 42 s |
| N | 257.06 M | 162 min | 42 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Zhang, B.; Chen, Z.; Bai, Y.; Chen, P. A Multi-Temporal Network for Improving Semantic Segmentation of Large-Scale Landsat Imagery. Remote Sens. 2022, 14, 5062. https://doi.org/10.3390/rs14195062
Yang X, Zhang B, Chen Z, Bai Y, Chen P. A Multi-Temporal Network for Improving Semantic Segmentation of Large-Scale Landsat Imagery. Remote Sensing. 2022; 14(19):5062. https://doi.org/10.3390/rs14195062
Chicago/Turabian StyleYang, Xuan, Bing Zhang, Zhengchao Chen, Yongqing Bai, and Pan Chen. 2022. "A Multi-Temporal Network for Improving Semantic Segmentation of Large-Scale Landsat Imagery" Remote Sensing 14, no. 19: 5062. https://doi.org/10.3390/rs14195062
APA StyleYang, X., Zhang, B., Chen, Z., Bai, Y., & Chen, P. (2022). A Multi-Temporal Network for Improving Semantic Segmentation of Large-Scale Landsat Imagery. Remote Sensing, 14(19), 5062. https://doi.org/10.3390/rs14195062