1. Introduction
Monitoring coastal areas is essential to the preservation of the land-water continuum’s habitats and the services they provide, particularly in a context of local and global changes [
1]. Seagrasses, salt marshes, mangroves, macroalgae, sandy dunes, or beaches are examples of such habitats that continually interact with the tide levels. They can be found along the temperate shorelines and play key roles in the ecological equilibrium of these ecotones. Seagrasses ensure water quality and are a significant carbon sink, along with salt marshes and mangroves [
1,
2]. Coastal habitats also provide protection from marine hazards to coastal communities and infrastructures and supply many recreational activities such as snorkeling, fishing, swimming, and land sailing [
1,
2,
3]. Finally, they support a wide range of endemic species by offering them nurseries, food, and oxygen [
1,
2]. However, coastal (including estuarine) habitats are exposed to a plethora of natural and anthropic threats that may be amplified by global changes. Thorough observation of coastal processes is necessary to identify the trends of evolution of these fragile environments. It requires regular data acquisition along the shoreline with spatial resolution and time spacing both adapted to the task. However, the surveying complexities inherent to land-water continuum areas hinder their monitoring at a time scale relevant to their fast evolution, and over large, representative extents. Remote sensing can adequately address this issue.
Due to the presence of water, coastal surveys are conventionally split between topographic and bathymetric campaigns, both constrained to the tide and the field accessibility. Subtidal areas can be surveyed with waterborne acoustic techniques, while supratidal domains are documented with passive or active imagery using satellite, airborne, or unmanned aerial vehicles (UAV) [
4,
5,
6]. Boats being unable to reach very shallow areas and imagery being limited by the water surface, intertidal, and shallow water areas are harder to accurately monitor [
7]. Distinct terrestrial and marine surveying campaigns can also be difficult to merge, considering they might rely on different reference systems, and their thin overlapping area can be challenging to sample thoroughly with ground control points. Existing seamless surveying techniques over land-water interface areas are summarized in the following section.
Multispectral or superspectral imagery can be used for coastal habitat mapping. In clear and shallow water, traditional image classification techniques can be applied [
7]. A more accurate approach consists in suppressing the effects of water on light refraction and diffusion by using inversion models on superspectral imagery. Using such models, it is possible to obtain satellite-derived bathymetry [
8] or satellite-derived topobathymetry [
9,
10], which are proven to improve the classification of coastal covers obtained [
11]. Bathymetry can also be extracted using multispectral imagery, as demonstrated in [
12]. Multispectral imagery has the advantage of being accessible with different platforms: UAVs, planes, or satellites nowadays all benefit from multiband sensors. The cost of acquisition can therefore be lowered depending on the chosen source, and the revisit time can allow high temporal resolution monitoring.
Hyperspectral imagery is the last passive imagery-based method to map the land-water continuum [
13,
14]. The key principle of methods using hyperspectral imagery to study submerged areas is to model the interactions of light with the water column and correct them to obtain imagery unaffected by these processes. By inversing a radiative transfer model of the water column, it is possible to derive the seafloor reflectance and estimate the bathymetry [
15]. These products are adapted to the characterization of sea bottom types and can be used for benthic classification tasks.
Although satellite passive imagery overcomes the issue of accessibility and temporal resolution, its spatial resolution is sometimes too coarse to spot specific changes (depending on the sensor and the quality of pan-sharpening), and it only penetrates water in shallow, clear areas [
16]. The main issue with passive imagery remains the depth range in which it is usable. Due to optical phenomena, past a certain depth threshold that varies with water clarity, passive imagery can no longer give information on what lies beneath the water surface. Bathymetry extraction via active imaging then becomes the only way to gather information on these areas. Furthermore, even in shallow waters, bathymetry derived from active sensors gives access to the seabed covers’ elevation but also to the seabed’s elevation itself, providing 3D information on these covers, which enables biomass estimation or other structural assessments [
17,
18,
19,
20]. The bathymetry measurements obtained with active sensors (airborne bathymetric lidar or waterborne acoustic soundings) also leverage a higher vertical precision, useful for ecological structural assessments [
12].
Airborne topobathymetric lidar is a reliable alternative: it ensures information continuity between land and water, covers vast areas quickly, penetrates a depth of up to dozens of meters and has a higher spatial resolution than satellite imagery [
21,
22]. Current approaches to map coastal interfaces using airborne lidar mostly make use of the digital terrain models or digital surface models derived from the lidar point clouds (PCs), including those obtained for the water bottoms after removing points corresponding to the water bodies [
17]. Fewer studies rely on the 3D PCs of the lidar surveys to generate coastal or riverside habitats maps. Directly processing the PCs and avoiding rasterization has the advantage of preserving the dense spatial sampling provided by lidar sensors. It also opens possibilities for 3D rendering of the results, and structural analysis thanks to the rich spatial information contained in PCs. Indeed, the vertical repartition of the points offers useful information on scene architecture, providing relevant features to determine their origin, namely for vegetation or building identification. Analysis of this geometrical context is the most frequently used method to produce maps of land and water covers [
23,
24,
25]. Research works conducted on PCs processing mostly rely on the computation of geometrical features using spherical neighborhoods [
23] and, more recently, on deep neural networks [
26].
Another possibility with airborne lidar is to exploit the spectral details contained in the backscattered signals. These can be recorded under the form of time series of intensities received by the sensor: lidar waveforms. Each object of the surveyed environment illuminated by the sensor’s laser reflects light in a specific way, generating a characteristic signature in the signal. Waveforms consequently provide additional information on the structure and physical attributes of the targets. The shape, width, and amplitude of their spectral signature—a peak—are information that can be used for land and water covers mapping [
27,
28,
29]. Waveforms are therefore a useful indicator of the diversity of coastal areas. Though many methods have been proposed to process airborne topographic lidar full-waveforms, airborne bathymetric lidar full-waveforms are, to the best of our knowledge, much less explored. They are even less employed for classification tasks, and often only analyzed to retrieve bathymetry. There are currently three main approaches to waveform processing. The first consists in decomposing the waveforms to isolate each element of the train of echoes in the signal [
30,
31]. The second consists in reconstructing the signal by fitting statistical models to the waveforms [
32]. Knowing how to approximate the sensed response allows to extract the position and the attributes of each component. The last approach is to analyze waveforms straightforwardly as any 1D signal to detect their peaks [
27], using first derivative thresholding for example. Identifying waveform components is useful in order to localize the objects populating the scene, but also to extract features to describe them and prepare their automatic classification [
27,
33,
34].
Classification of land or water covers using lidar data has been well explored recently. Even when using waveform data, most of the published research is based on 2D data classification [
17,
25,
27,
29,
33] while fewer articles exploit PCs [
24,
34,
35]. Many studies researching ways to classify lidar data used machine learning algorithms such as support vector machine (SVM), maximum likelihood (ML), or random forests. The maximum likelihood is mostly used for 2D lidar data, while SVM and random forests have been proofed on PCs. SVM and random forest seem to have similar classification performances on 3D lidar data [
36]. However, with these algorithms, the spatial context around each point is not considered and does not impact the prediction [
36]. Research papers show that conditional random field (CRF) and Markov random field (MRF) classifications produce better results in that way [
36,
37]. However, these require heavier computation and are more difficult to apply to large datasets. Currently, there is a consensus on the efficiency of random forest on that aspect [
36]. Contrary to SVM, CRF, or MRF, it is easy to apply to large datasets. Random forest is, furthermore, robust to overfitting issues and offers the possibility to retrieve predictors contribution easily. In this article, we therefore wish to implement a hand-crafted features’ random forest classification to map coastal habitats. Although machine learning classification of lidar waveform features has been explored previously, we have found no point-based studies dedicated to mapping a large number of habitats both marine and terrestrial. Previously cited studies such as [
24,
34,
35] classified either only marine or only terrestrial habitats from PCs and [
27] processed 2D data to produce their map of coastal habitats.
The present study aims at mapping an array of 21 habitats of the 3D land-water continuum seamlessly using exclusively airborne topobathymetric bispectral lidar. Our objective is to bridge the gap between marine and terrestrial surveys, demonstrate that efficient methods can be developed to automatically map the land-water interface, and show that an integrated vision of coastal zones is feasible and advised. Our contributions consist in (1) developing a point-based approach to exploit full-waveform data acquired during topobathymetric surveys for subtidal, intertidal, and supratidal habitats mapping, (2) quantifying the contribution of green waveform features, infrared (IR) intensities, and relief information to the classification accuracy based on a random forest machine learner. We improve an experimental method presented in a previous work [
29] and test it on a wider area including both emerged and submerged domains to determine the suitability of full-waveform lidar data for coastal zone mapping. UAV data, inexpensive to implement, is used to estimate the accuracy of the resulting very high spatial resolution maps, which are produced under the form of PCs, paving the way for 3D classification of land and sea covers using solely topobathymetric lidar data.
3. Methodology
The algorithm developed in this study was first introduced in [
29] to identify marine habitats using green full-waveform spectral features. In [
29], only seagrasses and sediments (two classes) at few meters’ depths were classified. We significantly improved this algorithm and adapted it to the classification of 21 habitats across the land-water interface, to test its abilities in supratidal and intertidal environments.
The enhanced version presented here was tailored to the identification of land and sea covers: the seabed or riverbed type was considered in the presence of water while we focused on the surface cover over terrestrial areas (i.e., if there were two layers of surface covers, such as a trees and grass beneath it, the land cover was labelled as tree). It used a supervised point-based classification algorithm trained on various sets of input features and evaluated on a test dataset. Classified PCs of the whole area were also produced to observe the ability of each predictor sets to produce a map of the habitats in the study area using this approach.
3.1. Classes of Land and Sea Covers Investigated
A total of 21 classes of land and sea covers has been designed based on on-site observations and photo-interpretation. These classes are illustrated in
Table 1.
3.2. Data Pre-Processing
The classification algorithm developed for this research aimed at processing bispectral lidar data. Two PCs were therefore used, but full-waveforms were available only for the green wavelength. IR data were thus incorporated as reflected intensities only. Due to the sensor’s configuration, IR and green lasers of the topobathymetric lidar used are not co-focal. They also do not have the same swath, density, and precision. The two resulting PCs are consequently different, and the points acquired do not have identical locations. A preprocessing step was therefore required to obtain the IR backscattered intensity at each green waveform’s location. Intensities of the IR PC were matched with each point of the green waveforms PC, which was kept as the reference PC, using the median IR intensity of the 10 nearest neighbors of each green waveform’s location in the IR PC, which was computed and assigned to the waveform as an attribute. To this end, we used the PC processing software “CloudCompare” [
43], in which the neighborhood search is performed by computing the 3D Euclidean distance between each point of the reference PC and the points of the compared PC. The coordinates of the waveforms’ cover component were used to locate each waveform and obtain a green waveform PC. Consequently, each waveform was synthesized as a point, and we obtained a green waveforms PC. The IR PC was cleaned manually beforehand, to ensure all noise points, significantly above the surface, were removed from the data.
The median intensity of the 10 closest neighbors in the IR PC was chosen for two reasons. First, the number of 10 neighbors was relevant considering the difference of the two lasers’ spot sizes and the resulting density of the PCs. Second, the use of the median intensity was more suited to the task than the mean intensity to avoid outliers’ artefacts in spheres located at the interface of two habitats.
3.3. Training and Testing Datasets
Two main datasets were designed to perform the data classifications and assess their quality, called the training dataset and test dataset. We collected 1000 training and 500 testing samples of each class. To do so, we first drew polygons over representative areas of the 21 land and water covers, based on the ground-truth data, and made sure none of the polygons intersected. We used these to segment the PC and extract points located within representative areas of each class. For each class, we then randomly selected 1000 of them for the training datasets and 500 others for testing, which resulted in training and test datasets of 21,000 and 10,500 items, respectively. This draw without replacement ensured that no training and testing points were the same and that they were all independent. We chose to use the same areas for random drawing of training and testing points in order to account for the widest diversity possible in the training and testing samples. The resulting training and test points have a mean distance of 1.6 m; their repartition is presented in
Figure 4.
Each array of coordinates, IR intensities, and waveform features was associated to one integer label between 1 and 21, forming a dataset with the structure illustrated in
Figure 5.
The point-based classification method is described in the following paragraphs. It relied on the interpolated IR intensities and on spectral features extracted from the green waveforms.
3.4. Waveform Processing Method
The waveform processing steps are presented in
Figure 6 and detailed in the following paragraphs. All these steps were performed using tailored scripts developed with Python 3.8.8.
The base concept consists in extracting tailored features from the relevant part of the waveforms. Here, we considered this part to be any return detected after the water surface component in submerged domains, and the part of the waveform encompassing the backscattered signal in terrestrial zones. In these zones, the sole processing was to isolate the useful part of the green waveform by identifying where the backscatter begins and the noise ends. This was made by evaluating the mean level of noise observable at the beginning and at the end of the waveform and extracting the part of the wave where the intensity was above this noise level.
To distinguish marine and terrestrial waveforms, we relied on a flag attributed by the Leica survey software Leica LIDAR Survey Studio (LSS) to points in the PC that correspond to an interpolated water surface under which refraction correction is made. Since waveform files integrate this information, it was possible to use it to differentiate submerged and emerged areas. This step is a pre-classification made by LSS before the data was delivered to us.
In submerged areas, further processing was required to detect the different peaks and isolate the parts of the signal that correspond to the water surface and the water column components. All green waveforms were first filtered using the Savitzky–Golay piecewise polynomial functions estimation method to remove the noise. As explained in [
29], a threshold was then applied to the first derivative of the smoothed waveforms to bring out the peaks. This step was well suited to the detection of the most significant peaks; however, depending on local conditions affecting the reflection of light, some bottom returns may be less intense and hard to expose. We therefore included a second thresholding: when only one peak was identified with the first threshold, another derivative thresholding step was introduced to try to detect peaks after the water surface (i.e., the peak already detected). This second threshold had a lower value, which would exacerbate noise if it were used on the whole waveform, but it was adapted to the detection of more attenuated returns when used on the underwater part of the waveform. If no additional return was identified with this first derivative thresholding, we concluded that no seabed was retrieved and discarded the waveform since there was no return to compute features on.
The same correction of the signal’s attenuation in water as the one in [
29] was applied to bathymetric waveforms; it relied on the fitting of an exponential function on the water column component to compensate for the effects of water absorption and diffusion in water on the bottom return. This was based on the estimation of the diffuse attenuation coefficient [
21,
22] through the evaluation of the intensity gradient at the end of the surface return. However, since there were mathematical limitations to this approach in very shallow water areas, no correction was applied in depths under 0.125 m since the optimization was impossible on a water column component containing less than two waveform samples (one sample corresponds to 0.063 m in that scenario). In places where depths were smaller than 0.125 m and over land, the attenuation was fixed at 0.
The waveform processing is summarized and illustrated in
Figure 7.
3.5. Waveform Features’ Extraction
Once all waveform components corresponding to ground or seabed covers were isolated, these intensities time series were converted into pseudo-reflectance series by dividing them with the emitted laser pulse intensity. This allowed us to remove potential bias induced by slightly varying emitted laser intensity. Statistical parameters were then computed on these truncated and normalized waveforms. They were selected based on [
27,
29,
44] and are described in
Table 2.
The terrain’s elevation value was also extracted: for topographic waveforms, it corresponds to the last return’s altitude (computed using traditional time of flight range measurement, extracted from the PC). For bathymetric waveforms, it was computed using the depth of the last return identified by our algorithm and withdrew to the altitude of our detected surface return, positioned with the PC. The vertical reference was the IGN 1969 system.
The spectral features computed on the truncated green waveforms, the IR intensities associated with the points and the elevations were then used as predictors for random forest classifications of ground covers over the study area. The 21,000 items of the dedicated dataset were used for the algorithm’s training, and the 10,500 items of the testing dataset were used to assess the quality of the predictions.
3.6. Random Forest Classification
Contrary to [
29], the data were not rasterized but features were directly classified to produce a 3D habitat map so as to avoid information loss. We also relied on a different classifier to predict data labels. A random forest model with 150 trees was used for the classification step. Considering that we wished to apply it to a dataset containing 24.5 million items after fitting, we chose a high number of trees to populate the forest, knowing that more trees theoretically equal to better classification accuracy and that the number of trees needs to be adapted to the complexity of the dataset. We also based our choice on the observation made in [
45] on several different datasets that state that past 128 trees in the forest, classification accuracy gains become negligible for each additional tree, compared to computational demands. The maximum tree depth was not fixed so that nodes expanded until the leaves were pure. We relied on impurity to determine whether a leaf has to be split or not using the Gini impurity criterion, which was calculated using the following formula:
where
is the probability of class
j. This criterion is close to 0 when the split is optimal.
We controlled the generalizability and over-fitting of the model by monitoring the generalization score obtained on random out-of-bag samples at each fitting step. The random forest implementation of the Python library scikit-learn was used.
3.7. Comparative Study
Random forest classifications were launched on several sets of predictors that were clustered based on their conceptual similarity. The performance metrics of each group of features were then retrieved. This allowed us to evaluate the contribution of each family of feature to the classification accuracy. The feature sets were the following:
Statistical features: mean, median, maximum, standard deviation, variance, amplitude, and total;
Peak shape features: complexity, skewness, kurtosis, area under curve, time range, and height;
Lidar return features: diffuse attenuation coefficient estimated value, maximum, maximum before attenuation correction, position of the maximum in the peak, and associated IR intensity;
Green spectral features: all features extracted from the green waveforms, except elevation (which is later referred to as Z).
We also performed importance variable contribution analysis by dropping green waveform features one by one and computing the classification accuracy difference between the reduced set of 15 predictors and the full 16 attributes.
3.8. Results’ Quality Assessment
Classification performances were assessed by considering the values obtained on the test dataset by the random forest classifier for the following metrics: overall accuracy (OA, ratio of correct predictions, best when its value is 1), precision (fraction of correct predictions among each ground truth classes, best when its value is 1), recall (fraction of correct estimation for each predicted classes, best when its value is 1), and F-score (combination of precision and recall, best when its value is 1). The precision, recall, and F-score were computed for each label, and their unweighted mean was used to compare the results obtained. Confusion matrixes presenting the producer’s accuracies (PA) were also created to analyze the performances of classification on each of the 21 classes.
3.9. Spatialization of the Random Forest Predictions
Although coordinates were not used during classification, the arrays of features were geolocated with the position of the waveform’s last echo, as illustrated by
Figure 5. To visualize our classification results as PCs, we associated the predictions’ vector to these coordinates. This allowed us to obtain the result under the form of a classified PC. The fact that we did not rasterize our data had the advantage of preserving the spatial density and therefore the spatial resolution, while also avoiding the critical issue of mixed pixels [
46].
Each waveform was localized with the planar coordinates of its last return using the PC coordinates. For bathymetric waveforms, this ensured that the effects of refraction of the laser beam on the air/water interface were considered, since the green PC was corrected before data delivery.
5. Discussion
We improved an approach initially designed to distinguish two seabed covers—fine sediment and seagrass—to map all land and sea covers present in our study scene in 3D. The findings showed lidar waveforms can be used to classify and map habitats of the coastal fringe and bridge the gap between marine and terrestrial surveys. All 21 selected classes were classified with at least 70% of accuracy in the best configuration obtained, which had an OA of 90%. Here, we discuss the results obtained regarding the classification predictors and the methodology employed. We also provide potential explanations for the performances of the algorithm.
5.1. Green Waveform Features
Our research partially aimed at exploring whether green lidar waveforms can be relevant for coastal habitat mapping. We defined 16 features to extract from the portions of the waveforms that correspond to layers of ground or seabed covers. These were efficiently retrieved both on land and underwater. However, our approach did not handle extremely shallow waters, where the surface component and the bottom return overlap in the waveforms. In these cases, the peak detection employed did not distinguish the seabed from the water surface and no features were retrieved. There was consequently a 24 m wide band without data in the surf zone on the sand beaches in our processed lidar dataset. We also noticed cases of confusion between seabed return and noise in the water column component of the waveform, which resulted in a mis-located detected seabed. These issues could be handled by improving the way the different waveform components are isolated: using waveform decomposition [
31] or deconvolution [
47,
48] could produce better results on that aspect.
The features defined to describe the spectral signatures of coastal habitats seemed to be equally relevant for land and sea covers mapping. However, they did not provide a highly accurate classification (56% of OA). This can be explained by analyzing the green waveforms obtained with the HawkEye III on land. Since this sensor was particularly designed for bathymetry extraction, its green lasers are set to be powerful enough to reach the seabed up to several dozens of meters in coastal waters. Over land, the laser power is so high that most of the waveforms originating from highly reflective surfaces are saturated. The green wavelength alone might consequently not encompass a fine enough range of intensities over land to allow separation of similar environments such as plane habitats, different types of herbaceous vegetation, etc. The shapes of the saturated waveform returns are also affected: there is lacking information on the shape of the peak around its maximum. This can explain why there was a lot of confusion between topographic habitats when using green waveforms only.
Though green information alone may not be enough to distinguish the 21 habitats accurately, our findings suggested that a finer selection of the waveform attributes used for classification could enhance the green waveform feature predictions. The results presented in
Table 3 and
Figure 8 revealed negative interactions between some of the features chosen. Combining the full sets of statistical and peak shape features (defined in
Section 3.7) resulted in lower accuracy than using them separately. Furthermore, the predictors’ contribution assessment (
Figure 8) showed that out of the 16 predictors, only nine contributed positively to the classification accuracy. This might be due to information redundancy between features relying on similar concepts such as mean and median intensity, for example. It could be due to the correction of attenuation performed on bathymetric waveforms. This exponential correction produced extremely high values of backscattered intensities under water, which made little sense physically. On the other hand, topographic waveforms were not corrected: their typical intensity order of magnitude was several times smaller, which might have disrupted the classifier. Fixing the issue of attenuation correction and using only a selected set of waveform predictors based on an assessment of their contribution would certainly result in better results when using the green wavelength alone.
The three different types of waveform features appeared to be complimentary: the nine predictors with a positive influence on the OA (
Figure 8) represented each feature family defined in
Section 3.7. This was consistent: the shape of the waveform return is characteristic of its nature, and the complexity, length, shape, maximum, and position of its maximum sum up the essential information differentiating one waveform from another.
5.2. Infrared Data
The addition of the IR wavelength increased the OA by 13%. The classification results certainly benefited from IR light’s interaction with water and chlorophyll pigments, which provided essential information for the labelling of vegetation and other topographic classes such as wet sand. Considering that the green wavelength was less adapted to land cover classification, the performance increase obtained by using both lasers was expected.
Our research showed the added value of topobathymetric lidar: on top of providing quasi-continuity between land and water, both wavelengths provided complementary information for land covers’ classification. The IR PC alone could not provide a coastal habitat map since it did not reach the seabed and riverbed; the OA obtained using only this wavelength (24%, presented in
Table 3) confirmed that. They also showed that green lidar features alone do not provide a sufficient basis for classification either, reaching an OA of only 56%. Coupling both wavelengths improved the overall result significantly, bringing together the strengths of IR data on land covers, and the ability of green lidar to penetrate the water surface. The matrixes presented in
Figure A4 and
Figure A5 show that the addition of IR intensities to green waveform features resulted in an accuracy increase for all but two of the 21 classes. The gain ranged between 0% (submerged sand) and 39% (tar). The minimum accuracy observed over the 21 labels rose from 21% to 29%. Water covers classes such as seagrass and submerged rock also benefited from the addition of IR intensities, as their accuracy showed an improvement of 1% and 6%, respectively. As HawkEye III is tailored for bathymetry, its green laser’s power was set to be high, which resulted in saturated intensities over land. The IR channel provided complimentary information in places when the green channel was weaker, which partially explains the algorithm’s performances we observe. The classification accuracies obtained for land covers confirm that; for example, the classification of soil, wet sand, and lawn was significatively enhanced: +28%, +34%, and +23% of OA, respectively. Our future work will focus on exploiting both IR and green waveforms for habitat classification, to maximize the accuracy attainable with full-waveform topobathymetric lidar.
5.3. Ground and Seabed Elevation
Similarly to the IR data, elevations contributed greatly to the improvement of the OA of the habitat classification, but could not be separated from spectral predictors and used alone to provide accurate detection of land and sea covers. Indeed,
Table 3 revealed that elevations produced a classification with an OA of 55%, which is less than what can be achieved with spectral predictors. This was expected since many different habitats coexist at similar altitudes and are mainly differentiated by their reflectance. However, for some others, mainly salt marsh types, elevation is an intrinsic quality and the base of their definition. This explains why those are the type of classes that benefited the most from the addition of elevation to a set of spectral predictors in terms of classification accuracy. Respectively, the classification accuracy of low salt marsh, mid salt marsh, and high salt marsh rose from 71%, 76%, and 21% by adding elevations to the green waveform features in the set of predictors (see
Figure A4 and
Figure A6).
Even though elevation combined with spectral information already provided high classification accuracy (90%, see
Table 3), the values extracted with our approach were not always consistent with those provided by the original PCs in marine areas, as explained above. To remove artifacts due to water quality, a post-processing step could be implemented, and the neighboring elevations could be used to regularize the processed PC obtained.
5.4. Classification Approach
Our results showed that topobathymetric lidar is fitted to the classification of coastal habitats. Although elevations, IR intensities, and green waveform features did not produce high accuracy classifications of the land-water continuum, they were complimentary and achieved high-precision results when combined. To the best of our knowledge, no similar papers proposing point-based land and water covers mapping from bispectral lidar data were published, so no direct comparisons of results are possible. However, our observations corroborate those made in [
35], which successfully used random forest algorithms to classify full-waveform lidar data over urban areas and obtained an overall accuracy of over 94% when identifying four types of land covers. This paper only focuses on terrestrial areas but confirms the high accuracy we observe when using waveform features without rasterization for mapping purposes. Class-wise, our results seem more homogeneous for the land covers we have in common, although this means that our approach performs less accurately than theirs on some urban classes. Indeed, ref. [
35] presents a PA of 94.8% for buildings, which is higher than we observe on our roof class (89%), but our vegetation classes (trees and shrubs) have an average PA of 82.6%, while theirs is 68.9%, and our natural ground classes (soil, lawn, salt marsh) reach an average PA of 91.6%, higher than the 32.7% presented in [
35]. Our approach and the method introduced in [
35] perform similarly on artificial ground (for us, tar and concrete), with PAs of 96% and 96.4%, respectively.
Although we found no other research performing point-based classification of subtidal, intertidal, and supra-tidal habitats, we can compare our findings to those in [
34], where the authors also observed that the use of waveform data improves seabed maps and obtained an OA of 86% for their classification of seabed substrates and aquatic macrovegetation. Their approach provides a better mapping of low underwater vegetation on soft substrate (100% versus 85% of PA in our case) but a less accurate detection of hard seabed substrate (68% versus 90% of PA in our study). Again, although we have less accurate results for some classes, our method seems to provide more balanced and homogeneous performances among different classes.
Our results also confirm those from [
27], where 19 land-water continuum habitats were classified with an OA of 90%, and in which the authors concluded that the best classification results were obtained when combining spectral information and elevation. However, in [
27], the authors used digital models of waveform features that they obtained by rasterizing their data, and they relied on an ML classifier. Although our metrics are similar, our classification has the advantage of preserving the spatial density and repartition of the data.
Other studies such as [
49,
50,
51] used 2D lidar-derived data and imagery along with machine learning classifiers to map similar coastal habitats as the ones we attempted to map. They obtained performance scores in the same range as ours, with OA between 84% and 92%. The authors did not use waveform data in these studies and observed low accuracy when classifying only digital elevation models obtained with lidar surveys, therefore requiring the additional processing of imagery. Our approach has the advantage of requiring only one source of data out of the two sources often used in existing literature, which facilitates both acquisition procedures and processing.
Globally, our results are in line with [
27,
35,
52], which all state that bathymetric lidar waveforms are well suited for benthic habitats mapping and observe the same complementarity between spectral and elevation information for habitat mapping. Our method offers an OA similar to existing research in lidar data classification for habitat mapping, while extending the application to a wider range of habitats—both marine and terrestrial—and avoiding information loss through rasterization. Although the PAs obtained for some classes are lower than results previously presented in other studies [
34,
35], this method also has the advantage of offering homogeneous performances and low inter classes PA differences, contrary to other existing research results [
34,
35].
The random forest models trained showed low overfitting, as the extended application results illustrated. The classification of boats located outside of the training and test data collection area, for example, illustrated that the classifiers obtained could be applied to other datasets accurately. Natural, semi-natural and anthropic habitats were well distinguished, and vegetation was precisely isolated, which opened perspectives for ecological assessments of those coastal areas. The remaining errors often involved classes that were close semantically. For example, there was confusion between salt marsh and high natural grasses but low confusion between lawns and low marsh. A potential improvement could be to review the classes defined initially and distinguish vegetation by layers (herbaceous, arbustive, arborescent) and by their natural, semi-natural, or anthropic nature.
Besides the quality of the training and test datasets established, a source of explanation for remaining classification errors could be found in the technical specifications of the sensor. The diameter of the HawkEye III’s green laser’s footprint is 1.80 m, which means that the returned waveform condensates information in a 2.5 m2 area. This parameter may have had an influence on the ability of a given array of features to describe pebble or sand, mostly at interfaces between habitats. This could partially explain the confusion between deciduous and evergreen trees: in a mixed-species forest, two different trees can coexist in a 2.5 m2 patch.
Although the main issues identified visually reflected in the metrics computed on the test dataset, there was a gap between the estimated quality of the map and the statistics computed. For example, the classification of portions of sandy beaches as pebble was not as obvious in the confusion matrix as it is in the map. This showed the influence of the way the test dataset is built. Further work should try to incorporate validation maps in addition to test datasets to qualify the output on the complete study site. A finer tree species inventory could also be integrated to better assess the results obtained.
Nonetheless, our results highlighted a strong classification approach, leveraging the strengths of 3D bispectral data. Working at the PC scale and not in 2D opens perspectives for 3D classifications, identifying all layers of land and sea cover, mostly in vegetated areas, by using waveform segmentation instead of waveform PC segmentation, as experimented in [
53]. It also shows possibilities for post-processing and neighbor-based result regularization, as well as the exploitation of spatial information through the addition of geometrical features such as roughness or local density. Lastly, the accurate classification of habitats through 3D data offers opportunities for structural ecology assessments and communication of these results to environmental managers through virtual reality or more relatable 3D visualizations, for the implementation of sustainable integrated management of coastal areas.
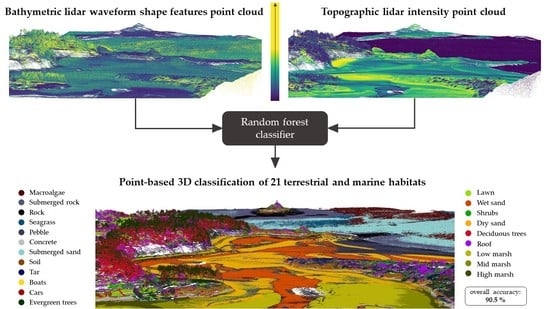
Figure 14 provides a 3D view of the 3D habitat mapping achieved in the present study.


 ,
, 





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









































