


Research on Intelligent Crack Detection in a Deep-Cut Canal Slope in the Chinese South–North Water Transfer Project

 , ,
, ,
Abstract
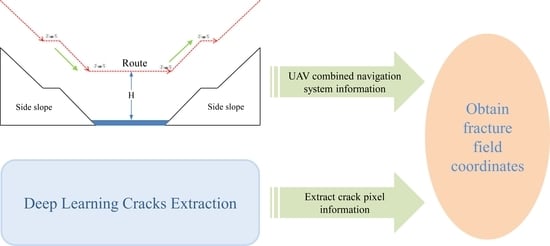
:
1. Introduction
- (1)
- Introducing the ground-imitating flying technique of a UAV to obtain ultra-high-resolution remote-sensing image data of channel slopes; the image resolution can reach millimeter level, which can meet the identification needs of fine cracks;
- (2)
- Using deep-learning image-processing methods and constructing a channel crack image dataset for intelligent, fast, and accurate acquisition of fracture information from massive, ultra-high-resolution remote-sensing images;
- (3)
- Using unmodeled data for combined UAV navigation information and pixel information of cracks on the image, a pioneering method for rapidly locating crack fields is proposed.
2. Review
2.1. Analysis of the Current Status of the South–North Water Transfer Channel Safety Monitoring Study
2.2. Image Fine Line Target Detection Methods
2.3. Rapid Geolocation Method for Images
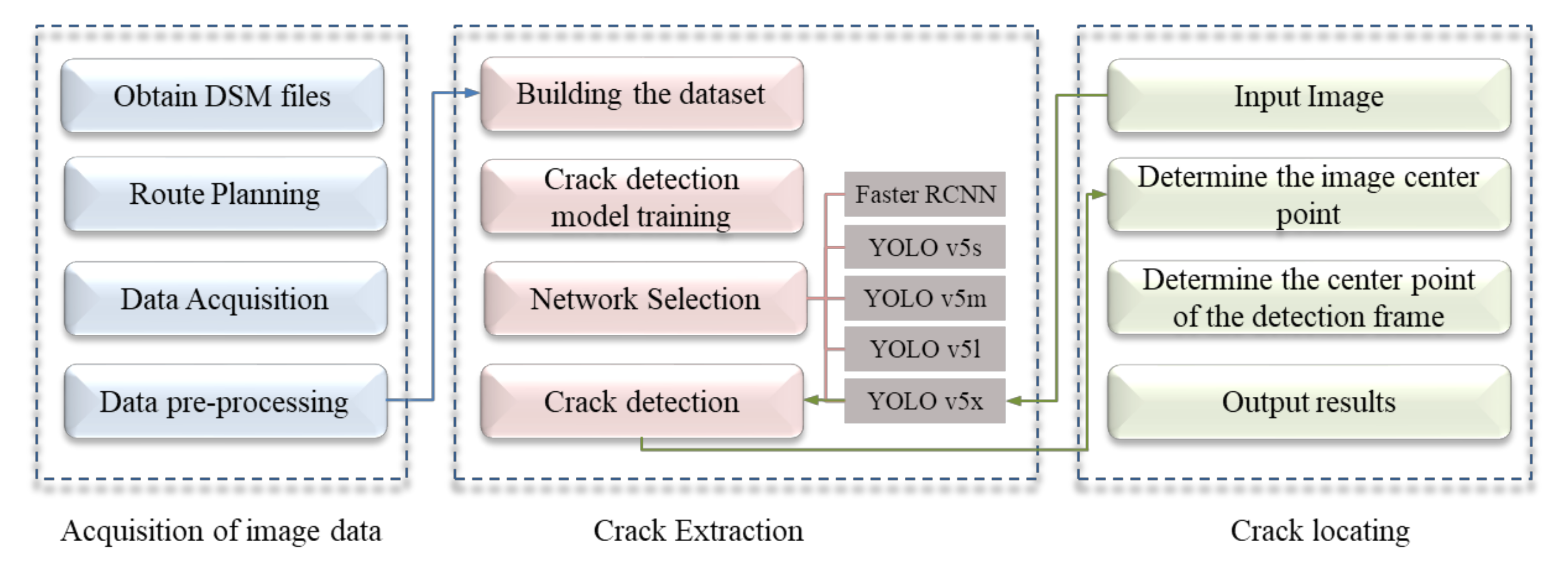
3. Materials and Methods
3.1. The Crack Plane’s Overall Right-Angle Coordinate-Acquisition Process
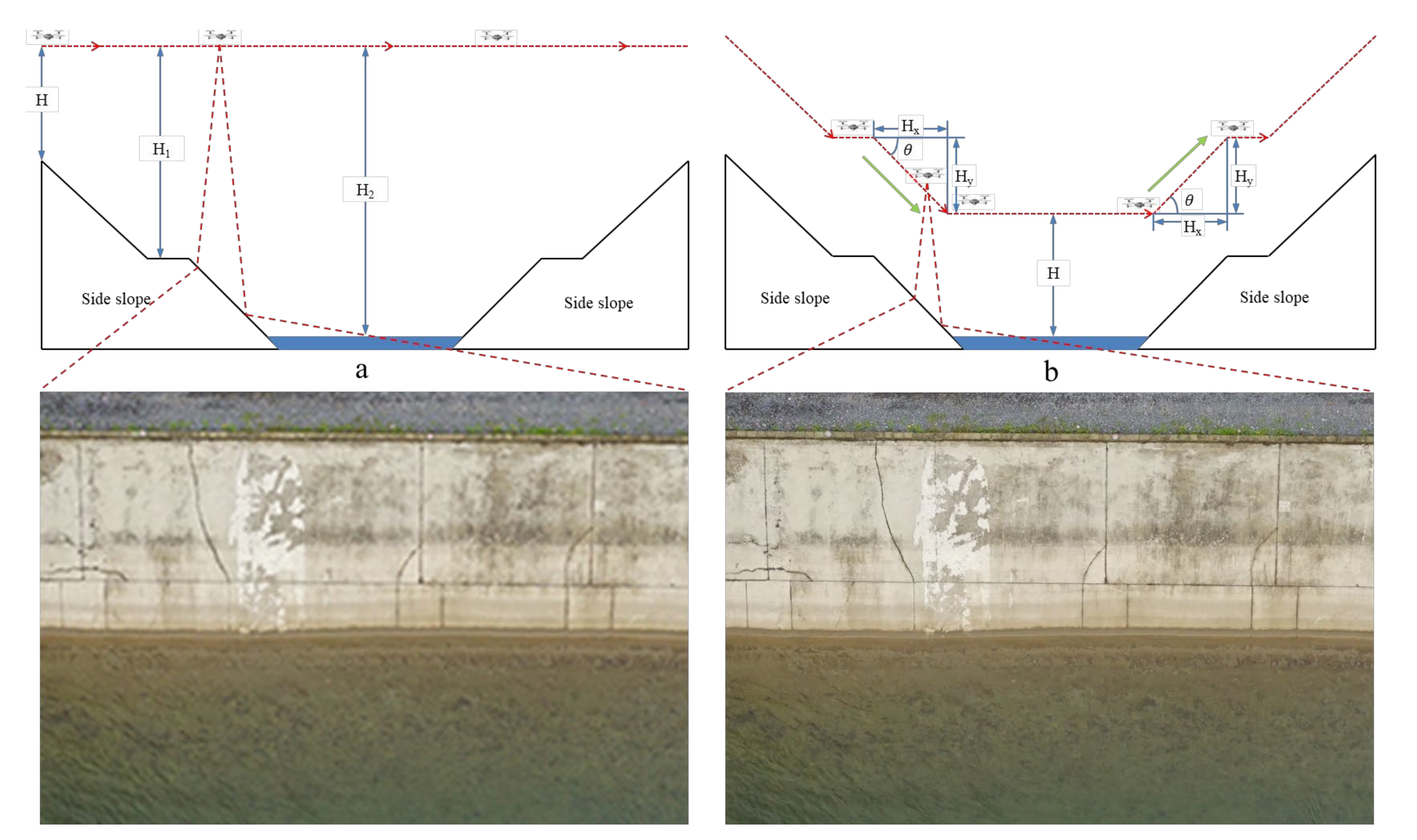
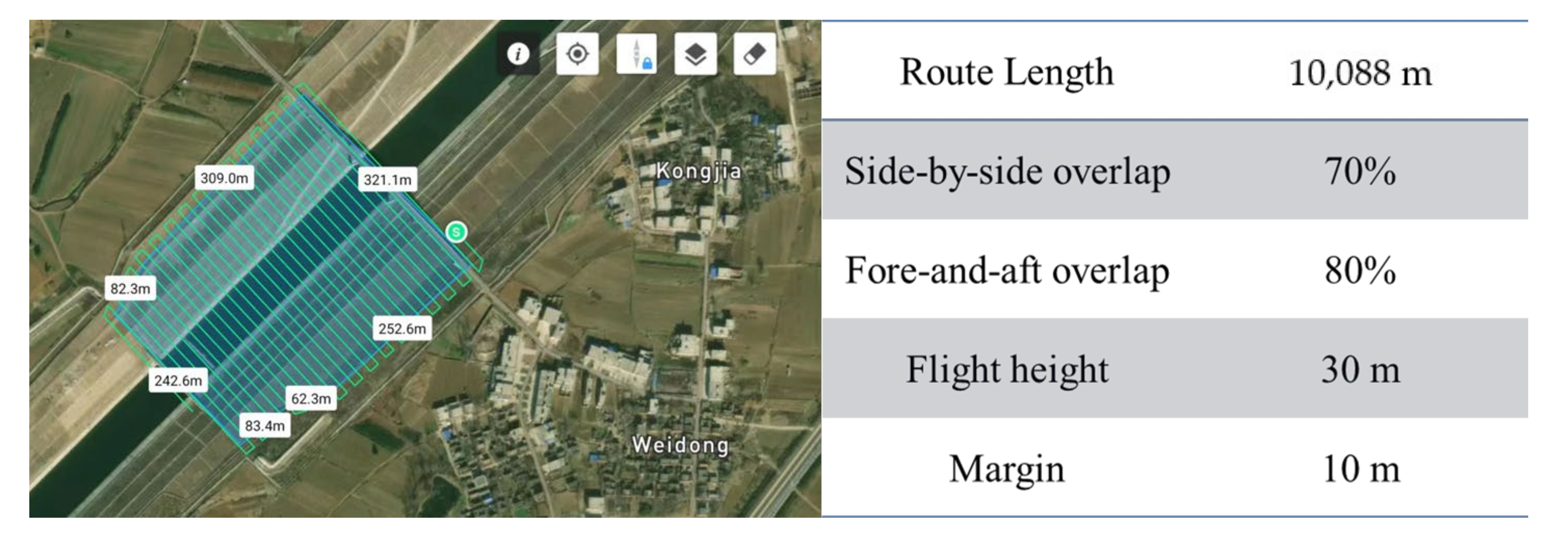
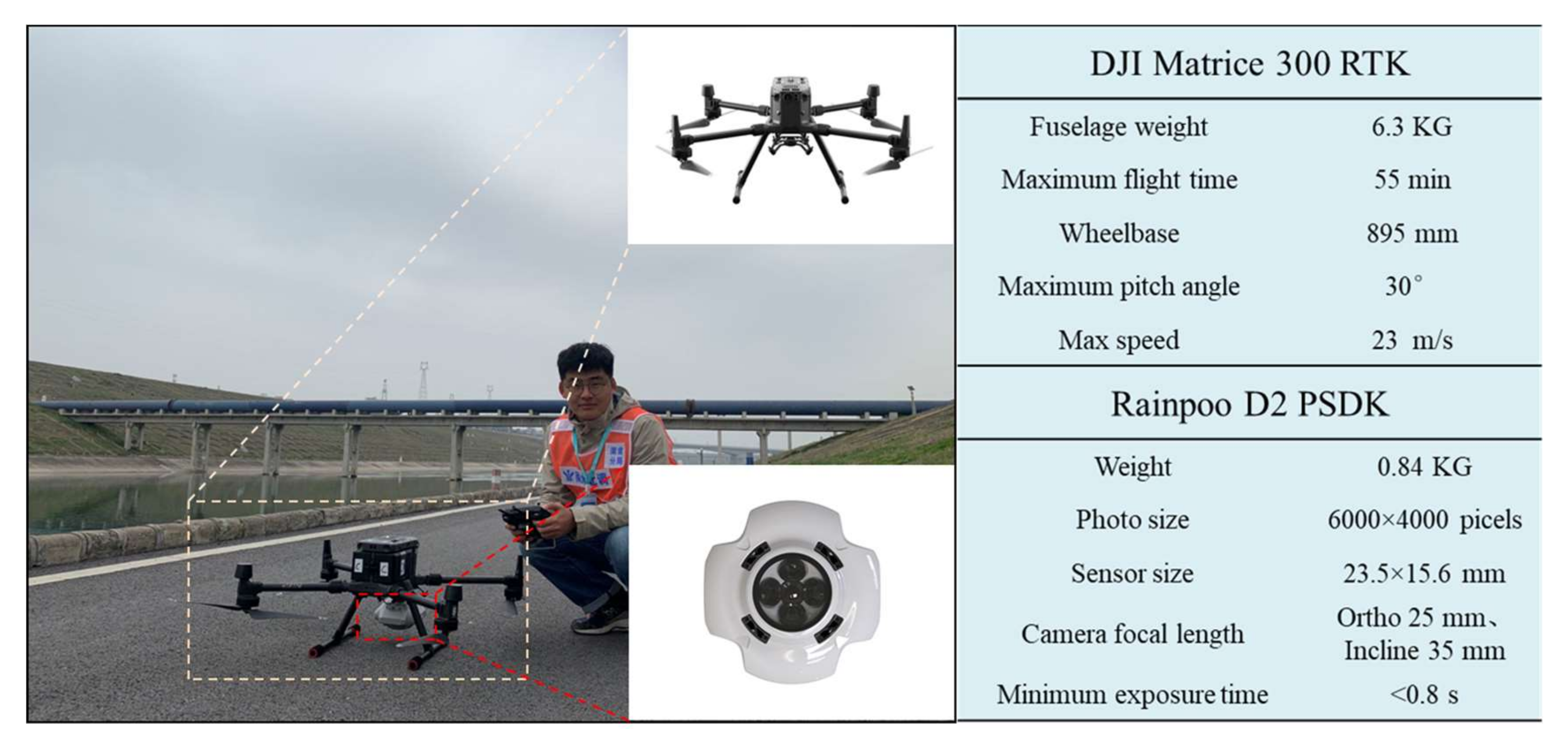
3.2. UAV Ground-Imitating Flying Measurement Remote-Sensing Image Acquisition
3.3. Channel Slope Crack-Detection Methods
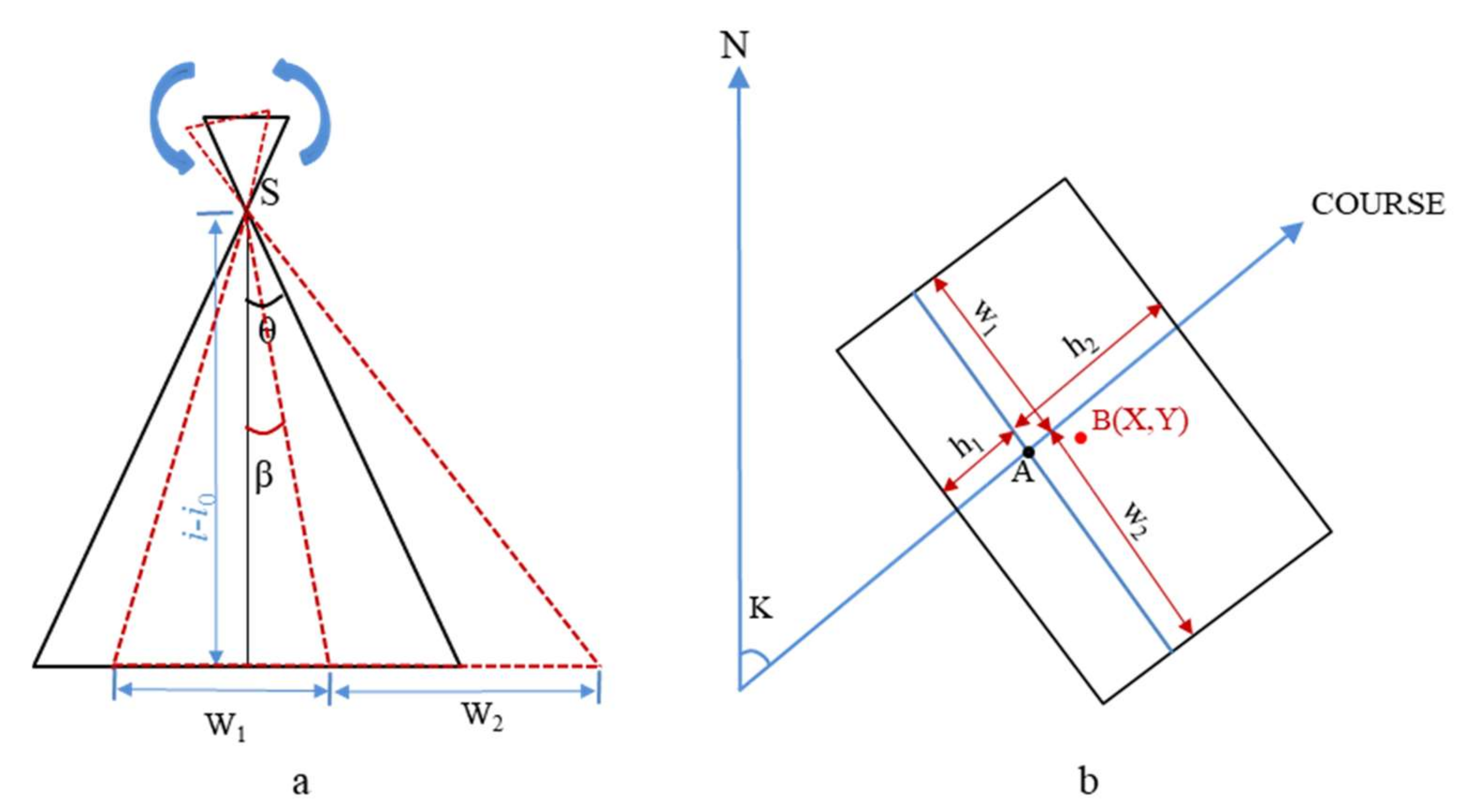
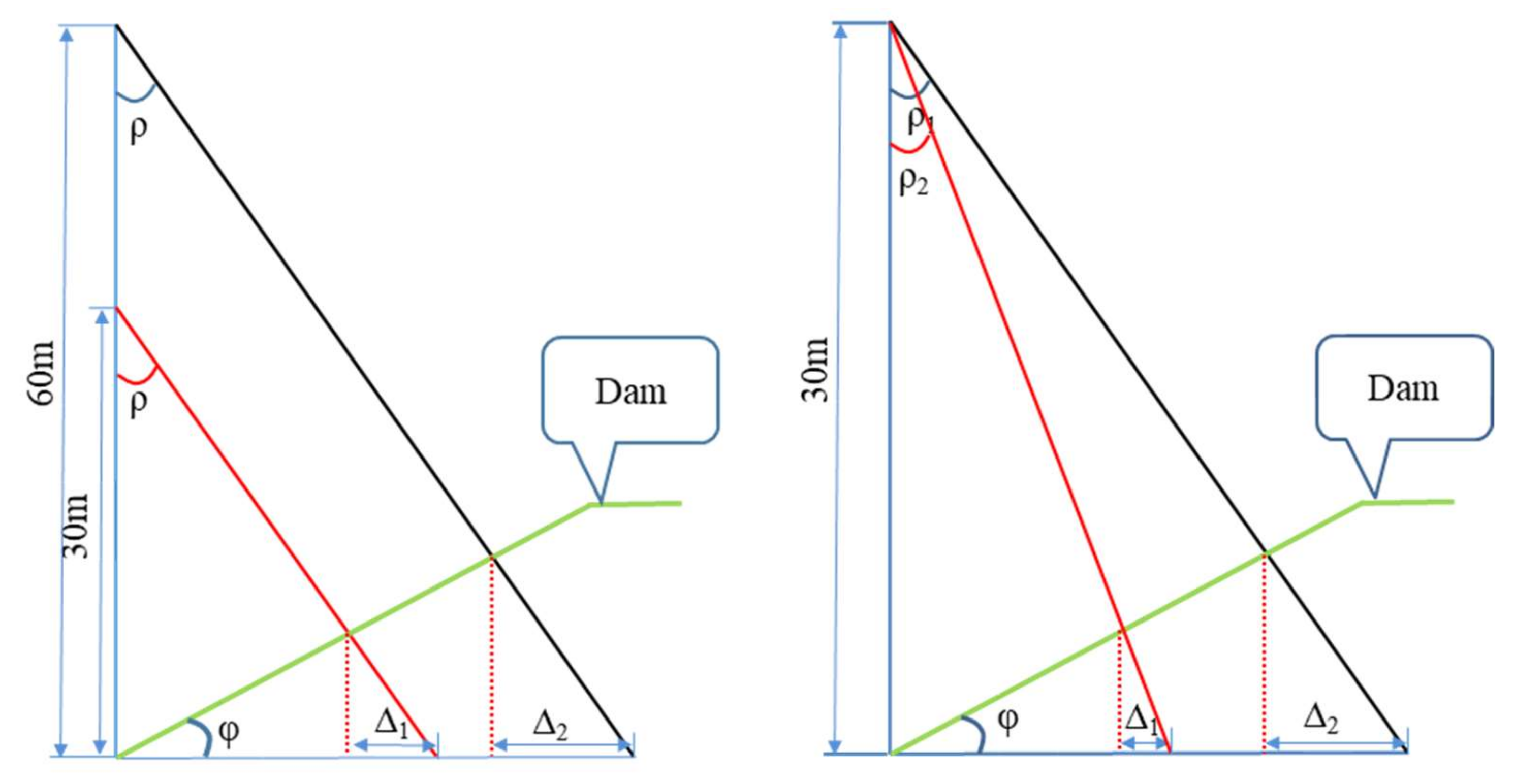
3.4. Channel Slope Crack Plane Right-Angle Coordinate-Acquisition Method
4. Experiment and Discussion
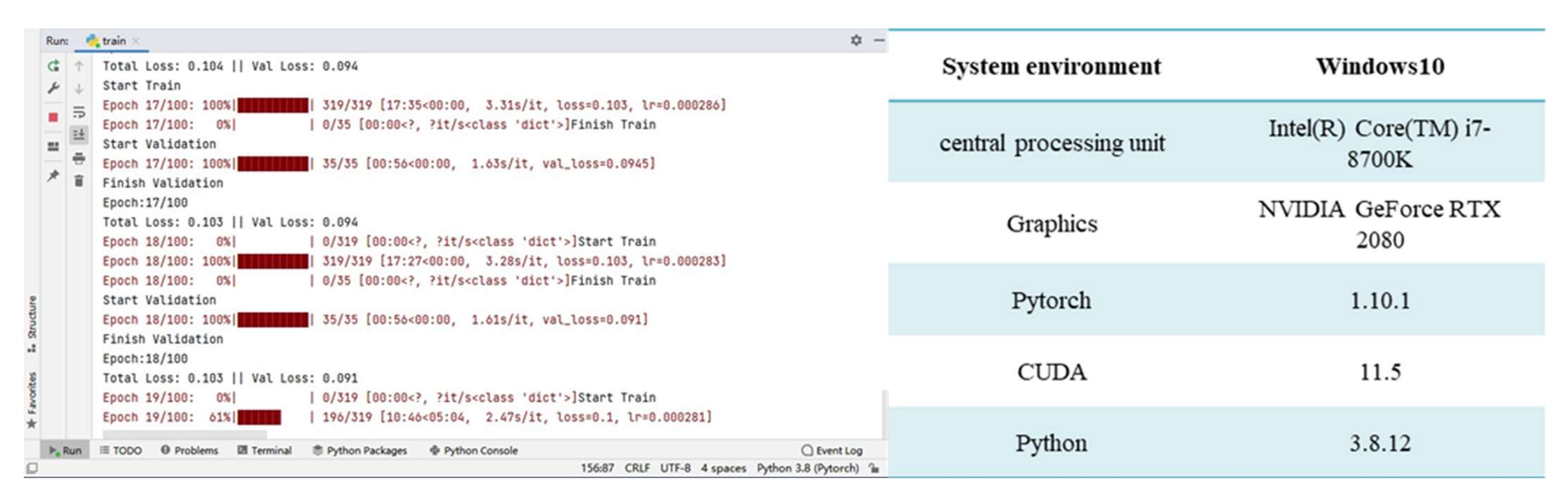
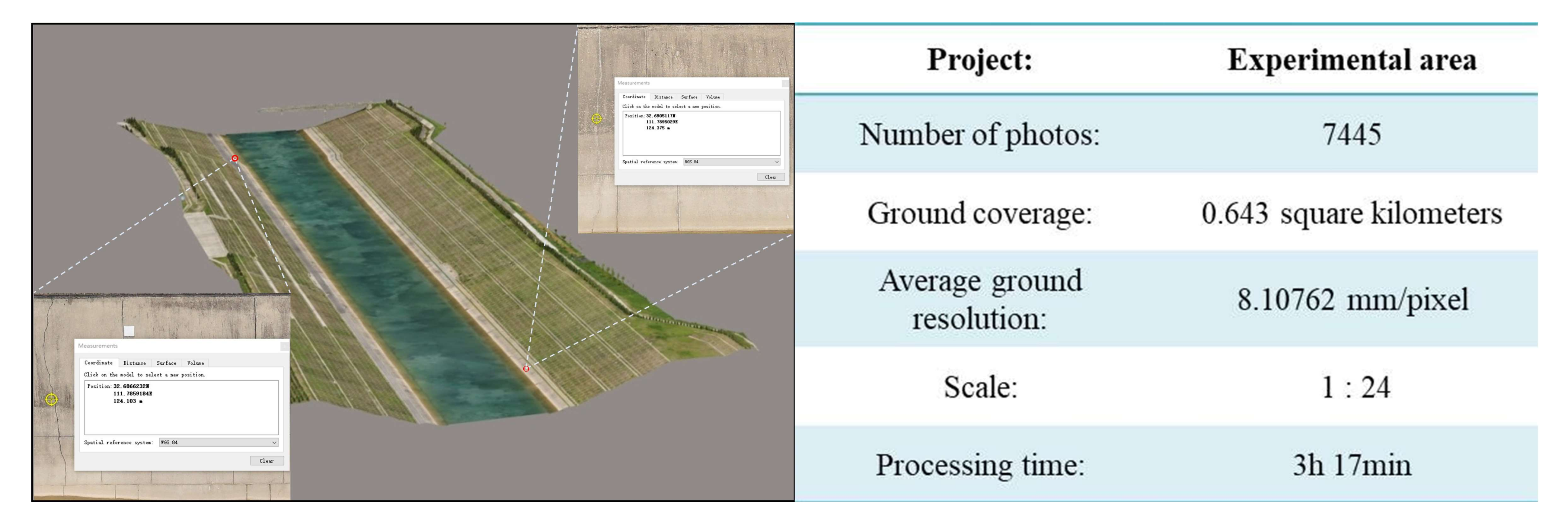
4.1. Experimental Data and Environment Configuration
4.2. Detection Results of Slope Cracks in Different Models of Channels
4.3. Application Analysis
5. Discussion
5.1. Data Acquisition and Pre-Processing Methods
- Making a dataset with cropped and preprocessed image data can improve the overall performance of the crack-detection model. The UAV flight height is set to 30 m due to the terrain characteristics of the survey area. The crack is small compared to the whole image, and the YOLO v5x network is less effective in recognizing small targets, so the features of small-sized cracks will be lost during the training process. After the data are preprocessed by cropping, the cracks are relatively larger than the cropped image, so the YOLO v5x network will be more comprehensive in learning the crack features, making the trained model more robust.
- The accuracy of crack positioning can be improved in the crack-positioning stage. Since geometric distortion exists in all orthophotos, the geometric distortion is larger the farther away it is from the central region. In this study, the fast-localization principle based on a single image is based on the geometric relationship between the image and its mapping area, so the cropped preprocessed image retains the area with less geometric distortion, reducing the impact of geometric image distortion on the localization accuracy.
5.2. Processing Massive Data Using Deep Learning
5.3. Single-Image Positioning Method
6. Conclusions
- (1)
- This study marks the first collection of data from the deep-cut canal slope section of the Chinese South–North Water Transfer Project by using a ground-imitating flying UAV technique, which ensures that all the images collected from the deep-cut canal slope section are of super-clear resolution and provide excellent discrimination of the channel side slope cracks. At the head of the network, the image-cropping preprocessing module is added to ensure a good detection effect for small cracks, which speeds up the overall detection rate and improves the accuracy of crack localization.
- (2)
- The YOLO v5x deep-learning model is selected to detect the channel slope, and the experiments show that the model outperforms other models in both detection accuracy and recall rate index. The YOLO v5x model detects cracks with a recall rate of up to 92.65%, an accuracy rate of up to 97.58%, and an F1 value of 0.95. There are fewer misses and errors in the detection process, and crack detection can be completed well.
- (3)
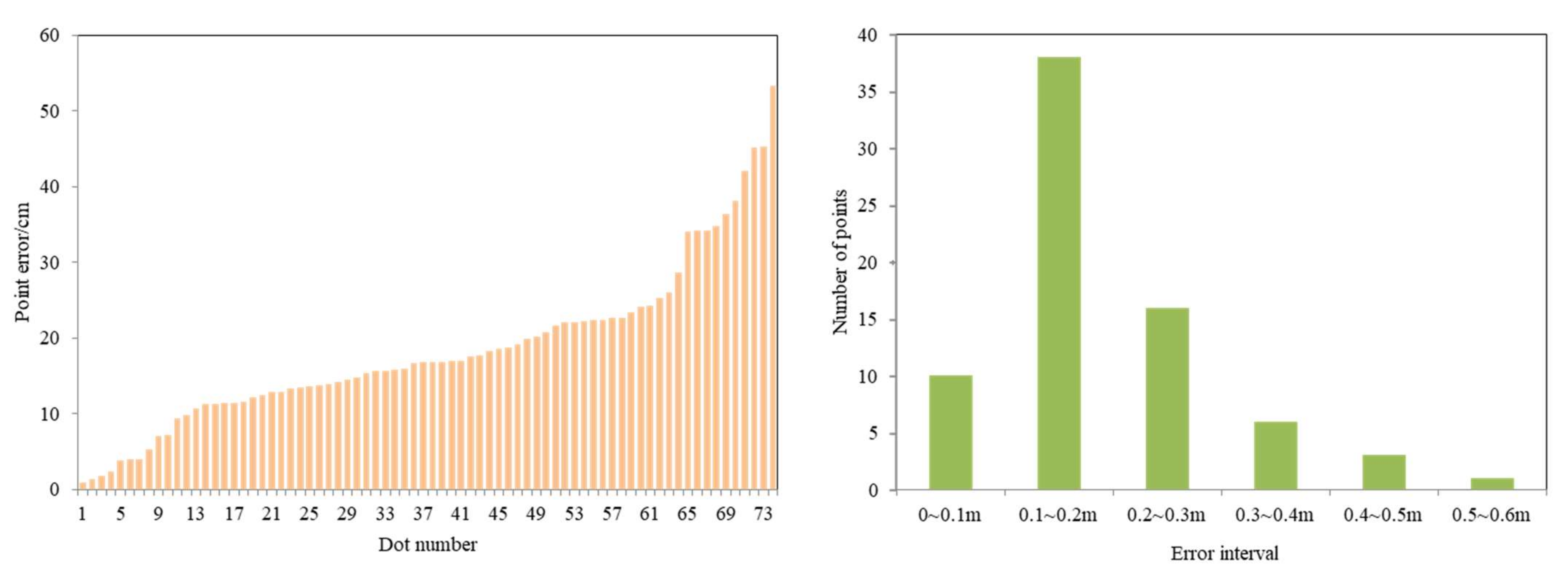
- Based on the crack-detection results from the crack-detection model, the crack-field positioning of a single image is realized by combining the image with the UAV navigation information. It is verified that the error of crack field positioning is within 0.6 m, and 73% of the crack point position error can be controlled to within 0.3 m. The South–North Water Transfer Project is a linear feature, and the sub-meter level positioning accuracy is sufficient to provide the field position of cracks. The method of acquiring the geographical coordinates of channel side slope cracks proposed in this study can control the point position error to within 0.6 m, which is fully capable of detecting and locating the cracks of a wide range of channel slopes, reducing workloads and improving working efficiency.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Liu, W.; Gong, T.; Hu, Q.; Gong, E.; Wang, G.; Kou, Y. 3D reconstruction of deep excavation and high fill channel of South-to-North Water Diversion Project based on UAV oblique photography. J. North China Univ. Water Resour. Electr. Power (Nat. Sci. Ed.) 2022, 43, 51–58. [Google Scholar]
- Liu, Z.; Luo, H.; Zhang, M.; Shi, Y. Study on expansion-shrinkage characteristics and deformation model for expansive soils in canal slope of South-to-North Water Diversion Project. Rock Soil Mech. 2019, 40, 409–414. [Google Scholar]
- Dai, F.; Dong, W.; Huang, Z.; Zhang, X.; Wang, A.; Cao, S. Study on Shear Strength of Undisturbed Expansive Soil of Middle Route of South-to-North Water Diversion Project. Adv. Eng. Sci. 2018, 50, 123–131. [Google Scholar]
- Vanneschi, C.; Eyre, M.; Francioni, M.; Coggan, J. The Use of Remote Sensing Techniques for Monitoring and Characterization of Slope Instability. Procedia Eng. 2017, 191, 150–157. [Google Scholar] [CrossRef] [Green Version]
- Casagli, N.; Cigna, F.; Bianchini, S.; Hölbling, D.; Füreder, P.; Righini, G.; Del Conte, S.; Friedl, B.; Schneiderbauer, S.; Iasio, C.; et al. Landslide mapping and monitoring by using radar and optical remote sensing: Examples from the EC-FP7 project SAFER. Remote Sens. Appl. Soc. Environ. 2016, 4, 92–108. [Google Scholar] [CrossRef] [Green Version]
- Jia, H.; Wang, Y.; Ge, D.; Deng, Y.; Wang, R. Improved offset tracking for predisaster deformation monitoring of the 2018 Jinsha River landslide (Tibet, China). Remote Sens. Environ. 2020, 247, 111899. [Google Scholar] [CrossRef]
- Chen, Z.; Yin, Y.; Yu, J.; Cheng, X.; Zhang, D.; Li, Q. Internal deformation monitoring for earth-rockfill dam via high-precision flexible pipeline measurements. Autom. Constr. 2022, 136, 104177. [Google Scholar] [CrossRef]
- Zhou, J.; Shi, B.; Liu, G.; Ju, S. Accuracy analysis of dam deformation monitoring and correction of refraction with robotic total station. PLoS ONE 2021, 16, e0251281. [Google Scholar] [CrossRef]
- Dong, J.; Lai, S.; Wang, N.; Wang, Y.; Zhang, L.; Liao, M. Multi-scale deformation monitoring with Sentinel-1 InSAR analyses along the Middle Route of the South-North Water Diversion Project in China. Int. J. Appl. Earth Obs. Geoinf. 2021, 100, 102324. [Google Scholar] [CrossRef]
- Vazquez-Ontiveros, J.R.; Martinez-Felix, C.A.; Vazquez-Becerra, G.E.; Gaxiola-Camacho, J.R.; Melgarejo-Morales, A.; Padilla-Velazco, J. Monitoring of local deformations and reservoir water level for a gravity type dam based on GPS observations. Adv. Space Res. 2022, 69, 319–330. [Google Scholar] [CrossRef]
- Xie, L.; Xu, W.; Ding, X.; Bürgmann, R.; Giri, S.; Liu, X. A multi-platform, open-source, and quantitative remote sensing framework for dam-related hazard investigation: Insights into the 2020 Sardoba dam collapse. Int. J. Appl. Earth Obs. Geoinf. 2022, 111, 102849. [Google Scholar] [CrossRef]
- Liu, Y.; Xie, Z.; Liu, H. LB-LSD: A length-based line segment detector for real-time applications. Pattern Recognit. Lett. 2019, 128, 247–254. [Google Scholar] [CrossRef]
- Von Gioi, R.G.; Jakubowicz, J.; Morel, J.-M.; Randall, G. LSD: A fast line segment detector with a false detection control. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 722–732. [Google Scholar] [CrossRef] [PubMed]
- Von Gioi, R.G.; Jakubowicz, J.; Morel, J.-M.; Randall, G. LSD: A Line Segment Detector. Image Process. Line 2012, 2, 35–55. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Koch, R. An efficient and robust line segment matching approach based on LBD descriptor and pairwise geometric consistency. J. Vis. Commun. Image Represent. 2013, 24, 794–805. [Google Scholar] [CrossRef]
- Yamaguchi, T.; Mizutani, T. Detection and localization of manhole and joint covers in radar images by support vector machine and Hough transform. Autom. Constr. 2021, 126, 103651. [Google Scholar] [CrossRef]
- Zhang, X.; Liao, G.; Yang, Z.; Li, S. Parameter estimation based on Hough transform for airborne radar with conformal array. Digit. Signal Process. 2020, 107, 102869. [Google Scholar] [CrossRef]
- Pang, S.; del Coz, J.J.; Yu, Z.; Luaces, O.; Díez, J. Deep learning to frame objects for visual target tracking. Eng. Appl. Artif. Intell. 2017, 65, 406–420. [Google Scholar] [CrossRef] [Green Version]
- Choi, K.; Lim, W.; Chang, B.; Jeong, J.; Kim, I.; Park, C.-R.; Ko, D.W. An automatic approach for tree species detection and profile estimation of urban street trees using deep learning and Google street view images. ISPRS J. Photogramm. Remote Sens. 2022, 190, 165–180. [Google Scholar] [CrossRef]
- Sayed, A.N.; Himeur, Y.; Bensaali, F. Deep and transfer learning for building occupancy detection: A review and comparative analysis. Eng. Appl. Artif. Intell. 2022, 115, 105254. [Google Scholar] [CrossRef]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Joshi, D.; Singh, T.P.; Sharma, G. Automatic surface crack detection using segmentation-based deep-learning approach. Eng. Fract. Mech. 2022, 268, 108467. [Google Scholar] [CrossRef]
- Ali, R.; Chuah, J.H.; Talip, M.S.A.; Mokhtar, N.; Shoaib, M.A. Structural crack detection using deep convolutional neural networks. Autom. Constr. 2022, 133, 103989. [Google Scholar] [CrossRef]
- Zhang, J.; Qian, S.; Tan, C. Automated bridge surface crack detection and segmentation using computer vision-based deep learning model. Eng. Appl. Artif. Intell. 2022, 115, 105225. [Google Scholar] [CrossRef]
- Yu, Z.; Shen, Y.; Shen, C. A real-time detection approach for bridge cracks based on YOLOv4-FPM. Autom. Constr. 2021, 122, 103514. [Google Scholar] [CrossRef]
- Yang, J.; Fu, Q.; Nie, M. Road Crack Detection Using Deep Neural Network with Receptive Field Block. IOP Conf. Ser. Mater. Sci. Eng. 2020, 782, 042033. [Google Scholar] [CrossRef]
- Chen, T.; Jiang, Y.; Jian, W.; Qiu, L.; Liu, H.; Xiao, Z. Maintenance Personnel Detection and Analysis Using Mask-RCNN Optimization on Power Grid Monitoring Video. Neural Process. Lett. 2019, 51, 1599–1610. [Google Scholar] [CrossRef]
- Sharma, V.; Mir, R.N. Saliency guided faster-RCNN (SGFr-RCNN) model for object detection and recognition. J. King Saud Univ.—Comput. Inf. Sci. 2022, 34, 1687–1699. [Google Scholar] [CrossRef]
- Zhao, S.; Kang, F.; Li, J. Concrete dam damage detection and localisation based on YOLOv5s-HSC and photogrammetric 3D reconstruction. Autom. Constr. 2022, 143, 104555. [Google Scholar] [CrossRef]
- Liu, J.; Zhao, Z.; Lv, C.; Ding, Y.; Chang, H.; Xie, Q. An image enhancement algorithm to improve road tunnel crack transfer detection. Constr. Build. Mater. 2022, 348, 128583. [Google Scholar] [CrossRef]
- Herrero, M.J.; Pérez-Fortes, A.P.; Escavy, J.I.; Insua-Arévalo, J.M.; De la Horra, R.; López-Acevedo, F.; Trigos, L. 3D model generated from UAV photogrammetry and semi-automated rock mass characterization. Comput. Geosci. 2022, 163, 105121. [Google Scholar] [CrossRef]
- Elhashash, M.; Qin, R. Cross-view SLAM solver: Global pose estimation of monocular ground-level video frames for 3D reconstruction using a reference 3D model from satellite images. ISPRS J. Photogramm. Remote Sens. 2022, 188, 62–74. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Category | Accuracy (m) | Number of Calibrated Photos | RMS of Reprojection Error (pixels) | RMS of Distances to Rays (m) | 3D Error (m) | Horizontal Error (m) | Vertical Error (m) |
|---|---|---|---|---|---|---|---|---|
| D1 | 3D | Horizontal: 0.01; Vertical: 0.010 | 30 | 0.33 | 0.00552 | 0.00261 | 0.00257 | 0.00044 |
| D2 | 3D | 29 | 0.13 | 0.00418 | 0.00114 | 0.00074 | 0.00086 | |
| D3 | 3D | 26 | 0.16 | 0.00439 | 0.00185 | 0.00072 | 0.0017 | |
| D4 | 3D | 29 | 0.2 | 0.00467 | 0.00184 | 0.00137 | −0.00123 | |
| D5 | 3D | 32 | 0.24 | 0.0039 | 0.00296 | 0.00112 | −0.00274 | |
| D6 | 3D | 31 | 0.23 | 0.00728 | 0.0021 | 0.00172 | 0.00122 |
| YOLO v5s | YOLO v5m | YOLO v5l | YOLO v5x | |
|---|---|---|---|---|
| Depth_multiple | 0.33 | 0.67 | 1.00 | 1.33 |
| Width_multiple | 0.50 | 0.75 | 1.00 | 1.25 |
| No. | B0 | L0 | i | i − i0 | β | α | K |
|---|---|---|---|---|---|---|---|
| 1 | 32.6857671 | 111.7858132 | 171.845 | 30 | 1.285 | −6.077 | 47.738 |
| 2 | 32.6857792 | 111.7858263 | 171.860 | 30 | −6.346 | −7.725 | 47.407 |
| 3 | 32.6857907 | 111.7858397 | 171.804 | 30 | −5.057 | −6.735 | 48.072 |
| 4 | 32.6858062 | 111.7858586 | 171.734 | 30 | −5.725 | −7.843 | 47.720 |
| 5 | 32.6858271 | 111.7858844 | 171.596 | 30 | −3.727 | −7.573 | 47.737 |
| Models | TP | Recall | Precision | F1-Score | FPS | Model Size (M) |
|---|---|---|---|---|---|---|
| Faster RCNN | 1812 | 93.15% | 98.32% | 0.96 | 5 | 522 |
| YOLO v5s | 1626 | 83.60% | 96.85% | 0.89 | 34.5 | 27 |
| YOLO v5m | 1683 | 86.53% | 97.03% | 0.91 | 31.8 | 84 |
| YOLO v5l | 1752 | 90.08% | 96.83% | 0.93 | 28.6 | 192 |
| YOLO v5x | 1802 | 92.65% | 97.58% | 0.95 | 26.3 | 367 |
| No. | B | L | X | Y | x | y | Δx | Δy | Δ |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 32.68804115 | 111.7875100 | 3,648,128.981 | 228,722.352 | 3,648,128.964 | 228,722.356 | −0.017 | 0.004 | 0.017 |
| 2 | 32.68989372 | 111.7896728 | 3,648,319.436 | 228,942.128 | 3,648,319.489 | 228,942.123 | 0.053 | −0.005 | 0.053 |
| 3 | 32.68795927 | 111.7874096 | 3,648,120.599 | 228,712.183 | 3,648,120.634 | 228,712.197 | 0.035 | 0.014 | 0.038 |
| 4 | 32.69037368 | 111.7892436 | 3,648,376.040 | 228,905.875 | 3,648,376.000 | 228,905.788 | −0.040 | −0.087 | 0.096 |
| 5 | 32.68978919 | 111.7895845 | 3,648,308.441 | 228,932.904 | 3,648,308.545 | 228,932.956 | 0.104 | 0.052 | 0.116 |
| 6 | 32.68779782 | 111.7862056 | 3,648,111.457 | 228,597.389 | 3,648,111.567 | 228,597.410 | 0.110 | 0.021 | 0.112 |
| 7 | 32.68933022 | 111.7880129 | 3,648,268.860 | 228,780.903 | 3,648,268.704 | 228,780.837 | −0.156 | −0.066 | 0.169 |
| 8 | 32.68920729 | 111.7878633 | 3,648,256.267 | 228,765.745 | 3,648,256.111 | 228,765.777 | −0.156 | 0.032 | 0.159 |
| 9 | 32.68783291 | 111.7862416 | 3,648,115.102 | 228,601.077 | 3,648115.194 | 228,601.020 | 0.092 | −0.057 | 0.108 |
| 10 | 32.68996726 | 111.7887767 | 3,648,334.203 | 228,858.374 | 3,648,334.258 | 228,858.486 | 0.055 | 0.112 | 0.125 |
| 11 | 32.69006801 | 111.7888819 | 3,648,344.652 | 228,869.155 | 3,648,344.748 | 228,869.069 | 0.096 | −0.086 | 0.129 |
| 12 | 32.68927322 | 111.7879452 | 3,648,263.008 | 228,774.036 | 3,648,263.145 | 228,774.147 | 0.137 | 0.111 | 0.176 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Q.; Wang, P.; Li, S.; Liu, W.; Li, Y.; Lu, W.; Kou, Y.; Wei, F.; He, P.; Yu, A. Research on Intelligent Crack Detection in a Deep-Cut Canal Slope in the Chinese South–North Water Transfer Project. Remote Sens. 2022, 14, 5384. https://doi.org/10.3390/rs14215384
Hu Q, Wang P, Li S, Liu W, Li Y, Lu W, Kou Y, Wei F, He P, Yu A. Research on Intelligent Crack Detection in a Deep-Cut Canal Slope in the Chinese South–North Water Transfer Project. Remote Sensing. 2022; 14(21):5384. https://doi.org/10.3390/rs14215384
Chicago/Turabian StyleHu, Qingfeng, Peng Wang, Shiming Li, Wenkai Liu, Yifan Li, Weiqiang Lu, Yingchao Kou, Fupeng Wei, Peipei He, and Anzhu Yu. 2022. "Research on Intelligent Crack Detection in a Deep-Cut Canal Slope in the Chinese South–North Water Transfer Project" Remote Sensing 14, no. 21: 5384. https://doi.org/10.3390/rs14215384
APA StyleHu, Q., Wang, P., Li, S., Liu, W., Li, Y., Lu, W., Kou, Y., Wei, F., He, P., & Yu, A. (2022). Research on Intelligent Crack Detection in a Deep-Cut Canal Slope in the Chinese South–North Water Transfer Project. Remote Sensing, 14(21), 5384. https://doi.org/10.3390/rs14215384