1. Introduction
Natural and social properties of the land surface can be presented by land cover. The land cover map shows the local or overall landscape state of a region, based on which we are able to study environmental change trends. On the other hand, it can be used to assess urban development and estimate the extent of the impact of natural disasters. With the information from land cover maps, city managers can make better decisions and anticipate the impact of those decisions on the region in advance [
1].The identification of land types to obtain high-precision land use maps has been a longstanding research topic. The pixel-level classification for remote sensing images has been widely used over the past decades [
2]. It relies on the spectral features for classification, such as vegetation index, building index, and others. Then, the inversion of land use type information was obtained by the analysis of multispectral satellite images [
3,
4,
5]. Another classification method is to build a classifier to explore the semantic features between pixels [
2,
3,
6]. Currently, with the advances in sensors and computer technology, the remote sensing images have higher spatial resolution and more complex pixel representation. For such images, the traditional image interpretation methods [
7,
8] may not meet the efficiency and accuracy of the real application. As a result, researchers in the remote sensing community have shifted their attention to methods-based deep learning. With robust feature modeling capabilities, deep learning has achieved unprecedented progress in many tasks in remote sensing, such as land cover classification, scene classification, and object detection [
9].
The trend toward deep learning began in 2012 when AlexNet [
10] won the ImageNet Large Scale Visual Recognition Challenge, marking the shift of image tasks from the era dominated by machine learning methods to that of deep convolutional neural networks (DCNNs). Limited by the classification task, AlexNet could only output a probability of the sample as part of a category. It could not judge the category of each pixel within the whole image. The FCN [
11] model proposed a pixel-level semantic segmentation by encoding-decoding convolutional neural networks and unveiled the key problems in semantic segmentation: loss of spatial information, insufficient perceptual field, and missing contextual information [
12]. UNet [
13] combined high-level semantic and fine-grained information and the convolutional deepening idea, and effectively improved the performance of the semantic segmentation network for large-sized graphics. The proposed PSPNet [
14] is a PPM module to obtain contextual information in different regions. SegNet [
15] achieved a significant increase in inference speed by replacing convolutional layers with empty convolution [
14]. DeepLab [
16], obtaining large perceptual fields through dilated convolution and the large kernel in its ASPP module, was also used for context information capture. HRNet can keep spatial information during the pixel decoding by keeping high-resolution representations through the whole pipeline. All these networks are based on the FCN’s convolutional neural network codec architecture.
Due to the limitations of convolutional kernels, they can accept contextual information over only a short range, as shown in
Figure 1c. As a result, previous studies have reported various types of attention mechanisms to acquire better long-range information [
17], although they may cost more inference time. PSANet [
18] developed a point-by-point spatial attention module for the dynamic capture of global context information. DANet embedded both spatial attention and channel attention. VIT [
19] applied the transformer [
20] architecture based solely on attention mechanisms to image information extraction and pioneered a visual recognition method based on image patches. A variety of visual transformer-based approaches have subsequently emerged, such as the Swin Transformer [
21] and SETR [
22]. And SegFormer [
23] specifically designed a simple decoder for the transformer backbone, using only six linear layers for per pixel prediction, effectively exploiting the long-range semantics of the transformer encoder. The transformer and attention mechanism effectively improve the performance of various downstream tasks, including semantic segmentation, but the tradeoff is the large dataset and a significant amount of training time.
For remote sensing imagery segmentation, high background complexity and indistinguishable classes are two challenging problems. As shown in the first row of
Figure 1, the white boxes show multiple objects in the background, while the yellow boxes show the similarity between low vegetation and trees. Feature pyramid or image patch-based approaches cannot further improve performance because they focus only on pixel representations and lack deeper supervision of category objects. PFNet [
24] adopts the point-wise affinity propagation module in the pixel decoder, which performs sparse mapping during forward between, improving training efficiency while reducing a large amount of noise from the background category. However, it does not consider interclass feature distinctions, and this results in ineffective recognition of indistinguishable classes. To enhance the representation of each pixel, MaskFormer [
25] proposes a new idea for the panoramic segmentation task inspired by encoding category object features; it encodes object features into learnable queries, and then optimizes the binary mask and determines its class by object queries. It should be highlighted that the encoding of the image category representations is much less computationally intensive than pixel-by-pixel attention.
Based on the aforementioned excellent works, we proposed a cross-attention-based pixel augmented model to handle the problems stated above. It aims to maximize the use of category spatial information in the image, as shown in
Figure 1d. Our main contributions are as follows:
We propose an object-embedding queries module for augmenting the category representation of each pixel, which can model complex category features, and effectively improve the segmentation accuracy of the model for indistinguishable classes and background. The effectiveness of this module is verified in two remote sensing segmentation datasets with different resolutions, the Potsdam dataset and GID-15 dataset.
Employing the cross-attention and transformer module to extract long-range semantic features in images. Both category representation decoding and encoding used cross-attention, but the details of their settings were a little different (See
Section 3.2 and
Section 3.3).
We designed a simplified feature pyramid for fusing the hierarchical features that were extracted by the backbone network at different stages; it reduces a large number of model parameters and provides high-quality representation for cross-attention during category representation decoding.
2. Related Works
Our method focuses on several key points: semantic segmentation on high-resolution remote sensing images; pixel decoding; object embedding queries; transformer module; interaction of cross-attention semantic features with spatial context information; and booster training with auxiliary output.
2.1. Semantic Segmentation
Early works on land cover classification primarily used surface features such as the color and texture of images for manual visual interpretation classification [
26,
27], or simple supervised classification [
28,
29] and unsupervised classification [
30]. After neural networks became popular, a series of network models applied to remote sensing images were developed [
6]. To date, the most widely used method for image characteristic extraction is still deep network classification based on image spatial information and contextual features. This technique is often referred to as deep learning-based semantic segmentation, whose pipeline is based on the FCN’s encoder-decoder structure. FCN replaced fully connected layers with convolutional layers and introduced deconvolution, the improvement of more than 20% compared with previous methods on the PASCAL VOC dataset, and solved the problem of CNNs model converging slowly and demanding fixed-size input. There are numerous FCN-based models for land cover classification, building detection, agricultural monitoring, and other scenarios. However, the accuracy of these methods is still affected by the problem of intra-class diversity and inter-class similarity Recently, some works attempted to obtain semantic information from different categories by extracting additional pixel-wise information. HPSNet [
31], for example, utilized a mini-branch in the part of the encoder for global feature optimization, and demonstrated on the GID-5 and GID-15 datasets that the use of mini-branches in the network optimization process resulted in better pixel-level optimal path selection for coding the distribution of land cover.
The method we proposed introduces cross-attention to the decoder, which effectively embeds the category representation into each pixel of the samples, and implements the segmentation of indistinguishable classes.
2.2. Pixel Decoder
Our pixel decoder contains two parts: feature fusion and feature upsampling. The classical means of feature fusion are addition and concatenation [
11,
32]. Feature pyramid networks (FPNs) [
33] fuse low-resolution features with spatial information and high-resolution features with texture features by addition, alleviating the problem of multi-scale target missing. Additionally, the feature alignment module proposed by FaPN [
34] added an additional bias to the fusion of features at different resolutions to match their positions, which reduces the error generated by features during upsampling. HRNet [
35] concatenates features of different resolutions obtained after multi-resolution fusion convolution, retains rich semantic information and more precise spatial information., and has achieved excellent scores on a large number of tasks, including semantic segmentation, human pose estimation, and object detection.
To obtain faster speed while reflecting the effectiveness of our designed object embedding queries and cross-attention, instead of using a complex pixel decoder with a large number of parameters, we simply fuse multiresolution features by concatenation from top to bottom of the feature pyramid.
2.3. Contextual Information
Unlike remote sensing scene classification [
36], the semantic segmentation task concerns the spatial details of the image and contextual information, and the problem often faced in remote sensing images lies in the large differences in target scales and uneven distribution of categories. To solve this kind of problem of spatial context information extraction, BiSenet [
37] set up two branching structures to extract detailed information and semantic information and connected them. This enhanced their feature representations through a bidirectional aggregation layer. DANet [
38] sets up a channel attention branching network to capture correlations between spatial locations. ACFNet [
39] proposed a class feature representation of Class Center, which first obtained coarse segmentation results and then implemented feature-to-class mapping at each pixel point for final refinement output through a class attention mechanism, where the formation of class region features was unsupervised. Based on this category-level contextual feature embedding, HRNet [
35] fused the high-resolution image features and low-resolution image features stored in its backbone to generate category object representations and regional pixel representations, and supervise the generation of coarse segmentation maps by ground truth, solving the problem that coarse segmentation accuracy could not be improved.
We designed flexible object embedding queries that can flexibly transform the dimension according to the characteristics of the target remote sensing image to overcome this challenge.
2.4. Transformer and Cross-Attention
The original transformer model was proposed for sequence-to-sequence machine translation tasks. It consisted of multiple encoder-decoder architectures. There are several different application approaches in computer vision. VIT [
19] used only encoders; MaskFormer [
25] used only decoders; and DETR [
40] used both encoders and decoders. The transformer model consisted of multiple encoder-decoder architectures where the encoder is divided into two parts: self-attention and feed-forward networks. The decoder adds a cross-attention layer between these two parts compared with the encoder, which is used to aggregate the encoder’s output and the input features of the decoder [
20].
Global contextual information is significant, and attention can effectively improve the performance of long-range semantic modeling. CCNet [
41] extracted the correlation tensor from the underlying features to obtain the correlation between a pixel and its horizontal and vertical pixel points, and combined it with vector-containing semantic features. OCRNet [
35] extracts the relationship between each pixel and the object region in which the pixel is located, representing object features as category queries, and assigns the object features to each pixel in the sample using a transformer decoder-like structure with cross-attention. OCRNet provides an efficient method for contextual feature aggregation.
All these methods use cross-attention to generate per-pixel features at different scales or different categories, and output predictions with generation of the high-resolution feature map. Obviously, the pixel-by-pixel category features encoding leads to a spike in the number of parameters when the model restores the resolution. In our method, we solved this problem by decoding and encoding category representations by two different cross-attentions, respectively.
2.5. Auxiliary Loss
Auxiliary tasks are commonly used a priori in multitask learning (MTL) [
42] to facilitate the process of learning optimization. In semantic segmentation tasks, like BiSenet [
37] and PSPNet [
14], auxiliary loss functions are used in convolutional layers to make use of the idea of hierarchical feature progression in the semantic segmentation encoder-decoder to make predictions on different layers of features so that the features can be effectively mined and the weights of primary and auxiliary losses balanced with the help of parameters. In contrast, the network DETR [
40] and MaskFormer [
25] that use the transformer architecture give the loss ensemble by a redundant class token, and the token with the smallest loss is selected to participate in the loss balancing, preventing the problem of uneven category distribution in image patches. SETR [
22] upsampled the features to the original resolution output as an auxiliary loss. In summary, the auxiliary loss can optimize the network training process, and has the advantage of not increasing the time spent in the inference phase.
3. Methods
The remote sensing imagery-based land cover classification problem is solved by obtaining the probability distribution
y of
pixels in an image and assigning it to one of the species in one of the label categories
with the highest probability. Formally,
where
denotes a
-dimensional probability simplex.
denotes the probability that pixel
belongs to a category, and
is the set of
output by the segmentation model of all pixels in the sample image. To train a segmentation model for pixel-by-pixel classification, each pixel is assigned to a ground truth category
. As in Equation (2):
where
indicates the category to which each pixel in the sample image is assigned. Then, the loss is calculated by the loss function. Based on the pixel category cross-entropy as Equation (3):
Accurate and efficient acquisition of pixel class probability
is the main task of segmentation. An overview of our method to obtain segmented prediction is shown in
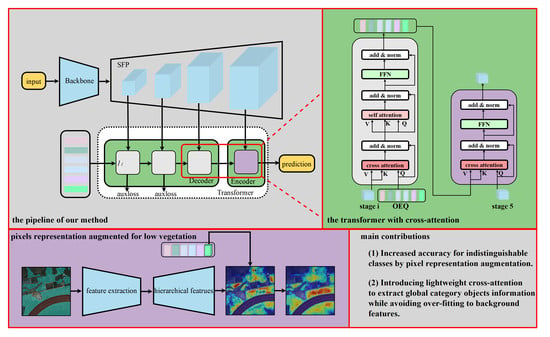
Figure 2, and our proposed scheme is as follows:
(1) Feature pyramid-based pixel decoding; (2) generating learnable object embedding queries and extracting category-contextual features by decode cross-attention; (3) augmenting the per-pixel feature representation by aggregating category-contextual information with encoder cross-attention.
3.1. Pixel Decoder
The backbone used for semantic segmentation usually constructs a collection of features from high to low resolution. Based on the idea of the feature pyramid [
33], we fused features of different resolutions by one feature space transformation (by a 1 × 1 convolutional layer) and one semantic feature extraction (by a 3 × 3 convolutional layer) and upsample them to the higher-level features to achieve the fusion of multiscale features. The pixel decoder module can be written as Equation (4):
We call this module the simplified feature pyramid (SFP), and the structure is shown in
Figure 3, which serves to aggregate the hierarchical features extracted by the backbone. When the image size of the input model is
, the backbone extracts a series of features with different resolutions
, where
is the number of feature channels and
is the downsampling multiplicity. The maximum downsampling rate chosen in our method is
, and
are the features after SFP.
is the feature space transformation function implemented by
convolution.
is the feature extraction function implemented by 3 × 3 convolution → GN → ReLU. Concat is the function that concatenates each feature in the channel dimension. Before concatenation, we sample all resolution features down to
.
3.2. Object Embedding Queries and Decoder Cross-Attention
The label that each pixel has expressed is the semantic label of the object in which the pixel is located. Based on this concept, we use a set of learnable object embedding queries (OEQs) to aggregate the contexture features of all pixels through category objects.
As shown in
Figure 4 (left), the object embedding queries structure the image into
object regions, represented as
, train it interactively with the four stages of features expressed through the feature fusion module SFP in the transformer decoder module with different stages of pixel-level features for the purpose of aggregating each pixel representation in the image.
The transformer containing the decoder cross-attention used in this paper uses a similar setup as in DETR [
40], with the
-dimensional object embedding queries initialized to a zero vector, a learnable position encoding attached to each query of the input, and an auxiliary loss function after each transformer. Additionally, considering the model inference time, we reduce the transformer stack and use only three transformer layers. In addition, we move the self-attention module to the back of the cross-attention module to avoid useless training at the beginning.
In the transformer decoder, long-range semantic modeling is performed by attention mechanisms. The attention mechanism usually means that the weight matrix containing similarity information is normalized by softmax and then applied to the transformed features by the dot product, and an output containing contextual information is obtained. In addition, we construct the weight mask, which is used to reduce the computational effort of the network and accelerate the convergence. Our object embedding queries are updated in the decoder cross-attention (with a shortcut layer) as Equation (5):
where
is the decoder layer index corresponding to the number of stages in SFP,
represents the object embedding queries output by the
lth layer decoder, and α is the attention
. In
Figure 5, this is computed as a softmax normalization of the dot-product between queries
and keys
for querying the correlation between features and categories for each pixel (We set
to a number greater than or equal to the number of classes, and
is a feature embedding index).
is the binarized output of the previous transformer encoder layer by sigmoid activation (thresholded at 0.5). Moreover, attention weight
at the cross attention is as follows:
Here, and denote input object embedding queries to the transformer decoder. , and are the linear transformations for mapping image features to different feature spaces, and and correspond to the resolution of the spatial feature output from the pixel decoder module.
3.3. Encoder Cross-Attention
The encoder cross-attention is also contained in the transformer module (See
Figure 4 (right)). Unlike the decoder cross-attention, it did not use the self-attention. Encoder cross-attention was used to augment each pixel representation output from the SFP by
object embedding queries as in
Figure 6 and Equation (7):
where
is the output from the decoders, and
and
are two linear transformations with a ReLU activation. The attention weights
between pixel
and category
are calculated as in Equation (8), which is similar to Equation (6):
where
is the unnormalized relation function, and
and
are two linear transformations. Note that we used 3 decoder layers and added an encoder with the same settings after each decoder layer for the auxiliary output. In our experiments, only the last layer of the decoder output was very competitive.
3.4. Loss Function
The average of focal loss [
43] and dice loss [
44] have been implemented in our work because of their potential to tackle class imbalance in remote sensing images. For example, the number of pixels on impervious surfaces and buildings is much larger than that on cars. These two loss functions have been computed under a binary classification after the one-hot encoder.
is the probability that the pixel belongs to class
, with the background of class
probability being
. Moreover, the same loss functions are used in the auxiliary loss.
Focal loss (FL) focuses training on hard negatives and can be expressed as:
where
and
are the modulating factors,
is used to increase the weight of the category with fewer samples in the loss function, and
is used to increase the weight of samples with larger classification loss in the loss function.
Dice loss (DL) is based on the Dice coefficient, which is used to gauge the similarity of two samples as follows:
Here, are the voxel values from the reference foreground segmentation. Furthermore, the second term on the right side of the above equation represents the predictive performance of the category foreground, and the third term represents the predictive performance of the background.
To optimize the learning process, we supervise the training of our proposed method using the auxiliary loss function, whose number depends on the number of layers of the transformer decoder L. The output of the whole network is calculated from the object query output of the last decoder layer. The weight between the auxiliary loss and main loss is balanced by the parameter α and the depth of the decoder. Each loss function is composed of the two loss functions mentioned above, and the loss ratio of the two loss functions results is 1:1. The final loss function can be written as Equation (11):
where
is the main loss,
is the auxiliary loss of the
ith layer of the decoder,
is the output of the transformer decoder,
is the number of layers of the transformer decoder, and
is the joint loss function. In the network, we only perform the inference of the auxiliary function in the training phase.
4. Experimental Results
In this section, we present the details of the datasets used and implementation of the model. Then, we performed an analysis of the performance to assess the impact of each component of the model through ablation experiments and a comparison with state-of-the-art models of the same type. The results reported here concern the final accuracy and inference speed of the model in different benchmark tests.
4.1. Datasets and Training Setting
The datasets used in this study are the ISPRS open source Potsdam [
45] and Wuhan University open source GID-15 [
46] remote sensing satellite dataset. Our model achieved state-of-the-art results on both datasets.
Potsdam provides 38 GRB three-channel images with 6000*6000 pixels at 5 cm resolution with a segmentation category of 5 classes, excluding No. 7_10, which showed labeling errors. We removed the wrong label and selected 20 of them as the training set, 8 as the validation set, and 9 as the test set. Each image was cropped to 512*512 small images with 5% overlap ratio for each small image when cropping.
GID-15 provides pixel-level labels for 15 categories with reference to the Chinese land use classification standard. This dataset contains 10 sheets with 7200*6800 pixels within the dataset, covering a land area of 506 km2. Because the distribution of land cover in each image is not similar, instead of dividing the dataset into a training set, validation set and test set, we selected the same type of crop as the Potsdam dataset, and then 50% of the selected dataset was used as the training set, 20% as the validation set, and the remaining 30% as the test set.
We trained our model using the PyTorch framework with an RTX3080 GPU with an image input size of 512*512 pixels. We adopted Visual Attention Net [
46] as the backbone. Moreover, we used the AdamW optimizer and cosine annealing rate schedule. An initial learning rate of 2 × 10
-4 was applied in the Potsdam dataset, and 1 × 10
-4 was applied in the GID-15 dataset. A momentum decay of 0.0001 was applied in both of the above datasets. The number of training epochs was 300. For data augmentation, 5–15% random linear stretching, fixed angle rotation, and image inversion were used.
4.2. Accuracy Assessment
For the experiments evaluated on test datasets, we reported the number of parameters, floating-point operations per second (FLOPs), and frames per second (FPS) of the model. In addition, the intersection over union (IoU) was reported as metrics on the GID-15 dataset, and F1-score and overall accuracy (OA) reported on the Potsdam dataset. mIoU is a semantic segmentation metric that calculates the average of the intersection and concatenation ratio for all categories. The F1-score is the harmonic mean of the precision (P) and recall (R). The core idea of the F1-score is to improve P and R as much as possible so that the difference between them is as small as possible. A higher F1-score value indicates a better segmentation performance of the network. OA indicates the global accuracy, regardless of category, considering only how well all samples are classified, i.e., all correctly classified samples divided by the total number of samples. As shown in
Table 1, we reported the main metrics used to evaluate the model, and on both the Potsdam and GID-15 datasets our model shows higher scores than the previous state-of-the-art model PFNet in all metrics.
4.3. Ablation Studies
Baseline. To evaluate the performance of the proposed method, we adopted our pixel decoder module SFP as the segmentation head and upsampled its last stage to obtain the results. Therefore, we compared the pixel decoder module SFP with the FPN model. As shown in
Table 2, although the result of the mean intersection (mIoU) from the SFP model is only 84.3%, 1.1% less than that from the FPN model; however, when we add cross-attention to them, the performance of SFP is better than FPN. This indicates that the spatial feature information gained from the concatenate design at the high-resolution stages of SFP has improved the network structure’s performance.
Learnable Object Embedding Queries (OQE). We defined a learnable object embedding query as a feature embedding a class of objects and performed an object-oriented feature augmentation on the final output by this query. The number of queries has a large impact on the result of the segmentation.
Figure 7 shows our model trained with different numbers of queries on the Potsdam and GID-15 datasets. We find that our model performed best on both datasets when the number of queries was set to approximately 20. This indicates that we do not need to adjust the number of queries in different types of remote sensing datasets. Moreover, the object embedding queries can also enhance performance even without the transformer module. As shown in
Table 3, even if we replaced the transformer encoder with a dot product operation and removed the transformer decoder, the performance of the model is still better than the baseline. The mIoU improved by 1.1 when the transformer decoder is added. The mIoU increased by 1.9 when the transformer encoder was also added.
Transformer Decoder (TrDec.). As the module that contributes the most to the model, we tested their significance by removing components from the transformer decoder one at a time. As shown in
Table 4, the model performance without cross-attention is lower than that of the baseline.
Table 5 shows that our model benefited from multiscale feature resolution and mask attention. Compared with single resolution features (e.g., a single scale of 1/8), the addition of multiresolution features can strengthen the model’s performance, and the attention mask kept the mIoU from increasing the inference time. Additionally, self-attention and FFN in the transformer decoder are also effective in enhancing the representation of object embedding queries after cross-attention. The introduction of different resolution features will effectively improve the model performance.
Transformer Encoder (TrEnc.). In our proposed model, the transformer encoder was used to enhance the representation of semantic features. We used a similar approach as the one for the transformer decoder module for the transformer encoder component validation. As shown in
Table 6, the encoder cross-attention (including the subsequent FFN) can aggregate object region representations more effectively than the dot product.
Figure 8 shows the gradient changes of the features of different objects that have been aggregated by the transformer module.
Auxiliary Segmentation Head. We added the transformer encoder as an auxiliary segmentation head to the SFP at different stages.
Table 7 illustrates the analysis output for experiments in which the insertion of the auxiliary segmentation head in the low-resolution stage helps to improve the model performance. Notably, adding an auxiliary segmentation head to the SFP stage 4 did not seem to get any improvement; therefore, we decided to remove this part to reduce the training time.
4.4. Benchmarking Recent Works on Potsdam Dataset
We also compared it with some semantic segmentation methods [
24,
47] based on output for the Potsdam test dataset in
Table 8. For an objective comparison, we reimplemented some methods using VAN-tiny as the backbone for feature extraction. All methods used patches cropped to 512*512 for inference at a single scale. Our proposed method achieved the best results among all free available models.
4.5. Comparison with State-of-the-Art Networks
In addition to the comparison of the benchmark work, we also conducted comparative experiments on the Potsdam and GID-15 datasets with previous state-of-the-art semantic segmentation works as shown in
Table 9 and
Table 10. Our method outperformed previous models. It is worth noting that on the Potsdam dataset, even though our results are not superior for the categories of buildings and cars, our method slightly outperformed other methods by at least av1% point in terms of the average F1 in both the hard-to-classify categories (e.g., trees and low vegetation) and in the background, as shown in
Figure 9. Similar to the results obtained from the GID-15 datasets, land cover categories that are often overwhelmed by background and other categories (e.g., ponds, garden plots) are identified with much higher accuracy than other models in the experiment and the models in the Learning to Understand Aerial Images (LUAI) 2021 challenge held on ICCV’2021, as illustrated by the results in
Figure 10. This illustrates that our model effectively has improved the semantic representation of indistinguishable classes.
4.6. The Complexity of the Network
In addition to the segmentation accuracy, the model was also evaluated in terms of the number of parameters and speed. We calculated the FLOPs in the ablation study. The number of computations occupied by each module in the network was evaluated. Furthermore, we reported the number of parameters and frames per second (FPS). As shown in
Table 8 and
Table 9, our model achieved better accuracy than large models, while the inference speed was still similar. Note that the fps was tested for the entire test set on an RTX3080 GPU with a batch size of 1.
5. Discussion
Experimental results show that our proposed method can efficiently improve the segmentation accuracy of background and indistinguishable classes. The main contribution to the accuracy improvement comes from the augmentation of pixel representation by object embedding queries. In
Figure 9, notably, the predictions from CNNs [
10] backbone [
16,
24,
38,
50] show unsmooth boundaries and some salt-and-pepper noise, owing to the loss of object contextual information caused by multiple downsampling. We addressed this problem by hierarchical feature fusion. Compared with FPN [
33], UperNet [
50], and PFNet [
24], we focus more on the high resolution pixel representation, which helps indistinguishable classes to get more object details. Additionally, self-attention [
22,
38] and dense affinity learning [
41] over-introduce features of clutter, and models [
35] that rely on these mechanisms to improve model performance have lower accuracy in clutter on both the Potsdam and GID-15 datasets. We addressed this problem by pixel representation augmentation, and achieved the best accuracy in clutter for both datasets. In
Figure 10, the three previous state-of-the-art models [
23] were unable to identify a pond in the clutter, while our approach successfully identifies them.
Of further importance is how the object embedding queries are generated. As shown in
Table 3, the ablation experiments for object embedding queries improve mIoU by 1.1% by using only the transformer decoder without the encoder. So optimizing the generation of coarse segmentation graphs by ground truth [
35,
39] is not better than random initialization of learnable object embedding queries. A better introduction of feature dependencies (e.g., cross-attention) would help the model performance more.
Furthermore, there is a possible misconception that the model has a large number of parameters and is hard to converge employing the concatenation and transformer modules. In fact, our method achieves convergence at about 120 epochs without cosine annealing, much faster than the pure transformer model [
23,
25]. Benefiting from efficient encoding of pixel representations by object embedding queries, high-resolution features do not require too many channels of semantics. Under the same backbone, the number of parameters of our method is 8.5 M, which is a little higher than 6.6 M for FPN [
33], 7.0 M for UperNet [
50], and lower than the 10.5 M for PFNet [
24]. With about the same number of parameters, our method achieves the highest mIoU and OA.
6. Conclusions
In this study, we have proposed a method based on object embedding queries for land cover classification of multi-resolution remote sensing images. Our main goal was to augment the semantic segmentation network to recognize feature types in complex backgrounds and hard-to-classify categories. To achieve this goal, we have used the following settings: (1) We set up a set of object feature embedding queries within the network and augment the feature representation of each pixel. (2) We redesigned the cross-attention module in the transformer for encoding and decoding different classes of image representation. (3) We trained object embedding queries in multilevel features and output auxiliary losses to improve the learning of spatial features. Our experiments show that the above approach effectively extracts category object representations from multiscale pixel representations thereby helping to identify similar categories and backgrounds. Additionally, we designed the SFP based on FPN with a compressed pixel decoding module to minimize the number of parameters and inference time of the model while ensuring there was no loss of performance.
Our work on the Potsdam and GID-15 test datasets showed strong performance, proving that the cross-attention-based transformer can be effectively applied to remote sensing imagery tasks. However, there are still limitations to our method. An SPF stage5 high-resolution feature map as a query in a transformer encoder takes more calculation resources to compute cross-attention and high-dimensional feature mapping; and the more calculation resources it takes, the higher the number of channels from object embedding queries. This is why we set the number of channels in the feature pyramid to 256 and do not use a large backbone. We will investigate how to augment pixel representation with a high number of channels more efficiently in future work.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}