

Spatial Estimation of Regional PM2.5 Concentrations with GWR Models Using PCA and RBF Interpolation Optimization

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
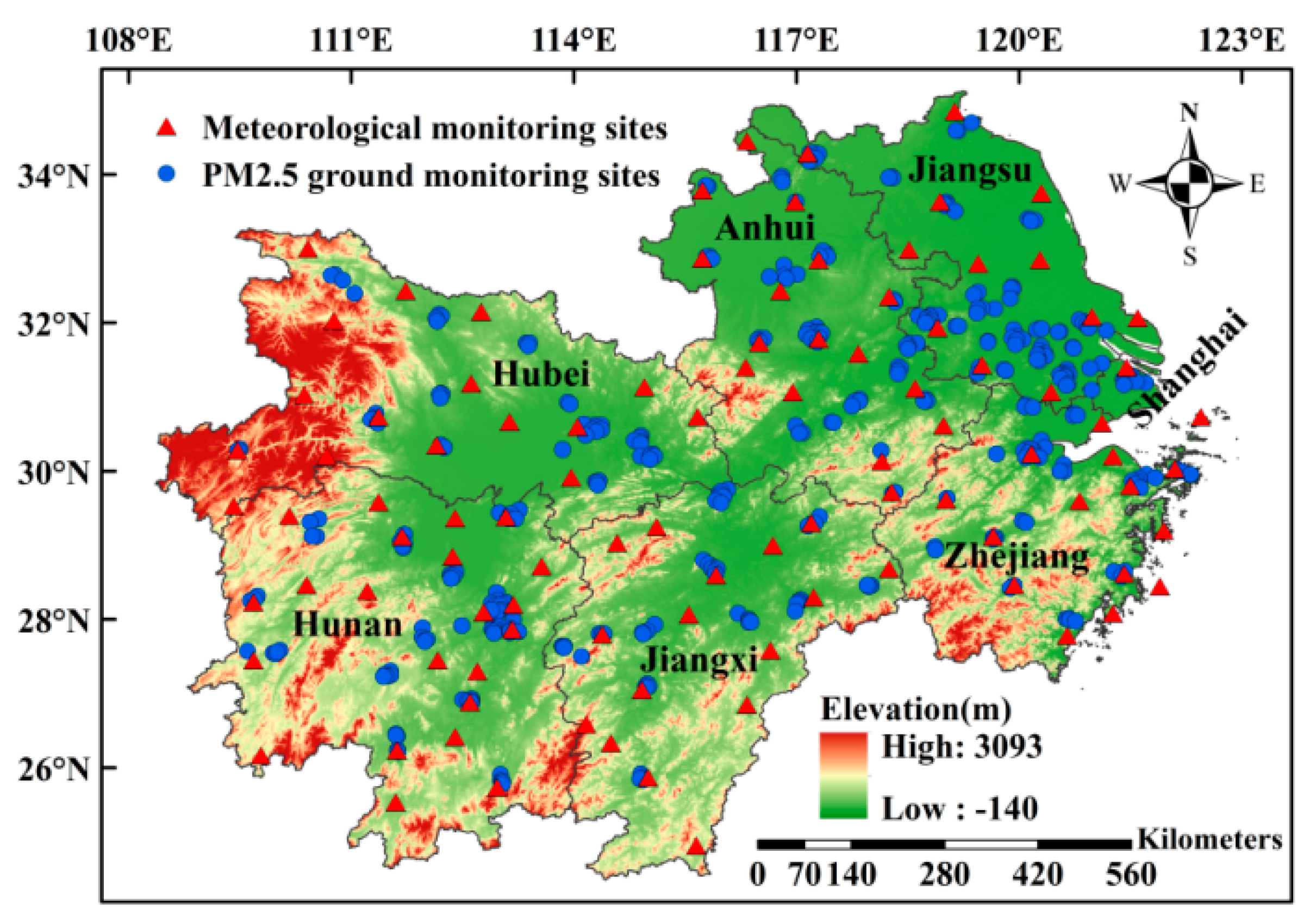
2.1. Study Area and Data Preprocessing
2.2. Methods
2.2.1. GWR Model
2.2.2. PCA-GWR Model
- Step 1: The data of the independent variables of the GWR model were standardized, then the Kaiser-Mayer-Olkin (KMO) test and Bartlett’s test of sphericity were performed on the data. If the KMO value was greater than 0.5 and the p-value of Bartlett’s test of sphericity was less than 0.05, there was a strong correlation between the independent variables, and PCA can be performed; otherwise, the data are not suitable for PCA [50].
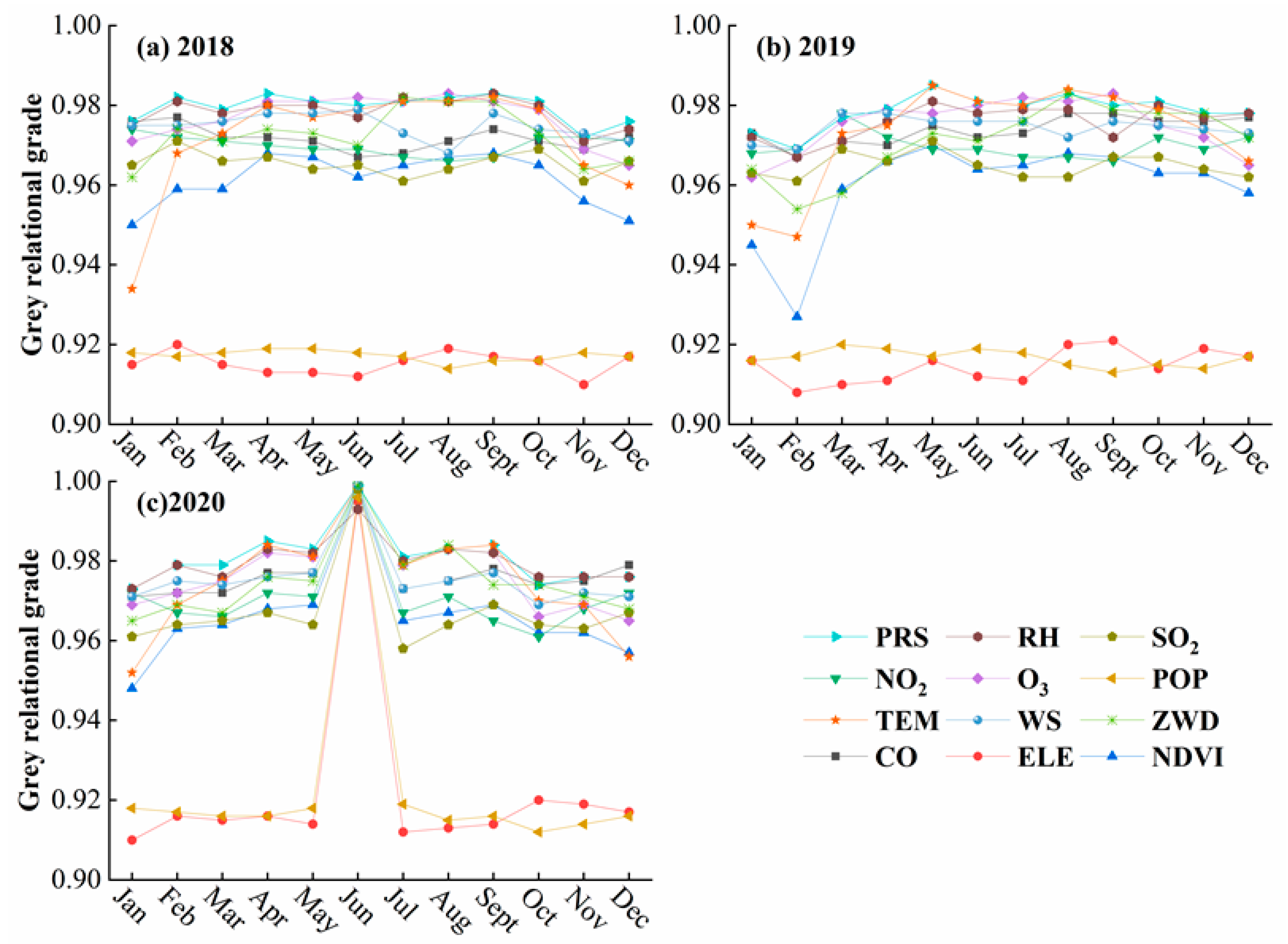
- Step 2: The correlation between PM2.5 and the independent variable data was analyzed using the gray relation analysis (GRA) [51] integrated tool in SPSSPRO to obtain the gray correlation value, and the closer the gray relational grade was to 1, the higher the correlation between the variable and PM2.5.
- Step 3: The variables with high correlation (gray relational grade >0.9) were selected as input variables for PCA, and all principal components were calculated using the PCA integration tool in SPSSPRO.
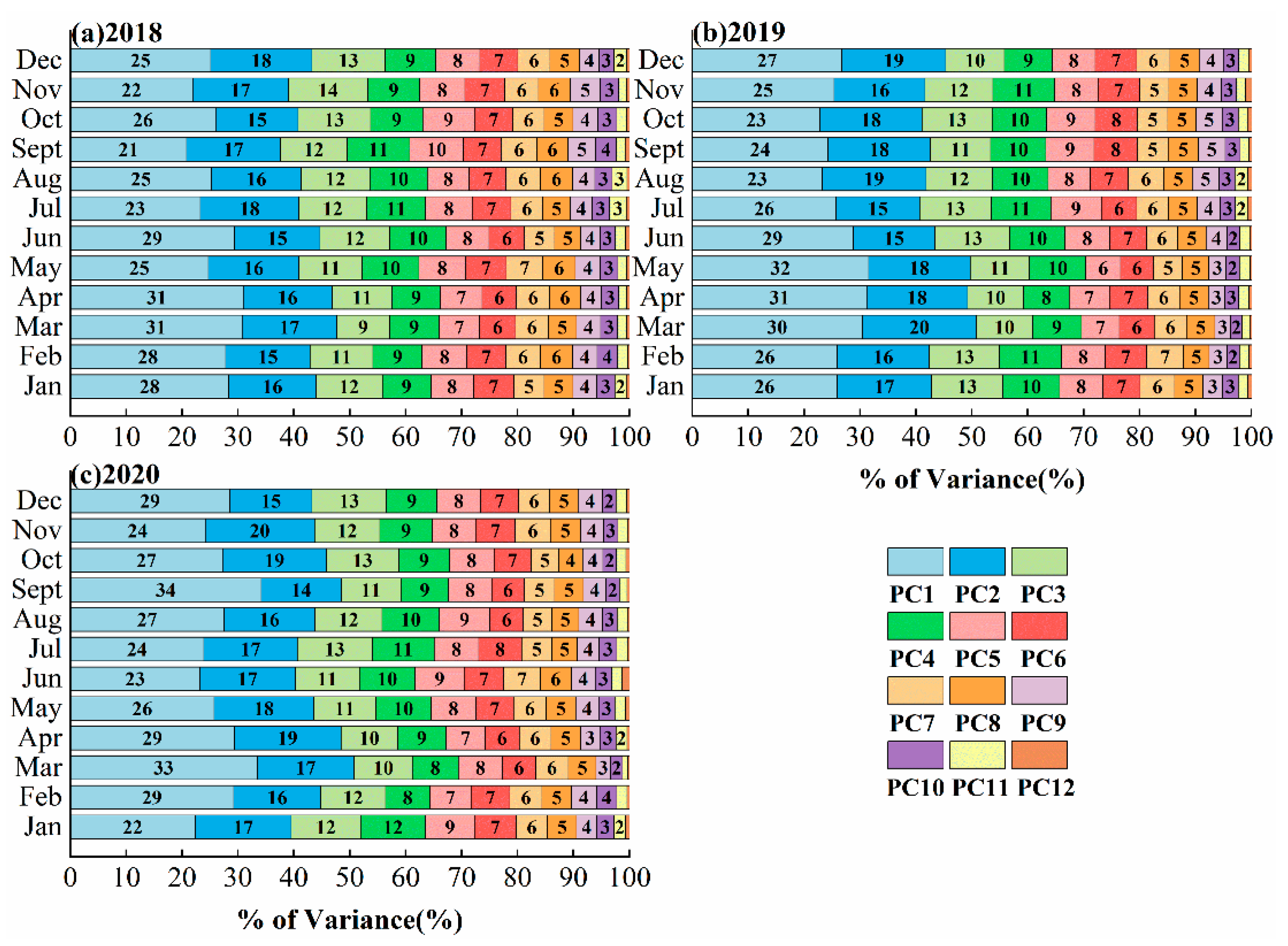
- Step 4: All the principal components were ranked and cumulatively summed according to the percentage of variance, and those with a cumulative percentage of variance greater than or close to 90% were selected as the final input variables of the GWR model. The PCA-GWR model was then constructed to obtain the estimation results of the target variables.
2.2.3. RBF Interpolation
2.2.4. Combined Model with Residual Correction Based on the RBF Interpolation
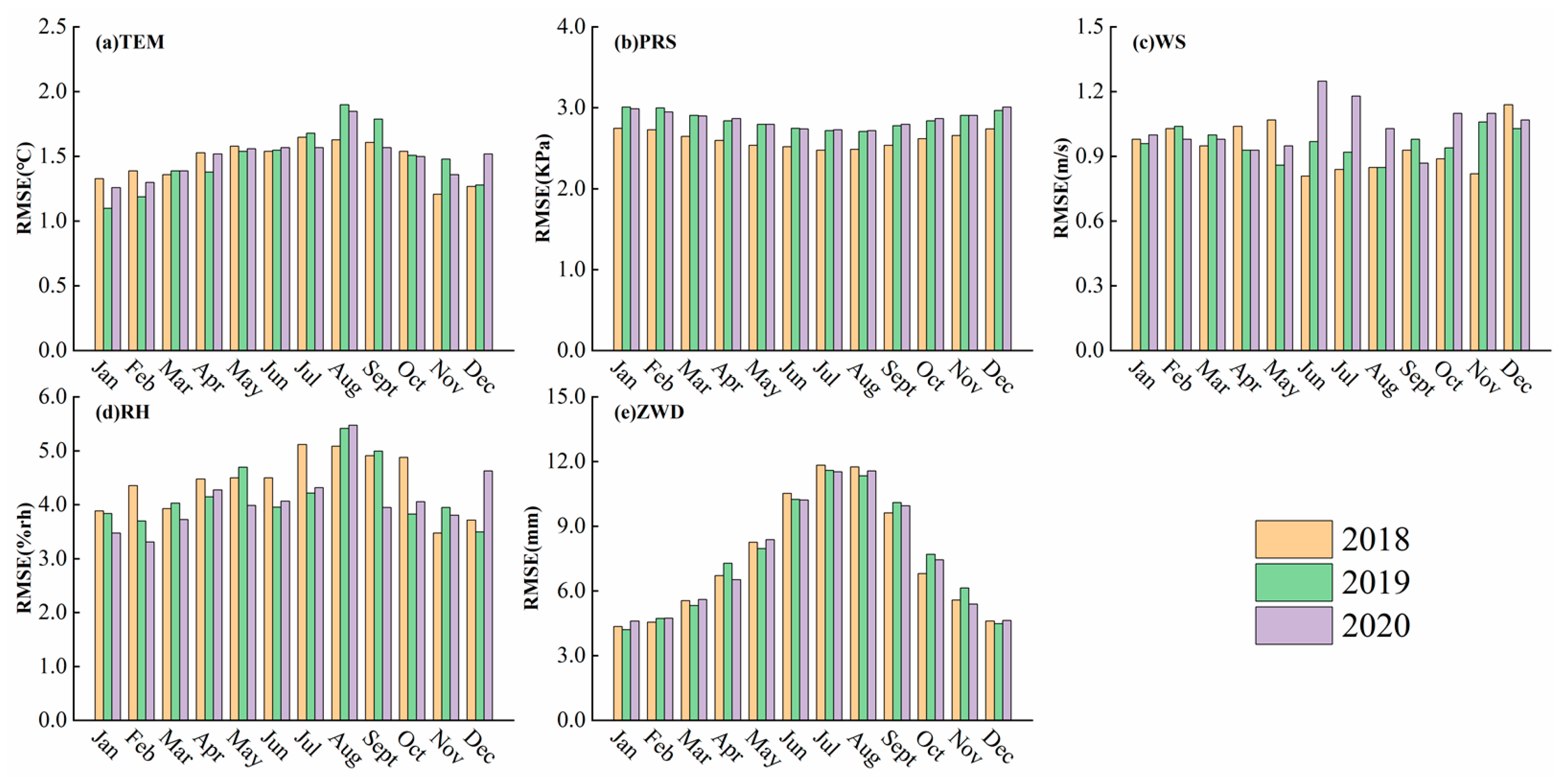
2.2.5. Evaluation Indicators
3. Results
3.1. Analysis of PM2.5 and Its Related Explanatory Variables
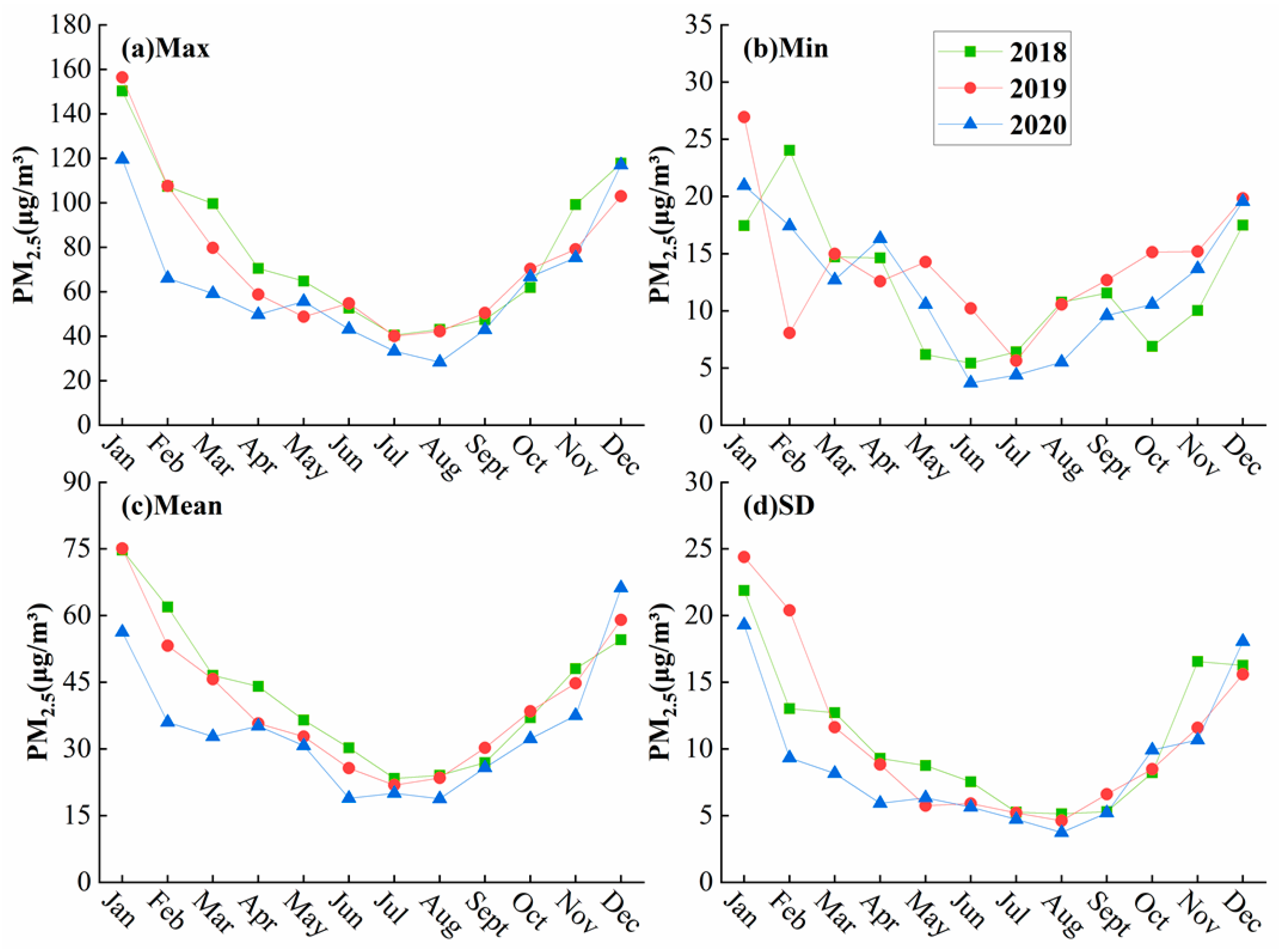
3.1.1. PM2.5 Descriptive Statistics
3.1.2. GRA
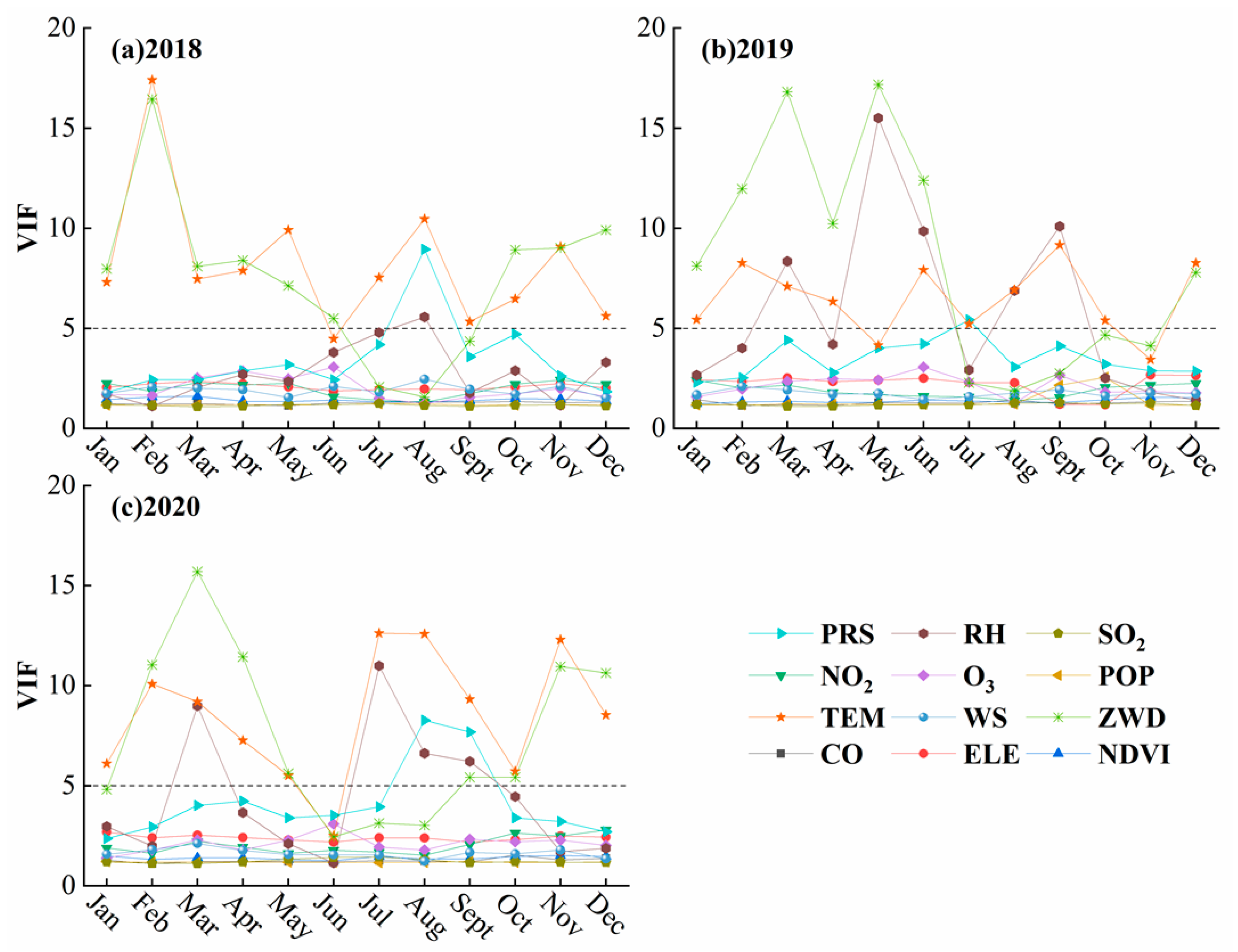
3.1.3. Multicollinearity Diagnosis
3.1.4. PCA
3.2. Model Regression
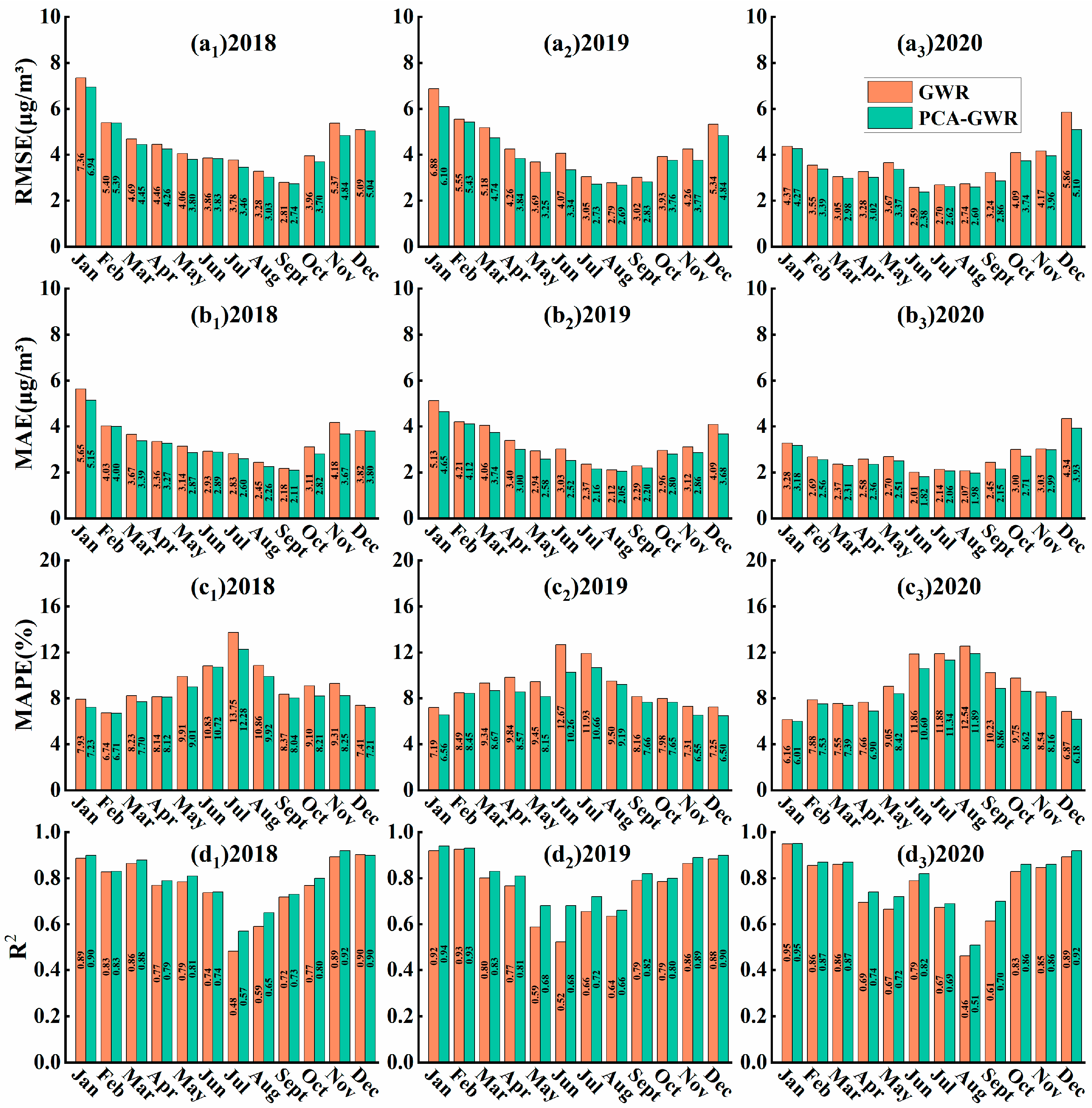
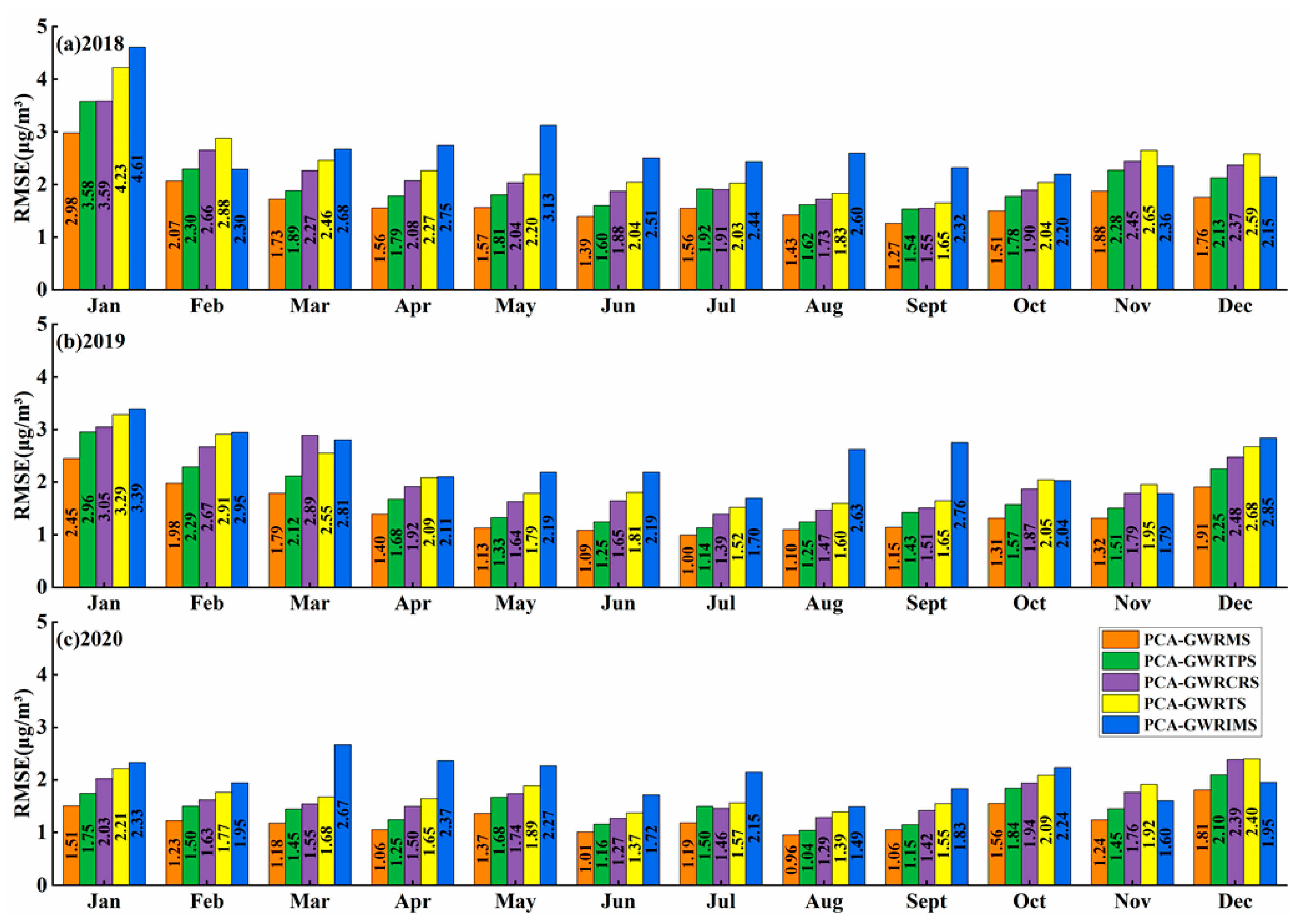
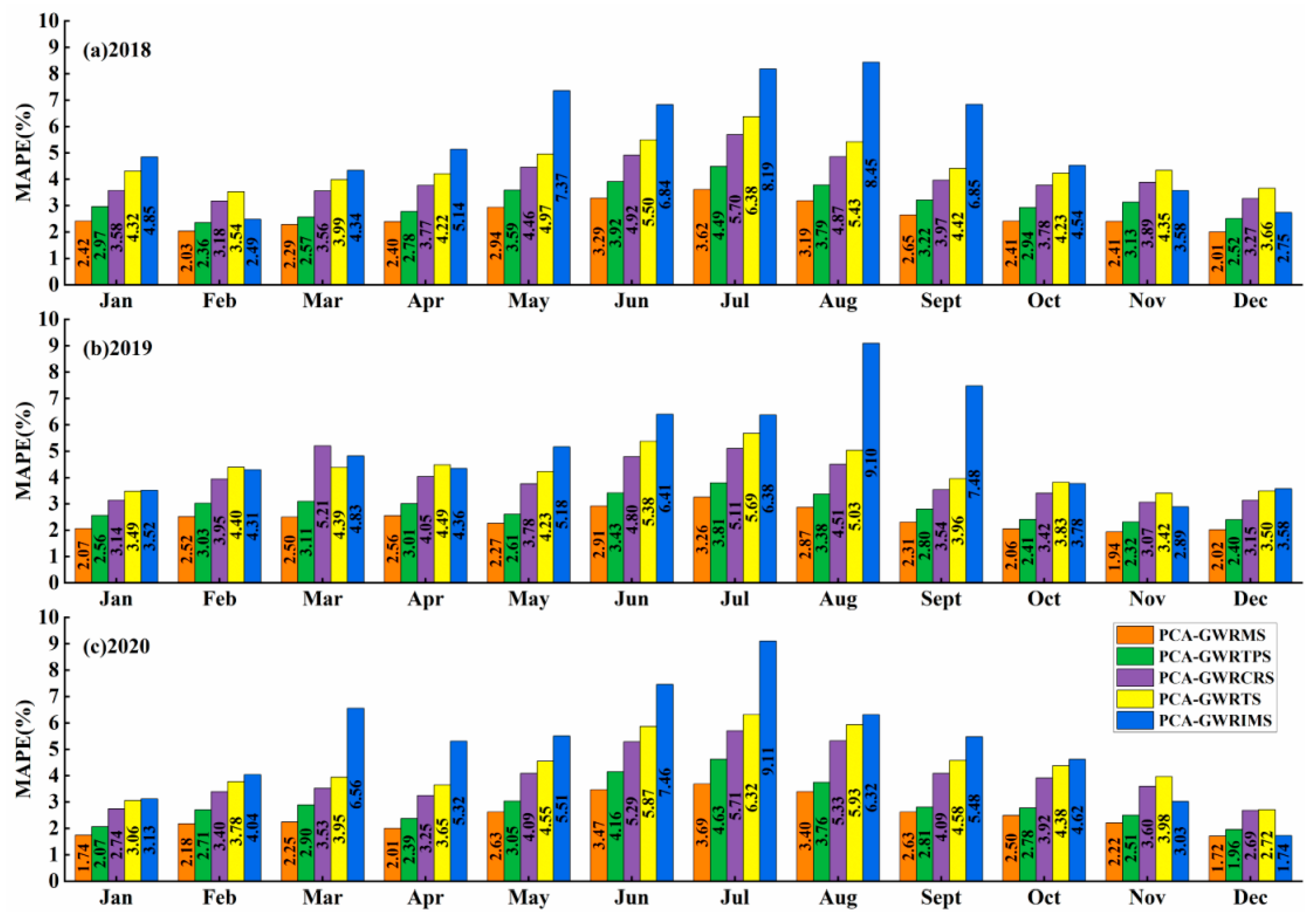
3.2.1. Comparison of Model Accuracy
3.2.2. Regional Distribution of Model Residuals
3.2.3. Residual Correction of PCA-GWR Model
3.3. Generation of the Spatial Distribution Map of the PM2.5 Concentration
- Step 1: Based on the PM2.5 concentration of 390 ground monitoring stations, we use ArcGIS 4.0 to encrypt the PM2.5 monitoring stations and obtain 0.5° × 0.5° grid points.
- Step 2: The inverse distance weighting (IDW) method is used to interpolate the atmospheric pollutants (CO, NO2, O3, SO2), meteorological data (TEM, PRS, WS, RH), and ZWD data to obtain the raster of the corresponding data, and then ArcGIS 4.0 is used to extract the values of the NDVI raster, ELE raster, and POP raster to the 0.5° × 0.5° grid points and 390 PM2.5 ground monitoring stations.
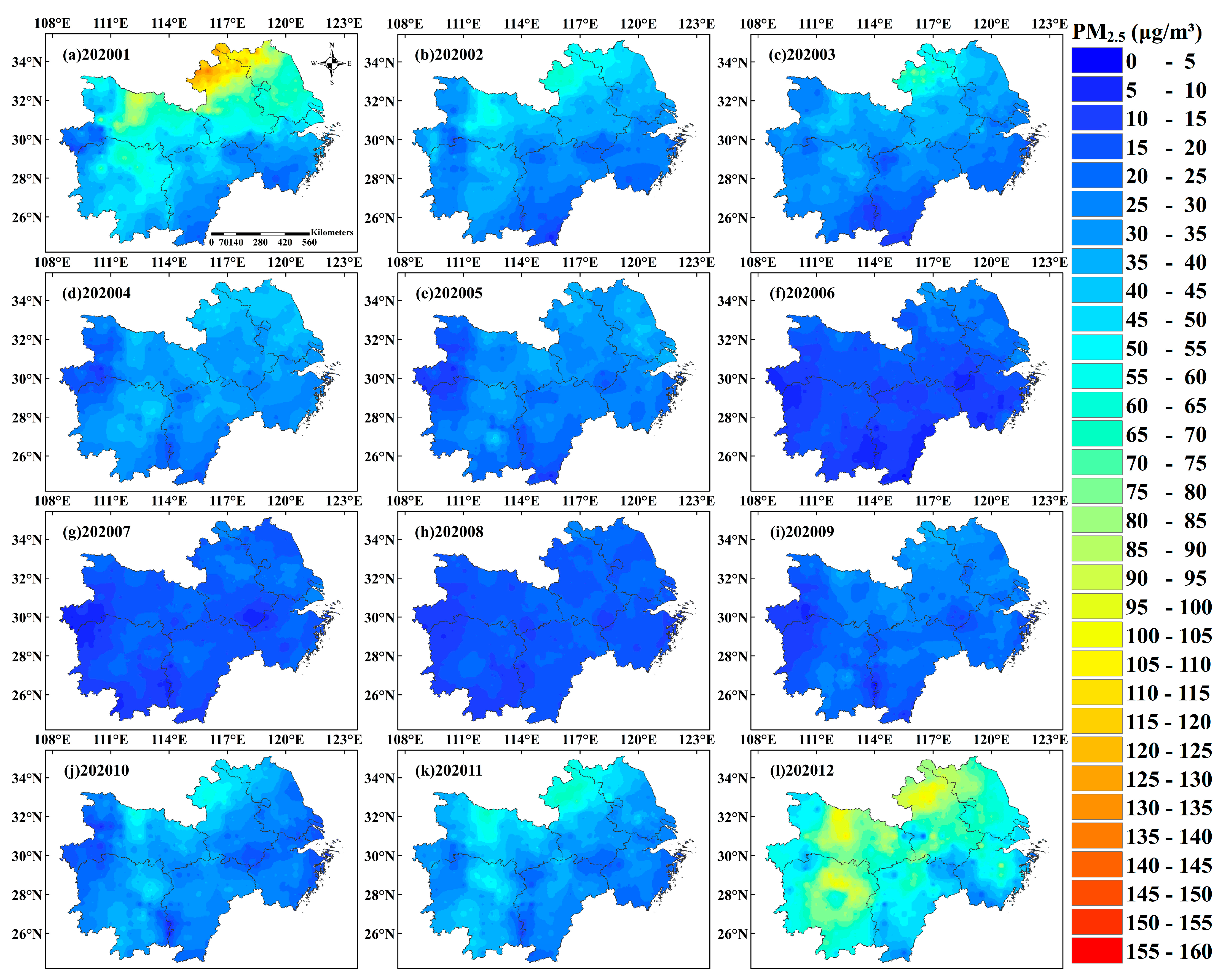
- Step 3: We construct the PCA-GWRMS model using data from 390 monitoring stations to obtain PM2.5 estimates for 0.5° × 0.5° grid points, then visualize the predicted values for 0.5° × 0.5° grid points and the actual PM2.5 values from 390 ground monitoring stations using the inverse distance weighting (IDW) [31] interpolation method to generate a PM2.5 concentration spatial distribution map from January to December 2018–2020 (Figure 11, Figure 12 and Figure 13).
4. Discussion
5. Conclusions
- PM2.5 concentrations show a ‘U’-shaped distribution and seasonal distribution on the monthly scale, mainly reflecting higher PM2.5 concentrations in January, February, and December (winter) and lower PM2.5 concentrations in June, July, and August (summer). On the spatial scale, PM2.5 concentrations are mainly high in the north and low in the south, and the high concentration areas are mainly located in the northern part of western Jiangsu Province, northern Anhui Province, central Hubei Province, and northeastern Hunan Province, while the PM2.5 concentrations in Jiangxi Province and southern Zhejiang Province are relatively low for the whole study area.
- To extract the best independent variables of the GWR model, the principal component analysis method has advantages over the traditional exploratory regression rejection method, and the PCA method can better balance the problems of multicollinearity among the explanatory variables of PM2.5 and the adequacy of the contribution of potential explanatory variables to the distribution of PM2.5 as well as the problem of data loss. The RMSE, MAE, MAPE, and R2 of the PCA-GWR model are all improved compared with those of the GWR model, which can better achieve the spatial estimation of PM2.5.
- All five residual correction combination models (PCA-GWRMS, PCA-GWRTPS, PCA-GWRCRS, PCA-GWRTS, and PCA-GWRIMS) outperform the PCA-GWR model in the spatial estimation of PM2.5 concentrations in the middle and lower reaches of the Yangtze River region of China for 2018–2020, indicating that the residual correction of the PCA-GWR model using radial basis function interpolation can effectively improve the model performance and better achieve the spatial estimation and mapping of PM2.5 concentrations in the study area. In addition, the PCA-GWRMS model shows stronger advantages than other combined models in terms of applicability and model performance for the spatial estimation of PM2.5 in the study area.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Miller, L.; Xu, X. Ambient PM2.5 human health effects—Findings in China and research directions. Atmosphere 2018, 9, 424. [Google Scholar] [CrossRef] [Green Version]
- Fang, K.; Wang, T.; Xu, A. The distribution and drivers of PM2.5 in a rapidly urbanizing region: The belt and road initiative in focus. Sci. Total Environ. 2020, 716, 137010. [Google Scholar] [CrossRef] [PubMed]
- Sun, X.; Zhang, R.; Wang, G. Spatial-temporal evolution of health impact and economic loss upon exposure to PM2.5 in China. Int. J. Environ. Res. Public Health 2022, 19, 1922. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.; Shang, Q.; Wan, C.; Song, P.; Ma, C.; Cao, L. Characteristics and sources of heavy metals in PM2.5 during a typical haze episode in rural and urban areas in Taiyuan, China. Atmosphere 2018, 9, 2. [Google Scholar] [CrossRef] [Green Version]
- Yu, G.; Wang, F.; Hu, J.; Liao, Y.; Liu, X. Value assessment of health losses caused by PM2.5 in Changsha City, China. Int. J. Environ. Res. Public Health 2019, 16, 2063. [Google Scholar] [CrossRef] [Green Version]
- Han, M.; Yang, F.; Sun, H. A bibliometric and visualized analysis of research progress and frontiers on health effects caused by PM2.5. Environ. Sci. Pollut. Res. 2021, 28, 30595–30612. [Google Scholar] [CrossRef]
- Ye, Z.; Li, X.; Han, Y.; Wu, Y.; Fang, Y. Association of long-term exposure to PM2.5 with hypertension and diabetes among the middle-aged and elderly people in Chinese mainland: A spatial study. BMC Public Health 2022, 22, 569. [Google Scholar] [CrossRef]
- Hao, Y.; Liu, Y.-M. The influential factors of urban PM2.5 concentrations in China: A spatial econometric analysis. J. Clean. Prod. 2016, 112, 1443–1453. [Google Scholar] [CrossRef]
- Fang, C.; Wang, Z.; Xu, G. Spatial-temporal characteristics of PM2.5 in China: A city-level perspective analysis. J. Geogr. Sci. 2016, 26, 1519–1532. [Google Scholar] [CrossRef]
- Huang, C.; Liu, K.; Zhou, L. Spatio-temporal trends and influencing factors of PM2.5 concentrations in urban agglomerations in China between 2000 and 2016. Environ. Sci. Pollut. Res. 2021, 28, 10988–11000. [Google Scholar] [CrossRef]
- Sun, X.; Luo, X.-S.; Xu, J.; Zhao, Z.; Chen, Y.; Wu, L.; Chen, Q.; Zhang, D. Spatio-temporal variations and factors of a provincial PM2.5 pollution in eastern China during 2013–2017 by Geostatistics. Sci. Rep. 2019, 9, 3613. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shukla, K.; Kumar, P.; Mann, G.S.; Khare, M. Mapping spatial distribution of particulate matter using kriging and inverse distance weighting at supersites of megacity Delhi. Sustain. Cities Soc. 2020, 54, 101997. [Google Scholar] [CrossRef]
- Choi, K.; Chong, K. Modified inverse distance weighting interpolation for particulate matter estimation and mapping. Atmosphere 2022, 13, 846. [Google Scholar] [CrossRef]
- Li, B.; Liu, Y.; Wang, X.; Fu, Q.; Lv, X. Application of the orthogonal polynomial fitting method in estimating PM2.5 concentrations in central and southern regions of China. Int. J. Environ. Res. Public Health 2019, 16, 1418. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.-J.; Xia, S.-Y.; Yang, Y.; Wu, J.; Zhou, Y.-N.; Ren, Y.-W. Spatiotemporal dynamics and impacts of socioeconomic and natural conditions on PM2.5 in the Yangtze River economic belt. Environ. Pollut. 2020, 263, 114569. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Z.; Zhang, W. Exploring spatiotemporal patterns of PM2.5 in China based on ground-level observations for 190 cities. Environ. Pollut. 2016, 216, 559–567. [Google Scholar] [CrossRef]
- Wei, P.; Xie, S.; Huang, L.; Liu, L. Ingestion of GNSS-derived ZTD and PWV for spatial interpolation of PM2.5 concentration in central and southern China. Int. J. Environ. Res. Public Health 2021, 18, 7931. [Google Scholar] [CrossRef]
- Ahmad, M.; Alam, K.; Tariq, S.; Anwar, S.; Nasir, J.; Mansha, M. Estimating fine particulate concentration using a combined approach of linear regression and artificial neural network. Atmos. Environ. 2019, 219, 117050. [Google Scholar] [CrossRef]
- Gogikar, P.; Tripathy, M.R.; Rajagopal, M.; Paul, K.K.; Tyagi, B. PM2.5 estimation using multiple linear regression approach over industrial and non-industrial stations of India. J. Ambient Intell. Hum. Comput. 2021, 12, 2975–2991. [Google Scholar] [CrossRef]
- Zou, B.; Luo, Y.; Wan, N.; Zheng, Z.; Sternberg, T.; Liao, Y. Performance comparison of LUR and OK in PM2.5 concentration mapping: A multidimensional perspective. Sci. Rep. 2015, 5, 8698. [Google Scholar] [CrossRef]
- Chen, L.; Gao, S.; Zhang, H.; Sun, Y.; Ma, Z.; Vedal, S.; Mao, J.; Bai, Z. Spatiotemporal modeling of PM2.5 concentrations at the national scale combining land use regression and bayesian maximum entropy in China. Environ. Int. 2018, 116, 300–307. [Google Scholar] [CrossRef] [PubMed]
- Wen, H.; Dang, Y.; Li, L. Short-term PM2.5 concentration prediction by combining GNSS and meteorological factors. IEEE Access 2020, 8, 115202–115216. [Google Scholar] [CrossRef]
- Guo, M.; Zhang, H.; Xia, P. A method for predicting short-time changes in fine particulate matter (PM2.5) mass concentration based on the global navigation satellite system zenith tropospheric delay. Meteorol. Appl. 2020, 27, e1866. [Google Scholar] [CrossRef] [Green Version]
- Huang, L.; Wang, X.; Xiong, S.; Li, J.; Liu, L.; Mo, Z.; Fu, B.; He, H. High-precision GNSS PWV retrieval using dense GNSS sites and in-situ meteorological observations for the evaluation of MERRA-2 and ERA5 reanalysis products over China. Atmos. Res. 2022, 276, 106247. [Google Scholar] [CrossRef]
- Huang, L.; Mo, Z.; Xie, S.; Liu, L.; Chen, J.; Kang, C.; Wang, S. Spatiotemporal characteristics of GNSS-derived precipitable water vapor during heavy rainfall events in Guilin, China. Satell. Navig. 2021, 2, 13. [Google Scholar] [CrossRef]
- Xu, W.; Wang, Y.; Sun, S.; Yao, L.; Li, T.; Fu, X. Spatiotemporal heterogeneity of PM2.5 and its driving difference comparison associated with urbanization in China’s multiple urban agglomerations. Environ. Sci. Pollut. Res. 2022, 29, 29689–29703. [Google Scholar] [CrossRef]
- Xia, S.; Liu, X.; Liu, Q.; Zhou, Y.; Yang, Y. Heterogeneity and the determinants of PM2.5 in the Yangtze River economic belt. Sci. Rep. 2022, 12, 4189. [Google Scholar] [CrossRef]
- Zou, Q.; Shi, J. The heterogeneous effect of socioeconomic driving factors on PM2.5 in China’s 30 province-level administrative regions: Evidence from Bayesian hierarchical spatial quantile regression. Environ. Pollut. 2020, 264, 114690. [Google Scholar] [CrossRef]
- Brunsdon, C.; Fotheringham, A.S.; Charlton, M.E. Geographically weighted regression: A method for exploring spatial nonstationarity. Geogr. Anal. 2010, 28, 281–298. [Google Scholar] [CrossRef]
- Zou, B.; Fang, X.; Feng, H.; Zhou, X. Simplicity versus accuracy for estimation of the PM2.5 concentration: A comparison between LUR and GWR methods across time scales. J. Spat. Sci. 2021, 66, 279–297. [Google Scholar] [CrossRef]
- Gu, K.; Zhou, Y.; Sun, H.; Dong, F.; Zhao, L. Spatial distribution and determinants of PM2.5 in China’s cities: Fresh evidence from IDW and GWR. Environ. Monit. Assess. 2021, 193, 15. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Gong, W.; Wang, W.; Ji, Y.; Zhu, Z.; Huang, Y. Ground level PM2.5 estimates over China using satellite-based geographically weighted regression (GWR) models are improved by including NO2 and enhanced vegetation index (EVI). Int. J. Environ. Res. Public Health 2016, 13, 1215. [Google Scholar] [CrossRef] [PubMed]
- Xiao, L.; Lang, Y.; Christakos, G. High-resolution spatiotemporal mapping of PM2.5 concentrations at mainland China using a combined BME-GWR technique. Atmos. Environ. 2018, 173, 295–305. [Google Scholar] [CrossRef]
- Wei, P.; Xie, S.; Huang, L.; Liu, L.; Tang, Y.; Zhang, Y.; Wu, H.; Xue, Z.; Ren, D. Spatial interpolation of PM2.5 concentrations during holidays in south-central China considering multiple factors. Atmos. Pollut. Res. 2022, 13, 101480. [Google Scholar] [CrossRef]
- Tan, H.; Chen, Y.; Wilson, J.P.; Zhou, A.; Chu, T. Self-adaptive bandwidth eigenvector spatial filtering model for estimating PM2.5 concentrations in the Yangtze River delta region of China. Environ. Sci. Pollut. Res. 2021, 28, 67800–67813. [Google Scholar] [CrossRef]
- Wu, Y.; Lin, S.; Shi, K.; Ye, Z.; Fang, Y. Seasonal prediction of daily PM2.5 concentrations with interpretable machine learning: A case study of Beijing, China. Environ. Sci. Pollut. Res. 2022, 29, 45821–45836. [Google Scholar] [CrossRef]
- Li, S.; Zhai, L.; Zou, B.; Sang, H.; Fang, X. A generalized additive model combining principal component analysis for PM2.5 concentration estimation. ISPRS Int. J. Geo-Inf. 2017, 6, 248. [Google Scholar] [CrossRef] [Green Version]
- Sun, W.; Sun, J. Daily PM2.5 concentration prediction based on principal component analysis and LSSVM optimized by cuckoo search algorithm. J. Environ. Manag. 2017, 188, 144–152. [Google Scholar] [CrossRef]
- Olvera, H.A.; Garcia, M.; Li, W.-W.; Yang, H.; Amaya, M.A.; Myers, O.; Burchiel, S.W.; Berwick, M.; Pingitore, N.E. Principal component analysis optimization of a PM2.5 land use regression model with small monitoring network. Sci. Total Environ. 2012, 425, 27–34. [Google Scholar] [CrossRef] [Green Version]
- Guo, L.; Luo, M.; Zhangyang, C.; Zeng, C.; Wang, S.; Zhang, H. Spatial modelling of soil organic carbon stocks with combined principal component analysis and geographically weighted regression. J. Agric. Sci. 2018, 156, 774–784. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, X.; Chow, T.E. Space-time cluster’s detection and geographical weighted regression analysis of COVID-19 mortality on Texas counties. Int. J. Environ. Res. Public Health 2021, 18, 5541. [Google Scholar] [CrossRef] [PubMed]
- Zhai, L.; Li, S.; Zou, B.; Sang, H.; Fang, X.; Xu, S. An improved geographically weighted regression model for PM2.5 concentration estimation in large areas. Atmos. Environ. 2018, 181, 145–154. [Google Scholar] [CrossRef]
- Huang, L.; Zhu, G.; Peng, H.; Chen, H.; Liu, L.; Jiang, W. A global grid model for the vertical correction of zenith wet delay based on the sliding window algorithm. Acta Geodaet. Cartogr. Sin. 2021, 50, 685. [Google Scholar] [CrossRef]
- Yang, F.; Guo, J.; Meng, X.; Li, J.; Zou, J.; Xu, Y. Establishment and assessment of a zenith wet delay (ZWD) augmentation model. GPS Solut. 2021, 25, 148. [Google Scholar] [CrossRef]
- Zhang, B.; Hou, P.; Zha, J.; Liu, T. Integer-estimable FDMA model as an enabler of GLONASS PPP-RTK. J. Geod. 2021, 95, 91. [Google Scholar] [CrossRef]
- Huang, L.; Zhu, G.; Liu, L.; Chen, H.; Jiang, W. A global grid model for the correction of the vertical zenith total delay based on a sliding window algorithm. GPS Solut. 2021, 25, 98. [Google Scholar] [CrossRef]
- Zhang, B.; Chen, Y.; Yuan, Y. PPP-RTK based on undifferenced and uncombined observations: Theoretical and practical aspects. J. Geod. 2019, 93, 1011–1024. [Google Scholar] [CrossRef]
- Jin, H.; Chen, X.; Zhong, R.; Liu, M. Influence and prediction of PM2.5 through multiple environmental variables in China. Sci. Total Environ. 2022, 849, 157910. [Google Scholar] [CrossRef]
- Wei, F.; Li, S.; Liang, Z.; Huang, A.; Wang, Z.; Shen, J.; Sun, F.; Wang, Y.; Wang, H.; Li, S. Analysis of spatial heterogeneity and the scale of the impact of changes in PM2.5 concentrations in major Chinese cities between 2005 and 2015. Energies 2021, 14, 3232. [Google Scholar] [CrossRef]
- Eze, N.M.; Asogwa, O.C.; Eze, C.M. Principal component factor analysis of some development factors in Southern Nigeria and its extension to regression analysis. J. Adv. Math. Comput. Sci. 2021, 36, 132–160. [Google Scholar] [CrossRef]
- Azzeh, M.; Neagu, D.; Cowling, P.I. Fuzzy grey relational analysis for software effort estimation. Empir. Softw. Eng. 2010, 15, 60–90. [Google Scholar] [CrossRef] [Green Version]
- Boreggio, M.; Bernard, M.; Gregoretti, C. Evaluating the differences of gridding techniques for digital elevation models generation and their influence on the modeling of stony debris flows routing: A case study from Rovina Di Cancia Basin (North-Eastern Italian Alps). Front. Earth Sci. 2018, 6, 89. [Google Scholar] [CrossRef] [Green Version]
- Powell, M.J.D. Radial basis function methods for interpolation to functions of many variables. Int. J. Comput. Maths Appl. 2002, 3, 23. [Google Scholar]
- Rocha, H. On the selection of the most adequate radial basis function. Appl. Math. Model. 2009, 33, 1573–1583. [Google Scholar] [CrossRef]
- Qiao, P.; Li, P.; Cheng, Y.; Wei, W.; Yang, S.; Lei, M.; Chen, T. Comparison of common spatial interpolation methods for analyzing pollutant spatial distributions at contaminated sites. Environ. Geochem. Health 2019, 41, 2709–2730. [Google Scholar] [CrossRef] [PubMed]
- Bai, L.; Jiang, L.; Yang, D.; Liu, Y. Quantifying the spatial heterogeneity influences of natural and socioeconomic factors and their interactions on air pollution using the geographical detector method: A case study of the Yangtze River economic belt, China. J. Clean. Prod. 2019, 232, 692–704. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R.; El-Haddad, B.A. Advanced machine learning algorithms for flood susceptibility modeling—Performance comparison: Red Sea, Egypt. Environ. Sci. Pollut. Res. 2022, 29, 66768–66792. [Google Scholar] [CrossRef]
- Nazif, A.; Mohammed, N.I.; Malakahmad, A.; Abualqumboz, M.S. Application of step wise regression analysis in predicting future particulate matter concentration episode. Water Air Soil Pollut. 2016, 227, 117. [Google Scholar] [CrossRef]
- Wang, S.; Zhou, C.; Wang, Z.; Feng, K.; Hubacek, K. The characteristics and drivers of fine particulate matter (PM2.5) distribution in China. J. Clean. Prod. 2017, 142, 1800–1809. [Google Scholar] [CrossRef]
- Zeng, Q.; Tao, J.; Chen, L.; Zhu, H.; Zhu, S.; Wang, Y. Estimating ground-level particulate matter in five regions of China using aerosol optical depth. Remote Sens. 2020, 12, 881. [Google Scholar] [CrossRef] [Green Version]
- Ma, S.; Chen, W.; Zhang, S.; Tong, Q.; Bao, Q.; Gao, Z. Characteristics and cause analysis of heavy haze in Changchun City in Northeast China. Chin. Geogr. Sci. 2017, 27, 989–1002. [Google Scholar] [CrossRef]
- Tan, Y.; Wang, H.; Zhu, B.; Zhao, T.; Shi, S.; Liu, A.; Liu, D.; Pan, C.; Cao, L. The interaction between black carbon and planetary boundary layer in the Yangtze River Delta from 2015 to 2020: Why O3 didn’t decline so significantly as PM2.5. Environ. Res. 2022, 214, 114095. [Google Scholar] [CrossRef] [PubMed]
- Su, Z.; Lin, L.; Chen, Y.; Hu, H. Understanding the distribution and drivers of PM2.5 concentrations in the Yangtze River Delta from 2015 to 2020 using random forest regression. Environ. Monit. Assess. 2022, 194, 284. [Google Scholar] [CrossRef] [PubMed]
- Nichol, J.E.; Bilal, M.; Ali, M.A.; Qiu, Z. Air pollution scenario over China during COVID-19. Remote Sens. 2020, 12, 2100. [Google Scholar] [CrossRef]
- Pei, Z.; Han, G.; Ma, X.; Su, H.; Gong, W. Response of major air pollutants to COVID-19 lockdowns in China. Sci. Total Environ. 2020, 743, 140879. [Google Scholar] [CrossRef]
- Chen, Q.; Mei, K.; Dahlgren, R.A.; Wang, T.; Gong, J.; Zhang, M. Impacts of land use and population density on seasonal surface water quality using a modified geographically weighted regression. Sci. Total Environ. 2016, 572, 450–466. [Google Scholar] [CrossRef] [Green Version]
- Fu, L.; Wang, Q.; Li, J.; Jin, H.; Zhen, Z.; Wei, Q. Spatiotemporal heterogeneity and the key influencing factors of PM2.5 and PM10 in Heilongjiang, China from 2014 to 2018. Int. J. Environ. Res. Public Health 2022, 19, 11627. [Google Scholar] [CrossRef]
- Gao, S.; Zhao, H.; Bai, Z.; Han, B.; Xu, J.; Zhao, R.; Zhang, N.; Chen, L.; Lei, X.; Shi, W.; et al. Combined use of principal component analysis and artificial neural network approach to improve estimates of PM2.5 personal exposure: A case study on older adults. Sci. Total Environ. 2020, 726, 138533. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Time Scale | Data Type | Resolution |
|---|---|---|---|
| PM2.5, O3, CO, NO2, SO2 | Jan 2018–Dec 2018 Jan 2019–Dec 2019 Jan 2020–Dec 2020 | 390 PM2.5 ground monitoring sites | / |
| TEM, PRS, WS, RH | 98 meteorological monitoring sites | / | |
| ZWD | Grid | 1° × 1° | |
| NDVI | Grid | 1 km | |
| POP | 2018–2020 | Grid | 1 km |
| ELE | / | Grid | 90 m |
| Date | Moran’s I | Z-Value | p-Value | Date | Moran’s I | Z-Value | p-Value | Date | Moran’s I | Z-Value | p-Value |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Jan, 2018 | 0.091 | 2.859 | 0.004 | Jan, 2019 | 0.177 | 5.365 | 0.001 | Jan, 2020 | 0.148 | 4.420 | 0.001 |
| Feb, 2018 | 0.142 | 4.915 | 0.001 | Feb, 2019 | 0.114 | 3.537 | 0.001 | Feb, 2020 | 0.201 | 6.071 | 0.001 |
| Mar, 2018 | 0.059 | 1.858 | 0.044 | Mar, 2019 | 0.141 | 4.458 | 0.001 | Mar, 2020 | 0.021 | 0.704 | 0.235 |
| Apr, 2018 | 0.114 | 3.381 | 0.002 | Apr, 2019 | 0.107 | 3.145 | 0.002 | Apr, 2020 | 0.041 | 1.297 | 0.114 |
| May, 2018 | 0.014 | 0.446 | 0.316 | May, 2019 | 0.066 | 1.972 | 0.049 | May, 2020 | 0.120 | 3.730 | 0.001 |
| Jun, 2018 | 0.125 | 3.645 | 0.001 | Jun, 2019 | 0.077 | 2.502 | 0.009 | Jun, 2020 | 0.066 | 2.015 | 0.027 |
| Jul, 2018 | 0.135 | 4.638 | 0.001 | Jul, 2019 | 0.088 | 2.720 | 0.007 | Jul, 2020 | 0.036 | 1.304 | 0.098 |
| Aug, 2018 | 0.087 | 3.096 | 0.003 | Aug, 2019 | 0.022 | 0.846 | 0.200 | Aug, 2020 | 0.186 | 5.414 | 0.001 |
| Sept, 2018 | 0.037 | 1.165 | 0.125 | Sept, 2019 | 0.044 | 1.418 | 0.079 | Sept, 2020 | 0.162 | 4.976 | 0.001 |
| Oct, 2018 | 0.083 | 2.449 | 0.014 | Oct, 2019 | 0.099 | 3.032 | 0.003 | Oct, 2020 | 0.148 | 4.327 | 0.002 |
| Nov, 2018 | 0.062 | 1.840 | 0.066 | Nov, 2019 | 0.155 | 4.644 | 0.001 | Nov, 2020 | 0.184 | 6.079 | 0.001 |
| Dec, 2018 | 0.185 | 6.442 | 0.001 | Dec, 2019 | 0.107 | 3.222 | 0.002 | Dec, 2020 | 0.147 | 4.285 | 0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, Y.; Xie, S.; Huang, L.; Liu, L.; Wei, P.; Zhang, Y.; Meng, C. Spatial Estimation of Regional PM2.5 Concentrations with GWR Models Using PCA and RBF Interpolation Optimization. Remote Sens. 2022, 14, 5626. https://doi.org/10.3390/rs14215626
Tang Y, Xie S, Huang L, Liu L, Wei P, Zhang Y, Meng C. Spatial Estimation of Regional PM2.5 Concentrations with GWR Models Using PCA and RBF Interpolation Optimization. Remote Sensing. 2022; 14(21):5626. https://doi.org/10.3390/rs14215626
Chicago/Turabian StyleTang, Youbing, Shaofeng Xie, Liangke Huang, Lilong Liu, Pengzhi Wei, Yabo Zhang, and Chunyang Meng. 2022. "Spatial Estimation of Regional PM2.5 Concentrations with GWR Models Using PCA and RBF Interpolation Optimization" Remote Sensing 14, no. 21: 5626. https://doi.org/10.3390/rs14215626
APA StyleTang, Y., Xie, S., Huang, L., Liu, L., Wei, P., Zhang, Y., & Meng, C. (2022). Spatial Estimation of Regional PM2.5 Concentrations with GWR Models Using PCA and RBF Interpolation Optimization. Remote Sensing, 14(21), 5626. https://doi.org/10.3390/rs14215626