
Improving Methodology for Tropical Cyclone Seasonal Forecasting in the Australian and the South Pacific Ocean Regions by Selecting and Averaging Models via Metropolis–Gibbs Sampling


Abstract
:1. Introduction
- Identify the most important climate indices that greatly influence TC seasonal activity.
- Improve the forecast utility using the approach of model averaging from the best models selected in (i).
2. Data
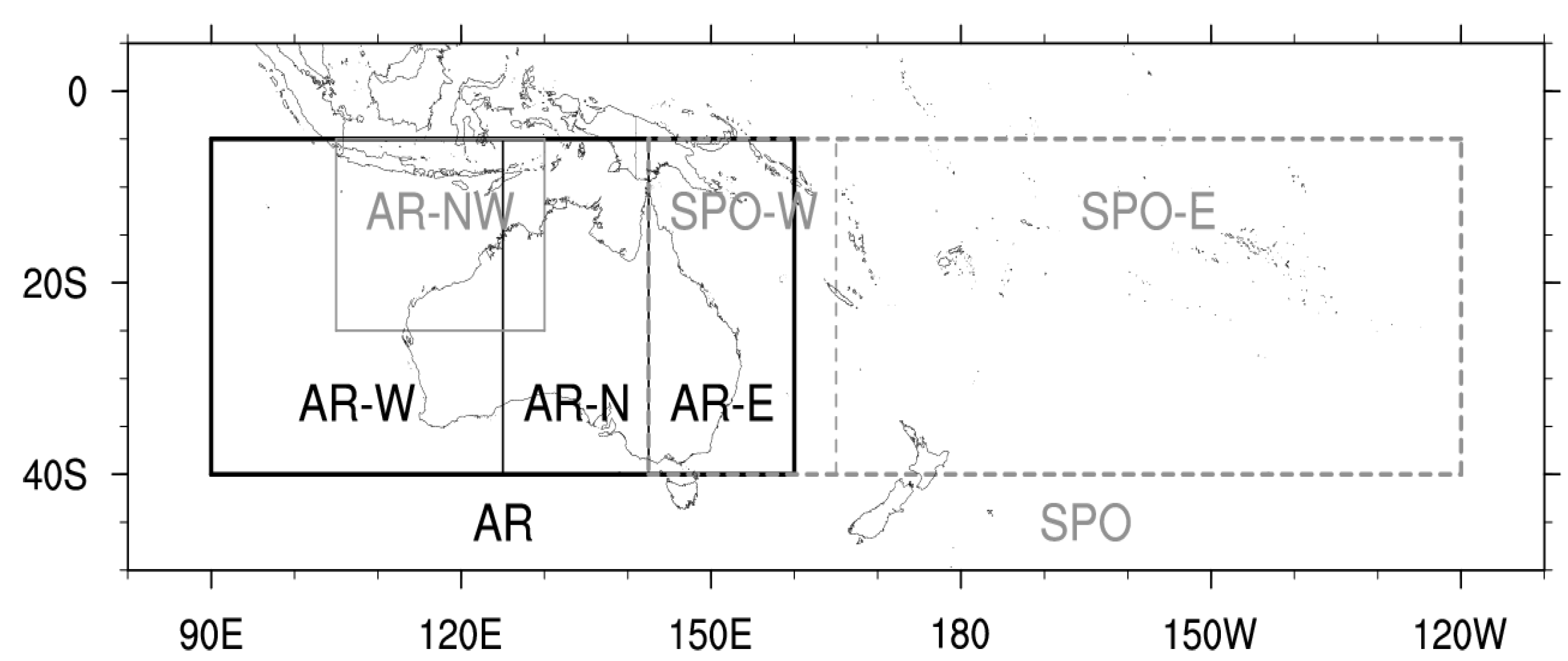
2.1. Study Area and TC Data
2.2. Model Covariates
3. Methods
3.1. Poisson Regression Model
3.2. Model Selection and Averaging
| Algorithm 1: Metropolis–Gibbs sampling with random scan (MGRS) |
|
3.3. Model Evaluation
4. Results
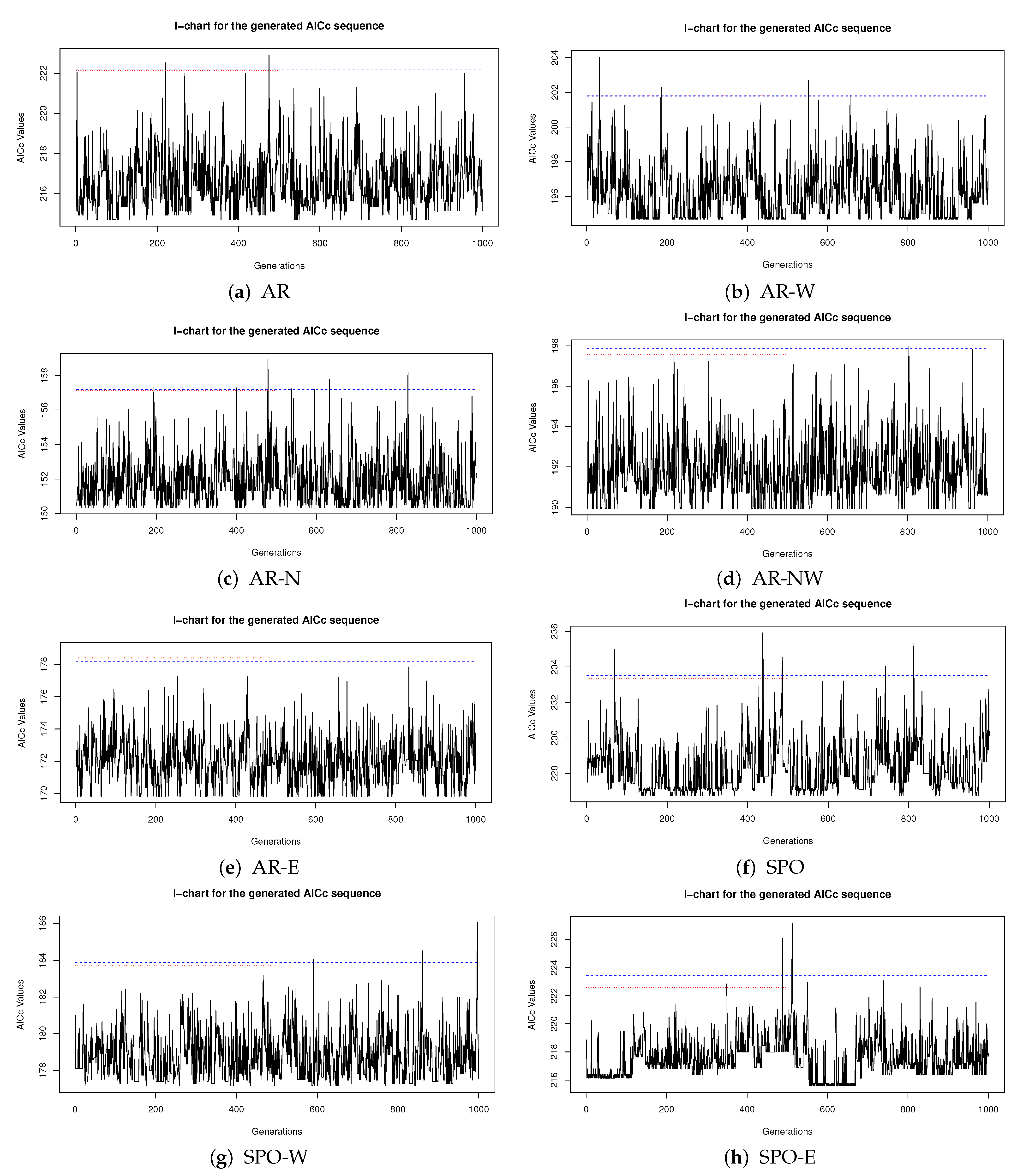
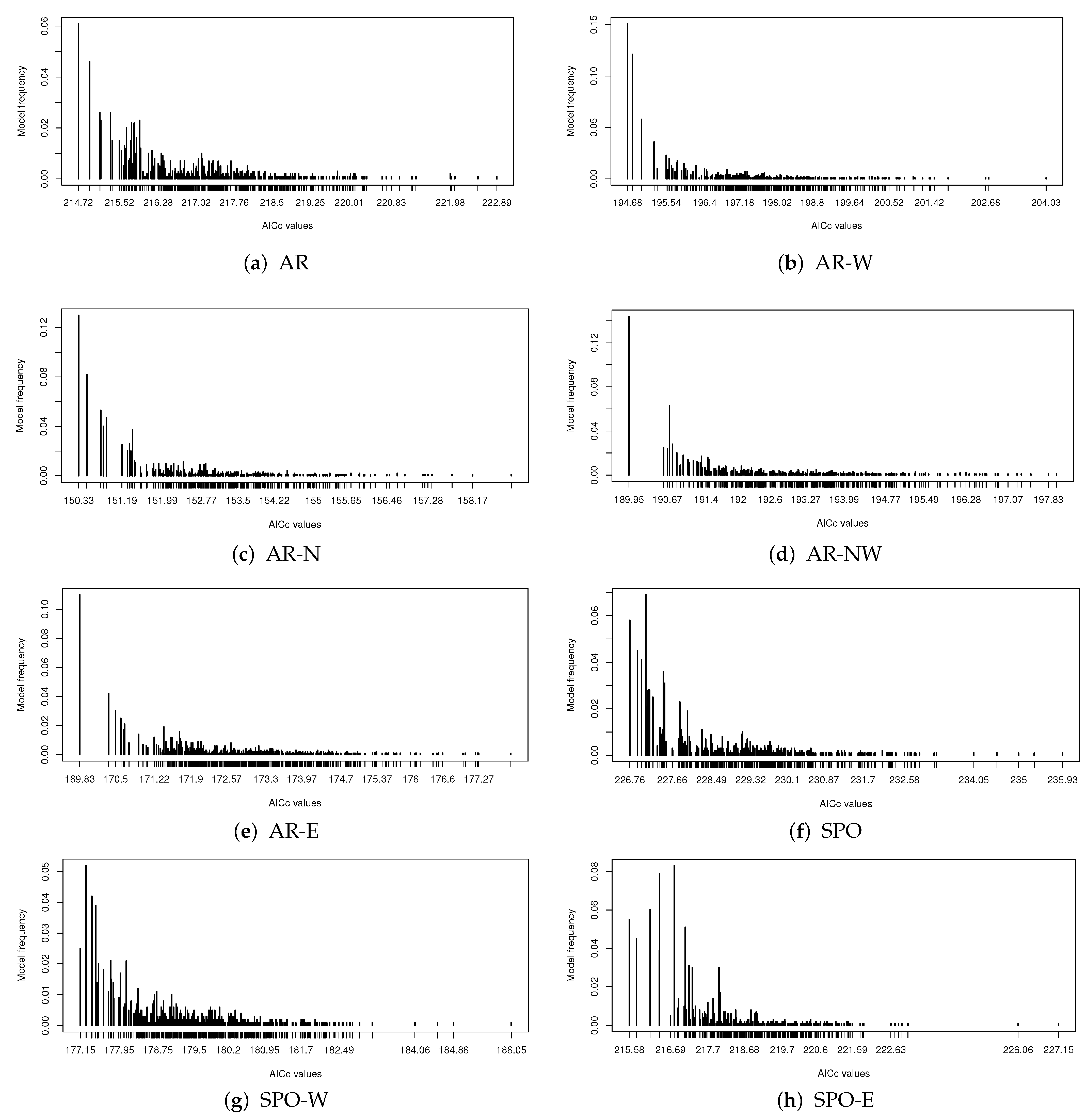
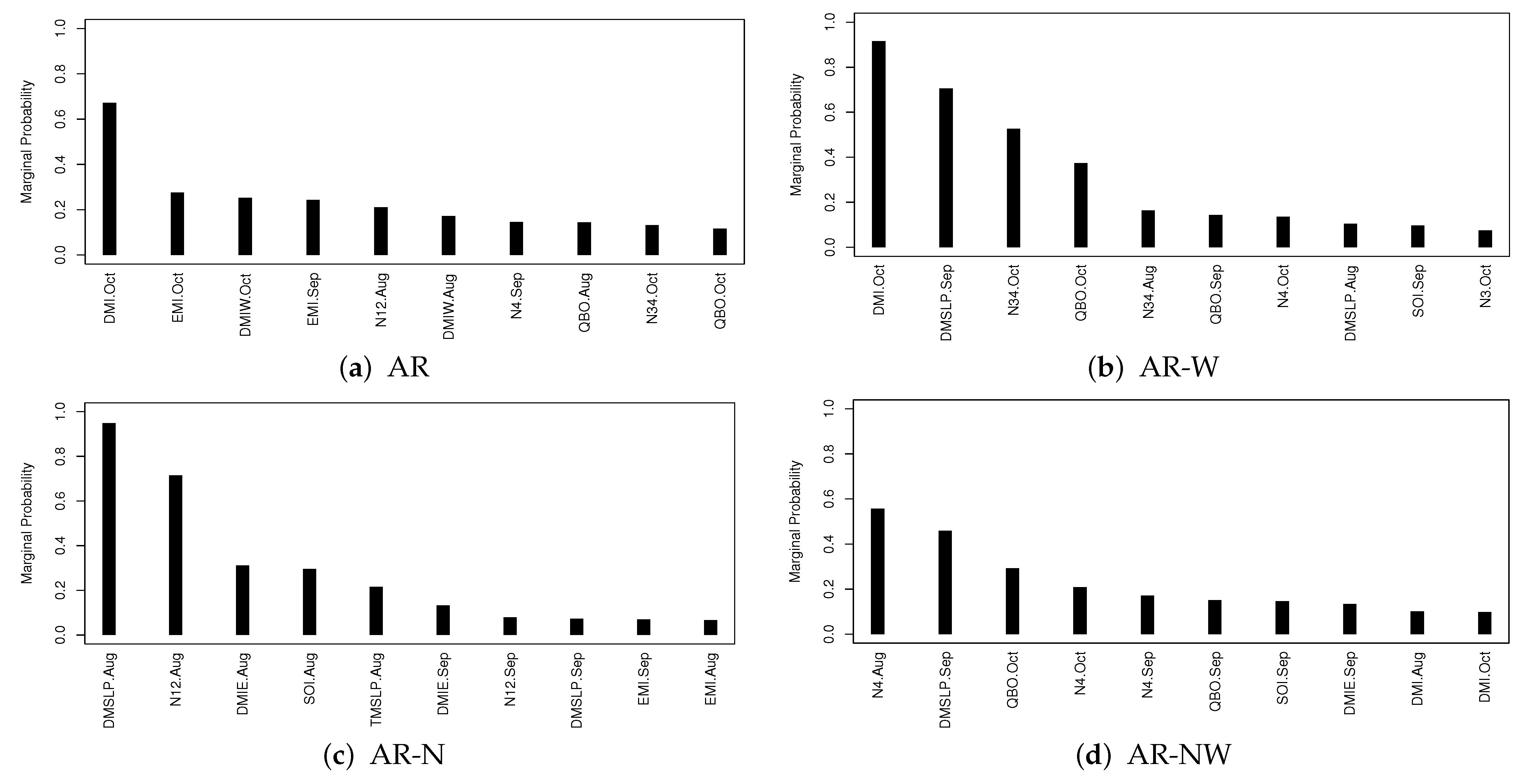
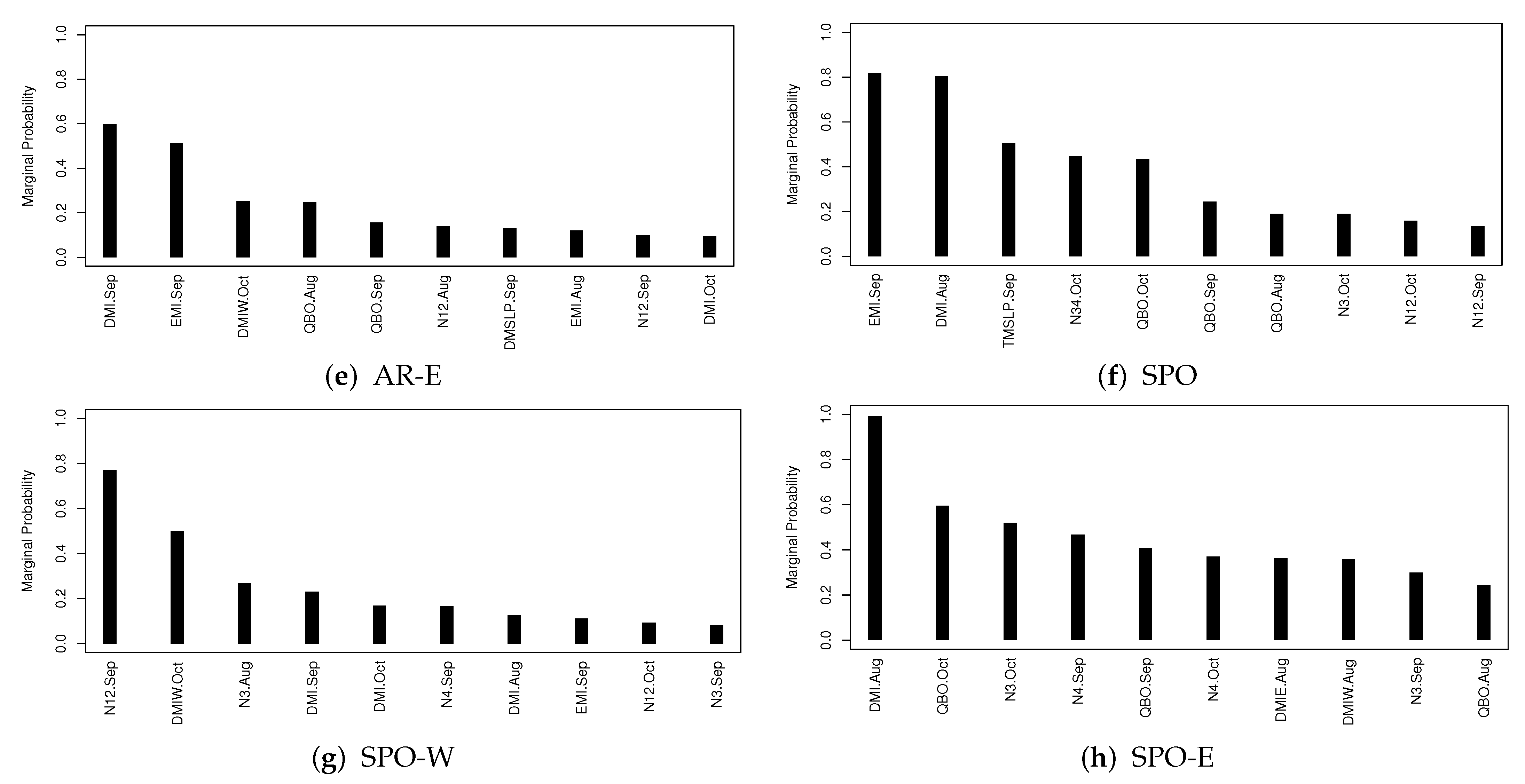
4.1. Model Selection
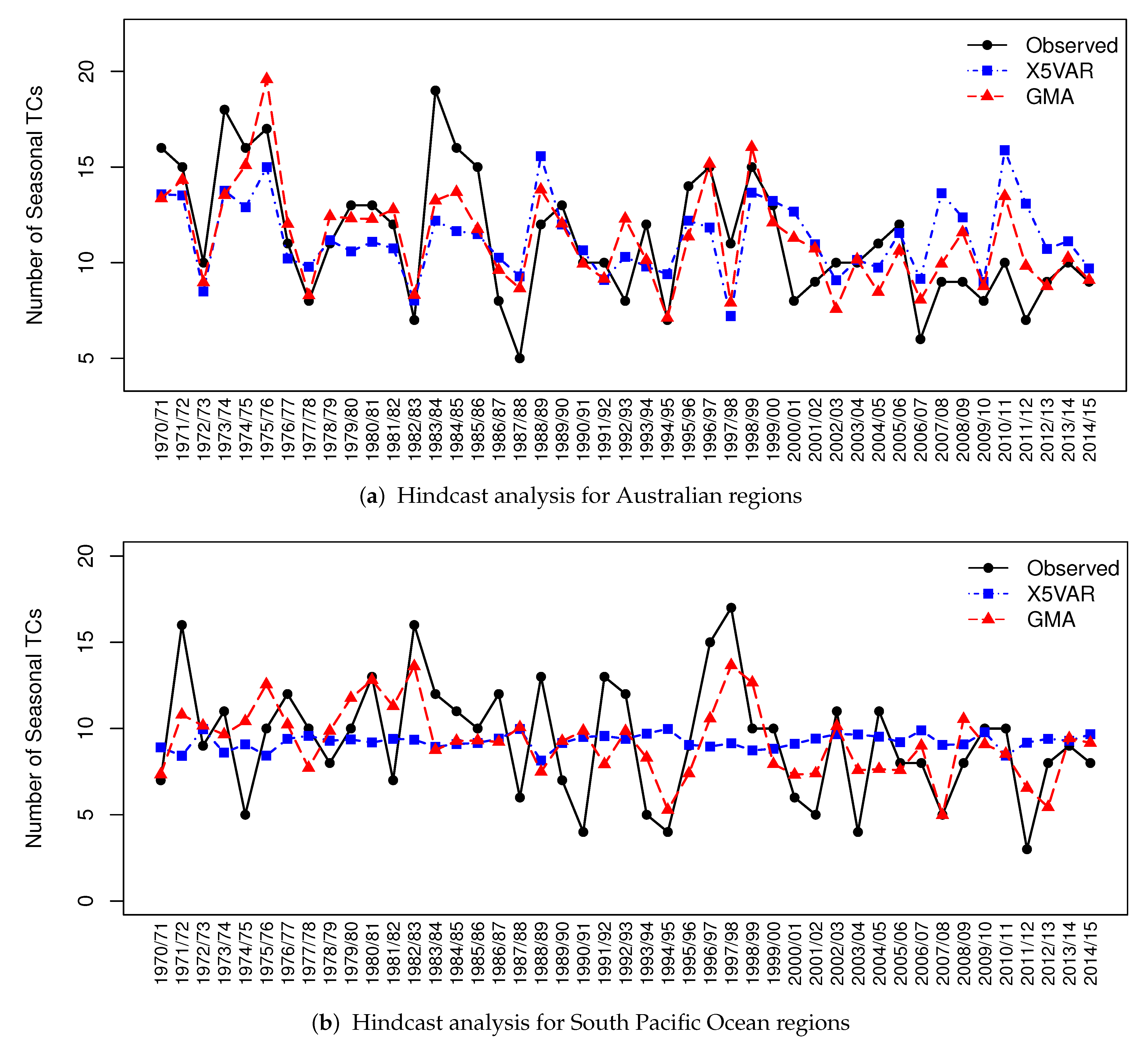
4.2. Hindcast Analysis
5. Summary
- We have identified the most important climate indices impacting seasonal TC frequency in each region and find DMI and EMI are among the most important ones in most regions.
- Finding the best model with minimal AICc values is computationally feasible where the MGRS algorithm is superior to the step-wise method.
- The MGRS algorithm is used to find a small set of top models with relatively small AICc values which, by a Gibbs sampling induced approach of model averaging, forms a GMA model. The GMA model is shown to have improved the performance of hindcast analysis of seasonal TC frequency in all regions.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kuleshov, Y.; Spillman, C.; Wang, Y.; Charles, A.; deWit, R.; Shelton, K.; Jones, D.; Hendon, H.; Ganter, C.; Watkins, A.; et al. Seasonal prediction of climate extremes for the Pacific: Tropical cyclones and extreme ocean temperatures. J. Mar. Sci. Technol. 2012, 20, 675–683. [Google Scholar] [CrossRef]
- Kuleshov, Y.; McGree, S.; Jones, D.; Charles, A.; Cottrill, B.; Prakash, B.; Atalifo, T.; Nihmei, S.; Seuseu, F.L.S.K. Extreme weather and climate events and their impacts on island countries in the Western Pacific: Cyclones, floods and droughts. Atmos. Clim. Sci. 2014, 4, 803–818. [Google Scholar] [CrossRef] [Green Version]
- Do, C.; Kuleshov, Y. Multi-hazard Tropical Cyclone Risk Assessment for Australia. Nat. Hazards Earth Syst. Sci. Discuss. 2022, preprint. [Google Scholar] [CrossRef]
- Kuleshov, Y.; Gregory, P.; Watkins, A.B.; Fawcwtt, R.J.B. Tropical cyclone early warnings for the regions of the Southern Hemisphere: Strengthening resilience to tropical cyclones in small island developing states and least developed countries. Nat. Hazards 2020, 104, 1295–1313. [Google Scholar] [CrossRef]
- Nicholls, N. A possible method for predicting seasonal tropical cyclone activity in the Australian region. Mon. Weather Rev. 1979, 107, 1221–1224. [Google Scholar] [CrossRef]
- Nicholls, N. The Southern Oscillation, sea-surface-temperature, and interannual fluctuations in Australian tropical cyclone activity. J. Climatol. 1984, 4, 661–670. [Google Scholar] [CrossRef]
- Gray, W.M. Atlantic seasonal hurricane frequency. Part I: El Niño and 30-mb quasi biennial oscillation influences. Mon. Weather Rev. 1984, 112, 1649–1668. [Google Scholar] [CrossRef]
- Gray, W.M. Atlantic seasonal hurricane frequency. Part II: Forecasting its variability. Mon. Weather Rev. 1984, 112, 1669–1683. [Google Scholar] [CrossRef]
- Nicholls, N. Recent performance of a method for forecasting Australian seasonal tropical cyclone activity. Aust. Meteorol. Mag. 1992, 40, 105–110. [Google Scholar]
- McDonnell, K.A.; Holbrook, N.J. A Poisson regression model of tropical cyclogenesis for the Australian–southwest Pacific Ocean region. Weather Forecast. 2004, 19, 440–455. [Google Scholar] [CrossRef]
- Jagger, T.H.; Elsner, J.B. A consensus model for seasonal hurricane prediction. J. Clim. 2010, 23, 6090–6099. [Google Scholar] [CrossRef]
- Kuleshov, Y.; Qi, L.; Fawcett, R.; Jones, D. Improving preparedness to natural hazards: Tropical cyclone prediction for the Southern Hemisphere. In Advances in Geosciences: Volume 12: Ocean Science (OS); Gan, J., Ed.; World Scientific Publishing: Singapore, 2009; pp. 127–143. [Google Scholar] [CrossRef]
- Wijnands, J.; Qian, G.; Shelton, K.; Fawcett, R.; Chan, J.; Kuleshov, Y. Seasonal forecasting of tropical cyclone activity in the Australian and the South Pacific Ocean regions. Math. Clim. Weather Forecast. 2015, 1, 21–42. [Google Scholar] [CrossRef]
- Vitart, F.; Stockdale, T.N. Seasonal Forecasting of Tropical Storms Using Coupled GCM Integrations. Mon. Weather Rev. 2001, 129, 2521–2537. [Google Scholar] [CrossRef]
- Camargo, S.J.; Barnston, A.G. Experimental dynamical seasonal forecasts of tropical cyclone activity at IRI. Weather Forecast. 2009, 24, 472–491. [Google Scholar] [CrossRef]
- Johnson, S.J.; Stockdale, T.N.; Ferranti, L.; Balmaseda, M.A.; Molteni, F.; Magnusson, L.; Tietsche, S.; Decremer, D.; Weisheimer, A.; Balsamo, G.; et al. SEAS5: The new ECMWF seasonal forecast system. Geosci. Model Dev. 2019, 12, 1087–1117. [Google Scholar] [CrossRef] [Green Version]
- Vecchi, G.; Zhao, M.; Wang, H.; Villarini, G.; Rosati, A.; Kumar, A.; Held, I.; Gudgel, G. Statistical-dynamical predictions of seasonal North Atlantic hurricane activity. Mon. Weather. Rev. 2011, 139, 1070–1082. [Google Scholar] [CrossRef]
- Klotzbach, P.; Blake, E.; Camp, J.; Caron, L.; Chan, L.C.J.; Kang, N.; Kuleshov, Y.; Lee, S.; Murakami, H.; Saunders, M.; et al. Seasonal Tropical Cyclone Forecasting. Trop. Cyclone Res. Rev. 2019, 8, 134–149. [Google Scholar] [CrossRef]
- Kuleshov, Y.; Qi, L.; Fawcett, R.; Jones, D. On tropical cyclone activity in the Southern Hemisphere: Trends and the ENSO connection. Geophys. Res. Lett. 2008, 35. [Google Scholar] [CrossRef]
- Kuleshov, Y.; Chane Ming, F.; Qi, L.; Chouaibou, I.; Hoareau, C.; Roux, F. Tropical cyclone genesis in the Southern Hemisphere and its relationship with the ENSO. Ann. Geophys. 2009, 27, 2523–2538. [Google Scholar] [CrossRef] [Green Version]
- Wijnands, J.S.; Qian, G.; Kuleshov, Y. Variable selection for tropical cyclogenesis predictive modeling. Mon. Weather Rev. 2016, 144, 4605–4619. [Google Scholar] [CrossRef]
- Hurvich, C.M.; Tsai, C.L. Regression and time series model selection in small samples. Biometrika 1989, 76, 297–307. [Google Scholar] [CrossRef]
- Qian, G.; Field, C. Using MCMC for logistic regression model selection involving large number of candidate models. In Monte Carlo and Quasi-Monte Carlo Methods 2000; Springer: Berlin/Heidelberg, Germany, 2002; pp. 460–474. [Google Scholar]
- Liu, J.S. Metropolized Gibbs Sampler: An Improvement; Technical Report; Department of Statistics, Stanford University: Stanford, CA, USA, 1996. [Google Scholar]
- Kuleshov, Y. Climate Change and Southern Hemisphere Tropical Cyclones International Initiative: Twenty Years of Successful Regional Cooperation. In Climate Change, Hazards and Adaptation Options: Handling the Impacts of a Changing Climate; Leal Filho, W., Nagy, G.J., Borga, M., Chávez Muñoz, P.D., Magnuszewski, A., Eds.; Springer International Publishing: Cham, Swizerland, 2020; pp. 411–439. [Google Scholar] [CrossRef]
- Dowdy, A.; Kuleshov, Y. An analysis of tropical cyclone occurrence in the Southern Hemisphere derived from a new satellite-era dataset. Int. J. Remote Sens. 2012, 33, 7382–7397. [Google Scholar] [CrossRef]
- Broomhall, M.; Berzins, B.; Grant, I.; Majewski, L.; Willmott, M.; Burton, A.; Paterson, L.; Santos, B.; Jones, D.; Kuleshov, Y. Investigating the Australian Bureau of Meteorology GMS Satellite Archive for use in Tropical Cyclone Reanalysis. Aust. Meteorol. Oceanogr. J. 2014, 64, 167–182. [Google Scholar] [CrossRef]
- Kuleshov, Y.; Fawcett, R.; Qi, L.; Trewin, B.; Jones, D.; McBride, J.; Ramsay, H. Trends in tropical cyclones in the South Indian Ocean and the South Pacific Ocean. J. Geophys. Res. Atmos. 2010, 115, D01101. [Google Scholar] [CrossRef]
- Gray, W.M. Environmental influences on tropical cyclones. Aust. Meteorol. Mag. 1988, 36, 127–139. [Google Scholar]
- Gray, W.M.; Landsea, C.W.; Mielke, P.W.J.; Berry, K.J. Predicting Atlantic basin tropical cyclone activity by 1 June. Weather. Forecast. 1994, 9, 103–115. [Google Scholar] [CrossRef]
- Camargo, S.J.; Sobel, A. Revisiting the influence of the quasi-biennial oscillation on tropical cyclone activity. J. Clim. 2010, 23, 5810–5825. [Google Scholar] [CrossRef]
- Jaramillo, A.; Dominguez, C.; Raga, G.; Quintanar, A.I. The combined QBO and ENSO influence on tropical cyclone activity over the North Atlantic Ocean. Atmosphere 2021, 12, 1588. [Google Scholar] [CrossRef]
- Klotzbach, P.; Abhik, S.; Hendon, H.; Bell, M.; Lucas, C.; Marshall, A.; Oliver, E. On the emerging relationship between the stratospheric Quasi-Biennial oscillation and the Madden-Julian oscillation. Sci. Rep. 2019, 9, 2981. [Google Scholar] [CrossRef] [Green Version]
- Klotzbach, P.J. The Madden-Julian oscillation’s impacts on worldwide tropical cyclone activity. J. Clim. 2014, 27, 2317–2330. [Google Scholar] [CrossRef]
- Camp, J.; Wheeler, M.; Hendon, H.; Gregory, P.; Marshall, A.; Tory, K.; Watkins, A.; MacLachlan, C.; Kuleshov, Y. Skilful multiweek tropical cyclone prediction in ACCESS-S1 and the role of the MJO. Q. J. R. Meteorol. Soc. 2018, 144, 1337–1351. [Google Scholar] [CrossRef]
- Wilks, D.S. Statistical Methods in the Atmospheric Sciences; Academic Press: Cambridge, MA, USA, 2011; Volume 100. [Google Scholar]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Magee, A.D.; Lorrey, A.M.; Kiem, A.S.; Colyvas, K. A new island-scale tropical cyclone outlook for southwest Pacific nations and territories. Sci. Rep. 2020, 10, 1–13. [Google Scholar] [CrossRef]
- Miller, A.J. Selection of subsets of regression variables. J. R. Stat. Soc. Ser. A 1984, 147, 389–410. [Google Scholar] [CrossRef]
- Robert, C.P.; Casella, G. Monte Carlo Statistical Methods; Springer: Berlin/Heidelberg, Germany, 2004; Volume 2. [Google Scholar]
- Qian, G.; Zhao, X. On time series model selection involving many candidate ARMA models. Comput. Stat. Data Anal. 2007, 51, 6180–6196. [Google Scholar] [CrossRef]
- George, E.I.; McCulloch, R.E. Approaches for Bayesian variable selection. Stat. Sin. 1997, 7, 339–373. [Google Scholar]
- Buckland, S.T.; Burnham, K.P.; Augustin, N.H. Model selection: An integral part of inference. Biometrics 1997, 53, 603–618. [Google Scholar] [CrossRef]
- Burnham, K.P.; Anderson, D.R. Multimodel inference: Understanding AIC and BIC in model selection. Sociol. Methods Res. 2004, 33, 261–304. [Google Scholar] [CrossRef]
- Drosdowsky, W.; Chambers, L.E. Near-global sea surface temperature anomalies as predictors of Australian seasonal rainfall. J. Clim. 2001, 14, 1677–1687. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description |
|---|---|
| N12.Aug | Niño1+2 SST anomalies (August) |
| N12.Sep | Niño1+2 SST anomalies (September) |
| N12.Oct | Niño1+2 SST anomalies (October) |
| N3.Aug | Niño3 SST anomalies (August) |
| N3.Sep | Niño3 SST anomalies (September) |
| N3.Oct | Niño3 SST anomalies (October) |
| N34.Aug | Niño3.4 SST anomalies (August) |
| N34.Sep | Niño3.4 SST anomalies (September) |
| N34.Oct | Niño3.4 SST anomalies (October) |
| N4.Aug | Niño4 SST anomalies (August) |
| N4.Sep | Niño4 SST anomalies (September) |
| N4.Oct | Niño4 SST anomalies (October) |
| EMI.Aug | El Niño Modoki Index (August) |
| EMI.Sep | El Niño Modoki Index (September) |
| EMI.Oct | El Niño Modoki Index (October) |
| DMI.Aug | Dipole Mode Index (August) |
| DMI.Sep | Dipole Mode Index (September) |
| DMI.Oct | Dipole Mode Index (October) |
| DMIW.Aug | Dipole Mode Index West (August) |
| DMIW.Sep | Dipole Mode Index West (September) |
| DMIW.Oct | Dipole Mode Index West (October) |
| DMIE.Aug | Dipole Mode Index East (August) |
| DMIE.Sep | Dipole Mode Index East (September) |
| DMIE.Oct | Dipole Mode Index East (October) |
| QBO.Aug | Quasi-biennial oscillation (August) |
| QBO.Sep | Quasi-biennial oscillation (September) |
| QBO.Oct | Quasi-biennial oscillation (October) |
| SOI.Aug | Southern Oscillation Index (August) |
| SOI.Sep | Southern Oscillation Index (September) |
| SOI.Oct | Southern Oscillation Index (October) |
| TMSLP.Aug | Tahiti mean sea level pressure (August) |
| TMSLP.Sep | Tahiti mean sea level pressure (September) |
| TMSLP.Oct | Tahiti mean sea level pressure (October) |
| DMSLP.Aug | Darwin mean sea level pressure (August) |
| DMSLP.Sep | Darwin mean sea level pressure (September) |
| DMSLP.Oct | Darwin mean sea level pressure (October) |
| AR | AR-W | AR-NW | AR-N | AR-E | SPO | SPO-W | SPO-E | |
|---|---|---|---|---|---|---|---|---|
| STEP | 216.3 | 195.9 | 191.6 | 152.6 | 175.0 | 233.8 | 177.7 | 216.1 |
| BEST | 214.7 | 194.5 | 189.9 | 150.3 | 169.8 | 226.8 | 177.2 | 215.6 |
| AR | AR-W | AR-NW | AR-N | AR-E | SPO | SPO-W | SPO-E | |
|---|---|---|---|---|---|---|---|---|
| X5VAR | ||||||||
| STEP | ||||||||
| BEST | ||||||||
| GMA | 0.66 |
| AR | AR-W | AR-NW | AR-N | AR-E | SPO | SPO-W | SPO-E | |
|---|---|---|---|---|---|---|---|---|
| X5VAR | ||||||||
| STEP | ||||||||
| BEST | ||||||||
| GMA | 1.73 |
| AR | AR-W | AR-NW | AR-N | AR-E | SPO | SPO-W | SPO-E | |
|---|---|---|---|---|---|---|---|---|
| X5VAR | ||||||||
| STEP | ||||||||
| BEST | ||||||||
| GMA |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qian, G.; Chen, L.; Kuleshov, Y. Improving Methodology for Tropical Cyclone Seasonal Forecasting in the Australian and the South Pacific Ocean Regions by Selecting and Averaging Models via Metropolis–Gibbs Sampling. Remote Sens. 2022, 14, 5872. https://doi.org/10.3390/rs14225872
Qian G, Chen L, Kuleshov Y. Improving Methodology for Tropical Cyclone Seasonal Forecasting in the Australian and the South Pacific Ocean Regions by Selecting and Averaging Models via Metropolis–Gibbs Sampling. Remote Sensing. 2022; 14(22):5872. https://doi.org/10.3390/rs14225872
Chicago/Turabian StyleQian, Guoqi, Lizhong Chen, and Yuriy Kuleshov. 2022. "Improving Methodology for Tropical Cyclone Seasonal Forecasting in the Australian and the South Pacific Ocean Regions by Selecting and Averaging Models via Metropolis–Gibbs Sampling" Remote Sensing 14, no. 22: 5872. https://doi.org/10.3390/rs14225872
APA StyleQian, G., Chen, L., & Kuleshov, Y. (2022). Improving Methodology for Tropical Cyclone Seasonal Forecasting in the Australian and the South Pacific Ocean Regions by Selecting and Averaging Models via Metropolis–Gibbs Sampling. Remote Sensing, 14(22), 5872. https://doi.org/10.3390/rs14225872