
Multiclass Land Cover Mapping from Historical Orthophotos Using Domain Adaptation and Spatio-Temporal Transfer Learning


Abstract
:1. Introduction
1.1. Historical Land Cover Mapping
1.2. Semantic Segmentation
1.3. Fully Convolutional Networks
1.4. Earth Observation Datasets
1.5. Transfer Learning
1.6. Unsupervised Domain Adaptation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Release | Name | Scene | Channels | Resolution | Annotations | Labelled Area | Classes |
|---|---|---|---|---|---|---|---|
| 2013 | ISPRS Potsdam 2D semantic labelling contest [44] | Urban, city of Potsdam (Germany) | RGB-IR + DSM (aerial orthophotos) | 0.05 m | Manual | 3.42 km² | 6: impervious surfaces, building, low vegetation, tree, car, clutter/background |
| 2013 | ISPRS Vaihingen 2D semantic labelling contest [43] | Urban, city of Vaihingen (Germany) | RG-NIR + DSM (aerial orthophotos) | 0.09 m | Manual | 1.36 km² | 6: impervious surfaces, building, low vegetation, tree, car, clutter/background |
| 2015 | 2015 IEEE GRSS Data Fusion Contest: Zeebruges [60] | Urban, harbour of Zeebruges (Belgium) | RGB + DSM (+ LIDAR) (aerial orthophotos) | 0.05 m + 0.1 m | Manual | 1.75 km² | 8: impervious surface, building, low vegetation, tree, car, clutter, boat, water |
| 2016 | DSTL Satellite Imagery Feature Detection Challenge [61] | Urban + rural, unknown | RGB + 16 (multispectral & SWIR) (Worldview-3) | 0.3 m + 1.24 m + 7.5 m | Unknown | 57 km² | 10: buildings, manmade structures, road, track, trees, crops, waterway, standing water, vehicle large, vehicle small |
| 2017 | 2017 IEEE GRSS Data Fusion Contest [62] | Urban + rural, local climate zones in various urban environments | 9 (Sentinel-2) + 8 (Landsat) + OSM layers (building, natural, roads, land-use areas) | 100 m | Crowdsourcing | ∼30,000 km² | 17: compact high rise, compact midrise, compact low-rise, open high-rise, open midrise, open low-rise, lightweight low-rise, large low-rise, sparsely built, heavy industry, dense trees, scattered trees, bush and scrub, low plants, bare rock or paved, bare soil or sand, water |
| 2018 | 2018 IEEE GRSS Data Fusion Contest [63] | Urban, university of Houston campus and its neighborhood | RGB + DSM + 48 hyperspectral (+ Lidar) (aerial) | 0.05 m + 0.5 m + 1 m | Manual, 0.5m resolution labels | 1.4 km² | 20: healthy grass, stressed grass, artificial turf, evergreen trees, deciduous trees, bare earth, water, residential buildings, non-residential buildings, roads, sidewalks, crosswalks, major thoroughfares, highways, railways, paved parking lots, unpaved parking lots, cars, trains, stadium seats |
| 2018 | DLRSD [64] | UC Merced images | RGB | Various (HR) | Manual (2100 256,256 images) | — | 17: airplane, bare soil, buildings, cars, chaparral, court, dock, field, grass, mobile home, pavement, sand, sea, ship, tanks, trees, water |
| 2018 | DeepGlobe—Land Cover Classification [65] | Urban + rural, unknown | RGB (Worldview-2/-3, GeoEye-1) | 0.5 m | Manual, minimum 20 × 20 m labels (Anderson Classification) | 1716.9 km² | 6: urban, agriculture, rangeland, forest, water, barren |
| 2019 | 2019 IEEE GRSS Data Fusion Contest [66] | Urban, Jacksonville (Florida, USA) and Omaha (Nebraska, USA) | panchromatic + 8 (VNIR) + DSM (+ LIDAR) (Wordlview-3, unrectified + epipolar) | 0.35 m + 1.3 m | Manual | 20 km² | 5: buildings, elevated roads and bridges, high vegetation, ground, water |
| 2019 | SkyScapes [67] | Urban, greater area of Munich (Germany) | RGB (aerial nadir-looking images) | 0.13 m | Manual | 5.69 km² | 31: 19 categories urban infrastructure (low vegetation, paved road, non-paved road, paved parking place, non-paved parking place, bike-way, sidewalk, entrance/exit, danger area, building, car, trailer, van, truck, large truck, bus, clutter, impervious surface, tree) & 12 categories street lane markings (dash-line, long-line, small dash-line, turn sign, plus sign, other signs, crosswalk, stop-line, zebra zone, no parking zone, parking zone, other lane-markings) |
| 2019 | Slovenia Land Cover classification [68] | Urban + rural, part of Slovenia | RGB, NIR, SWIR1, SWIR2 (Sentinel-2) | 10 m | Manual, official Slovenian land cover classes | ∼2.4 106 km² | 10: artificial surface, bareland, cultivated land, forest, grassland, shrubland, water, wetland |
| 2019 | DroneDeploy Segmentation Dataset [69] | Urban, unknown | RGB + DSM (drone orthophotos) | 0.1 m | Manual | <24 km² | 6: building, clutter, vegetation, water, ground, car |
| 2019 | SEN12MS [70] | Rural, globally distributed over all inhabited continents during all meteorological seasons | SAR (Sentinel-1) + multispectral (Sentinel-2) | 10 m | MODIS 500 m resolution labels, labels only 81% max correct | ∼3.6 106 km² | 17: water, evergreen needleleaf forest, evergreen broadleaf forest, deciduous needleleaf forest, deciduous broadleaf forest, mixed forest, closed shrublands, open shrublands, woody savannas, savannas, grasslands, permanent wetlands, croplands, urban and built-up, cropland/natural vegetation mosaic, snow and ice, barren or sparsely vegetated |
| 2019 | MiniFrance [71] | Urban + rural, imagery over Nice and Nantes/Saint Nazaire from 2012 to 2014 (France) | RGB (aerial orthophotos) | 0.5 m | Urban Atlas 2012 (second hierarchical level) | ∼10,225 km² | 15: urban fabric, transport units, mine/dump/construction, artificial non-agricultural vegetated areas, arable land (annual crops), permanent crops, pastures, complex and mixed cultivation patterns, orchards at the fringe of urban classes, forests, herbaceous vegetation associations, open spaces with little or no vegetation, wetlands, water, clouds and shadows |
| 2019 | HRSCD [72] | Rural, imagery over France for 2006 and 2012 | RGB (aerial orthophotos) | 0.5 m | Urban Atlas 2006 and 2012 at first level + binary change mask | ∼7275 km² | 5: artificial surfaces, agricultural areas, forests, wetlands, water |
| 2019 | Chesapeake Land Cover [19] | Urban + rural, Chesapeake Bay (USA) | RGB-NIR (NAIP 2013/2014) + RGB-NIR (NAIP 2011/2012) + 9 (Landsat 8 surface reflectance leaf-on) + 9 (Landsat 8 surface reflectance leaf-off) | 1 m (upsampled for Landsat) | HR LULC labels from the Chesapeake Conservancy (1 m) + low-resolution LULC labels from the USGS NLCD 2011 database + HR building footprint masks from Microsoft Bing | ∼32,940 km² | 6 (CC): water, tree canopy/forest, low vegetation/field, barren land, impervious (other), impervious (road). 20 (USGS NLCD): open water, perennial ice/snow, developed open space, developed low intensity, developed medium intensity, developed high intensity, barren land, deciduous forest, evergreen forest, mixed forest, dwarf scrub, shrub/scrub, grassland/herbaceous, sedge/herbaceous, lichens, moss, pasture/hay, cultivated crops, woody wetlands, emergent herbaceous wetlands |
| 2019 | iSAID [73] | Urban, unknown | RGB (Google Earth, satellite JL-1, satellite GF-2) | various (HR) | Manual, 2806 images with 655,451 instances | — | 15: plane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, large vehicle, small vehicle, helicopter, roundabout, soccer ball field and swimming pool |
| 2020 | WHDLD [74] | Urban, city of Wuhan (China) | RGB | 2 m | Manual | 1295 km² | 6: building, road, pavement, vegetation, bare soil, water |
| 2020 | Landcover.ai [75] | Urban + rural, imagery over Poland | RGB (aerial orthophotos) | 0.25 m/0.5 m | Manual | 216.27 km² | 3: Buildings, woodland, water |
| 2020 | LandCoverNet v1.0 [76] | Rural, imagery over Africa in 2018 | multispectral (Sentinel-2) | 10 m | Manual | 12,976 km² | 7: water, natural bare ground, artificial bare ground, woody vegetation, cultivated vegetation, (semi) natural vegetation, permanent snow/ice |
| 2020 | Agriculture Vision Dataset (CVPR 2020) [77] | Rural, farmlands across the USA throughout 2019 | RGB + NIR (aerial) | 0.1 m/ 0.15 m/ 0.2 m | Manual, 21,061 images with 169,086 instances | — | 6: cloud shadow, double plant, planter skip, standing water, waterway, weed cluster |
1.7. Research Scope and Contributions
- 1.
- We present a new small multi-temporal multiclass VHR annotated dataset: the ‘Sagalassos historical land cover dataset’, which covers both urban and rural scenes;
- 2.
- We propose and validate a novel methodology for obtaining LULC maps from historical monochromatic orthophotos with limited or even no training data available, based on FCNs and leveraging both domain pretraining and domain adaptation, i.e., ‘spatio-temporal transfer learning’;
- 3.
- Using this methodology, we generate a first historical LULC map for the greater area of the Sagalassos archaeological site (Turkey) in 1981.
2. Datasets
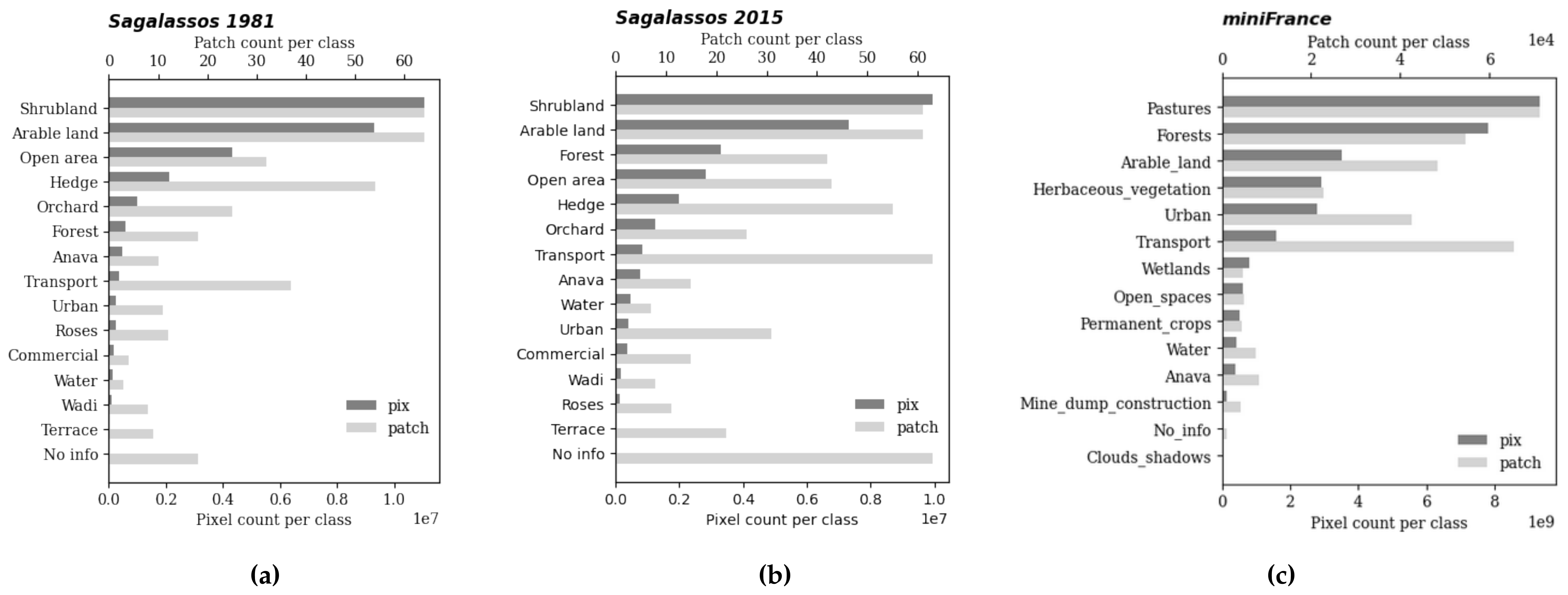
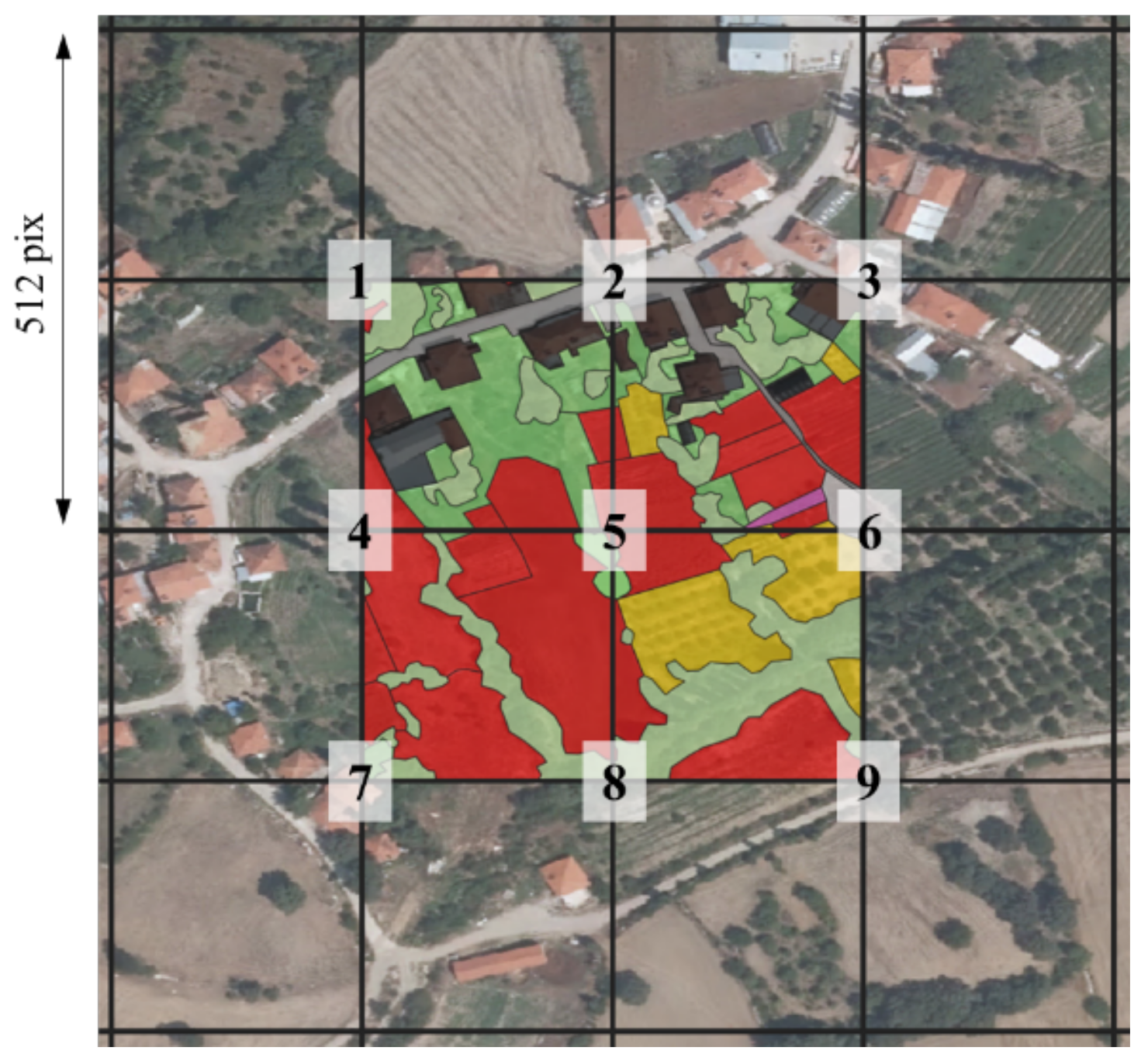
2.1. Sagalassos Historical Land Cover Dataset
2.2. MiniFrance
3. Experiments
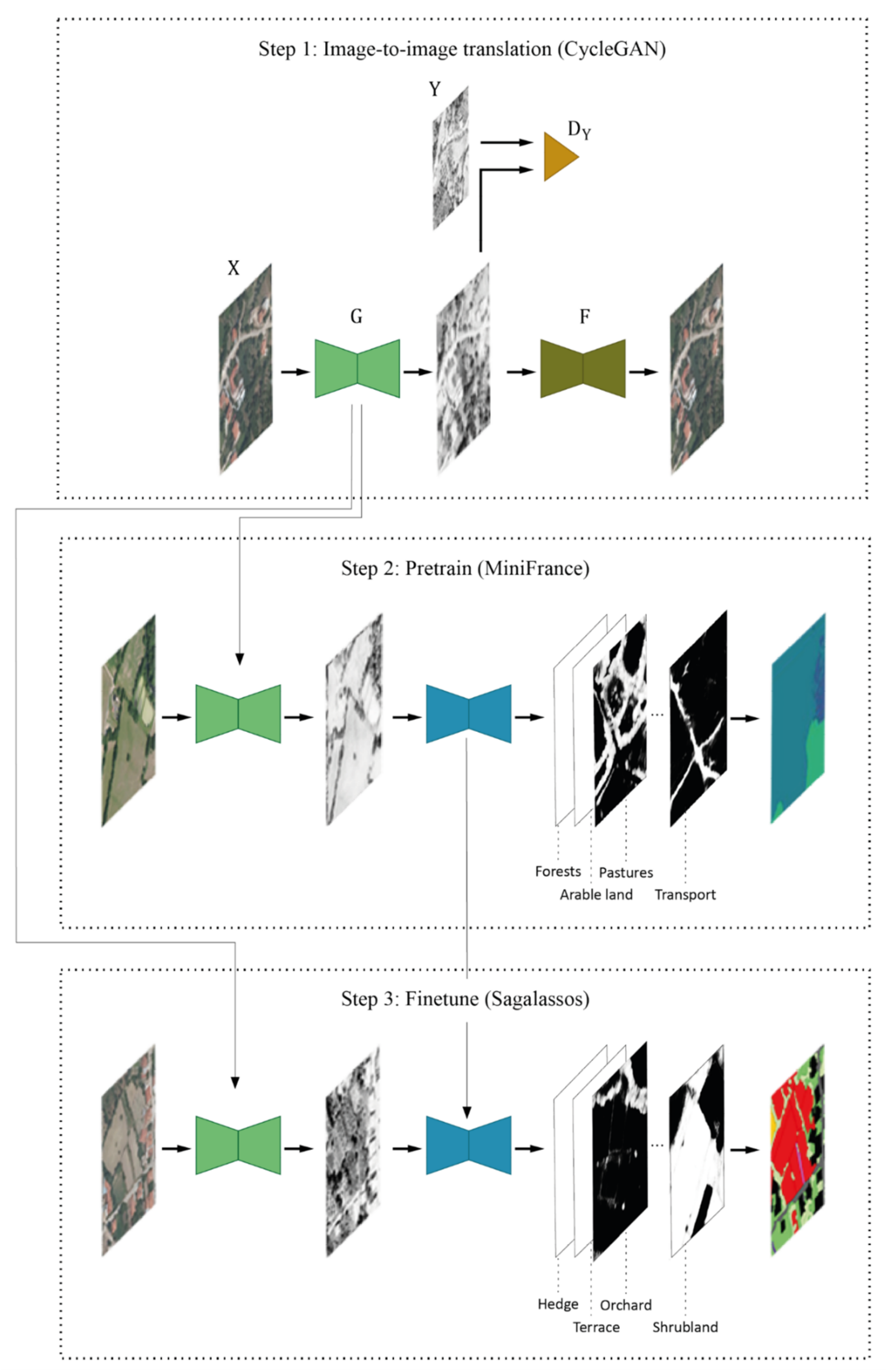
3.1. Spatio-Temporal Transfer Learning
3.1.1. Temporal Transfer Learning: Image to Image Translation
3.1.2. Spatial Transfer Learning: Pretraining
3.2. Neural Network Models
3.2.1. Image to Image
3.2.2. Semantic Segmentation
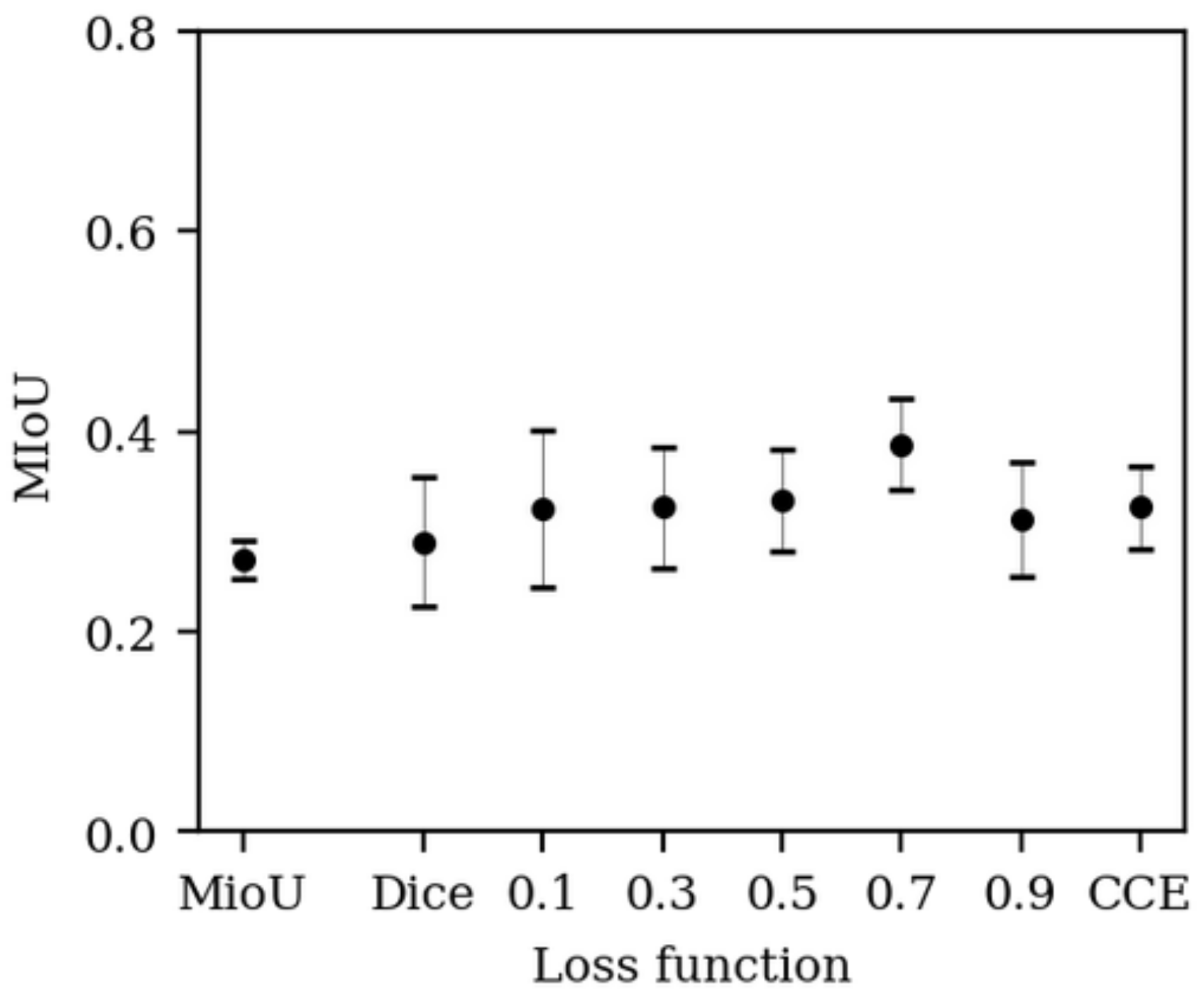
3.3. Model Training and Evaluation
3.3.1. CycleGAN
3.3.2. Segmentation Models
3.3.3. MiniFrance Pretraining
3.3.4. Sagalassos Training/Fine-Tuning
3.4. Inference and Post-Processing
3.4.1. Inference
3.4.2. Post-Processing
4. Results
4.1. Image to Image Translation
4.2. Transfer Learning
4.3. Semantic Segmentation
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CCE | Categorical Cross Entropy |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| DN | Digital Number |
| EO | Earth Observation |
| FCN | Fully Convolutional Network |
| FPN | Feature Pyramid Network |
| GAN | Generative Adversarial Network |
| GEOBIA | Geographical Object Based Image Analysis |
| GSD | Ground Sampling Distance |
| HIST | Historical-like monochromatic image |
| HR | High Resolution |
| I2I | Image-to-Image |
| LULC | Land-Use/Land-Cover |
| MAE | Mean Absolute Error |
| mTPR | mean True Positive Rate |
| MF | MiniFrance |
| mIoU | Mean Intersection over Union |
| MMU | Minimum Mapping Unit |
| MSE | Mean Squared Error |
| OA | Overall Accuracy |
| PAN | Panchromatic |
| ReLU | Rectified Linear Unit |
| RGB | Red, Green, Blue optical image |
| RS | Remote Sensing |
| SAG | Sagalassos |
| SLIC | Simple Linear Iterative Clustering |
| UDA | Unsupervised Domain Adaptation |
| UNet-EffB5 | UNet with EfficientNet-B5 backbone |
| VHR | Very High Resolution |
References
- Gómez, C.; White, J.C.; Wulder, M.A. Optical remotely sensed time series data for land cover classification: A review. ISPRS J. Photogramm. Remote. Sens. 2016, 116, 55–72. [Google Scholar] [CrossRef] [Green Version]
- Thyagharajan, K.K.; Vignesh, T. Soft Computing Techniques for Land Use and Land Cover Monitoring with Multispectral Remote Sensing Images: A Review. Arch. Comput. Methods Eng. 2017, 26, 275–301. [Google Scholar] [CrossRef]
- Hoeser, T.; Bachofer, F.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review—Part II: Applications. Remote Sens. 2020, 12, 3053. [Google Scholar] [CrossRef]
- Mboga, N.; D’Aronco, S.; Grippa, T.; Pelletier, C.; Georganos, S.; Vanhuysse, S.; Wolff, E.; Smets, B.; Dewitte, O.; Lennert, M.; et al. Domain Adaptation for Semantic Segmentation of Historical Panchromatic Orthomosaics in Central Africa. ISPRS Int. J. Geo-Inf. 2021, 10, 523. [Google Scholar] [CrossRef]
- Mboga, N.; Grippa, T.; Georganos, S.; Vanhuysse, S.; Smets, B.; Dewitte, O.; Wolff, E.; Lennert, M. Fully convolutional networks for land cover classification from historical panchromatic aerial photographs. ISPRS J. Photogramm. Remote. Sens. 2020, 167, 385–395. [Google Scholar] [CrossRef]
- Ratajczak, R.; Crispim-Junior, C.F.; Faure, E.; Fervers, B.; Tougne, L. Automatic Land Cover Reconstruction from Historical Aerial Images: An Evaluation of Features Extraction and Classification Algorithms. IEEE Trans. Image Process. 2019, 28, 3357–3371. [Google Scholar] [CrossRef] [Green Version]
- Deshpande, P.; Belwalkar, A.; Dikshit, O.; Tripathi, S. Historical land cover classification from CORONA imagery using convolutional neural networks and geometric moments. Int. J. Remote. Sens. 2021, 42, 5144–5171. [Google Scholar] [CrossRef]
- Ettehadi Osgouei, P.; Sertel, E.; Kabadayı, M.E. Integrated usage of historical geospatial data and modern satellite images reveal long-term land use/cover changes in Bursa/Turkey, 1858–2020. Sci. Rep. 2022, 12, 9077. [Google Scholar] [CrossRef]
- Morgan, J.L.; Gergel, S.E.; Coops, N.C. Aerial Photography: A Rapidly Evolving Tool for Ecological Management. BioScience 2010, 60, 47–59. [Google Scholar] [CrossRef]
- Pinto, A.T.; Gonçalves, J.A.; Beja, P.; Pradinho Honrado, J. From Archived Historical Aerial Imagery to Informative Orthophotos: A Framework for Retrieving the Past in Long-Term Socioecological Research. Remote Sens. 2019, 11, 1388. [Google Scholar] [CrossRef]
- Potůčková, M.; Kupková, L.; Červená, L.; Lysák, J.; Krause, D.; Hrázský, Z.; Březina, S.; Müllerová, J. Towards resolving conservation issues through historical aerial imagery: Vegetation cover changes in the Central European tundra. Biodivers. Conserv. 2021, 30, 3433–3455. [Google Scholar] [CrossRef]
- Lysandrou, V.; Agapiou, A. The Role of Archival Aerial Photography in Shaping Our Understanding of the Funerary Landscape of Hellenistic and Roman Cyprus. Open Archaeol. 2020, 6, 417–433. [Google Scholar] [CrossRef]
- Stichelbaut, B.; Plets, G.; Reeves, K. Towards an inclusive curation of WWI heritage: Integrating historical aerial photographs, digital museum applications and landscape markers in “Flanders Fields” (Belgium). J. Cult. Herit. Manag. Sustain. Dev. 2021, 11, 344–360. [Google Scholar] [CrossRef]
- Lech, P.; Zakrzewski, P. Depopulation and devastation: Using GIS for tracing changes in the archaeological landscape of Kharaib al-Dasht, a Late Islamic fishing village (Kuwait). Archaeol. Prospect. 2021, 28, 17–24. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A review. IEEE Geosci. Remote. Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote. Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Hossain, M.D.; Chen, D. Segmentation for Object-Based Image Analysis (OBIA): A review of algorithms and challenges from remote sensing perspective. ISPRS J. Photogramm. Remote. Sens. 2019, 150, 115–134. [Google Scholar] [CrossRef]
- Lang, S.; Hay, G.J.; Baraldi, A.; Tiede, D.; Blaschke, T. GEOBIA achievements and spatial opportunities in the era of big Earth observation data. ISPRS Int. J. Geo-Inf. 2019, 8, 474. [Google Scholar] [CrossRef] [Green Version]
- Robinson, C.; Hou, L.; Malkin, K.; Soobitsky, R.; Czawlytko, J.; DIlkina, B.; Jojic, N. Large scale high-resolution land cover mapping with multi-resolution data. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12718–12727. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote. Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Semantic segmentation of earth observation data using multimodal and multi-scale deep networks. Lect. Notes Comput. Sci. 2017, 10111 LNCS, 180–196. [Google Scholar] [CrossRef] [Green Version]
- Gaetano, R.; Ienco, D.; Ose, K.; Cresson, R. A two-branch CNN architecture for land cover classification of PAN and MS imagery. Remote Sens. 2018, 10, 1746. [Google Scholar] [CrossRef] [Green Version]
- Peng, C.; Li, Y.; Jiao, L.; Chen, Y.; Shang, R. Densely Based Multi-Scale and Multi-Modal Fully Convolutional Networks for High-Resolution Remote-Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2019, 12, 2612–2626. [Google Scholar] [CrossRef]
- Sun, W.; Wang, R. Fully Convolutional Networks for Semantic Segmentation of Very High Resolution Remotely Sensed Images Combined with DSM. IEEE Geosci. Remote Sens. Lett. 2018, 15, 474–478. [Google Scholar] [CrossRef]
- Mboga, N.; Georganos, S.; Grippa, T.; Lennert, M.; Vanhuysse, S.; Wolff, E. Fully Convolutional Networks and Geographic Object-Based Image Analysis for the Classification of VHR Imagery. Remote Sens. 2019, 11, 597. [Google Scholar] [CrossRef] [Green Version]
- Papadomanolaki, M.; Vakalopoulou, M.; Karantzalos, K. A Novel Object-Based Deep Learning Framework for Semantic Segmentation of Very High-Resolution Remote Sensing Data: Comparison with Convolutional and Fully Convolutional Networks. Remote Sens. 2019, 11, 684. [Google Scholar] [CrossRef] [Green Version]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote. Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef] [Green Version]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 640–651. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, Hawaii, 21–26 July 2016; pp. 2261–2269. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. IEEE Access 2015, 9, 16591–16603. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1867. [Google Scholar] [CrossRef] [Green Version]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Hoeser, T.; Kuenzer, C. Object Detection and Image Segmentation with Deep Learning on Earth Observation Data: A Review-Part I: Evolution and Recent Trends. Remote Sens. 2020, 12, 1667. [Google Scholar] [CrossRef]
- Fei-Fei, L.; Deng, J.; Li, K. ImageNet: Constructing a large-scale image database. J. Vision 2010, 9, 1037. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. Lect. Notes Comput. Sci. 2014, 8693 LNCS, 740–755. [Google Scholar] [CrossRef] [Green Version]
- Long, Y.; Xia, G.S.; Li, S.; Yang, W.; Yang, M.Y.; Zhu, X.X.; Zhang, L.; Li, D. On Creating Benchmark Dataset for Aerial Image Interpretation: Reviews, Guidances, and Million-AID. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2021, 14, 4205–4230. [Google Scholar] [CrossRef]
- Sumbul, G.; Charfuelan, M.; Demir, B.; Markl, V. Bigearthnet: A Large-Scale Benchmark Archive for Remote Sensing Image Understanding. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 5901–5904. [Google Scholar] [CrossRef] [Green Version]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar] [CrossRef] [Green Version]
- Van Etten, A.; Hogan, D.; Martinez-Manso, J.; Shermeyer, J.; Weir, N.; Lewis, R. The Multi-Temporal Urban Development SpaceNet Dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- ISPRS WGII/4. 2D Semantic Labeling—Vaihingen Data. 2013. Available online: https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-vaihingen/ (accessed on 18 March 2021).
- ISPRS WGII/4. 2D Semantic Labeling—Potsdam Data. 2013. Available online: https://www2.isprs.org/commissions/comm2/wg4/benchmark/2d-sem-label-potsdam/ (accessed on 18 March 2021).
- Kaiser, P.; Wegner, J.D.; Lucchi, A.; Jaggi, M.; Hofmann, T.; Schindler, K. Learning Aerial Image Segmentation from Online Maps. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6054–6068. [Google Scholar] [CrossRef]
- Kornblith, S.; Shlens, J.; Le, Q.V. Do better ImageNet models transfer better? arXiv 2018, arXiv:1805.08974. [Google Scholar]
- de Lima, R.P.; Marfurt, K. Convolutional neural network for remote-sensing scene classification: Transfer learning analysis. Remote Sens. 2020, 12, 86. [Google Scholar] [CrossRef] [Green Version]
- Wurm, M.; Stark, T.; Zhu, X.X.; Weigand, M.; Taubenböck, H. Semantic segmentation of slums in satellite images using transfer learning on fully convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2019, 150, 59–69. [Google Scholar] [CrossRef]
- Tuia, D.; Persello, C.; Bruzzone, L. Domain Adaptation for the Classification of Remote Sensing Data: An Overview of Recent Advances. IEEE Geosci. Remote Sens. Magaz. 2016, 4, 41–57. [Google Scholar] [CrossRef]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Liu, M.Y.; Belongie, S.; Kautz, J. Multimodal unsupervised image-to-image translation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 172–189. [Google Scholar]
- Bousmalis, K.; Silberman, N.; Dohan, D.; Erhan, D.; Krishnan, D. Unsupervised pixel-level domain adaptation with generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3722–3731. [Google Scholar]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.Y.; Isola, P.; Saenko, K.; Efros, A.A.; Darrell, T. CyCADA: Cycle-Consistent Adversarial Domain Adaptation. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018. [Google Scholar] [CrossRef]
- Murez, Z.; Kolouri, S.; Kriegman, D.; Ramamoorthi, R.; Kim, K. Image to image translation for domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4500–4509. [Google Scholar]
- Cai, Y.; Yang, Y.; Zheng, Q.; Shen, Z.; Shang, Y.; Yin, J.; Shi, Z. BiFDANet: Unsupervised Bidirectional Domain Adaptation for Semantic Segmentation of Remote Sensing Images. Remote Sens. 2022, 14, 190. [Google Scholar] [CrossRef]
- Benjdira, B.; Ammar, A.; Koubaa, A.; Ouni, K. Data-efficient domain adaptation for semantic segmentation of aerial imagery using generative adversarial networks. Appl. Sci. 2020, 10, 1092. [Google Scholar] [CrossRef] [Green Version]
- Tasar, O.; Tarabalka, Y.; Giros, A.; Alliez, P.; Clerc, S. StandardGAN: Multi-source domain adaptation for semantic segmentation of very high resolution satellite images by data standardization. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 747–756. [Google Scholar] [CrossRef]
- Tasar, O.; Giros, A.; Tarabalka, Y.; Alliez, P.; Clerc, S. DAugNet: Unsupervised, Multisource, Multitarget, and Life-Long Domain Adaptation for Semantic Segmentation of Satellite Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1067–1081. [Google Scholar] [CrossRef]
- Campos-Taberner, M.; Romero-Soriano, A.; Gatta, C.; Camps-Valls, G.; Lagrange, A.; Le Saux, B.; Beaupere, A.; Boulch, A.; Chan-Hon-Tong, A.; Herbin, S.; et al. Processing of Extremely High-Resolution LiDAR and RGB Data: Outcome of the 2015 IEEE GRSS Data Fusion Contest-Part A: 2D Contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2016, 9, 5547–5559. [Google Scholar] [CrossRef]
- Kaggle. Dstl Satellite Imagery Feature Detection. 2016. Available online: https://www.kaggle.com/c/dstl-satellite-imagery-feature-detection/data (accessed on 18 March 2021).
- Devis, T.; Moser, G.; Bertrand, L.S.; Benjamin, B. Data Fusion Contest 2017 (DFC2017). IEEE Dataport 2017, 5, 70–73. [Google Scholar] [CrossRef]
- Prasad, S.; Le Saux, B.; Yokoya, N.; Hansch, R. 2018 IEEE GRSS Data Fusion Challenge—Fusion of Multispectral LiDAR and Hyperspectral Data. IEEE Dataport 2018. [Google Scholar] [CrossRef]
- Shao, Z.; Yang, K.; Zhou, W. Performance Evaluation of Single-Label and Multi-Label Remote Sensing Image Retrieval Using a Dense Labeling Dataset. Remote Sens. 2018, 10, 964. [Google Scholar] [CrossRef] [Green Version]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raska, R. DeepGlobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, San Juan, PR, USA, 17–19 June 1997; pp. 172–181. [Google Scholar] [CrossRef] [Green Version]
- Le Saux, B.; Yokoya, N.; Haensch, R.; Brown, M. 2019 IEEE GRSS Data Fusion Contest: Large-Scale Semantic 3D Reconstruction [Technical Committees]. IEEE Geosci. Remote Sens. Magaz. 2019, 7, 33–36. [Google Scholar] [CrossRef]
- Azimi, S.M.; Henry, C.; Sommer, L.; Schumann, A.; Vig, E. SkyScapes Fine-Grained Semantic Understanding of Aerial Scenes. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 7392–7402. [Google Scholar] [CrossRef] [Green Version]
- Eo-learn. Example dataset of EOPatches for Slovenia 2019. 2019. Available online: http://eo-learn.sentinel-hub.com/ (accessed on 18 March 2021).
- DroneDeploy. DroneDeploy Segmentation Dataset. 2019. Available online: https://github.com/dronedeploy/dd-ml-segmentation-benchmark (accessed on 18 March 2021).
- Schmitt, M.; Hughes, L.H.; Qiu, C.; Zhu, X.X. SEN12MS—A Curated Dataset of Georeferenced Multi-Spectral Sentinel-1/2 Imagery for Deep Learning and Data Fusion. ISPRS Ann. Photogramm. Remote. Sens. Spat. Inf. Sci. 2019, IV-2/W7, 153–160. [Google Scholar] [CrossRef] [Green Version]
- Castillo-Navarro, J.; Audebert, N.; Boulch, A.; Le Saux, B.; Lefevre, S. What data are needed for semantic segmentation in earth observation? In Proceedings of the 2019 Joint Urban Remote Sensing Event, JURSE 2019, Vannes, France, 22–24 May 2019. [Google Scholar] [CrossRef] [Green Version]
- Caye Daudt, R.; Le Saux, B.; Boulch, A.; Gousseau, Y. Multitask learning for large-scale semantic change detection. Comput. Vis. Image Underst. 2019, 187, 102783. [Google Scholar] [CrossRef] [Green Version]
- Zamir, S.W.; Arora, A.; Gupta, A.; Khan, S.; Sun, G.; Khan, F.S.; Zhu, F.; Shao, L.; Xia, G.S.; Bai, X. iSAID: A large-scale dataset for instance segmentation in aerial images. arXiv 2019, arXiv:1905.12886. [Google Scholar]
- Shao, Z.; Zhou, W.; Deng, X.; Zhang, M.; Cheng, Q. Multilabel Remote Sensing Image Retrieval Based on Fully Convolutional Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2020, 13, 318–328. [Google Scholar] [CrossRef]
- Boguszewski, A.; Batorski, D.; Ziemba-Jankowska, N.; Zambrzycka, A.; Dziedzic, T. LandCover.ai: Dataset for automatic mapping of buildings, woodlands and water from aerial imagery. arXiv 2020, arXiv:2005.02264. [Google Scholar]
- Alemohammad, H.; Booth, K. LandCoverNet: A global benchmark land cover classification training dataset. arXiv 2020, arXiv:2012.03111. [Google Scholar]
- Chiu, M.T.; Xu, X.; Wei, Y.; Huang, Z.; Schwing, A.; Brunner, R.; Khachatrian, H.; Karapetyan, H.; Dozier, I.; Rose, G.; et al. Agriculture-vision: A large aerial image database for agricultural pattern analysis. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2825–2835. [Google Scholar] [CrossRef]
- Copernicus Land Monitoring Service. Mapping Guide v4.7 for a European Urban Atlas. 2016, p. 39. Available online: https://land.copernicus.eu/user-corner/technical-library/urban-atlas-2012-mapping-guide-new/view (accessed on 14 November 2022).
- Alotaibi, A. Deep Generative Adversarial Networks for Image-to-Image Translation: A Review. Symmetry 2020, 12, 1705. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef] [Green Version]
- A_K_Nain. CycleGAN. 2020. Available online: https://github.com/keras-team/keras-io/blob/master/examples/generative/cyclegan.py (accessed on 14 February 2021).
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 10–15 June 2019; pp. 10691–10700. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. Lect. Notes Comput. Sci. 2018, 11211 LNCS, 833–851. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2019 IEEE Intelligent Conference on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), Xiamen, China, 16–18 December 2016; pp. 1500–1504. [Google Scholar] [CrossRef]
- Yakubovskiy, P. Segmentation Models. 2019. Available online: https://github.com/qubvel/segmentation_models (accessed on 10 January 2021).
- Lu, Y. Amazing Semantic Segmentation. 2020. Available online: https://github.com/luyanger1799/Amazing-Semantic-Segmentation (accessed on 5 March 2021).
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- van der Walt, S.; Schönberger, J.L.; Nunez-Iglesias, J.; Boulogne, F.; Warner, J.D.; Yager, N.; Gouillart, E.; Yu, T. Scikit-image: Image processing in Python. PeerJ 2014, 2, e453. [Google Scholar] [CrossRef]
- Ouyang, S.; Li, Y. Combining deep semantic segmentation network and graph convolutional neural network for semantic segmentation of remote sensing imagery. Remote Sens. 2021, 13, 119. [Google Scholar] [CrossRef]
- Wang, F.; Luo, X.; Wang, Q.; Li, L. Aerial-BiSeNet: A real-time semantic segmentation network for high resolution aerial imagery. Chinese J. Aeronaut. 2021, 34, 47–59. [Google Scholar] [CrossRef]
- Marmanis, D.; Wegner, J.D.; Galliani, S.; Schindler, K.; Datcu, M.; Stilla, U. Semantic segmentation of aerial images with an ensemble of CNNS. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2016, 3, 473–480. [Google Scholar] [CrossRef]
- Caye Daudt, R.; Le Saux, B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the International Conference on Image Processing, ICIP, Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar] [CrossRef] [Green Version]
- Khelifi, L.; Mignotte, M. Deep Learning for Change Detection in Remote Sensing Images: Comprehensive Review and Meta-Analysis. IEEE Access 2020, 8, 126385–126400. [Google Scholar] [CrossRef]
- Park, T.; Efros, A.A.; Zhang, R.; Zhu, J.Y. Contrastive Learning for Unpaired Image-to-Image Translation. Lect. Notes Comput. Sci. 2020, 12354 LNCS, 319–345. [Google Scholar] [CrossRef]
- Fang, B.; Kou, R.; Pan, L.; Chen, P. Category-sensitive domain adaptation for land cover mapping in aerial scenes. Remote Sens. 2019, 11, 2631. [Google Scholar] [CrossRef]













| Year | Resolution [pixels] | Channels | GSD 1 [m] |
|---|---|---|---|
| 2015 | RGB | 0.30 | |
| 1992 | PAN 2 | 0.84 | |
| 1981 | PAN | 0.34 | |
| 1971 | PAN | 0.50 |
| ID | Class | Description |
|---|---|---|
| 0 | No info | No label information available; can be any of the 14 classes below. |
| 1 | Anava | (Artificial non-agricultural vegetated area) Everything in the urban area which is not Transport, Urban, Arable land or Forest |
| 2 | Arable land | Everything looking like an agricultural parcel, which is not Orchard or Roses; if not clearly Hedge the boarders are also arable land |
| 3 | Commercial | Industry, storage areas, dumps, mines; buildings within industry are classified as Urban |
| 4 | Forest | Strictly dense tree aggregation (non-shrubs); tree aggregations in urban area are also Forest |
| 5 | Hedge | Tree/shrub rows in between agricultural parcels |
| 6 | Open area | None of the other classes; pastures, rocky/mountain areas, wetlands |
| 7 | Orchard | Parcel in agricultural area with trees with a pattern-like appearance; always Orchard unless clearly Roses |
| 8 | Roses | Parcel in agricultural area with a more row-like pattern then Orchard (and non-tree) |
| 9 | Shrubland | Areas with intermittent open area and shrubs; everything that is not Forest; relatively broad class |
| 10 | Terrace | Human made walls, mostly in steeper terrain and at the border of agricultural parcels; only annotated when visible as terrace wall, annotated as Hedge/Forest when trees on top |
| 11 | Transport | All roads (paved and non-paved) and parking space; road parts with overhanging trees are also classified as Transport |
| 12 | Urban | All buildings |
| 13 | Wadi | Dry riverbeds |
| 14 | Water | Open waters of all sizes |
| Experiment | 2015 Validation | 1981 Test 2 | |||
|---|---|---|---|---|---|
| Pre-Train | Finetune | mIoU | mTPR | mIoU | mTPR |
| - | SAG15 | 34.3 | 69.0 | 16.2 | 29.3 |
| ImageNet | SAG15 | 13.8 | 44.4 | 0.6 | 9.6 |
| ImageNet | SAG15 | 58.7 | 85.5 | 27.8 | 44.9 |
| MiniFrance | SAG15 | 59.1 | 80.6 | 31.1 | 45.5 |
| MiniFrance | SAG15 | 65.0 | 86.9 | 29.2 | 42.3 |
| MiniFrance | SAG15 f.c.1 | 60.0 | 85.4 | 31.1 | 46.1 |
| Data Set | MF Validation | |
|---|---|---|
| mIoU | mTPR | |
| MiniFrance-rgb | 29.5 | 45.5 |
| MiniFrance-grey | 29.3 | 53.1 |
| MiniFrance-hist | 25.8 | 46.3 |
| Model | Parameters | Inference Speed [kms ] | 2015 Validation | 1981 Test 1 | ||
|---|---|---|---|---|---|---|
| mIoU | mTPR | mIoU | mTPR | |||
| UNet-EffB5 | 41 | 0.28 | 34.3 | 69.0 | 16.2 | 29.3 |
| FPN-EffB5 | 32 | 0.27 | 27.0 | 58.2 | 16.7 | 43.1 |
| DeeplabV3+ | 54 | 0.28 | 31.8 | 64.6 | 17.2 | 40.6 |
| Inference Stride | Aggregation | Post Proc. | 1981 Test | |
|---|---|---|---|---|
| mIoU | mTPR | |||
| 1 | - | - | 30.0 | 46.8 |
| 1/2 | max | - | 30.7 | 45.9 |
| 1/2 | avg | - | 31.1 | 46.1 |
| 1/3 | avg | - | 31.1 | 46.1 |
| 1/4 | avg | - | 31.1 | 46.1 |
| 1/4 | avg | SLIC | 31.1 | 46.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Van den Broeck, W.A.J.; Goedemé, T.; Loopmans, M. Multiclass Land Cover Mapping from Historical Orthophotos Using Domain Adaptation and Spatio-Temporal Transfer Learning. Remote Sens. 2022, 14, 5911. https://doi.org/10.3390/rs14235911
Van den Broeck WAJ, Goedemé T, Loopmans M. Multiclass Land Cover Mapping from Historical Orthophotos Using Domain Adaptation and Spatio-Temporal Transfer Learning. Remote Sensing. 2022; 14(23):5911. https://doi.org/10.3390/rs14235911
Chicago/Turabian StyleVan den Broeck, Wouter A. J., Toon Goedemé, and Maarten Loopmans. 2022. "Multiclass Land Cover Mapping from Historical Orthophotos Using Domain Adaptation and Spatio-Temporal Transfer Learning" Remote Sensing 14, no. 23: 5911. https://doi.org/10.3390/rs14235911
APA StyleVan den Broeck, W. A. J., Goedemé, T., & Loopmans, M. (2022). Multiclass Land Cover Mapping from Historical Orthophotos Using Domain Adaptation and Spatio-Temporal Transfer Learning. Remote Sensing, 14(23), 5911. https://doi.org/10.3390/rs14235911