
Autoencoder Neural Network-Based STAP Algorithm for Airborne Radar with Inadequate Training Samples





Abstract
:1. Introduction
2. Signal Model
3. The Proposed Algorithm
4. Simulation Results
4.1. Space-Time Distributions of Clutter and Two Dimensional Frequency Response
4.2. Improvement Factor Results
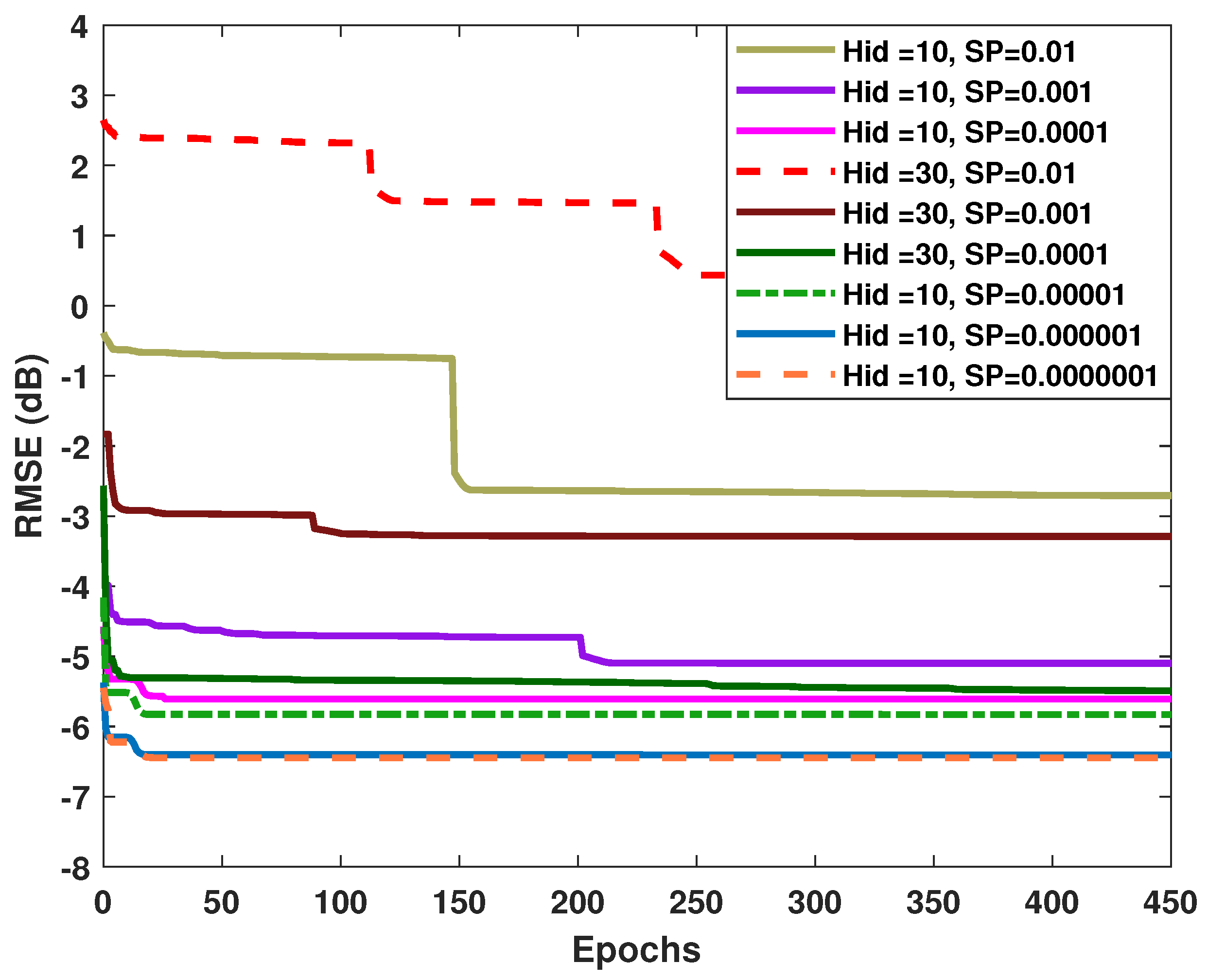
4.3. Convergence Results of the Proposed Algorithm
4.4. Computation Time of the Proposed Algorithm
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kang, M.S.; Kim, K.T. Automatic SAR Image Registration via Tsallis Entropy and Iterative Search Process. IEEE Sens. J. 2020, 20, 7711–7720. [Google Scholar] [CrossRef]
- Gong, M.G.; Cao, Y.; Wu, Q.D. A Neighborhood-Based Ratio Approach for Change Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2012, 9, 307–311. [Google Scholar] [CrossRef]
- Hakim, W.L.; Achmad, A.R.; Eom, J.; Lee, C.W. Land Subsidence Measurement of Jakarta Coastal Area Using Time Series Interferometry with Sentinel-1 SAR Data. J. Coast. Res. 2020, 102, 75–81. [Google Scholar] [CrossRef]
- Ward, J. Space-Time Adaptive Processing for Airborne Radar; Technical Report; MIT Lincoln Laboratory: Lexington, KY, USA, 1998. [Google Scholar]
- Klemm, R. Principles of Space-Time Adaptive Processing; The Institution of Electrical Engineers: London, UK, 2002. [Google Scholar]
- Guerci, J.R. Space-Time Adaptive Processing for Radar; Artech House: Norwood, MA, USA, 2003. [Google Scholar]
- Reed, I.S.; Mallett, J.D.; Brennan, L.E. Rapid convergence rate in adaptive arrays. IEEE Trans. Aerosp. Electron. Syst. 1974, AES-10, 853–863. [Google Scholar] [CrossRef]
- Zhang, Q.; Mikhael, W.B. Estimation of the clutter rank in the case of subarraying for space-time adaptive processing. Electron. Lett. 1997, 35, 419–420. [Google Scholar] [CrossRef]
- Melvin, W.L. Space-time adaptive radar performance in heterogeneous clutter. IEEE Trans. Aerosp. Electron. Syst. 2000, 36, 621–633. [Google Scholar] [CrossRef]
- Lapierre, F.D.; Ries, P.; Verly, J.G. Foundation for mitigating range dependence in radar space-time adaptive processing. IET Radar Sonar Navig. 2009, 3, 18–29. [Google Scholar] [CrossRef] [Green Version]
- Guerci, J.R.; Goldstein, J.S.; Reed, I.S. Optimal and adaptive reduced-rank STAP. IEEE Trans. Aerosp. Electron. Syst. 2000, 36, 647–663. [Google Scholar] [CrossRef]
- Liao, G.S.; Bao, Z.; Xu, Z.Y. A framework of rank-reduced space-time adaptive processing for airborne radar and its applications. Sci. China Ser. E Technol. Sci. 1997, 40, 505–512. [Google Scholar] [CrossRef]
- Zhang, L.; Bao, Z.; Liao, G.S. A comparative study of eigenspace based rank reduced STAP methods. Acta Electron. Sin. 2000, 28, 27–30. [Google Scholar]
- Goldstein, J.S. Reduced rank adaptive filtering. IEEE Trans. Signal Process. 1997, 45, 492–496. [Google Scholar] [CrossRef]
- Wang, W.L.; Liao, G.S.; Zhang, G.B. Improvement on the performance of the auxiliary channel STAP in the non-homogeneous environment. J. Xidian Univ. 2004, 20, 426–429. [Google Scholar]
- Wang, Y.; Peng, Y. Space-time joint processing method for simultaneous clutter and jamming rejection in airborne radar. Electron. Lett. 1996, 32, 258. [Google Scholar] [CrossRef]
- Yang, Z.C.; Li, X.; Wang, H.Q.; Jiang, W.D. On clutter sparsity analysis in space-time adaptive processing airborne radar. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1214–1218. [Google Scholar] [CrossRef]
- Sun, K.; Meng, H.; Wang, Y.; Wang, X. Direct data domain STAP using sparse representation of clutter spectrum. Signal Process. 2011, 91, 2222–2236. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.C.; Lamare, R.; Liu, W. Sparsity-based STAP using alternating direction method with gain/phase errors. IEEE Trans. Aerosp. Electron. Syst. 2017, 53, 2756–2768. [Google Scholar]
- Ji, S.; Xue, Y.; Carin, L. Bayesian compressive sensing. IEEE Trans. Signal Process. 2008, 56, 2346–2356. [Google Scholar] [CrossRef]
- Lim, C.H.; Mulgrew, B. Filter banks based JDL with angle and separate Doppler compensation for airborne bistatic radar. In Proceedings of the International Radar Symposium India, Bangalore, India, 18–22 December 2005; pp. 583–587. [Google Scholar]
- Lapierre, F.; Droogenbroeck, M.V.; Verly, J.G. New methods for handling the dependence of the clutter spectrum in non-sidelooking monostatic STAP radars. In Proceedings of the IEEE Acoustics, Speech, and Signal Processing Conference, Hong Kong, China, 6–10 April 2003; pp. 73–76. [Google Scholar]
- Lapierre, F.; Verly, J.G. Registration-based range dependence compensation for bistatic STAP radars. EURASIP J. Appl. Signal Process. 2005, 1, 85–98. [Google Scholar] [CrossRef] [Green Version]
- Lapierre, F.; Verly, J.G. Computationally-efficient range dependence compensation method for bistatic radar STAP. In Proceedings of the IEEE International Radar Conference, Arlington, VA, USA, 9–12 May 2005; pp. 714–719. [Google Scholar]
- Borsari, G.K. Mitigating effects on STAP processing caused by an inclined array. In Proceedings of the 1998 IEEE Radar Conference, Dallas, TX, USA, 11–14 May 1998; pp. 135–140. [Google Scholar]
- Kreyenkamp, O.; Klemm, R. Doppler compensation in forward-looking STAP radar. IEE Proc. Radar Sonar Navig. 2001, 148, 253–258. [Google Scholar] [CrossRef]
- Himed, B.; Zhang, Y.; Hajjari, A. STAP with angle-Doppler compensation for bistatic airborne radars. In Proceedings of the IEEE Radar Conference, Long Beach, CA, USA, 25 April 2002; pp. 311–317. [Google Scholar]
- Pearson, F.; Borsari, G. Simulation and analysis of adaptive interference suppression for bistatic surveillance radars. In Proceedings of the Adaptive Sensor Array Process, Lexington, MA, USA, 5–6 June 2007; LincoIn Laboratory: VIrkshop, MA, USA, 2007. [Google Scholar]
- Liu, K.; Wang, T.; Wu, J.; Liu, C.; Cui, W. On the Efficient Implementation of Sparse Bayesian Learning-Based STAP Algorithms. Remote Sens. 2022, 14, 3931. [Google Scholar] [CrossRef]
- Xu, J.W.; Liao, G.S.; Huang, L.; Zhu, S.Q. Joint magnitude and phase constrained STAP approach. Digit. Signal Process. 2015, 46, 32–40. [Google Scholar] [CrossRef]
- Ottersten, B.; Stoica, P.; Roy, R. Covariance matching estimation techniques for array signal processing applications. Digit. Signal Process. 1998, 8, 185–210. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, UK, 2016; Volume 1, Chapter 14; pp. 499–507. [Google Scholar]
- Gregor, K.; Lecun, Y. Learning fast approximations of sparse coding. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 399–406. [Google Scholar]
- Zhang, S.X.; Choromanska, A.; Yann, L.C. Deep learning with Elastic Averaging SGD. Adv. Neural Inf. Process. Syst. 2015, 28, 1–24. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Liao, G.; Xu, J.; Zhu, S.; Juwono, F.H.; Zeng, C. Autoencoder Neural Network-Based STAP Algorithm for Airborne Radar with Inadequate Training Samples. Remote Sens. 2022, 14, 6021. https://doi.org/10.3390/rs14236021
Liu J, Liao G, Xu J, Zhu S, Juwono FH, Zeng C. Autoencoder Neural Network-Based STAP Algorithm for Airborne Radar with Inadequate Training Samples. Remote Sensing. 2022; 14(23):6021. https://doi.org/10.3390/rs14236021
Chicago/Turabian StyleLiu, Jing, Guisheng Liao, Jingwei Xu, Shengqi Zhu, Filbert H. Juwono, and Cao Zeng. 2022. "Autoencoder Neural Network-Based STAP Algorithm for Airborne Radar with Inadequate Training Samples" Remote Sensing 14, no. 23: 6021. https://doi.org/10.3390/rs14236021
APA StyleLiu, J., Liao, G., Xu, J., Zhu, S., Juwono, F. H., & Zeng, C. (2022). Autoencoder Neural Network-Based STAP Algorithm for Airborne Radar with Inadequate Training Samples. Remote Sensing, 14(23), 6021. https://doi.org/10.3390/rs14236021