
Semantic Segmentation and Edge Detection—Approach to Road Detection in Very High Resolution Satellite Images


 , , ,
, , , 
Abstract
:1. Introduction
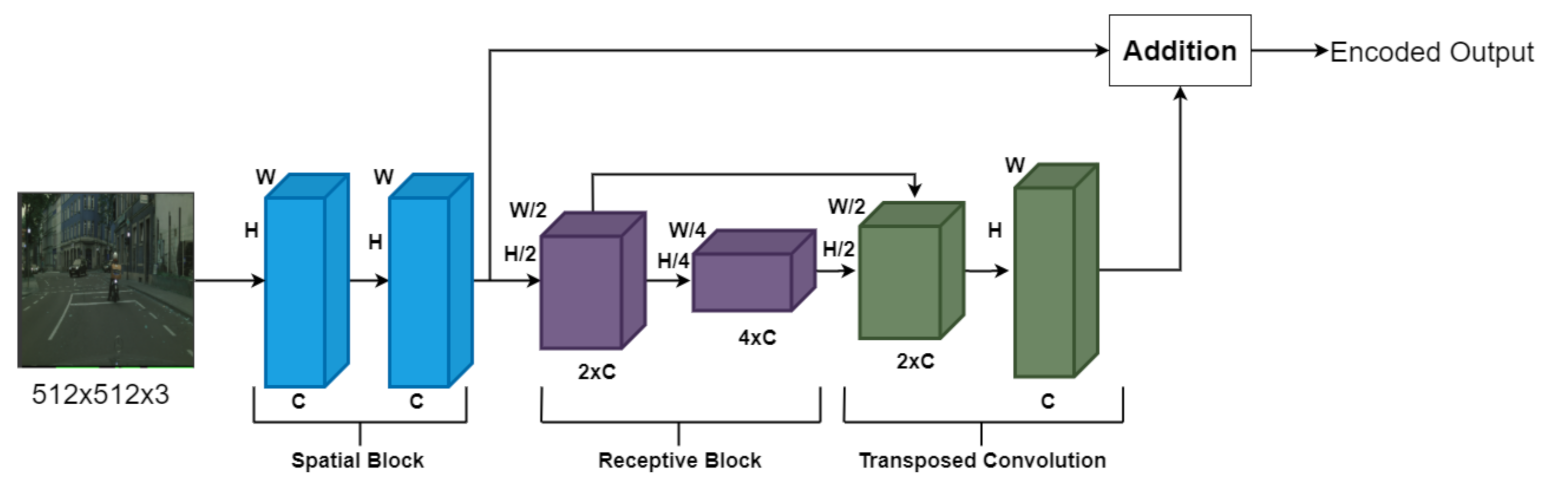
- This study designs an encoder with a large receptive field, meaning that it can adequately segment large objects and encode features in full resolution. This step is essential, as a high resolution is needed to produce fine segmentation masks.
- The study then uses these features to generate fine segmentation masks, which are then used to create road edges.
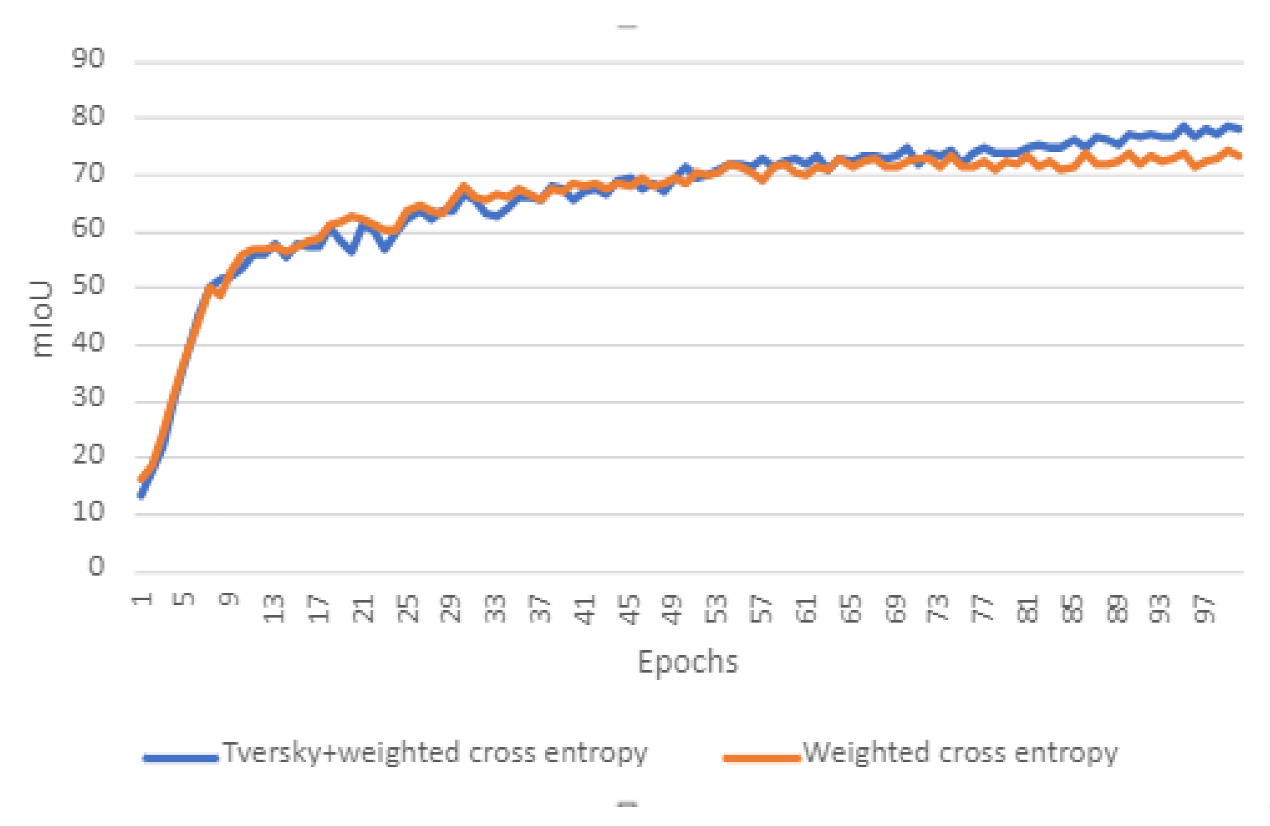
- The study also implements and tests the combination of weighted cross-entropy and the Tversky loss functions, training the network to handle highly imbalanced data.
2. Literature Review
3. Background Knowledge
3.1. Attention Mechanism
3.2. Receptive Field and Spatial Resolution
3.3. Dilated Convolution
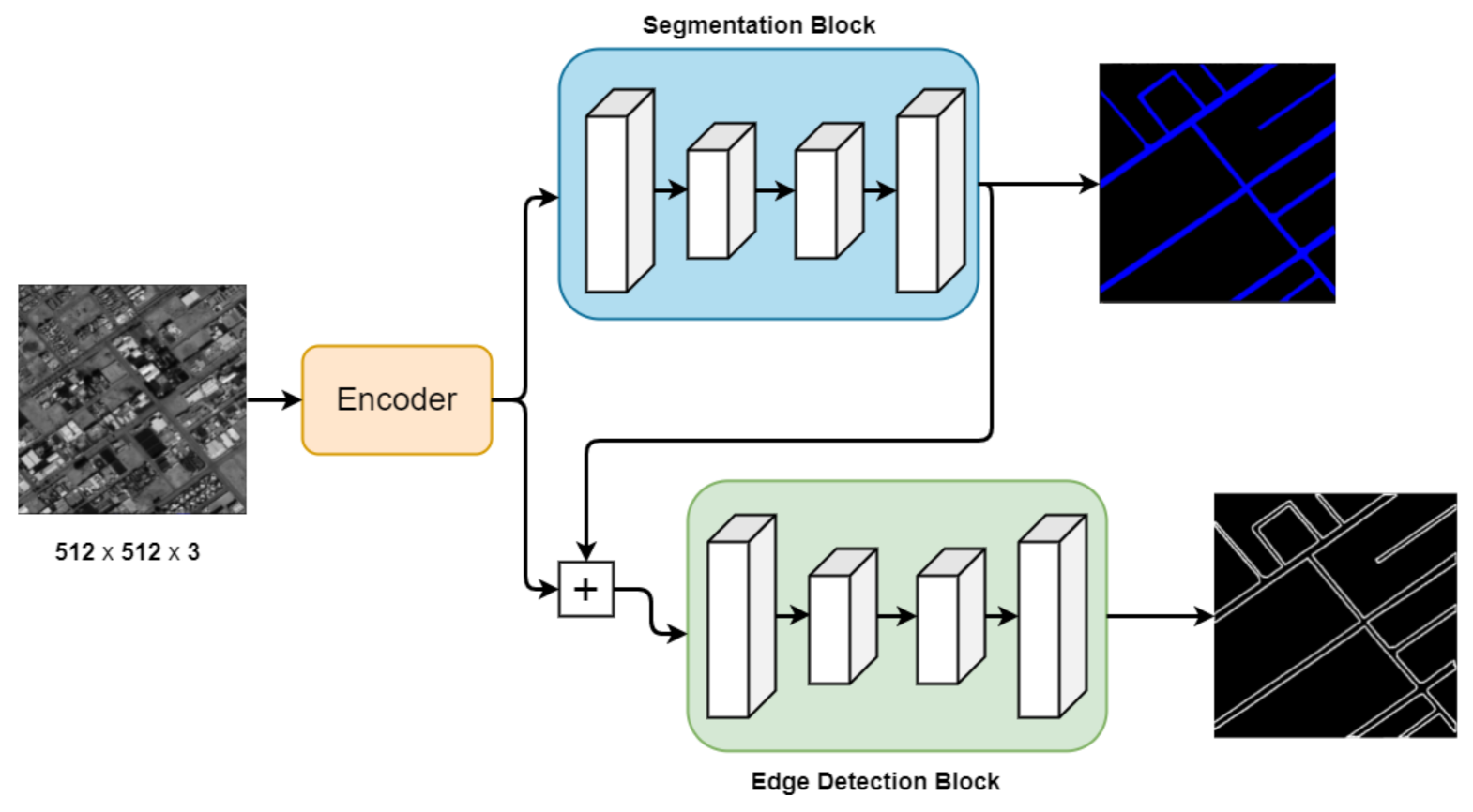
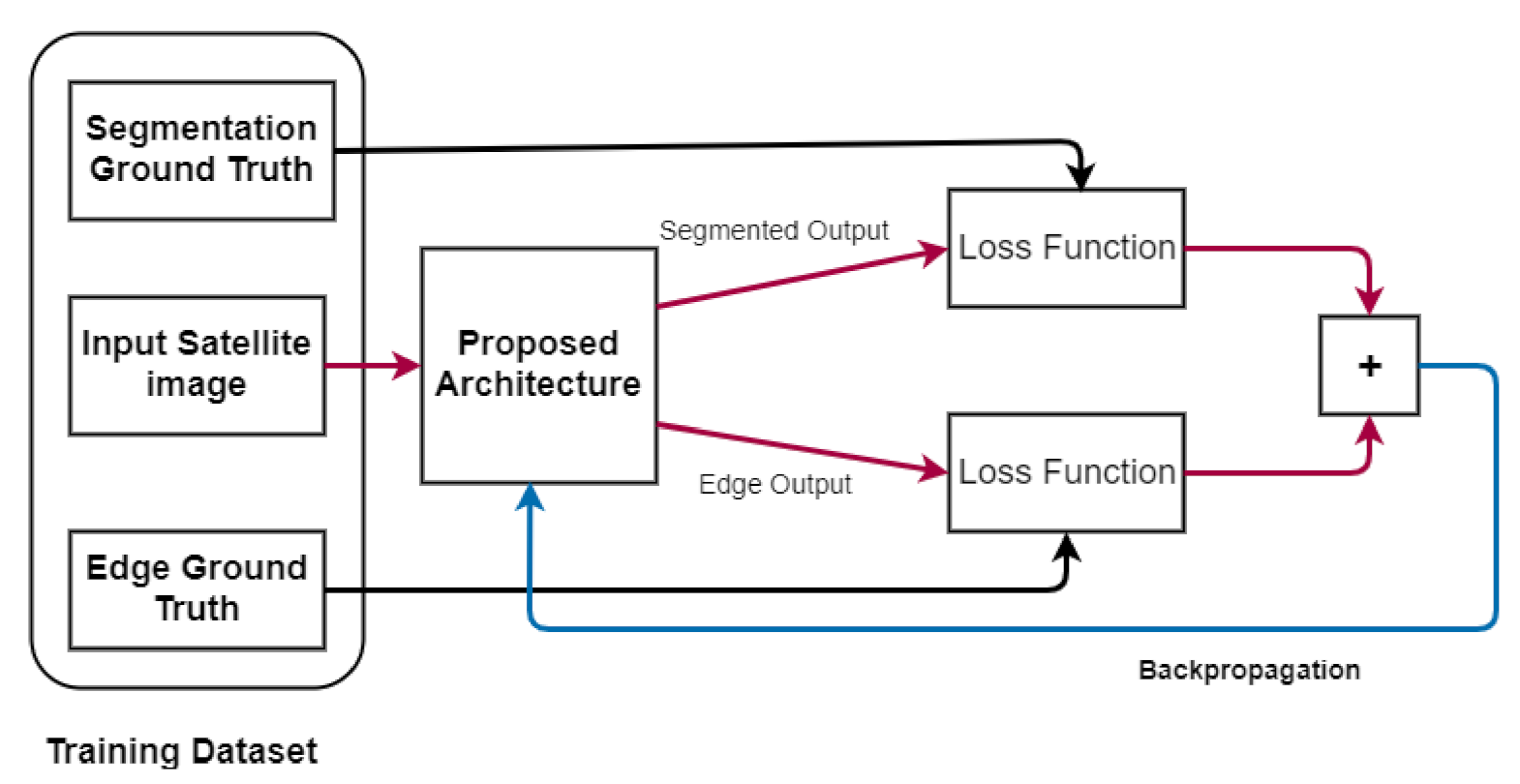
4. Proposed Method
- The encoder encodes the features in full resolution with the help of attention maps.
- The encoded features are then used to produce segmentation masks.
- The previously generated segmentation masks, along with the encoded features, are then used to predict the road edges.
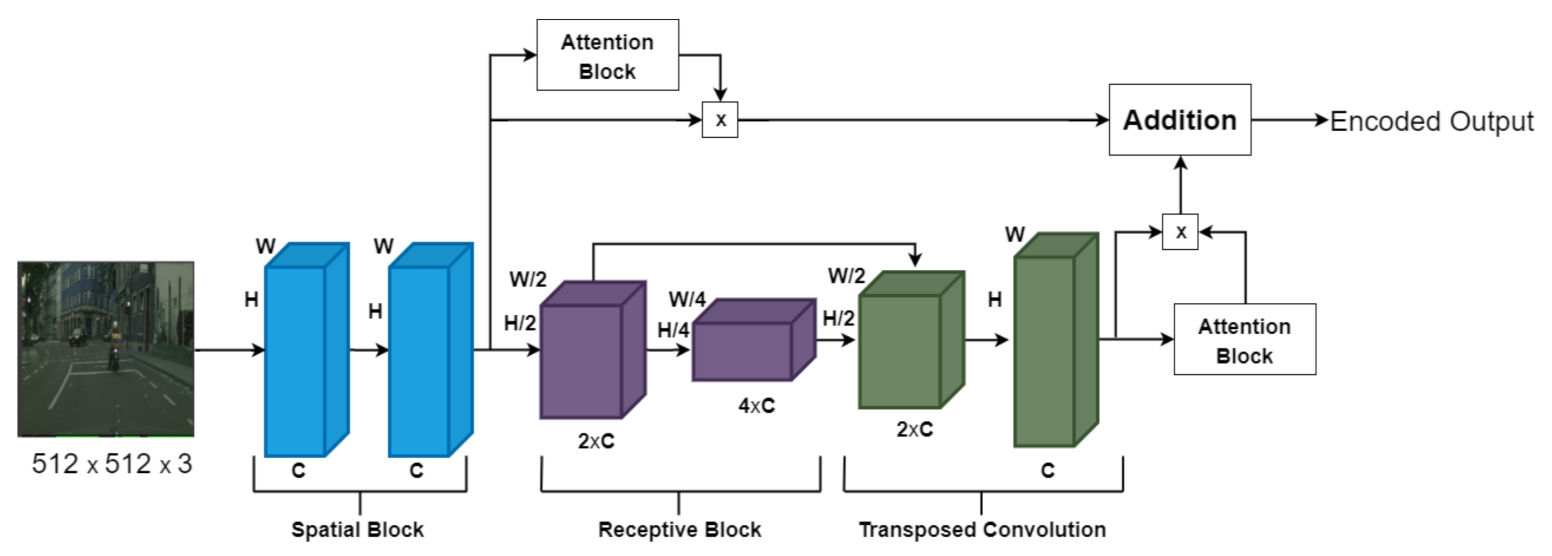
4.1. Encoder
Attention Blocks
4.2. Segmentation and Edge Detection
| Algorithm 1 Algorithm for road segmentation and edge detection |
// x: Input image; rx: Features with reduced channels // S: Segmented output; E: Edge output // Comb: Combined channels Input: Satellite image of size 512 × 512 for x do // RedConv = 2D convolutional layer with a 1x1 kernel end for |
4.3. Loss Function
5. Materials
5.1. Understanding Saudi Arabia’s Land Cover
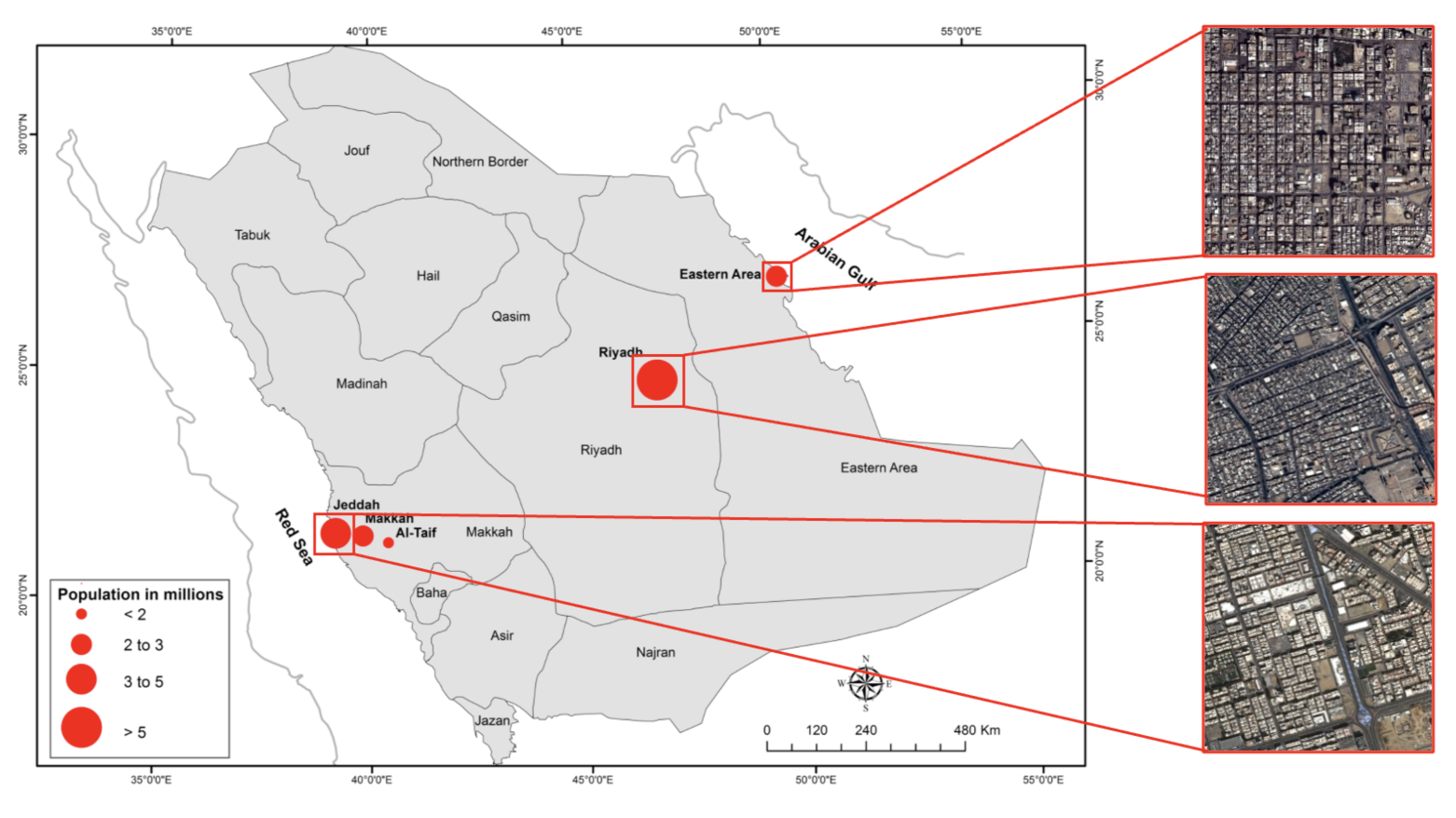
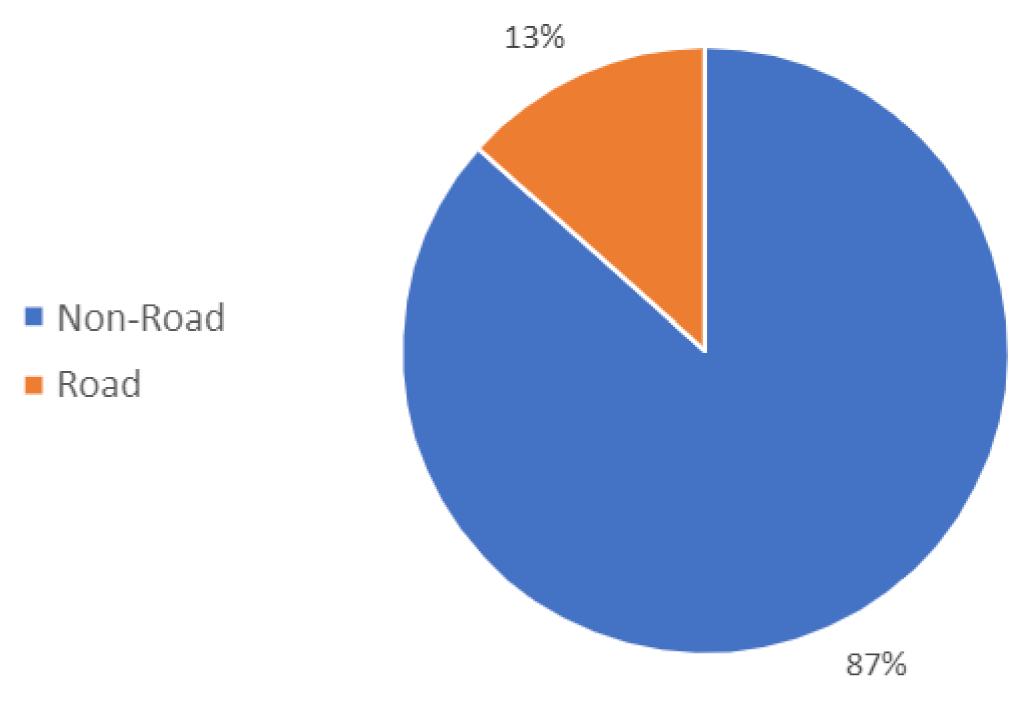
5.2. Study Regions and Dataset Description
- Riyadh, Saudi Arabia’s capital city, has undergone significant change over the years. Riyadh has been identified as one of Saudi Arabia’s fastest-growing cities. The population has increased from 4 million in 2004 to 7 million in 2019. Because of the rate of growth observed in Riyadh, the city is now recognized as one of the fastest-growing in the world by population [46]. Riyadh is located at GPS coordinates of 24°4627.3540 N and 46°4418.9096 E. Since 1932, the size of what is now known as municipal Riyadh has more than doubled 1000 times, and the population has more than doubled 200 times [46,47]. Aside from traffic issues and pollution, there is a significant social cost associated with the high number of car accidents, which result in one of the world’s highest rates of death and casualties. The city’s over-reliance on automobiles, combined with a lack of effective street policies aimed at improving walkability, has contributed to a drop in the livability and sustainability scales in Riyadh [47].
- Jeddah, Saudi Arabia’s second largest city, has experienced rapid urbanization over the last four decades. Jeddah is located at GPS coordinates of 21°3235.9988 N and 39°1022.0044 E. Jeddah’s population increased rapidly, from nearly 148,000 in 1964 to nearly 3.4 million in 2010, while its urban area increased dramatically, from nearly 18,300 hectares in 1964 to nearly 54,000 hectares in 2007. Furthermore, transportation infrastructure expanded rapidly, from 101 km in 1964 to 826 km in 2007. It has been discovered that approximately 50% of the Jeddah population has limited or no access to the current public transportation system; daily travel behaviors changed, and the daily share of car trips has increased. The proportion of daily car trips increased from 50% in 1970 to 96% in 2012. Jeddah is characterized by deficiency and poor condition of the infrastructure, including buses. High-need districts are concentrated and clustered in the city center, whereas single districts are dispersed to the north of the city center [48].
- Dammam began with a land area of less than 0.7 km in 1947 and grew to 15 km by the 1970s. Its population was estimated to be around 1350 people in 1935 and had grown to 43,000 by 1970, representing a 95.5 percent growth rate during this time period. Between 1950 and 2000, Dammam was one of the world’s fastest-growing cities. Dammam has now expanded to over 800 km and has a population of over 1 million people, making it the fifth largest Saudi city in terms of population size. Dammam is situated on a sandy beach with GPS coordinates of 26°263.91 N and 50°0611.74 E. Dammam differs greatly from other cities in that it was built almost entirely from the ground up following the discovery of oil. Its urban environment was designed from the beginning with modernist architecture and planning principles in mind, in tandem with rapid advancements in transportation [44].
5.3. Implementation Details
| Algorithm 2 Algorithm for forward propagation |
// B: Batch size; C: Channel number // H: Height; W: width // x: Input sample // img: Input image //Sgt: Segmentation groundtruth; Egt: Edge groundtruth Input: The entire dataset was first divided into batches in such a way that each sample contained satellite images of shape [B, C, H, W] Training: for x do // Setting the gradients to zero. optimizer.zero_grad loss.backward() //updating weights optimizer.step() end for |
6. Results
6.1. Data Augmentation
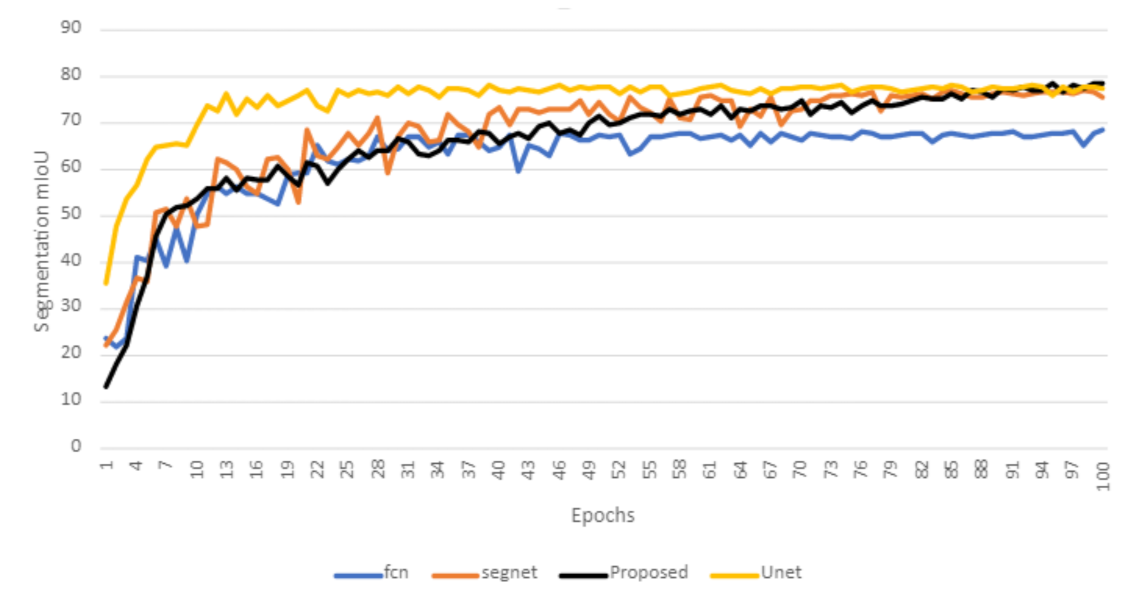
6.2. Training the Proposed Model
6.3. Ablation Study
6.4. Evaluation of the Proposed Approach
6.5. Massachusetts Dataset
7. Discussion
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Boulila, W.; Farah, I.R.; Saheb Ettabaa, K.; Solaiman, B.; Ben Ghézala, H. Spatio-Temporal Modeling for Knowledge Discovery in Satellite Image Databases. In Proceedings of the CORIA, Sousse, Tunisia, 18–20 March 2010; pp. 35–49. [Google Scholar]
- Boulila, W. A Top-Down Approach for Semantic Segmentation of Big Remote Sensing Images. Earth Sci. Inform. 2019, 12, 295–306. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Munich, Germany, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. 2015, pp. 3431–3440. Available online: https://www.computer.org/csdl/proceedings-article/cvpr/2015/07298965/12OmNy49sME (accessed on 19 September 2021). [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:cs.CV/1706.05587. [Google Scholar]
- Li, R.; Zheng, S.; Duan, C.; Zhang, C.; Su, J.; Atkinson, P.M. Multi-Attention-Network for Semantic Segmentation of Fine Resolution Remote Sensing Images. arXiv 2020, arXiv:eess.IV/2009.02130. [Google Scholar]
- Heidler, K.; Mou, L.; Baumhoer, C.; Dietz, A.; Zhu, X.X. HED-UNet: Combined Segmentation and Edge Detection for Monitoring the Antarctic Coastline. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Tao, A.; Sapra, K.; Catanzaro, B. Hierarchical Multi-Scale Attention for Semantic Segmentation. arXiv 2020, arXiv:cs.CV/2005.10821. [Google Scholar]
- Salehi, S.S.; Erdogmus, D.; Gholipour, A. Tversky Loss Function for Image Segmentation Using 3D Fully Convolutional Deep Networks. In International Workshop on Machine Learning in Medical Imaging; Springer: Cham, Germany, 2017; pp. 379–387. [Google Scholar] [CrossRef] [Green Version]
- Cira, C.I.; Alcarria, R.; Manso-Callejo, M.Á.; Serradilla, F. A deep learning-based solution for large-scale extraction of the secondary road network from high-resolution aerial orthoimagery. Appl. Sci. 2020, 10, 7272. [Google Scholar] [CrossRef]
- Wan, J.; Xie, Z.; Xu, Y.; Chen, S.; Qiu, Q. DA-RoadNet: A Dual-Attention Network for Road Extraction from High Resolution Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6302–6315. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep Learning Approaches Applied to Remote Sensing Datasets for Road Extraction: A State-Of-The-Art Review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 17–19 June 2017; pp. 6230–6239. [Google Scholar] [CrossRef] [Green Version]
- Henry, C.; Azimi, S.M.; Merkle, N. Road segmentation in SAR satellite images with deep fully convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1867–1871. [Google Scholar] [CrossRef] [Green Version]
- Xin, J.; Zhang, X.; Zhang, Z.; Fang, W. Road extraction of high-resolution remote sensing images derived from DenseUNet. Remote Sens. 2019, 11, 2499. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Zhang, Z.; Zhong, R.; Zhang, L.; Ma, H.; Liu, L. A dense feature pyramid network-based deep learning model for road marking instance segmentation using MLS point clouds. IEEE Trans. Geosci. Remote Sens. 2020, 59, 784–800. [Google Scholar] [CrossRef]
- Emara, T.; Munim, H.E.A.E.; Abbas, H.M. LiteSeg: A Novel Lightweight ConvNet for Semantic Segmentation. In 2019 Digital Image Computing: Techniques and Applications (DICTA). 2019. Available online: https://ieeexplore.ieee.org/abstract/document/8945975 (accessed on 19 September 2021). [CrossRef] [Green Version]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Aich, S.; van der Kamp, W.; Stavness, I. Semantic Binary Segmentation Using Convolutional Networks without Decoders. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Sovetkin, E.; Achterberg, E.J.; Weber, T.; Pieters, B.E. Encoder–Decoder Semantic Segmentation Models for Electroluminescence Images of Thin-Film Photovoltaic Modules. IEEE J. Photovolt. 2021, 11, 444–452. [Google Scholar] [CrossRef]
- Hamaguchi, R.; Fujita, A.; Nemoto, K.; Imaizumi, T.; Hikosaka, S. Effective Use of Dilated Convolutions for Segmenting Small Object Instances in Remote Sensing Imagery. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1442–1450. [Google Scholar] [CrossRef] [Green Version]
- Boulila, W.; Ghandorh, H.; Khan, M.A.; Ahmed, F.; Ahmad, J. A Novel CNN-LSTM-based Approach to Predict Urban Expansion. Ecol. Inform. 2021, 64, 101325. [Google Scholar] [CrossRef]
- Boulila, W.; Mokhtar, S.; Driss, M.; Al-Sarem, M.; Safaei, M.; Ghaleb, F. RS-DCNN: A Novel Distributed Convolutional Neural Networks based-approach for Big Remote-Sensing Image Classification. Comput. Electron. Agric. 2021, 182, 106014. [Google Scholar] [CrossRef]
- Alkhelaiwi, M.; Boulila, W.; Ahmad, J.; Koubaa, A.; Driss, M. An Efficient Approach Based on Privacy-Preserving Deep Learning for Satellite Image Classification. Remote Sens. 2021, 13, 2221. [Google Scholar] [CrossRef]
- Shao, Z.; Zhou, Z.; Huang, X.; Zhang, Y. MRENet: Simultaneous Extraction of Road Surface and Road Centerline in Complex Urban Scenes from Very High-Resolution Images. Remote Sens. 2021, 13, 239. [Google Scholar] [CrossRef]
- Brewer, E.; Lin, J.; Kemper, P.; Hennin, J.; Runfola, D. Predicting road quality using high resolution satellite imagery: A transfer learning approach. PLoS ONE 2021, 16, e0253370. [Google Scholar] [CrossRef]
- Zhang, J.; Wei, F.; Feng, F.; Wang, C. Spatial–Spectral Feature Refinement for Hyperspectral Image Classification Based on Attention-Dense 3D-2D-CNN. Sensors 2020, 20, 5191. [Google Scholar] [CrossRef]
- He, C.; Li, S.; Xiong, D.; Fang, P.; Liao, M. Remote Sensing Image Semantic Segmentation Based on Edge Information Guidance. Remote Sens. 2020, 12, 1501. [Google Scholar] [CrossRef]
- Xie, S.; Tu, Z. Holistically-Nested Edge Detection. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar] [CrossRef] [Green Version]
- Zhaoa, Z.; Wang, Y.; Liu, K.; Yang, H.; Sun, Q.; Qiao, H. Semantic Segmentation by Improved Generative Adversarial Networks. arXiv 2021, arXiv:2104.09917. [Google Scholar]
- Cira, C.I.; Manso-Callejo, M.Á.; Alcarria, R.; Fernández Pareja, T.; Bordel Sánchez, B.; Serradilla, F. Generative Learning for Postprocessing Semantic Segmentation Predictions: A Lightweight Conditional Generative Adversarial Network Based on Pix2pix to Improve the Extraction of Road Surface Areas. Land 2021, 10, 79. [Google Scholar] [CrossRef]
- Shamsolmoali, P.; Zareapoor, M.; Zhou, H.; Wang, R.; Yang, J. Road Segmentation for Remote Sensing Images Using Adversarial Spatial Pyramid Networks. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4673–4688. [Google Scholar] [CrossRef]
- Liu, X.; Milanova, M. Visual attention in deep learning: A review. Int. Rob. Auto. J. 2018, 4, 154–155. [Google Scholar]
- Li, X.; Zhang, W.; Ding, Q. Understanding and improving deep learning-based rolling bearing fault diagnosis with attention mechanism. Signal Process. 2019, 161, 136–154. [Google Scholar] [CrossRef]
- Chen, Y.; Peng, G.; Zhu, Z.; Li, S. A novel deep learning method based on attention mechanism for bearing remaining useful life prediction. Appl. Soft Comput. 2020, 86, 105919. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the Effective Receptive Field in Deep Convolutional Neural Networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4905–4913. [Google Scholar]
- Liu, Y.; Yu, J.; Han, Y. Understanding the Effective Receptive Field in Semantic Image Segmentation. Multimed. Tools Appl. 2018, 77, 22159–22171. [Google Scholar] [CrossRef]
- Chen, X.; Li, Z.; Jiang, J.; Han, Z.; Deng, S.; Li, Z.; Fang, T.; Huo, H.; Li, Q.; Liu, M. Adaptive Effective Receptive Field Convolution for Semantic Segmentation of VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 3532–3546. [Google Scholar] [CrossRef]
- Liu, R.; Cai, W.; Li, G.; Ning, X.; Jiang, Y. Hybrid Dilated Convolution Guided Feature Filtering and Enhancement Strategy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, P.; Song, F.; Fan, G.; Sun, Y.; Wang, Y.; Tian, Z.; Zhang, L.; Zhang, G. D2A U-Net: Automatic Segmentation of COVID-19 CT Slices Based on Dual Attention and Hybrid Dilated Convolution. Comput. Biol. Med. 2021, 135, 104526. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.b.; Xuan, Y.; Lin, A.j.; Guo, S.h. Lung Computed Tomography Image Segmentation based on U-Net Network Fused with Dilated Convolution. Comput. Methods Programs Biomed. 2021, 207, 106170. [Google Scholar] [CrossRef] [PubMed]
- Alabdullah, M.M. Reclaiming Urban Streets for Walking in a Hot and Humid Region: The Case of Dammam City, the Kingdom of Saudi Arabia. Ph.D. Thesis, University of Edinburgh, Edinburgh, UK, 2017. [Google Scholar]
- Susilawati, C.; Surf, M.A. Challenges facing sustainable housing in Saudi Arabia: A current study showing the level of public awareness. In Proceedings of the 17th Annual Pacific Rim Real Estate Society Conference, Gold Coast, Australia, 16–19 January 2011; pp. 1–12. Available online: http://www.prres.net/ (accessed on 19 September 2021).
- Alghamdi, A.; Cummings, A.R. Assessing riyadh’s urban change utilizing high-resolution imagery. Land 2019, 8, 193. [Google Scholar] [CrossRef] [Green Version]
- Al-Mosaind, M. Applying complete streets concept in Riyadh, Saudi Arabia: Opportunities and challenges. Urban Plan. Transp. Res. 2018, 6, 129–147. [Google Scholar] [CrossRef] [Green Version]
- Aljoufie, M. Spatial analysis of the potential demand for public transport in the city of Jeddah, Saudi Arabia. WIT Trans. Built Environ. 2014, 138, 113–123. [Google Scholar]
- Xu, Y.; Xie, Z.; Feng, Y.; Chen, Z. Road Extraction from High-Resolution Remote Sensing Imagery Using Deep Learning. Remote Sens. 2018, 10, 1461. [Google Scholar] [CrossRef] [Green Version]
- Abdollahi, A.; Pradhan, B.; Alamri, A. VNet: An End-to-End Fully Convolutional Neural Network for Road Extraction From High-Resolution Remote Sensing Data. IEEE Access 2020, 8, 179424–179436. [Google Scholar] [CrossRef]
- Lian, R.; Wang, W.; Mustafa, N.; Huang, L. Road Extraction Methods in High-Resolution Remote Sensing Images: A Comprehensive Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5489–5507. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | DL Method | Main Steps | Findings |
|---|---|---|---|
| Henry et al. [15] | Fully Convolutional Neural Networks (FCNNs) | Segmentation with FCNNs Adjusting the FCNNs for road segmentation. | (1) FCNNs are an effective method to extract roads from SAR images. (2) Adding a tolerance rule to FCNNs can handle mistakes spatially and enhance road extraction. |
| Xin et al. [16] | DenseUNet | (1) Encoder–Decoder. (2) Backpropagation to Train Multilayer Architectures. (3) DenseUNet. | (1) Combination of dense connection mode and U-Net to solve the problem of tree and shadow occlusion. (2) Use of weighted loss function to emphasize foreground pixels. (3) Dense and skip connection help transfer information and accelerate computation. |
| Chen et al. [17] | Dense Feature Pyramid Network (DFPN) | (1) Data Preprocessing. (2) DFPN-Based Deep Learning Model. (3) Constructions of Feature Extraction Framework. (4) Establishments of FPN, and DFPN. (5) Generation of Object Proposals. (6) Road Marking Instance Segmentation. | (1) Introduction of the focal loss function in the calculation of mask loss to pay more attention to the hard-classified samples with less-pixel foreground. (2) Combining the “MaskIoU” method into optimizing the segmentation process to improve the accuracy of instance segmentation of road markings. |
| Brewer et al. [27] | Transfer learning models: ResNet50, ResNet152V2, Inceptionv3, VGG16, DenseNet201, InceptionResNetV2, and Xception. | (1) Collect data from the cabin of vehicles. (2) Categorize data into groups: high, mid, and low quality. (3) Label data. (4) Classify road segments using transfer learning models. (5) Test the networks on a subset of the Virginia dataset used for training. (6) Test the transfer learning model with Nigerian roads not used in training. | (1) Capture of variance in road quality across multiple geographies exploration of different DL approaches in a wider range of geographic contexts. (2) Need for more tailored approaches for satellite imagery analysis. (3) Fuzzy-class membership for object qualification using satellite data and CNNs. (4) Continuous estimation of road quality from satellite imagery. (5) Use of a phone app combined with ML for road quality prediction. |
| Heidler et al. [8] | HED-UNet | (1) Computation of pyramid feature maps using Encoder. (2) Combination of feature maps by the task-specific merging heads using the hierarchical attention mechanism. | (1) Uses hierarchical attention maps to merge predictions from multiple scales. (2) Exploitation of the synergies between the two tasks to surpass both edge detection and semantic segmentation baselines. |
| Shao et al. [26] | CNN termed multitask road-related extraction network (MRENet) | (1) ResBlock operates according to two steps: extraction of image features using convolution operation and enlarging the receptive field using pooling operation. (2) Pyramid scene parsing (PSP) integrates multilevel features. (3) Multitask learning. | (1) Two-task and end-to-end CNN to bridge the extraction of both road surface and road centerlines by enabling feature transferring. (2) Use of a Resblock and a PSP pooling module to expand the receptive field and integrate multilevel features and to acquire much information. |
| Parameters | Value |
|---|---|
| 0.7 | |
| 0.3 | |
| 4/3 | |
| Tversky weight | 0.2 |
| Cross-entropy weight | 0.8 |
| Parameters | Value |
|---|---|
| 0.5 | |
| 0.5 | |
| 4/3 | |
| Tversky weight | 0.5 |
| Cross-entropy weight | 0.5 |
| Network | Size | Learnable Parameters | mIoU | Dice Score |
|---|---|---|---|---|
| Proposed Network | 23 Mb | 2.93 M | 78.3 | 87.47 |
| UNet | 118.5 Mb | 31.04 M | 77.34 | 87.97 |
| SegNet | 28.2 Mb | 7.37 M | 75.44 | 85.23 |
| FCN | 71.1 Mb | 18.65 M | 68.53 | 79.83 |
| Network | Size | Learnable Parameters | mIoU | Dice Score |
|---|---|---|---|---|
| Proposed Network | 23 Mb | 2.98 M | 80.71 | 89.82 |
| UNet | 118.5 Mb | 31.04 M | 80.32 | 90.25 |
| SegNet | 28.2 Mb | 7.37 M | 77.74 | 88.49 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghandorh, H.; Boulila, W.; Masood, S.; Koubaa, A.; Ahmed, F.; Ahmad, J. Semantic Segmentation and Edge Detection—Approach to Road Detection in Very High Resolution Satellite Images. Remote Sens. 2022, 14, 613. https://doi.org/10.3390/rs14030613
Ghandorh H, Boulila W, Masood S, Koubaa A, Ahmed F, Ahmad J. Semantic Segmentation and Edge Detection—Approach to Road Detection in Very High Resolution Satellite Images. Remote Sensing. 2022; 14(3):613. https://doi.org/10.3390/rs14030613
Chicago/Turabian StyleGhandorh, Hamza, Wadii Boulila, Sharjeel Masood, Anis Koubaa, Fawad Ahmed, and Jawad Ahmad. 2022. "Semantic Segmentation and Edge Detection—Approach to Road Detection in Very High Resolution Satellite Images" Remote Sensing 14, no. 3: 613. https://doi.org/10.3390/rs14030613
APA StyleGhandorh, H., Boulila, W., Masood, S., Koubaa, A., Ahmed, F., & Ahmad, J. (2022). Semantic Segmentation and Edge Detection—Approach to Road Detection in Very High Resolution Satellite Images. Remote Sensing, 14(3), 613. https://doi.org/10.3390/rs14030613