
NaGAN: Nadir-like Generative Adversarial Network for Off-Nadir Object Detection of Multi-View Remote Sensing Imagery

 , ,
, ,
Abstract
:1. Introduction
- (1)
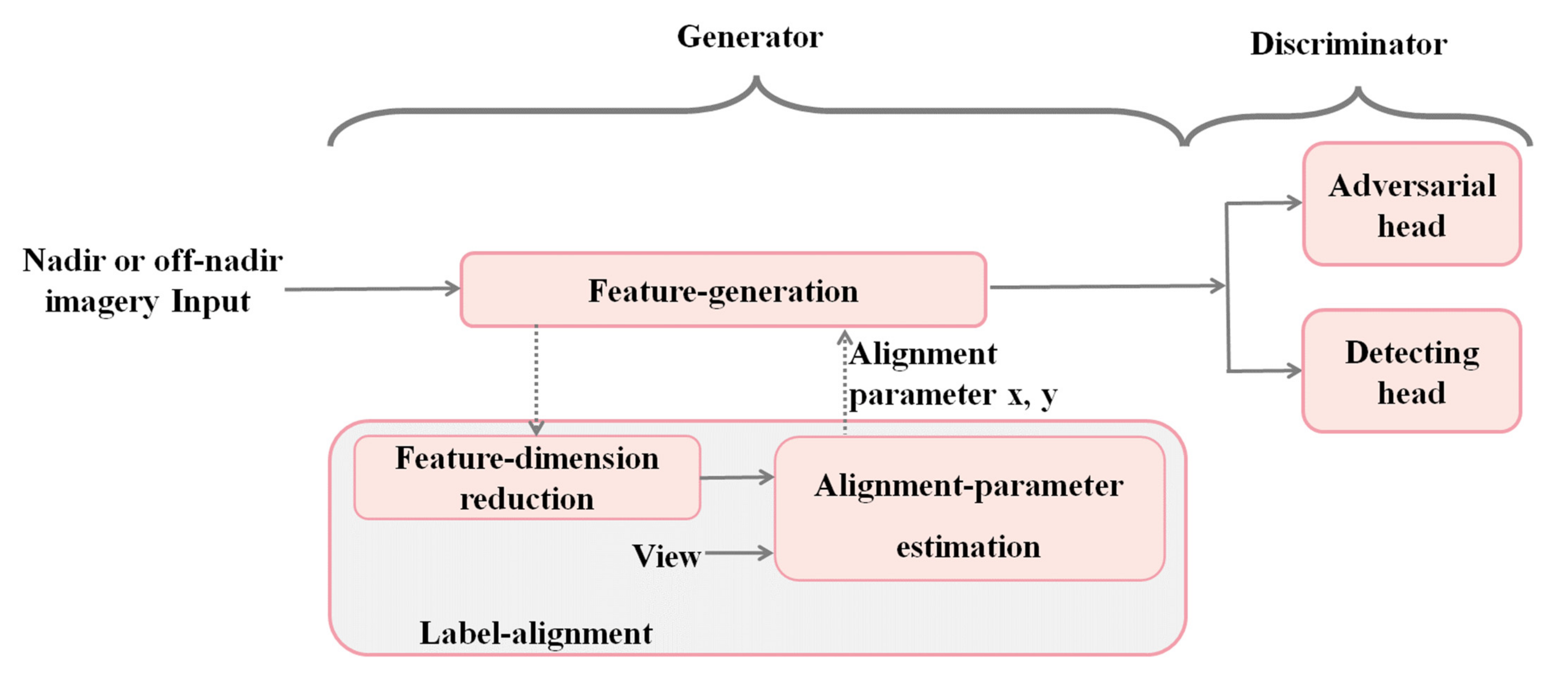
- A nadir-like representation is generated for the off-nadir object by the generator, and the intra-class similarity between the nadir-like representation and nadir feature is improved by the discriminator to “supervise” the generation process.
- (2)
- The generator consists of the feature generation and the label alignment. The feature-generation aims to generate the nadir-like representation for the off-nadir object. The label alignment aims to assist the feature generation, which aligns the feature map of the off-nadir object and aims to pertinently generate a nadir-like representation.
- (3)
- The discriminator consists of the adversarial head and the detecting head. The former aims to distinguish the nadir object and the off-nadir object, and the latter aims to accomplish the object detection task. Specifically, the discriminator is the multi-task collaborative learning between feature discrimination and object detection, rather than the single discrimination between the real nadir object and the generated one.
2. Related Work
2.1. Viewpoint-Invariant Object Detection by Image Matching
2.1.1. Feature Descriptor
2.1.2. Feature Matching
2.1.3. Feature Learning
2.2. Data Augmentation and Generation
3. The Proposed Approach
3.1. Overview of NaGAN
3.2. Modeling and Loss Function
3.2.1. Generator Modeling
3.2.2. Modeling and Loss Function of Discriminator
3.3. Network Architecture and Loss Design
4. Experiments
4.1. Experiments Setting
4.2. Implementation Details
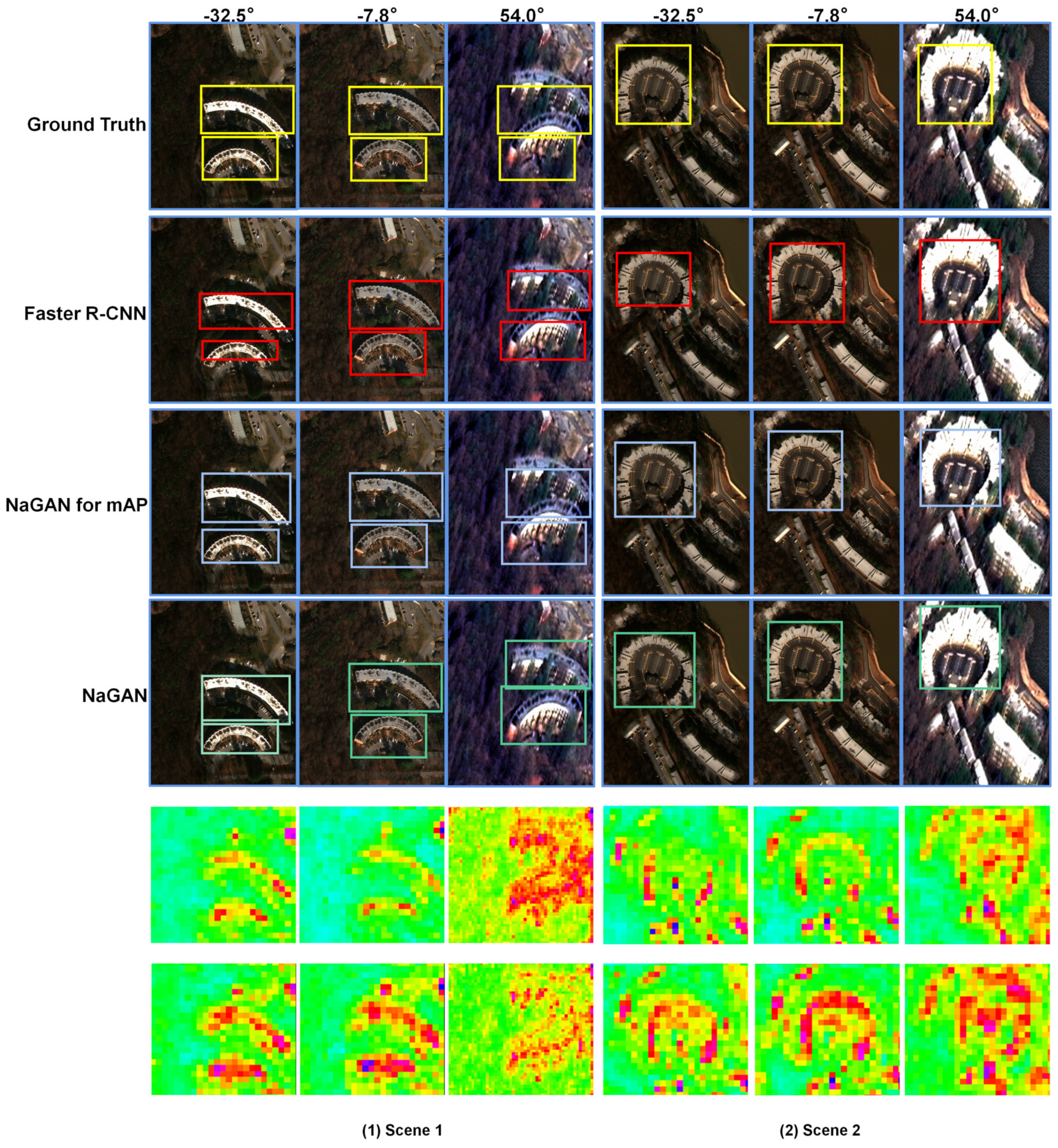
4.3. Performance Analysis

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model\View | −32.5° | −29.1° | −25.4° | −21.3° | −16.9° | −13.9° | −10.5° | −7.8° | 8.3° | 10.6° |
|---|---|---|---|---|---|---|---|---|---|---|
| Faster_r50 [30] | 52.1 | 55.6 | 58.5 | 62.3 | 63.4 | 65.7 | 66.1 | 67.3 | 67.3 | 67.2 |
| Faster_r101 [30] | 41.4 | 49.6 | 54.8 | 59.3 | 61.1 | 63.8 | 65.2 | 66.6 | 66.5 | 66.3 |
| Cascade_r50 [34] | 24.5 | 33.9 | 41.7 | 46.7 | 47.8 | 52.9 | 54.2 | 59.7 | 60.7 | 59.7 |
| Cascade_r101 [34] | 26.0 | 35.6 | 46.8 | 52.6 | 56.0 | 59.1 | 59.8 | 61.7 | 60.0 | 63.0 |
| Cascade_x101 [34] | 40.2 | 47.9 | 54.2 | 57.6 | 60.5 | 61.8 | 63.2 | 64.3 | 64.4 | 63.3 |
| CornerNet [35] | 7.3 | 18.8 | 26.1 | 26.8 | 29.6 | 31.3 | 32.3 | 33.1 | 32.8 | 32.8 |
| Fovea_r50 [36] | 19.6 | 38.1 | 44.7 | 50.1 | 53.0 | 58.0 | 59.5 | 61.2 | 61.8 | 61.1 |
| Fovea_r101 [36] | 19.6 | 42.8 | 47.9 | 52.5 | 54.1 | 58.0 | 60.1 | 60.8 | 61.8 | 61.5 |
| RetinaNet [37] | 37.8 | 46.7 | 51.3 | 55.8 | 58.1 | 60.9 | 62.4 | 63.4 | 64.4 | 63.4 |
| Htc [38] | 32.6 | 44.9 | 51.1 | 56.3 | 59.4 | 63.2 | 64.5 | 65.8 | 65.9 | 65.6 |
| Libra rcnn [39] | 25.9 | 35.6 | 47.9 | 55.7 | 60.3 | 62.3 | 63.8 | 65.0 | 65.9 | 65.3 |
| Nas_fpn [40] | 13.3 | 29.5 | 47.9 | 53.1 | 57.2 | 58.8 | 60.3 | 61.3 | 61.7 | 61.2 |
| Centripetal [41] | 5.5 | 20.7 | 47.4 | 55.3 | 58.5 | 63.3 | 64.7 | 66.1 | 66.2 | 67.0 |
| NaGAN | 54.0 | 57.2 | 59.8 | 63.0 | 64.1 | 66.1 | 66.2 | 67.3 | 67.4 | 67.3 |
| Model\View | 14.8° | 19.3° | 23.5° | 27.4° | 31.0° | 34.0° | 37.0° | 39.6° | 42.0° | 44.2° |
| Faster_r50 | 66.9 | 65.5 | 64.4 | 62.0 | 59.0 | 57.7 | 56.0 | 51.8 | 49.1 | 39.8 |
| Faster_r101 | 66.3 | 64.7 | 63.5 | 61.1 | 57.9 | 54.6 | 50.8 | 44.6 | 43.5 | 34.1 |
| Cascade_r50 | 59.6 | 58.2 | 52.4 | 54.5 | 44.0 | 39.4 | 52.5 | 33.5 | 27.0 | 18.5 |
| Cascade_r101 | 57.8 | 56.6 | 57.8 | 53.1 | 51.2 | 50.3 | 53.6 | 35.1 | 34.3 | 28.3 |
| Cascade_x101 | 64.2 | 63.0 | 52.4 | 59.2 | 55.5 | 55.5 | 52.7 | 48.4 | 45.3 | 34.4 |
| CornerNet | 32.8 | 31.9 | 31.7 | 31.0 | 29.7 | 28.1 | 25.6 | 21.4 | 21.6 | 19.8 |
| Fovea_r50 | 61.0 | 59.3 | 57.9 | 55.3 | 50.9 | 49.8 | 48.2 | 43.6 | 40.5 | 30.1 |
| Fovea_r101 | 61.9 | 59.6 | 59.4 | 57.3 | 53.6 | 51.4 | 48.9 | 44.0 | 43.4 | 34.3 |
| RetinaNet_r50 | 63.6 | 62.0 | 61.0 | 58.5 | 55.3 | 53.9 | 51.5 | 47.1 | 46.1 | 34.4 |
| Htc | 65.8 | 64.2 | 62.9 | 60.3 | 55.6 | 55.5 | 52.8 | 48.3 | 45.6 | 35.1 |
| Libra rcnn | 64.2 | 63.3 | 60.8 | 58.5 | 53.6 | 48.8 | 42.1 | 31.9 | 28.9 | 20.4 |
| Nas_fpn | 61.4 | 60.8 | 59.6 | 57.2 | 54.3 | 53.5 | 50.8 | 47.0 | 44.9 | 31.3 |
| Centripetal | 65.8 | 63.3 | 62.5 | 59.8 | 56.8 | 55.8 | 52.5 | 44.3 | 44.3 | 41.6 |
| NaGAN | 67.2 | 65.8 | 64.8 | 62.5 | 59.6 | 58.4 | 56.7 | 52.6 | 50.0 | 40.8 |
| Model\View | 46.1° | 47.8° | 49.3° | 50.9° | 52.2° | 53.4° | 54.0° | ALL | NADIR | OFF |
| Faster_r50 | 36.9 | 40.9 | 37.2 | 26.9 | 26.7 | 11.4 | 7.5 | 52.7 | 64.7 | 43.7 |
| Faster_r101 | 27.5 | 33.2 | 28.4 | 20.6 | 19.8 | 7.0 | 2.1 | 48.0 | 63.6 | 35.4 |
| Cascade_r50 | 13.5 | 15.8 | 12.2 | 9.4 | 10.0 | 2.6 | 5.7 | 29.9 | 51.4 | 26.1 |
| Cascade_r101 | 15.0 | 15.8 | 19.5 | 10.6 | 8.5 | 3.3 | 6.9 | 31.3 | 59.1 | 20.9 |
| Cascade_x101 | 27.1 | 33.7 | 30.3 | 23.8 | 23.0 | 12.7 | 6.4 | 48.8 | 61.7 | 38.4 |
| CornerNet | 17.5 | 17.8 | 15.6 | 9.6 | 10.7 | 3.4 | 1.0 | 23.4 | 31.0 | 17.8 |
| Fovea_r50 | 21.4 | 27.4 | 25.7 | 20.4 | 17.5 | 8.2 | 2.1 | 43.0 | 57.1 | 32.0 |
| Fovea_r101 | 26.7 | 32.9 | 29.6 | 20.4 | 21.3 | 11.4 | 4.3 | 45.2 | 58.0 | 35.5 |
| RetinaNet_r50 | 26.8 | 35.2 | 31.9 | 22.9 | 22.9 | 12.5 | 6.1 | 47.8 | 60.7 | 37.8 |
| Htc | 26.5 | 32.0 | 29.1 | 22.3 | 20.5 | 11.2 | 3.5 | 48.2 | 62.1 | 36.9 |
| Libra rcnn | 15.9 | 17.4 | 16.3 | 13.1 | 9.5 | 2.2 | 0.8 | 39.0 | 61.7 | 23.2 |
| Nas_fpn | 21.9 | 32.4 | 31.1 | 18.9 | 17.5 | 3.4 | 1.1 | 43.0 | 58.6 | 31.4 |
| Centripetal | 34.0 | 32.0 | 28.7 | 18.2 | 19.2 | 4.4 | 1.2 | 45.5 | 62.1 | 32.8 |
| NaGAN | 38.1 | 42.3 | 38.7 | 28.5 | 28.4 | 13.2 | 9.4 | 54.1 | 65.1 | 45.3 |
4.4. The Effectiveness of the Label Alignment
4.5. Comparison to Image Matching Method
4.6. Ablation Studies
4.6.1. The Variant of Label Alignment
| Model | OFF-NADIR | ALL |
|---|---|---|
| NaGAN w/o LAM(R) | 52.9 | 59.4 |
| NaGAN w/o LAM(P) | 44.7 | 53.6 |
| NaGAN w/o IV(R) | 53.0 | 59.7 |
| NaGAN w/o IV(P) | 45.0 | 53.9 |
| NaGAN w/o DD(R) | 52.9 | 59.7 |
| NaGAN w/o DD(P) | 44.9 | 53.8 |
| NaGAN(R) | 53.2 | 59.8 |
| NaGAN(P) | 45.3 | 54.1 |
4.6.2. Different Layers of Feature Generation Utilized
| Model | OFF-NADIR | ALL |
|---|---|---|
| NaGAN_Conv1(R) | 52.2 | 59.2 |
| NaGAN_Conv1(P) | 44.6 | 53.7 |
| NaGAN_Conv2(R) | 52.7 | 59.6 |
| NaGAN_Conv2(P) | 44.8 | 53.8 |
| NaGAN_Conv3(R) | 53.0 | 59.6 |
| NaGAN_Conv3(P) | 45.1 | 54.0 |
| NaGAN(R) | 53.2 | 59.8 |
| NaGAN(P) | 45.3 | 54.1 |
4.6.3. Different Parameters for Label Alignment
| Model | OFF-NADIR | ALL |
|---|---|---|
| NaGAN_STN_6(R) | 52.6 | 59.5 |
| NaGAN_STN_6(P) | 45.0 | 53.9 |
| NaGAN_LAM_2(R) | 53.2 | 59.8 |
| NaGAN_LAM_2(P) | 45.3 | 54.1 |
4.6.4. The Effectiveness of Adversarial Head
| Model | OFF-NADIR | ALL |
|---|---|---|
| NaGAN_w/o AH(R) | 52.5 | 59.2 |
| NaGAN_w/o AH(P) | 44.7 | 53.6 |
| NaGAN_with AH(R) | 53.2 | 59.8 |
| NaGAN_with AH(P) | 45.3 | 54.1 |
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ehsani, K.; Mottaghi, R.; Farhadi, A. Segan: Segmenting and generating the invisible. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6144–6153. [Google Scholar]
- Liao, K.; Lin, C.; Zhao, Y.; Gabbouj, M. DR-GAN: Automatic Radial Distortion Rectification Using Conditional GAN in Real-Time. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 725–733. [Google Scholar] [CrossRef]
- Turner, D.; Lucieer, A.; Malenovský, Z.; King, D.H.; Robinson, S.A. Spatial Co-Registration of Ultra-High Resolution Visible, Multispectral and Thermal Images Acquired with a Micro-UAV over Antarctic Moss Beds. Remote Sens. 2014, 6, 4003–4024. [Google Scholar] [CrossRef] [Green Version]
- Ng, P.C.; Henikoff, S. SIFT: Predicting amino acid changes that affect protein function. Nucleic Acids Res. 2003, 31, 3812–3814. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Morel, J.-M.; Yu, G. ASIFT: A new framework for fully affine invariant image comparison. SIAM J. Imaging Sci. 2009, 2, 438–469. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up robust features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Ye, Y.; Shan, J.; Bruzzone, L.; Shen, L. Robust Registration of Multimodal Remote Sensing Images Based on Structural Similarity. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2941–2958. [Google Scholar] [CrossRef]
- Ye, Y.; Shen, L.; Hao, M.; Wang, J.; Xu, Z. Robust Optical-to-SAR Image Matching Based on Shape Properties. IEEE Geosci. Remote Sens. Lett. 2017, 14, 564–568. [Google Scholar] [CrossRef]
- Yang, K.; Pan, A.; Yang, Y.; Zhang, S.; Ong, S.H.; Tang, H. Remote Sensing Image Registration Using Multiple Image Features. Remote Sens. 2017, 9, 581. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Nevalainen, P.; Queralta, J.; Heikkonen, J.; Westerlund, T. Localization in Unstructured Environments: Towards Autonomous Robots in Forests with Delaunay Triangulation. Remote Sens. 2020, 12, 1870. [Google Scholar] [CrossRef]
- Dekel, T.; Oron, S.; Rubinstein, M.; Avidan, S.; Freeman, W.T. Best-Buddies Similarity for robust template matching. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2021–2029. [Google Scholar]
- Saurer, O.; Baatz, G.; Köser, K.; Ladický, L.; Pollefeys, M. Image Based Geo-localization in the Alps. Int. J. Comput. Vis. 2016, 116, 213–225. [Google Scholar] [CrossRef]
- Tian, Y.; Chen, C.; Shah, M. Cross-View Image Matching for Geo-Localization in Urban Environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1998–2006. [Google Scholar] [CrossRef] [Green Version]
- Park, J.-H.; Nam, W.-J.; Lee, S.-W. A Two-Stream Symmetric Network with Bidirectional Ensemble for Aerial Image Matching. Remote Sens. 2020, 12, 465. [Google Scholar] [CrossRef] [Green Version]
- Wu, G.; Kim, M.; Wang, Q.; Munsell, B.C.; Shen, D. Scalable High-Performance Image Registration Framework by Unsupervised Deep Feature Representations Learning. IEEE Trans. Biomed. Eng. 2016, 63, 1505–1516. Erratum in IEEE Trans. Biomed. Eng. 2017, 64, 250. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, X.; Leung, T.; Jia, Y.; Sukthankar, R.; Berg, A.C. Matchnet: Unifying feature and metric learning for patch-based matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3279–3286. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Zhang, X.; Liu, Y.; Huo, C.; Xu, N.; Wang, L.; Pan, C. PSNet: Perspective-sensitive convolutional network for object detection. Neurocomputing 2022, 468, 384–395. [Google Scholar] [CrossRef]
- Zhang, X.; Huo, C.; Pan, C. View-Angle Invariant Object Monitoring Without Image Registration. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2283–2287. [Google Scholar]
- Talmi, I.; Mechrez, R.; Zelnik-Manor, L. Template Matching with Deformable Diversity Similarity. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1311–1319. [Google Scholar]
- Liu, L.; Li, H. Lending Orientation to Neural Networks for Cross-View Geo-Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5617–5626. [Google Scholar] [CrossRef] [Green Version]
- Tran, N.-T.; Tran, V.-H.; Nguyen, N.-B.; Nguyen, T.-K.; Cheung, N.-M. On Data Augmentation for GAN Training. IEEE Trans. Image Process. 2021, 30, 1882–1897. [Google Scholar] [CrossRef] [PubMed]
- Antoniou, A.; Storkey, A.; Edwards, H. Augmenting Image Classifiers Using Data Augmentation Generative Adversarial Networks. In Proceedings of the International Conference on Artificial Neural Networks, Bratislava, Slovakia, 15–18 September 2018; pp. 594–603. [Google Scholar] [CrossRef] [Green Version]
- Połap, D.; Woźniak, M. A hybridization of distributed policy and heuristic augmentation for improving federated learning approach. Neural Networks 2022, 146, 130–140. [Google Scholar] [CrossRef] [PubMed]
- Połap, D.; Srivastava, G. Neural image reconstruction using a heuristic validation mechanism. Neural Comput. Appl. 2020, 33, 10787–10797. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 936–944. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weir, N.; Lindenbaum, D.; Bastidas, A.; Etten, A.; Kumar, V.; McPherson, S.; Shermeyer, J.; Tang, H. SpaceNet MVOI: A Multi-View Overhead Imagery Dataset. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 992–1001. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2020, 128, 642–656. [Google Scholar] [CrossRef] [Green Version]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. FoveaBox: Beyound Anchor-Based Object Detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, K.; Ouyang, W.; Loy, C.C.; Lin, D.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; et al. Hybrid Task Cascade for Instance Segmentation. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4974–4983. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20June 2019; pp. 821–830. [Google Scholar]
- Ghiasi, G.; Lin, T.-Y.; Le, Q.V. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7029–7038. [Google Scholar] [CrossRef] [Green Version]
- Dong, Z.; Li, G.; Liao, Y.; Wang, F.; Ren, P.; Qian, C. CentripetalNet: Pursuing High-Quality Keypoint Pairs for Object Detection. In Proceedings of the Ieee/Cvf Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10516–10525. [Google Scholar] [CrossRef]
- ASIFT. Available online: http://www.cmap.polytechnique.fr/~yu/research/ASIFT/demo.html (accessed on 5 November 2021).
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. In Proceedings of the Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2017–2025. [Google Scholar]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ni, L.; Huo, C.; Zhang, X.; Wang, P.; Zhang, L.; Guo, K.; Zhou, Z. NaGAN: Nadir-like Generative Adversarial Network for Off-Nadir Object Detection of Multi-View Remote Sensing Imagery. Remote Sens. 2022, 14, 975. https://doi.org/10.3390/rs14040975
Ni L, Huo C, Zhang X, Wang P, Zhang L, Guo K, Zhou Z. NaGAN: Nadir-like Generative Adversarial Network for Off-Nadir Object Detection of Multi-View Remote Sensing Imagery. Remote Sensing. 2022; 14(4):975. https://doi.org/10.3390/rs14040975
Chicago/Turabian StyleNi, Lei, Chunlei Huo, Xin Zhang, Peng Wang, Luyang Zhang, Kangkang Guo, and Zhixin Zhou. 2022. "NaGAN: Nadir-like Generative Adversarial Network for Off-Nadir Object Detection of Multi-View Remote Sensing Imagery" Remote Sensing 14, no. 4: 975. https://doi.org/10.3390/rs14040975
APA StyleNi, L., Huo, C., Zhang, X., Wang, P., Zhang, L., Guo, K., & Zhou, Z. (2022). NaGAN: Nadir-like Generative Adversarial Network for Off-Nadir Object Detection of Multi-View Remote Sensing Imagery. Remote Sensing, 14(4), 975. https://doi.org/10.3390/rs14040975