3.1. Data Augmentation via Adjusting T-F Graph Display Scope and Feature Fusion
The main parameters of the K-band FMCW radar used in this paper are shown in
Table 1. A higher working frequency will result in a more obvious m-D signature. The modulation bandwidth related to the range resolution and longer modulation period means more integration time with longer observation range. The parameter of −3 db beamwidth indicates the beam coverage.
Figure 3 shows the data acquisition and signal processing flowchart of K-band FMCW radar. The processing results obtained after data acquisition are shown in
Figure 4, which are a one-dimensional range profile (after demodulation), range-period graph, range-period graph after stationary clutter suppression and T-F graph of the target’s range unit.
Figure 4c,d can accurately reflect the location and micro-motion information of the target, which are also the basis of the following m-D dataset.
The measurement principle of FMCW (triangular wave) radar for detecting relative moving target is shown in
Figure 5.
ft is the transmitted modulated signal,
fr is the received reflected signal,
B is the signal modulation bandwidth,
f0 is the initial frequency of the signal,
fd is the Doppler shift,
T is the modulation period of the signal, and
τ is the time delay. For FMCW radar (triangular wave modulation mode), the range information and speed information between the radar and the target can be measured by the difference frequency signal
and
of the triangular wave for two consecutive cycles [
23].
Then, the received signal after demodulation can be written as
where
M represents the number of range unit and
N is the samplings during the modulation periods.
The feature selection of target’s signal includes high-resolution range-period and m-D features. The former can reflect the property of radar cross section (RCS) and the range walk information. The latter can obtain the characteristic of the vibration and rotation of the target and its components. At present, moving target classification usually uses T-F information, while the characteristics of range profile and range walk are ignored. Moreover, it cannot bring in additional effective features using traditional image augmentation methods, such as image rotation, cropping, blurring, and adding noise. It only generates similar images with the original images, and as the increment of expanded dataset, the similar data will also lead to network overfitting and poor generalization. In this paper we proposed three methods for effective data enhancement.
In Method 1, the display of range unit in the range-time/period graph is selected and focused on the target location to obtain the most obvious radar m-D characteristics of flying birds and rotary drones.
In Method 2, the amplitude scope displayed in T-F graph is adjusted to enhance the m-D features, and then the detail features of m-D are more obvious in the spectrum.
In Method 3, the above two methods can be combined together, i.e., adjusting different range units and setting different amplitude scopes. The advantage of the proposed data augmentation is that more different data can be fed into the classification model, and more feature information can be learned from the m-D signals.
The detailed data augmentation is described as follows:
Step 1: The target’s range unit is selected from the range-time/period graph, and T-F transform is performed on the time dimension data of a certain range unit to obtain the two-dimensional T-F graph, i.e.,
.
where
is the demodulated signal or the signal after MTI processing,
is a movable window function and the variable parameter is the window length of the STFT.
Step 2: The amplitude is firstly normalized to [0, 1]. For the obtained range-time/period graph and T-F graph, the dataset is expanded by changing the display scope (spectrum amplitude). By controlling the color range display of the m-D feature in the T-F graph and the range-time/period graph, the m-D feature of the target and the range walk information can be enhanced or weakened.
The data in the range-time/period graph and T-F graph can be regarded as an array
C, which is displayed by
. The color range (spectrum amplitude) is specified as a two-element vector of the form
. According to the characteristic display of the graph, different color ranges can be set appropriately to obtain different number of datasets. Take the drone as an example: set the color display for the range-periods graph to [
A, 1] and specify the value of
A as 0.01, 0.0001, and 0.00001. Then, the range-periods graph drawn in dB is shown in
Figure 6. The drone target is located at 1 m, and different amplitude modulation features are given. Set the color display range for the T-F graph to [
B, 1] and specify the values of
B as 0.01, 0.0001 and 0.00001, respectively. The dataset augmentation of the T-F graph drawn in dB is shown in
Figure 7.
Step 3: The dataset is performed by cropping, feature fusion and label calibration.
Based on the original range-period graph and T-F graph, select an area containing the target micro-motion feature for cropping, and the cropped image contains the target micro-movement feature in the uniform size. Feature fusion is to merge the range-period graph and T-F graph of the cropped image, which contains the target’s micro-motion features. The width of the range-period graph and T-F graph are consistent with the categories of different micro-motions. Then, label calibration of the dataset after feature fusion is performed for unified size. The feature fusion processing is shown in
Figure 8.
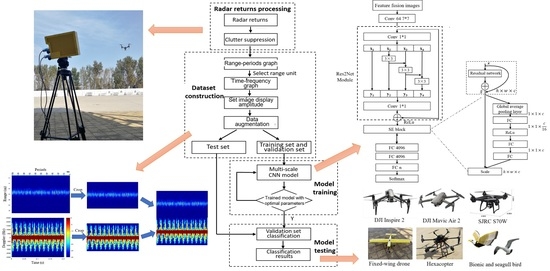
3.3. The Modified Multi-Scale CNN Model
This paper proposes a target m-D feature classification method based on the modified multi-scale CNN [
25], which uses multi-scale splitting of the hybrid connection structure. The output of the multi-scale module contains a combination of different receptive field sizes, which is conducive to extracting the global feature information and the local information of the target. Firstly, a single-layer convolution kernel with a 7 × 7 convolutional layer is used to extract features from the input image, and then a multi-scale network characterization module is employed. The 1 × 1 convolution kernel is used to adjust the number of input channels, so that the next multi-scale module can perform in-depth feature extraction. The structure of the multi-scale CNN model is shown in
Figure 19, which is based on the residual network module (Res2 Net). The filter bank with a convolution kernel size of 3 × 3 is used to replace the 1 × 1 convolutional feature map of
n channels. The feature map after 1 × 1 convolution of two channels is divided into
s feature map subsets, and each feature map subset contains
n/
s number of channels. Except for the first feature map subset that is directly passed down, the rest of the feature map subsets are followed by a convolutional layer with a convolution kernel size of 3 × 3, and the convolution operation is performed.
The second feature map subset is convoluted, and a new feature subset is formed and passed down in two lines. One line is passed down directly; and the other line is combined with the third feature map subset using a hierarchical arrangement connection method and sent to the convolution to form a new feature map subset. Then, the new feature map subset is divided into two lines; one is directly passed down, and the other line is still connected with the fourth feature map subset using a hierarchical progressive arrangement and sent to the convolutional layer to obtain other new feature map subsets. Repeat the above operations until all feature map subsets have been processed. Each feature map subset is combined with another feature map subset after passing through the convolutional layer. This operation will increase the equivalent receptive field of each convolutional layer gradually, so as to complete the extraction of information at different scales.
Use
Ki() to represent the 3 × 3 output of the convolution kernel, and
xi represents the divided feature map subsets, where
and
s represents the number of feature map subsets divided by the feature map. The above process can be expressed as follows
Then the output
yi can be expressed as
Based on the above network structure, the output of the multi-scale module includes a combination of different receptive field sizes via the split hybrid connection structure, which is conducive to extracting global and local information. Specifically, the feature map after the convolution operation with the convolution kernel size of 1 × 1 is divided into four feature map subsets; after the multi-scale structure hybrid connection, the processed feature map subsets are combined by a splicing method, i.e., y1 + y2 + y3 + y4. A convolutional layer with convolution kernel size 1 × 1 is used on the spliced feature map subsets to realize the information fusion of the divided four feature map subsets. Then, the multi-scale residual module is combined with the identity mapping y = x.
The squeeze excitation (SE) module is added after the multi-scale residual module, and then the modified multi-scale neural network residual module is completed. The structure of the SE module is given in the right of 0. For a feature map with a shape of (
h,
w,
c), i.e., (height, width, channel), the SE module first performs a compression operation, and the feature map is globally averaged in the spatial dimension to obtain a feature vector representing global information. Convert the output of the multi-scale residual module
into the output of
. The second is the incentive operation, which is shown as follows.
where
represents the first fully connected operation (FC), the first layer weight parameter is
W1 whose dimension is
,
r is called the scaling factor.
Here, let r = 16, its function is to reduce the number of channels with less calculations, and z is the result of the previous squeeze operation with the dimension 1 × c. g(z, W) represents the output result after the first fully connected operation. After the first fully connected layer, the dimension becomes , and then a ReLu layer activation function is added to increase the nonlinearity of the network, while the output dimension remains unchanged. Then, it is multiplied by W2, i.e., weight of the second fully connected layer. The output dimension becomes and the output of the SE module is calculated through the activation function Sigmoid.
Finally, the re-weighting operation is performed, and the feature weights S are multiplied to the input feature map channel by channel to complete the feature re-calibration operation. This learning method can automatically obtain the importance of each feature channel, increase the useful features accordingly and suppress the features useless for the current task. The multi-scale residual module and the SE module are combined together and with 18 such modules the modified multi-scale network is formed. The combination of the multi-scale residual module and the SE module can learn different receptive field combinations and retain useful features, and suppress invalid feature information, which greatly reduces the parameter calculation burden. Finally, we add a three-layer fully connected layer. It is used to map the effective features learned by the multi-scale model to the label space of the samples; moreover, the depth of the network model is increased so that it can learn refined features. Compared with the global average pooling, the fully connected layer can achieve faster convergence speed and higher recognition accuracy.
By setting the parameter solving algorithm Adam, the nonlinear activation function ReLU, the initial learning rate 0.0001, the training round (Epoch) 100 and other parameters, the dataset is trained. After training for one round, a verification is performed on the verification set until the correct recognition rate meets the requirements, and the network model parameters are saved to obtain the suitable network model. The final test is to input the test data not involved in training and verification into the trained network model to verify the effectiveness and generalization ability of the multi-scale CNN model. By calculating the ratio of the number of samples correctly classified in the test dataset to the total number of samples in the entire test set, the classification accuracy is obtained.




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}