
Mining Cross-Domain Structure Affinity for Refined Building Segmentation in Weakly Supervised Constraints



Abstract
:1. Introduction
- Buildings in remote sensing images usually present regular spatial structures, which is not considered by SSNet and other weakly supervised semantic segmentation methods.
- Remote sensing images captured by different sensors usually present distinct domain shifts due to the various imaging conditions and sensor parameters.
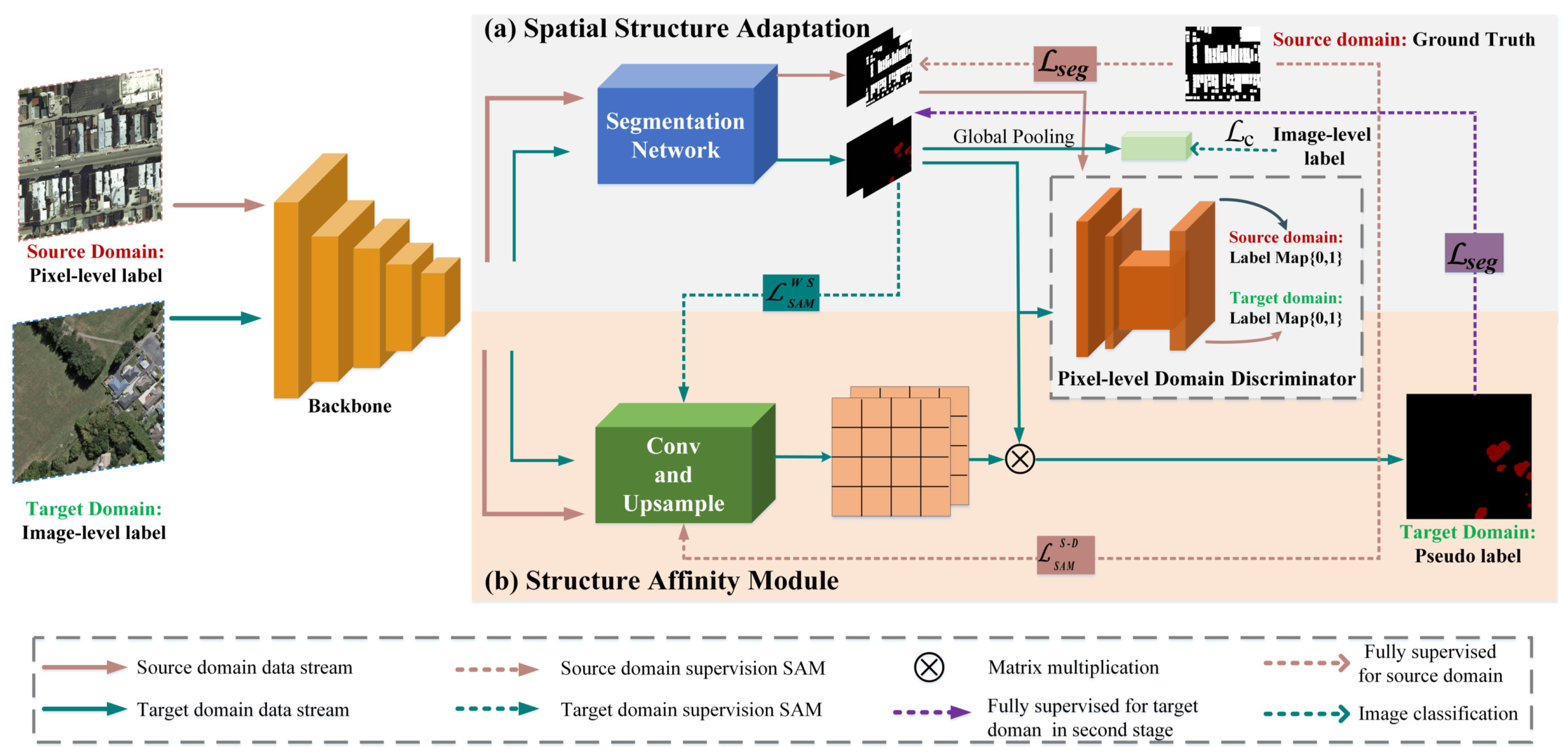
- We propose a new weakly supervised building segmentation network, CDSA, by mining the cross-domain structure affinity from multi-source remote sensing images.
- We develop a new SAM branch to learn the structure affinity of the buildings from source domain, and a new SSA branch to infuse the structure affinity to the target domain.
- We design an end-to-end network structure to simultaneously optimize the SAM and SSA so as to realize the interaction of pseudosupervised information and structure affinity.
2. Related Work
2.1. Building Segmentation for Remote Sensing
2.2. Weakly Supervised Learning
3. Methodology
3.1. Overall Architecture of CDSA
3.2. Spatial Structure Adaptation
3.2.1. Weakly Supervised Segmentation
3.2.2. Pixel-Level Domain Adaptation
3.3. The Structure Affinity Module
3.3.1. Affinity Learning of Weakly Supervised Pseudolabel
3.3.2. Mining Cross-Domain Affinity
3.3.3. Affinity Spread
3.4. Training Design of CDSA
| Algorithm 1 The pseudocode for CDSA. |
|
4. Experiments
4.1. Data Sets
4.1.1. Inria
4.1.2. WHU
4.1.3. ISPRS
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Ablation Studies
4.4.1. Influence of the Pixel-Level Domain Discriminator
4.4.2. Influence of SAM under Weakly Supervised Learning
4.4.3. Influence of SAM under Cross-Domain Supervised
4.5. Comparisons with State of the Arts
4.5.1. Comparison with Weakly Supervised
4.5.2. Compared with Domain Adaptation
- SSA can map the spatial structure domain-invariant features to the target domain and use image-level labels of the target domain to roughly locate objects.
- SAM can mine the structure context between the pixels to refine the edges of buildings.
4.5.3. Comparison with Fully Supervised
4.6. Qualitative Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Q.; Gao, J.; Li, X. Weakly supervised adversarial domain adaptation for semantic segmentation in urban scenes. IEEE Trans. Image Process. 2019, 28, 4376–4386. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ren, P.; Xu, M.; Yu, Y.; Chen, F.; Jiang, X.; Yang, E. Energy minimization with one dot fuzzy initialization for marine oil spill segmentation. IEEE J. Ocean. Eng. 2018, 44, 1102–1115. [Google Scholar] [CrossRef] [Green Version]
- Milosavljević, A. Automated processing of remote sensing imagery using deep semantic segmentation: A building footprint extraction case. ISPRS Int. J. Geo-Inf. 2020, 9, 486. [Google Scholar] [CrossRef]
- Shi, Y.; Li, Q.; Zhu, X.X. Building segmentation through a gated graph convolutional neural network with deep structured feature embedding. ISPRS J. Photogramm. Remote Sens. 2020, 159, 184–197. [Google Scholar] [CrossRef]
- Wu, G.; Shao, X.; Guo, Z.; Chen, Q.; Yuan, W.; Shi, X.; Xu, Y.; Shibasaki, R. Automatic building segmentation of aerial imagery using multi-constraint fully convolutional networks. Remote Sens. 2018, 10, 407. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Q.; Li, Z.; Zhang, Y.; Guan, Q. Building extraction from high spatial resolution remote sensing images via multiscale-aware and segmentation-prior conditional random fields. Remote Sens. 2020, 12, 3983. [Google Scholar] [CrossRef]
- Gupta, R.; Shah, M. Rescuenet: Joint building segmentation and damage assessment from satellite imagery. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 4405–4411. [Google Scholar]
- Lu, Z.; Chen, D.; Xue, D. Survey of weakly supervised semantic segmentation methods. In Proceedings of the 2018 Chinese Control And Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1176–1180. [Google Scholar]
- Rafique, M.U.; Jacobs, N. Weakly Supervised Building Segmentation from Aerial Images. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3955–3958. [Google Scholar]
- Zhang, M.; Zhou, Y.; Zhao, J.; Man, Y.; Liu, B.; Yao, R. A survey of semi-and weakly supervised semantic segmentation of images. Artif. Intell. Rev. 2020, 53, 4259–4288. [Google Scholar] [CrossRef]
- Fu, K.; Lu, W.; Diao, W.; Yan, M.; Sun, H.; Zhang, Y.; Sun, X. WSF-NET: Weakly supervised feature-fusion network for binary segmentation in remote sensing image. Remote Sens. 2018, 10, 1970. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; He, F.; Zhang, Y.; Sun, G.; Deng, M. SPMF-Net: Weakly supervised building segmentation by combining superpixel pooling and multi-scale feature fusion. Remote Sens. 2020, 12, 1049. [Google Scholar] [CrossRef] [Green Version]
- Zeng, Y.; Zhuge, Y.; Lu, H.; Zhang, L. Joint learning of saliency detection and weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7223–7233. [Google Scholar]
- Bruzzone, L.; Carlin, L. A multilevel context-based system for classification of very high spatial resolution images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2587–2600. [Google Scholar] [CrossRef] [Green Version]
- Tuia, D.; Persello, C.; Bruzzone, L. Domain adaptation for the classification of remote sensing data: An overview of recent advances. IEEE Geosci. Remote Sens. Mag. 2016, 4, 41–57. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Mou, L.; Zhu, X.X. Rifcn: Recurrent network in fully convolutional network for semantic segmentation of high resolution remote sensing images. arXiv 2018, arXiv:1805.02091. [Google Scholar]
- Huang, J.; Zhang, X.; Xin, Q.; Sun, Y.; Zhang, P. Automatic building extraction from high-resolution aerial images and lidar data using gated residual refinement network. ISPRS J. Photogramm. Remote Sens. 2019, 151, 91–105. [Google Scholar] [CrossRef]
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. Brrnet: A fully convolutional neural network for automatic building extraction from high-resolution remote sensing images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef] [Green Version]
- Xie, Y.; Zhu, J.; Cao, Y.; Feng, D.; Hu, M.; Li, W.; Zhang, Y.; Fu, L. Refined extraction of building outlines from high-resolution remote sensing imagery based on a multifeature convolutional neural network and morphological filtering. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1842–1855. [Google Scholar] [CrossRef]
- He, S.; Jiang, W. Boundary-assisted learning for building extraction from optical remote sensing imagery. Remote Sens. 2021, 13, 760. [Google Scholar] [CrossRef]
- Zhu, Y.; Liang, Z.; Yan, J.; Chen, G.; Wang, X. Ed-net: Automatic building extraction from high-resolution aerial images with boundary information. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4595–4606. [Google Scholar] [CrossRef]
- Jadon, S. A survey of loss functions for semantic segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Via del Mar, Chile, 27–29 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar]
- Fan, R.; Hou, Q.; Cheng, M.M.; Yu, G.; Martin, R.R.; Hu, S.M. Associating inter-image salient instances for weakly supervised semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 367–383. [Google Scholar]
- Wang, X.; You, S.; Li, X.; Ma, H. Weakly-supervised semantic segmentation by iteratively mining common object features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1354–1362. [Google Scholar]
- Sun, G.; Wang, W.; Dai, J.; Van Gool, L. Mining cross-image semantics for weakly supervised semantic segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 347–365. [Google Scholar]
- Wang, Y.; Zhang, J.; Kan, M.; Shan, S.; Chen, X. Self-supervised equivariant attention mechanism for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12275–12284. [Google Scholar]
- Wang, S.; Chen, W.; Xie, S.M.; Azzari, G.; Lobell, D.B. Weakly supervised deep learning for segmentation of remote sensing imagery. Remote Sens. 2020, 12, 207. [Google Scholar] [CrossRef] [Green Version]
- Ma, F.; Gao, F.; Sun, J.; Zhou, H.; Hussain, A. Weakly supervised segmentation of SAR imagery using superpixel and hierarchically adversarial CRF. Remote Sens. 2019, 11, 512. [Google Scholar] [CrossRef] [Green Version]
- Wu, S.; Du, C.; Chen, H.; Xu, Y.; Guo, N.; Jing, N. Road extraction from very high resolution images using weakly labeled OpenStreetMap centerline. ISPRS Int. J. Geo-Inf. 2019, 8, 478. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Ma, J.; Lv, X.; Chen, D. Hierarchical weakly supervised learning for residential area semantic segmentation in remote sensing images. IEEE Geosci. Remote Sens. Lett. 2019, 17, 117–121. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Tsai, Y.H.; Hung, W.C.; Schulter, S.; Sohn, K.; Yang, M.H.; Chandraker, M. Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7472–7481. [Google Scholar]
- Deng, X.; Yang, H.L.; Makkar, N.; Lunga, D. Large scale unsupervised domain adaptation of segmentation networks with adversarial learning. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 4955–4958. [Google Scholar]
- Pan, Z.; Yu, W.; Yi, X.; Khan, A.; Yuan, F.; Zheng, Y. Recent progress on generative adversarial networks (gans): A survey. IEEE Access 2019, 7, 36322–36333. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Ahn, J.; Kwak, S. Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4981–4990. [Google Scholar]
- Lovász, L. Random walks on graphs. In Combinatorics, Paul Erdos Is Eighty; Janos Bolyai Mathematical Society: Budapest, Hungary, 1993; Volume 2, p. 4. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? The inria aerial image labeling benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3226–3229. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Gerke, M. Use of the Stair Vision Library within the ISPRS 2D Semantic Labeling Benchmark (Vaihingen). 2014. Available online: https://research.utwente.nl/en/publications/use-of-the-stair-vision-library-within-the-isprs-2d-semantic-labe (accessed on 20 January 2022).
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Durand, T.; Mordan, T.; Thome, N.; Cord, M. Wildcat: Weakly supervised learning of deep convnets for image classification, pointwise localization and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 642–651. [Google Scholar]
- Fan, J.; Zhang, Z.; Song, C.; Tan, T. Learning integral objects with intra-class discriminator for weakly-supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4283–4292. [Google Scholar]
- Zhang, Y.; Qiu, Z.; Yao, T.; Liu, D.; Mei, T. Fully convolutional adaptation networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6810–6818. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SSA | Baseline | ✓ | ✓ | ✓ | ✓ | ✓ |
| Pixel-level Domain Discriminator | ✓ | ✓ | ✓ | |||
| SAM | Weakly Supervised | ✓ | ||||
| Cross-domain Supervised | ✓ | ✓ | ||||
| Image-level labels of target domain | ✓ | ✓ | ✓ | ✓ | ||
| The first stage | IoU | 51.75 | 52.93 | 54.26 | 55.03 | 56.51 |
| OA | 92.42 | 93.30 | 93.28 | 93.43 | 93.56 | |
| The second stage | IoU | 55.03 | 56.17 | 56.64 | 57.19 | 57.87 |
| OA | 93.36 | 93.42 | 93.51 | 93.67 | 93.84 | |
| Methods | Sourec Domain | Target Domain | IoU | OA | |
|---|---|---|---|---|---|
| Weakly supervised Methods | WILDCAT [45] | - | WHU | 24.78 | 82.64 |
| SEAM [27] | - | WHU | 25.48 | 69.23 | |
| ICD [46] | - | WHU | 24.32 | 48.89 | |
| SSNet [13] | Inria | WHU | 55.03 | 93.36 | |
| CDSA(Ours) | Inria | WHU | 57.87 | 93.84 | |
| Domain adaptation Methods | NoAdapt | Inria | WHU | 35.60 | 86.10 |
| FCAN [47] | Inria | WHU | 40.79 | 91.74 | |
| CDSA(Ours) | Inria | WHU | 57.87 | 93.84 | |
| NoAdapt | WHU | Inria | 27.84 | 81.34 | |
| FCAN [47] | WHU | Inria | 35.05 | 87.41 | |
| CDSA(Ours) | WHU | Inria | 39.82 | 91.23 | |
| Fully supervised Methods | FCN [16] | - | WHU | 73.29 | 96.52 |
| DeeplabV3 [33] | - | WHU | 75.89 | 96.86 |
| Methods | Source Domain | Target Domain | IoU | OA | |
|---|---|---|---|---|---|
| Weakly supervised Methods | WILDCAT [45] | - | Vaihingen | 44.92 | 78.08 |
| SEAM [27] | - | Vaihingen | 30.49 | 75.38 | |
| ICD [46] | - | Vaihingen | 39.48 | 69.10 | |
| SSNet [13] | Postdam | Vaihingen | 75.73 | 93.18 | |
| CDSA(Ours) | Postdam | Vaihingen | 79.57 | 94.52 | |
| Domain adaptation Methods | NoAdapt | Postdam | Vaihingen | 21.92 | 65.91 |
| FCAN [47] | Postdam | Vaihingen | 45.00 | 67.19 | |
| CDSA(Ours) | Postdam | Vaihingen | 79.57 | 94.52 | |
| NoAdapt | Vaihingen | Postdam | 28.75 | 67.39 | |
| FCAN [47] | Vaihingen | Postdam | 35.96 | 76.06 | |
| CDSA(Ours) | Vaihingen | Postdam | 69.94 | 90.58 | |
| Fully supervised Methods | FCN [16] | - | Vaihingen | 79.20 | 94.06 |
| DeeplabV3 [33] | - | Vaihingen | 80.31 | 94.57 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Liu, Y.; Wu, P.; Shi, Z.; Pan, B. Mining Cross-Domain Structure Affinity for Refined Building Segmentation in Weakly Supervised Constraints. Remote Sens. 2022, 14, 1227. https://doi.org/10.3390/rs14051227
Zhang J, Liu Y, Wu P, Shi Z, Pan B. Mining Cross-Domain Structure Affinity for Refined Building Segmentation in Weakly Supervised Constraints. Remote Sensing. 2022; 14(5):1227. https://doi.org/10.3390/rs14051227
Chicago/Turabian StyleZhang, Jun, Yue Liu, Pengfei Wu, Zhenwei Shi, and Bin Pan. 2022. "Mining Cross-Domain Structure Affinity for Refined Building Segmentation in Weakly Supervised Constraints" Remote Sensing 14, no. 5: 1227. https://doi.org/10.3390/rs14051227
APA StyleZhang, J., Liu, Y., Wu, P., Shi, Z., & Pan, B. (2022). Mining Cross-Domain Structure Affinity for Refined Building Segmentation in Weakly Supervised Constraints. Remote Sensing, 14(5), 1227. https://doi.org/10.3390/rs14051227