
SR-Net: Saliency Region Representation Network for Vehicle Detection in Remote Sensing Images

Abstract
:1. Introduction
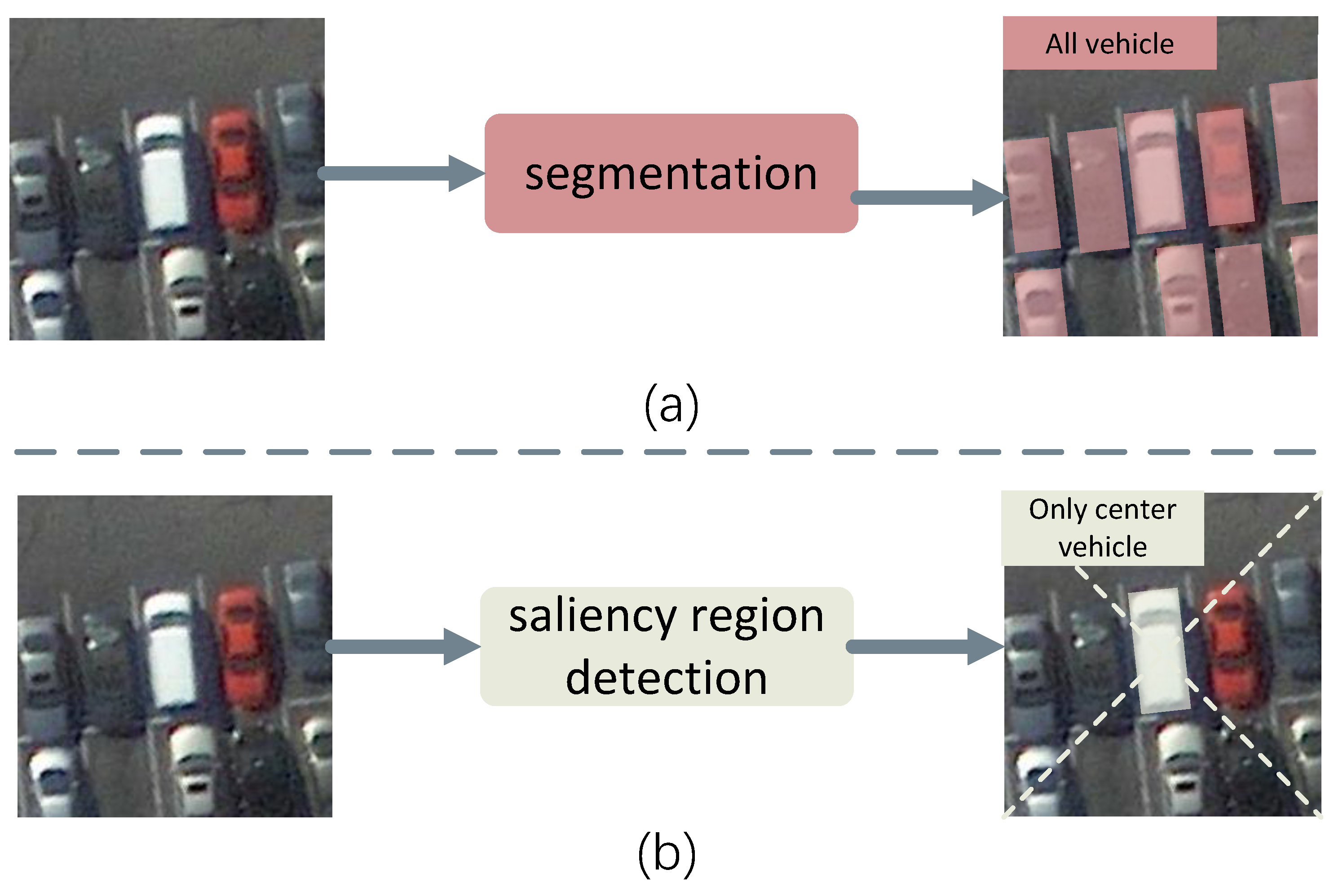
- We propose a new model, SR-Net, to exploit saliency-area-based representation and localize the vehicle objects in remote sensing images. To the best of our knowledge, we are the first to detect vehicles via saliency object detection;
- Our model can handle the discontinuous problem of angular regression by replacing vanilla oriented-box-based representation with the proposed distance-regression-free saliency-area-based representation;
- To obtain a more accurate boundary of the saliency region and enhance the edge information of the saliency area, we design a contour-aware module to capture the object’s edge;
- To eliminate the divergence of feature construction, we propose a new pipeline that divides the localization networks and saliency-based representation networks into two paths.
2. Method
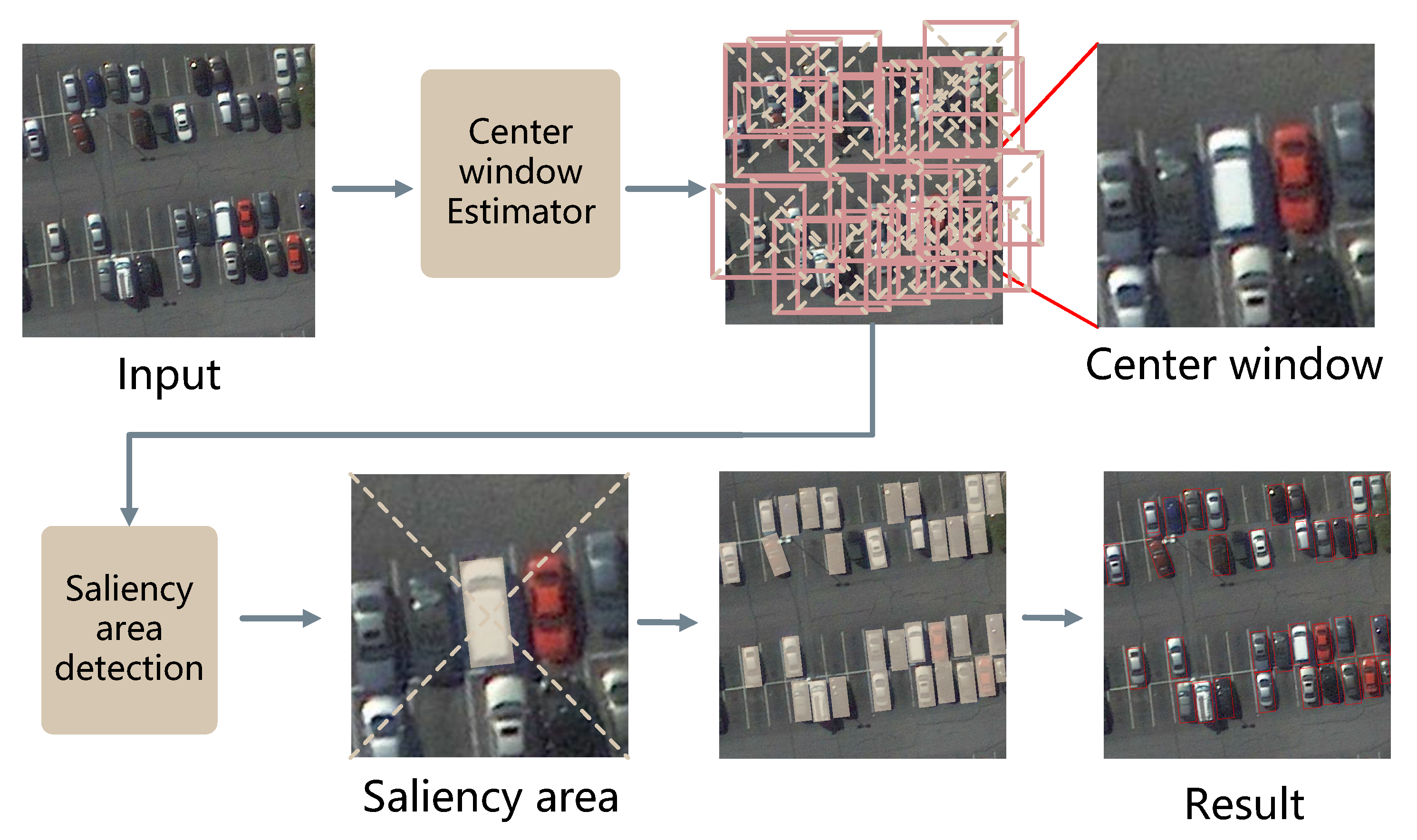
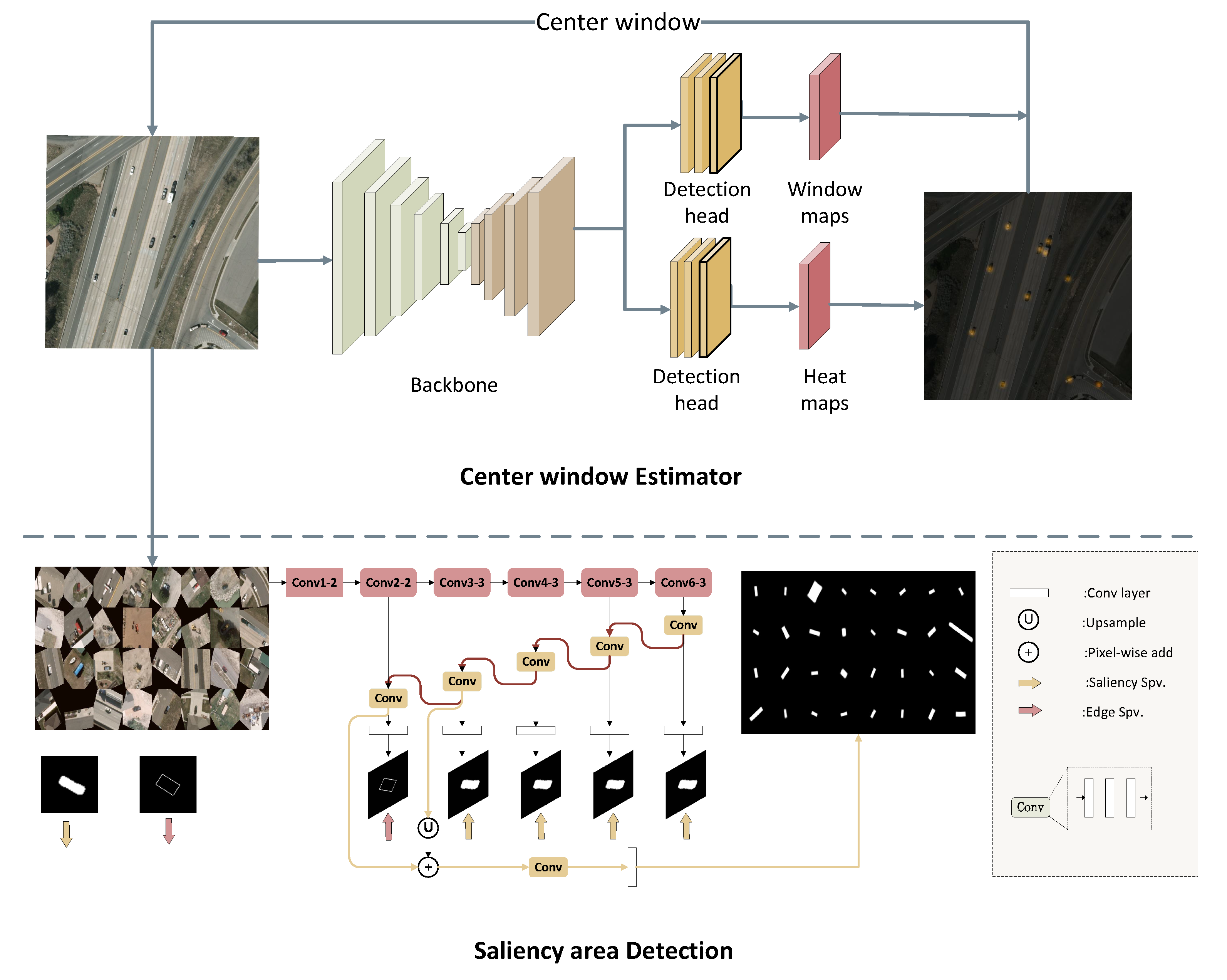
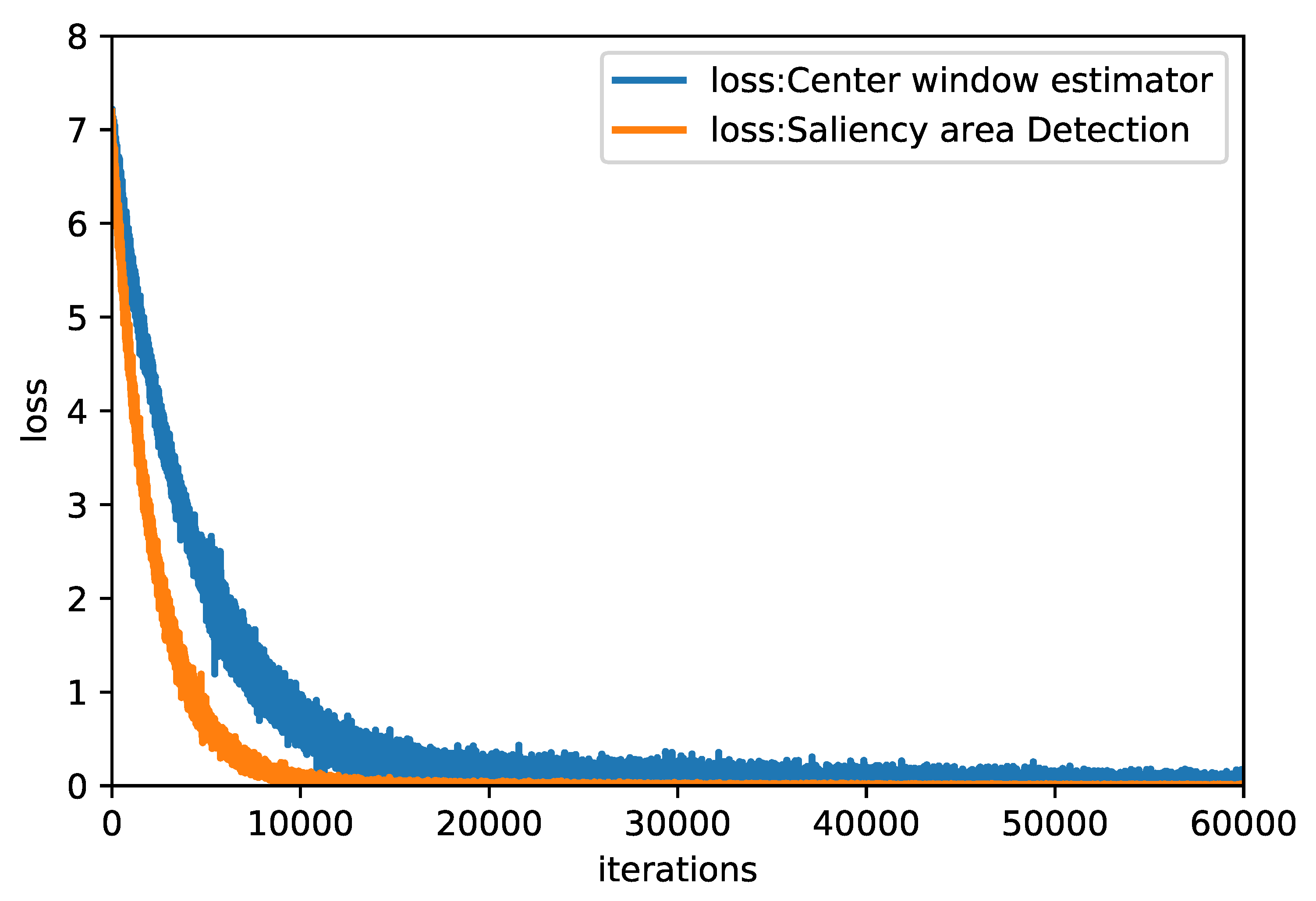
2.1. Center Window Estimator Module
2.1.1. Center Window Estimator
2.1.2. Center Estimator Loss Function
2.1.3. Center Window
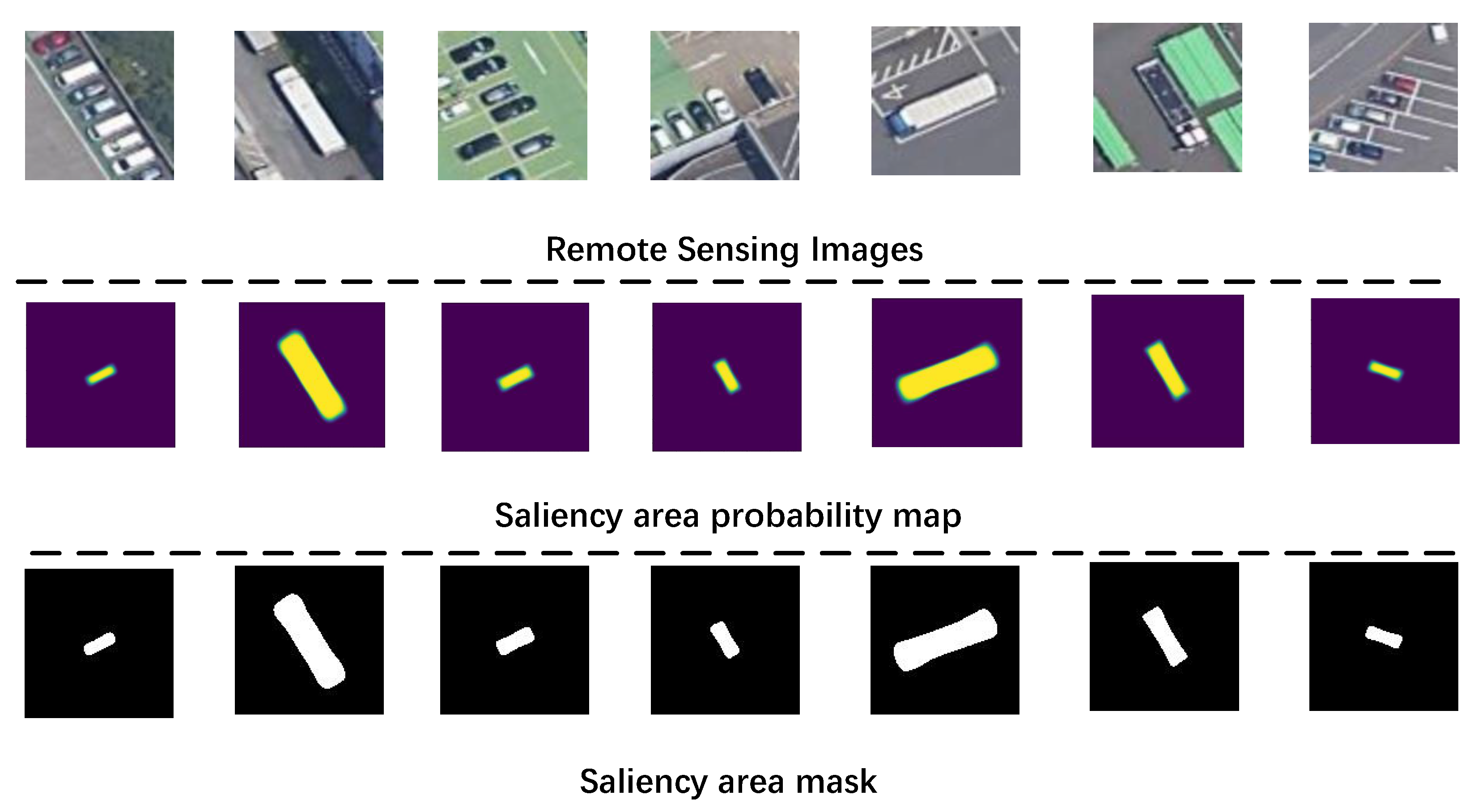
2.2. Saliency Region Detection
2.2.1. Complementary Information Modeling
2.2.2. Saliency Object Features Extraction
2.2.3. Saliency Edge and Region Masks Extraction
2.2.4. Saliency Object Detection
3. Result
3.1. Data Set
3.2. Evaluation Metric
3.3. Training Details
3.4. Comparisons with State-of-the-Art Detectors
3.5. Qualitative Quantity Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, F.; Du, B.; Zhang, L.; Xu, M. Weakly Supervised Learning Based on Coupled Convolutional Neural Networks for Aircraft Detection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5553–5563. [Google Scholar] [CrossRef]
- Mou, L.; Zhu, X.X. Spatiotemporal scene interpretation of space videos via deep neural network and tracklet analysis. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium, Beijing, China, 10–15 July 2016; pp. 1823–1826. [Google Scholar] [CrossRef]
- Mou, L.; Zhu, X.; Vakalopoulou, M.; Karantzalos, K.; Paragios, N.; Saux, B.L.; Moser, G.; Tuia, D. Multitemporal Very High Resolution From Space: Outcome of the 2016 IEEE GRSS Data Fusion Contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3435–3447. [Google Scholar] [CrossRef] [Green Version]
- Audebert, N.; Saux, B.L.; Lefèvre, S. Segment-before-Detect: Vehicle Detection and Classification through Semantic Segmentation of Aerial Images. Remote Sens. 2017, 9, 368. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Mou, L.; Liu, Q.; Wang, Y.; Zhu, X.X. HSF-Net: Multiscale Deep Feature Embedding for Ship Detection in Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 7147–7161. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the International Conference on Computer Vision, Kerkyra, Corfu, Greece, 20–25 September 1999; pp. 1150–1157. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikäinen, M.; Mäenpää, T. Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Moranduzzo, T.; Melgani, F. Automatic Car Counting Method for Unmanned Aerial Vehicle Images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1635–1647. [Google Scholar] [CrossRef]
- Moranduzzo, T.; Melgani, F. Detecting Cars in UAV Images With a Catalog-Based Approach. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6356–6367. [Google Scholar] [CrossRef]
- Liu, K.; Máttyus, G. Fast Multiclass Vehicle Detection on Aerial Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1938–1942. [Google Scholar] [CrossRef] [Green Version]
- Elmikaty, M.; Stathaki, T. Detection of Cars in High-Resolution Aerial Images of Complex Urban Environments. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5913–5924. [Google Scholar] [CrossRef]
- Zhou, H.; Wei, L.; Lim, C.P.; Creighton, D.C.; Nahavandi, S. Robust Vehicle Detection in Aerial Images Using Bag-of-Words and Orientation Aware Scanning. IEEE Trans. Geosci. Remote Sens. 2018, 56, 7074–7085. [Google Scholar] [CrossRef]
- Kalantar, B.; Mansor, S.; Halin, A.A.; Shafri, H.Z.M.; Zand, M. Multiple Moving Object Detection From UAV Videos Using Trajectories of Matched Regional Adjacency Graphs. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5198–5213. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25, Proceedings of the 26th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Morgan Kaufmann Publishers, Inc.: Lake Tahoe, NV, USA, 2012; pp. 1106–1114. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. arXiv 2013, arXiv:1311.2901. Available online: http://xxx.lanl.gov/abs/1311.2901 (accessed on 8 May 2012).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. CoRR 2015. abs/1512.03385. Available online: http://xxx.lanl.gov/abs/1512.03385 (accessed on 8 May 2012).
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HA, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Xie, S.; Girshick, R.B.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HA, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.B. Fast R-CNN. In Proceedings of the Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; Available online: http://xxx.lanl.gov/abs/1504.08083 (accessed on 8 May 2012).
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Available online: http://xxx.lanl.gov/abs/1506.01497 (accessed on 8 May 2012).
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef] [Green Version]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019; pp. 9626–9635. [Google Scholar]
- Wei, H.; Zhang, Y.; Wang, B.; Yang, Y.; Li, H.; Wang, H. X-LineNet: Detecting Aircraft in Remote Sensing Images by a Pair of Intersecting Line Segments. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1645–1659. [Google Scholar] [CrossRef]
- Wei, H.; Zhou, L.; Zhang, Y.; Li, H.; Guo, R.; Wang, H. Oriented Objects as pairs of Middle Lines. ISPRS J. Photogramm. Remote Sens. 2020, 169, 268–279. [Google Scholar] [CrossRef]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-Oriented Scene Text Detection via Rotation Proposals. IEEE Trans. Multimed. 2017, 20, 3111–3122. Available online: http://xxx.lanl.gov/abs/1703.01086 (accessed on 8 May 2012). [CrossRef] [Green Version]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Sun, X.; Fu, K. SCRDet: Towards More Robust Detection for Small, Cluttered and Rotated Objects. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea, 27 October–2 November 2019; pp. 8231–8240. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Yan, J. Arbitrary-Oriented Object Detection with Circular Smooth Label. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12353, pp. 677–694. [Google Scholar]
- Yang, X.; Hou, L.; Zhou, Y.; Wang, W.; Yan, J. Dense Label Encoding for Boundary Discontinuity Free Rotation Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 15819–15829. [Google Scholar]
- Zhou, L.; Wei, H.; Li, H.; Zhao, W.; Zhang, Y. Objects detection for remote sensing images based on polar coordinates. arXiv 2020, arXiv:2001.02988. Available online: http://xxx.lanl.gov/abs/2001.02988 (accessed on 8 May 2012).
- Fu, K.; Chang, Z.; Zhang, Y.; Sun, X. Point-Based Estimator for Arbitrary-Oriented Object Detection in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4370–4387. [Google Scholar] [CrossRef]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part VIII. pp. 483–499. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Zhao, J.; Liu, J.; Fan, D.; Cao, Y.; Yang, J.; Cheng, M. EGNet: Edge Guidance Network for Salient Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Kümmerer, M.; Theis, L.; Bethge, M. Deep Gaze I: Boosting Saliency Prediction with Feature Maps Trained on ImageNet. arXiv 2015, arXiv:1411.1045. [Google Scholar]
- Pan, J.; McGuinness, K.; Sayrol, E.; O’Connor, N.E.; Giró-i-Nieto, X. Shallow and Deep Convolutional Networks for Saliency Prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HA, USA, 21–26 July 2016. [Google Scholar]
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.J.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar] [CrossRef] [Green Version]
- Zhu, H.; Chen, X.; Dai, W.; Fu, K.; Ye, Q.; Jiao, J. Orientation robust object detection in aerial images using deep convolutional neural network. In Proceedings of the 2015 IEEE International Conference on Image Processing, ICIP 2015, Quebec City, QC, Canada, 27–30 September 2015; pp. 3735–3739. [Google Scholar] [CrossRef]
- Razakarivony, S.; Jurie, F. Vehicle detection in aerial imagery: A small target detection benchmark. J. Vis. Commun. Image Represent. 2016, 34, 187–203. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection. arXiv 2017, arXiv:1706.09579. Available online: http://xxx.lanl.gov/abs/1706.09579 (accessed on 8 May 2012).
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic Ship Detection in Remote Sensing Images from Google Earth of Complex Scenes Based on Multiscale Rotation Dense Feature Pyramid Networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef] [Green Version]
- Azimi, S.M.; Vig, E.; Bahmanyar, R.; Körner, M.; Reinartz, P. Towards Multi-class Object Detection in Unconstrained Remote Sensing Imagery. In Proceedings of the Computer Vision—ACCV 2018—14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Revised Selected Papers, Part III. pp. 150–165. [Google Scholar] [CrossRef] [Green Version]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.; Lu, Q. Learning RoI Transformer for Oriented Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 2849–2858. [Google Scholar] [CrossRef]
- Li, Q.; Mou, L.; Xu, Q.; Zhang, Y.; Zhu, X.X. R3-Net: A Deep Network for Multioriented Vehicle Detection in Aerial Images and Videos. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5028–5042. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Liu, Q.; Yan, J.; Li, A. R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object. arXiv 2019, arXiv:1908.05612. Available online: http://xxx.lanl.gov/abs/1908.05612 (accessed on 8 May 2012).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S | O | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | 1 | 64 | 3 | 1 | 64 | 3 | 1 | 64 | 3 | 1 | 1 |
| 3 | 3 | 1 | 128 | 3 | 1 | 128 | 3 | 1 | 128 | 3 | 1 | 1 |
| 4 | 3 | 1 | 256 | 3 | 1 | 256 | 3 | 2 | 256 | 3 | 1 | 1 |
| 5 | 5 | 2 | 256 | 5 | 2 | 256 | 5 | 2 | 256 | 3 | 1 | 1 |
| 6 | 5 | 2 | 256 | 5 | 2 | 256 | 5 | 2 | 256 | 3 | 1 | 1 |
| Models | FPS | AP | AP | AP | AP | AP | AP | AP | AP | AP | AP | AP | AP | AP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv2(O) [44] | 15.31 | 4.43 | 6.70 | 4.73 | 11.29 | 18.21 | 12.74 | 12.84 | 20.32 | 14.30 | 12.25 | 19.80 | 14.36 | 10.20 |
| [45] | 3.81 | 34.94 | 57.20 | 41.64 | 59.83 | 87.95 | 61.88 | 59.65 | 87.22 | 64.54 | 60.79 | 64.59 | 46.31 | 53.80 |
| RRPN [29] | 5.25 | 34.09 | 53.19 | 39.25 | 59.83 | 86.17 | 62.50 | 58.17 | 85.43 | 61.93 | 51.85 | 62.34 | 44.88 | 50.99 |
| R-DFPN [46] | 5.84 | 34.22 | 54.33 | 39.17 | 60.41 | 87.37 | 61.72 | 55.08 | 84.35 | 59.21 | 54.91 | 60.57 | 43.73 | 51.15 |
| ICN [47] | 6.54 | 45.64 | 65.77 | 48.20 | 58.24 | 89.24 | 64.93 | 54.34 | 86.12 | 63.81 | 56.15 | 63.22 | 44.94 | 53.59 |
| RetinaNet(O) [25] | 7.34 | 42.08 | 68.26 | 50.99 | 62.54 | 89.65 | 64.60 | 54.54 | 86.30 | 63.08 | 53.16 | 65.41 | 47.74 | 53.08 |
| Roi-Transformer [48] | 3.92 | 43.77 | 70.27 | 50.31 | 60.90 | 90.56 | 66.69 | 55.86 | 88.53 | 65.15 | 56.12 | 66.52 | 48.82 | 54.16 |
| P-RSDet [33] | 7.82 | 46.55 | 71.52 | 51.70 | 57.93 | 90.87 | 66.19 | 54.75 | 88.75 | 64.96 | 61.94 | 70.33 | 49.58 | 55.29 |
| SCRDet [30] | 6.37 | 40.17 | 65.97 | 47.56 | 57.27 | 90.25 | 64.40 | 56.58 | 89.67 | 63.21 | 55.77 | 74.65 | 54.34 | 52.44 |
| -DNet [28] | 7.62 | 47.09 | 72.45 | 51.43 | 59.42 | 91.06 | 67.15 | 63.08 | 90.64 | 67.88 | 56.01 | 71.34 | 52.07 | 56.40 |
| -Net [49] | 3.23 | 49.58 | 73.24 | 52.07 | 60.19 | 91.22 | 66.21 | 63.12 | 91.48 | 67.69 | 56.26 | 69.23 | 50.39 | 57.28 |
| -Det [50] | 6.53 | 46.49 | 75.24 | 55.15 | 61.09 | 91.63 | 64.85 | 62.01 | 90.14 | 66.34 | 56.42 | 70.58 | 51.02 | 56.50 |
| SR-Net(ResNet-101) | 7.64 | 50.27 | 76.40 | 57.75 | 61.18 | 92.03 | 69.55 | 64.47 | 90.68 | 69.82 | 53.42 | 70.53 | 56.54 | 57.33 |
| SR-Net(104-Hourglass) | 7.43 | 52.30 | 80.09 | 59.03 | 62.44 | 93.24 | 70.55 | 68.25 | 91.01 | 71.89 | 55.81 | 72.53 | 58.16 | 59.60 |
| 0.1 | 1 | 2 | 3 | 5 | 7 | |
|---|---|---|---|---|---|---|
| AP | 0.602 | 0.608 | 0.612 | 0.610 | 0.609 | 0.593 |
| 0 | 0.1 | 0.4 | 0.8 | 1.2 | 1.4 | 1.6 | |
|---|---|---|---|---|---|---|---|
| AP | 0.574 | 0.586 | 0.604 | 0.609 | 0.612 | 0.610 | 0.608 |
| Edge Supervision | Area Supervision | AP | AP | AP |
|---|---|---|---|---|
| ✓ | 0.613 | 0.919 | 0.683 | |
| ✓ | 0.612 | 0.942 | 0.695 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, F.; Zhao, W.; Zhou, G.; Zhao, L.; Wei, H. SR-Net: Saliency Region Representation Network for Vehicle Detection in Remote Sensing Images. Remote Sens. 2022, 14, 1313. https://doi.org/10.3390/rs14061313
Liu F, Zhao W, Zhou G, Zhao L, Wei H. SR-Net: Saliency Region Representation Network for Vehicle Detection in Remote Sensing Images. Remote Sensing. 2022; 14(6):1313. https://doi.org/10.3390/rs14061313
Chicago/Turabian StyleLiu, Fanfan, Wenzhe Zhao, Guangyao Zhou, Liangjin Zhao, and Haoran Wei. 2022. "SR-Net: Saliency Region Representation Network for Vehicle Detection in Remote Sensing Images" Remote Sensing 14, no. 6: 1313. https://doi.org/10.3390/rs14061313
APA StyleLiu, F., Zhao, W., Zhou, G., Zhao, L., & Wei, H. (2022). SR-Net: Saliency Region Representation Network for Vehicle Detection in Remote Sensing Images. Remote Sensing, 14(6), 1313. https://doi.org/10.3390/rs14061313