
Potential of Convolutional Neural Networks for Forest Mapping Using Sentinel-1 Interferometric Short Time Series


Abstract
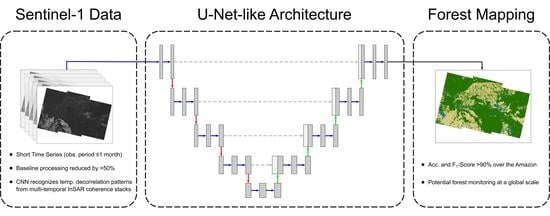
:
1. Introduction
2. Materials and Background Concepts
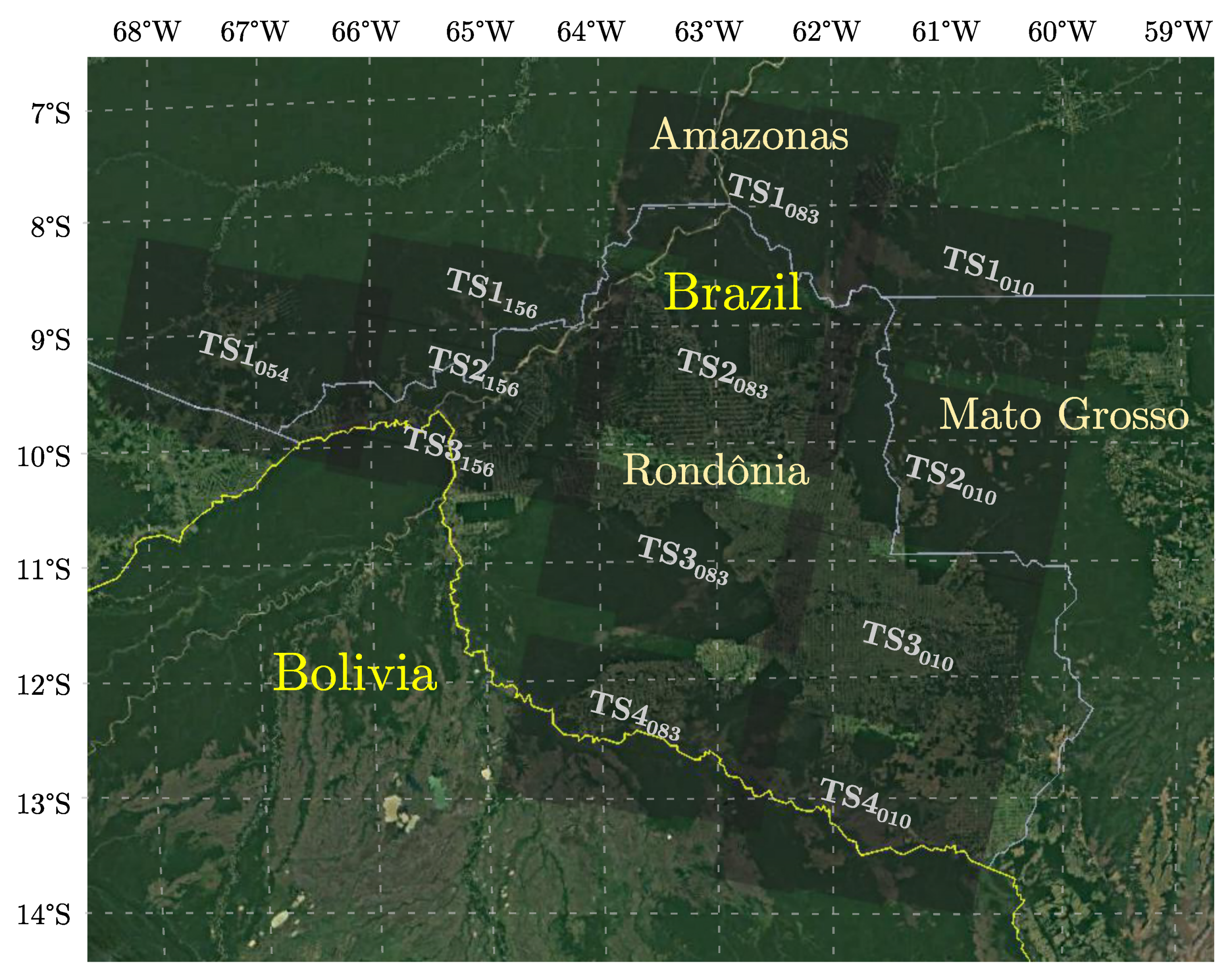
2.1. Sentinel-1 Multi-Temporal Dataset
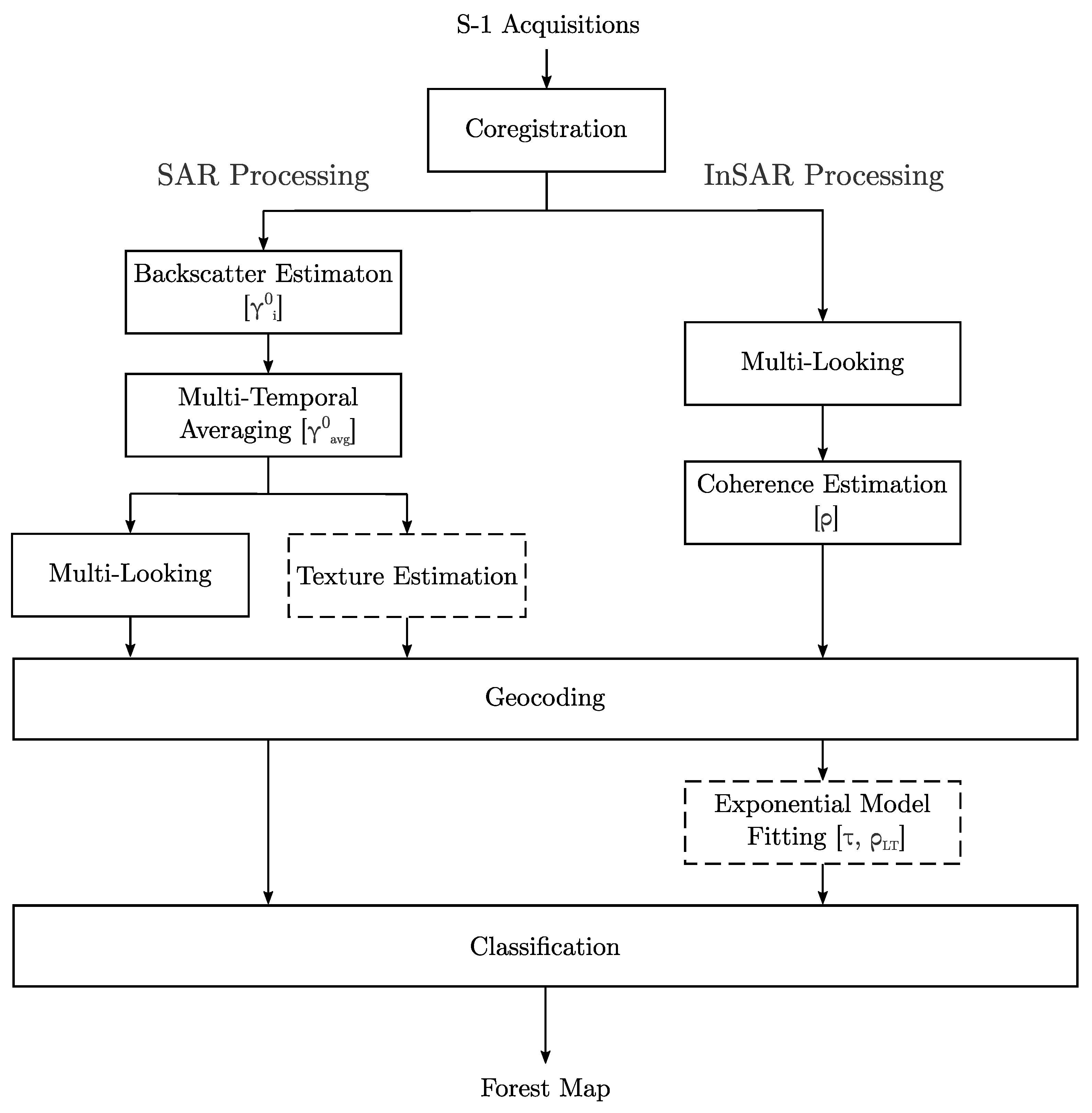
2.2. Sentinel-1 Data Preparation
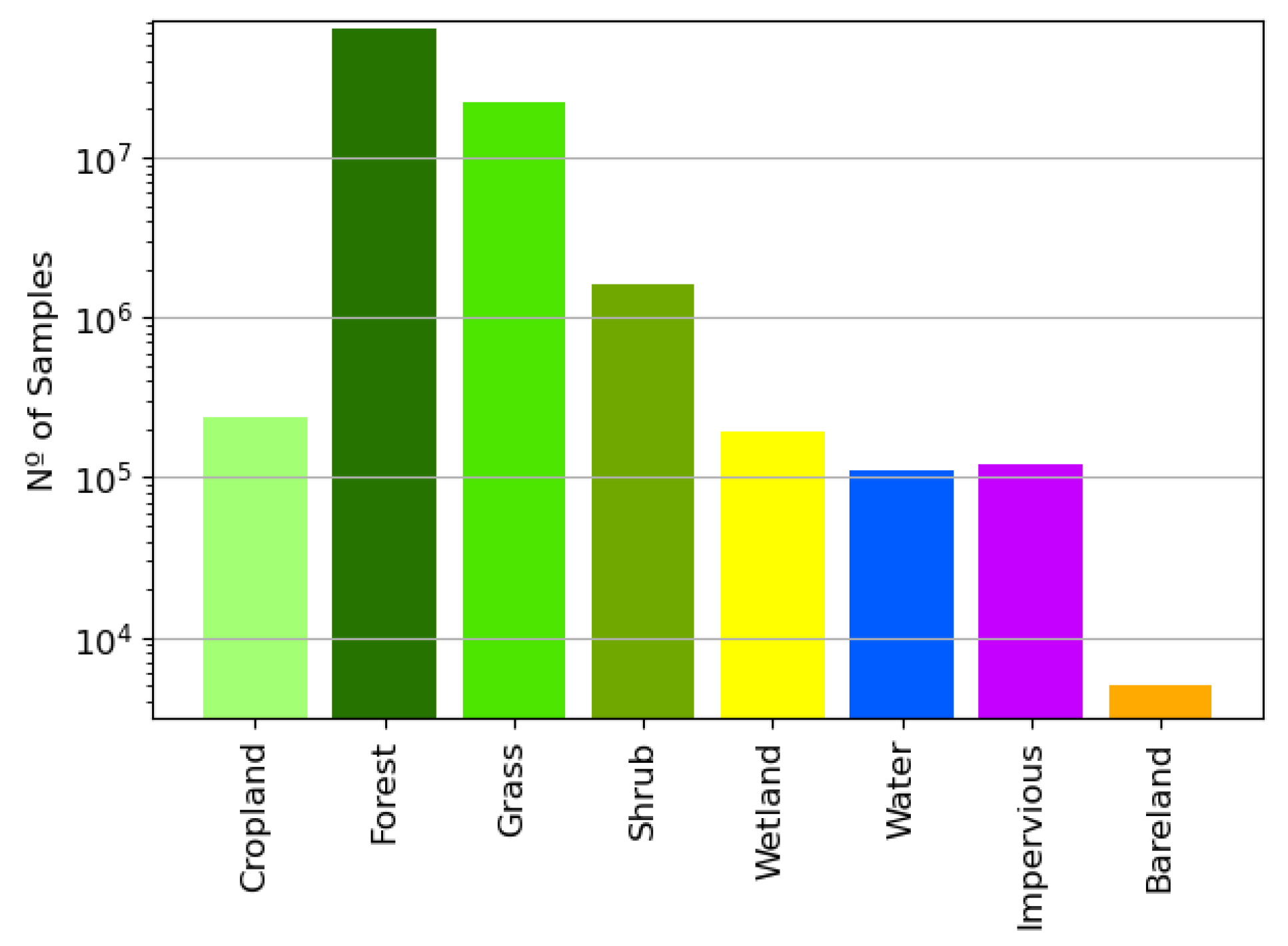
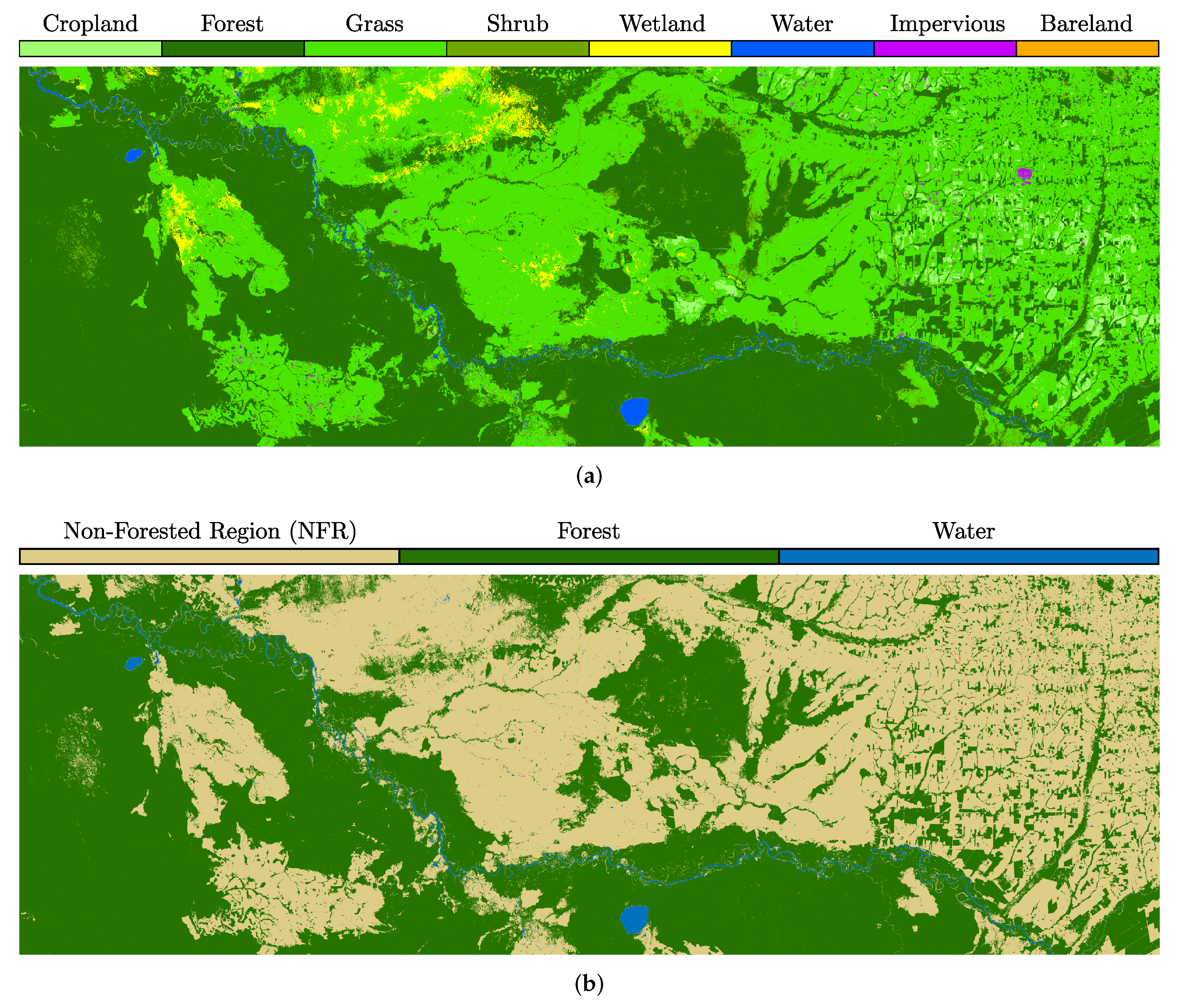
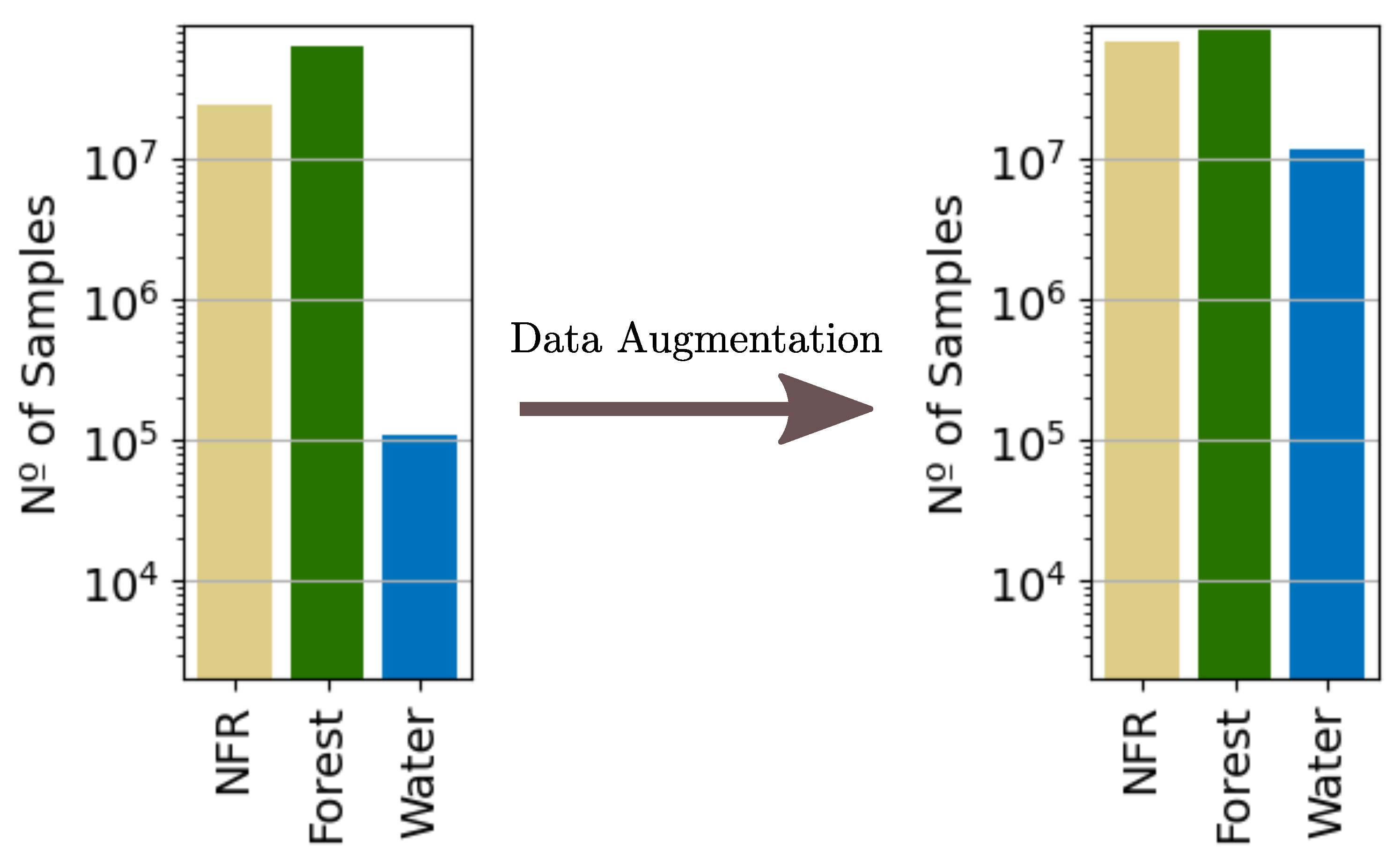
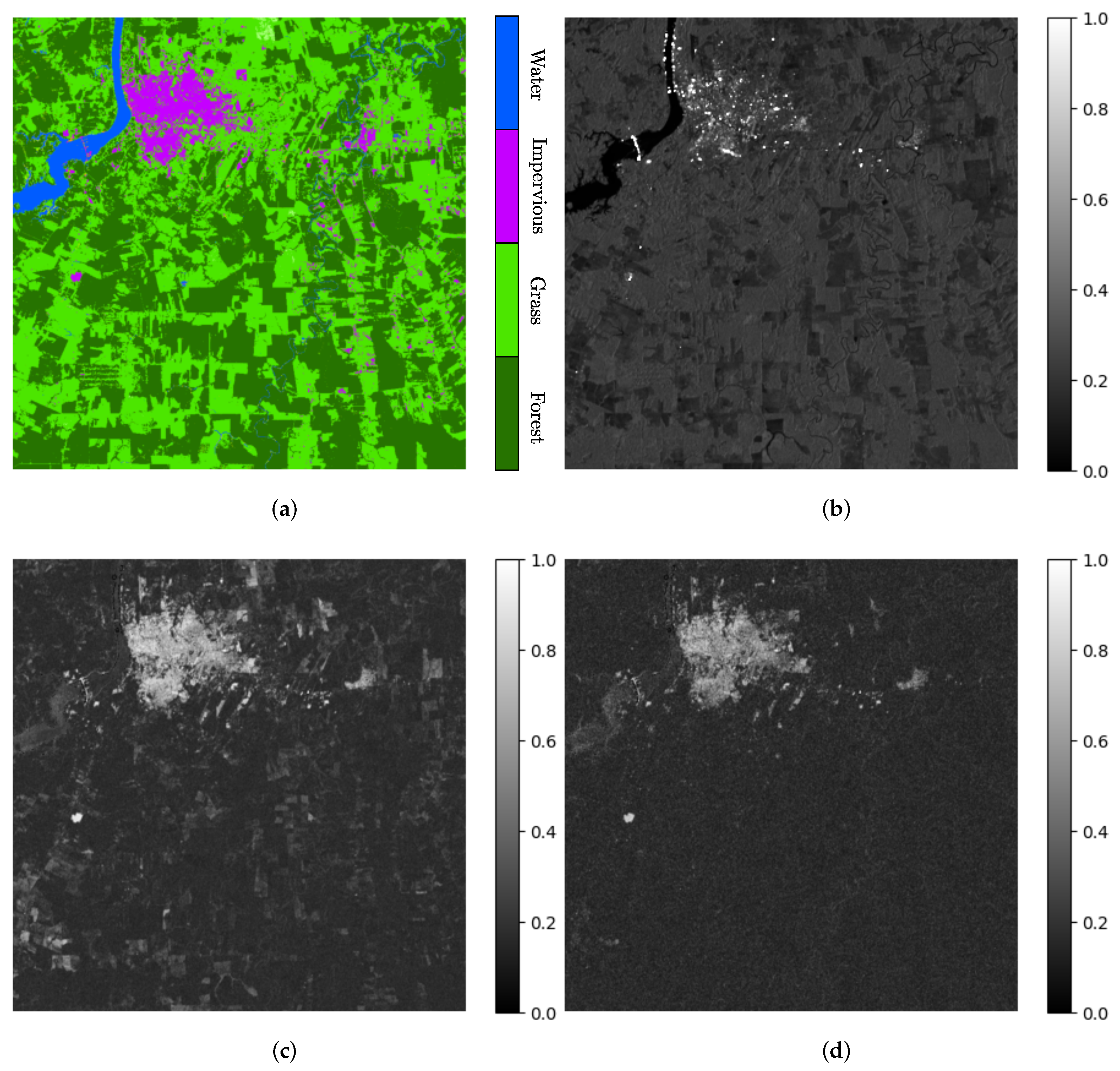
2.3. From-GLC Thematic Maps and Reference Database Generation
3. Methodology
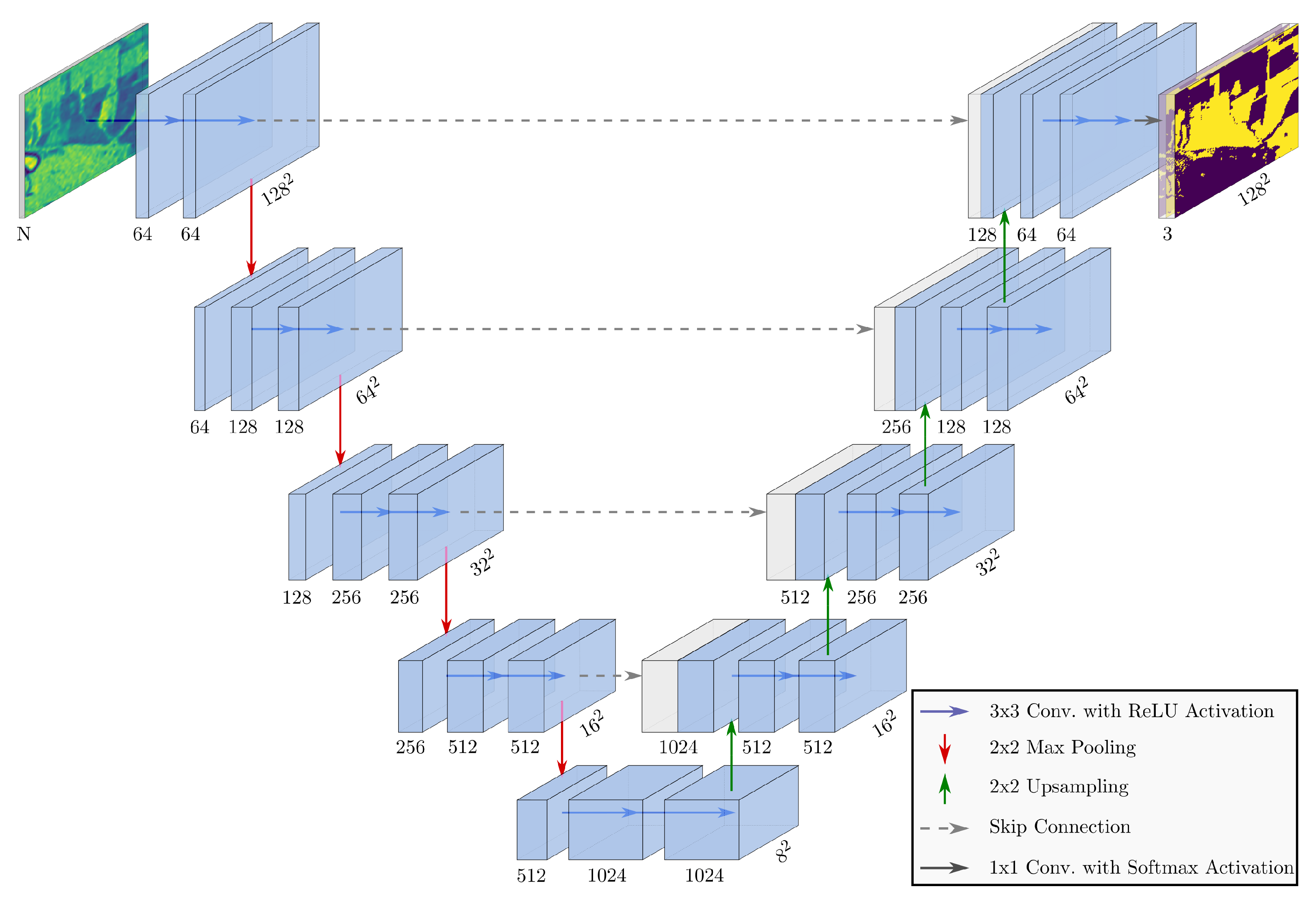
3.1. Proposed U-Net-Like Classification Model
3.2. Performance Evaluation Metrics
- True Positive (TP): data points correctly assigned to their class, i.e., the predicted label is the same as the ground truth;
- True Negative (TN): correct rejection of a given class;
- False Positive (FP): data points mistakenly predicted as the class under consideration;
- False Negative (FN): incorrect rejection of a class.
3.3. Experimental Setup
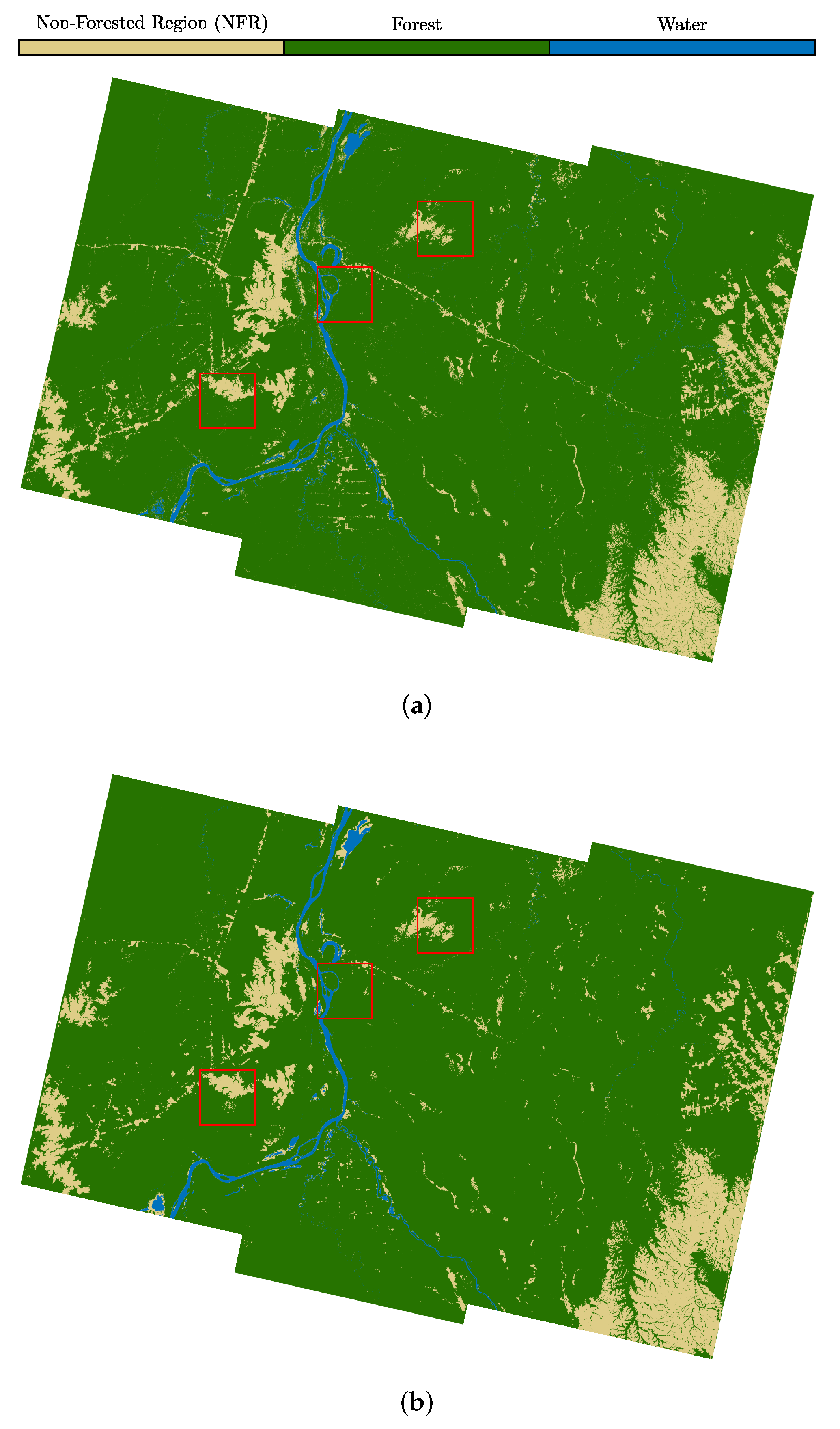
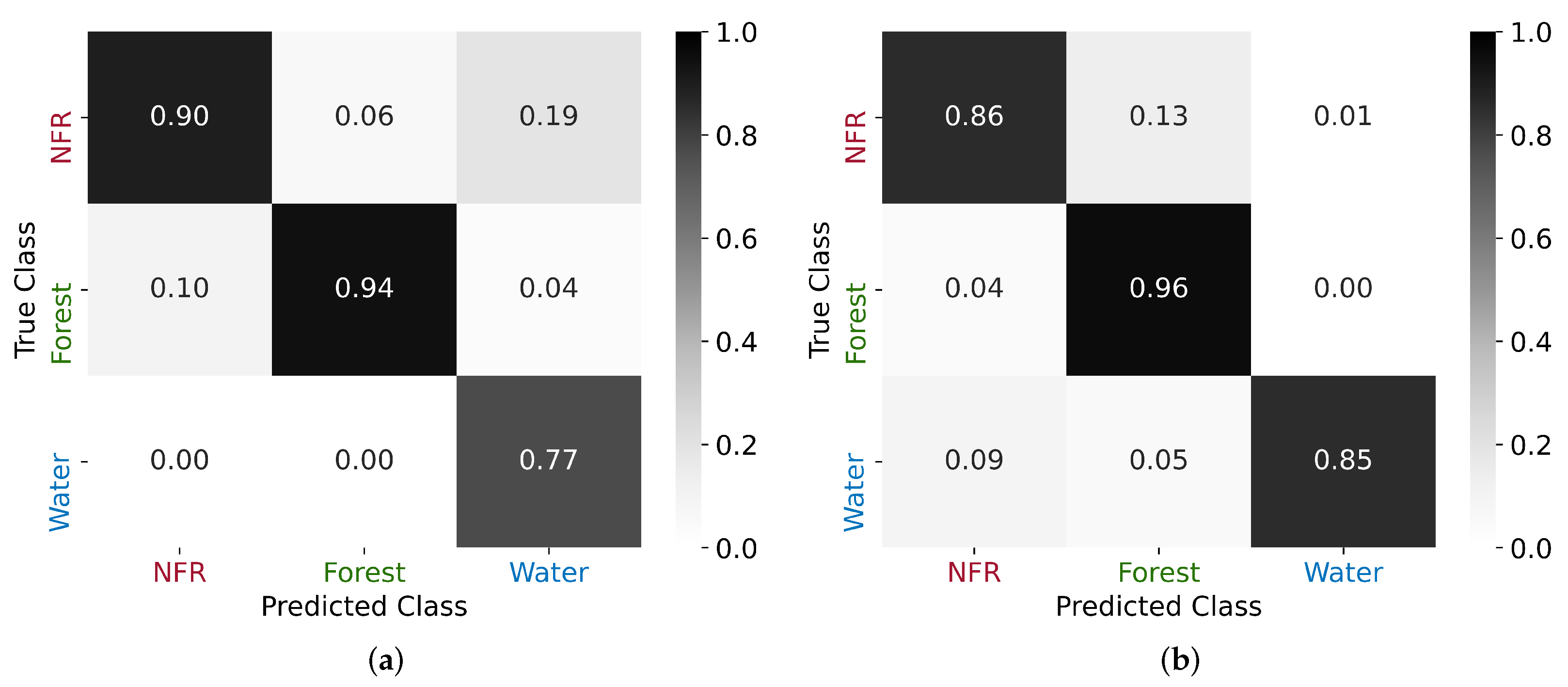
4. Results
Performance Evaluation
- Given a direct comparison (i.e., for the same baseline processing, training and test sets, and input features), the use of our CNN in case already achieved an improvement of more than five percentage points in both the overall F1-score and accuracy with respect to case I. Moreover, when comparing case to case , the performance gain was smaller—approximately 1.4 percentage points—but, most importantly, the computational load of case was extremely reduced since no specific computation of backscatter textures was required as in case ;
- Case and V make use of either the backscatter information or the stack of multi-temporal coherences, respectively, as input features to the CNN. In both cases, a small drop in the performance was visible with respect to all other CNN-based cases in which both backscatter and coherence were exploited. This confirmed the added value of combining both SAR intensity and interferometric information for classification purposes when utilizing STS;
- Case X achieved the best performance for every considered metric, although case might be deemed comparable in terms of F1-score and accuracy. Nevertheless, the required processing load was greatly reduced for case X, as both the backscatter texture estimation and the exponential model fitting of the temporal decorrelation were avoided in this setting. This suggests that the proposed CNN scheme was able to recognize by itself the temporal decorrelation patterns from the input multi-temporal coherence stacks;
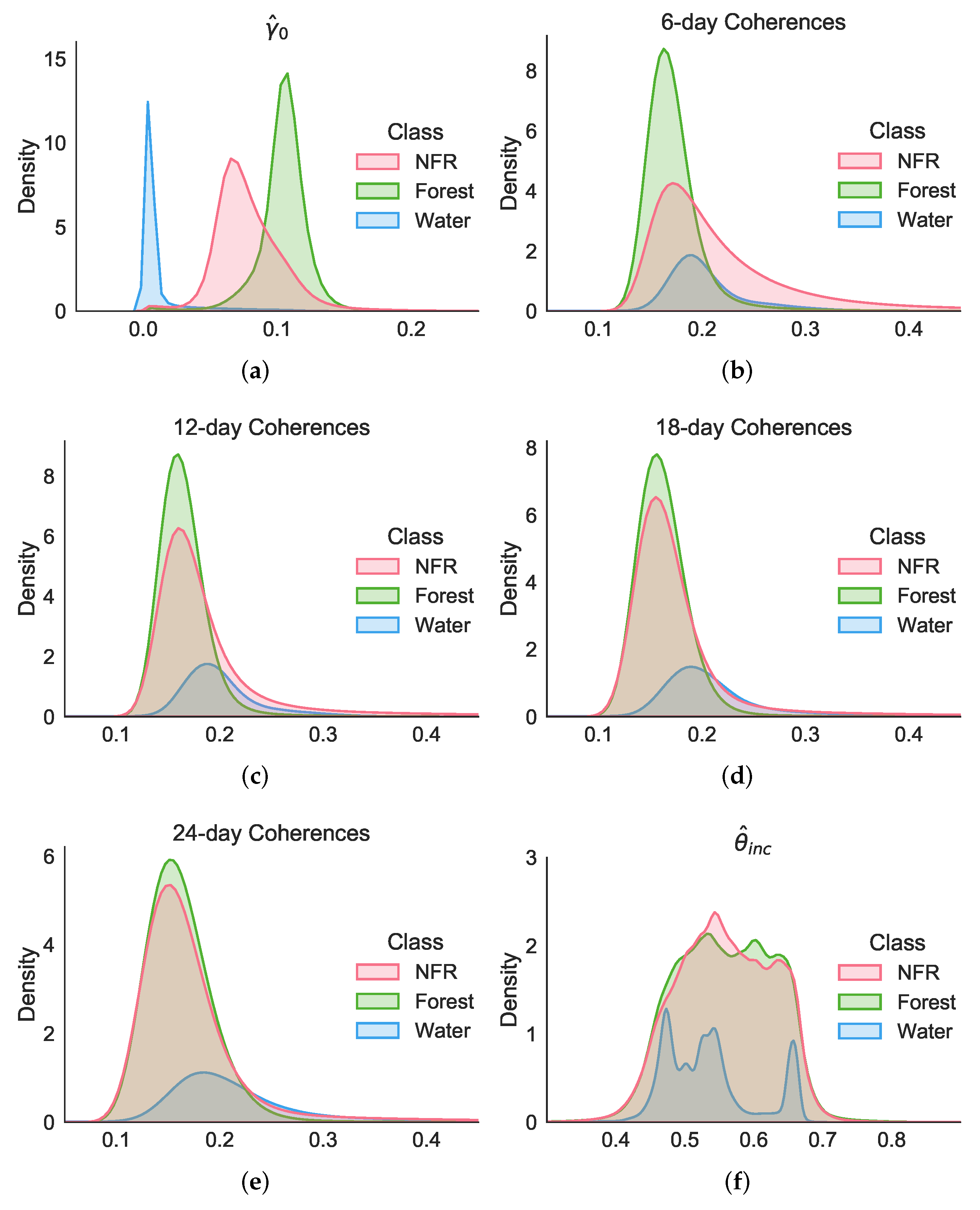
- It should also be noted that even when the 6 d coherence stack was not considered (see case ), an overall F1-score and accuracy above 90% could be achieved. Therefore, this method could be successfully applied at a global scale, where only S-1 temporal baselines of at least 12 d (for a single Sentinel-1 satellite) are available, overcoming the limitations of [23,24], which required short temporal baselines for the theoretical modeling of the temporal decorrelation;
- From the analysis of cases from to X, it becomes clear that coherences at low temporal baselines allowed for the retrieval of a higher information content for the discrimination between forested and non-forested areas. This behavior was expected, since, if forests are severely decorrelated already at 6 d temporal baselines, at higher temporal baselines, non-vegetated areas appear almost completely decorrelated as well, increasing the confusion between these two classes. On the other hand, the long-term coherence at a 24 d temporal baseline remains very helpful for the discrimination of impervious areas, such as urban settlements, characterized by the presence of stable targets on the ground. This aspect is further discussed later on in Section 5.2;
- It is also important to point out that the test set still remained quite imbalanced, with a predominance of Forest samples and underrepresentation of Water ones. Therefore, the per-class metrics should be interpreted with caution. For instance, the Water class will have a high accuracy in all cases since minority classes tend to have a high number of true negatives.
5. Discussion
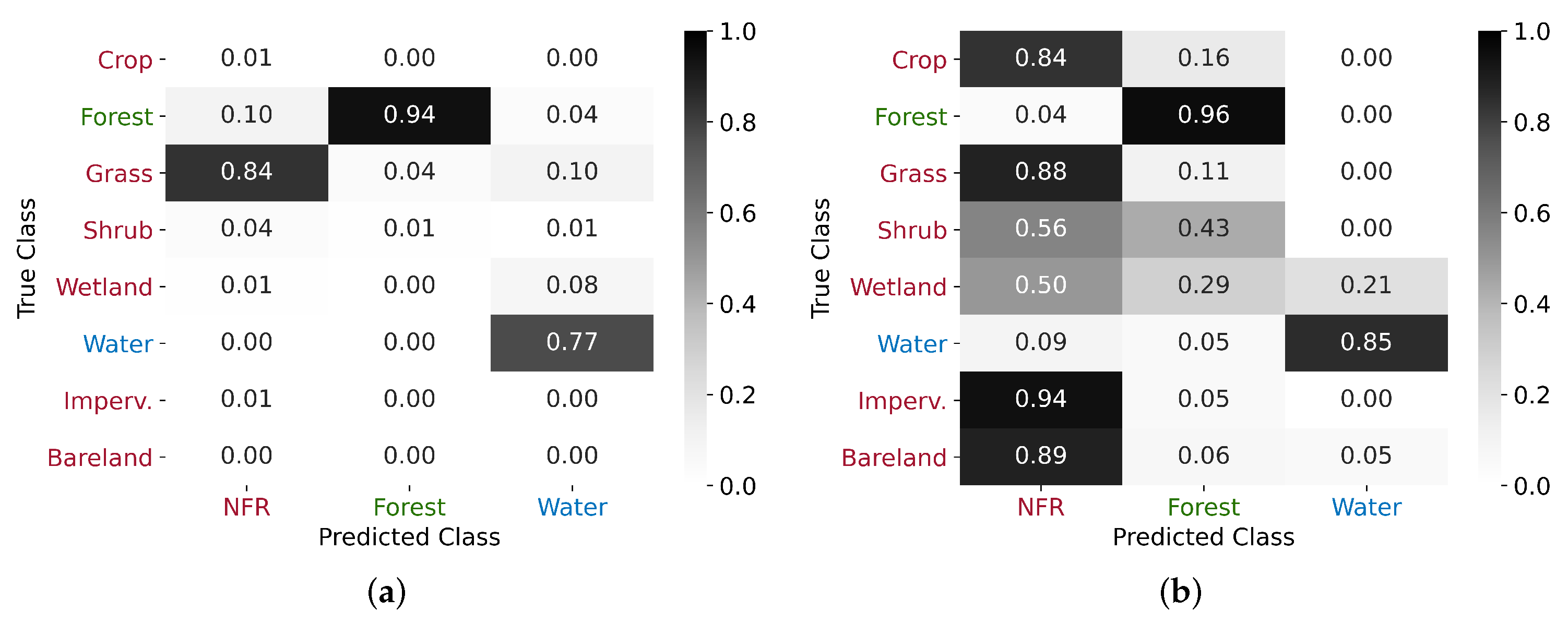
5.1. Class Assignment and Potential Confusion Sources
5.2. Impervious Areas and the Role of Short- and Long-Term Coherences
6. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- FAO. Global Forest Resources Assessment 2020: Main report; FAO: Rome, Italy, 2020; p. 184. [Google Scholar]
- Bravo, F.; Jandl, R.; LeMay, V.; Gadow, K. Managing Forest Ecosystems: The Challenge of Climate Change; Springer International Publishing: New York, NY, USA, 2008; p. 452. [Google Scholar]
- FAO; UNEP. The State of the World’s Forests 2020: Forests, Biodiversity and People; FAO and UNEP: Rome, Italy, 2020; p. 214. [Google Scholar]
- Lawrence, D.; Vandecar, K. Effects of tropical deforestation on climate and agriculture. Nat. Clim. Chang. 2015, 5, 27–36. [Google Scholar] [CrossRef]
- Monitoramento do Desmatamento da Floresta Amazônica Brasileira por Satélite. Available online: http://www.obt.inpe.br/OBT/assuntos/programas/amazonia/prodes (accessed on 26 August 2021).
- Diniz, C.G.; Souza, A.A.d.A.; Santos, D.C.; Dias, M.C.; Luz, N.C.d.; Moraes, D.R.V.d.; Maia, J.S.; Gomes, A.R.; Narvaes, I.d.S.; Valeriano, D.M.; et al. DETER-B: The New Amazon Near Real-Time Deforestation Detection System. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3619–3628. [Google Scholar] [CrossRef]
- Almeida, C.A.d.; Coutinho, A.C.; Esquerdo, J.C.D.M.; Adami, M.; Venturieri, A.; Diniz, C.G.; Dessay, N.; Durieux, L.; Gomes, A.R. High spatial resolution land use and land cover mapping of the Brazilian Legal Amazon in 2008 using Landsat-5/TM and MODIS data. Acta Amaz. 2016, 46, 291–302. [Google Scholar] [CrossRef]
- de Bem, P.P.; de Carvalho Junior, O.A.; Fontes Guimarães, R.; Trancoso Gomes, R.A. Change Detection of Deforestation in the Brazilian Amazon Using Landsat Data and Convolutional Neural Networks. Remote Sens. 2020, 12, 901. [Google Scholar] [CrossRef] [Green Version]
- Doblas, J.; Shimabukuro, Y.; Sant’Anna, S.; Carneiro, A.; Aragão, L.; Almeida, C. Optimizing Near Real-Time Detection of Deforestation on Tropical Rainforests Using Sentinel-1 Data. Remote Sens. 2020, 12, 3922. [Google Scholar] [CrossRef]
- Shimada, M.; Itoh, T.; Motooka, T.; Watanabe, M.; Shiraishi, T.; Thapa, R.; Lucas, R. New global forest/non-forest maps from ALOS PALSAR data (2007–2010). Remote Sens. Environ. 2014, 155, 13–31. [Google Scholar] [CrossRef]
- Reiche, J.; Mullissa, A.; Slagter, B.; Gou, Y.; Tsendbazar, N.E.; Odongo-Braun, C.; Vollrath, A.; Weisse, M.J.; Stolle, F.; Pickens, A.; et al. Forest disturbance alerts for the Congo Basin using Sentinel-1. Environ. Res. Lett. 2021, 16, 024005. [Google Scholar] [CrossRef]
- Copernicus Sentinel-1. Available online: https://sentinels.copernicus.eu/web/sentinel/missions/sentinel-1 (accessed on 3 September 2021).
- Krieger, G.; Moreira, A.; Fiedler, H.; Hajnsek, I.; Werner, M.; Younis, M.; Zink, M. TanDEM-X: A satellite formation for high-resolution SAR interferometry. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3317–3341. [Google Scholar] [CrossRef] [Green Version]
- Martone, M.; Rizzoli, P.; Wecklich, C.; González, C.; Bueso-Bello, J.L.; Valdo, P.; Schulze, D.; Zink, M.; Krieger, G.; Moreira, A. The global forest/non-forest map from TanDEM-X interferometric SAR data. Remote Sens. Environ. 2018, 205, 352–373. [Google Scholar] [CrossRef]
- Kuck, T.N.; Sano, E.E.; Bispo, P.d.C.; Shiguemori, E.H.; Silva Filho, P.F.F.; Matricardi, E.A.T. A Comparative Assessment of Machine-Learning Techniques for Forest Degradation Caused by Selective Logging in an Amazon Region Using Multitemporal X-Band SAR Images. Remote Sens. 2021, 13, 3341. [Google Scholar] [CrossRef]
- COSMO-SkyMed Mission and Products Description. Available online: https://earth.esa.int/eogateway/documents/20142/37627/COSMO-SkyMed-Mission-Products-Description.pdf (accessed on 4 October 2021).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, UK, 2016. [Google Scholar]
- Mazza, A.; Sica, F.; Rizzoli, P.; Scarpa, G. TanDEM-X forest mapping using convolutional neural networks. Remote Sens. 2019, 11, 2980. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- De Zan, F.; Monti Guarnieri, A. TOPSAR: Terrain Observation by Progressive Scans. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2352–2360. [Google Scholar] [CrossRef]
- Sica, F.; Pulella, A.; Nannini, M.; Pinheiro, M.; Rizzoli, P. Repeat-pass SAR interferometry for land cover classification: A methodology using Sentinel-1 Short-Time-Series. Remote Sens. Environ. 2019, 232, 111277. [Google Scholar] [CrossRef]
- Pulella, A.; Aragão Santos, R.; Sica, F.; Posovszky, P.; Rizzoli, P. Multi-Temporal Sentinel-1 Backscatter and Coherence for Rainforest Mapping. Remote Sens. 2020, 12, 847. [Google Scholar] [CrossRef] [Green Version]
- Unser, M. Sum and Difference Histograms for Texture Classification. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 118–125. [Google Scholar] [CrossRef] [PubMed]
- Ferretti, A.; Prati, C.; Rocca, F. Permanent scatterers in SAR interferometry. IEEE Trans. Geosci. Remote Sens. 2001, 39, 8–20. [Google Scholar] [CrossRef]
- Jacob, A.W.; Vicente-Guijalba, F.; Lopez-Martinez, C.; Lopez-Sanchez, J.; Litzinger, M.; Kristen, H.; Mestre-Quereda, A.; Ziolkowski, D.; Lavalle, M.; Notarnicola, C.; et al. Sentinel-1 InSAR Coherence for Land Cover Mapping: A Comparison of Multiple Feature-Based Classifiers. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 535–552. [Google Scholar] [CrossRef] [Green Version]
- Batistella, M.; Robeson, S.; Moran, E. Settlement Design, Forest Fragmentation, and Landscape Change in Rondonia, Amazonia. Photogramm. Eng. Remote Sens. 2003, 69, 805–812. [Google Scholar] [CrossRef] [Green Version]
- Prats, P.; Rodriguez-Cassola, M.; Marotti, L.; Nannini, M.; Wollstadt, S.; Schulze, D.; Tous-Ramon, N.; Younis, M.; Krieger, G.; Reigber, A. TAXI: A Versatile Processing Chain for Experimental TanDEM-X Product Evaluation. In Proceedings of the IEEE Geoscience and Remote Sensing Symposium, Honolulu, HI, USA, 25–30 July 2010; pp. 1–4. [Google Scholar]
- Yague-Martinez, N.; Prats-Iraola, P.; Gonzalez, F.R.; Brcic, R.; Shau, R.; Geudtner, D.; Eineder, M.; Bamler, R. Interferometric processing of Sentinel-1 TOPS data. IEEE Trans. Geosci. Remote Sens. 2016, 54, 2220–2234. [Google Scholar] [CrossRef] [Green Version]
- Gong, P.; Liu, H.; Zhang, M.; Li, C.; Wang, J.; Huang, H.; Clinton, N.; Ji, L.; Li, W.; Bai, Y.; et al. Stable classification with limited sample: Transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. Coursera Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Hawkings, R.; Attema, E.; Crapolicchio, R.; Lecomte, P.; Closa, J.; Meadows, P.; Srivastava, S.K. Stability of Amazon Backscatter at C-Band: Spaceborne Results from ERS-1/2 and RADARSAT-1. In Proceedings of the CEOS SAR Workshop 1999, Toulouse, France, 26–29 October 2000. [Google Scholar]
- Piantanida, R.; Miranda, N.; Franceschi, N.; Meadows, P. Thermal Denoising of Products Generated by the S-1 IPF; Technical Report; European Space Agency (ESA): Paris, France, 2017. [Google Scholar]
- Rees, G. The Remote Sensing Data Book; Cambridge University Press: Cambridge, UK, 1999. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Satellite platform | Sentinel-1A, Sentinel-1B |
| Orbital node | Descending |
| Acquisition mode | Interferometric Wide Swath (IW) |
| Center frequency | 5.405 GHz, C-band |
| Data product | Single-Look Complex (SLC) images |
| Revisit time | 6 d |
| Stack[orbit] | Observation Period | Master Date | Center Coordinates | |
|---|---|---|---|---|
| Latitude | Longitude | |||
| TS1010 | 25.04.19–19.05.19 | 07.05.19 | 8°43′22.08″ S | 60°48′27.36″ W |
| TS2010 | 10°14′31.02″ S | 61°09′11.52″ W | ||
| TS3010 | 11°44′22.56″ S | 61°30′21.06″ W | ||
| TS4010 | 13°12′30.24″ S | 61°51′05.76″ W | ||
| TS1054 | 28.04.19–22.05.19 | 10.05.19 | 9°08′25.44″ S | 67°04′17.76″ W |
| TS1083 | 24.04.19–18.05.19 | 06.05.19 | 7°51′05.76″ S | 62°39′54.72″ W |
| TS2083 | 9°25′42.24″ S | 63°01′30.72″ W | ||
| TS3083 | 10°57′17.28″ S | 63°22′40.08″ W | ||
| TS4083 | 12°28′26.04″ S | 63°43′50.88″ W | ||
| TS1156 | 29.04.19–23.05.19 | 11.05.19 | 8°43′22.08″ S | 64°55′07.68″ W |
| TS2156 | 9°33′28.08″ S | 65°06′21.06″ W | ||
| TS3156 | 10°09′46.08″ S | 65°14′55.09″ W | ||
| Approach | # | Backscatter | Exp. Model | Geom. | Coh. Stacks | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Textures | ||||||||||
| RF [23] | I | ● | - | ● | ● | ● | - | - | - | - |
| RF [24] | ● | ● | ● | ● | ● | - | - | - | - | |
| CNN | ● | - | ● | ● | ● | - | - | - | - | |
| CNN | - | - | - | - | ● | ● | ● | ● | ● | |
| V | ● | - | - | - | ● | - | - | - | - | |
| ● | - | - | - | ● | ● | - | - | - | ||
| ● | - | - | - | ● | - | ● | - | - | ||
| ● | - | - | - | ● | ● | - | - | ● | ||
| ● | - | - | - | ● | - | ● | - | ● | ||
| X | ● | - | - | - | ● | ● | ● | ● | ● | |
| # | Metrics | Classes | Mean | Overall | ||
|---|---|---|---|---|---|---|
| NFR | Forest | Water | ||||
| I | F1-Score | 78.41% | 91.26% | 61.85% | 77.17% | 87.20% |
| Accuracy | 87.44% | 87.85% | 98.93% | 91.41% | 87.11% | |
| F1-Score | 80.81% | 92.17% | 69.56% | 80.85% | 88.62% | |
| Accuracy | 88.86% | 89.10% | 99.18% | 92.38% | 88.57% | |
| F1-Score | 87.15% | 94.92% | 79.99% | 87.35% | 92.50% | |
| Accuracy | 92.64% | 92.87% | 99.55% | 95.02% | 92.53% | |
| F1-Score | 79.21% | 90.19% | 58.15% | 75.85% | 86.65% | |
| Accuracy | 87.13% | 86.73% | 98.78% | 90.88% | 86.32% | |
| V | F1-Score | 81.30% | 92.56% | 64.66% | 79.51% | 88.98% |
| Accuracy | 89.13% | 89.56% | 99.42% | 92.70% | 89.05% | |
| F1-Score | 84.25% | 93.47% | 81.05% | 86.26% | 90.65% | |
| Accuracy | 90.70% | 90.94% | 99.60% | 93.75% | 90.62% | |
| F1-Score | 82.65% | 92.91% | 80.80% | 85.45% | 89.79% | |
| Accuracy | 89.88% | 90.11% | 99.59% | 93.19% | 89.79% | |
| F1-Score | 84.89% | 93.28% | 80.26% | 86.15% | 90.70% | |
| Accuracy | 90.64% | 90.88% | 99.56% | 93.69% | 90.54% | |
| F1-Score | 83.21% | 93.97% | 80.52% | 85.90% | 90.69% | |
| Accuracy | 91.07% | 91.28% | 99.57% | 93.97% | 90.96% | |
| X | F1-Score | 87.73% | 95.18% | 80.91% | 87.94% | 92.85% |
| Accuracy | 92.99% | 93.21% | 99.58% | 95.26% | 92.89% | |
| No. of samples | 16,157,783 | 38,624,552 | 579,201 | 55,361,536 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dal Molin, R., Jr.; Rizzoli, P. Potential of Convolutional Neural Networks for Forest Mapping Using Sentinel-1 Interferometric Short Time Series. Remote Sens. 2022, 14, 1381. https://doi.org/10.3390/rs14061381
Dal Molin R Jr., Rizzoli P. Potential of Convolutional Neural Networks for Forest Mapping Using Sentinel-1 Interferometric Short Time Series. Remote Sensing. 2022; 14(6):1381. https://doi.org/10.3390/rs14061381
Chicago/Turabian StyleDal Molin, Ricardo, Jr., and Paola Rizzoli. 2022. "Potential of Convolutional Neural Networks for Forest Mapping Using Sentinel-1 Interferometric Short Time Series" Remote Sensing 14, no. 6: 1381. https://doi.org/10.3390/rs14061381
APA StyleDal Molin, R., Jr., & Rizzoli, P. (2022). Potential of Convolutional Neural Networks for Forest Mapping Using Sentinel-1 Interferometric Short Time Series. Remote Sensing, 14(6), 1381. https://doi.org/10.3390/rs14061381