
Multi-Output Network Combining GNN and CNN for Remote Sensing Scene Classification




Abstract
:1. Introduction
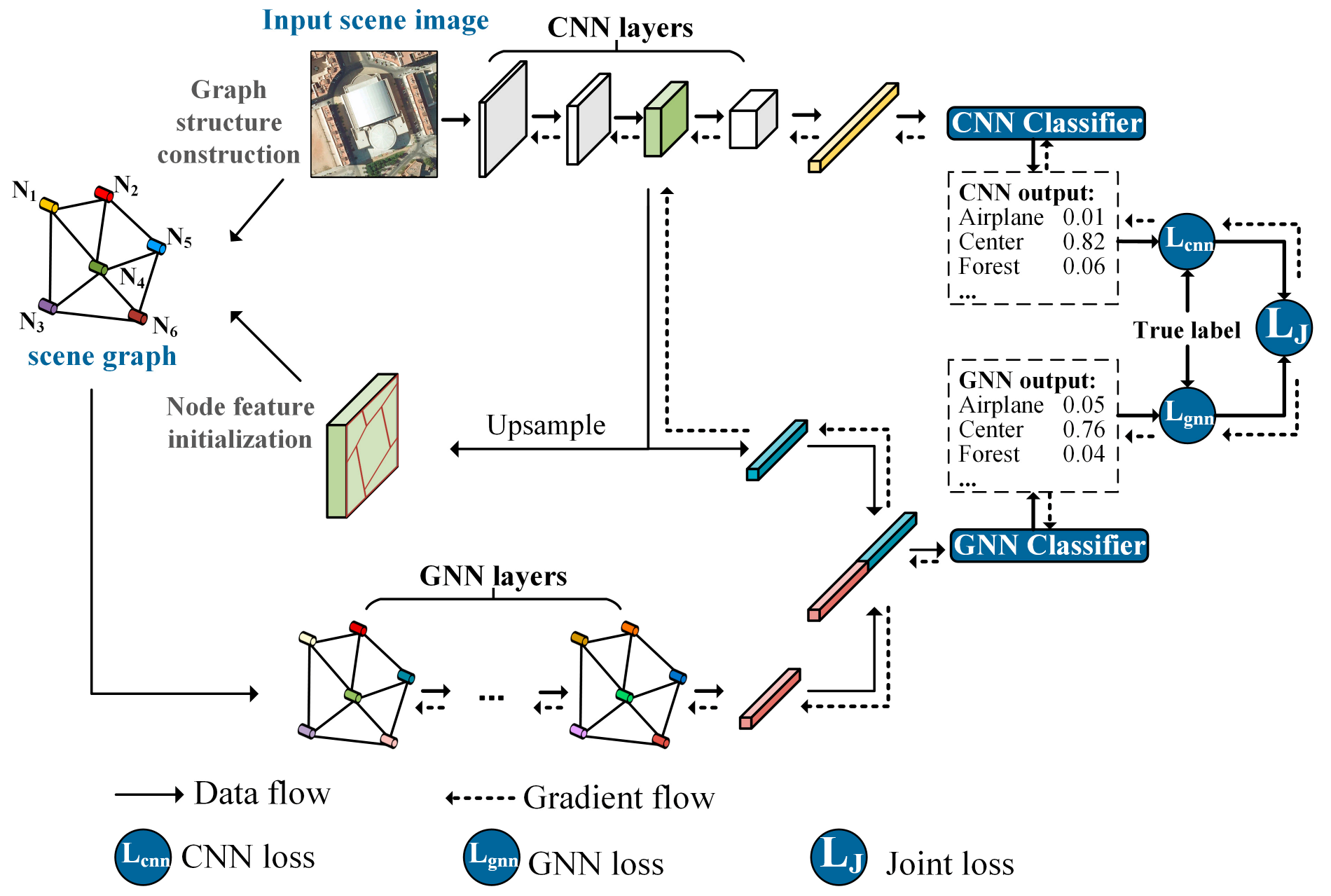
2. Methods
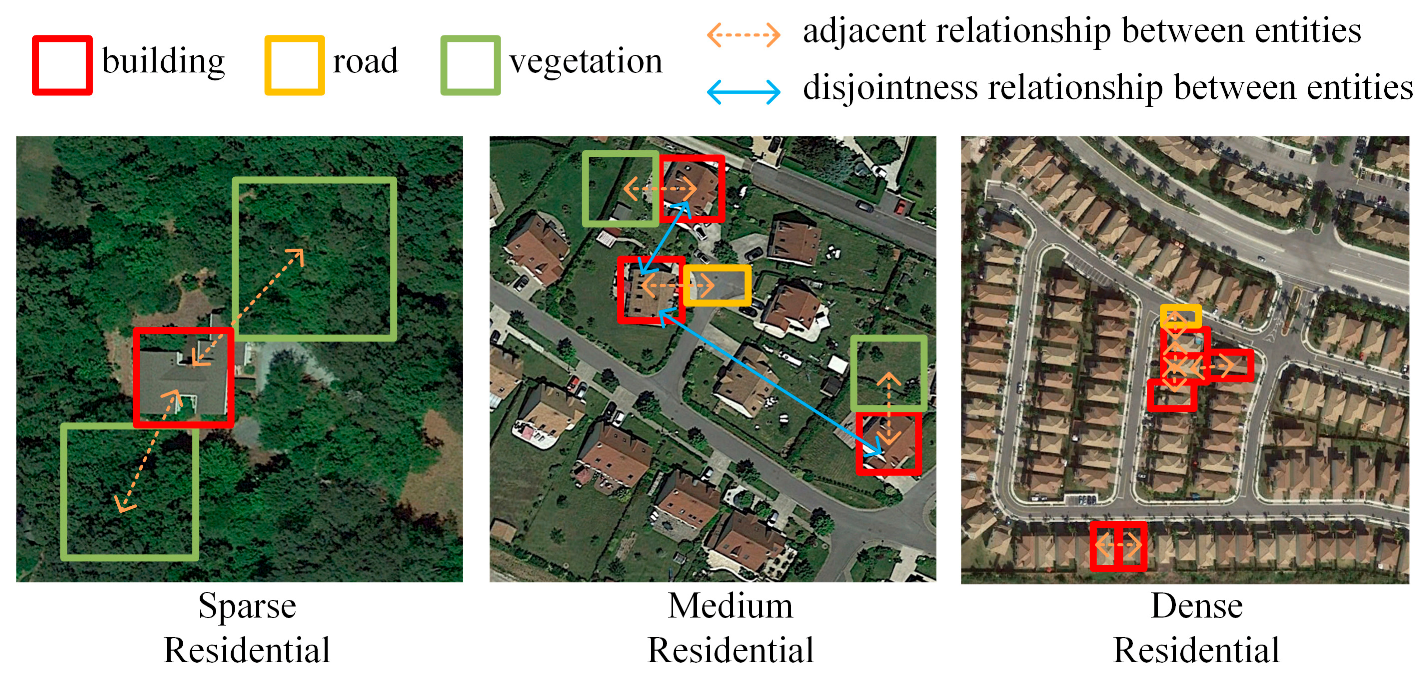
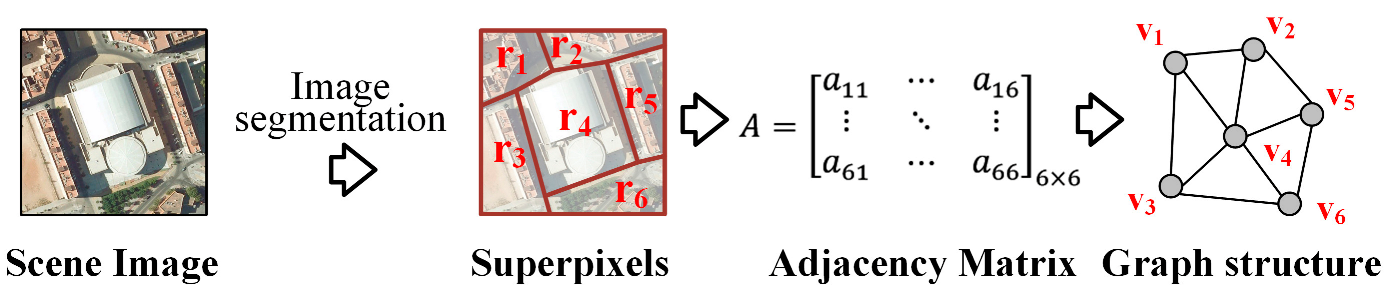
2.1. Graph Structure Construction
2.2. Node Feature Matrix Initialization
2.3. Encoders and Classifiers in MopNet
2.3.1. Global Visual Feature Vector Extraction from the CNN Encoder
2.3.2. Global Graph Representations from the GNN Encoder
2.3.3. Multi-Output Logits of MopNet from Classifiers
2.4. Loss Function of MopNet
| Algorithm 1. Training process of MopNet. |
| Input: RS images I, adjacent matrix A, segmented superpixel regions R and true labels y in training set. Output: GNN parameters , CNN parameters and parameters of classifiers . Learning MopNet:
|
3. Experiments and Results
3.1. Experimental Data Sets
3.2. Experimental Settings
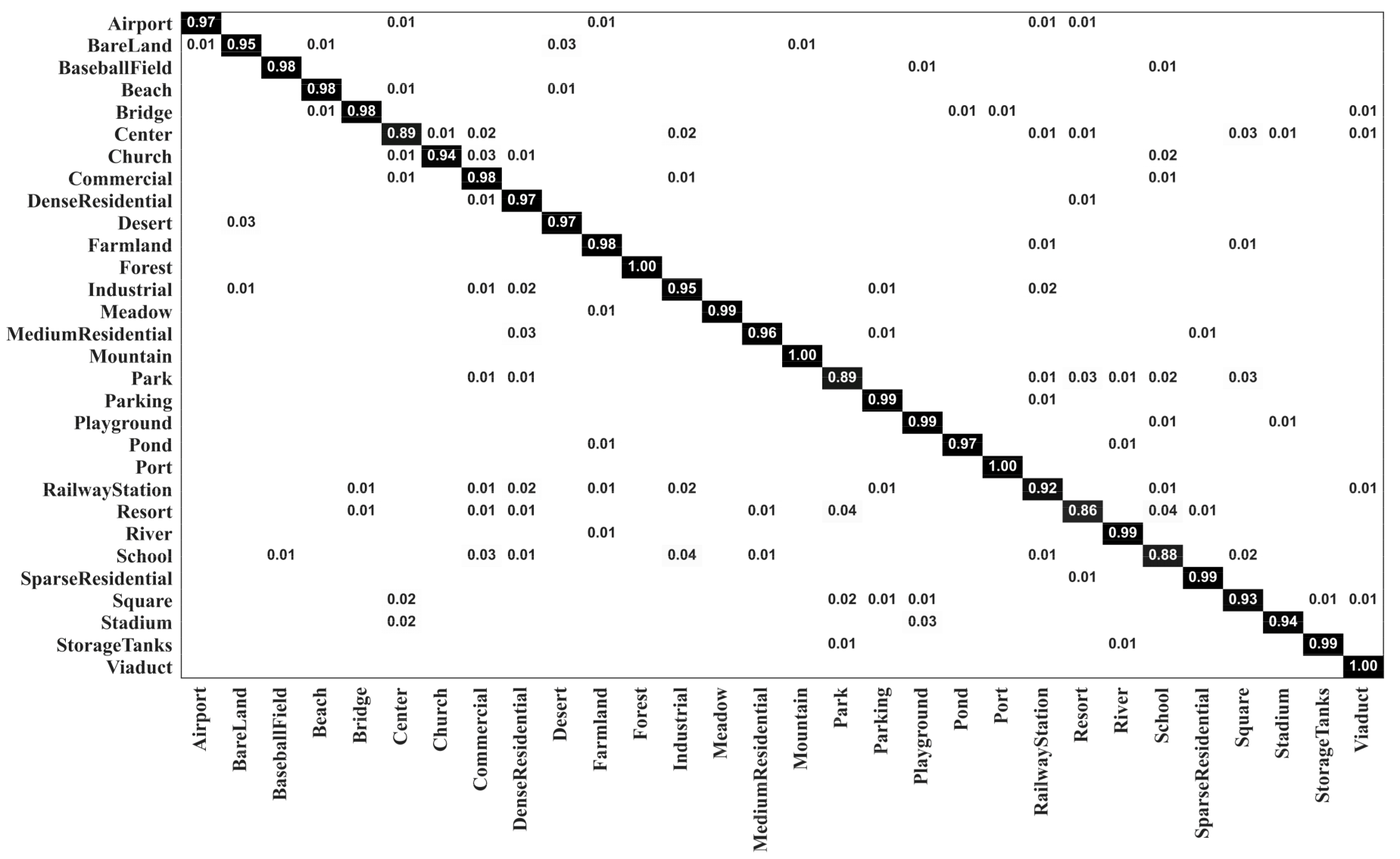
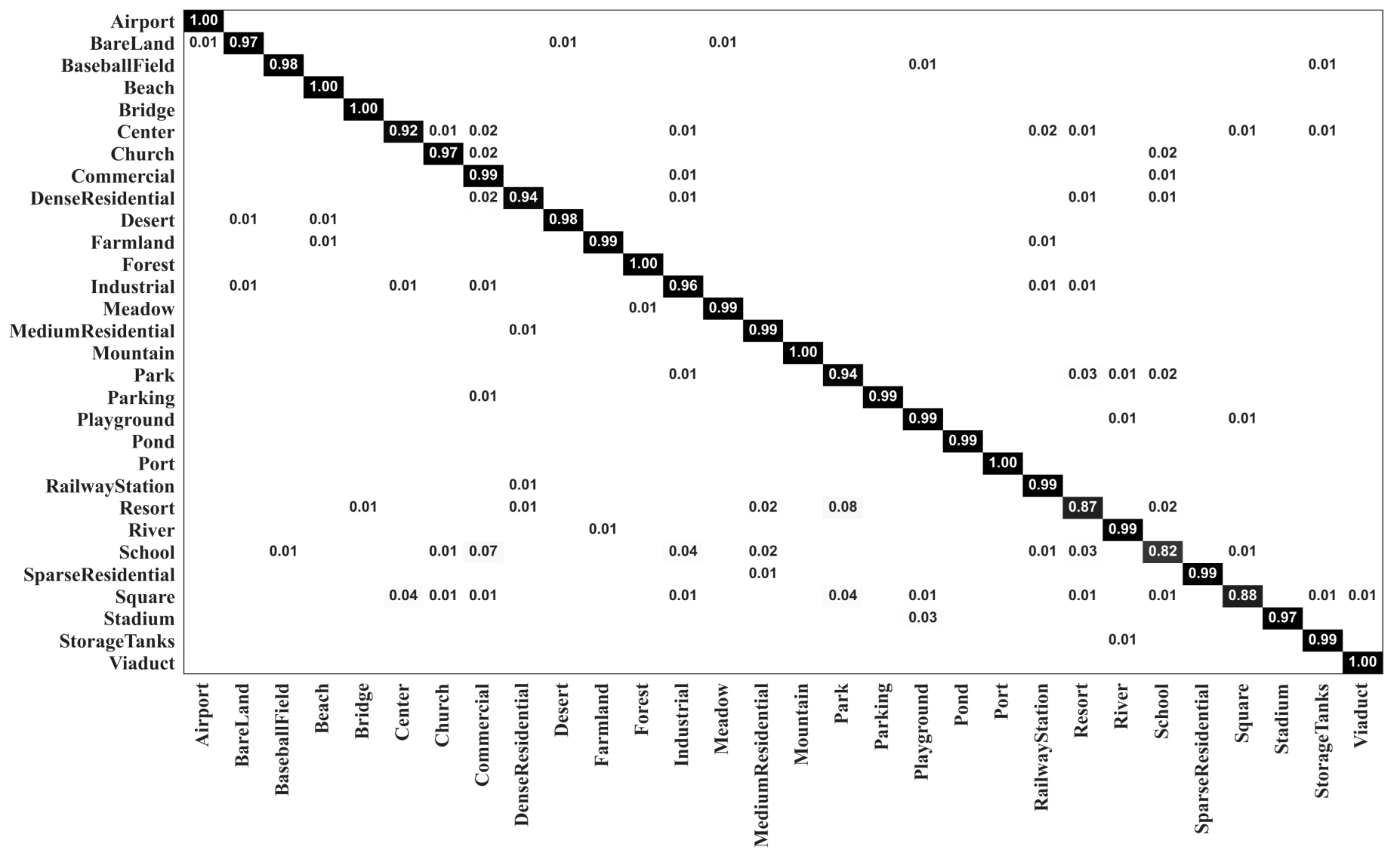
3.3. Scene Classification Results
3.3.1. Results under Different Balance Parameters
3.3.2. Results of MopNet on the OPTIMAL-31 Dataset
3.3.3. Results of MopNet on the AID Dataset
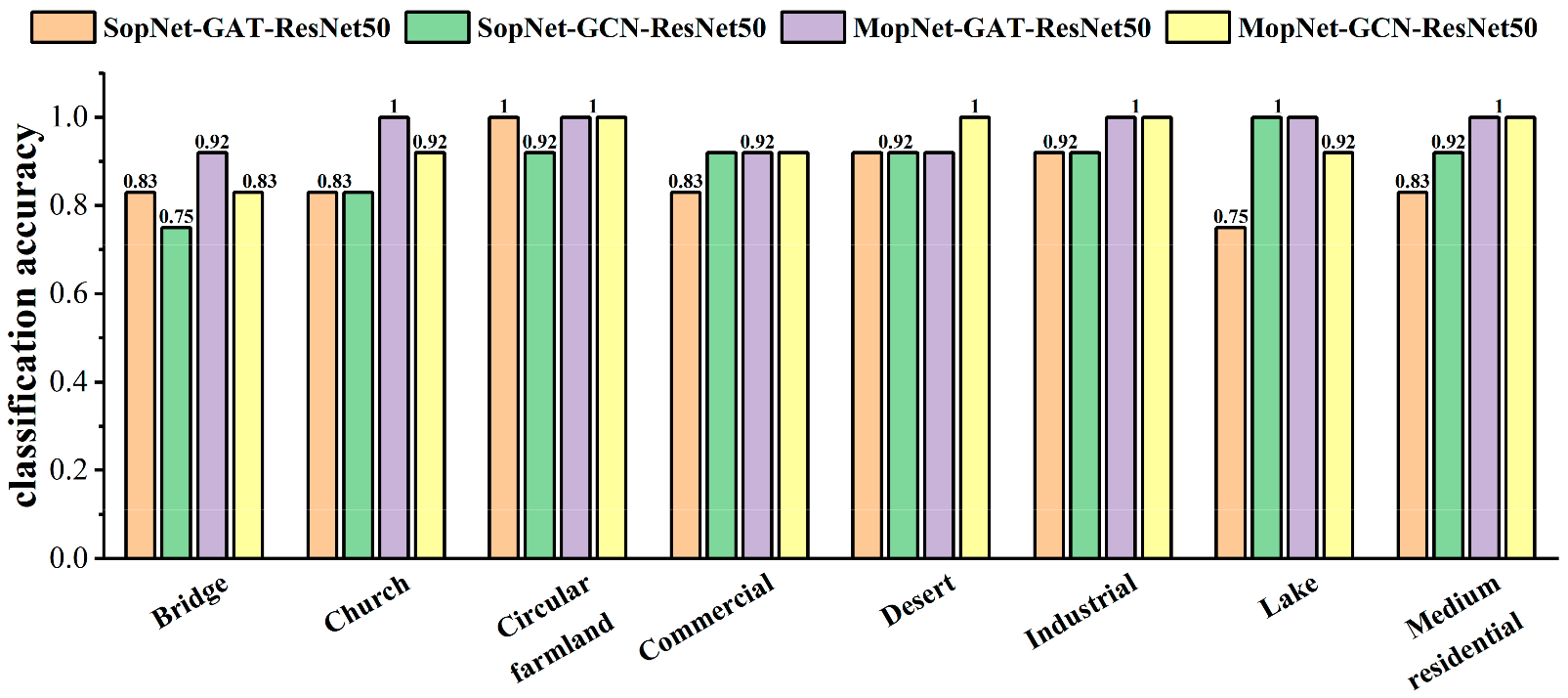
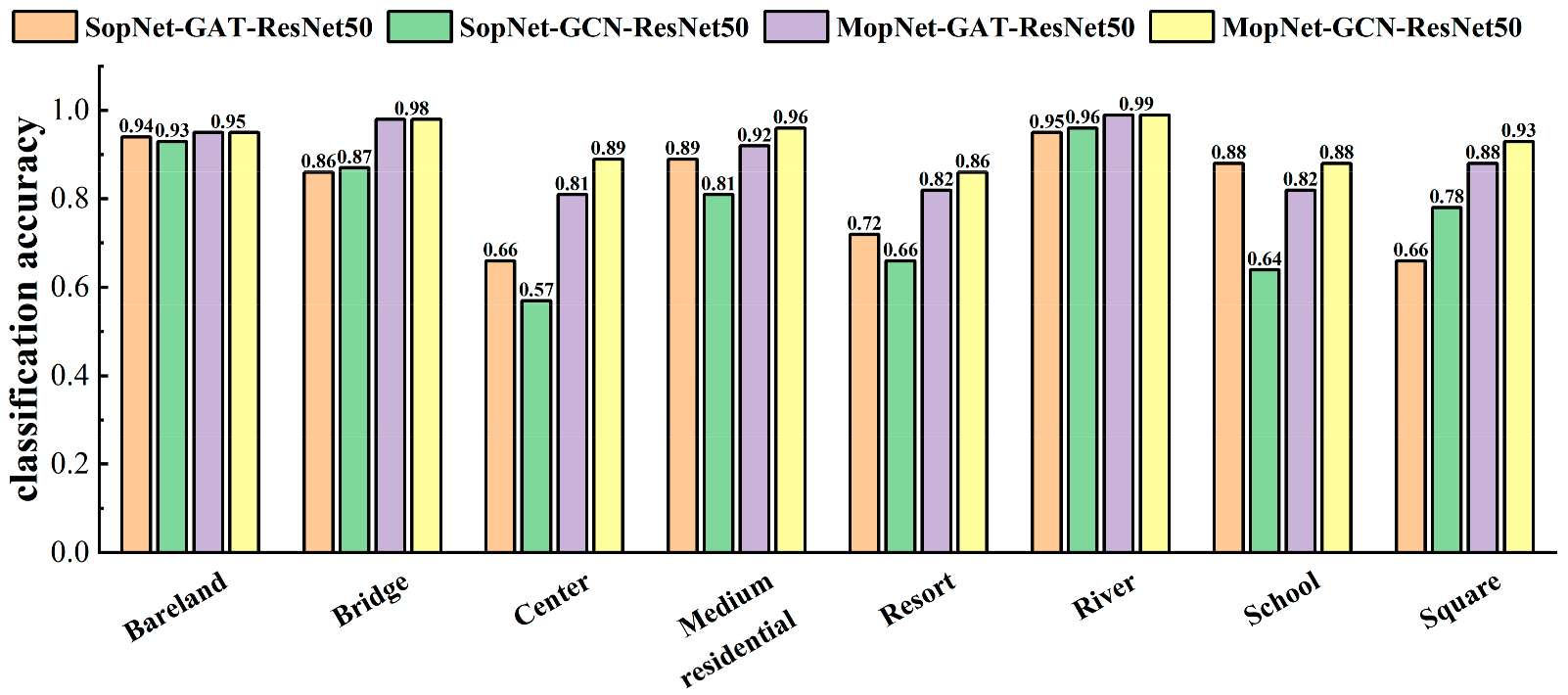
3.3.4. Comparison Results of MopNet and SopNet
4. Discussion
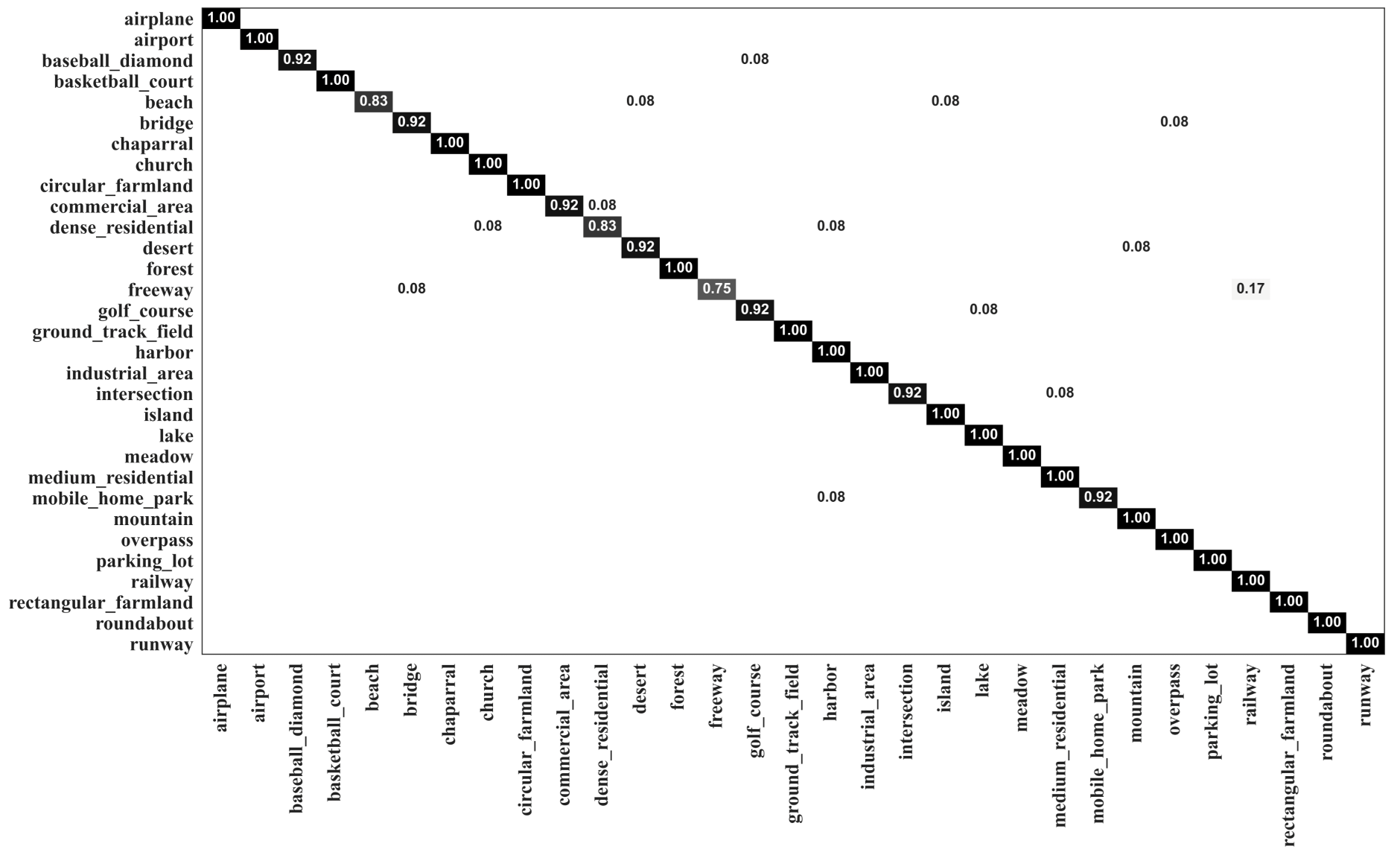
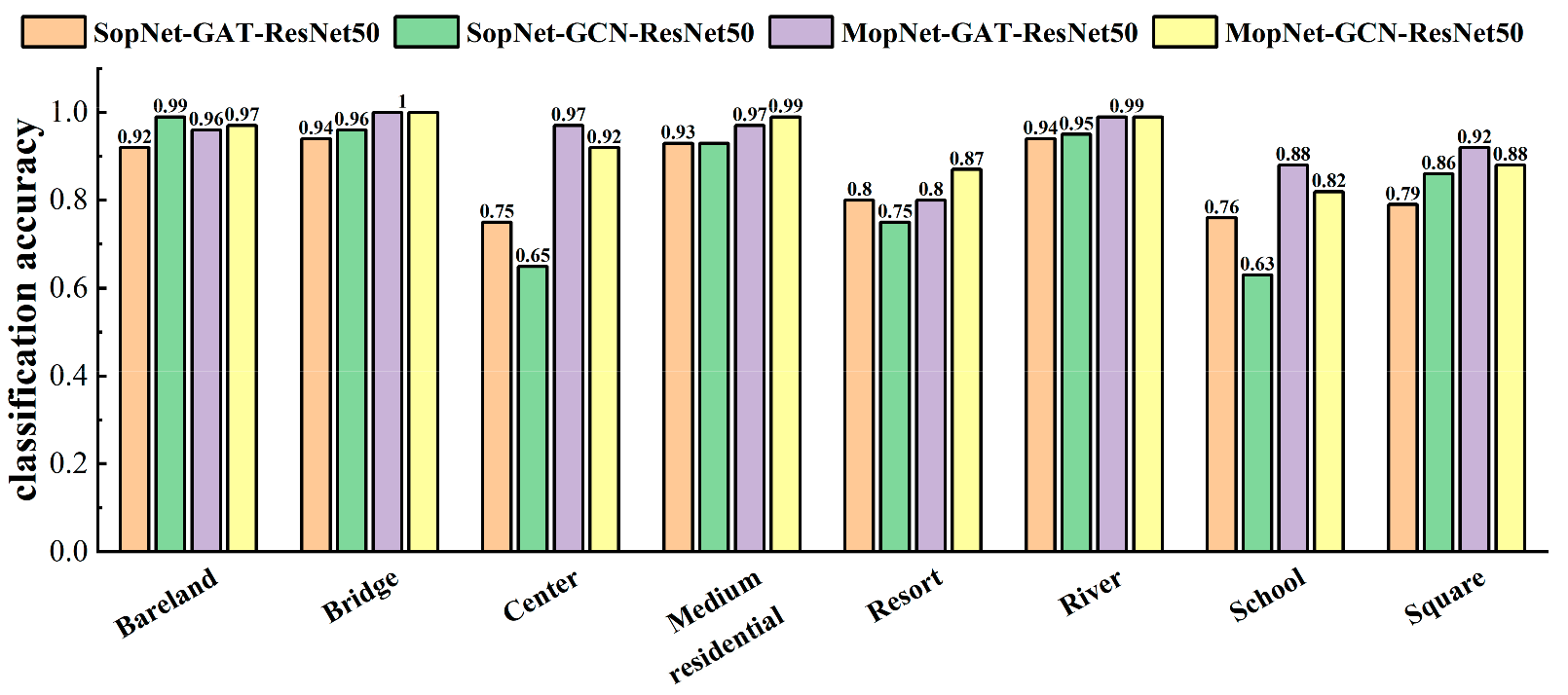
4.1. Effectiveness of MopNet for Various Categories
4.2. Contribution of the GNN and CNN in MopNet to Scene Classification
- (1)
- The GNN-based branch employs spatial and topological relationships imbedded in RS images, leading to an improved classification accuracy of MopNet. The GNN compensates for the shortcoming of the CNN by representing features in non-Euclidean space. Given that the balance parameter λ was suggested to be set as 0.7 by the comparison experiments, the GNN plays an important role in minimizing the joint loss of the MopNet. Moreover, the contribution of the GNN to MopNet can also be drawn from the comparison between our MopNet and GLDBS [34]. GLDBS [34] used two CNNs as the backbones of two branches, unlike our MopNet, which has a GNN branch beside a CNN branch. It is difficult for models such as GLDBS to effectively learn the spatial and topological information. The experimental results show that our MopNet obtained higher overall accuracies than GLDBS on the AID dataset.
- (2)
- The CNN-based branch helps to improve the performance and stability of MopNet. As shown in Table 3 and Table 4, MopNet obtained higher overall accuracies (OAs) and lower standard deviations of OAs in comparison to the corresponding SopNet, which did not involve the CNN prediction in the optimized objective of the model. As shown in Figure 9, Figure 10 and Figure 11, MopNet achieved obvious accuracy improvements in comparison to the corresponding SopNet for various categories, such as commercial and industrial in the OPTIMAL-31 dataset and center, resort, school, and square in the AID dataset. SopNet suffers from the effect of uncertainties caused by image segmentation and graph structure construction for images of these categories. For MopNet, the CNN-based branch helps to reduce the effect and thus improve the stability.
4.3. Differences between MopNets and Existing Methods Combining CNN and GNN
- (1)
- Training strategy: A training strategy of jointly learning CNN and GNN was adopted in MopNet. The parameters of the CNN and GNN in MopNet are updated simultaneously with the guidance of a joint loss via the backpropagation mechanism. In contrast, the method in [24] adopts the step-by-step training strategy, training the CNN and the GNN separately. The parameters of the CNN and GNN in [24] were not simultaneously optimized as in our MopNet. The classification performance of the GNN in [24] may suffer from the effect of the representation ability of the CNN.
- (2)
- Prediction output: The experimental results indicate that the MopNet obtained higher classification accuracies with more robustness than the corresponding SopNet that did not involve the CNN output in the optimized objective. Moreover, our MopNet regarded both outputs of the GNN and CNN as the optimized objective, unlike the method in [32] using the GNN prediction alone. Our MopNet obtained better classification results than the method in [32]. In the future, MopNet will be investigated with more CNN backbones and various GNN backbones.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cheng, G.; Xie, X.; Han, J.; Xia, G.S. Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3735–3756. [Google Scholar] [CrossRef]
- Egenhofer, M.J.; Franzosa, R.D. Point-set topological spatial relations. Int. J. Geogr. Inf. Syst. 1991, 5, 161–174. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Q.; Zhong, Y.; Zhao, B.; Xia, G.; Zhang, L. Bag-of-Visual-Words Scene Classifier with Local and Global Features for High Spatial Resolution Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 747–751. [Google Scholar] [CrossRef]
- Zhao, L.J.; Tang, P.; Huo, L.Z. Land-use scene classification using a concentric circle-structured multiscale bag-of-visual-words model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4620–4631. [Google Scholar] [CrossRef]
- Dong, R.; Xu, D.; Jiao, L.; Zhao, J.; An, J. A Fast Deep Perception Network for Remote Sensing Scene Classification. Remote Sens. 2020, 12, 729. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Wang, C.; Ma, Z.; Chen, J.; He, D.; Ackland, S. Remote Sensing Scene Classification Based on Convolutional Neural Networks Pre-Trained Using Attention-Guided Sparse Filters. Remote Sens. 2018, 10, 290. [Google Scholar] [CrossRef] [Green Version]
- Hu, F.; Xia, G.-S.; Hu, J.; Zhang, L. Transferring Deep Convolutional Neural Networks for the Scene Classification of High-Resolution Remote Sensing Imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef] [Green Version]
- Gu, Y.; Wang, Y.; Li, Y. A Survey on Deep Learning-Driven Remote Sensing Image Scene Understanding: Scene Classification, Scene Retrieval and Scene-Guided Object Detection. Appl. Sci. 2019, 9, 2110. [Google Scholar] [CrossRef] [Green Version]
- Pires de Lima, R.; Marfurt, K. Convolutional Neural Network for Remote-Sensing Scene Classification: Transfer Learning Analysis. Remote Sens. 2020, 12, 86. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When Deep Learning Meets Metric Learning: Remote Sensing Image Scene Classification via Learning Discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Akodad, S.; Bombrun, L.; Xia, J.; Berthoumieu, Y.; Germain, C. Ensemble Learning Approaches Based on Covariance Pooling of CNN Features for High Resolution Remote Sensing Scene Classification. Remote Sens. 2020, 12, 3292. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Kilian, Q.W. Densely connected convolutional networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, J.; Tian, J.; Zhuo, L.; Zhang, J. Residual Dense Network Based on Channel-Spatial Attention for the Scene Classification of a High-Resolution Remote Sensing Image. Remote Sens. 2020, 12, 1887. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, P.; Zhao, L. Remote Sensing Image Scene Classification Using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Lin, D.; Wang, Y.; Xu, G.; Zhang, Y.; Ding, C.; Zhou, Y. Deep Discriminative Representation Learning with Attention Map for Scene Classification. Remote Sens. 2020, 12, 1366. [Google Scholar] [CrossRef]
- Shi, C.; Zhao, X.; Wang, L. A Multi-Branch Feature Fusion Strategy Based on an Attention Mechanism for Remote Sensing Image Scene Classification. Remote Sens. 2021, 13, 1950. [Google Scholar] [CrossRef]
- Li, M.; Lei, L.; Tang, Y.; Sun, Y.; Kuang, G. An Attention-Guided Multilayer Feature Aggregation Network for Remote Sensing Image Scene Classification. Remote Sens. 2021, 13, 3113. [Google Scholar] [CrossRef]
- Li, Q.; Yan, D.; Wu, W. Remote Sensing Image Scene Classification Based on Global Self-Attention Module. Remote Sens. 2021, 13, 4542. [Google Scholar] [CrossRef]
- Xu, C.; Zhu, G.; Shu, J. A Lightweight and Robust Lie Group-Convolutional Neural Networks Joint Representation for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Shen, J.; Zhang, T.; Wang, Y.; Wang, R.; Wang, Q.; Qi, M. A Dual-Model Architecture with Grouping-Attention-Fusion for Remote Sensing Scene Classification. Remote Sens. 2021, 13, 433. [Google Scholar] [CrossRef]
- Li, Y.; Chen, R.; Zhang, Y.; Zhang, M.; Chen, L. Multi-Label Remote Sensing Image Scene Classification by Combining a Convolutional Neural Network and a Graph Neural Network. Remote Sens. 2020, 12, 4003. [Google Scholar] [CrossRef]
- Manzo, M.; Rozza, A. DOPSIE: Deep-Order Proximity and Structural Information Embedding. Mach. Learn. Knowl. Extr. 2019, 1, 684–697. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [Green Version]
- Gao, Y.; Shi, J.; Li, J.; Wang, R. Remote sensing scene classification based on high-order graph convolutional network. Eur. J. Remote Sens. 2021, 54 (Suppl. S1), 141–155. [Google Scholar] [CrossRef]
- Ouyang, S.; Li, Y. Combining Deep Semantic Segmentation Network and Graph Convolutional Neural Network for Semantic Segmentation of Remote Sensing Imagery. Remote Sens. 2021, 13, 119. [Google Scholar] [CrossRef]
- Liu, H.; Xu, D.; Zhu, T.; Shang, F.; Liu, Y.; Lu, J.; Yang, R. Graph Convolutional Networks by Architecture Search for PolSAR Image Classification. Remote Sens. 2021, 13, 1404. [Google Scholar] [CrossRef]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Yang, P.; Tong, L.; Qian, B.; Gao, Z.; Yu, J.; Xiao, C. Hyperspectral Image Classification with Spectral and Spatial Graph Using Inductive Representation Learning Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 791–800. [Google Scholar] [CrossRef]
- Liang, J.; Deng, Y.; Zeng, D. A Deep Neural Network Combined CNN and GCN for Remote Sensing Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4325–4338. [Google Scholar] [CrossRef]
- Ren, X.; Malik, J. Learning a classification model for segmentation, Computer Vision. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003. [Google Scholar]
- Xu, K.; Huang, H.; Deng, P. Remote Sensing Image Scene Classification Based on Global-Local Dual-Branch Structure Model. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Müller, R.; Kornblith, S.; Hinton, G. When does label smoothing help? arXiv 2019, arXiv:1906.02629. [Google Scholar]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene Classification with Recurrent Attention of VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1155–1167. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient Graph-Based Image Segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Wang, M.; Zheng, D.; Ye, Z.; Gan, Q.; Li, M.; Song, X.; Zhou, J.; Ma, C.; Yu, L.; Gai, Y.; et al. Deep graph library: A graph-centric, highly-performant package for graph neural networks. arXiv 2019, arXiv:1909.01315. [Google Scholar]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision Transformers for Remote Sensing Image Classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Lv, Y.; Zhang, X.; Xiong, W.; Cui, Y.; Cai, M. An End-to-End Local-Global-Fusion Feature Extraction Network for Remote Sensing Image Scene Classification. Remote Sens. 2019, 11, 3006. [Google Scholar] [CrossRef] [Green Version]
- Liu, N.; Celik, T.; Li, H.C. MSNet: A Multiple Supervision Network for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Bazi, Y.; Al Rahhal, M.M.; Alhichri, H.; Alajlan, N. Simple Yet Effective Fine-Tuning of Deep CNNs Using an Auxiliary Classification Loss for Remote Sensing Scene Classification. Remote Sens. 2019, 11, 2908. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Ren, Y.; Parr, G.; Guan, Y.; Shao, L. Invariant Deep Compressible Covariance Pooling for Aerial Scene Categorization. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6549–6561. [Google Scholar] [CrossRef]
- Xie, J.; He, N.; Fang, L.; Plaza, A. Scale-Free Convolutional Neural Network for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6916–6928. [Google Scholar] [CrossRef]
- Tang, X.; Ma, Q.; Zhang, X.; Liu, F.; Ma, J.; Jiao, L. Attention consistent network for remote sensing scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2030–2045. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | No. of Classes | Total Number of Images | No. of Images per Class | Image Size (in pixels) | Training Ratio |
|---|---|---|---|---|---|
| OPTIMAL-31 [38] | 31 | 1860 | 60 | 256 | 80% |
| Aerial Image Dataset (AID) [39] | 30 | 1000 | 220–420 | 600 | 20%, 50% |
| Overall Accuracy (%) | |
|---|---|
| 0.1 | 95.16 ± 0.47 |
| 0.2 | 95.32 ± 0.46 |
| 0.3 | 95.34 ± 0.31 |
| 0.4 | 95.03 ± 0.57 |
| 0.5 | 95.16 ± 0.47 |
| 0.6 | 95.30 ± 0.55 |
| 0.7 | 96.06 ± 0.31 |
| 0.8 | 95.16 ± 0.38 |
| 0.9 | 94.62 ± 0.26 |
| Methods | OA (80% Training) |
|---|---|
| Fine-tuning ResNet50 [43] | 90.46 ± 0.38 |
| ARCNet-ResNet [38] | 91.28 ± 0.45 |
| MSNet [44] | 93.92 ± 0.41 |
| EfficientNet-B3-aux [45] | 94.51 ± 0.75 |
| ResNet_LGFFE [43] | 94.55 ± 0.36 |
| IDCCP with ResNet50-512 [46] | 94.89 ± 0.22 |
| Vision transformer [42] | 95.56 ± 0.18 |
| DM-GAF [23] | 96.24 ± 1.10 |
| SopNet-GCN-ResNet50 | 93.37 ± 0.68 |
| MopNet-GCN-ResNet50 (Ours) | 95.34 ± 0.31 |
| SopNet-GAT-ResNet50 | 93.55 ± 0.71 |
| MopNet-GAT-ResNet50 (Ours) | 96.06 ± 0.31 |
| Methods | OA (20%) | OA (50%) |
|---|---|---|
| Fine-tuning ResNet50 [43] | 86.48 ± 0.49 | 89.22 ± 0.34 |
| ResNet_LGFFE [43] | 90.83 ± 0.55 | 94.46 ± 0.48 |
| ACNET [48] | 93.33 ± 0.29 | 95.38 ± 0.29 |
| DM-GAF [23] | 94.05 ± 0.10 | 96.12 ± 0.14 |
| EfficientNet-B3-aux [45] | 94.19 ± 0.15 | 96.56 ± 0.14 |
| SFCNN [47] | 93.60 ± 0.12 | 96.66 ± 0.11 |
| Combined CNN with GCN [32] | 94.93 ± 0.31 | 96.70 ± 0.28 |
| DCNN [10] | 90.82 ± 0.16 | 96.89 ± 0.10 |
| IDCCP with ResNet50-512 [46] | 94.80 ± 0.18 | 96.95 ± 0.13 |
| MSNet [44] | 95.59 ± 0.15 | 96.97 ± 0.27 |
| GLDBS [34] | 95.45 ± 0.19 | 97.01 ± 0.22 |
| SopNet-GCN-ResNet50 | 89.06 ± 0.39 | 93.56 ± 0.28 |
| MopNet-GCN-ResNet50 (Ours) | 95.53 ± 0.11 | 97.11 ± 0.07 |
| SopNet-GAT-ResNet50 | 91.26 ± 0.43 | 95.16 ± 0.16 |
| MopNet-GAT-ResNet50 (Ours) | 95.16 ± 0.16 | 96.75 ± 0.11 |
| Class | Node Counts | Class | Node Counts | Class | Node Counts |
|---|---|---|---|---|---|
| airplane | 131 ± 27 | desert | 133 ± 54 | medium residential | 210 ± 28 |
| airport | 194 ± 30 | forest | 197 ± 47 | mobile home park | 219 ± 26 |
| baseball diamond | 135 ± 33 | freeway | 162 ± 35 | mountain | 204 ± 49 |
| basketball court | 181 ± 38 | golf course | 135 ± 28 | overpass | 179 ± 33 |
| beach | 129 ± 38 | ground track field | 189 ± 37 | parking lot | 192 ± 23 |
| bridge | 120 ± 31 | harbor | 163 ± 24 | railway | 194 ± 32 |
| chaparral | 185 ± 37 | industrial | 226 ± 27 | rectangular farmland | 135 ± 47 |
| church | 198 ± 31 | intersection | 201 ± 22 | roundabout | 193 ± 26 |
| circular farmland | 154 ± 42 | island | 96 ± 30 | runway | 112 ± 28 |
| commercial | 212 ± 24 | lake | 147 ± 49 | ||
| dense residential | 243 ± 16 | meadow | 93 ± 33 |
| Class | Node Counts | Class | Node Counts | Class | Node Counts |
|---|---|---|---|---|---|
| airport | 123 ± 36 | farmland | 70 ± 34 | port | 124 ± 53 |
| bare land | 46 ± 26 | forest | 74 ± 37 | railway station | 142 ± 50 |
| baseball field | 108 ± 29 | industrial | 175 ± 53 | resort | 153 ± 57 |
| beach | 55 ± 33 | meadow | 24 ± 15 | river | 72 ± 30 |
| bridge | 73 ± 31 | medium residential | 159 ± 45 | school | 190 ± 53 |
| center | 158 ± 51 | mountain | 105 ± 49 | sparse residential | 101 ± 21 |
| church | 204 ± 36 | park | 132 ± 42 | square | 155 ± 51 |
| commercial | 170 ± 52 | parking | 211 ± 41 | stadium | 163 ± 44 |
| dense residential | 228 ± 45 | play ground | 101 ± 33 | storage | 159 ± 47 |
| desert | 27 ± 21 | pond | 72 ± 30 | viaduct | 126 ± 43 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, F.; Lu, W.; Tan, W.; Qi, K.; Zhang, X.; Zhu, Q. Multi-Output Network Combining GNN and CNN for Remote Sensing Scene Classification. Remote Sens. 2022, 14, 1478. https://doi.org/10.3390/rs14061478
Peng F, Lu W, Tan W, Qi K, Zhang X, Zhu Q. Multi-Output Network Combining GNN and CNN for Remote Sensing Scene Classification. Remote Sensing. 2022; 14(6):1478. https://doi.org/10.3390/rs14061478
Chicago/Turabian StylePeng, Feifei, Wei Lu, Wenxia Tan, Kunlun Qi, Xiaokang Zhang, and Quansheng Zhu. 2022. "Multi-Output Network Combining GNN and CNN for Remote Sensing Scene Classification" Remote Sensing 14, no. 6: 1478. https://doi.org/10.3390/rs14061478
APA StylePeng, F., Lu, W., Tan, W., Qi, K., Zhang, X., & Zhu, Q. (2022). Multi-Output Network Combining GNN and CNN for Remote Sensing Scene Classification. Remote Sensing, 14(6), 1478. https://doi.org/10.3390/rs14061478