1. Introduction
Agricultural nutrient management is complicated by soil variability. The variation in soil fertility to support optimal crop production is a global concern. The growth in crop production was found to decelerate in all regions, particularly in developed countries and also in East Asia [
1]. Several factors limit agricultural production by affecting crops, namely climatic, edaphic and biotic factors. At present, the major cause of declining global crop production is soil degradation. Soil degradation, as measured by diminishing fertility, is a key factor limiting the crop yield in many regions of the world, including India’s north-eastern region [
2]. The spatial variability of soil nutrients is affected by the landform, soil type, vegetation, climate and different anthropogenic activities. Moreover, hilly and mountainous regions influence the spatial variability of soils due to the wide range of environmental factors. Improper application of fertilizers in highly variable soils has increasingly become a serious threat to sustainable crop production and, at the same time, fertilizer losses have some associated environmental hazards [
3,
4]. On the other hand, deficiency of nutrients is more prevalent in all agricultural soils and crops. Blanket fertilizer application in fields often leads to over and under input application [
5]. To achieve a high return with less adverse impacts on the environment, fertilizer application in excess should be avoided [
6]. Hence, the calibration of fertilizer rates based on estimates to achieve a targeted yield is required to address spatial variability within targeted fields [
7,
8]. Therefore, efficient techniques should be implemented to precisely gauge variations in soil attributes within the fields, which is important for delineating homogeneous management zones (MZs) [
9]. Wide variation in content, as well as in the availability of soil nutrients is present both within and between the fields [
5]. Most of these studies were based on agro-ecological zones that were similar in topography, climate and the major soil types. The wide variation within the study area was hypothesized considering varying degrees of terrain attributes that affect soil biogeochemical properties. In the predictive models, different covariates, e.g., terrain factors, climate and remotely sensed imagery, are widely used [
10]. However, terrain with digital elevation model (DEM) derivatives would be the main predictor variable, as it is easily quantified and correlated directly with the state factors [
11].
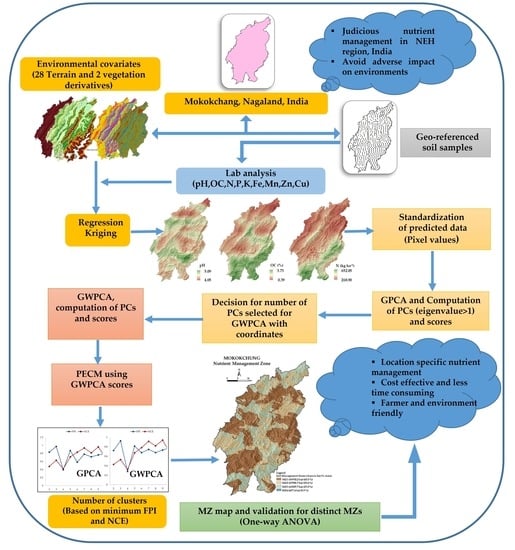
Recently, digital soil mapping (DSM) approaches have been used to estimate the distribution of soil attributes at spatial scales [
12]. The delineation of MZs with the aid of DSM helps to enhance site-specific nutrient management (SSNM) more sustainably. The delineation of management zones (MZs) by creating several subsets in an area based on homogeneous soil or plant properties is the most popular [
13]. However, to delineate the proper MZs of an area, better know-how regarding soil fertility status is of utmost importance and ultimately assists in better crop management and environmental protection. Several scholars have employed principal component analysis (PCA) and fuzzy c-means clustering to designate MZs based on soil properties, among other approaches [
14,
15,
16]. In addition to this, numerous alternate methods viz. top sheet and soil survey [
17], crop yield-based management zone techniques [
18,
19] and nutrient index techniques [
20,
21,
22] were utilized for delineating management zones.
Recently, two prime steps involved in the delineation of MZs are the use of PCA to reduce the dataset and their subsequent classification into management areas by using cluster analysis. PCA is mostly used to characterize the relationship between attributes and related environmental factors, and the subsequent quantification of the spatial variability pattern of these attributes [
23,
24,
25]. However, the major limitation of any standard aspatial statistic is that it does not account for geographical variations in the observed value or any relationship between them [
26]. Moreover, PCA does not consider spatial relationships and was not designed for the identification of spatial structures [
27]. Geographically weighted PCA (GWPCA) can be used to address such limitations of PCA in which weights are fixed based on the location of each sampling point [
26,
28]. This methodology is used to study the correlation between each soil attribute and locally derived components, and thus consider geographic variations in numerous soil attributes across space. Later work involves several cluster analyses, and several researchers have used several clustering techniques to classify management zones, such as c-means [
29], possibilistic c-means (PCM) [
30], and fuzzy c-means (FCM) [
9]. However, possibilistic fuzzy c-means (PFCM), which inherits the properties of both PCM and FCM, has a better clustering algorithm that reduces the coincidence of clustering as well as noisy sensitivity. Therefore, PFCM gives more value to typicality or membership values [
31].
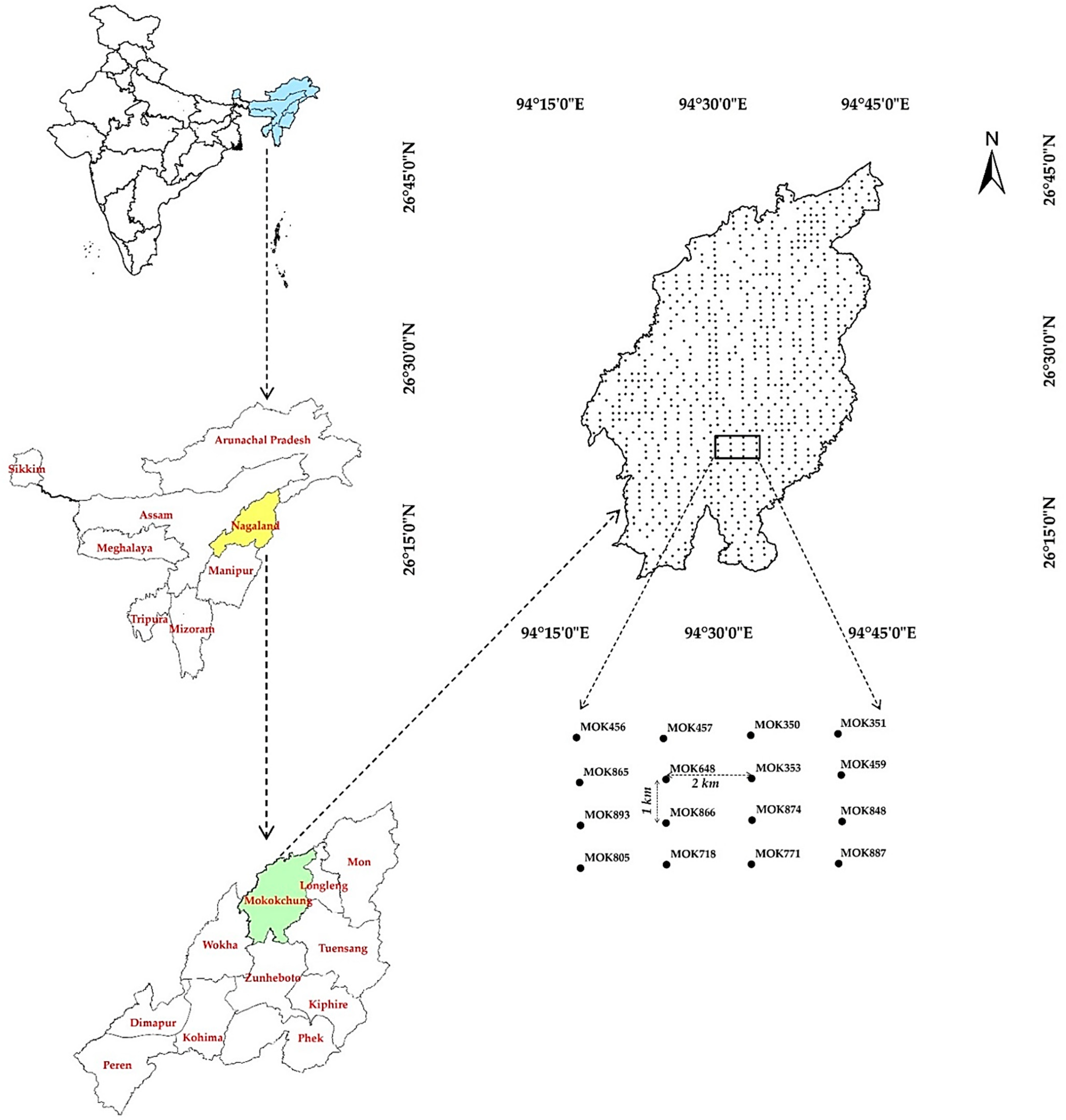
The north-eastern Himalayan region of India (NEHR) is a unique fragile ecosystem due to its strategic setting, occupying 8% of the total geographical area (TGA) of the country. Soil nutrient losses pose a threat to crop cultivation due to undulating terrain with steep ridges and intermountain valleys [
32]. However, data regarding the variability of soil nutrients at a regional scale in the NEHR of India are very limited. Here we aimed to utilize the GWPCA algorithm to explore these fertility parameters through a case study, evaluating the degree of spatial correlation among the surface soil nutrients. More particularly, studies that use GWPCA are very limited, and none of them have evaluated the spatial distribution of the soil nutrients. Keeping this as background information, the present study was conducted (a) to predict the spatial distribution of soil attributes and available nutrients using the regression kriging approach, (b) to identify possible management zones (MZs) using GWPCA and PFCM and (c) to study the potential of the identified MZs for site-specific nutrient and crop management in the NEHR of India.
4. Discussion
It is indeed critical to monitor the nutrient level of soil on a regular basis. In such rugged terrain, timely surveying is a difficult and costly task. In light of the foregoing, samples gathered in the research region were analysed to determine the relationship with environmental variables and then segregated to create a reasonable number of management zones that can be controlled. In this study, it was found that the soil properties were quite variable, with a significant coefficient of variance. The OC content was high in the soils of Nagaland state due to thick vegetation cover [
53]. Forest diversity, geographical factors, and climate change impacts have all been linked to the higher OC in this region [
54]. The soil’s physical and chemical characteristics and alterations in the quality and quantity of organic matter input into the soils are being primarily influenced by the mean annual temperature, hence regulating the OC stability [
55]. The variation in the concentration of available nutrients may be attributed to prevailing climatic conditions, contrasting landforms, parent materials and dynamic land-use patterns [
56,
57,
58]. The studied soil properties showed low to very high variability. Out of all of the soil properties, the lowest CV value was registered by the pH. Several authors have documented modest and moderate variations in the soil pH and OC concentration in India’s acid soils, which are consistent with our findings [
16,
57,
59].
The substantial diversity in soil micronutrient availability throughout space might be due to changes in parent materials and paedogenic processes, which are the two major causes of variance [
60]. The high CV values of soil parameters indicated spatial variability, which pushed for site-specific fertilizer management to boost crop output.
A correlation study suggested that variations in soil pH are causing changes in micronutrient solubility and distribution [
39]. Tripathi et al. [
59] also reported the positive correlation between the soil pH and available Zn and Mn in the rice cultivation soils of Odisha. In addition to these, the micronutrients were positively and substantially connected with each other, and there was a positive and significant link between OC and accessible Fe, Mn, Zn and Cu. The present results corroborated the findings of others [
61,
62].
It was observed in the case of the SMLR model in the present study that the prediction power was moderate for OC and N, but low prediction was observed for other soil attributes with a significant contribution of covariates in the model. In comparison to previous research, the outcomes differ depending on the models employed, the projected soil properties, and the study’s location. Mapping macronutrients in agricultural (depth 0–15 cm) lands in Iran with the cubist model yielded a lower validation R
2 of 13% for N, but a higher, though still low, R
2 of 17% for P, compared to the current work [
63]. With the QRF in the semiarid tropics of South India at a 30 cm depth, Dharumarajan et al. [
64] obtained substantially lower R
2 values of 0.23 for OC. In the prediction of soil parameters, factors such as the sampling intensity in relation to the geographical extent, topography features and bioclimatic variables may have played a critical impact. The soil characteristics displayed a pattern of spatial dependency that might be attributable to internal variables, such as chemical, physical and mineralogical features, external influences, such as human activities, or both [
24,
65]. The pH and OC ranges in the research region were moderate. Reza et al. [
66] found a similar pH range in the alluvial soils of India; however, Fathi et al. [
67] found a smaller range of pH and organic matter variability. The influence zones for N, P and K were arranged in decreasing order. It was relatively high for N, but not so much for P or K. Reza et al. [
68] showed a similar and larger geographical range for available N (2.0 km) and available K (2.3 km) at the district level of soil fertility mapping. When considering the zone of effect at the district level, the trend in soil micronutrients was moderate. While using kriging interpolation approaches, some authors observed varying micronutrient ranges [
69,
70,
71]. The effect of random factors and the resolution of gridded soil data might explain these contradicting results in terms of the spatial range of soil attributes. Apart from the spatial range, another key indication is spatial dependency. The soil pH, N, Fe, Mn and Cu had modest spatial dependence, but OC, P and K had moderate geographical dependence, except for Zn, which had large geographical dependence. This is due to topography, prevailing climate conditions, soil types and changing land-use patterns, such as shifting farming. In the research region, around 101 km
2 of land was subjected to intermittent shifting cropping [
72].
The soil properties showed high variations in the spatially predicted maps, which were ascribed to the changing nature of the environment, land use and management [
12]. Such predicted maps with high spatial resolution are necessary for assessing and monitoring soil health and, at the same time, they will act as a guide for developing a proper land-use plan.
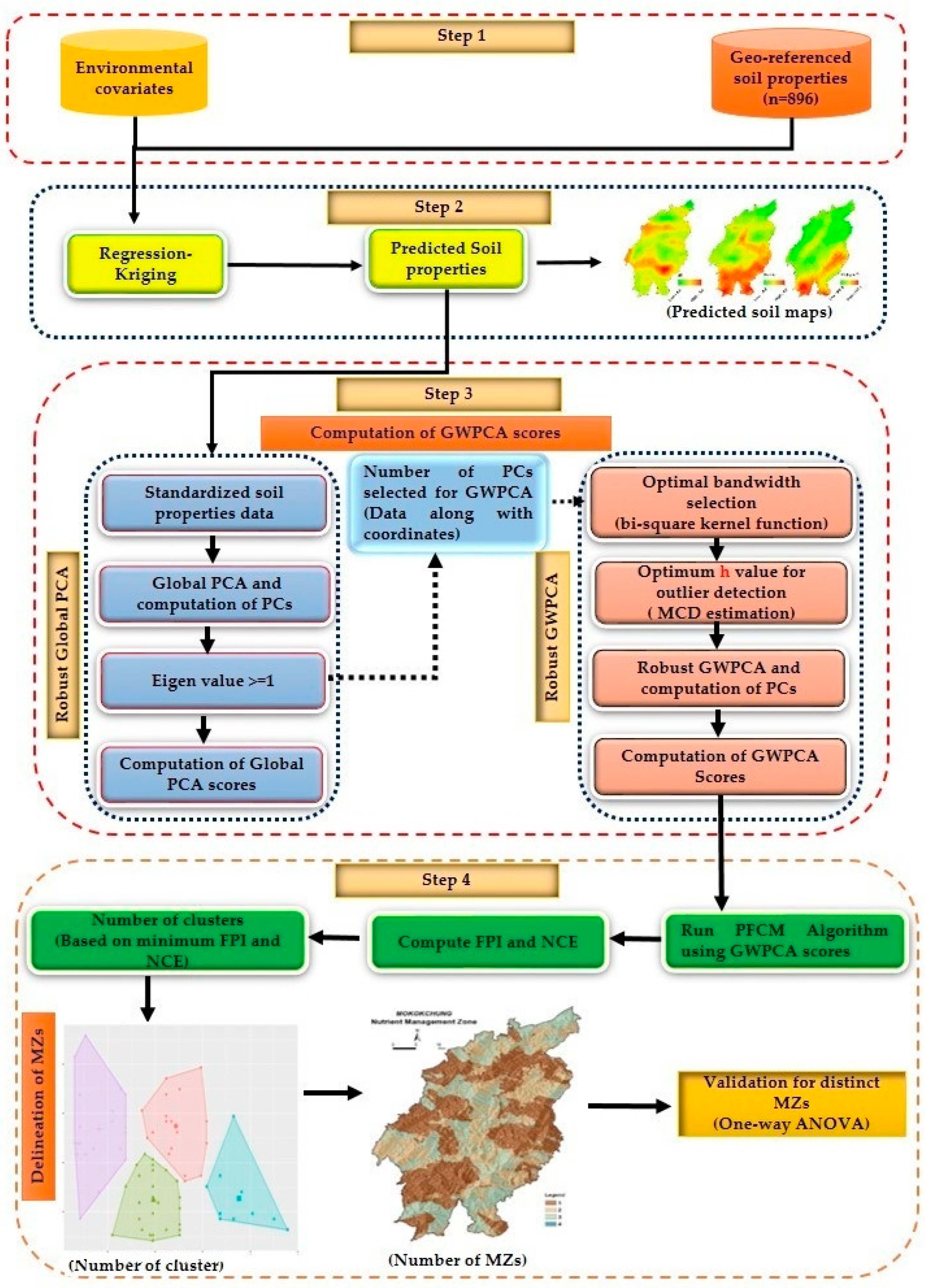
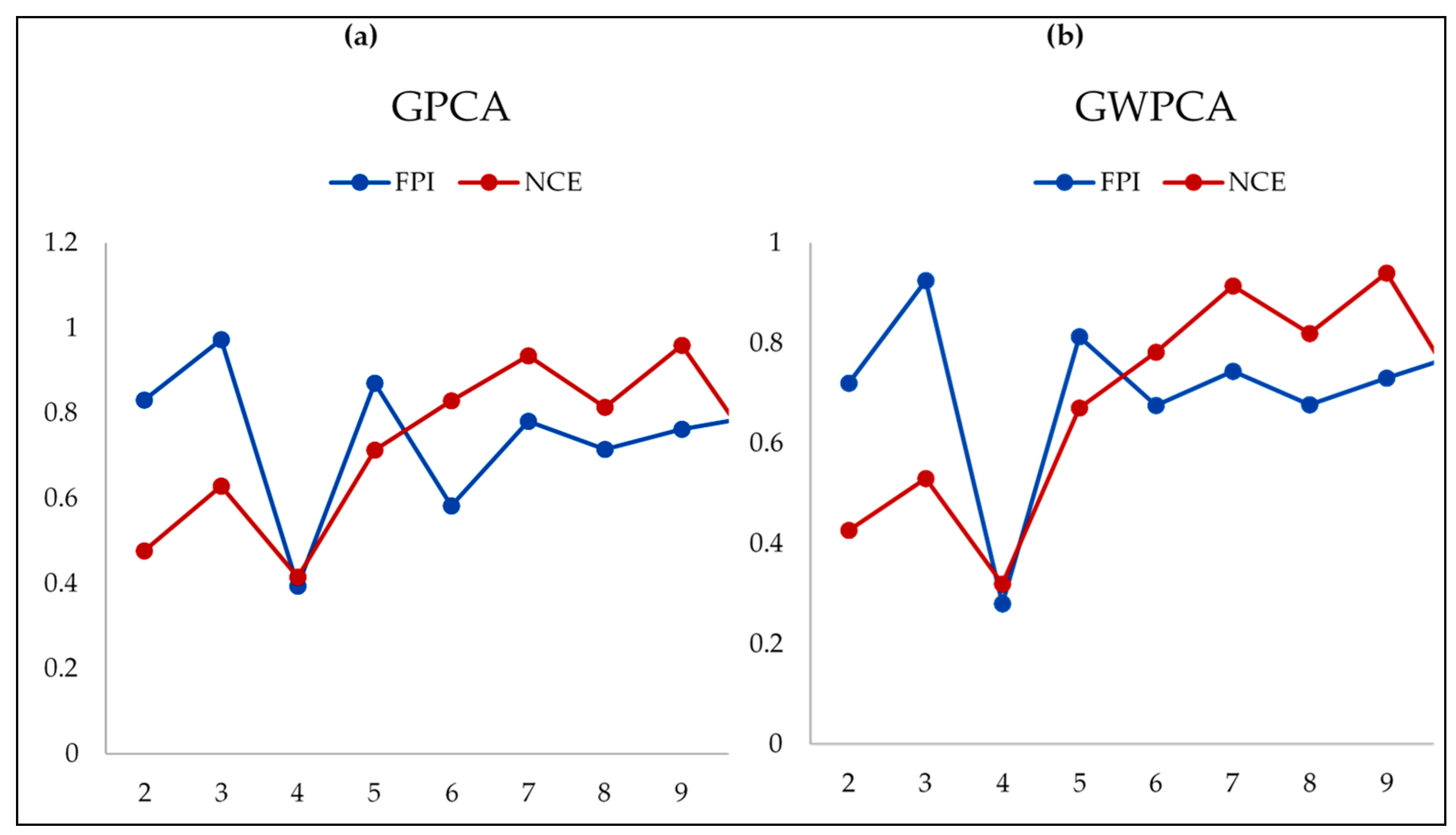
The methodology of delineation of MZs solely considered the available nutrients, but the abeyance of spatial information in PCA does not justify our hypothesis concerning the segregation of distinct MZs. Distinct spatial variation was observed in the maps of soil characteristics; however, it is impossible to identify the variables responsible for regional variations. In terms of variance decomposition for spatial data sets, the use of a GPCA in a spatial data structure provides an incomplete view. GPCA does not consider the local structure (i.e., longitude/latitude) of soil nutrients, which tends to provide an incomplete understanding of soil nutrient distribution over space. To avoid such problems, GWPCA was used to adopt a local distribution pattern of soil nutrients over space, which is essential for the delineation of MZs. GWPCA is nothing but the local adaptation of classical PCA in a spatial data structure.
Considering the additional advantages of the former, the anticipated spatial heterogeneity in the soil properties and available nutrients was due to the GWPCA. The results from GWPCA and GPCA were compared throughout. The comparison between GWPCA and GPCA was conducted for the first three components from each calibration and the PC scores were mapped (PC1 to PC3) (
Figure 6). For GWPCA, the total
n = 17, 86 and 985 valued scores dataset (raster data) was generated through regression kriging for each location, i.e., 30 m spatial resolution of each component. In GWPCA, there were 17, 86 and 985 PCAs (corresponding to each pixel) for each soil nutrient in comparison to GPCA, where only one PCA existed for each nutrient. As a result, the GWPCA scores corresponding to their location were computed. A matrix of three main components (eigenvalue ≥ 1) was chosen for each site, together with their corresponding amount of variance explained and the winning variables for downstream analysis. The best bandwidth (bw) was calculated by using a bi-square method for
k = 3 components based on the minimum CV, and was found to be bw = 1, 10, 207. A sample of
h = 0.85
n (
n = 17, 86, 985) data points was chosen based on the shortest MCD estimator for robust GWPCA estimation [
73]. It was clear that the MZs generated through the former procedures were evidently (based on analysis of variance) different from each other (
Table 7) [
14,
59,
74].
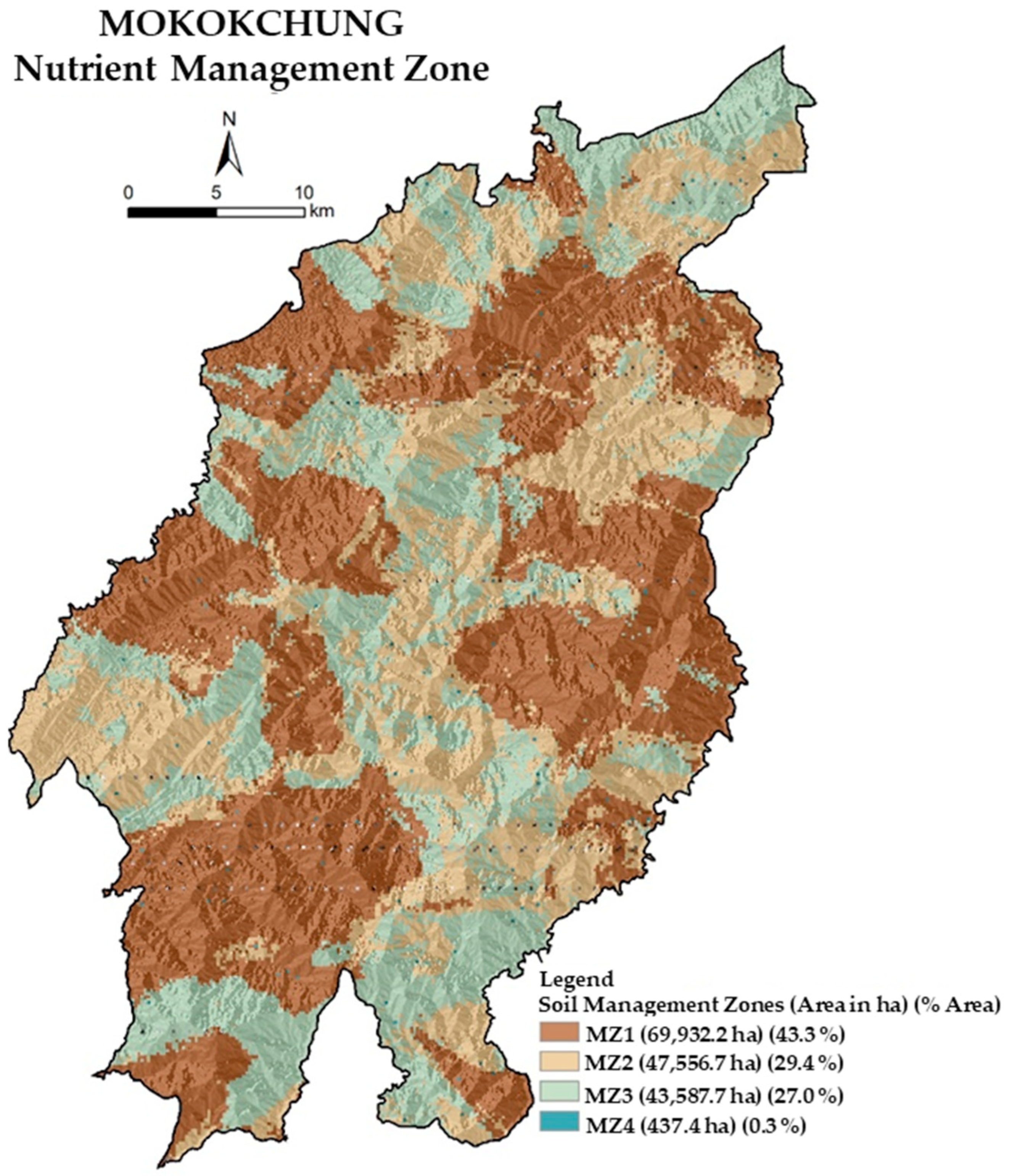
Variations in mineralogy, microclimatic variables, and other anthropogenic activities, such as soil and crop management, may account for the differences across the four MZs [
13,
57]. The study area is located on the western slope of the Purvanchal hills of the north-eastern Himalayan region, where the elevation decreases from east to west and the climate, vegetation and parent material vary significantly with elevation, from warm to humid thermic ecosystems at higher elevations to the hot moist sub-humid hyperthermic ecosystem at lower elevations. As a result, the altitude was a component that contributed to the variation in soil properties. Greater mean amounts of these nutrients might be linked to higher levels of OC, acidic pH, high altitude with temperature changes and forest vegetation, notwithstanding the substantial diversity across the MZs. Especially in the case of micronutrients, several authors also reported that the availability of micronutrients in the acidic and highly weathered soils of the north-eastern hilly regions are quite high [
20,
21,
22,
75,
76]. Only 2.11% of the study area is covered by agriculture, with the majority of the land covered by various forest vegetation (87.93%), followed by other land cover classifications. The main source of concern in the district, which covers 6.31% of the total land area, is shifting agriculture [
72]. This zonation concept based on essential nutrient availability combined with the land use–land cover layer will aid in identifying suitable areas for growing cereals, pulses, vegetables and tuber crops through judicious nutrient applications, as previous studies have suggested land use planning based on pedological attributes, rather than considering soil fertility parameters. The method would also provide an effective and efficient means for scientific nutrient management. The above study on geostatistical analysis illustrated the regional heterogeneity of soil properties in terms of spatial dependency, especially macro and micronutrients. As a result, knowledge of soil qualities in individual MZs might be valuable for farmers and other stakeholders to make informed decisions about nutrient management on a site-by-site basis.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}