1. Introduction
Land cover data are crucial for ecological environmental protection [
1,
2,
3,
4], natural resource management [
5,
6,
7,
8], urban planning [
9,
10,
11,
12], and precision agriculture [
13,
14,
15,
16]. Rural populations continue to migrate to cities and towns for work, study, and live as a result of urbanization, prompting the need for planning authorities to adjust the extent of new urban build-up land. Remote sensing sensor and aerospace technology advancements have resulted in easier access to an increasing number of remote sensing images with shorter time periods. Remote sensing imagery has become an important data source for land cover and urban land use monitoring [
17]. Urban land has expanded in large cities and small counties in China as a result of the reform and opening-up policy [
18,
19]. Large cities can have timely map data updates because their mapping is supported by the system and investment [
20,
21,
22]. In contrast, small towns in China are considerable and widely dispersed with varied topography, making dynamic mapping of urban land difficult.
Many scholars have extensively studied land surface mapping based on remote sensing. These studies have mainly used machine learning for supervised or unsupervised classification based on medium- and high-resolution remote sensing images [
23,
24,
25]. The supervised approach is more widely utilized because the sample data allow the algorithm in effectively differentiating features. Early supervised classification methods include maximum likelihood, neural network, and decision trees, while support vector machines (SVM) and random forests (RF) outperform other traditional supervised classifiers [
26]. Supervised methods require a training set with a certain size of correctly labeled samples for the model to learn the classification patterns of the samples.
Deep neural network models have achieved great success in the field of remote sensing image analysis with the development of deep learning techniques and computer hardware. For example, these models have played an important role in the fields of high-resolution image scene classification [
27,
28,
29,
30], high-resolution image semantic segmentation [
31,
32,
33,
34], hyperspectral image classification [
35], remote sensing image object detection [
36,
37,
38,
39], and image retrieval [
40]. Land cover classification methods based on deep learning have gradually replaced machine learning methods in the field of land cover classification research because of their high accuracy [
41]. Among the deep learning methods, convolutional neural network (CNN) is widely used in the field of land use and land cover classification due to their advantages in extracting image features [
42], while the feature extraction capability [
43] and transfer capability [
44] of CNNs are also being developed.
In land use and land cover mapping, medium and high-resolution remote sensing images such as Landsat, MODIS, Sentinel 1 and Sentinel 2 images play a great role. They are used individually or in combination to be used in land use or land cover mapping tasks under different scenarios and different needs [
16,
45,
46,
47,
48]. Additionally, with the widespread use of convolutional neural networks, more datasets produced based on these remote sensing data are needed to complete the training of the models.
However, the performance of deep learning methods will be greatly affected when the size of the dataset or the accuracy of the labels are not sufficient (i.e., small datasets or inaccurate labels). The former can be addressed to a certain extent by data augmentation strategies, while the latter problem of inaccurate labeling is relatively more difficult to solve.
Datasets, such as SAT-6 [
49], DeepGlobe-2018 [
50], EuroSAT [
51], BigEarthNet [
52], and SEN12MS [
53], have been proposed in the field of land cover classification to meet the demand of deep learning methods for large sample data. Meanwhile, several agencies around the world produce global free land cover products that are mapped and regularly updated to meet the global demand for land cover data applications from other industries. Examples of these products include European Space Agency (ESA) global 10 m land cover classification product [
54], Esri global 10 m land cover classification product [
45], Tsinghua University FROM-GLC10 land cover product [
46], and Aerospace Information Research Institute GlobeLand30 product [
55]. However, the challenge in producing large-scale datasets and data products is the accurate labeling of the samples. Manual expert labeling of large sample collections is often not feasible. Accordingly, labeling is conducted by non-expert through crowdsourcing [
56]. In the case of images, such as open street maps and outdated classification maps, data annotation is performed by keyword queries from search engines [
57]. These inexpensive alternative procedures allow scaling the size of the labeled dataset at the cost of introducing labeling noise (i.e., inaccurately labeled samples). Even if manual experts are involved in labeling data samples, they must be provided with sufficient information; otherwise, inaccurate labeling may still occur (e.g., during field surveys) [
58]. Volunteers’ labeling is often subjective, and it can also produce labeling errors. In addition, tagging errors may arise due to problems with remote sensing sensors, the timing of photography, weather, camera angles, geographic alignment errors, or complexity of land cover. Therefore, large-scale datasets will inevitably contain inaccurately labeled samples or suffer from labeling noise.
When deep learning methods are used with traditional loss functions (e.g., classification cross entropy and mean square error), they are not robust to labeling noise, resulting in a significant reduction in the classification accuracy [
59]. This situation calls for robust methods to mitigate the influence of label noise on deep learning methods. This work aims to improve the generalization ability of deep learning models in the presence of label noise.
When training deeper neural networks, the models tend to memorize the training data, which is more prominent when the dataset is affected by label noise [
60]. In deep learning models, the effect of label noise can be partially circumvented by regularization techniques, such as layer removal and weight regularization. These strategies make neural networks robust, but they are still tending to remember noisy labels with medium to large noise levels. The problem of learning with noisy labels has been studied in machine learning for a long time [
61], but research focusing on neural networks is still scarce. The fields of computer vision and machine learning have proposed new approaches to address label noise by cleaning up noisy labels or designing robust loss functions in deep learning frameworks [
62].
The noise contained in a dataset is divided into two main categories: the first category corresponds to feature noise, which is defined as inaccuracies or errors introduced in the instance attribute values. Feature noise comes from spectral noise caused by poor acquisition conditions (e.g., cloudy days); geometric errors brought in by data preprocessing, such as orthorectification and geometric correction; alignment differences caused by digitization or outlining; or errors in coding problems. The second category corresponds to class label noise (i.e., instance labels are different from ground truth labels). The corresponding instances are called corrupted or mislabeled instances. Label noise is considered to be more harmful and difficult to handle than attribute noise and can significantly degrade classification performance [
63]. Noisy label learning using shallow learning methods has been studied in the literature [
61]. However, research in the context of deep learning is still scarce (but has recently grown) [
64]. Among several approaches that have been proposed to robustly train deep neural networks on datasets with noisy labels, some approaches address this problem by removing noisy labels and using clean estimated labels to train deep neural networks or smoothly reduce the effect of noisy labels by applying smaller weights on noisy labeled samples. These approaches use directed graphical models [
65], conditional random fields [
66], knowledge graph distillation [
60], meta-learning [
67], or noisy transfer matrix estimation [
64] to solve the noisy labeling problem. However, these approaches require an additional small fraction of data with clean labels or ground truth of pre-identified noise labels to model the noise in the dataset.
Few studies have been focused on the adverse effects of label noise in remote sensing image analysis. Some studies have analyzed the effects of noisy labels on the classification performance of satellite image time series [
68] and hyperspectral images [
69]. Jian [
70] and Damodaran [
71] proposed loss functions to learn improved classification models to reduce the detrimental effect of noisy labels on the classification problem of remote sensing images. Kaiser [
72] used online open street maps (outdated or unlabeled ground truth) to obtain the feasibility of classification maps. The aforementioned study did not directly consider label noise as the problem specificity. Some other studies have dealt with label noise in the context of shallow classifiers (RF and logistic regression) by selecting clean labeled instances through outlier detection [
68] or using existing noise-resistant logistic regression methods [
73]. However, these label noise minimization methods are designed for specific models; thus, the algorithms lack generality. Combining noisy label correction strategies with deep learning is a promising approach in solving the land cover classification problem of remote sensing images under noisy labels.
This work develops a noisy label learning method using land cover products as a benchmark to produce high-resolution construction-use maps using existing label data (i.e., land cover products). This method uses existing remote sensing images and low-resolution landcover maps containing noise as label data and produces high-resolution build-up landcover maps by semi-supervised data filtering and fault-tolerant learning loss functions.
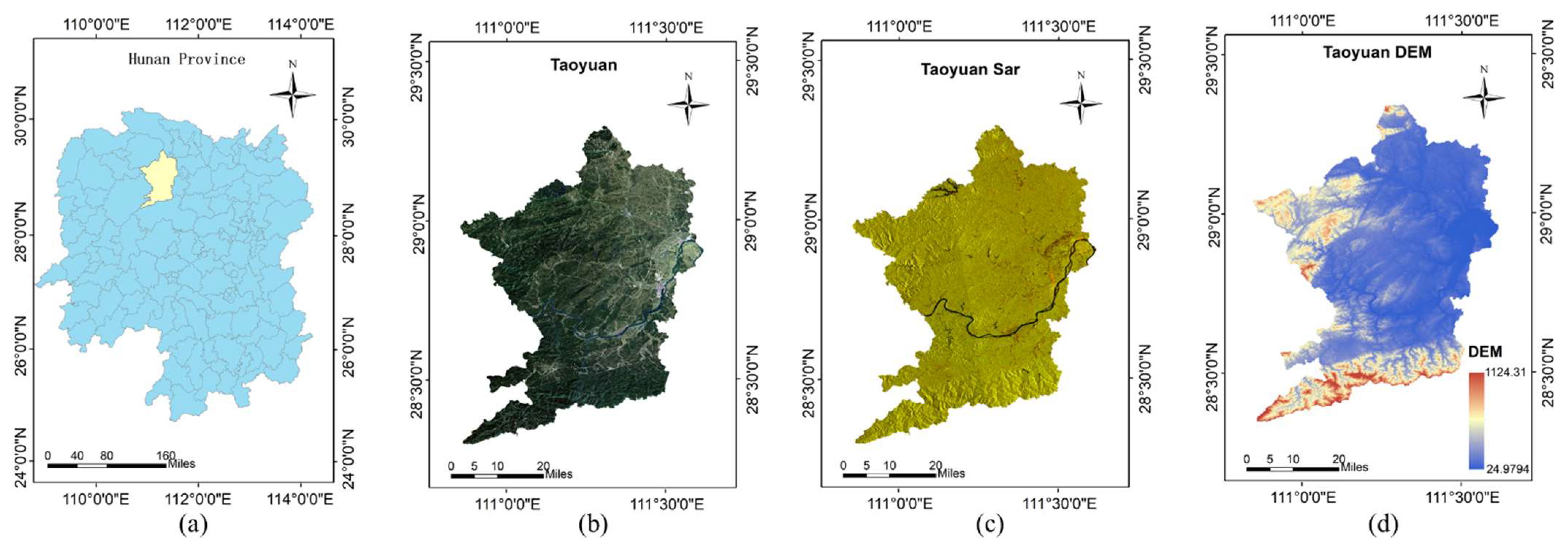
Section 2 introduces the study area and the data source.
Section 3 explains the methodology, including details of semi-supervised data filtering and the fault-tolerant learning loss functions.
Section 4 presents the results. A discussion is presented in
Section 5 and conclusions are drawn in
Section 6.
3. Method
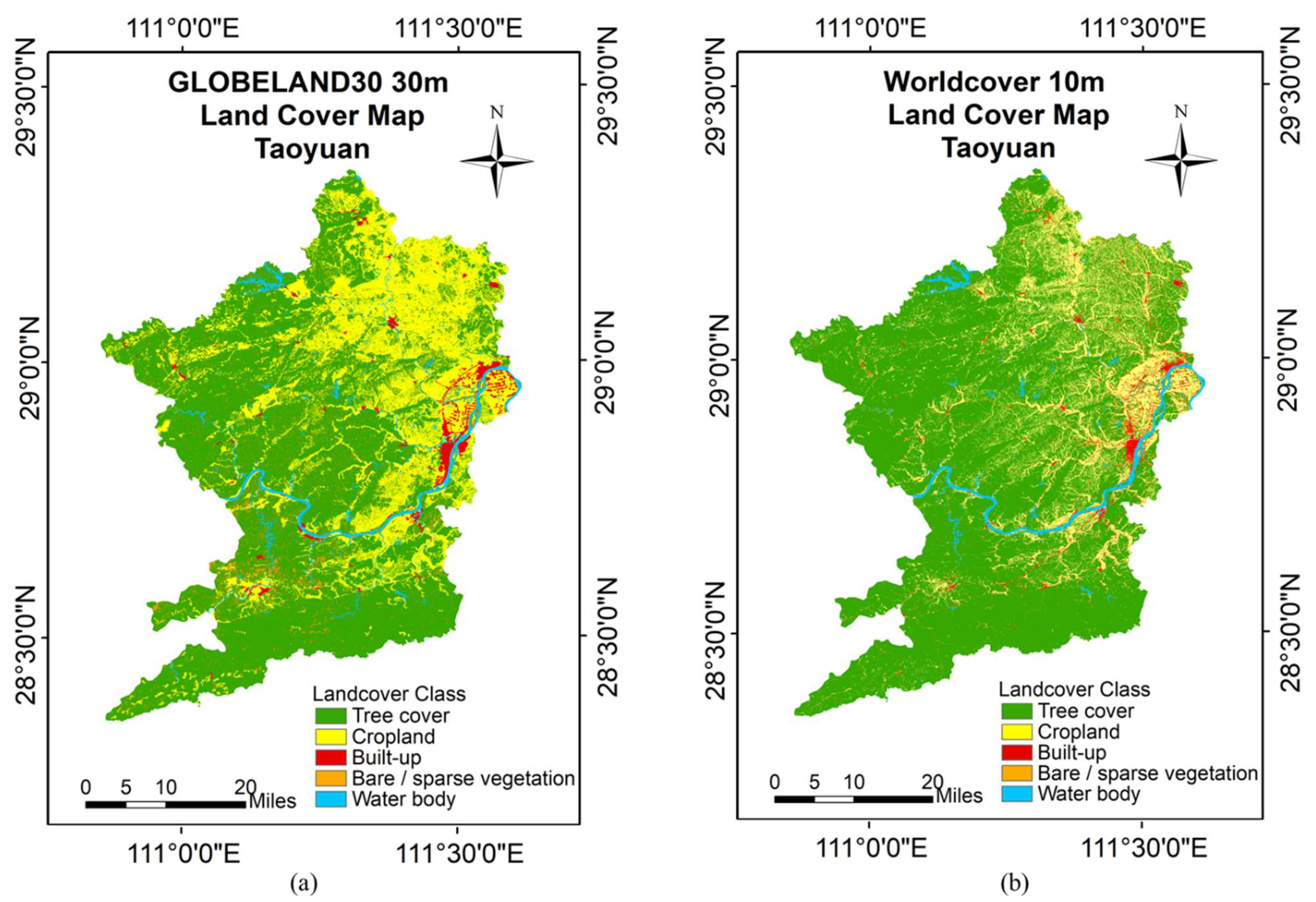
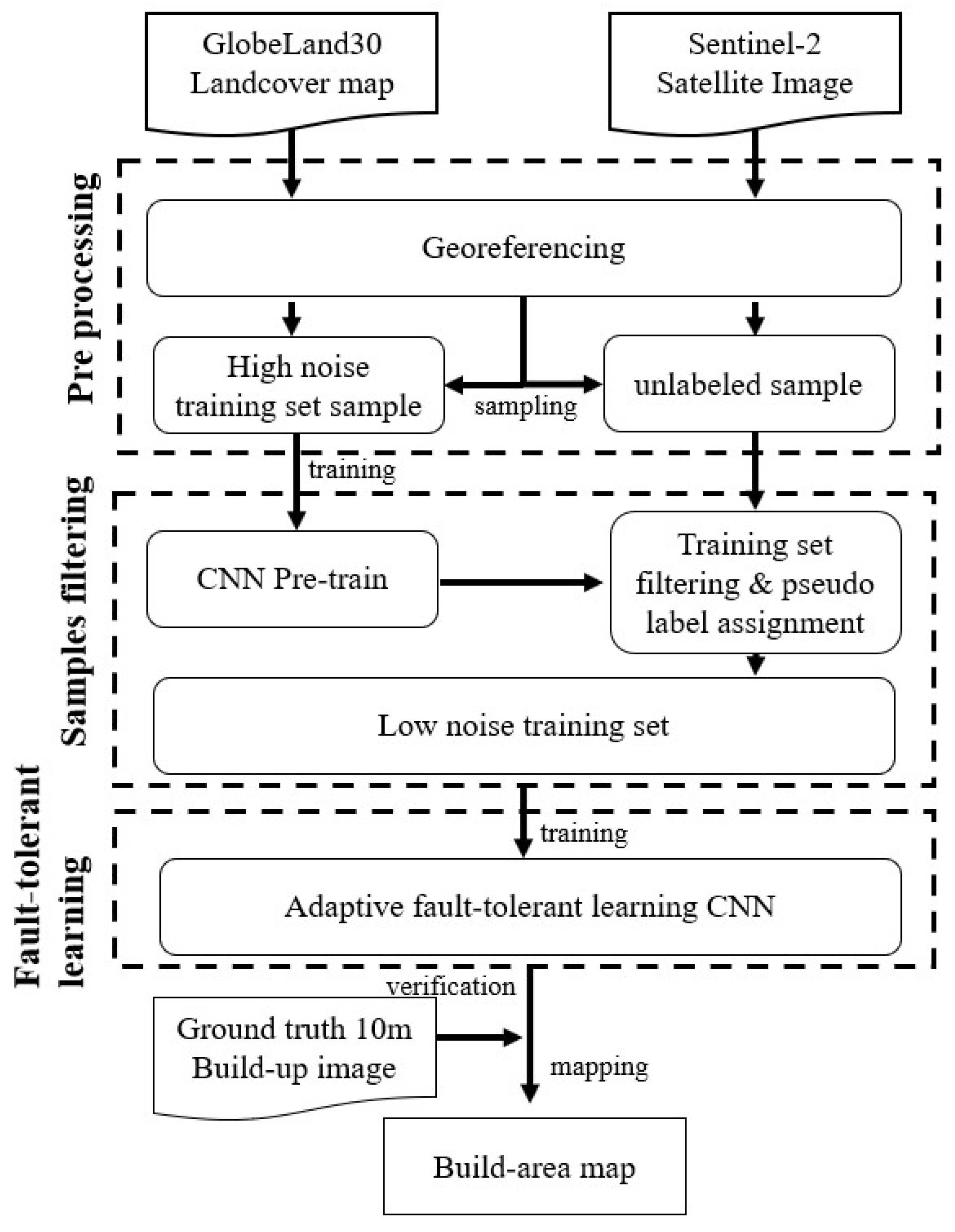
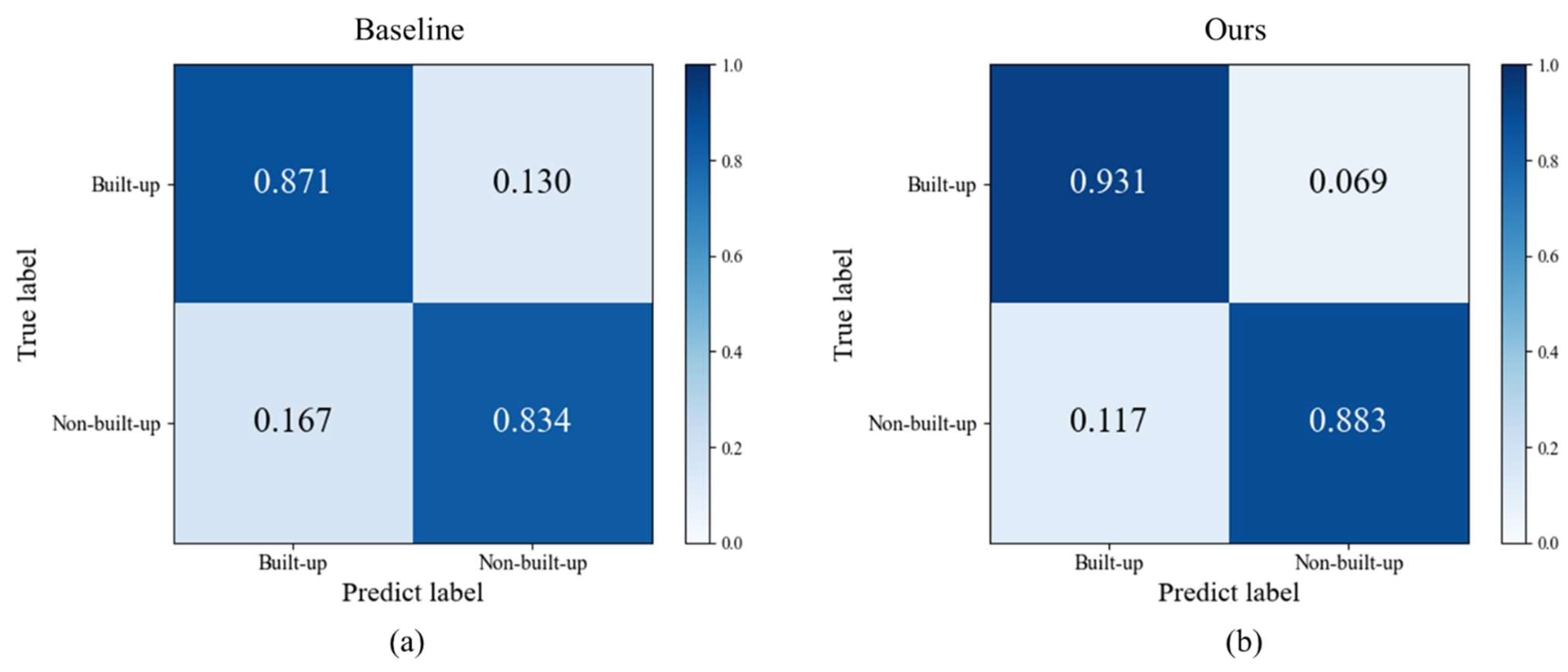
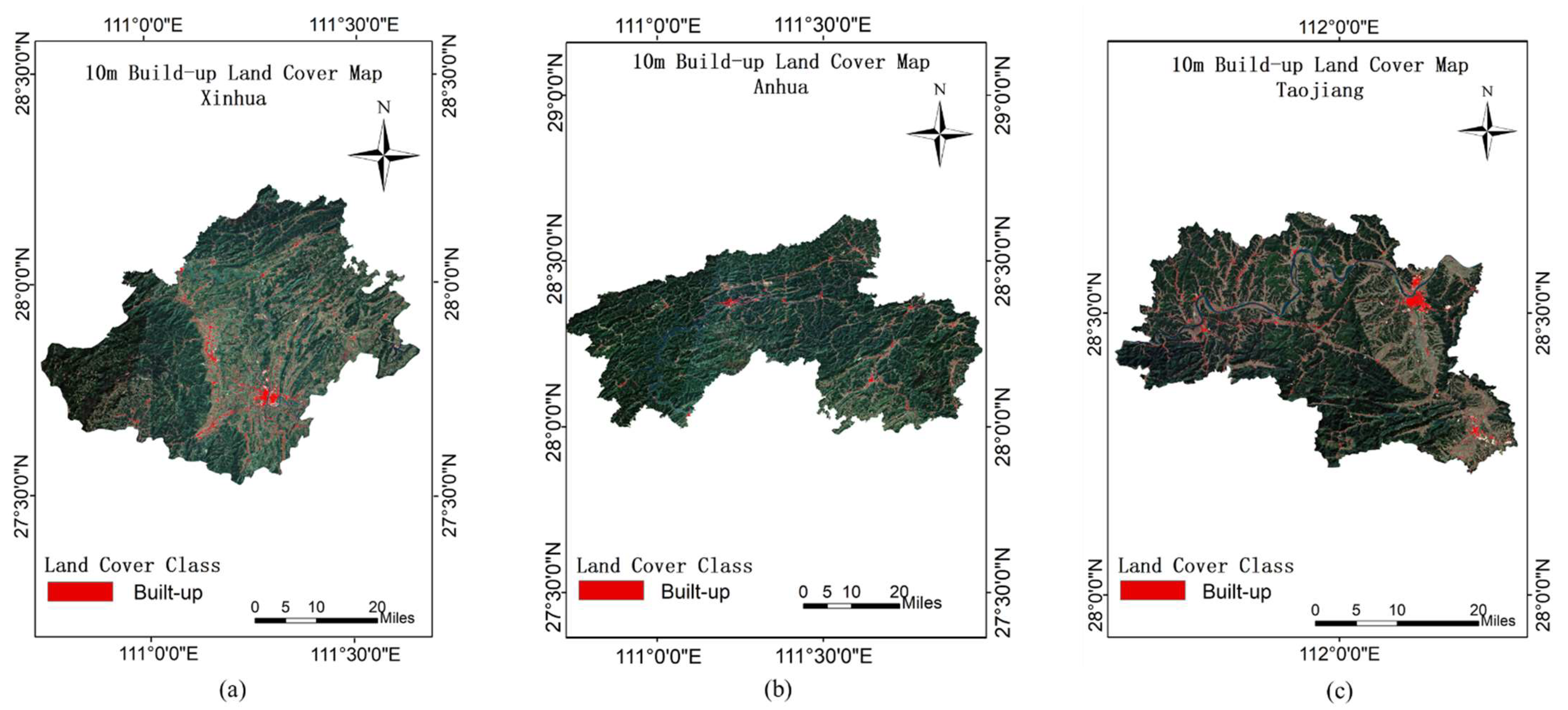
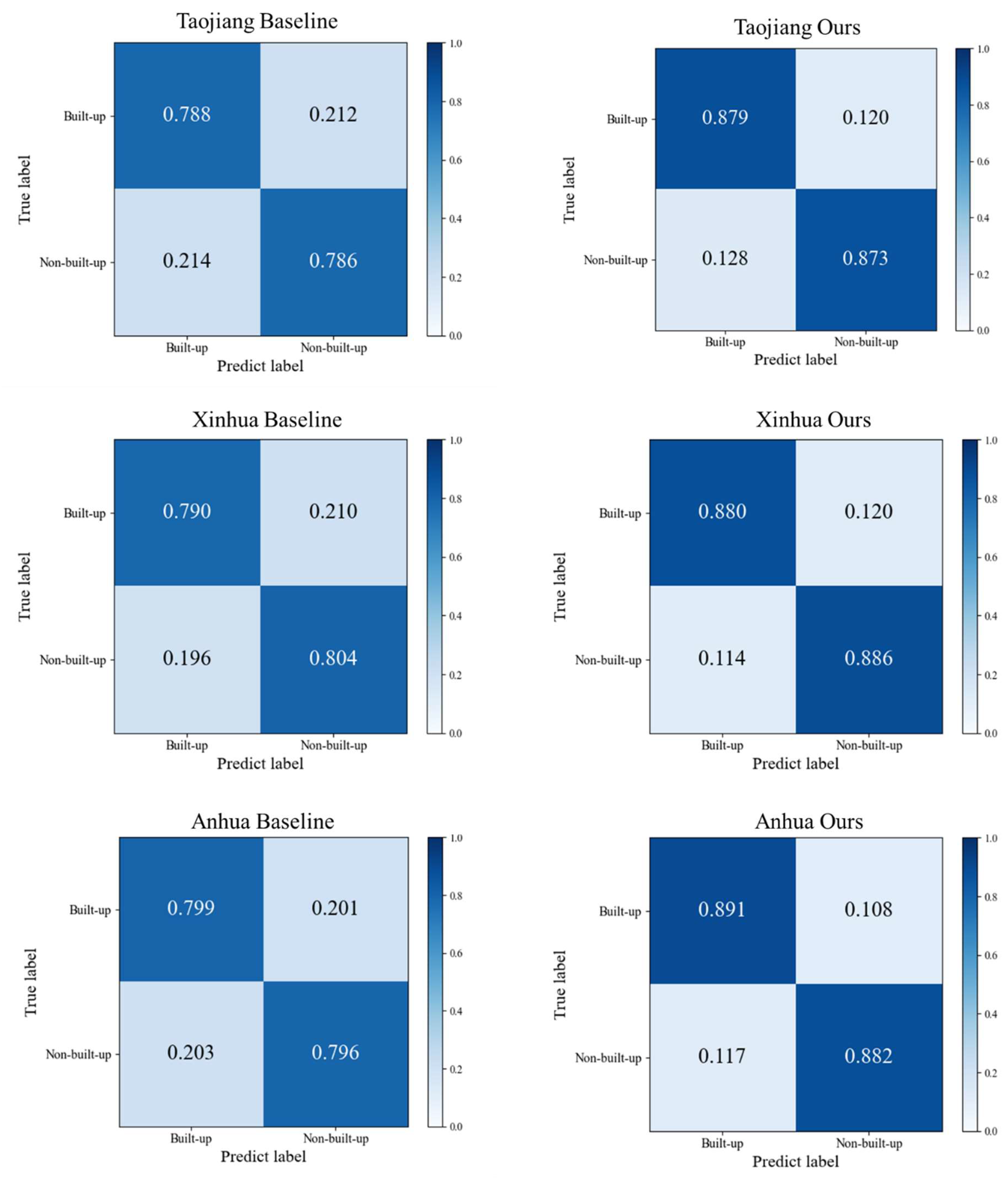
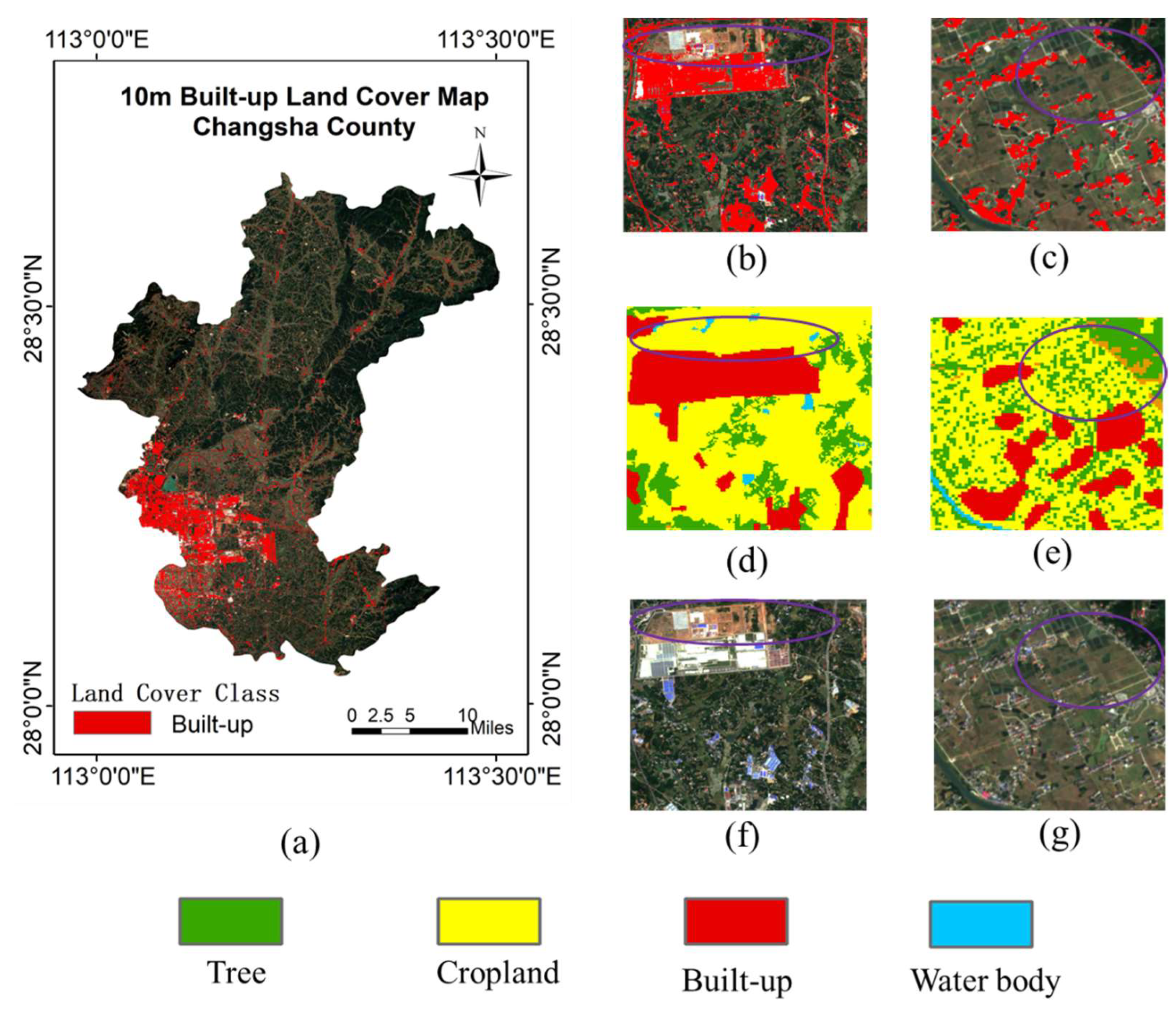
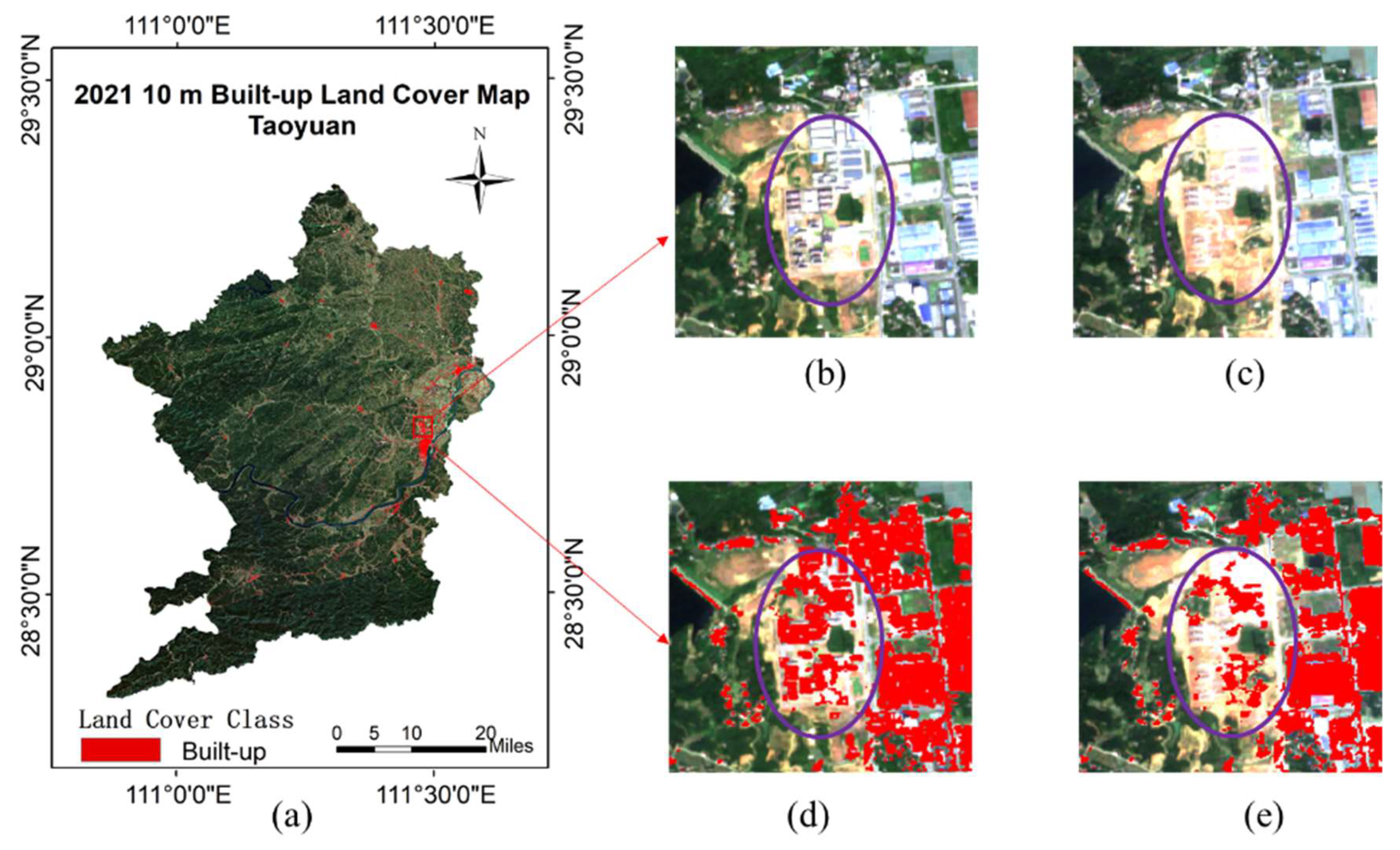
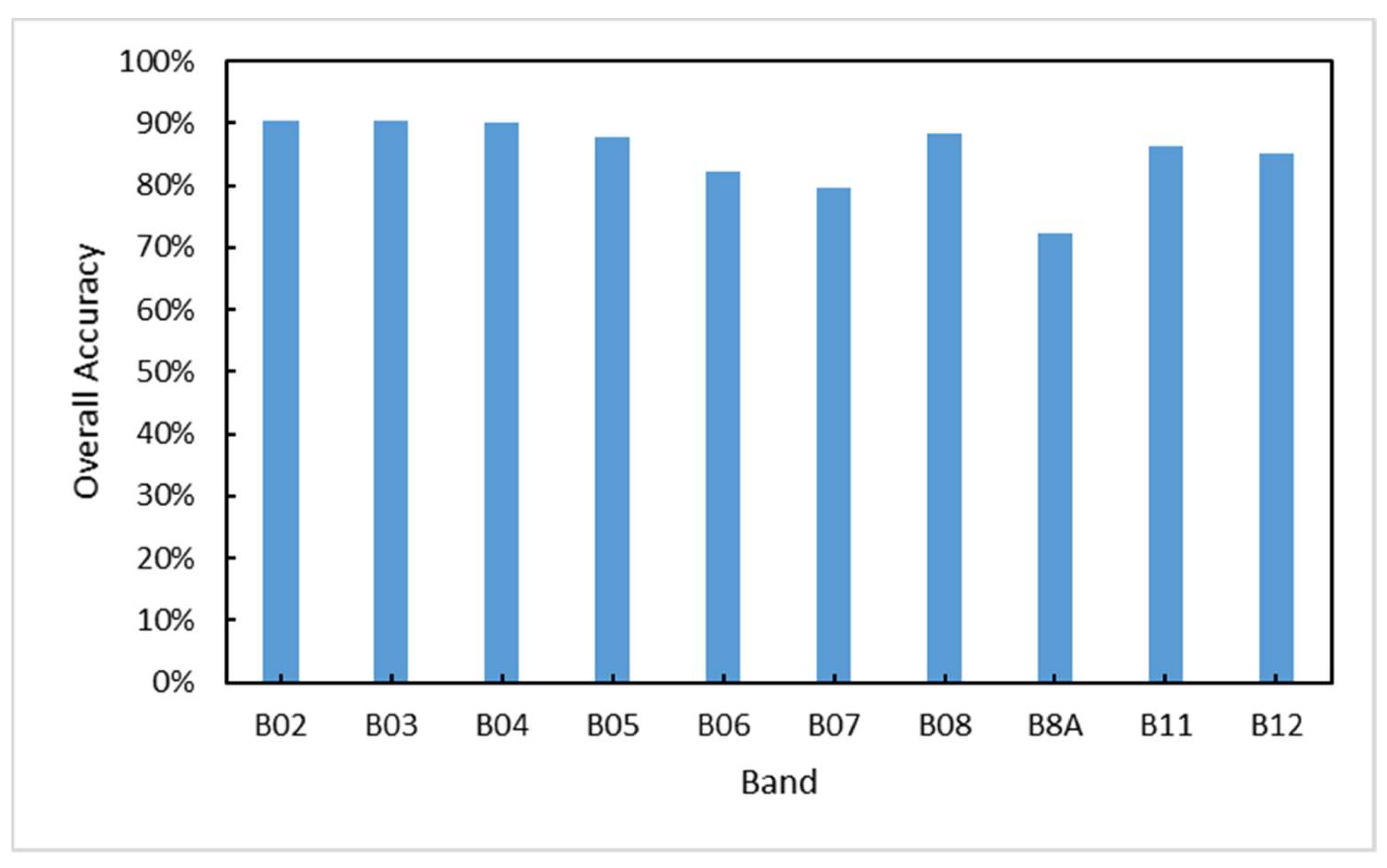
One pixel at 30 m resolution corresponds to 3 × 3 pixels at a 10 m rate due to the difference in resolution. These 9 pixels can only be given category labels of the same pixel from 30 m resolution when using the training set for manufacturing construction land category labels at 30 m resolution for construction land mapping at 10 m resolution. However, the land cover categories of these 9 pixels are not exactly the same in the actual 10 m resolution case. Consequently, the training set will contain incorrect labels (i.e., noisy labels). The goal of the method in this work is for the classifier to find the incorrect labels and learn against the correctly labeled samples in the case that the training set contains noisy labels, allowing the corresponding features of the correct class to be learned, and the images with 10 m resolution can be correctly classified. The flow chart of the method in this work is shown in
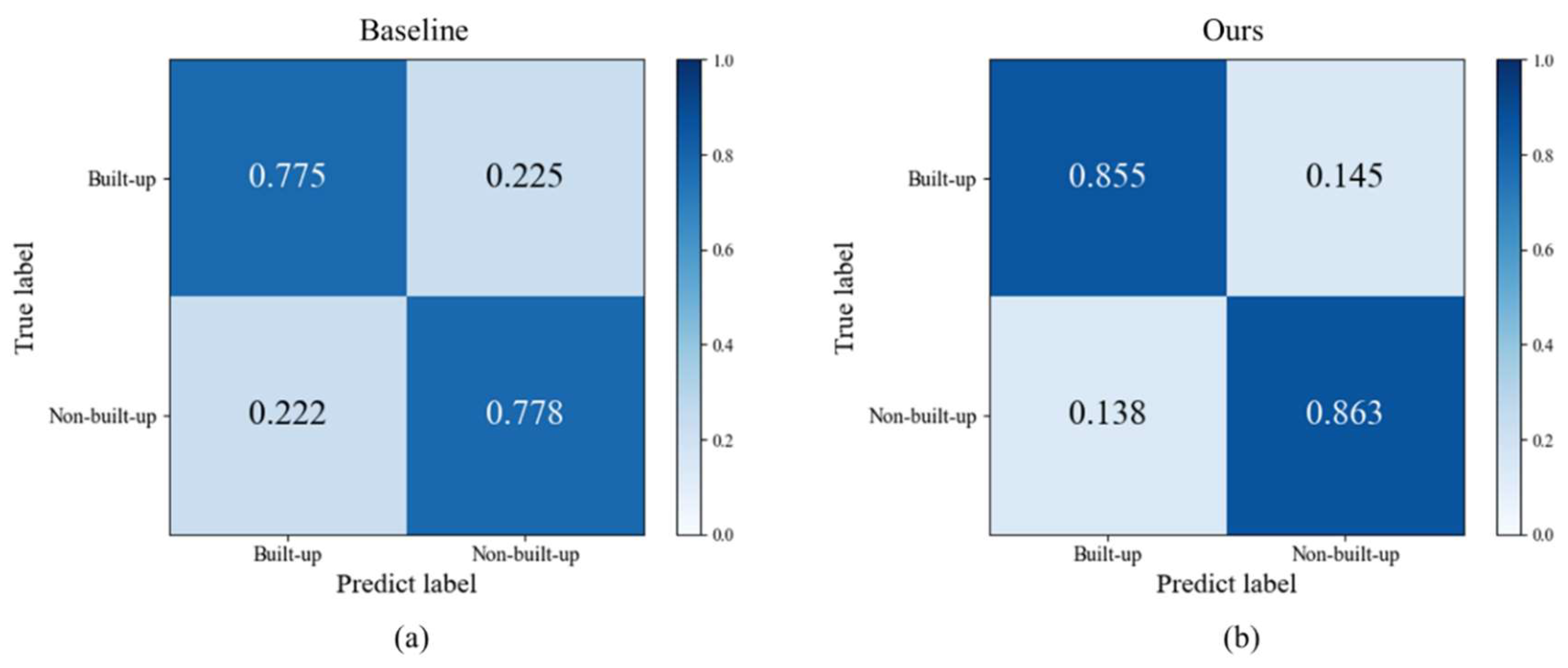
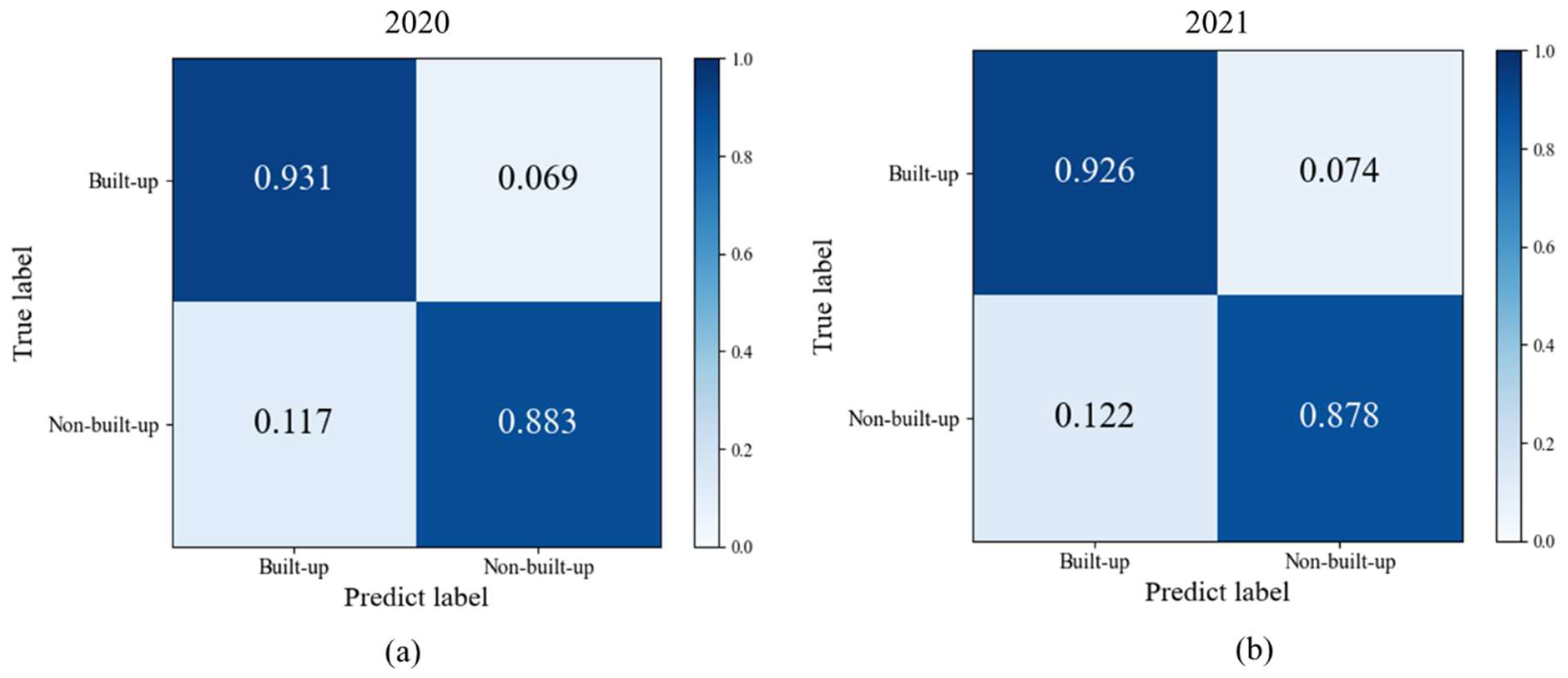
Figure 3, which includes three steps. First, the land cover map and remote sensing images are preprocessed. Second, the pre-trained baseline is used to calculate the classification confidence of the unlabeled data and filter the samples with higher confidence in the building category to join the new training set for initial noise filtering. Finally, the filtered samples are trained using the fault-tolerant learning loss, and the build-up land mapping results are obtained after verifying the accuracy.
3.1. Problem Formulation of Fault-Tolerant Learning
We suppose that
remote sensing image land cover categories with
category classes are present in the training set, and each land cover category can be represented by feature type. Let
be the feature space of the land cover category, and
be the label space. We assume that all the labels are one-hot vectors and use
to denote a one-hot vector corresponding to class
. Let
be the
independently and identically distributed samples obtained according to the distribution
of
. The task of land cover classification is to train the classifier to learn the pattern of distribution
using
as the training set. However, there is no such
training set when using 30 m resolution land cover category labels for land cover classification of 10 m resolution remote sensing images. Instead, the training set
is obtained, and
is obtained based on the distribution
. Here,
denotes the incorrect label, and
denotes the correct label.
and
are correlated, and their relationship can be expressed as follows:
where
denotes the noise rate, which is the probability that the label
becomes
. This general model is called class conditional noise because the probability of a label error in this model depends on the original label class. A special case of this model is called symmetric noise. The probability of converting a class label to any other class label is equal in the presence of symmetric noise (i.e., assuming that
and
, where
denotes the probability of a class label error). If all samples labeled by a particular category are selected from the training set of label errors under the condition that
, then the samples that really belong to that category are still in the majority in the set.
Now, the fault-tolerant learning problem of build-up land classification under noise labels can be formulated as follows: The build-upland classifier needs to learn the pattern of distribution . However, the training set can only be obtained from the distribution containing the error labels. In the build-up land classification task, let the function of the classifier be , where is a parameter. Assuming that the softmax output layer is used as the last layer of the neural network classifier, the labels of the training samples are all one-hot vectors when the training set is used for training. is a probability vector of the same length as . Thus, the loss function of the classifier in the training phase can be defined as .
3.2. Training Set Sample Filtering and Pseudo-Label Assignment Method
The presence of category noise in the training set leads to a degradation of the classification performance. Accordingly, direct training with training sets containing a large amount of noise does not achieve satisfactory accuracy. We propose a semi-supervised learning scheme for confidence-based filtering of unlabeled remote sensing images to produce a low-noise dataset in this work to obtain datasets containing less noise, which is inspired by the pseudo-label assignment strategy [
76] for obtaining valuable samples and the joint fine-tuning strategy [
77] for using high-confidence samples to participate in optimization. The idea of the pseudo-label assignment is to select valuable samples based on the predicted classification confidence [
76]. However, these pseudo-labels may not be reliable. Joint fine-tuning optimizes the classification model by adding samples with high confidence in the training set [
77], but it requires a small number of labeled samples. Our solution combines the advantages of the above-mentioned two approaches to obtain reliable training information from unlabeled data for low-noise dataset construction for model optimization.
In a given training set , we input each patch into the baseline for pre-training. The output vector of the softmax layer is the confidence given by the classifier for the class to which belongs. This vector is denoted by using , where denotes the confidence that patch belongs to category c, and C is the total number of categories. We can use the confidence level to determine whether an unlabeled sample is associated with a label because the baseline has a strong discrimination ability.
After inputting unlabeled samples into the pre-training model, the first step is to rank the maximum value of the confidence level of each category to which the unlabeled patch belongs. In a given filtering threshold [0, 1], the N× samples with the maximum confidence level are selected to be added to the new training set, and the maximum value in is used for the samples assigned with category labels. The filtering threshold can be set based on the results of the pre-training test precision, which is also a response to the category labels in the samples. If the precision is low, indicating that the sample contains more noise, then should be reduced to obtain samples with better confidence; if the precision is high, indicating less noise in the sample, then can be appropriately increased. However, the precision should not be set particularly large. A large will bring in many noisy samples and weaken the effect of sample filtering.
3.3. Adaptive Fault-Tolerant Curriculum Learning Based on Batch Statistics
Curriculum learning can be considered a minimization of weighted losses [
78]:
where
represents the curriculum.
b is selected here as the size of a minibatch because the optimizer generally chooses SGD in the learning process. A simple choice for this curriculum is
. Substituting this equation into Equation (2) and taking
and considering the case where λ depends on the category label, Equation (2) can become:
Where . In any fixed , the optimal solution of the optimization problem is given by the relation: when , the optimal solution ; when , the optimal solution , with . Moreover, this relationship holds even when is a function of or a function of all samples in the data set that matches . Then, a truly dynamically adaptive optimization problem is available for the curriculum (i.e., by letting depend on all in the minibatch and on the current value of ).
In the choice of threshold , consider those samples with no errors in the labels for satisfying , and can be set to update in minibatches when . Given enough empirical evidence that samples with correct category labels are easier to learn than those with noise, some quantiles of the set of loss values obtained in small batches quantile or a similar statistic would be a good choice for .
We can obtain because we use cross-entropy loss. is the posterior probability that belongs to class at current because the network has a softmax output layer. The criterion for choosing the threshold can be that the assigned posterior probability is higher than a threshold value because the loss value and this posterior probability are inversely proportional. The method threshold in this work is set to the mean value of the posterior probability of each category of samples in a minibatch because the mean value can represent the confidence level of most of the samples in this category.
The above-mentioned method of learning adaptive fault-tolerant curriculum based on batch statistics can become:
where mean
denotes the sample mean of the category posterior probability of the samples with category label
, where
denotes the number of all
category samples in the minibatch.
Considering that the neural network is trained using minibatches, the algorithm consists of three parts:
Calculation of the sample selection threshold for a given small batch of data;
Sample selection based on the threshold and Equation (4);
Network parameter update using these selected samples.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}