
A Context Feature Enhancement Network for Building Extraction from High-Resolution Remote Sensing Imagery





Abstract
:1. Introduction
- An end-to-end context feature enhancement network, namely CFENet, is proposed to address the challenges of complexity and diversity of buildings encountered in building extraction from remote sensing images.
- CFENet balances efficiency and accuracy by employing dilated convolution in the spatial fusion module and asymmetric convolution in the focus enhancement module.
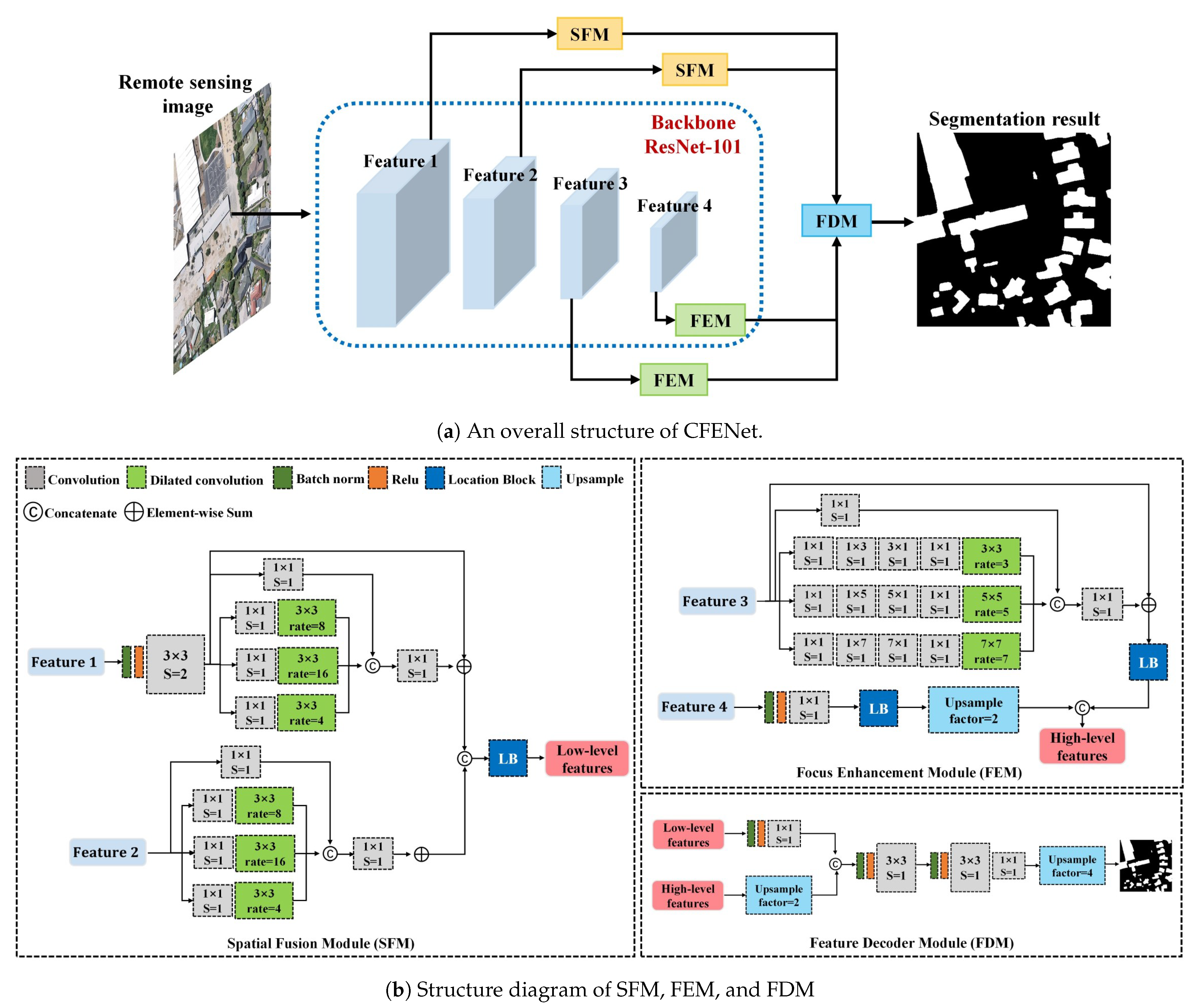
2. The Proposed Context Feature Enhancement Network
2.1. Model Description
2.2. Spatial Fusion Module
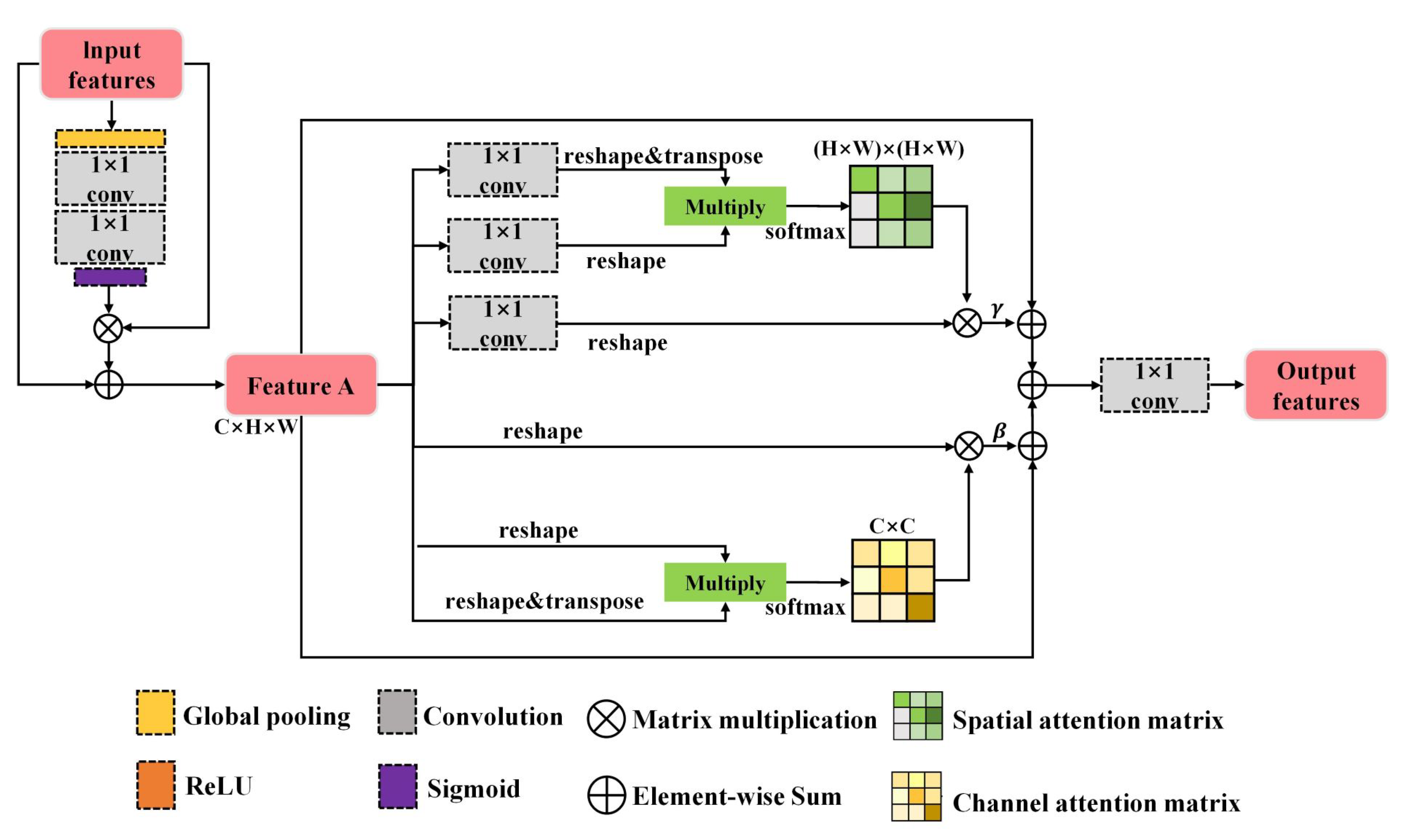
2.3. Location Block
2.4. Focus Enhancement Module
2.5. Feature Decoder Module
2.6. Loss Function
3. Experiments and Results
3.1. Evaluation Metrics
3.2. Dataset and Implementation Details
3.3. Comparative Experiments
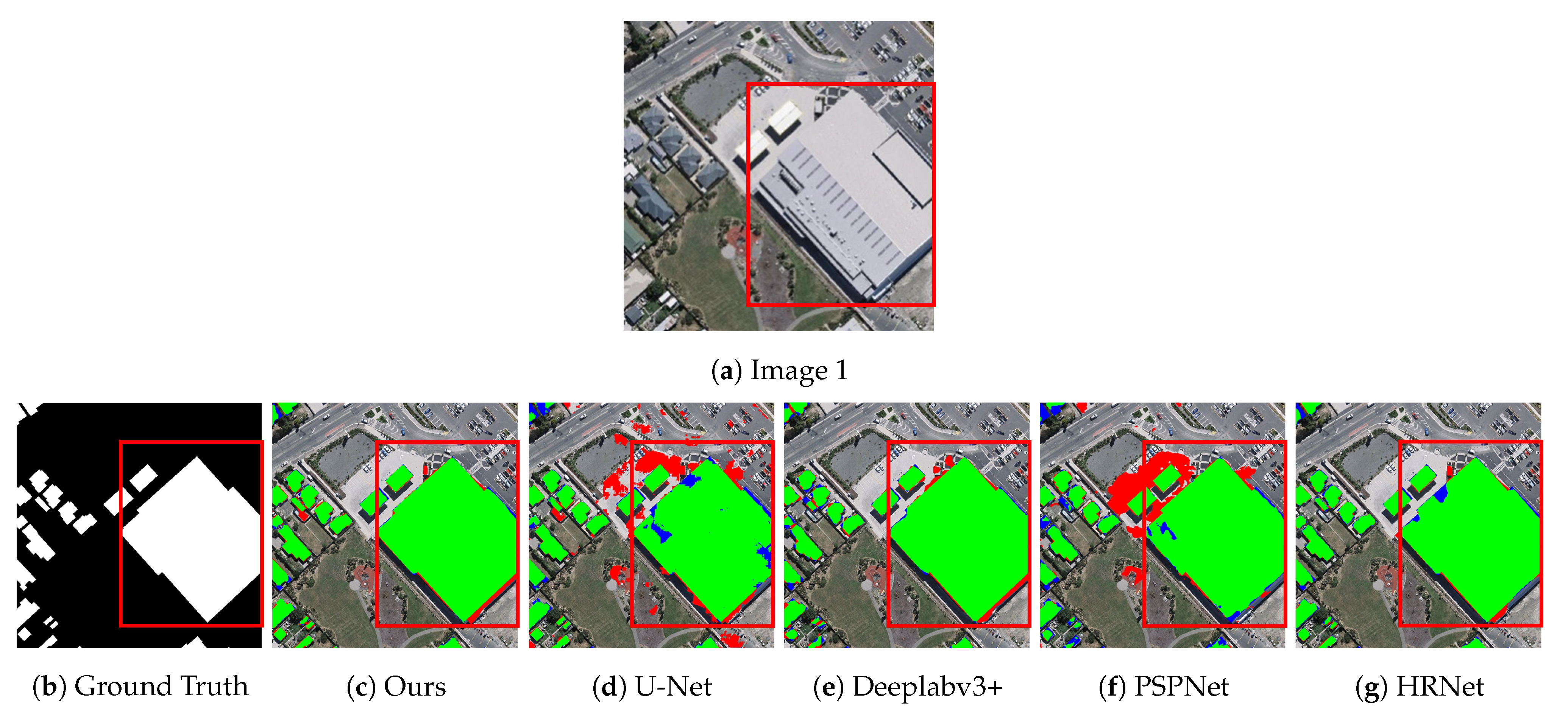
3.3.1. Results on WHU Building Dataset
3.3.2. Results on Massachusetts Building Dataset
3.4. Ablation Experiments
4. Discussion
4.1. Comparison of the Efficiency of Different Methods
4.2. Heatmaps for Validating the Effectiveness of CFENet’s Modules
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CFENet | Context Feature Enhancement Network |
| CNN | Convolutional Neural Network |
| FCN | Fully Convolutional Network |
| SFM | Spatial Fusion Module |
| FEM | Focus Enhancement Module |
| FDM | Feature Decoder Module |
| LB | Location Block |
| BN | Batch Normalization |
| Adam | Adaptive Moment Estimation |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
| GPU | Graphics Processing Unit |
| PA | Pixel Accuracy |
| PC | Precision |
| F1 | F1 score |
| IoU | Intersection over Union |
| FWIoU | Frequency Weighted Intersection over Union |
| MBI | Morphological Building Index |
| Mask R-CNN | Mask Region Convolutional Neural Network |
References
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; Vanhuysse, S.; Lennert, M.; Shimoni, M.; Kalogirou, S.; Wolff, E. Less is more: Optimizing classification performance through feature selection in a very-high-resolution remote sensing object-based urban application. GISci. Remote Sens. 2018, 55, 221–242. [Google Scholar] [CrossRef]
- Yang, H.L.; Yuan, J.; Lunga, D.; Laverdiere, M.; Rose, A.; Bhaduri, B. Building Extraction at Scale Using Convolutional Neural Network: Mapping of the United States. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2600–2614. [Google Scholar]
- Kuras, A.; Brell, M.; Rizzi, J.; Burud, I. Hyperspectral and Lidar Data Applied to the Urban Land Cover Machine Learning and Neural-Network-Based Classification: A Review. Remote Sens. 2021, 13, 3393. [Google Scholar] [CrossRef]
- Munawar, H.S.; Ullah, F.; Qayyum, S.; Heravi, A. Application of deep learning on uav-based aerial images for flood detection. Smart Cities 2021, 4, 1220–1242. [Google Scholar] [CrossRef]
- Wang, Y.; Cui, L.; Zhang, C.; Chen, W.; Xu, Y.; Zhang, Q. A Two-Stage Seismic Damage Assessment Method for Small, Dense, and Imbalanced Buildings in Remote Sensing Images. Remote Sens. 2022, 14, 1012. [Google Scholar] [CrossRef]
- Peng, B.; Ren, D.; Zheng, C.; Lu, A. TRDet: Two-Stage Rotated Detection of Rural Buildings in Remote Sensing Images. Remote Sens. 2022, 14, 522. [Google Scholar] [CrossRef]
- Mahabir, R.; Croitoru, A.; Crooks, A.T.; Agouris, P.; Stefanidis, A. A critical review of high and very high-resolution remote sensing approaches for detecting and mapping slums: Trends, challenges and emerging opportunities. Urban Sci. 2018, 2, 8. [Google Scholar] [CrossRef] [Green Version]
- Ball, J.E.; Anderson, D.T.; Chan Sr, C.S. Comprehensive survey of deep learning in remote sensing: Theories, tools, and challenges for the community. J. Appl. Remote Sens. 2017, 11, 042609. [Google Scholar] [CrossRef] [Green Version]
- Luo, L.; Li, P.; Yan, X. Deep Learning-Based Building Extraction from Remote Sensing Images: A Comprehensive Review. Energies 2021, 14, 7982. [Google Scholar] [CrossRef]
- Li, E.; Xu, S.; Meng, W.; Zhang, X. Building extraction from remotely sensed images by integrating saliency cue. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 10, 906–919. [Google Scholar] [CrossRef]
- Chen, R.; Li, X.; Li, J. Object-Based Features for House Detection from RGB High-Resolution Images. Remote Sens. 2018, 10, 451. [Google Scholar] [CrossRef] [Green Version]
- Inglada, J. Automatic recognition of man-made objects in high resolution optical remote sensing images by SVM classification of geometric image features. ISPRS J. Photogramm. Remote Sens. 2007, 62, 236–248. [Google Scholar] [CrossRef]
- Ding, Z.; Wang, X.; Li, Y.; Zhang, S. Study on building extraction from high-resolution images using Mbi. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci 2018, 42. [Google Scholar] [CrossRef] [Green Version]
- Katartzis, A.; Sahli, H.; Nyssen, E.; Cornelis, J. Detection of buildings from a single airborne image using a Markov random field model. In Proceedings of the IGARSS 2001, Scanning the Present and Resolving the Future, IEEE 2001 International Geoscience and Remote Sensing Symposium (Cat. No. 01CH37217), Sydney, NSW, Australia, 9–13 July 2001; Volume 6, pp. 2832–2834. [Google Scholar]
- Awrangjeb, M.; Fraser, C.S. An automatic and threshold-free performance evaluation system for building extraction techniques from airborne LIDAR data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4184–4198. [Google Scholar] [CrossRef]
- Tu, Z.; Li, H.; Zhang, D.; Dauwels, J.; Li, B.; Yuan, J. Action-stage emphasized spatiotemporal VLAD for video action recognition. IEEE Trans. Image Process. 2019, 28, 2799–2812. [Google Scholar] [CrossRef]
- Zhang, D.; He, L.; Tu, Z.; Han, F.; Zhang, S.; Yang, B. Learning motion representation for real-time spatio-temporal action localization. Pattern Recognit. 2020, 103, 107312. [Google Scholar] [CrossRef]
- Zhang, D.; He, F.; Tu, Z.; Zou, L.; Chen, Y. Pointwise geometric and semantic learning network on 3D point clouds. Integr.-Comput.-Aided Eng. 2020, 27, 57–75. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; SegNet, R.C. A deep convolutional encoder-decoder architecture for image segmentation. arXiv 2015, arXiv:1511.00561. [Google Scholar] [CrossRef] [PubMed]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Guo, M.; Liu, H.; Xu, Y.; Huang, Y. Building extraction based on U-Net with an attention block and multiple losses. Remote Sens. 2020, 12, 1400. [Google Scholar] [CrossRef]
- Chen, M.; Wu, J.; Liu, L.; Zhao, W.; Tian, F.; Shen, Q.; Zhao, B.; Du, R. DR-Net: An improved network for building extraction from high resolution remote sensing image. Remote Sens. 2021, 13, 294. [Google Scholar] [CrossRef]
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. BRRNet: A fully convolutional neural network for automatic building extraction from high-resolution remote sensing images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building extraction in very high resolution remote sensing imagery using deep learning and guided filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Q.; Liao, C.; Hu, H.; Mei, X.; Li, H. MAP-Net: Multiple Attending Path Neural Network for Building Footprint Extraction from Remote Sensed Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6169–6181. [Google Scholar] [CrossRef]
- Liao, C.; Hu, H.; Li, H.; Ge, X.; Chen, M.; Li, C.; Zhu, Q. Joint Learning of Contour and Structure for Boundary-Preserved Building Extraction. Remote Sens. 2021, 13, 1049. [Google Scholar] [CrossRef]
- Yang, H.; Wu, P.; Yao, X.; Wu, Y.; Wang, B.; Xu, Y. Building extraction in very high resolution imagery by dense-attention networks. Remote Sens. 2018, 10, 1768. [Google Scholar] [CrossRef] [Green Version]
- Wen, Q.; Jiang, K.; Wang, W.; Liu, Q.; Guo, Q.; Li, L.; Wang, P. Automatic building extraction from Google Earth images under complex backgrounds based on deep instance segmentation network. Sensors 2019, 19, 333. [Google Scholar] [CrossRef] [Green Version]
- Zheng, G.; Zhang, H.; Li, Y.; Zhao, J. A Universal Automatic Bottom Tracking Method of Side Scan Sonar Data Based on Semantic Segmentation. Remote Sens. 2021, 13, 1945. [Google Scholar] [CrossRef]
- Yu, Y.; Zhao, J.; Gong, Q.; Huang, C.; Zheng, G.; Ma, J. Real-Time Underwater Maritime Object Detection in Side-Scan Sonar Images Based on Transformer-YOLOv5. Remote Sens. 2021, 13, 3555. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Denton, E.L.; Zaremba, W.; Bruna, J.; LeCun, Y.; Fergus, R. Exploiting linear structure within convolutional networks for efficient evaluation. Adv. Neural Inf. Process. Syst. 2014, 27, 1269–1277. [Google Scholar]
- Jaderberg, M.; Vedaldi, A.; Zisserman, A. Speeding up convolutional neural networks with low rank expansions. arXiv 2014, arXiv:1405.3866. [Google Scholar]
- De Boer, P.T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
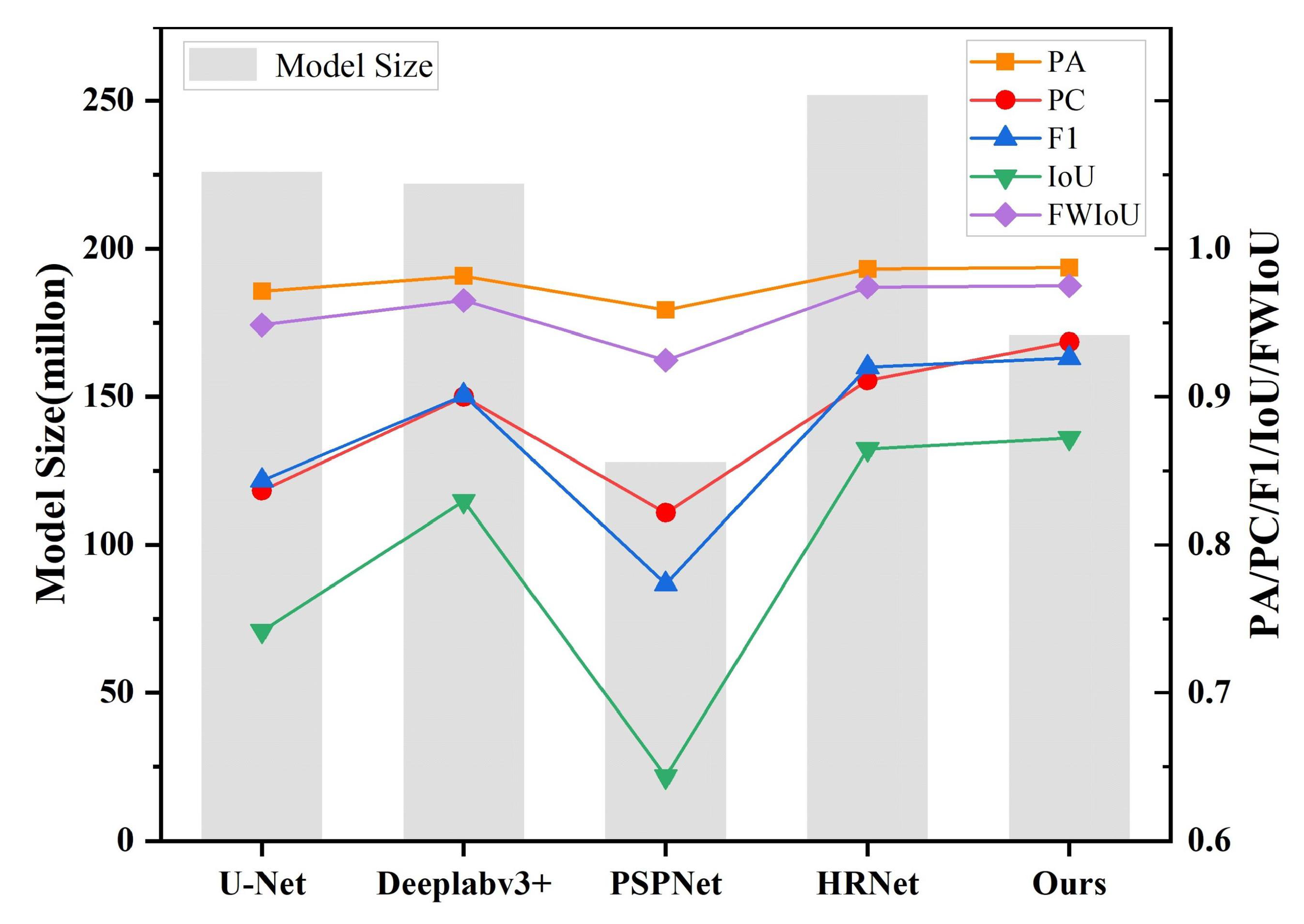
| Method | PA | PC | F1 | IoU | FWIoU |
|---|---|---|---|---|---|
| U-Net [28] | 0.9713 | 0.8366 | 0.8435 | 0.7419 | 0.9485 |
| Deeplabv3+ [50] | 0.9816 | 0.9001 | 0.9010 | 0.8296 | 0.9651 |
| PSPNet [30] | 0.9586 | 0.8215 | 0.7734 | 0.6434 | 0.9247 |
| HRNet [31] | 0.9864 | 0.9109 | 0.9201 | 0.8647 | 0.9742 |
| CFENet (Ours) | 0.9871 | 0.9370 | 0.9262 | 0.8722 | 0.9751 |
| Method | PA | PC | F1 | IoU | FWIoU |
|---|---|---|---|---|---|
| U-Net | 0.9517 | 0.8635 | 0.7701 | 0.6626 | 0.9099 |
| Deeplabv3+ | 0.9163 | 0.7153 | 0.6506 | 0.5266 | 0.8559 |
| PSPNet | 0.9116 | 0.7375 | 0.6084 | 0.4704 | 0.8455 |
| HRNet | 0.9581 | 0.8292 | 0.7910 | 0.6968 | 0.9225 |
| CFENet (Ours) | 0.9626 | 0.8277 | 0.8304 | 0.7486 | 0.9317 |
| Method | BaseNet | Component | PA | PC | F1 | IoU | FWIoU | ||
|---|---|---|---|---|---|---|---|---|---|
| SFM | FEM | FDM | |||||||
| FCN | ResNet-101 | 0.9638 | 0.7578 | 0.8387 | 0.7309 | 0.9365 | |||
| CFENet | ResNet-101 | √ | 0.9806 | 0.8954 | 0.8887 | 0.8148 | 0.9640 | ||
| CFENet | ResNet-101 | √ | √ | 0.9864 | 0.9182 | 0.9161 | 0.8608 | 0.9744 | |
| CFENet | ResNet-101 | √ | √ | √ | 0.9871 | 0.9370 | 0.9262 | 0.8722 | 0.9751 |
| Method | Batch Size | Model Size (Million) | Time (Min/Epoch) |
|---|---|---|---|
| U-Net (ResNet-101) | 8 | 226 | 20.050 |
| Deeplabv3+ (ResNet-101) | 8 | 222 | 10.417 |
| PSPNet (ResNet-101) | 8 | 128 | 20.383 |
| HRNet | 8 | 252 | 20.450 |
| CFENet (ResNet-101) | 8 | 171 | 13.250 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Zhang, D.; Wu, Y.; Chen, Y.; Yan, X. A Context Feature Enhancement Network for Building Extraction from High-Resolution Remote Sensing Imagery. Remote Sens. 2022, 14, 2276. https://doi.org/10.3390/rs14092276
Chen J, Zhang D, Wu Y, Chen Y, Yan X. A Context Feature Enhancement Network for Building Extraction from High-Resolution Remote Sensing Imagery. Remote Sensing. 2022; 14(9):2276. https://doi.org/10.3390/rs14092276
Chicago/Turabian StyleChen, Jinzhi, Dejun Zhang, Yiqi Wu, Yilin Chen, and Xiaohu Yan. 2022. "A Context Feature Enhancement Network for Building Extraction from High-Resolution Remote Sensing Imagery" Remote Sensing 14, no. 9: 2276. https://doi.org/10.3390/rs14092276
APA StyleChen, J., Zhang, D., Wu, Y., Chen, Y., & Yan, X. (2022). A Context Feature Enhancement Network for Building Extraction from High-Resolution Remote Sensing Imagery. Remote Sensing, 14(9), 2276. https://doi.org/10.3390/rs14092276