1. Introduction
Approximately 41% of Earth’s land surface is considered dryland, making drylands one of the most prevalent land cover types in the world [
1,
2]. Drylands are characterized by their low annual precipitation and soil moisture relative to other land cover types and are typically classified by the ratio of annual precipitation (P) to annual potential evapotranspiration (PET) [
1]. Through the progression of climate change, it is expected that global dryland cover will increase by 10% under high greenhouse gas emission scenarios relative to 1961–1990 climatology [
1,
3]. This dryland expansion is primarily associated with increased aridity as global temperature rises [
1,
2]. In addition to their high land cover percentage, drylands are home to more than one third of the global human population, are comprised of diverse ecosystems (e.g., desert, grassland, and savanna), provide humans with rangeland, cropland, and recreational area, and facilitate ecosystem functions and services (e.g., soil retention, nutrient cycling, carbon sequestration) [
1,
3,
4,
5,
6]. While dryland regions are highly valuable, as seen by their myriad benefits to humans and wildlife, their ecosystems are fragile and prone to rapid degradation. It is therefore paramount to understand the threats to dryland regions, and how to quantify them, to inform land and water resource management in these delicate regions.
Dryland ecosystems are extremely susceptible to subtle changes in disturbance [
1,
3,
4]. Common high-impact disturbances in dryland regions include abrupt changes in precipitation patterns, wildlife and livestock grazing pressures, shifting fire regimes, and land use [
1,
4,
6,
7,
8]. These disturbances often occur in tandem and have compounding interactions that can cause dramatic shifts in ecosystem structure and function and ultimately degrade dryland functionality [
1,
4,
6,
7,
8]. Metrics like net primary productivity (NPP) and Normalized Difference Vegetation Index (NDVI) are often used to measure such land degradation, as these metrics are proxies for vegetation health, with decreases (“browning”) indicating land degradation and increases (“greening”) indicating healthy land [
9,
10]. There is issue with this simplified way of assessing land degradation, however, as land health is not always a function of vegetation health/productivity [
11,
12]. An example occurring in dryland regions is called woody plant encroachment (WPE), which can be regarded as a type of dryland degradation when shifts from non-woody to woody plant dominance result in loss of land function and biodiversity [
4,
6,
7,
8,
11,
13]. Such processes would not be easily identified as land degradation when looking at greenness or NPP alone. Therefore, other metrics like vegetation structure (canopy height, cover, and density) are just as important as “greenness” and NPP for identifying land degradation processes at global and regional scales [
6,
12].
The intrusion of woody plants into grassland and savanna ecosystems has rapidly increased throughout global dryland regions over the past 100–200 years, threatening endemic biodiversity and socioeconomic stability [
4,
6,
7,
11,
14,
15]. WPE is a process of woody plant densification and occurs in both woody and non-woody plant communities through understory succession and canopy development [
11]. While WPE can facilitate restorative ecosystem shifts in landscapes that have been cleared for other uses (e.g., pasture or timber harvest), its rate has been unprecedented in historically stable grassland and savanna ecosystems, ultimately degrading them. WPE is primarily driven by changes to mean annual precipitation, soil properties, and changes to disturbance regimes (fire, grazing) [
1,
4,
6,
7,
8]. The relationships between these variables and how they drive woody plant extent is complex. Mean annual precipitation drives woody plant growth on a fundamental level, as more water availability spurs woody plant growth [
4]. However, as drylands become more arid, lower water tables can favor woody plants over herbaceous plants [
4]. Water availability can also result in changes to water efficiency between different plant species, influencing plant fitness [
4]. Therefore, water availability/precipitation alone cannot be used to predict whether WPE will occur. Soil type also plays into water retention, with clay-rich soils storing more water than silty or sandy soils [
16]. These factors, combined with the absence of major fires and increased grazing pressure, allow woody plants to recruit into grassland and savanna ecosystems. Historically, woody plant dominance has been stunted by fire-driven dieback and limited access to water, with links to indigenous humans helping drive fire frequency [
17]. Grasses and herbaceous vegetation recover more quickly from such disturbance and resource limitations, and generally re-establish before woody plants can gain dominance [
6]. Over the past two centuries, however, increased grazing pressures, decreased frequency and intensity of fires, and changes to precipitation patterns has led to rapid WPE in many areas [
4,
6,
7]. In dryland regions, WPE negatively impacts human and wildlife populations by decreasing grazing/cropland productivity, overlapping human–wildlife boundaries, and degrading land functions [
4,
6,
7,
14,
15]. For example, dryland degradation in the southwestern United States has been estimated to reduce net primary productivity by 35.9 ± 4.7 Tg of carbon per year [
18]. Land managers in dryland regions throughout the world are now faced with the challenge of identifying where and at what rates WPE is occurring at the landscape scale to prevent, control, and restore degraded drylands and protect the integrity of dryland ecosystems.
Current WPE management and mitigation strategies rely on access to accurate estimates of Fractional Woody Cover (FWC) to prioritize management areas, formulate budgets, and monitor mechanical/fire-based treatment effectiveness [
19]. FWC is defined as the proportion of area covered by woody vegetation and has been traditionally estimated by community-scale field sampling and/or landscape-scale remote sensing [
19]. Today, in situ and remote sensing data can be leveraged with new open-source machine learning (ML) algorithms to further enhance the scale of woody plant monitoring by training models to classify woody vegetation [
2,
19,
20,
21,
22,
23]. Once woody vegetation has been mapped effectively, land managers can strategically implement bush management methods such as mechanical removal, herbicide application, and controlled burning to efficiently combat WPE [
4,
19,
24]. Ideal methods for estimating FWC balance the use of field sampling and remote sensing by acquiring enough ground truth data to reliably classify larger remotely sensed areas through machine learning algorithms [
19]. While remote sensing data is crucial for large-scale estimates of FWC, few open-source datasets offer the ability to extract vegetation structure metrics, which play an important role in classifying woody vegetation for estimating FWC [
15,
19,
20]. Due to the high cost of Light Detection and Ranging (LiDAR) sensors, the large volume of data to collect and process, and the limited structure data capabilities of photogrammetry (cannot penetrate canopy), large open-source databases that satisfy a diversity of user needs are difficult to conceive, let alone actualize. In recognition of this data gap, the National Science Foundation, in partnership with a non-profit organization called Battelle, has established a highly diverse and comprehensive ecosystem monitoring network in the United States called the National Ecological Observatory Network (NEON) [
25].
The current landscape of remote sensing and ML integration highlights several top contending statistical models for classifying vegetation at scale, many of which rely on decision trees [
2,
19,
20,
21,
23]. Common ML models used to classify vegetation rely on “forests” of decision trees and include Bagging and Random Forest (RF). Bagging and RF are known as independent ML models, as each decision tree is constructed independently [
26]. Sequential ML models are another type of ML model that differ from independent models in that each newly generated decision tree is created based on information from the previous decision tree. These sequential models are commonly referred to as ‘boosting’ models (e.g., Gradient Boost (GB), eXtreme Gradient Boost (XGB), Light Gradient Boost (LGB), Ada Boost (ADA), and Cat Boost (CAT)). Upon review of current literature surrounding the use of NEON data to classify woody plants, only two major studies were found [
22,
23]. One study used semi-supervised neural networks to delineate tree crowns in a primarily closed-canopy forest [
22], while the other used pixel-based Random Forest to classify coniferous tree species in an open woodland ecosystem [
23]. With [
22] studying dense canopy complexity and [
23] studying open woodland canopy, a gap is presented in ML-driven vegetation monitoring at NEON sites with low canopy complexity. A combination of this gap in research and suggestions by [
23] that canopy complexity influences classification model performance helped inform our study site selection of NEON’s Santa Rita Experimental Range (SRER)—a long studied shrub/scrub ecosystem with relatively simple canopy complexity.
The broad goals of this study were to contribute to current understanding of optimal ML models for monitoring/managing woody vegetation in dryland regions by exploring novel data and approaches for monitoring woody vegetation patterns in a testable, replicable manner. Our focused research goal was to develop methods for monitoring woody vegetation cover and ecosystem change in dryland regions that are subjected to human management and global climate variables while making use of modern datasets. The methods from this study provide FWC estimates in a dryland region with relatively low canopy complexity. Optimizing FWC estimates will provide valuable insight and methods for land managers interested in pursuing large-scale vegetation monitoring in dryland regions.
This study addresses three research questions (RQs) to meet our goals:
(RQ1) What classification models and schemes most accurately classify woody vegetation at a dryland NEON site with low canopy complexity?
(RQ2) What variables are most important for classifying woody vegetation at a dryland NEON site with low canopy complexity?
(RQ3) How do FWC estimates derived from manual classification methods compare to FWC estimates derived from ML models?
2. Materials and Methods
The National Ecological Observatory Network (NEON) is an array of 81 terrestrial and freshwater study sites dispersed throughout the continental United States, Alaska, Hawaii, and Puerto Rico. NEON was established in 2016 by the National Science Foundation with the primary goal of capturing the ecological heterogeneity of the US. To accomplish this goal, NEON relies on its Aerial Observation Platform (AOP) and Terrestrial Observation System (TOS) to collect a comprehensive suite of airborne remote sensing and in situ sampling data across 20 ecoclimatic domains, from tundra to tropical ecosystems. All NEON data are open-source and can be directly downloaded from the NEON Data Portal (
https://data.neonscience.org/ (accessed on 23 August 2021)) [
27].
The NEON AOP began collecting data in 2013 and consists of Twin Otter aircraft mounted with a discrete waveform LiDAR sensor to capture ground structure and elevation, an imaging spectroradiometer to capture multispectral reflection data, and a high-resolution digital camera [
25]. The sensors are co-mounted within the aircraft and flown at an average altitude of one kilometer to deliver high spatial consistency between generated data products. The AOP is flown at each site annually, surveying a flight box that covers a minimum of 100 km
2. The remote sensing data collected and derived from the AOP is used in this study as ancillary/covariate data for mapping the extent of woody plants in dryland regions by supporting the development of ML models aimed at estimating FWC [
24,
25].
The NEON TOS began collecting in situ measurements in 2016. Data are collected every 1–3 years at each site by highly trained field technicians. A large variety of ecological data are collected at NEON sites; therefore, several types of plots have been established. Tower base plots (located in proximity around a sensor tower) and distributed base plots (spread throughout the entire study area) are plots used to collect vegetation data and are the source of in situ vegetation data for this study. Plots are established according to a spatially balanced and stratified-random design and are placed to represent dominant land cover classes according to the National Land Cover Database (NLCD) [
28].
Santa Rita Experimental Range (SRER) is a NEON site that falls within Domain 14: Desert Southwest. SRER is located approximately 25 miles south of Tucson, Arizona (31.91068°N, −110.83549°W) and is one of the most extensively studied dryland regions in the United States [
29]. SRER was established in 1903 by the U.S. Forest Service and managed by the U.S. Department of Agriculture until 1988, when management was handed over to the University of Arizona [
29]. The initial establishment of SRER was prompted by a severe drought in the late 1800s that wiped out ranching activities in the region. At first, research activities were focused on forage plants on the range, allowing scientists to determine phenology patterns, carrying capacity, and restoration strategies for the area, with the overall goal to understand rangeland and cattle management. Over time, research focus has shifted to general studies about climate change, environmental restoration, and ecological processes [
29]. SRER became a NEON study site in 2015 in pursuit of NEON’s goal to capture the ecological heterogeneity of the United States and is designated as a terrestrial core site within the network. A site overview is provided in
Figure 1.
Dominant vegetation at SRER is dependent on elevation, with trees (
Prosopis veluntina) and cacti (
Cylindropuntia spp.) dominating elevations between 975–1100 m and shrubs (
Larrea tridentata) dominating elevations below 975 m [
29]. Vegetation data collected at SRER indicate that most of the site falls within the Shrub/Scrub land cover class as defined by the National Land Cover Database with FWC estimated between 30–35% and an overall mean canopy height of 2.0 m [
16,
29]. The Shrub/Scrub land cover class is described as areas dominated by shrubs less than five meters tall, with shrub canopy typically greater than 20% of the total vegetation [
28]. Climate at SRER is characterized by semi-arid, hot conditions. Mean annual precipitation at SRER is 346 mm and occurs in a bimodal frequency, with most rainfall occurring as summer monsoons and winter rains [
29]. Mean annual temperature is 19.3 °C (67 °F) with diurnal temperature swings of up to 15 °C (59 °F) regardless of season [
13]. Soils at SRER are mostly composed of alluvial deposits from the nearby Santa Rita Mountains, with the most common soil subgroup being Typic Torrifluvents (hot, dry floodplain soils) [
13]. Soils at higher elevations have higher organic content, less salt, and lower temperature compared to soils at lower elevations [
13].
All data were downloaded from the NEON data portal (neonscience.org) and are listed and described in
Table 1. All data and imagery are from the year 2017, as this was the first year the AOP was flown at SRER. A total of 38 plots (18 tower, 20 distributed) at SRER had in situ vegetation data collected between 2016–2019 and all were used to create training data. Plot size ranged from 400–1600 m
2, with distributed plots being smaller than tower plots. LiDAR point clouds, hyperspectral imagery, and high resolution RGB imagery were collected using the NEON AOP. Data were collected at a period of peak greenness to ensure all vegetation were at maximum phenological stages.
Level-0 NEON AOP data products are raw, unprocessed data and are not used in this study. Level-1 data products are derived from Level-0 through geometric, atmospheric, and radiometric correction. Level-2 data products are derived from Level-1 through additional processing depending on the data product type. Level-2 CHMs for NEON sites are corrected so that canopy heights of less than 2.0 m are automatically set to zero. With a mean canopy height of 2.0 m at SRER, the Level-2 CHM did not capture the level of detail needed for this study. Therefore, the Level-1 classified LiDAR point clouds were used to manually generate CHMs through an open-source point cloud processing software called Cloud Compare [
35]. Point clouds were initially cleaned of erroneous points using a Statistical Outlier Removal (SOR) filter [
35]. Next, point clouds were visually inspected to remove any other erroneous points that may have been missed by the SOR filter. Once point clouds were cleaned, a plugin for ArcGIS Pro called LAStools was used to normalize height values for the point cloud [
36]. Using the “lasheight” tool from the LAStools plugin, the lowest point in each cloud was set to zero meters and all other points were scaled accordingly. Once cleaned and height normalized, point clouds were converted into CHMs, Canopy Density Models (CDMs), and Canopy Cover Models (CCMs) using the “lascover” tool from the LASTools plugin. These three data products are hereby referred to collectively as vegetation structure models. Each vegetation structure model was parameterized to match the resolution, extent, and grid placement of the Level-2 vegetation index models (NDVI, EVI, SAVI, and ARVI).
Once all vegetation structure models had been created, the Segment Mean Shift tool in ArcGIS Pro was used to segment the high resolution orthophotos into groups of pixels with similar spectral properties. Parameters of the Segment Mean Shift tool were adjusted until pixels from individual shrub crowns were delineated from their surroundings. Next, we used the Region Group tool in ArcGIS Pro to assign unique IDs for each segmented region. The Raster to Polygon tool was then used to convert the rasterized pixel groups into polygons. This polygon layer was used to generate zonal statistics for each vegetation structure and index variable by calculating the minimum, maximum, mean, range, and median pixel value for each polygon. The resulting polygon layer had these five statistics for each of the seven variables, leading to 35 total variables (shown in
Table 2 and
Figure S1). Figures starting with “S” can be found at the end of this document via the link to
Supplementary Materials.
Once the polygon layer had been populated with data, we proceeded with polygon classification. Two classification schemes were used in this study to classify polygons: binary and multiclass. Initial classification was performed using a simple canopy height threshold like those used in other studies [
2,
15]. Polygons with mean canopy height values greater than or equal to ten centimeters were deemed woody and polygons with mean canopy height values less than ten centimeters were deemed non-woody. A combination of in situ vegetation location data and aerial image confirmation were then used to manually reclassify any mistakes incurred by the initial thresholding. The multiclass dataset was derived from the binary dataset, but with a new “other” class. The “other” class was used to classify polygons with mixed cover and bare ground.
Once all polygons were classified, the dataset was exported to a Comma Separated Value (CSV) file and imported into the Jupyter Notebook programming environment for Python. Initial exploratory data analysis (EDA) was performed to explore our binary and multiclass training datasets, their properties, and relationships between variables. In the process of generating zonal statistics, some polygons did not cross the centroid of a single pixel, resulting in 151 records with null values. Our initial data cleaning removed these null records, leaving us with a total of 4339 polygons across the 38 training plots. Under the binary classification scheme, the woody and non-woody classes each comprised about half of the polygons (51.9%, 48.1%, respectively). Under the multiclass scheme, the woody class was more abundant (50.1%), followed by non-woody (37.6%), then other (12.3%).
Variable correlation was assessed with heat maps to understand the relationships between each variable. High correlation was observed between certain statistics for the same variable (e.g., mean and max, max and range) which is expected due to the nature of such statistics. High correlation was observed between the statistics for the canopy cover and canopy density variables, which is thought to be due to the growth form of shrubs (somewhat cube-like or spherical). High correlations were also observed between all vegetation indices due to their shared property of having higher values for photosynthetically active vegetation and lower values for anything else. All variables were also right skewed, with the most skewness observed in the canopy height statistics. This indicates that high values for any given vegetation index or structure variable–indicative of vegetation–are relatively uncommon in the training dataset and more field collection may be necessary to bolster the representation of woody plant properties in the data.
After EDA, each dataset was input into each machine learning model and performance was assessed. Five-Fold Cross Validation (FFCV) was used to train each model and assess its predictions. Performance was compared between decision tree-based and non-decision tree-based models for initial model selection. The top variables were then ranked by importance from all selected models using a simple voting method, where if a variable was in the top ten for a given model, it received one vote. Ten was chosen as the cutoff due to importance rapidly decreasing after the top ten variables for most models. The Boruta package in Python (Python Version 3.9.8, Python Software Foundation, Wilmington, DE, USA) was then used to further supplement and verify the initial variable selection method [
37]. The Boruta package allowed us to see variable importance for each of the five folds on the FFCV, granting more insight into variable importance.
Once top variables had been selected, models were reassessed using FFCV. Next, we performed model tuning by making adjustments to each model’s hyperparameters using a Grid Search method to determine the ideal settings for each model [
38]. A list of all settings tested for each model can be found in
Table 3 and visualized at plot level in
Figure S1.
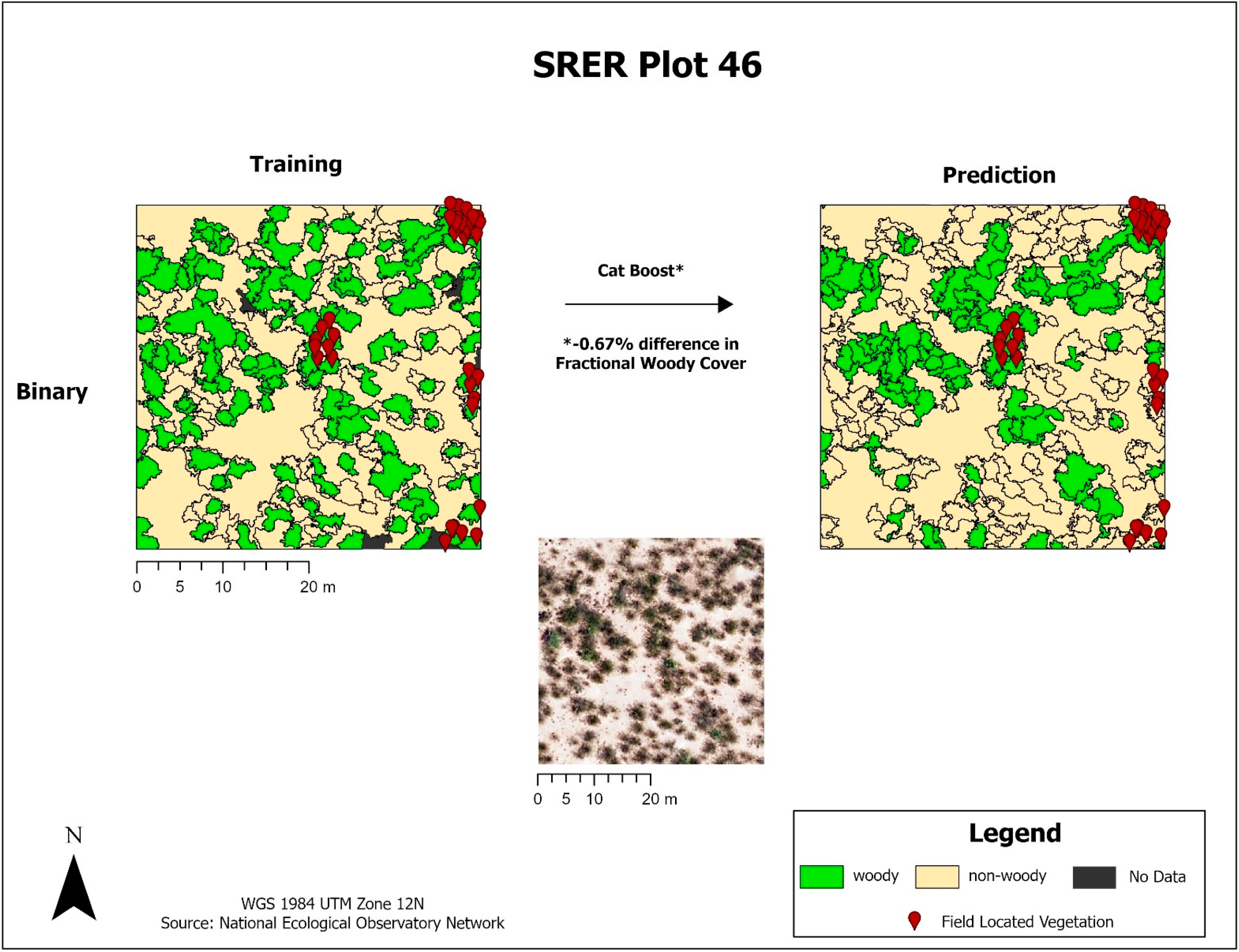
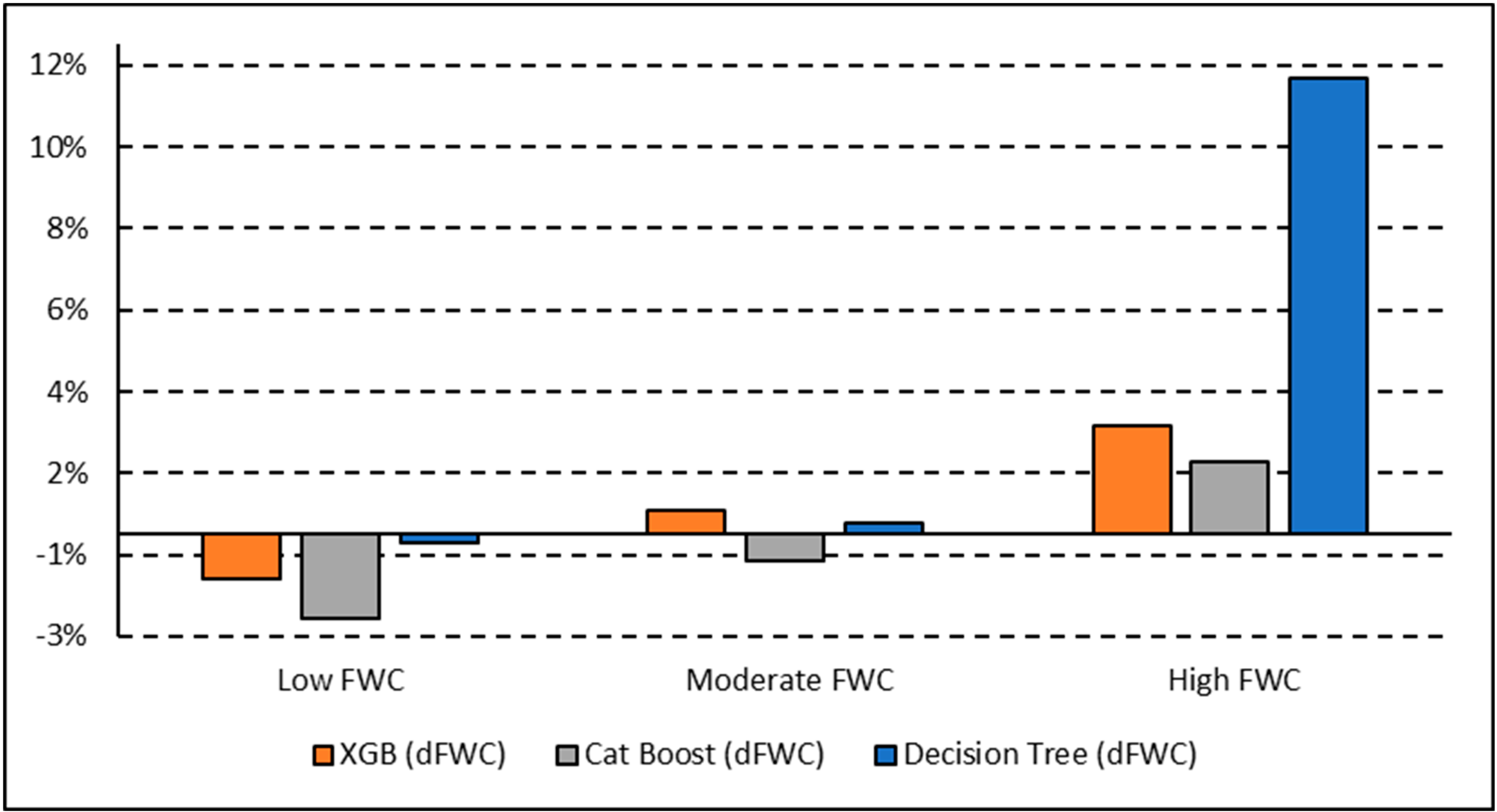
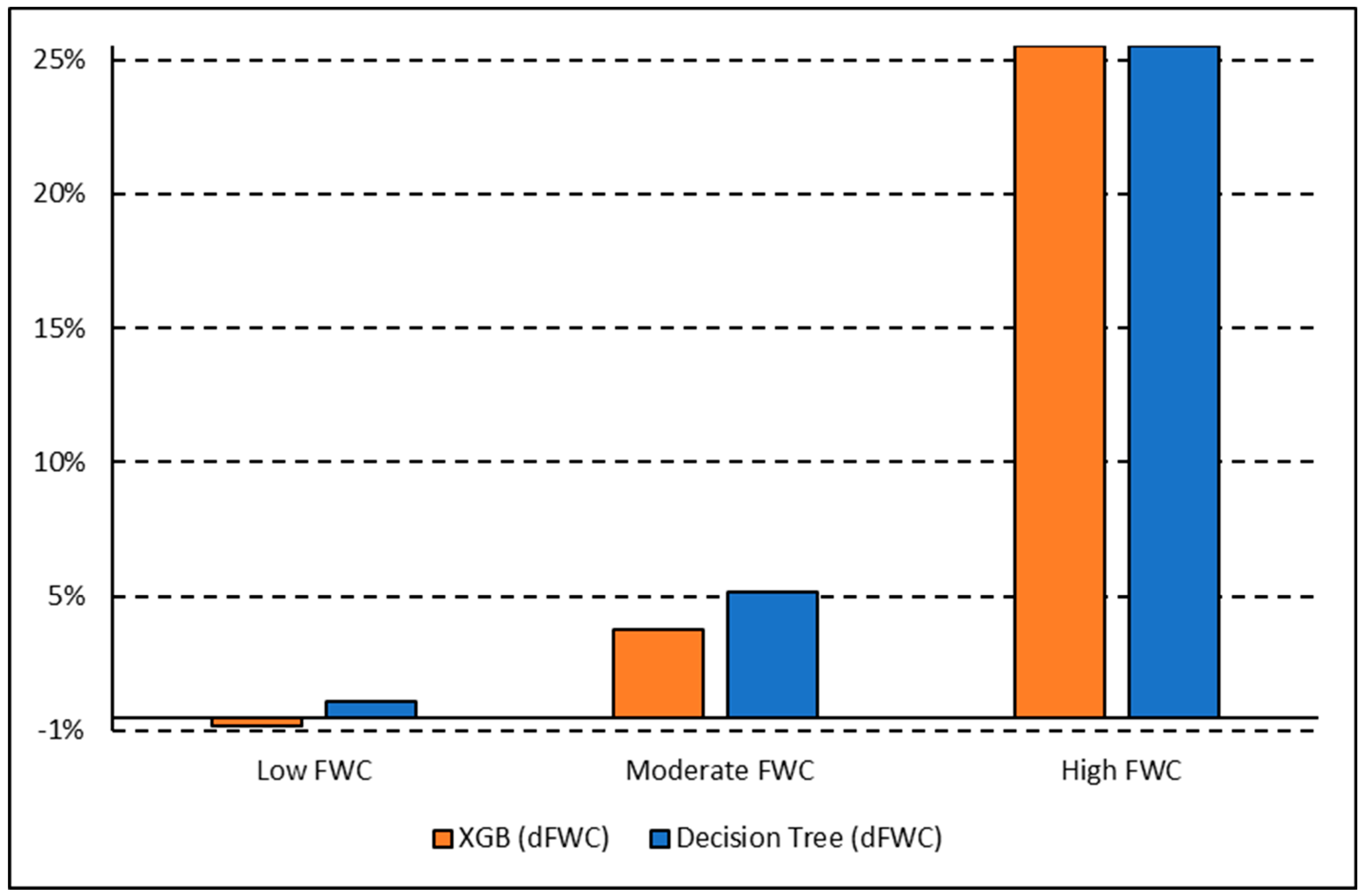
Once tuned, the finalized models predicted woody plant cover for the 1.0 km2 image tile that each training plot was contained within. A total of 20 image tiles were predicted due to the 18 tower plots all falling within a single image tile and another case where two plots fell within the same image tile. The results from each model were exported as a CSV and brought into ArcGIS Pro, where they were joined back to a corresponding polygon layer. A prediction field for each model and classification scheme was calculated from the model output, resulting in a polygon layer with predictions from each model. FWC was calculated from the training data and compared to predicted FWC for each model by calculating the difference in FWC (dFWC). Training sites were also ranked by FWC into Low, Moderate, and High to assess if canopy density influenced dFWC.
4. Discussion
Overall, we have answered all three of our RQs with the following conclusions:
- RQ1:
What classification models and schemes most accurately classify woody vegetation at a dryland NEON site with low canopy complexity?
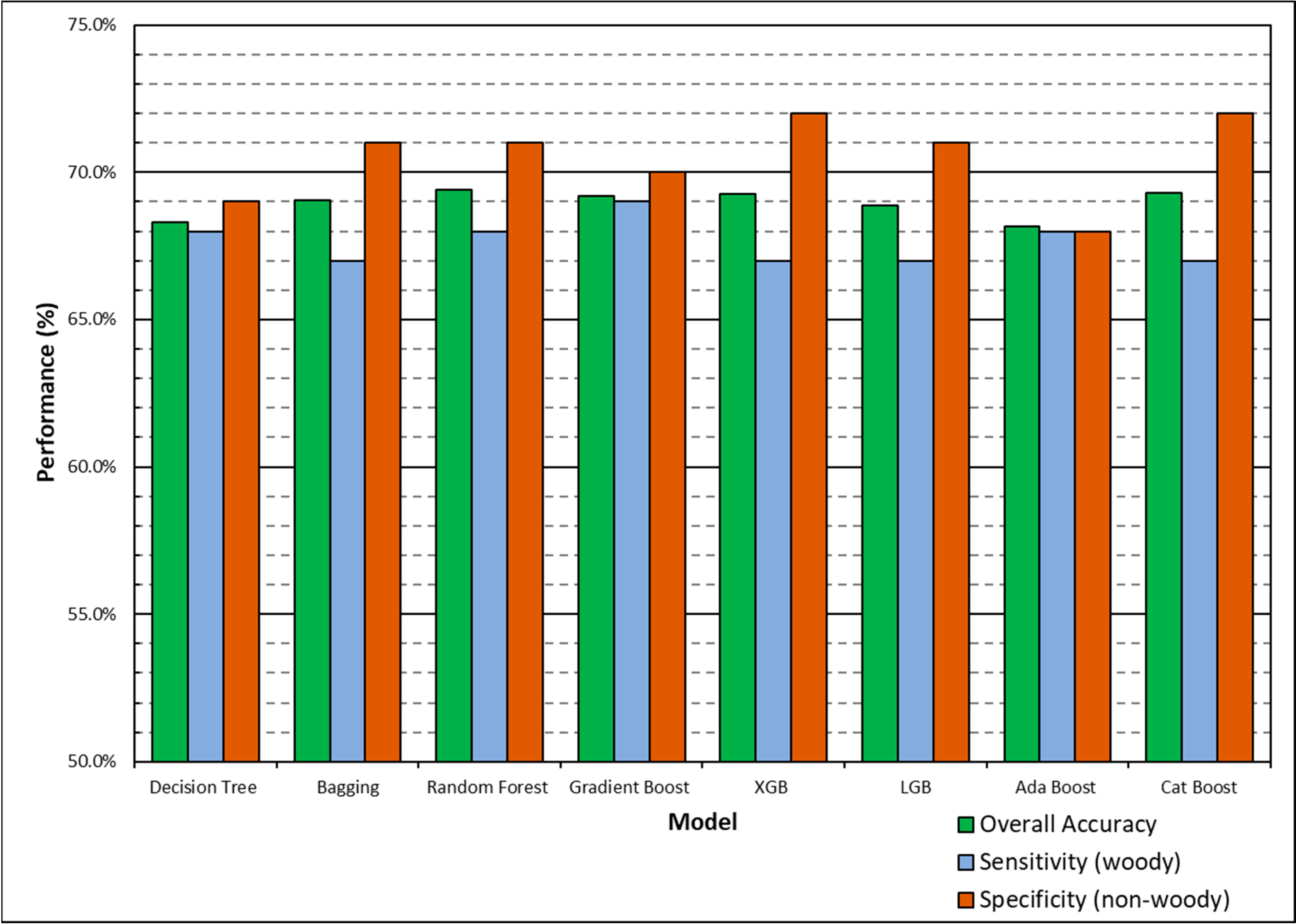
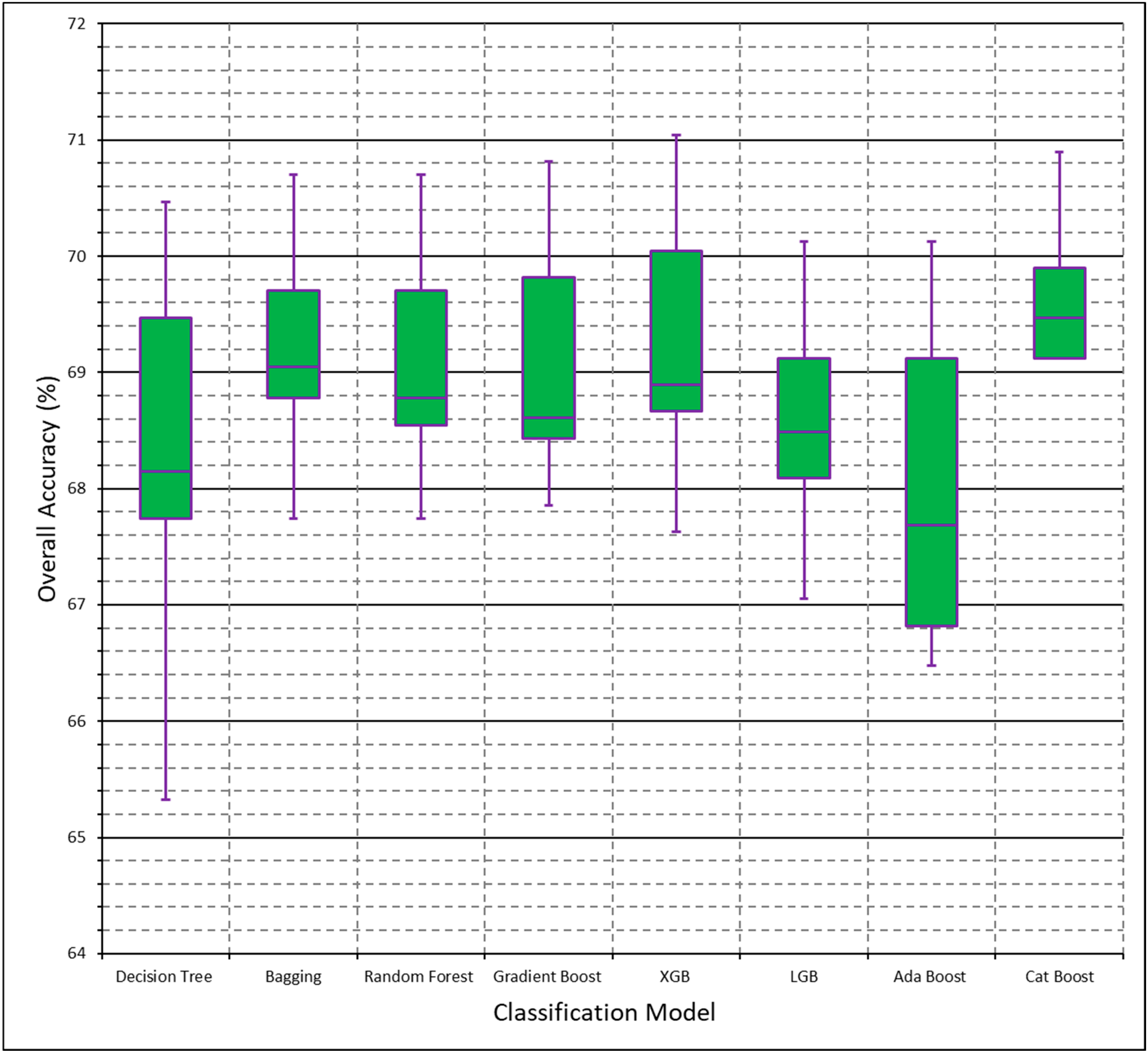
Decision tree-based models had higher model performance compared to non-decision tree-based models, with Gradient Boost having higher polygon-based classification accuracy in both initial and finalized models. We have also identified limitations with scikit-learn models, as Logistic Regression could not run without the removal of variables and Cat Boost could not be implemented with the multiclass dataset. In this study, we test both a binary (‘woody’ vs. ‘non-woody’ cover) and multiclass (‘woody’ vs. ‘non-woody’ vs. ‘other’ cover) scheme. It is important to denote that the ‘non-woody’ class in the binary scheme does not solely represent vegetation cover, as the ‘non-woody’ class can also represent non-vegetated areas such as roads, water, and bare ground. Conversely, the ‘non-woody’ class in the multiclass scheme solely represents vegetation cover, with the ‘other’ class handling non-vegetated cover like roads, water, and bare ground. The binary classification scheme had higher overall accuracy compared to multiclass, but the multiclass scheme may provide additional feature delineation that the binary scheme does not provide. More field data is needed to assess the type of features that the non-woody class represents, if there are common features. Narrowing down the high performing models and classification scheme uses will save time for future research by ruling out underperforming models and demonstrating the advantages of different classification schemes.
- RQ2:
What variables are most important for classifying woody vegetation at a dryland NEON site with low canopy complexity?
The only high-importance vegetation structure variable was mean canopy height, and all vegetation indices were deemed highly important, but only their mean, median, and maximum statistics. Narrowing down the best variables for classifying woody vegetation will save time for variable collection and processing in future work. For example, the generation of canopy cover and canopy density variables was unnecessary for this study. Model runtimes and error also improve with a smaller number of highly important variables. The variables tested in this study are only a small handful of the wide variety of variables collected by NEON, and future studies might consider testing variables such as leaf area index and canopy moisture content.
- RQ3:
How do FWC estimates derived from manual classification methods compare to FWC estimates derived from ML models?
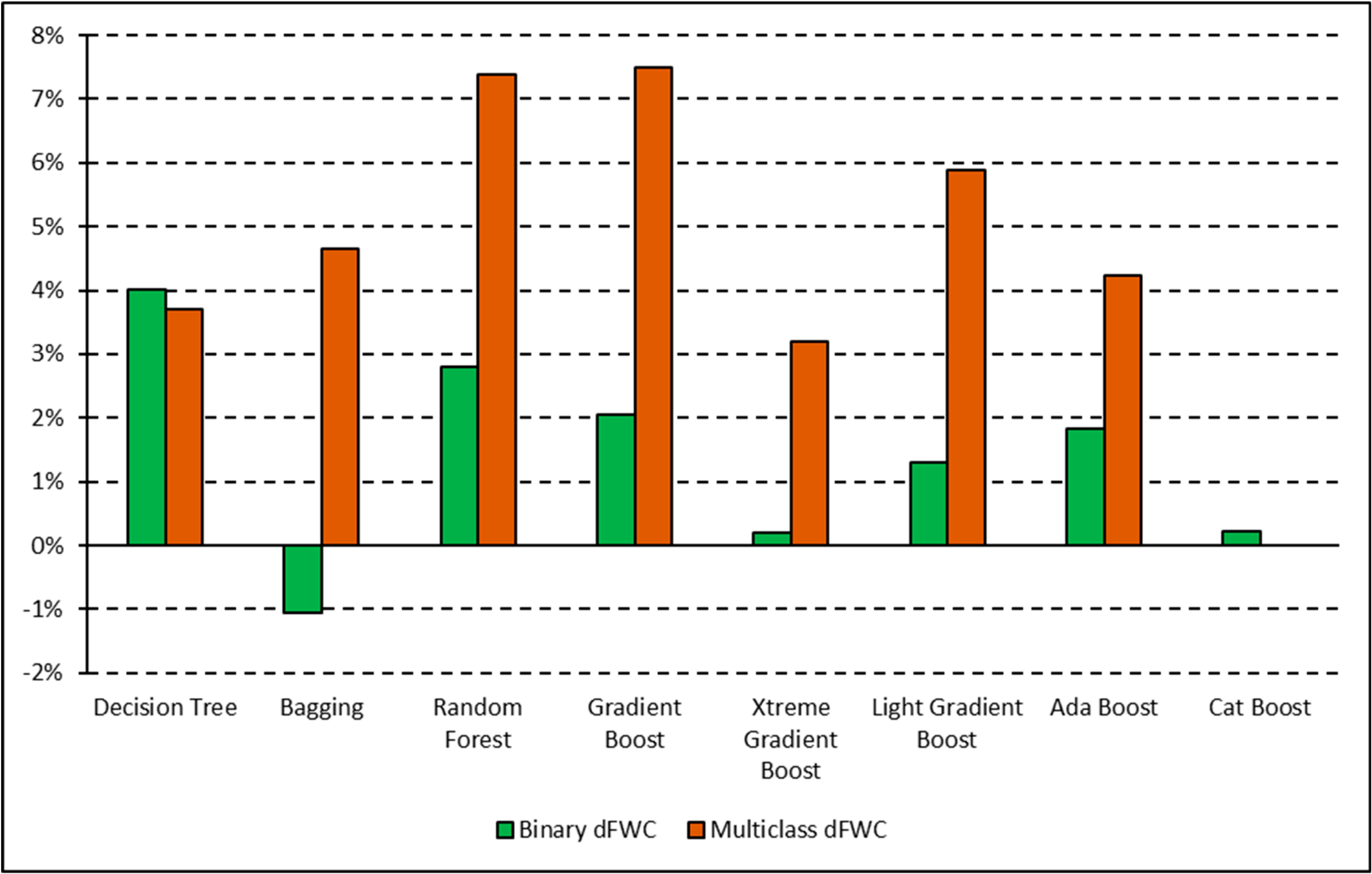
The XGB model had the lowest overall dFWC (0.2% for binary, 3.2% for multiclass) when compared to the manually annotated training data, indicating that it predicted gross FWC estimations with the highest agreeance. This dFWC metric has not been spatially assessed, however, to determine spatial accuracy. dFWC also differed depending on FWC at the plot level, with high FWC plots having much higher dFWC across models. This indicates that these models may perform best in low to moderate FWC areas, which is where most of the training data has been collected. More field sampling in the southern portions of SRER, where vegetation density and complexity is more robust, may improve estimates in areas of high FWC, but also introduce more prediction error for the low and moderate classes. Overall, manual classification methods have estimated FWC at 34.8% across all training plots, with a dFWC range from −1.1–7.5% when considering all models. This mostly falls within the 30–35% range suggested by [
16], indicating that both manual and automated classification methods are reasonably accurate overall.
While this study provides a good starting point for estimating FWC in a semi-arid region, it only provides a snapshot in time of the dynamic WPE process. As time progresses and WPE occurs, the annual data collected by NEON will be crucial for time-series analysis and change detection to assess the true extent and rate of WPE at SRER. With this study serving as a baseline establishment of FWC estimation methods, further studies that replicate these methods can be used with subsequent years of in situ and remote sensing data collection to monitor WPE throughout the study area and possibly throughout other similar areas of interest.
We also recognize that the variables used in this study are by no means a comprehensive representation of those that can be collected or derived to fully describe woody vegetation, nor do they represent all potential vegetation variables collected by NEON. Further variable selection is therefore necessary to assess variables like Leaf Area Index (LAI), Ecohydrological Index (EI), and Soil Moisture Index (SMI), to name a few. Finally, we also recognize that the training data used in this study is small relative to other studies. With the goal of using solely NEON data for this study, we were limited to the amount of training data included by the amount of data collected at the time of this study. Using data from other similar NEON sites, such as the San Joaquin Experimental Range (SJER), or future in situ and remote sensing data collected at SRER, would be expected to improve classification results.
5. Conclusions
The results from this study lay the groundwork for future use and implementation of NEON data by determining the best models, variables, and hyperparameter settings for predicting woody plant cover at SRER along with exploring different classification schemes. Land managers at SRER can apply these ML models to develop and monitor woody plant management strategies within their domain. With a planned mission time of 30 years, the volume of data collected at SRER will continue to grow, allowing developed models to be augmented and reassessed as land cover change occurs. This study also demonstrates the capabilities of using solely open-source NEON data and open-source code to train prediction models without any additional data collection—a workflow that can be implemented for any NEON site from anywhere in the world.
Land managers in other dryland landscapes where WPE is occurring can also use the methods from this study as a framework for developing their own models, and possibly use the models trained in this study to predict woody cover within their own domain, provided the same data are available and the sites have similar vegetation structure and distribution patterns. A prime example of such a location is the San Joaquin Experimental Range (SJER), which is the only other study area within the Desert Southwest Domain (D14) established by NEON. Using the models from this study to assess model performance at other manually classified training plots would provide more insight into model performance outside of their own training data.
With NEON in its infancy, limited work has been published that relies solely on its data to delineate or classify woody vegetation. Two other studies, 22,23], have accomplished this, but their chosen NEON sites were representative of open and closed woodland ecosystems, respectively. This study fills a research gap by developing woody plant detection models in shrub/scrub ecosystems with relatively low vegetation complexity. As suggested by [
23], the prediction models used for this study had higher classification accuracy than those conducted in more complex ecosystems, supporting their suggestion. The classification methods for this study are simpler however, as we only tested very general classes, rather than classifying at species level. The simplification of both the modeling framework and the vegetation complexity may be working in tandem to drive classification accuracy higher. Dryland regions have been traditionally defined by an aridity index (AI) as described in our introduction by the ratio P/PET [
1]. Use of ML to model dryland migration under the context of climate change has consistently predicted an overall expansion of global dryland cover [
1]. In 2021, Berg & McColl [
39] suggested that a new index, coined the ecohydrological index (EI), may be more appropriate for predicting dryland migration, as it takes plant physiology and soil moisture into account rather than solely relying on climatic variables. In their study, Berg & McColl [
39] found that dryland expansion will not occur under the RCP 8.5 climate scenario when using EI as a metric, which is highly contradictory to past studies. Therefore, further investigation of EI as a predictor of drylands is necessary both under the current and future climate models published by the IPCC. Luckily, all variables needed to calculate EI are collected and publicly available through the NEON data portal, further highlighting its future role in investigating ecosystem dynamics.
The National Ecological Observatory Network (NEON) is the largest and most comprehensive ecological dataset of its kind, with the promise of 30 continuous years of high-resolution remote sensing and in situ monitoring over its 81 field sites. Discovering how we can use solely NEON data to train Machine Learning (ML) and Artificial Intelligence (AI) models for land cover prediction is vital to land managers throughout the world looking for new and cost-effective ways to gain insight to their changing landscapes. As more data is collected at these NEON sites, models and methods such as those tested in this study have the potential to evolve in ways that will inform land management strategies far into the future. Successive studies conducted with this data may investigate other ML/AI models, additional variables collected by NEON, and change detection of FWC over time and in response to woody plant management regimes.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}