1. Introduction
Cereal, pulse, and oilseed crops of the Palouse wheat-growing region of Eastern Washington and Northern Idaho are adapted to circumneutral soil pH and experience nutrient deficiencies and metal toxicities when grown in acidic soils. In particular, acidified soils can lead to aluminum toxicity in crops, which stunts growth and limits productivity [
1]. Soil acidification is a growing problem in agricultural soils of the Palouse that results from two processes: (1) soil weathering, where the depletion of soil organic matter and leaching of base cations such as calcium and magnesium from the soil profile decrease the cation exchange capacity of the soil matrix and (2) nitrification of ammoniacal fertilizer followed by leaching of nitrate anions from the soil profile. These processes are counteracted by evapotranspiration [
2] and are accelerated by excessive nitrogen fertilizer applications and the removal of base cations in harvested crop biomass [
1]. The Palouse region is characterized by steep hillslopes with a legacy of intense soil erosion, resulting in exposure of subsoil on ridge tops, soil inversions in low-lying areas, and discontinuous argillic horizons at variable depths within soil profiles [
3,
4]. These topographic features and past soil disturbances create extreme field-scale variability in terms of soil moisture, rooting depth, crop yield, soil organic matter, and vertical and lateral water flow, which in turn influence the rates of evapotranspiration, nitrification, nitrate leaching, and removal of base cations via the leaching and harvesting of crop biomass [
4], all of which result in highly variable rates of soil acidification and soil pH at the field scale.
Soil acidity can be neutralized with calcium carbonate and other lime amendments. Recommendations for lime application rates are determined via soil buffer tests, which give a better indication of lime requirements than pH alone by measuring the pH of soil in a buffered solution. Comparison of several buffer tests by McFarland et al. with lime incubations in soils of the Palouse has demonstrated that the modified Mehlich buffer procedure produces the most accurate results [
5,
6]. However, both lime amendments and extensive soil testing to capture the field-scale variability on Palouse farms are often prohibitively expensive. A method of soil sampling that minimizes the number of points and allows accurate interpolation of liming requirements would permit precision application of lime and reduce input costs. A few studies have investigated remote sensing for pH prediction, including Gogumulla [
7] and Zhang [
8], who reported RMSEs of 0.35 and 0.3 using random forests and partial least squares, respectively. These studies do not incorporate spatial relationships in the data.
Spatial sampling optimization is an active area of research structured around one of two assumptions: design-based or model-based. In design-based sampling, sample independence is derived from the random selection of sample locations while sample values are considered fixed [
9]. This situation is reversed for model-based sampling, which is more common in the geostatistical community and accommodates regular grid sampling. Using one of these assumptions, simulated sampling can be conducted to optimize sampling locations for kriging to attain the lowest-error interpolation [
10] or to optimize other statistics, such as global means, variogram ranges, or linear model coefficients, with the aim of minimizing variance and bias. Sampling optimization methods include simple random sampling (SRS), where points are selected spatially at random; geographically stratified sampling (GSS), where the sampling area is divided into a grid with SRS in each cell; and covariate stratified sampling, where the data are stratified by covariates with SRS in each stratum (e.g., stratifying by soil type and slope, and sample for organic matter). One model-based approach where these strategies are combined is K-means clustering by covariates and geographical coordinates to produce strata that optimally disperse samples in covariates and space, for example, as achieved by Wang [
11] and Kidd [
12].
In order to optimize field sampling to interpolate soil lime requirements, a predictive model that incorporates spatial error structures and permits Monte Carlo simulation of the variable of interest is needed. Bayesian hierarchical models (BHMs) are an extension of linear modeling that estimate variables using Bayes’ Theorem to propagate random errors through a hierarchy of equations [
13,
14,
15]. For example, the observations z are conditionally distributed on latent variables y and parameters θ
1. At the next level in the hierarchy, y is conditionally distributed on other parameters θ
2. Finally, the parameters θ are described by distributions which iteratively fit. In equations, this looks like
In practice, y might be a linear function of covariates, plus a random error, which can be spatially correlated. In this case, the slopes and correlation parameters follow random distributions. This structure allows random instances of the variables to be generated through Monte Carlo Markov chain methods, as in the R package spBayes developed by [
16]. BHMs have been applied in pricing crop insurance, for example [
14]. As an example, crop yield might be a linear function of average temperature, fertilizer applied, and normalized difference vegetation index (NDVI), with a spatially correlated random error. Temperature, fertilizer, and NDVI, at the lower level of the hierarchy, would have their own error distributions.
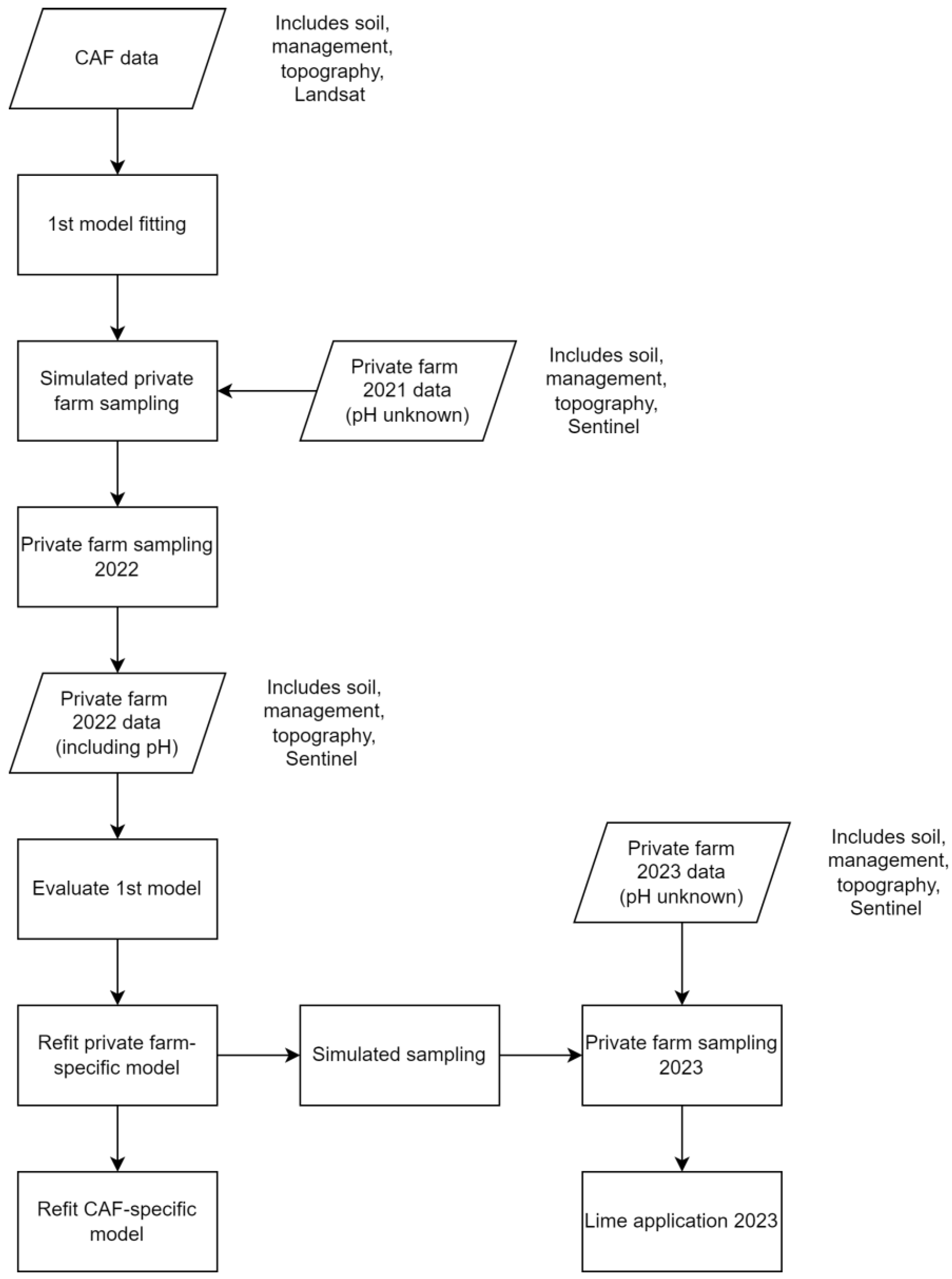
To obtain data for use of these models, there are two experimental modalities considered in this paper. Long-term agricultural research permits the monitoring of soil processes such as soil acidification and crop management impacts such as soil erosion that manifest incrementally over long periods of time [
17], while on-farm research enables scientists and engineers to work directly with farmers to gain information from expanded sampling environments that is relevant to real-world farm operations [
18,
19]. This study combined data from both a long-term research site and a local farm in the Palouse region to develop optimal sampling strategies for the determination of lime requirements in Palouse soils. We first generated a model for soil acidity based on the research site data. Then, we used this model to generate a sampling plan for the local farm and sample accordingly. After evaluating the model’s performance based on soil pH and modified Mehlich buffer tests from the local farm samples, we developed revised models and re-evaluated these at both sites. This method addresses a major problem for farmers in the Palouse, and we expect that sampling plans can be similarly developed to capture field-scale variability in soil acidity on farms throughout the world. With additional test farms, it could be expanded to different regions. A flow chart showing the process used in this study is provided in
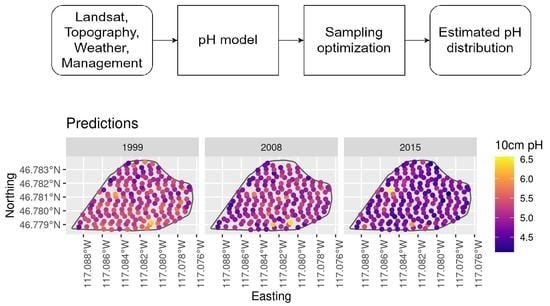
Figure 1.
2. Methods
The USDA Long-Term Agroecosystem Research (LTAR) region under consideration is shown in
Figure 2. The study was conducted on two nearby sites in the Palouse/Eastern WA dryland cropping system: a research farm (the R.J. Cook Agronomy Farm) and a privately owned farm. The Cook Agronomy Farm (CAF) (
Figure 3) is a 37 ha site operated as part of the USDA Long-Term Agroecosystem Research (LTAR) network, and a brief description of the vast dataset collected there is included in work by Huggins [
20]. Topography is highly variable and has been characterized by a 2 m resolution digital elevation model using a Trimble RTK 4400. Soils are mostly Thatuna (a fine–silty, mixed, superactive, mesic Oxyaquic Argixeroll), Palouse (a fine–silty, mixed, superactive, mesic Pachic Ultic Haploxeroll), and Naff (a fine–silty, mixed, superactive, mesic Typic Argixeroll) soil types [
21]. For the on-farm portion, we investigated the northeast quadrant of the property located near Palouse, Washington (
Figure 4). Soil survey data indicate that the predominant soil type at this location is Thatuna silt loam [
21].
On the CAF, harvest samplings at 369 georeferenced points have been conducted annually for over 20 years of crop rotations. Of these points, 177 were sampled in 1999, 2008, and 2015 with 153 cm deep by 4.1 cm diameter soil cores. Cores were classified, described by soil horizon, and divided into 10 cm depth increments, which were dried, sieved, and analyzed for numerous soil properties, including soil pH (
Figure 5 and
Figure 6). This was measured in 1:1 soil and water slurries with a Denver Instrument Model 250 pH ISE conductivity benchtop meter or an Accumet AB200 Benchtop pH/Conductivity Meter with a saturated KCl-filled, glass electrode using methods from [
6]. Georeferenced points at the CAF farm were additionally sampled for harvested grain and residue biomass in a 2 m
2 area. Air- and oven-dried masses of the plant material were measured, and then finely milled sub-samples of grain and residue were analyzed for bulk carbon and nitrogen concentrations via combustion on a Costech ECS4010 Elemental Analyzer. Satellite data consisted of Landsat 5, 7, and 8 analysis-ready multispectral surface reflectance data controlled for clouds, sensor saturation, and other errors, acquired in between the planting and harvest days of harvest years 1999, 2008, and 2015. The following NDVI-based metrics were used in this study: maximum NDVI (NDVI0), maximum rate of NDVI (NDVI1), days after planting when NDVI rate was at a maximum (NDVI2), minimum NDVI (NDVI3), minimum rate of NDVI (NDVI4), and days after planting when NDVI rate was at a minimum (NDVI5).
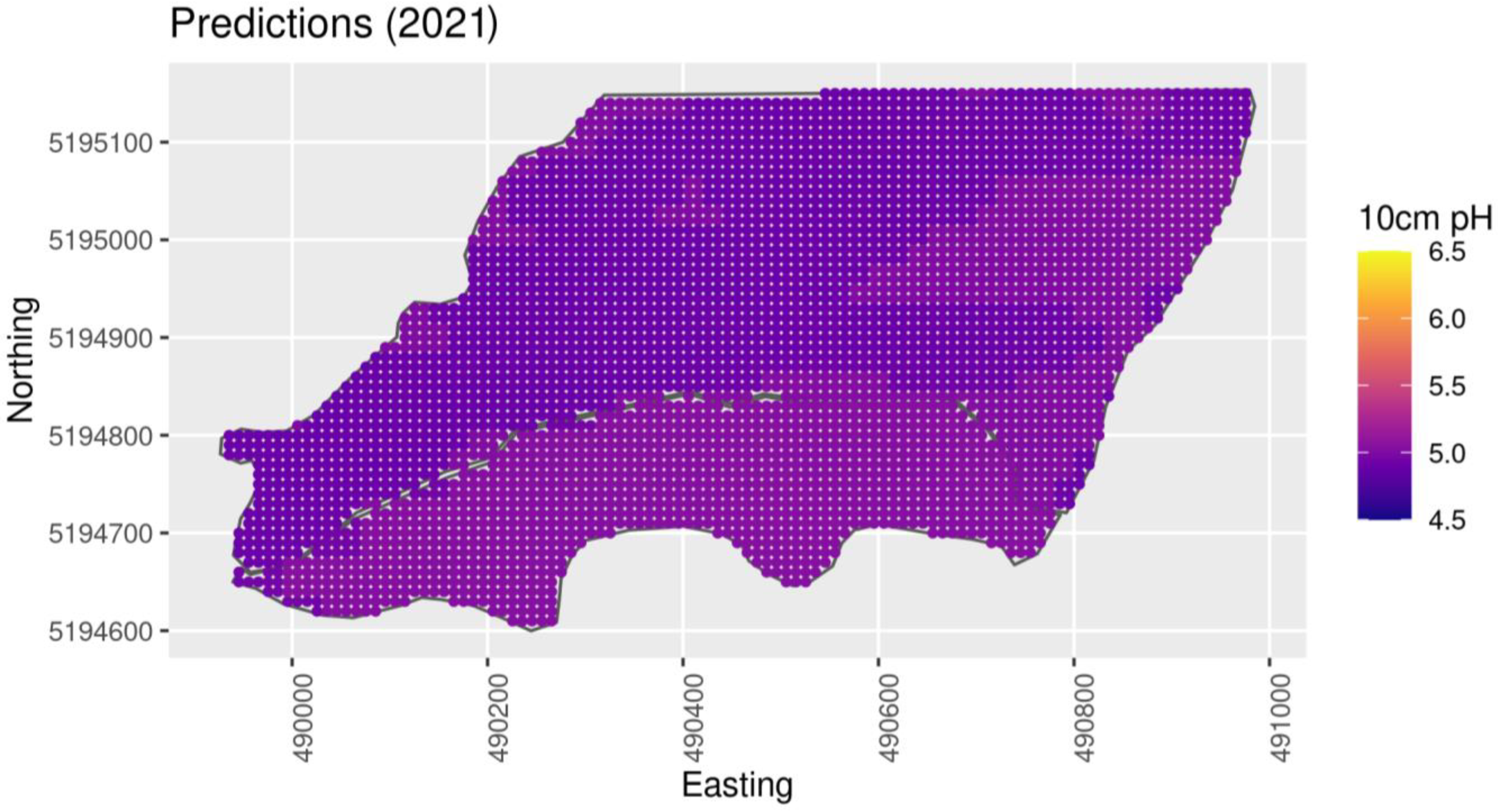
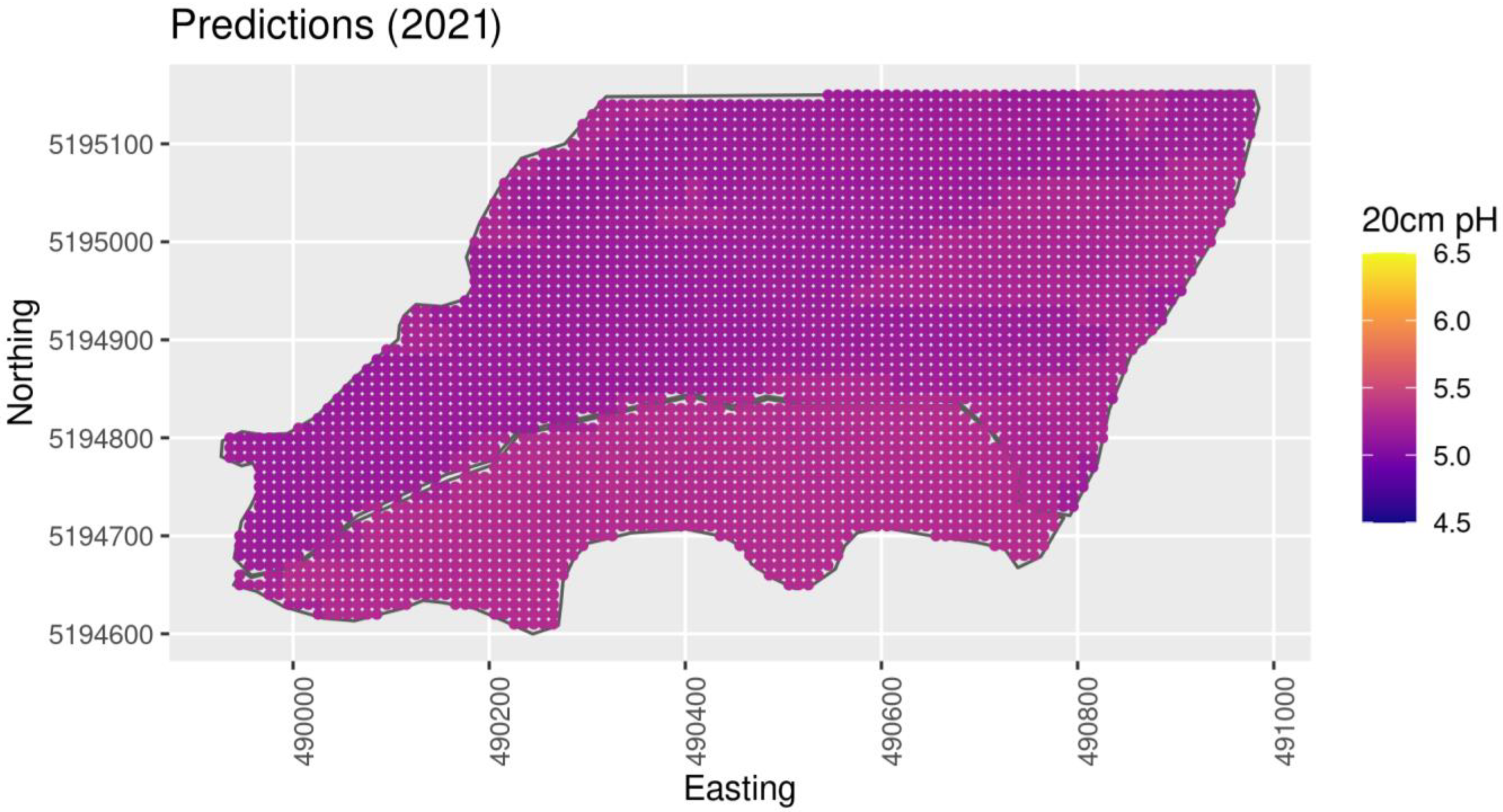
The north section of the private farm, as shown in
Figure 4, was planted with chickpeas in 2021; the south was planted in spring with pea. In 2022, the entirety was planted with winter wheat. Following the 2022 wheat harvest, soil sampling occurred at 75 points determined through methods described in subsequent sections. These samples were taken only from 0–10 cm depths due to time and labor constraints, and were analyzed with a Fisher Accumet AB200 probe using similar methods to the CAF sampling procedure given in [
22]. Additionally, the farmer specifically requested modified Mehlich buffer pH as an indicator of lime requirements, so this analysis was performed accordingly [
23]. Satellite data consisted of Sentinel 2 multispectral data, filtered for cloud cover, acquired in between the planting and harvest days of harvest years 2021 and 2022, and SRTM elevation, all of which we transformed into similar topographical variables as CAF using the same methodology. Multispectral data were also transformed into the same variables as for CAF.
Initial variable selection for the CAF was based on observed correlations in pair plots and known physical relationships (described in Results). A summary of the variables examined in this study is given in
Table 1.This was used as the basis for a Bayesian model to generate simulated samplings based on the private farm data for 2021. Modeling for interpolation and simulated sampling was conducted using the spBayes package [
16] in R [
24]. A multivariate model was chosen to incorporate the strong relationship between pH at 0–10 cm and that at 10–20 cm. The model included exponentially spatially correlated noise as well as a Gaussian sampling error term and covariates derived from management, remote sensing, soil survey, and topography.
Using the spBayes model for CAF to generate synthetic data for the private farm, we developed a k-means stratified random sampling design [
10,
12]. This design ensures good coverage in space, particular that of relevant covariates. Variables used for cluster generation included face (whether the point was north- or south-facing), GYZ (normalized yield), easting, and northing. Based on typical availability of farm labor, fewer than 100 samples would be practical to collect. In Monte Carlo simulations, 1000 different instantiations of field samplings were generated, each of which was sampled 100 times, for a different number of total samples and k-means clusters (e.g., 100 points and 10 clusters, 80 points and 16 clusters). The means and variogram ranges of soil pH at 0–10 cm and 10–20 cm depths were calculated from the synthetic sampling data for each combination of instance, sampling, sample number, and cluster number. The mean and variance of these soil acidity indicators were calculated for all instances and samplings and compared to values calculated using all points to identify an unbiased sampling design with minimal variance.
Soil samples at 0–10 cm depth were collected at the private farm according to the selected sampling design, and pH and lime requirements were determined as described above. These new data prompted an assessment of the model’s performance. To check the Bayesian model’s interpolation, 20% of the points were withheld, and the root mean squared error (RMSE) and Pearson’s correlation (r) of the interpolated values were used to assess the fit. To cross-validate, this process was repeated 5 times, with different selections for training and testing sets. The Deviance Information Criterion (DIC), also cross-validated, was used to assess the model fit with penalty for parameterization. The CAF model was assessed on the CAF dataset (pH 0–10 cm and pH 10–20 cm) as well as the private farm dataset (pH 0–10 cm only). Cross-validation was not used when testing the 1st CAF model on the private farm, since it was trained on the CAF data.
After initial model assessment, new models were fit for each farm. The CAF dataset did not include modified Mehlich buffer pH, and private farm dataset did not include 10–20 cm soil depths, so separate model structures were necessary for each situation. The final model variable selection was conducted through an exhaustive search for many variables, including the presence of a Bt horizon, NDVI metrics, topographical variables (aspect, slope, and elevation), and nitrogen fertilizer rates. Bt and face were binary indicator variables (i.e., Bt = 0 means no Bt horizon; face = 0 means north-facing). We used dredge from the R package MuMIn [
25] with the objective of minimizing the Aikake Information Criterion (AIC). The new models were reassessed as above. Additionally, a qualitative evaluation of the gap filling is provided through the interpolated pH map.
4. Discussion
The CAF long-term agricultural research site provided a rich historical dataset, permitting the development of a model for interpolation of soil pH from limited direct measurements based on factors that could be easily measured in on-farm settings. The private farm in turn provided a complementary dataset at a similar commercial site, permitting the improvement in model performance on both the CAF and the private farm. The farmer will use the data collected in a follow-up sampling in 2023 based on the improved model to make real-world decisions regarding lime application to raise soil pH with minimal input waste and soil testing costs to accommodate practical constraints surrounding farm labor and timing of farm operations. Having established a working relationship with a farmer, we can continue sampling in subsequent seasons to observe the outcomes of a precision agriculture approach in a real-world scenario that would not be feasible on the research farm. The drawbacks of the on-farm approach were primarily the constraints imposed by working around the field operations and the limited availability of historical data for the farm. This approach combining long-term and on-farm research demonstrates the power of researcher–stakeholder collaborations and knowledge co-production in agriculture [
17].
A few interesting trends were observed in the data when both farms were considered. NDVI5, slope, and Bt horizons were important covariates on both farms. This shows that senescence timing, topography, and restrictive layers such as argillic horizons all influence the field-scale variability of soil pH. Early senescence was associated with low soil pH on both farms. This could represent a soil-acidifying feedback loop whereby limited crop growth results in decreased evapotranspiration to counteract the downward leaching of base cations through the soil profile [
2], decreased nitrogen uptake results in further soil acidification via nitrification of excess ammoniacal fertilizer, and soil-acidity-induced Al toxicity results in an ongoing decrease in crop growth [
2]. However, the senescence rate must be used with care to predict soil pH as some crops, such as chickpeas, are chemically senesced for harvest. The two farms exhibited opposing trends linking soil pH to the presence of Bt horizons, possibly reflecting differences in the continuities and spatial extents of the restrictive layers. The link between low soil pH and Bt horizons on the private farm could be explained by localized decreased rooting depth leading to decreased evapotranspiration and decreased nitrogen uptake, similarly to early senescence. On the other hand, the link between high soil pH and Bt horizons on the CAF research site could reflect argillic horizons with sufficient continuity and spatial extent to create seasonally perched water tables that limit the downward leaching of base cations and lead to high soil moisture levels that inhibit microbial nitrification reactions. Regardless of the mechanisms, senescence timing, topography, and Bt horizons (via soil survey data) are all simpler to assess than soil pH in on-farm settings such that the model developed from the CAF and private farms can be used to improve the efficiency of lime applications without burdensome soil testing.
The interpolation results show satisfactorily low RMSEs could be obtained for pH and MMpH at 0–10 cm, using a limited number of samples, in comparison to other studies predicting pH, which achieved RMSEs of 0.3–0.35 [
7,
8]. The DIC of the initial model versus that of the revised models shows that increasing the number of parameters improved the applicability of this technique for designing precision lime applications, where fine-resolution maps of buffer pH are needed but difficult to obtain for farms over 50 ha. However, some sampling is still necessary to capture the baseline level of acidity. This depends a great deal on the long-term management history, which can be difficult to incorporate into a model.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}