



Bi-Objective Crop Mapping from Sentinel-2 Images Based on Multiple Deep Learning Networks

 , ,
, ,
Abstract
:1. Introduction
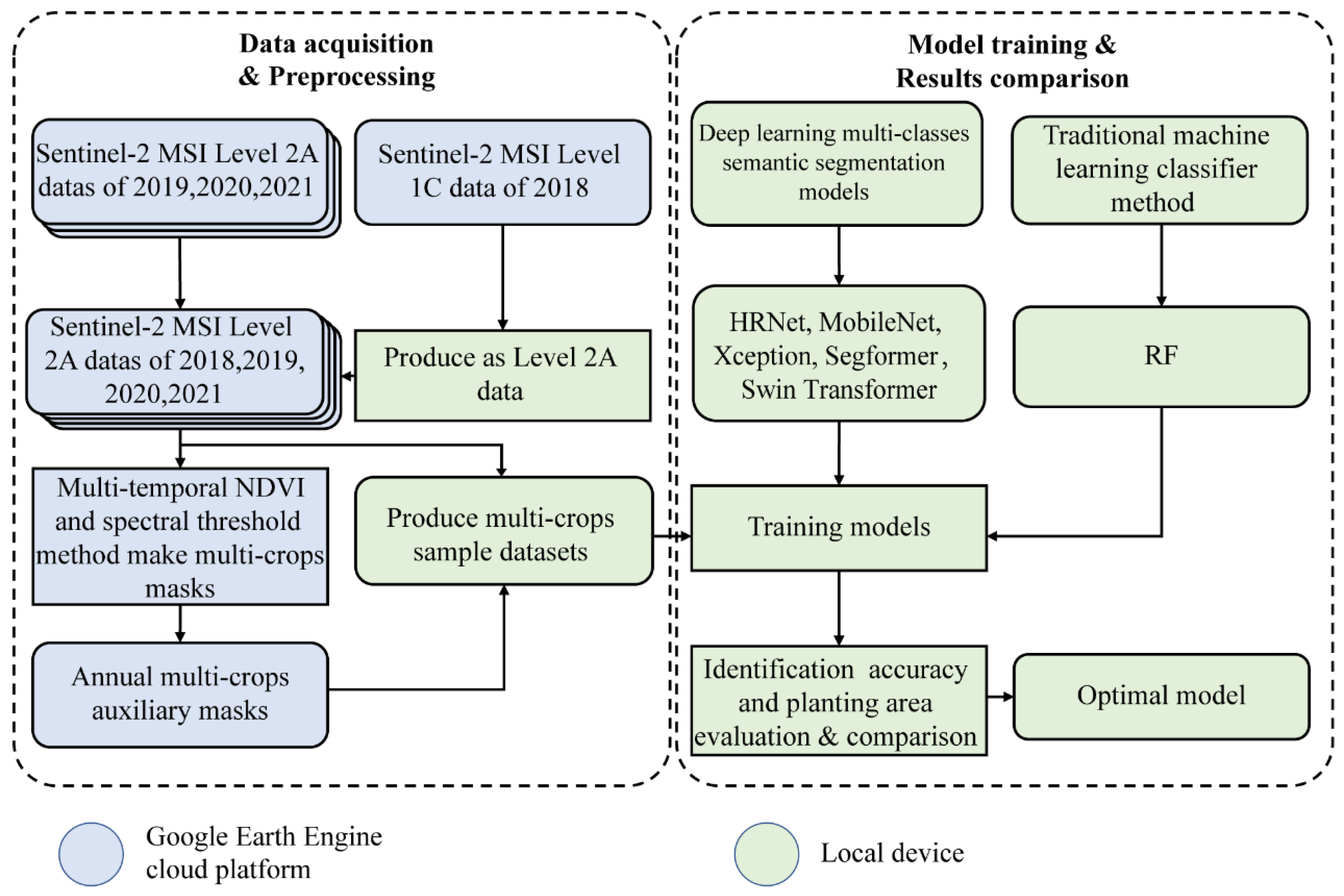
2. Materials and Methods
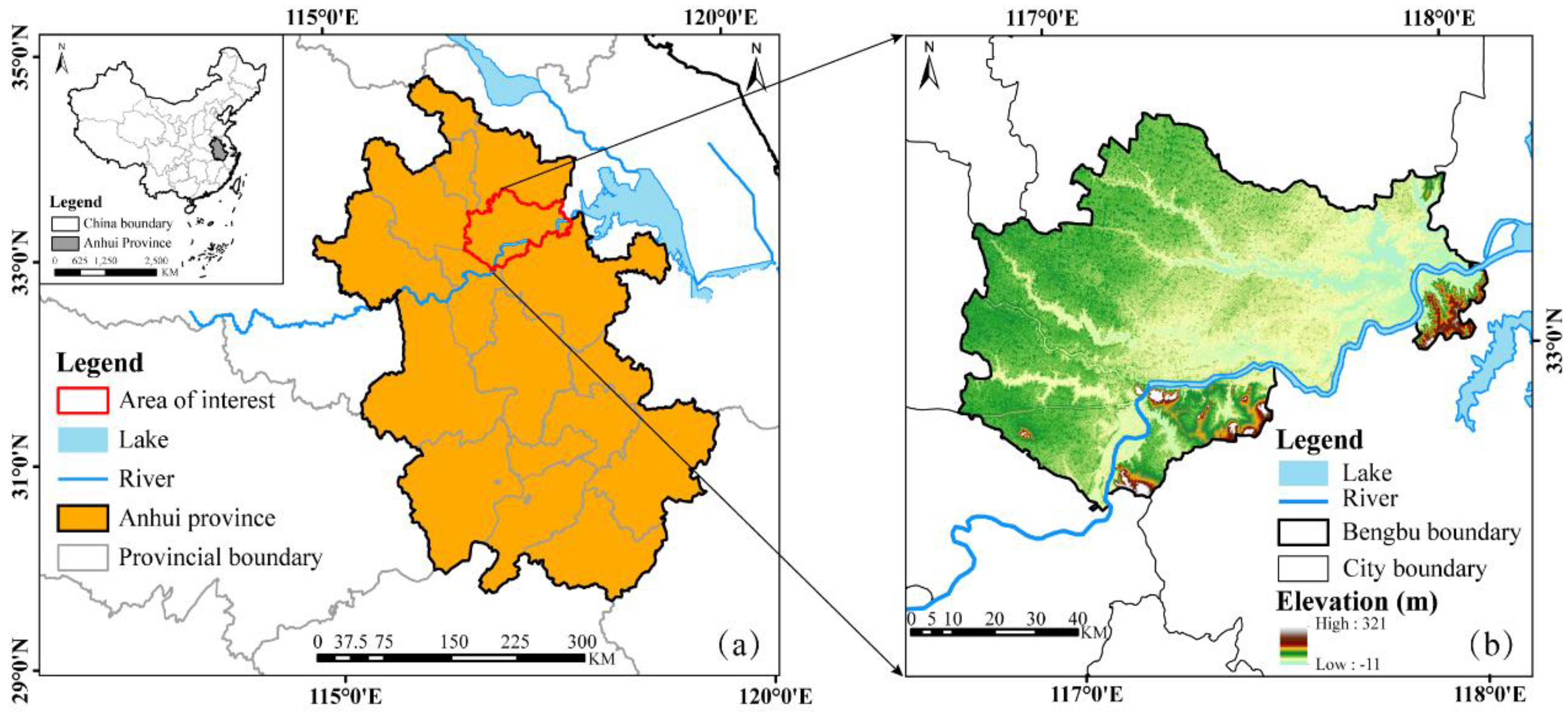
2.1. Study Area
2.2. Data
2.2.1. Sentinel-2 Imagery
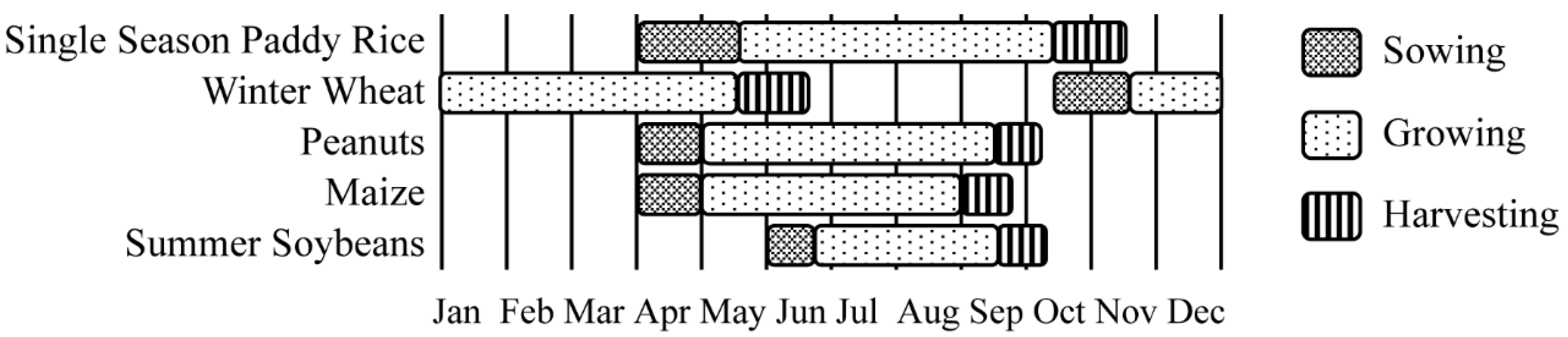
2.2.2. Crops Phenology Information
2.2.3. Production of Auxiliary Reference
2.3. Methods
2.3.1. Data Preprocessing and Annotation
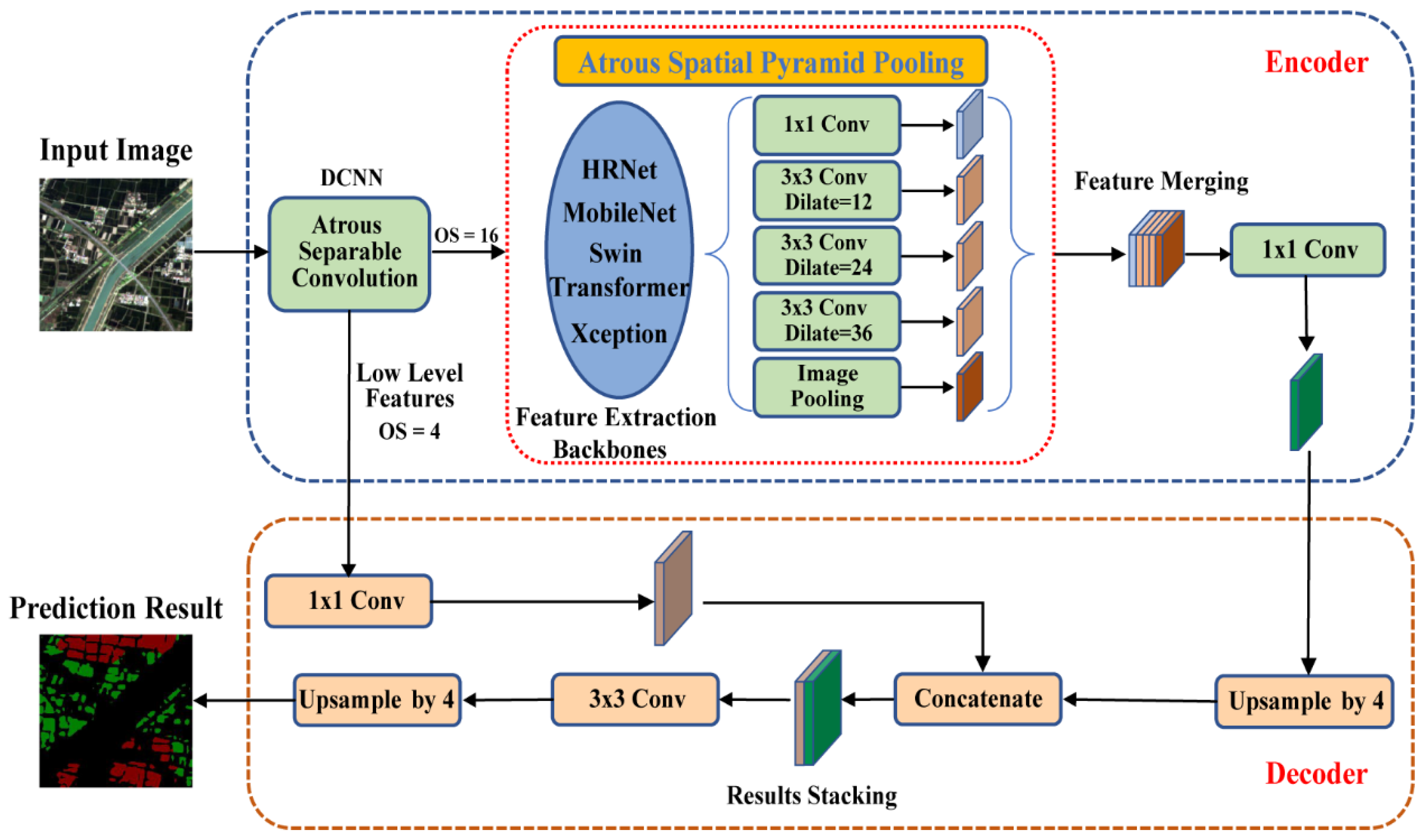
2.3.2. The Improved DeepLabv3+
2.3.3. HRNet, MoblieNet, Xception and Swin Transformer
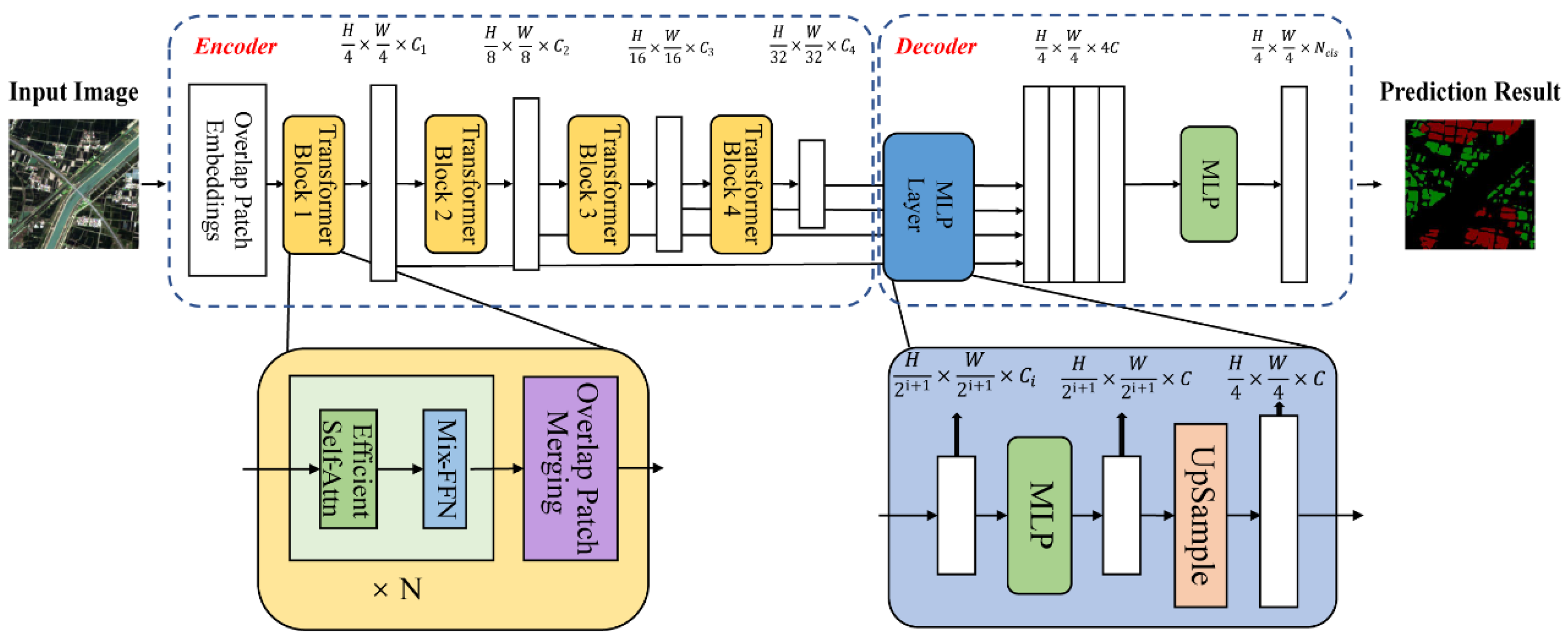
2.3.4. Segformer
2.3.5. RF
2.4. Experimental Setup
2.5. Evaluation Metrics
3. Results
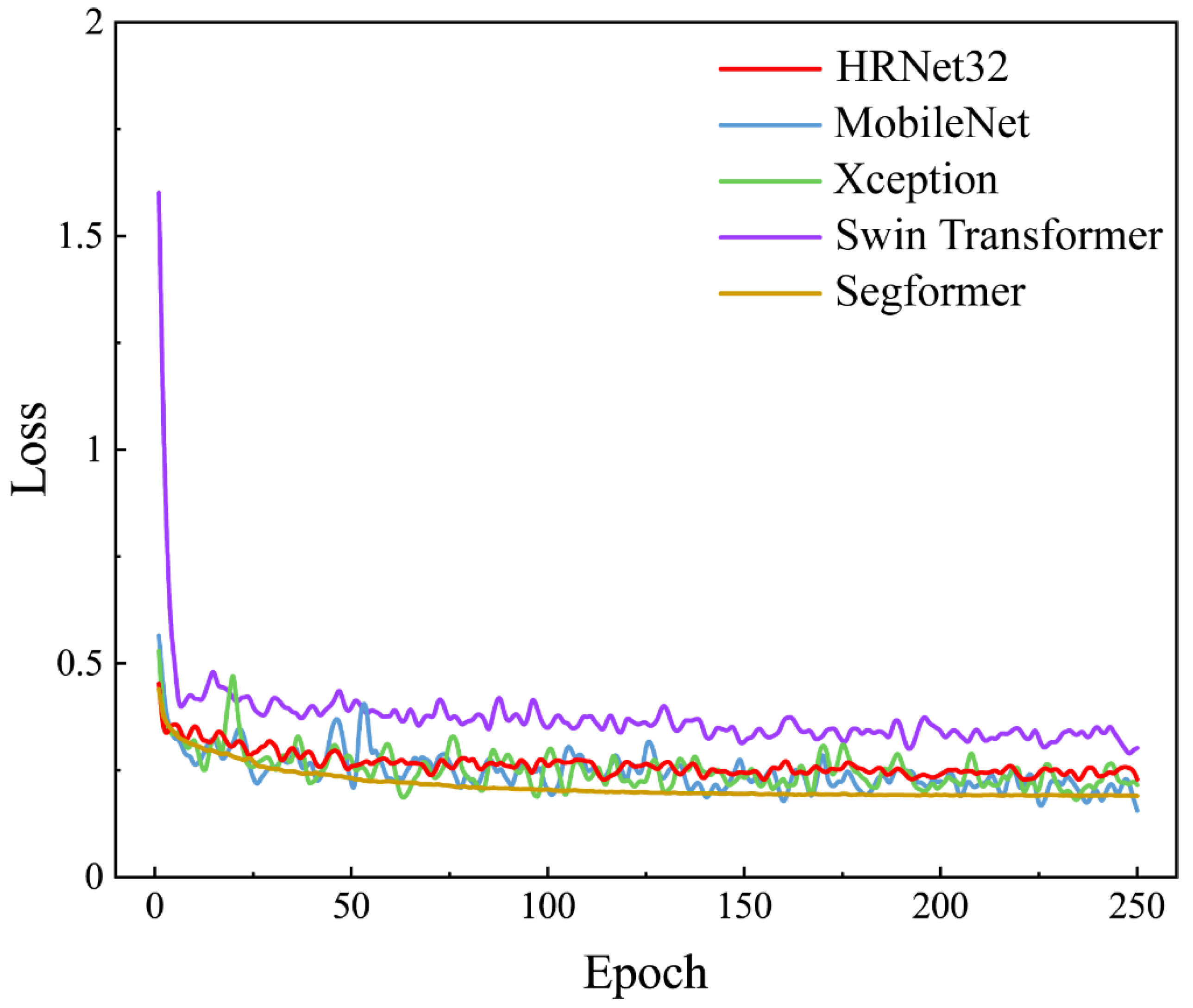
3.1. Overall Performances Assessment
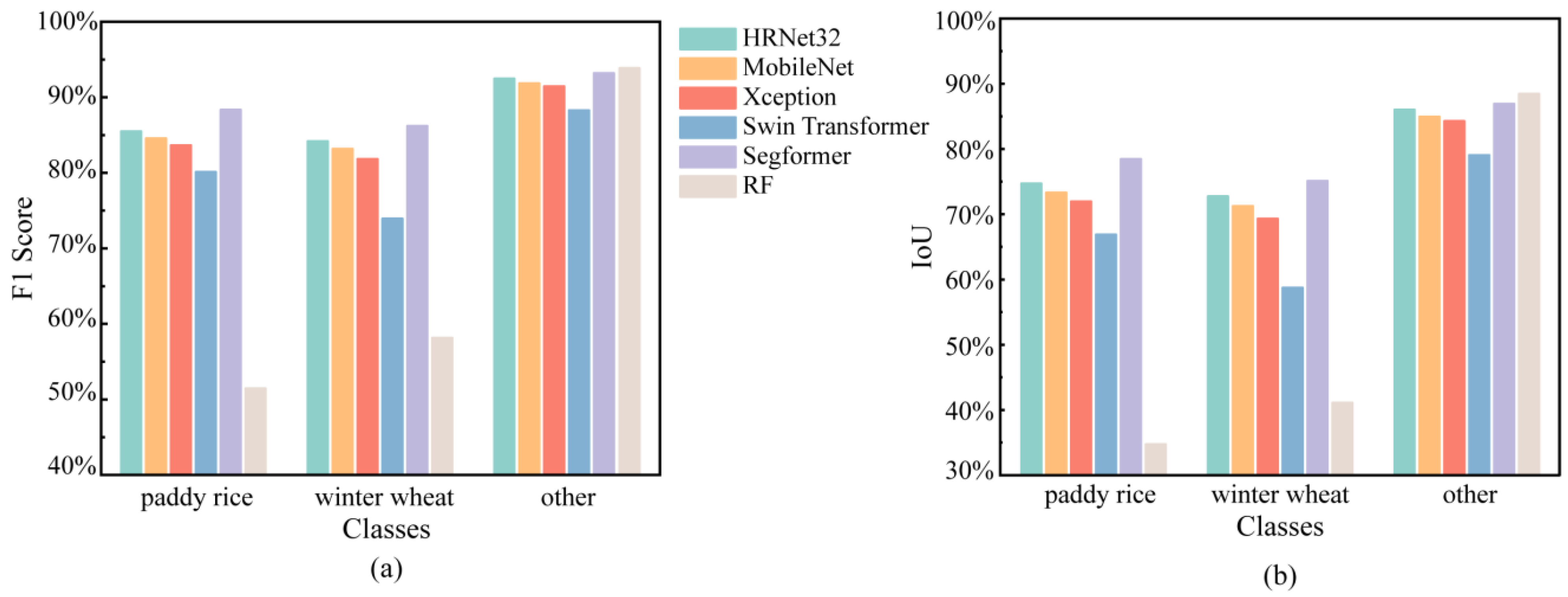
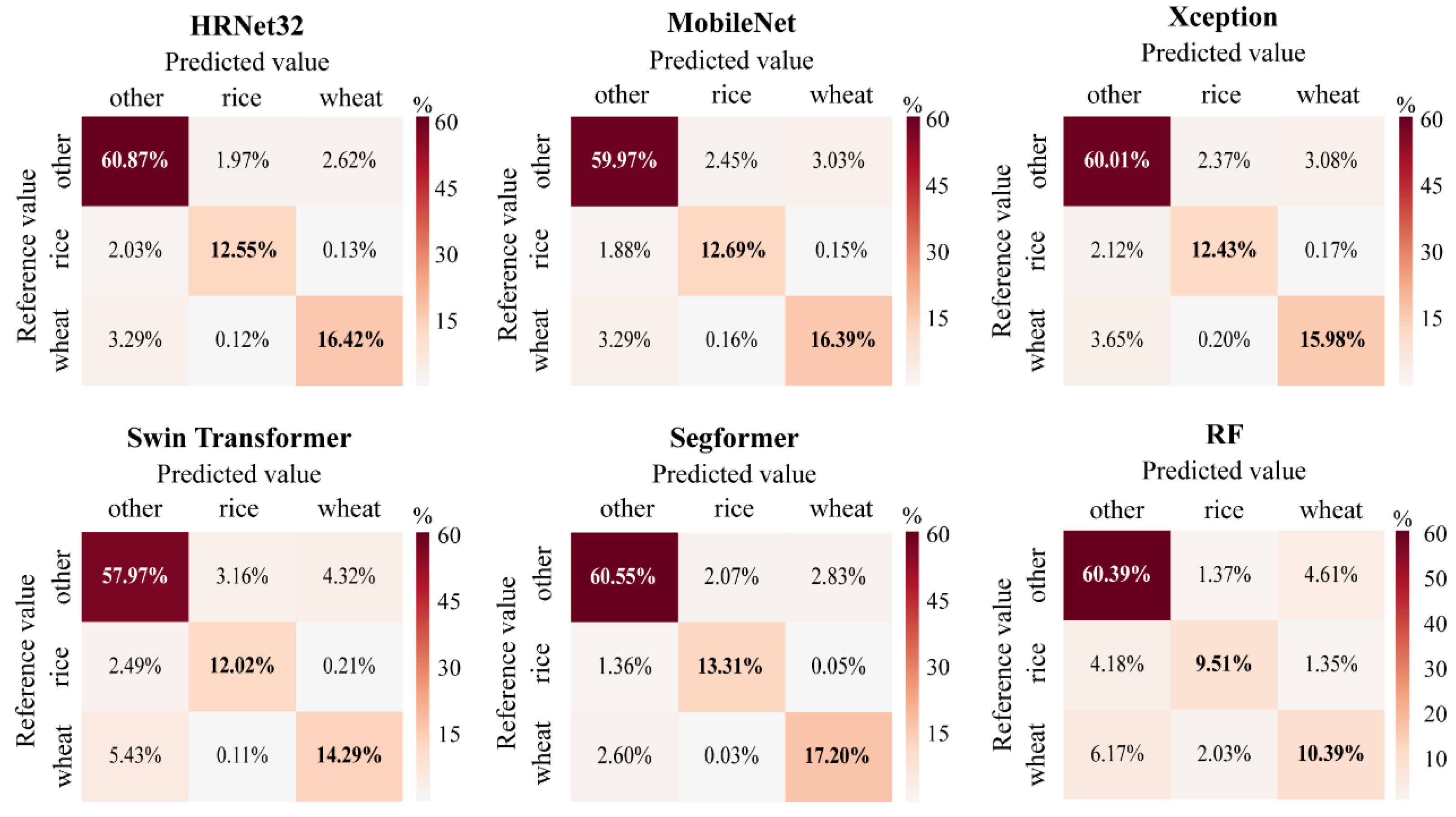
3.2. Paddy Rice and Winter Wheat Classification
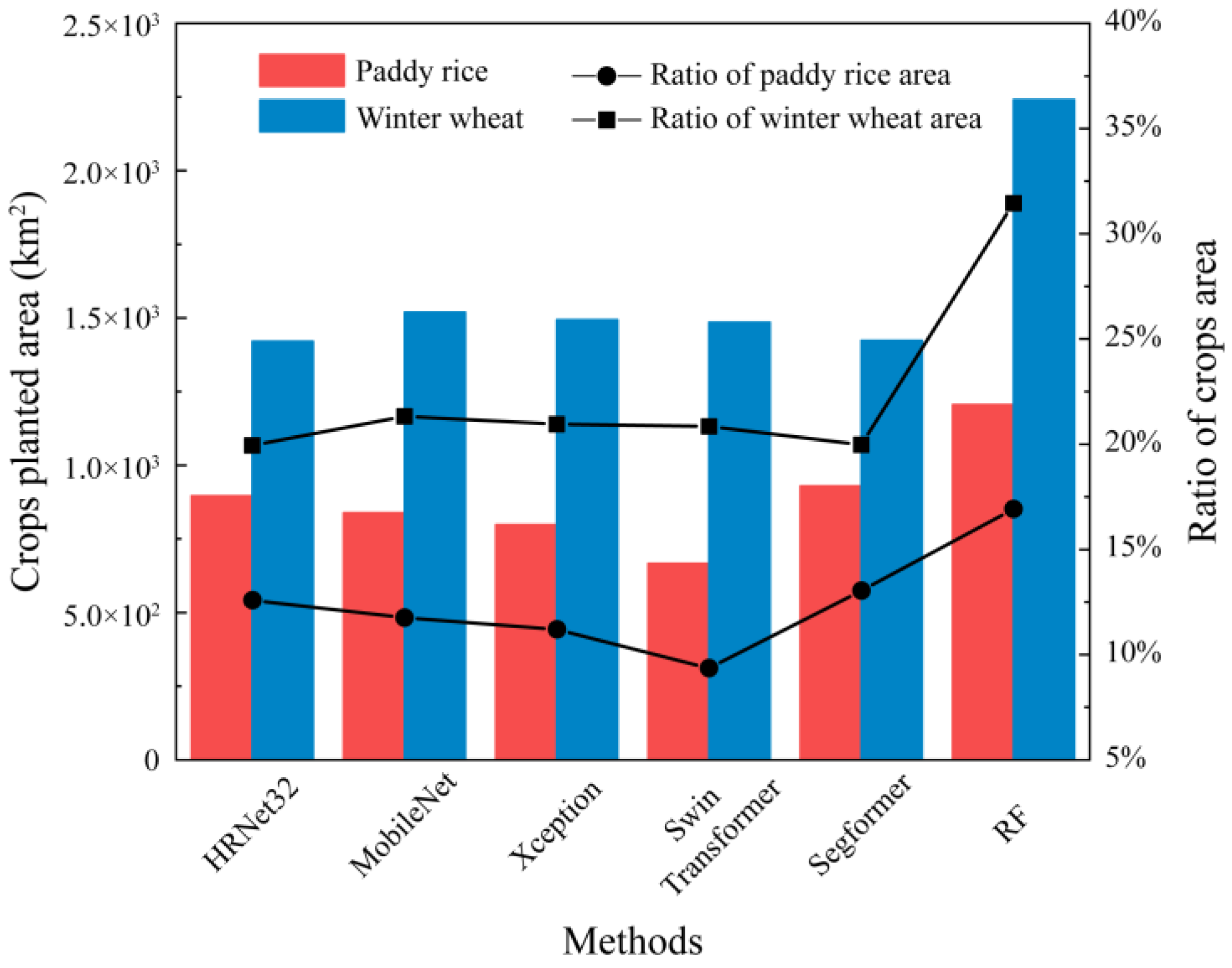
3.3. Planting Area Statistics
4. Discussion
5. Conclusions
- (1)
- High-resolution RS combined with DL methods are highly feasible for identifying and mapping a wide range of crops, significantly reducing the human and material costs of traditional field surveys, and compensating for the lack of quality of statistical data, which is of great importance for accurate knowledge of the crop range and food security.
- (2)
- The extensive experimental results show that the DL approach benefits from its powerful image-level information enhancement and multi-scale semantic feature capture; the results are far superior to traditional ML methods. In particular, the Segformer, based on the Transformers structural encoder and the lightweight MLP decoder structure, achieved an OA value of 91.06%, an mF1 value of 89.26% and a mIoU value of 80.70%, which is the best-performing network for paddy rice and winter wheat classification.
- (3)
- DL methods generally take longer to train than ML methods due to their complex network structure and many model parameters. The training time for the MobileNet model is only 8 h, which is the fastest convergence speed among the DL methods; it also achieves quite a good classification accuracy with high practical value. The RF method is an excellent classification method due to its short training time, low training data requirement and strong model generalization, although the final model performance is unsatisfactory.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, X.W.; Liu, J.F.; Qin, Z.Y.; Qin, F. Winter wheat identification by integrating spectral and temporal information derived from multi-resolution remote sensing data. J. Integr. Agric. 2019, 18, 2628–2643. [Google Scholar] [CrossRef]
- Wang, Y.M.; Zhang, Z.; Feng, L.W.; Du, Q.Y.; Runge, T. Combining Multi-Source Data and Machine Learning Approaches to Predict Winter Wheat Yield in the Conterminous United States. Remote Sens. 2020, 12, 1232. [Google Scholar] [CrossRef] [Green Version]
- Ni, R.G.; Tian, J.Y.; Li, X.J.; Yin, D.M.; Li, J.W.; Gong, H.L.; Zhang, J.; Zhu, L.; Wu, D.L. An enhanced pixel-based phenological feature for accurate paddy rice mapping with Sentinel-2 imagery in Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2021, 178, 282–296. [Google Scholar] [CrossRef]
- Li, S.L.; Li, F.J.; Gao, M.F.; Li, Z.L.; Leng, P.; Duan, S.B.; Ren, J.Q. A New Method for Winter Wheat Mapping Based on Spectral Reconstruction Technology. Remote Sens. 2021, 13, 1810. [Google Scholar] [CrossRef]
- Huang, Q.; Wu, W.; Zhang, L.; Li, D. MODIS-NDVI-based crop growth monitoring in China agriculture remote sensing monitoring system. In Proceedings of the 2010 Second IITA International Conference on Geoscience and Remote Sensing, Qingdao, China, 28–31 August 2010; pp. 287–290. [Google Scholar]
- He, S.; Peng, P.; Chen, Y.Y.; Wang, X.M. Multi-Crop Classification Using Feature Selection-Coupled Machine Learning Classifiers Based on Spectral, Textural and Environmental Features. Remote Sens. 2022, 14, 3153. [Google Scholar] [CrossRef]
- Liu, J.H.; Zhu, W.Q.; Atzberger, C.; Zhao, A.Z.; Pan, Y.Z.; Huang, X. A Phenology-Based Method to Map Cropping Patterns under a Wheat-Maize Rotation Using Remotely Sensed Time-Series Data. Remote Sens. 2018, 10, 1203. [Google Scholar] [CrossRef] [Green Version]
- Khan, A.; Hansen, M.C.; Potapov, P.V.; Adusei, B.; Pickens, A.; Krylov, A.; Stehman, S.V. Evaluating Landsat and RapidEye Data for Winter Wheat Mapping and Area Estimation in Punjab, Pakistan. Remote Sens. 2018, 10, 489. [Google Scholar] [CrossRef] [Green Version]
- Jiang, M.; Xin, L.J.; Li, X.B.; Tan, M.H.; Wang, R.J. Decreasing Rice Cropping Intensity in Southern China from 1990 to 2015. Remote Sens. 2019, 11, 35. [Google Scholar] [CrossRef] [Green Version]
- Dong, Q.; Chen, X.H.; Chen, J.; Zhang, C.S.; Liu, L.C.; Cao, X.; Zang, Y.Z.; Zhu, X.F.; Cui, X.H. Mapping Winter Wheat in North China Using Sentinel 2A/B Data: A Method Based on Phenology-Time Weighted Dynamic Time Warping. Remote Sens. 2020, 12, 1274. [Google Scholar] [CrossRef] [Green Version]
- Han, J.C.; Zhang, Z.; Luo, Y.C.A.; Cao, J.; Zhang, L.L.; Cheng, F.; Zhuang, H.M.; Zhang, J.; Tao, F.L. NESEA-Rice10: High-resolution annual paddy rice maps for Northeast and Southeast Asia from 2017 to 2019. Earth Syst. Sci. Data 2021, 13, 5969–5986. [Google Scholar] [CrossRef]
- Chen, Y.; Yu, P.; Chen, Y.; Chen, Z. Spatiotemporal dynamics of rice–crayfish field in Mid-China and its socioeconomic benefits on rural revitalisation. Appl. Geogr. 2022, 139, 102636. [Google Scholar] [CrossRef]
- Frolking, S.; Qiu, J.; Boles, S.; Xiao, X.; Liu, J.; Zhuang, Y.; Li, C.; Qin, X. Combining remote sensing and ground census data to develop new maps of the distribution of rice agriculture in China. Glob. Biogeochem. Cycles 2002, 16, 38-1–38-10. [Google Scholar] [CrossRef] [Green Version]
- Cheng, H.; Ren, W.; Ding, L.; Liu, Z.; Fang, C. Responses of a rice–wheat rotation agroecosystem to experimental warming. Ecol. Res. 2013, 28, 959–967. [Google Scholar] [CrossRef]
- Khatami, R.; Mountrakis, G.; Stehman, S.V. A meta-analysis of remote sensing research on supervised pixel-based land-cover image classification processes: General guidelines for practitioners and future research. Remote Sens. Environ. 2016, 177, 89–100. [Google Scholar] [CrossRef] [Green Version]
- King, L.; Adusei, B.; Stehman, S.V.; Potapov, P.V.; Song, X.-P.; Krylov, A.; Di Bella, C.; Loveland, T.R.; Johnson, D.M.; Hansen, M.C. A multi-resolution approach to national-scale cultivated area estimation of soybean. Remote Sens. Environ. 2017, 195, 13–29. [Google Scholar] [CrossRef]
- Löw, F.; Michel, U.; Dech, S.; Conrad, C. Impact of feature selection on the accuracy and spatial uncertainty of per-field crop classification using support vector machines. ISPRS J. Photogramm. Remote Sens. 2013, 85, 102–119. [Google Scholar] [CrossRef]
- Massey, R.; Sankey, T.T.; Congalton, R.G.; Yadav, K.; Thenkabail, P.S.; Ozdogan, M.; Meador, A.J.S. MODIS phenology-derived, multi-year distribution of conterminous US crop types. Remote Sens. Environ. 2017, 198, 490–503. [Google Scholar] [CrossRef]
- Shi, D.; Yang, X. An assessment of algorithmic parameters affecting image classification accuracy by random forests. Photogramm. Eng. Remote Sens. 2016, 82, 407–417. [Google Scholar] [CrossRef]
- Xu, J.; Zhu, Y.; Zhong, R.; Lin, Z.; Xu, J.; Jiang, H.; Huang, J.; Li, H.; Lin, T. DeepCropMapping: A multi-temporal deep learning approach with improved spatial generalizability for dynamic corn and soybean mapping. Remote Sens. Environ. 2020, 247, 111946. [Google Scholar] [CrossRef]
- Azzari, G.; Lobell, D.B. Landsat-based classification in the cloud: An opportunity for a paradigm shift in land cover monitoring. Remote Sens. Environ. 2017, 202, 64–74. [Google Scholar] [CrossRef]
- Saini, R.; Ghosh, S.K. Crop classification in a heterogeneous agricultural environment using ensemble classifiers and single-date Sentinel-2A imagery. Geocarto Int. 2021, 36, 2141–2159. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Prins, A.J.; Van Niekerk, A. Crop type mapping using LiDAR, Sentinel-2 and aerial imagery with machine learning algorithms. Geo-Spat. Inf. Sci. 2021, 24, 215–227. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification. IEEE T Geosci. Remote 2017, 55, 645–657. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Liu, Z.; Ren, T.W.; Liu, D.Y.; Ma, Z.; Tong, L.; Zhang, C.; Zhou, T.Y.; Zhang, X.D.; Li, S.M. Identification of Seed Maize Fields with High Spatial Resolution and Multiple Spectral Remote Sensing Using Random Forest Classifier. Remote Sens. 2020, 12, 362. [Google Scholar] [CrossRef] [Green Version]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep Learning Classification of Land Cover and Crop Types Using Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Marcos, D.; Volpi, M.; Kellenberger, B.; Tuia, D. Land cover mapping at very high resolution with rotation equivariant CNNs: Towards small yet accurate models. ISPRS J. Photogramm. Remote Sens. 2018, 145, 96–107. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Dong, Z.; Wang, G.J.; Amankwah, S.O.Y.; Wei, X.K.; Hu, Y.F.; Feng, A.Q. Monitoring the summer flooding in the Poyang Lake area of China in 2020 based on Sentinel-1 data and multiple convolutional neural networks. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102400. [Google Scholar] [CrossRef]
- Fourure, D.; Emonet, R.; Fromont, E.; Muselet, D.; Tremeau, A.; Wolf, C. Residual conv-deconv grid network for semantic segmentation. arXiv 2017, arXiv:1707.07958. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, J.H.; Xun, L.; Wang, J.W.; Wu, Z.J.; Henchiri, M.; Zhang, S.C.; Zhang, S.; Bai, Y.; Yang, S.S.; et al. Evaluating the Effectiveness of Machine Learning and Deep Learning Models Combined Time-Series Satellite Data for Multiple Crop Types Classification over a Large-Scale Region. Remote Sens. 2022, 14, 2341. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Zuo, Q.; Chen, Y.; Tao, J. Climate change and its impact on water resources in the Huai River Basin. Bull. Chin. Acad. Sci. 2012, 26, 32–39. [Google Scholar]
- Xu, D.; Fu, M.C. Detection and Modeling of Vegetation Phenology Spatiotemporal Characteristics in the Middle Part of the Huai River Region in China. Sustainability 2015, 7, 2841–2857. [Google Scholar] [CrossRef] [Green Version]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef] [Green Version]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Papandreou, G.; Kokkinos, I.; Savalle, P.-A. Modeling local and global deformations in deep learning: Epitomic convolution, multiple instance learning, and sliding window detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 390–399. [Google Scholar]
- Holschneider, M.; Kronland-Martinet, R.; Morlet, J.; Tchamitchian, P. A real-time algorithm for signal analysis with the help of the wavelet transform. In Proceedings of the Wavelets: Time-Frequency Methods and Phase Space Proceedings of the International Conference; Marseille, France, 14–18 December 1987, 1990; pp. 286–297. [Google Scholar]
- Giusti, A.; Cireşan, D.C.; Masci, J.; Gambardella, L.M.; Schmidhuber, J. Fast image scanning with deep max-pooling convolutional neural networks. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 4034–4038. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Bai, H.; Mao, H.; Nair, D. Dynamically pruning segformer for efficient semantic segmentation. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 3298–3302. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. Icnet for real-time semantic segmentation on high-resolution images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 405–420. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Belgiu, M.; Dragut, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Du, P.J.; Samat, A.; Waske, B.; Liu, S.C.; Li, Z.H. Random Forest and Rotation Forest for fully polarized SAR image classification using polarimetric and spatial features. ISPRS J. Photogramm. Remote Sens. 2015, 105, 38–53. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Wang, G.; Wu, M.; Wei, X.; Song, H. Water identification from high-resolution remote sensing images based on multidimensional densely connected convolutional neural networks. Remote Sens. 2020, 12, 795. [Google Scholar] [CrossRef] [Green Version]
- Elert, E. Rice by the numbers: A good grain. Nature 2014, 514, S50. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dang, B.; Li, Y.S. MSResNet: Multiscale Residual Network via Self-Supervised Learning for Water-Body Detection in Remote Sensing Imagery. Remote Sens. 2021, 13, 3122. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y. Segment anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-scnn: Gated shape cnns for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5229–5238. [Google Scholar]
- Li, X.; Zhao, H.; Han, L.; Tong, Y.; Tan, S.; Yang, K. Gated fully fusion for semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11418–11425. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| OA | mP | mR | mF1 | RIoU | WIoU | OIoU | mIoU | Time | |
|---|---|---|---|---|---|---|---|---|---|
| HRNet32 | 89.84% | 87.02% | 87.77% | 87.40% | 74.67% | 72.71% | 86.00% | 77.79% | 351,201 s |
| MobileNet | 89.05% | 86.83% | 86.26% | 86.55% | 73.27% | 71.21% | 84.92% | 76.47% | 28,815 s |
| Xception | 88.42% | 85.57% | 85.74% | 85.66% | 71.91% | 69.25% | 84.25% | 75.14% | 119,003 s |
| STSF | 84.29% | 80.78% | 80.84% | 80.81% | 66.83% | 58.66% | 79.02% | 68.17% | 611,899 s |
| Segformer | 91.06% | 88.62% | 89.90% | 89.26% | 79.13% | 75.74% | 87.24% | 80.70% | 159,933 s |
| RF | 87.65% | 65.28% | 71.40% | 67.83% | 34.64% | 41.01% | 88.43% | 54.69% | ____ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, W.; Feng, A.; Wang, G.; Zhang, Q.; Dai, W.; Wei, X.; Hu, Y.; Amankwah, S.O.Y.; Zhou, F.; Liu, Y. Bi-Objective Crop Mapping from Sentinel-2 Images Based on Multiple Deep Learning Networks. Remote Sens. 2023, 15, 3417. https://doi.org/10.3390/rs15133417
Song W, Feng A, Wang G, Zhang Q, Dai W, Wei X, Hu Y, Amankwah SOY, Zhou F, Liu Y. Bi-Objective Crop Mapping from Sentinel-2 Images Based on Multiple Deep Learning Networks. Remote Sensing. 2023; 15(13):3417. https://doi.org/10.3390/rs15133417
Chicago/Turabian StyleSong, Weicheng, Aiqing Feng, Guojie Wang, Qixia Zhang, Wen Dai, Xikun Wei, Yifan Hu, Solomon Obiri Yeboah Amankwah, Feihong Zhou, and Yi Liu. 2023. "Bi-Objective Crop Mapping from Sentinel-2 Images Based on Multiple Deep Learning Networks" Remote Sensing 15, no. 13: 3417. https://doi.org/10.3390/rs15133417
APA StyleSong, W., Feng, A., Wang, G., Zhang, Q., Dai, W., Wei, X., Hu, Y., Amankwah, S. O. Y., Zhou, F., & Liu, Y. (2023). Bi-Objective Crop Mapping from Sentinel-2 Images Based on Multiple Deep Learning Networks. Remote Sensing, 15(13), 3417. https://doi.org/10.3390/rs15133417