1. Introduction
Ship classification plays an important role in various maritime activities, such as defense intelligence, fisheries monitoring, and maritime search [
1]. SAR, due to its characteristics of all-day and all-weather working, has gradually become a critical device for ship monitoring. With the launch of the new generation of SAR satellites, a large number of mid- and high-resolution SAR images have gradually become easier to access, making it possible to identify ship types.
Generally, traditional SAR ship classification methods usually extract low-level features, such as geometric features [
2,
3,
4,
5], scattering features [
2,
3,
4,
6,
7], and statistical features [
8] by manual methods, then classify ships using traditional machine learning algorithms. For example, Margarit et al. [
2] proposed a fuzzy logic model by utilizing the mean radar cross-section (RCS) features and geometric features. Ji et al. [
3] proposed a classifier combination model using geometric features and the local RCS features. Lang et al. [
4] designed a model that can jointly select features and classifiers by searching the best triplet of the feature scaling classifier from 21 candidate low-level features and 5 candidate classifiers. Jiang et al. [
6] proposed an SVM model using the superstructure scattering features. Lang et al. [
5] proposed a multiple kernel learning model using the naive geometric features derived from the length and width of ships. Zhu et al. [
7] proposed a template matching model using the improved shape contexts features that simultaneously consider the topology and intensity of ship scattering points. Lin et al. [
8] designed a task-driven dictionary learning model by integrating structured incoherent constraints using the manifold learning SAR-HOG feature. In brief, these handcrafted features can barely represent ship targets comprehensively, and are limited in some complex scenarios, especially in mid-resolution SAR images [
9].
Recently, DL-based SAR ship classification methods have drawn increasing attention and become a research hotspot. For example, ref [
10] proposed a polarization fusion network with geometric feature embedding to fuse the polarization from input data, the feature level, and the decision level. Li et al. [
11] designed a dense residual network with resampling, and integrated cost-sensitive learning for the class imbalance problem in ship classification. Dechesne et al. [
12] designed a multi-task structure to simultaneously implement the detection and classification as well as length estimation tasks. Firoozy et al. [
13] utilized adversarial training to generate samples for the minority classes to balance the training dataset. Zhang et al. [
14] designed a meta-learning approach to achieve cross-task and cross-domain SAR target classification. He et al. [
9] proposed a densely connected triplet CNN with a Fisher regularization term for the mid-resolution SAR image ship classification task. Zhao et al. [
15] proposed the learning of discriminant features for SAR image classification by designing a deep belief network with ensemble learning. Zeng et al. [
16] proposed to jointly use the information contained in the polarized channels (VV and VH) by designing a hybrid channel feature loss for dual-polarized SAR ship-grained classification. Zhang et al. [
17] designed a lightweight CNNs classification model combining DML with gradually balanced sampling to decrease the computational complexity and address the class imbalance in high-resolution SAR images. Dong et al. [
18] proposed a hierarchical receptive network to eliminate the influence of speckles for ship recognition in SAR images. In brief, DL-based methods can extract high-level features directly from large-scale data and perform end-to-end training, showing great potential for practical applications.
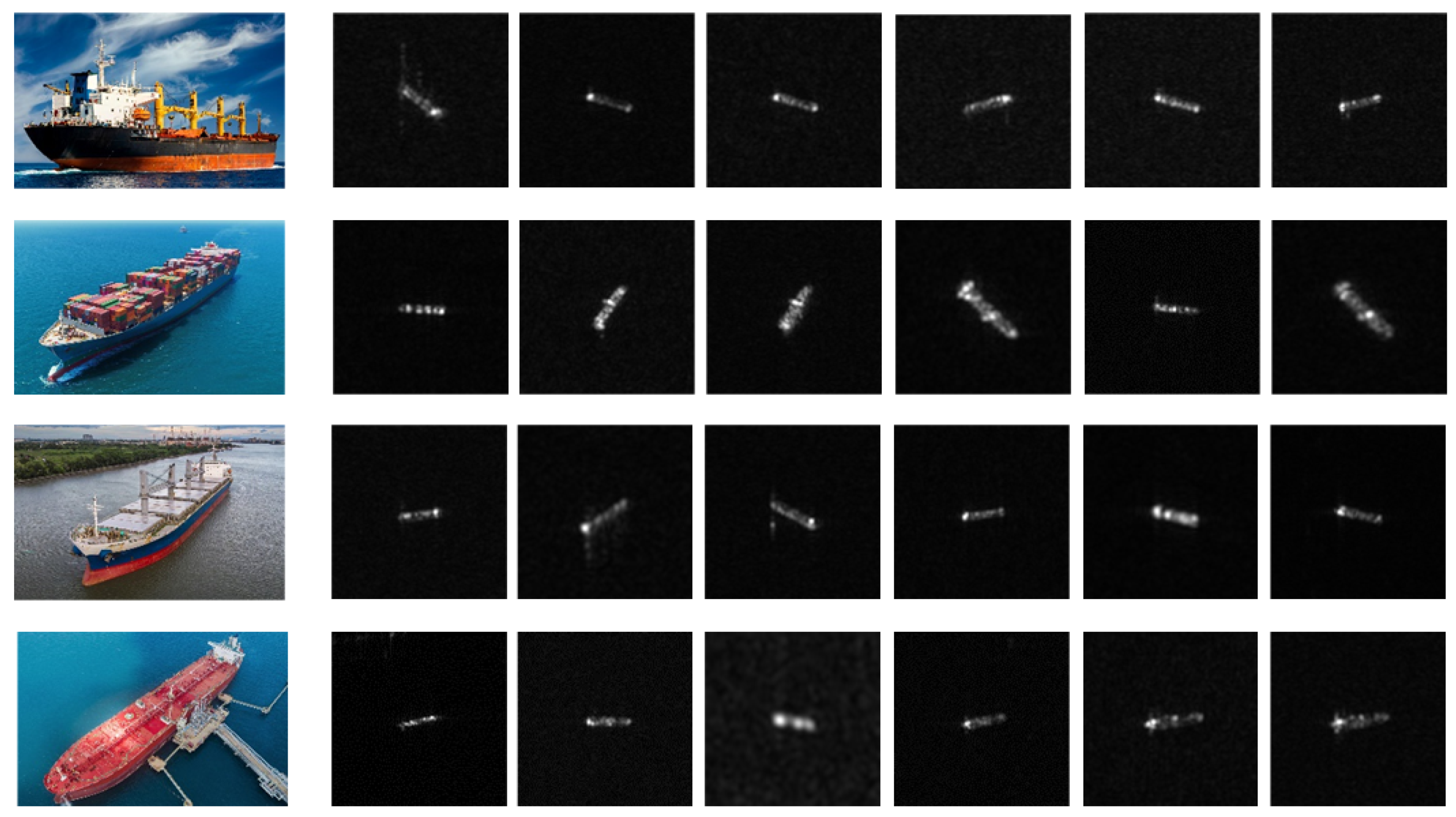
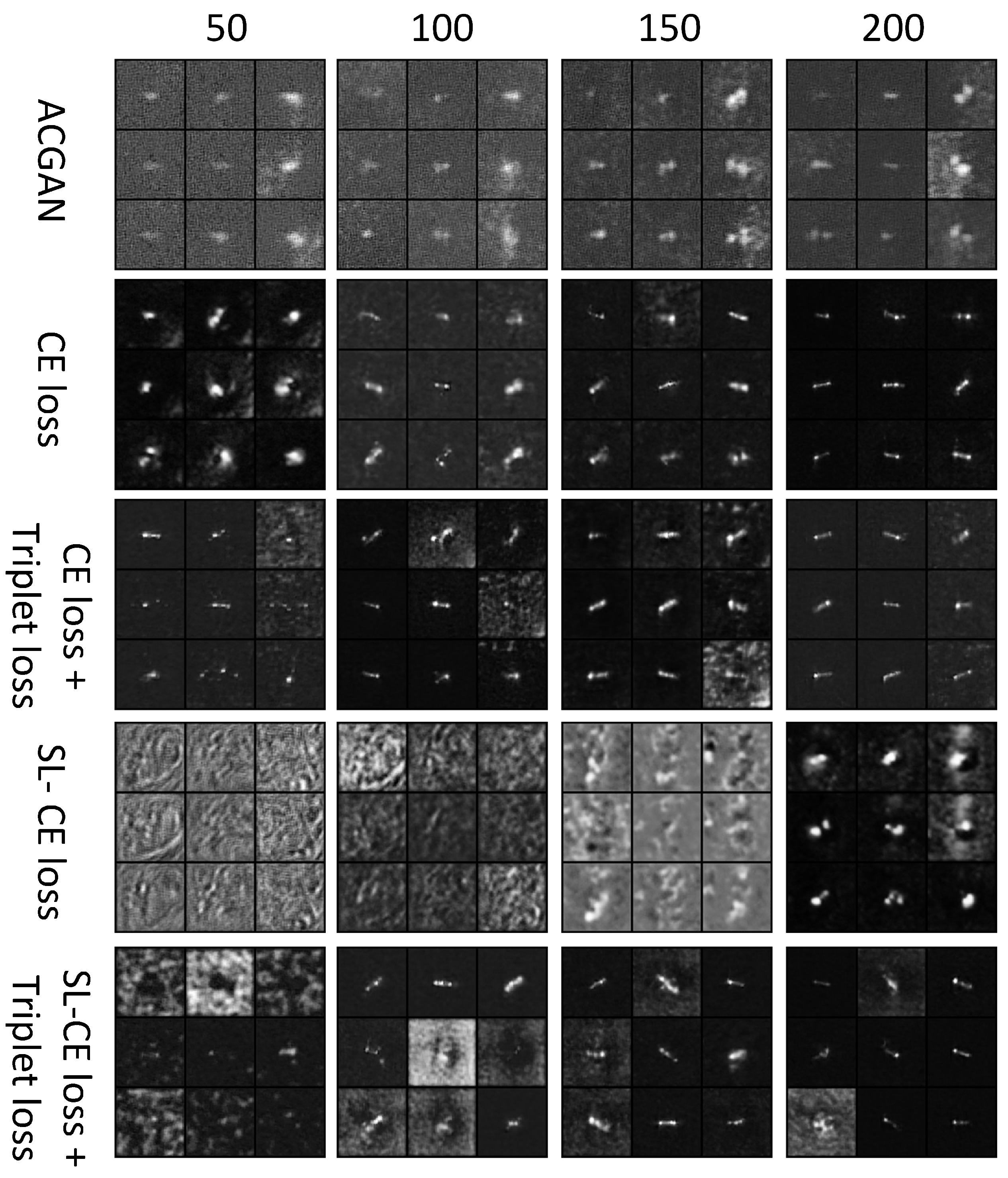
These previous methods have obtained remarkable performance for SAR ship classification tasks by training models with large-scale datasets. However, despite the great quantity of SAR images, the volume of available SAR ship classification data is relatively small, especially for some maritime military targets such as destroyers and aircraft carriers, while the manual labeling cost is expensive. DL-based models trained on small-scale datasets usually suffer from the overfitting problem, thus reducing the generalization ability. Furthermore, different from optical images, the information on SAR images is limited because of the shortcoming of the SAR imaging mechanism. Some examples are shown in
Figure 1 where we can see that the appearance of different types of ships has subtle differences, while the appearance of the same type of ship has distinct changes. This problem is called intraclass diversity and interclass similarity, and further degrades the classification performance.
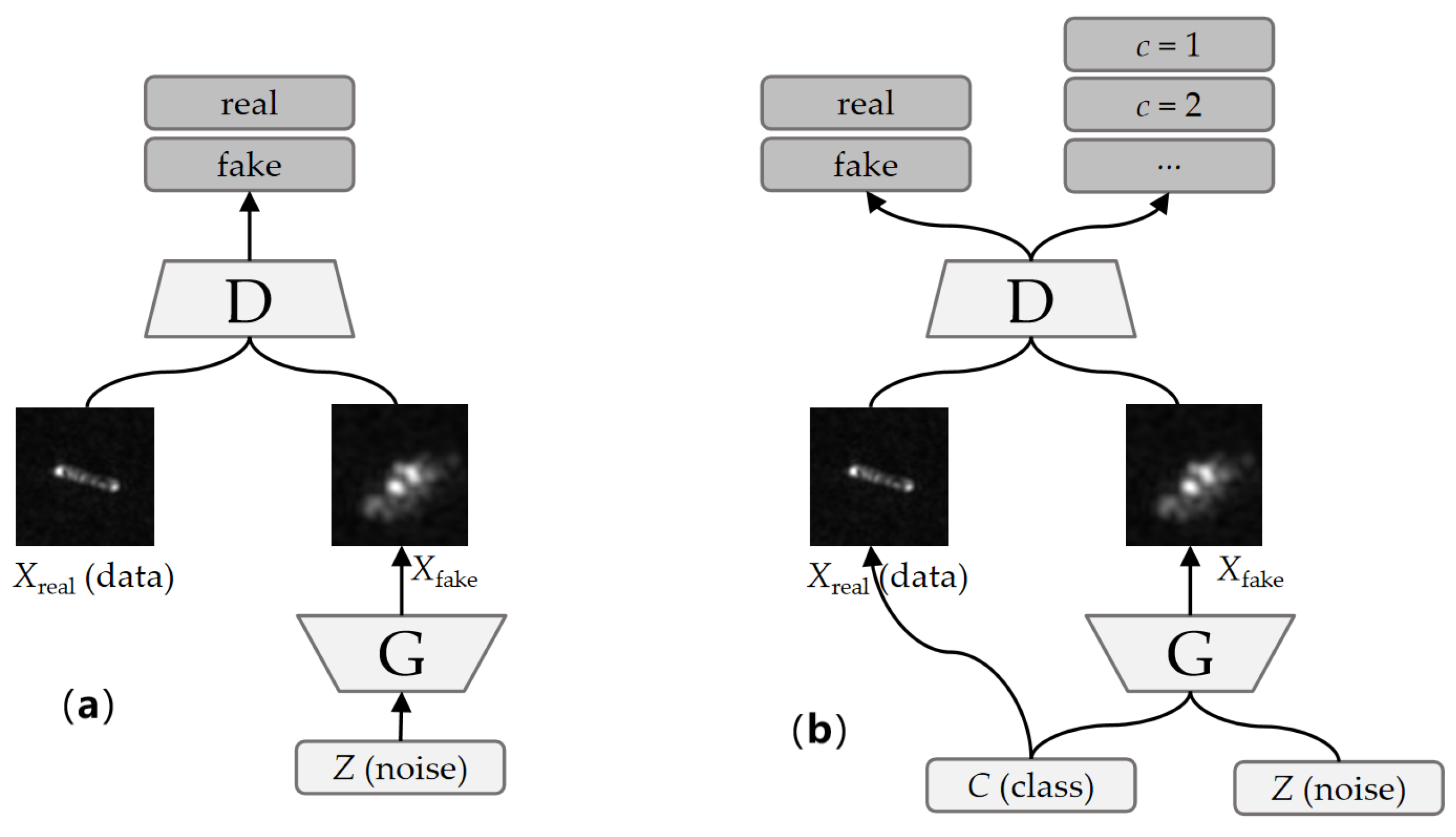
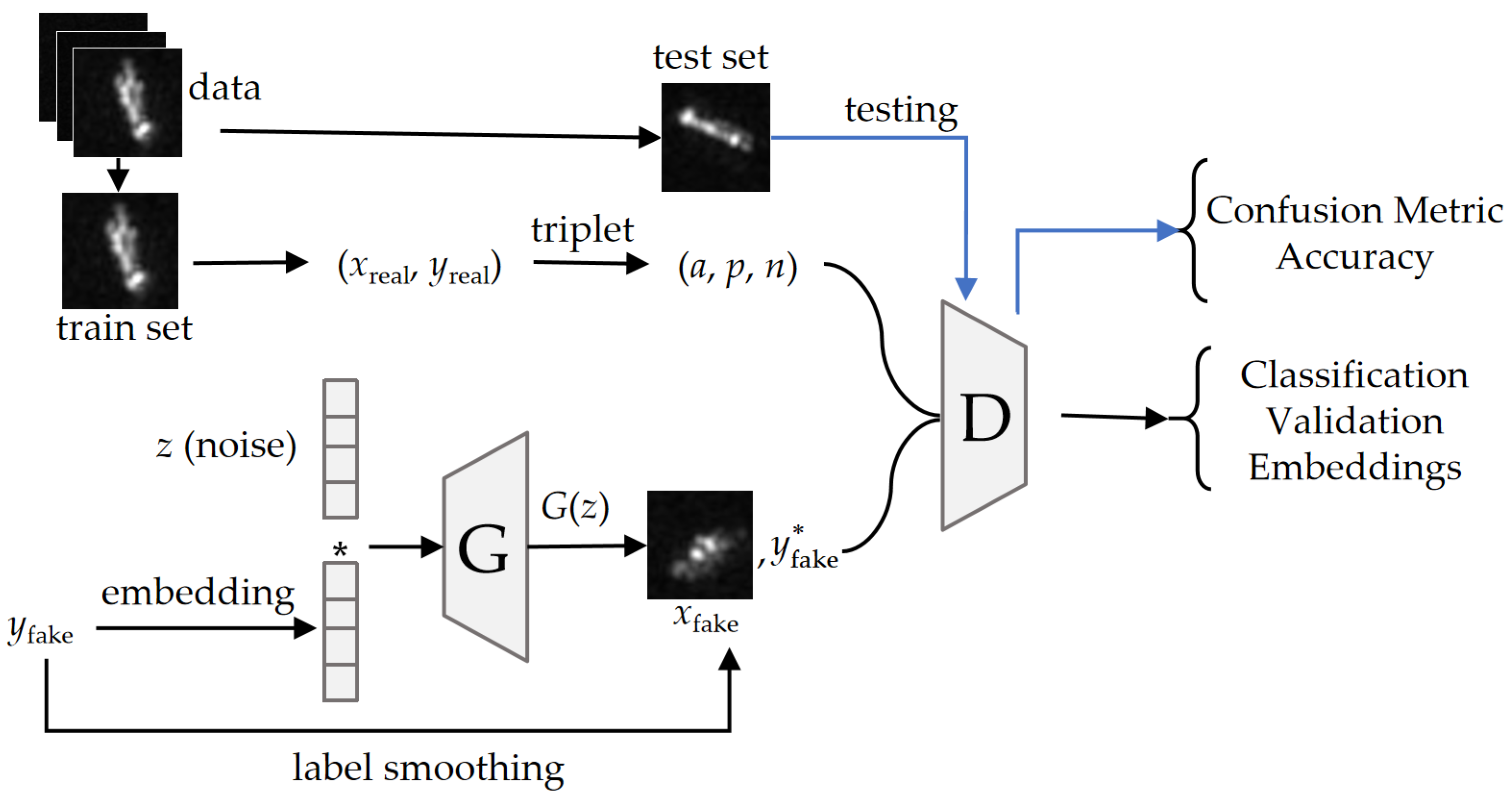
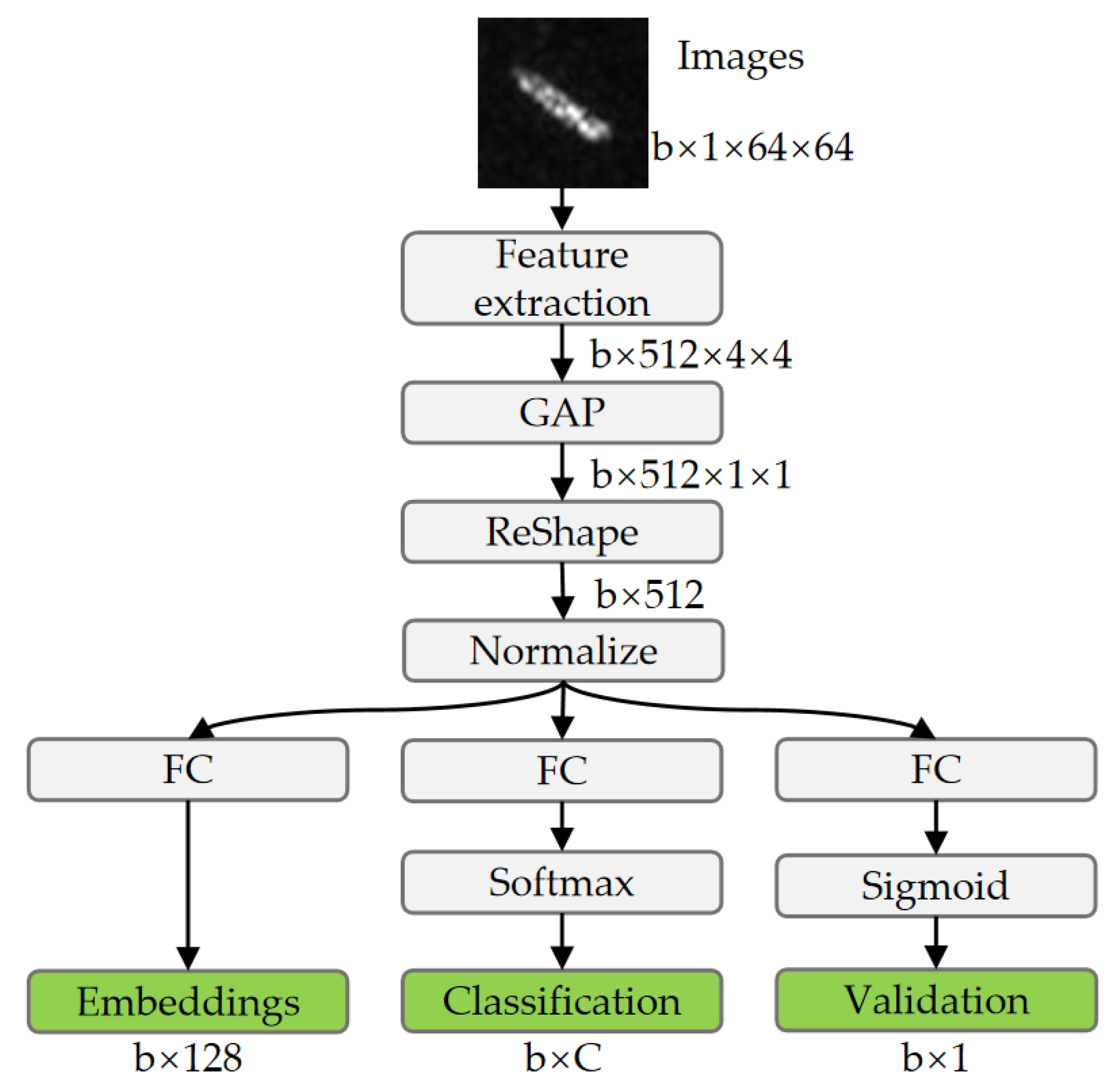
To address these problems, this article proposes an LST-ACGAN for SAR ship classification by introducing an ACGAN [
19] to generate new samples, assigning smooth labels [
20] to generated samples, and integrating the triplet loss [
21] into the ACGAN. An ACGAN is one of the GAN’s variants [
19,
22,
23]. By adding category information to the generator and an auxiliary classifier to the discriminator, the ACGAN can generate samples with category labels and also has classification capacity. Due to the excellent characteristics of the ACGAN, this article introduces its architecture to alleviate the data insufficiency problem by generating ship samples with category labels while classifying ships. However, the training of an ACGAN typically requires plenty of data to learn the distribution of real images. Otherwise, it is hard to generate samples with precise categories and prone to model collapse during training. To address this problem, this article assigns smooth labels to generated samples rather than hard labels to prevent the model from being overconfident in generated images during training, and the CE loss is replaced with smooth label SL-CE loss for the classification of generated images. By assigning smooth labels, the training procedure is made more stable, and generated samples can also play the role of regularization.
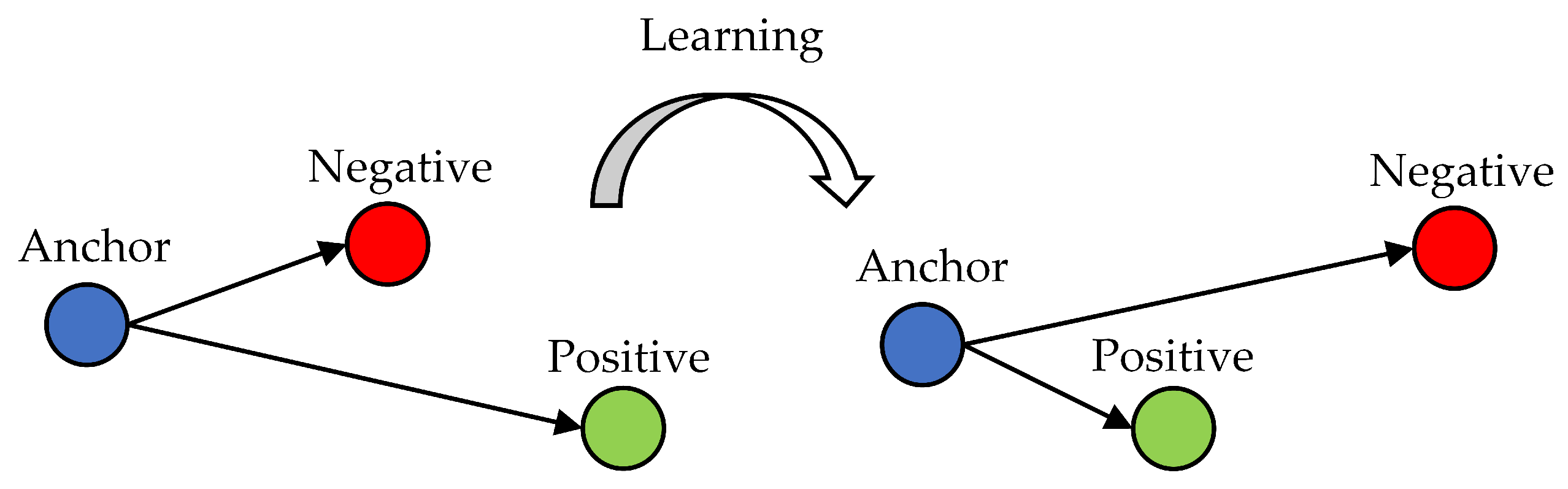
Furthermore, in the SAR image dataset, targets belonging to the same class usually have high intraclass diversity, while targets belonging to different classes usually have high interclass similarity. To address this problem, triplet loss [
21] is integrated into the ACGAN. Different from traditional CNNs with CE loss, the triplet loss can enhance the classification margin by pulling the intraclass samples closer and pushing the interclass samples farther in the embedding space. During training, triplets are built by sampling anchor images, positive images that belong to the same classes, and negative images that belong to other classes, and then the triplet loss is jointly optimized with the multi-task loss. By integrating these modules, the proposed method can learn better classification margins and obtain higher performance.
Our contribution can be summarized as follows:
- (1)
An ACGAN is introduced to generate images for the small-scale SAR ship classification task to alleviate the overfitting problem. To prevent the model from mode collapse, smooth labels are assigned to generated images to avoid the model being overconfident in the generated images.
- (2)
Triplet loss is integrated into the ACGAN to learn discriminative features by pulling the intraclass samples closer and pushing the interclass samples farther.
- (3)
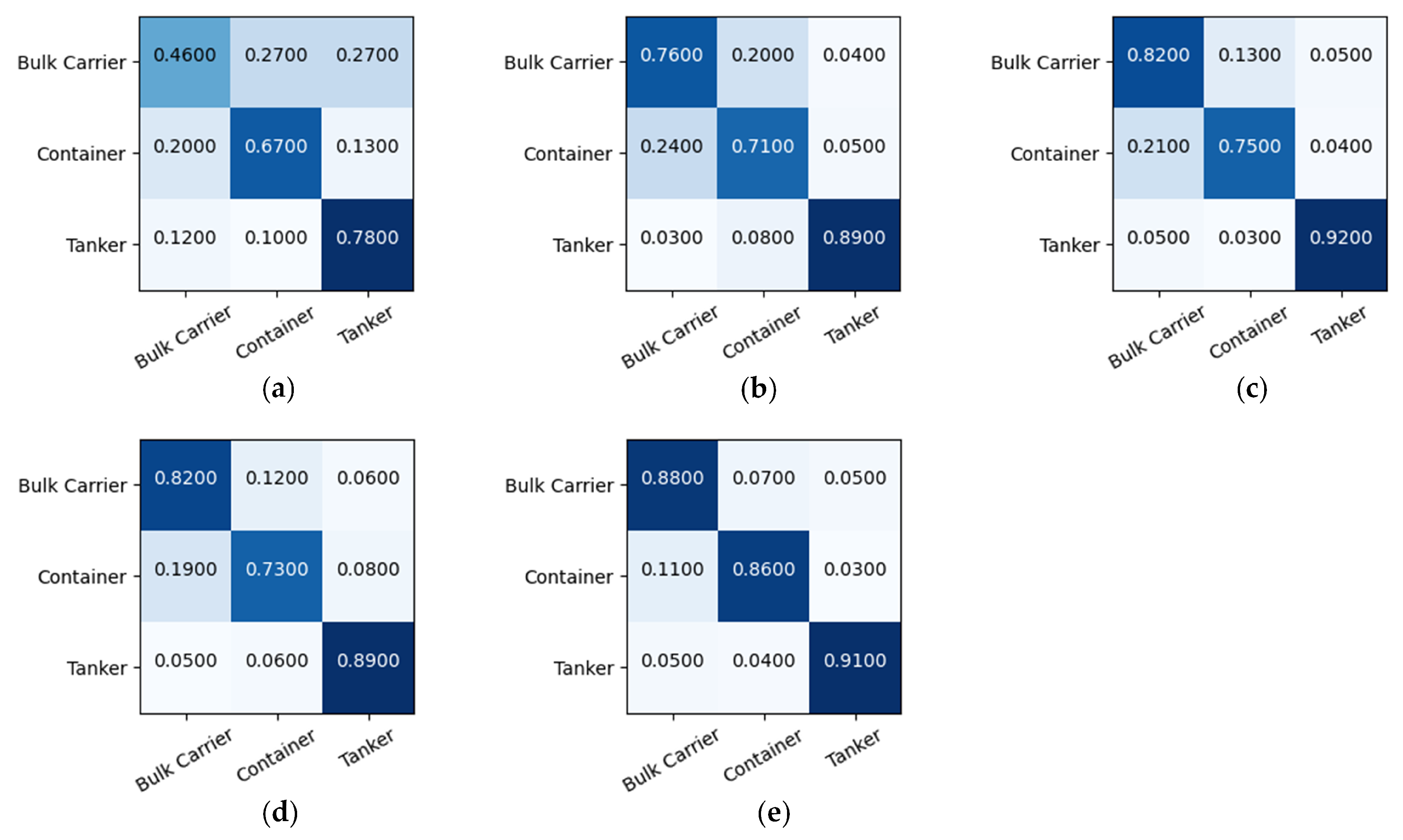
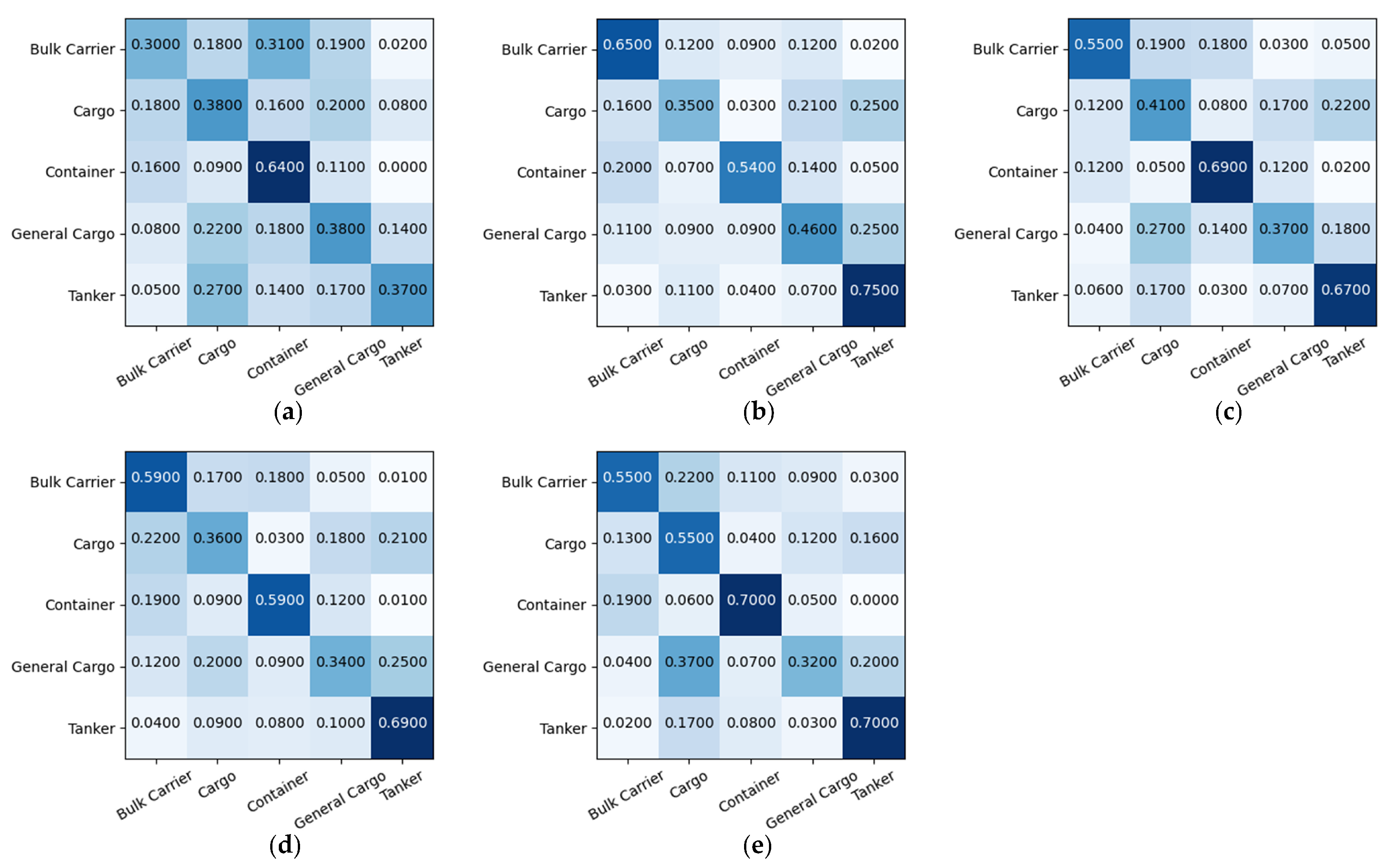
Extensive experiments in three aspects on the OpenSARShip [
24] dataset demonstrate the superior performance of our method over the previous methods.
The article is organized into five sections.
Section 2 introduces the ACGAN and triplet loss that are relevant to our method.
Section 3 presents the proposed LST-ACGAN method in detail.
Section 4 describes the experimental settings and results.
Section 5 is the conclusion.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}