

Multi-Agent Deep Reinforcement Learning Framework Strategized by Unmanned Aerial Vehicles for Multi-Vessel Full Communication Connection

Abstract
:1. Introduction
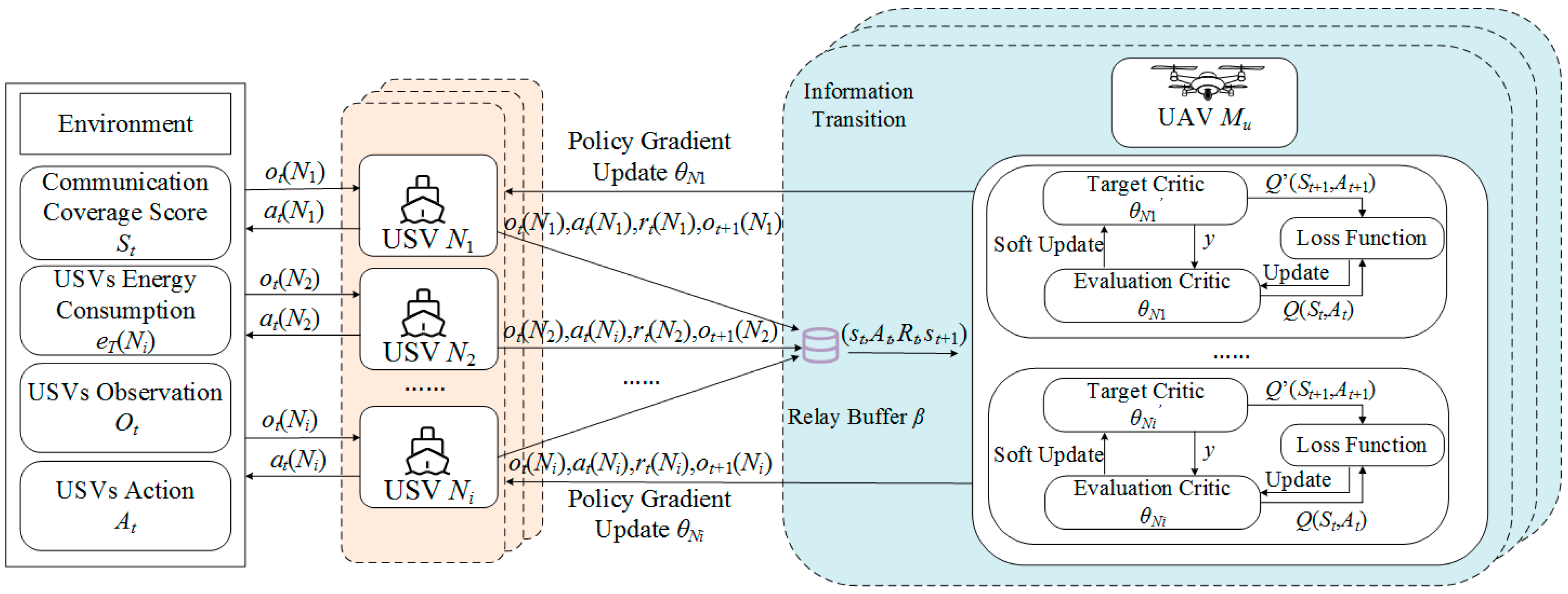
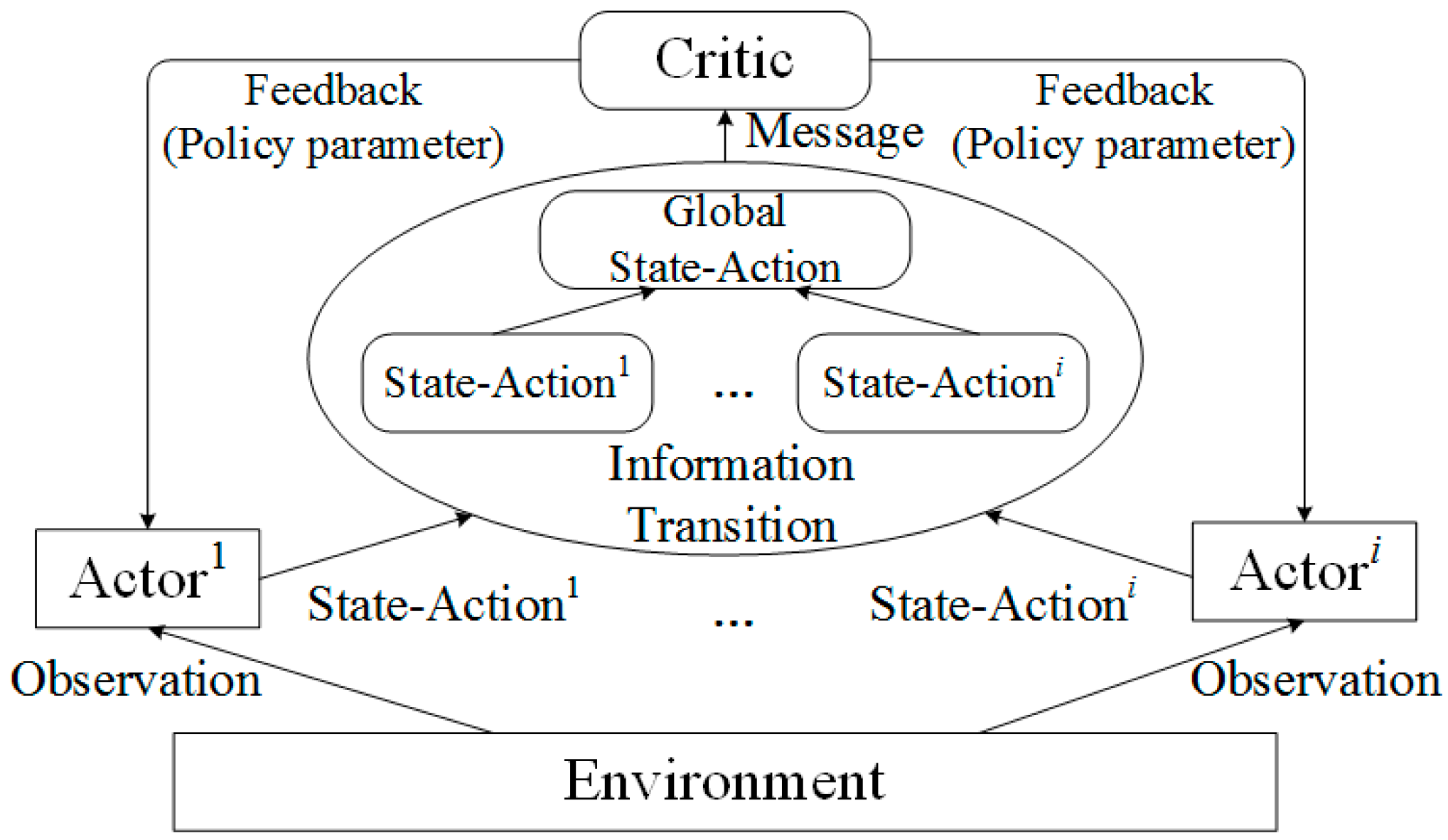
- We use a deep neural network (DNN) to model each USV and dispatch UAVs to evaluate the movement policy of USVs. The USVs not only interact with the environment, but also interact with each other. In the distributed scenes, multiple USV agents learn to make decisions based on their local observations and the global cooperation by UAVs for the same system targets.
- Considering the marine communication feature and the joint behavior of multiple USVs, we define the optimization indexes, including communication coverage, energy consumption, USVs movement fairness, and communication efficiency. Balancing the optimization among them is a coupled and non-convex problem. Therefore, we transform it into a POMG. Then, to achieve an FCC with the improved optimization indexes, we design a UST-ACS, separating the the agents in the USVs and UAVs, i.e., USVs act as actors and UAVs act as critics. The UAVs can efficiently communicate with the USVs, evaluate the movement policy of USVs in the critic networks of UAVs, and feed the evaluation back to the USVs.
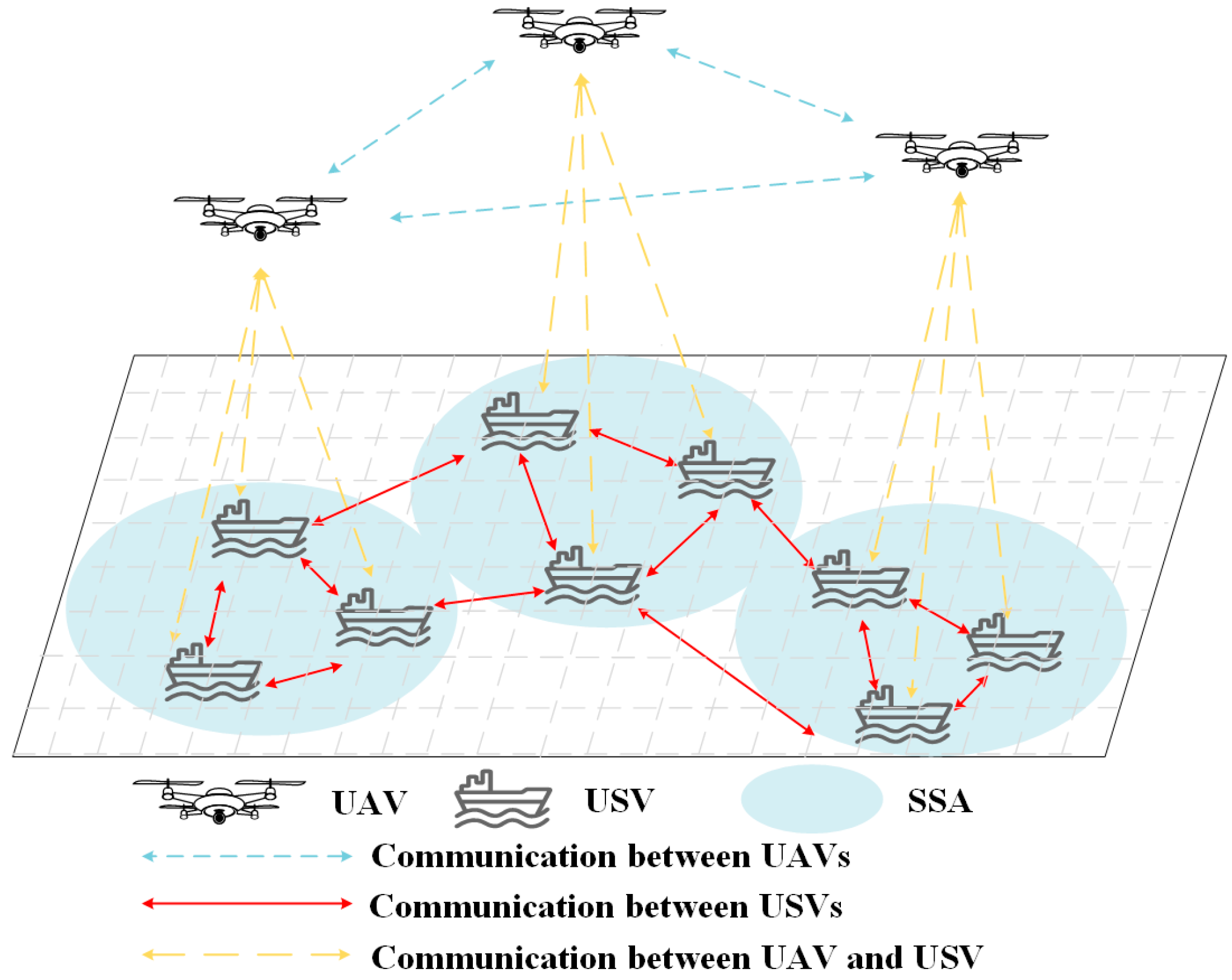
- The information transition module is responsible for collecting the action–state information of USVs and for message fusion. Meanwhile, we divide the target sea area into several SSAs and execute the UST-ACS in each SSA in order to effectively reduce the computational complexity and facilitate the convergence of solution algorithms.
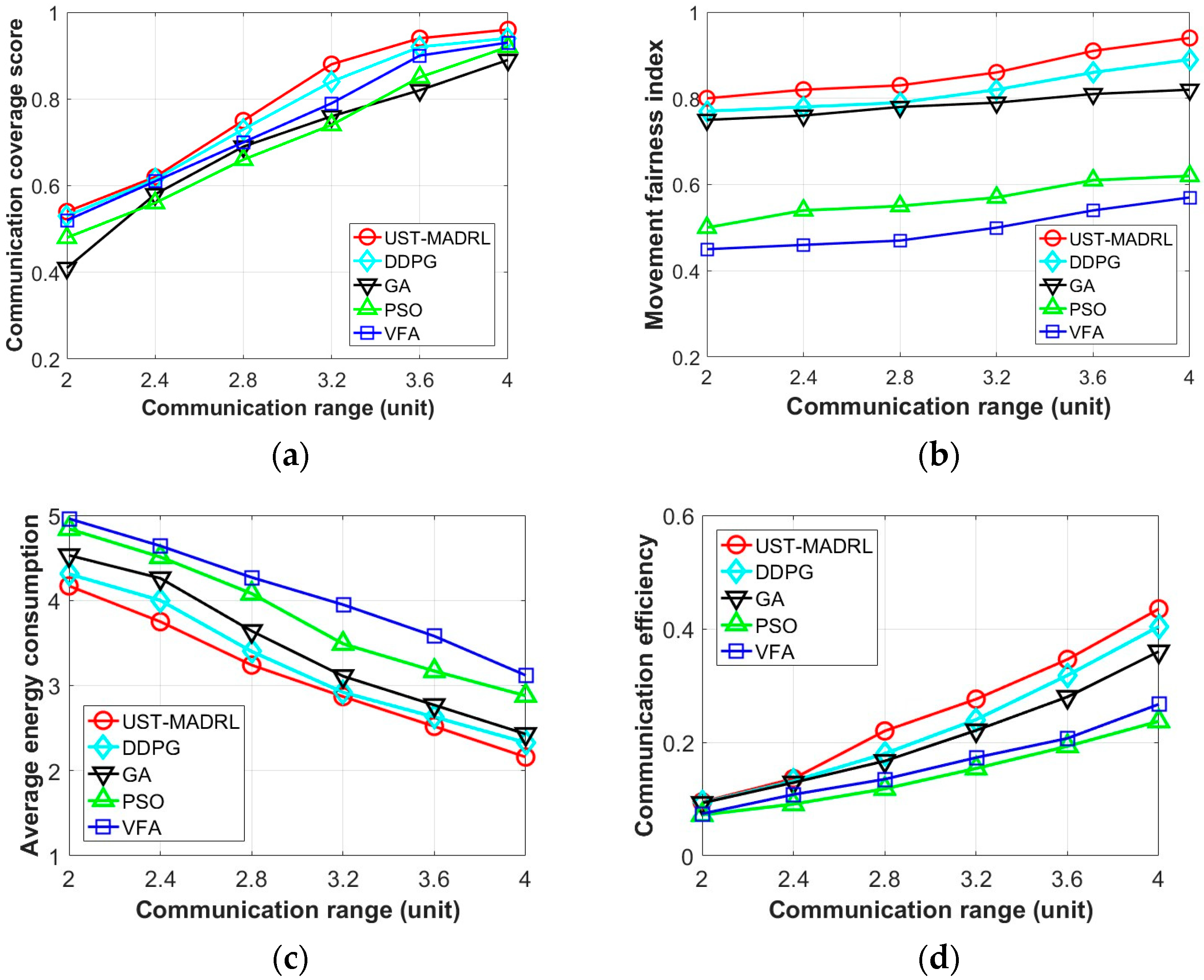
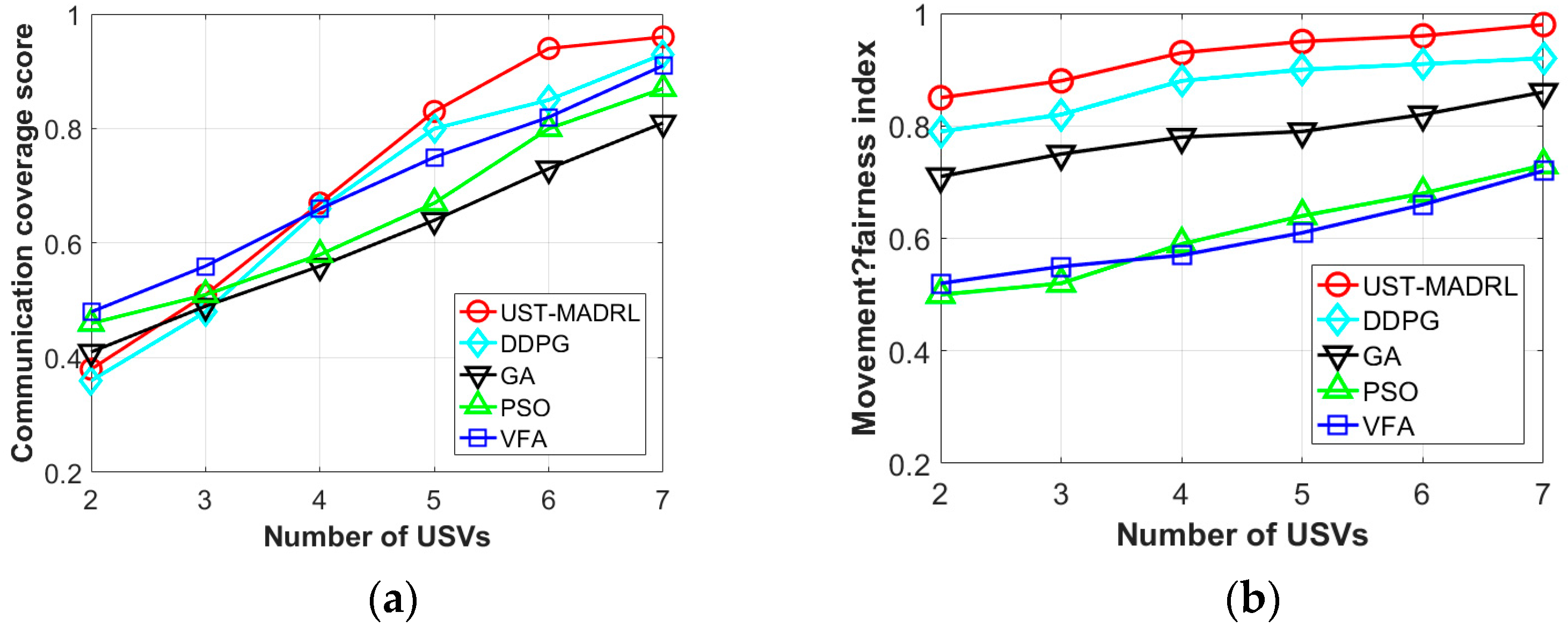
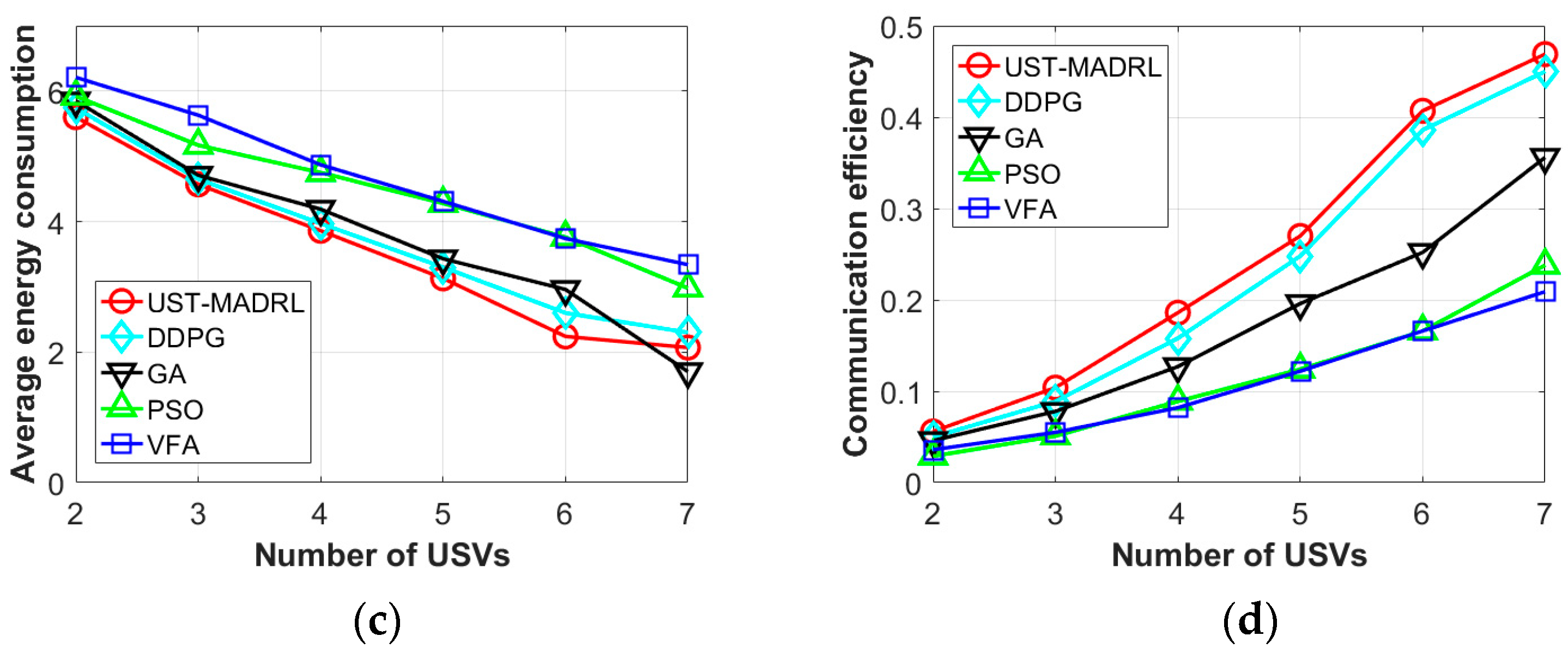
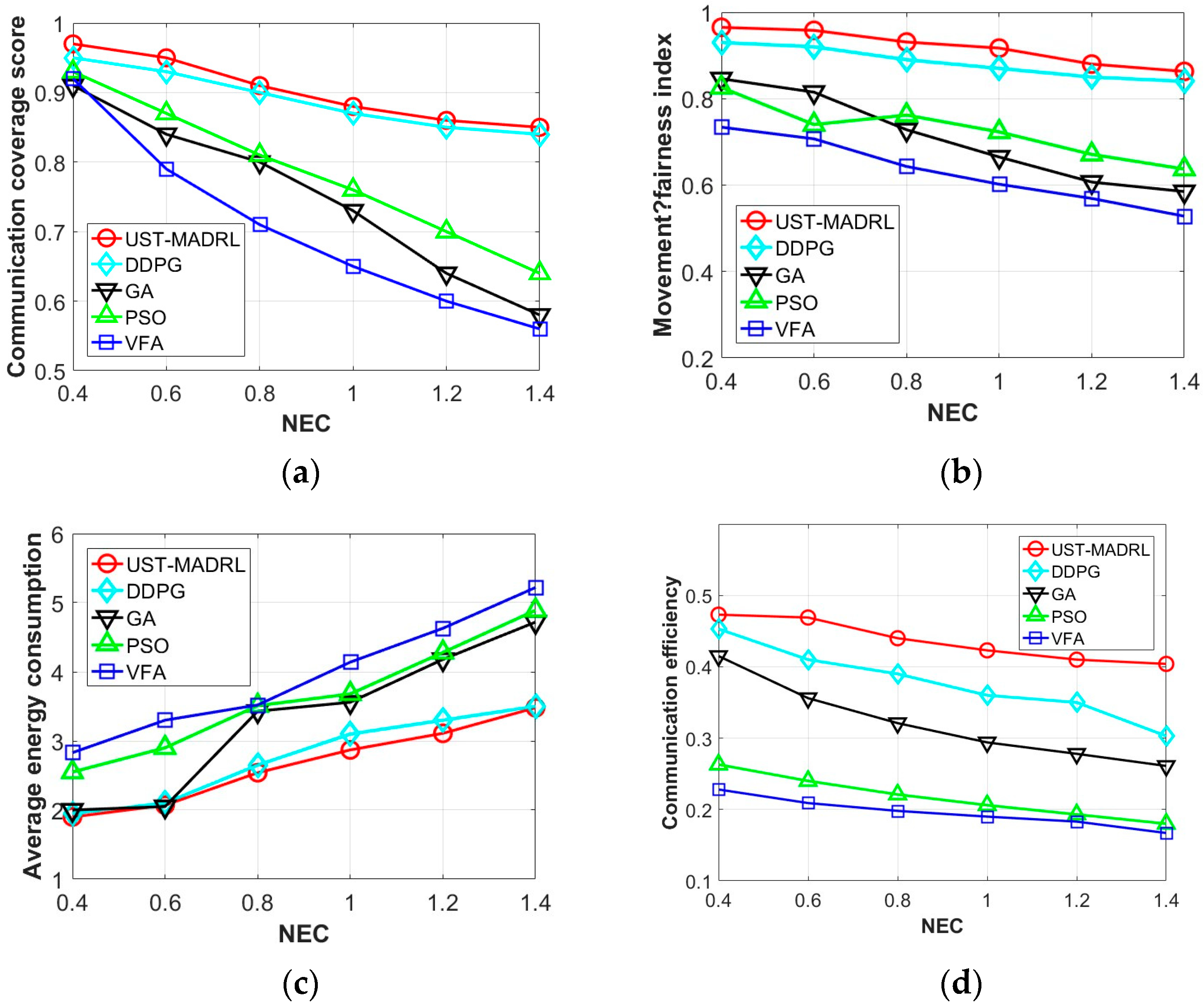
- We perform extensive simulations and compare them to the deep deterministic policy gradient (DDPG) and three baselines. A large number of experiment results show that our proposed framework has better communication coverage performance, higher communication efficiency, and fairer movement decision making.
2. Related Work
2.1. Full Communication Connections among USVs
2.2. UAV-Assisted USV Networks
2.3. DRL for UAV-Assisted Networks
3. System Model
3.1. Network Model
3.2. Communication Channel Models and UAV SSA Partition
3.2.1. Communication Channel Model of USVs
3.2.2. Communication Channel Model between USVs and UAVs
3.2.3. SSA Partition of UAV
3.3. Problem Definition
4. Problem Formulation
4.1. Multi-Agent Set N
4.2. Observation Space Ot and State S
4.3. Action Space At
4.4. State Transition Function
4.5. Reward–Penalty Mechanism for USVs Rt
- (1)
- Communication Efficiency : It integrates three optimization indexes, namely the communication coverage score of USVs , the average energy consumption of USVs eT(avg), and the movement fairness index of USVs Ft, defined as
- (2)
- Non-connectivity Penalty : If the action selected by USV Ni were to change its position from inside of the communication range to outside of the communication range, i.e., , where Nj is any neighbor of Ni, this kind of action should receive a penalty, and the penalty value is . The reason is that it will cause disconnections among USVs and finally undermine the FCC.
- (3)
- Redundancy Penalty : If the action selected by USV Ni causes the Euclidean distance between USV Ni and any neighbor USV Nj to be less than the distance threshold D, i.e., , this kind of action should receive a redundancy penalty, and the value is . This is because it will increase the communication coverage redundancy and reduce the communication coverage score.
- (4)
- Cross Border Penalty : When USV Ni moves beyond the target sea area, we will impose a penalty for this kind of action, and the penalty value is . This operation ensures that USVs learn how to move continually on the given target sea area.
5. Proposed Solution
5.1. Actor Network Design for USVs
| Algorithm 1. Actor network of USVs |
| 1: Input: USVs observation ot (Ni), policy for each USV Ni with parameter , discount factor γ, learning rate for actor network of USVs η; 2: Output: . 3: for USV Ni: = 1,…, |N| do 4: Initialize a random process for action exploration with target parameter ; 5: Receive initial state st; 6: end for 7: for episode: = 1,…, Episode Length do 8: for Timeslot t: = 1,…, T do 9: for USV Ni = 1,…, |N| do 10: USV i obtain according to the local policy and the observation; 11: end for 12: Execute all actions of USVs and get reward; 13: Send , , and to Information Transition; 14: st←st+1; 15: end for 16: end for |
5.2. Information Transition
| Algorithm 2. Information transition of UAVs |
| 1: Input: USVs observation ot (Ni), USVs action at (Ni), USVs reward rt (Ni), USVs observation in next state ot+1 (Ni); 2: Output: Global environment information . 3: Initialize the capacity of replay buffer β to B; 4: for UAV Mu: = 1, ..., |M| do 5: Receive the USV local information in its SSA; 6: Generate information sequence ht (Ni); 7: Integrate ; 8: Store , in replay buffer β; 9: end for |
5.3. Critic Network Design for UAVs
| Algorithm 3. Critic network of UAVs |
| 1: Input: st, At, Rt, st+1, action selection by policy πθt(Ni) for each USV; 2: Output: Updated policy parameter set θ. 3: for each episode: = 1,…, Episode Length do 4: for Timeslot t: = 1,…, T do 5: for UAV Mu: = 1,…, |M| do 6: Sample a random mini-batch of k samples, from β; 7: Set target value y by (23); 8: Update critic network by minimizing the loss L(θi) by (22); 9: Update actor network using the sampled policy gradient by (21); 10: end for 11: Update two target network parameters for each USV Ni; 12: ’ ←ς + (1 − ς) ’; 13: end for |
| 14: end for |
5.4. Training Process
5.5. Testing Process
5.6. Complexity Analysis
6. Simulation Results
6.1. Setup and Evaluation Metrics
6.2. Baselines
- DDPG [45]: A policy-gradient-based approach for continuous control tasks, which uses one actor network and one critic network to output control decisions for all UAVs. The state and reward functions in DDPG are consistent with those in our framework.
- Genetic algorithm (GA) [46]: A stochastic global search optimization method that simulates the replication, crossover, and mutation phenomena occurring in natural selection and genetics, starting from any initial population by the genetic operation to produce a group of individuals better suited for the environment. Here, the USV’s position is adjusted according to the fitness that is calculated from the reward of our paper. In each timeslot t, each USV chooses an action with high fitness value. Combined with the gene crossover and mutation, we use the roulette to eliminate the fittest.
- Particle swarm optimization (PSO) [47]: A bionic optimization algorithm based on multiple agents, which is derived from the study of bird predation behavior. The velocity of the particle is updated according to its own previous best position and the previous best position of its companions. The particles fly with the updated velocities.
- Virtual force algorithm (VFA) [48]: VFA constructs a virtual force field, which is composed of the attractive force field of the target orientation and the repulsive force field around the other agents. It searches in the descending direction of the potential function to find an optimal path and makes the agent move along the direction of the resultant force of virtual attractive force and virtual repulsive force. The attractive force and virtual repulsive force are mainly reflected by the distance among the agents. For a given number of USVs, our optimization indicators can be provided as inputs to the VFA, thereby ensuring flexibility.
6.3. Evaluation Results
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| UAVs | Unmanned Aerial Vehicles |
| USVs | Unmanned Surface Vessels |
| IoV | Internet of Vessels |
| FCC | Full Communication Connection |
| MADRL | Multi-Agent Deep Reinforcement Learning |
| POMG | Partial Observable Markov Game |
| MADDPG | Multi-agent Deep Deterministic Policy Gradient |
| UST-MADRL | MADRL Scenario Strategized by UAVs for Multi-USV FCC |
| ACS | Multi-agent Actor-Critic Structure |
| SSA | Sea Service Area |
| DNN | Deep Neural Network |
| LR | Long Range |
| DRL | Deep Reinforcement Learning |
| RL | Reinforcement Learning |
| DDPG | Deep Deterministic Policy Gradient |
| DQN | Deep Q-network |
| MADQN | Multi-Agent Deep Q-network |
| SNR | Signal/Noise Ratio |
| TD | Time Difference |
| ReLU | Rectified Linear Unit |
| TPU | Tensor Processing Unit |
| GA | Genetic Algorithm |
| PSO | Particle Swarm Optimization |
| VFA | Virtual Force Algorithm |
| NEC | Normalized Energy Consumed |
References
- Lin, B.; Wang, X.; Yuan, W.; Wu, N. A Novel OFDM Autoencoder Featuring CNN-Based Channel Estimation for Internet of Vessels. IEEE Internet Things J. 2020, 7, 7601–7611. [Google Scholar] [CrossRef]
- Singh, R.; Bhushan, B. Condition Monitoring Based Control Using Wavelets and Machine Learning for Unmanned Surface Vehicles. IEEE Trans. Ind. Electron. 2021, 68, 7464–7473. [Google Scholar] [CrossRef]
- Yuan, S.; Li, Y.; Bao, F.; Xu, H.; Yang, Y.; Yan, Q.; Zhong, S.; Yin, H.; Xu, J.; Huang, Z.; et al. Marine environmental monitoring with unmanned vehicle platforms: Present applications and future prospects. Sci. Total. Environ. 2023, 858, 159741. [Google Scholar] [CrossRef] [PubMed]
- Gaugue, M.A.; Menard, M.; Migot, E.; Bourcier, P.; Gaschet, C. Development of an Aquatic USV with High Communication Capability for Environmental Surveillance. In Proceedings of the OCEANS 2019, Marseille, France, 17–20 June 2019; pp. 1–8. [Google Scholar]
- Wang, Y.; Feng, W.; Wang, J.; Quek, T.Q.S. Hybrid Satellite-UAV-Terrestrial Networks for 6G Ubiquitous Coverage: A Maritime Communications Perspective. IEEE J. Sel. Areas Commun. 2021, 39, 3475–3490. [Google Scholar] [CrossRef]
- Do-Duy, T.; Nguyen, L.D.; Duong, T.Q.; Khosravirad, S.R.; Claussen, H. Joint Optimization of Real-Time Deployment and Resource Allocation for UAV-Aided Disaster Emergency Communications. IEEE J. Sel. Areas Commun. 2021, 39, 3411–3424. [Google Scholar] [CrossRef]
- Zeng, J.; Sun, J.; Wu, B.; Su, X. Mobile edge communications, computing, and caching (MEC3) technology in the maritime communication network. China Commun. 2020, 17, 223–234. [Google Scholar] [CrossRef]
- Li, X.; Feng, W.; Chen, Y.; Wang, C.; Ge, N. Maritime Coverage Enhancement Using UAVs Coordinated with Hybrid Satellite-Terrestrial Networks. IEEE Trans. Commun. 2020, 68, 2355–2369. [Google Scholar] [CrossRef]
- Ao, T.; Zhang, K.; Shi, H.; Jin, Z.; Zhou, Y.; Liu, F. Energy-Efficient Multi-UAVs Cooperative Trajectory Optimization for Communication Coverage: An MADRL Approach. Remote Sens. 2023, 15, 429. [Google Scholar] [CrossRef]
- Liu, C.H.; Dai, Z.; Zhao, Y.; Crowcroft, J.; Wu, D.O.; Leung, K. Distributed and Energy-Efficient Mobile Crowdsensing with Charging Stations by Deep Reinforcement Learning. IEEE Trans. Mob. Comput. 2019, 20, 130–146. [Google Scholar] [CrossRef]
- Samir, M.; Ebrahimi, D.; Assi, C.; Sharafeddine, S.; Ghrayeb, A. Leveraging UAVs for Coverage in Cell-Free Vehicular Networks: A Deep Reinforcement Learning Approach. IEEE Trans. Mob. Comput. 2021, 20, 2835–2847. [Google Scholar] [CrossRef]
- Zhang, Y.; Jiang, L.; Ewe, H.T. A Novel Data-Driven Modeling Method for the Spatial–Temporal Correlated Complex Sea Clutter. IEEE Trans. Geosci. Remote Sens. 2020, 60, 5104211. [Google Scholar] [CrossRef]
- Liu, H.; Weng, P.; Tian, X.; Mai, Q. Distributed adaptive fixed-time formation control for UAV-USV heterogeneous multi-agent systems. Ocean Eng. 2023, 267, 113240. [Google Scholar] [CrossRef]
- Zainuddin, Z.; Wardi; Nantan, Y. Applying Maritime Wireless Communication to Support Vessel Monitoring. In Proceedings of the International Conference on Information Technology, Computer, and Electrical Engineering (ICITACEE), Semarang, Indonesia, 18–19 October 2017; pp. 158–161. [Google Scholar] [CrossRef]
- Chen, L.; Huang, Y.; Zheng, H.; Hopman, H.; Negenborn, R. Cooperative Multi-Vessel Systems in Urban Waterway Networks. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3294–3307. [Google Scholar] [CrossRef]
- Fang, X.; Zhou, J.; Wen, G. Location Game of Multiple Unmanned Surface Vessels with Quantized Communications. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 1322–1326. [Google Scholar] [CrossRef]
- Yang, T.; Liang, H.; Cheng, N.; Deng, R.; Shen, X. Efficient Scheduling for Video Transmissions in Maritime Wireless Communication Networks. IEEE Trans. Veh. Technol. 2015, 64, 4215–4229. [Google Scholar] [CrossRef]
- Huang, Z.; Xue, K.; Wang, P.; Xu, Z. A nested-ring exact algorithm for simple basic group communication topology optimization in Multi-USV systems. Ocean Eng. 2022, 266, 113239. [Google Scholar] [CrossRef]
- Zolich, A.; Sœgrov, A.; Vågsholm, E.; Hovstein, V.; Johansen, T.A. Coordinated Maritime Missions of Unmanned Vehicles—Network Architecture and Performance Analysis. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Cao, H.; Yang, T.; Yin, Z.; Sun, X.; Li, D. Topological Optimization Algorithm for HAP Assisted Multi-unmanned Ships Communication. In Proceedings of the 2020 IEEE 92nd Vehicular Technology Conference, Victoria, BC, Canada, 18 November–16 December 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Zhang, J.; Liang, F.; Li, B.; Yang, Z.; Wu, Y.; Zhu, H. Placement optimization of caching UAV-assisted mobile relay maritime communication. China Commun. 2020, 17, 209–219. [Google Scholar] [CrossRef]
- Huang, M.; Liu, A.; Xiong, N.N.; Wu, J. A UAV-Assisted Ubiquitous Trust Communication System in 5G and Beyond Networks. IEEE J. Sel. Areas Commun. 2021, 39, 3444–3458. [Google Scholar] [CrossRef]
- Güldenring, J.; Koring, L.; Gorczak, P.; Wietfeld, C. Heterogeneous Multilink Aggregation for Reliable UAV Communication in Maritime Search and Rescue Missions. In Proceedings of the 2019 International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob’19), Barcelona, Spain, 21–23 October 2019; pp. 215–220. [Google Scholar] [CrossRef]
- Li, X.; Feng, W.; Wang, J.; Chen, Y.; Ge, N.; Wang, C.X. Enabling 5G on the Ocean: A Hybrid Satellite-UAV-Terrestrial Network Solution. IEEE Wirel. Commun. 2020, 27, 116–121. [Google Scholar] [CrossRef]
- Yang, T.; Jiang, Z.; Sun, R.; Cheng, N.; Feng, H. Maritime Search and Rescue Based on Group Mobile Computing for Unmanned Aerial Vehicles and Unmanned Surface Vehicles. IEEE Trans. Ind. Inform. 2020, 16, 7700–7708. [Google Scholar] [CrossRef]
- Liu, C.; Ma, X.; Gao, X.; Tang, J. Distributed Energy-Efficient Multi-UAV Navigation for Long-Term Communication Coverage by Deep Reinforcement Learning. IEEE Trans. Mob. Comput. 2020, 19, 1274–1285. [Google Scholar] [CrossRef]
- Bae, H.J.; Koumoutsakos, P. Scientific multi-agent reinforcement learning for wall-models of turbulent flows. Nat. Commun. 2022, 13, 1443. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Yang, Z.; Liu, H.; Zhang, T.; Basar, T. Fully Decentralized Multi-agent Reinforcement Learning with Networked Agents. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5872–5881. [Google Scholar]
- Peng, H.; Shen, X. Multi-Agent Reinforcement Learning Based Resource Management in MEC- and UAV-Assisted Vehicular Networks. IEEE J. Sel. Areas Commun. 2021, 39, 131–141. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, O.P.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6379–6390. [Google Scholar]
- Liang, L.; Ye, H.; Li, G.Y. Spectrum Sharing in Vehicular Networks Based on Multi-Agent Reinforcement Learning. IEEE J. Sel. Areas Commun. 2019, 37, 2282–2292. [Google Scholar] [CrossRef]
- Ouamri, M.A.; Barb, G.; Singh, D.; Adam, A.B.M.; Muthanna, M.S.A.; Li, X. Nonlinear Energy-Harvesting for D2D Networks Underlaying UAV with SWIPT Using MADQN. IEEE Commun. Lett. 2023, 27, 1804–1808. [Google Scholar] [CrossRef]
- Ouamri, M.A.; Alkanhel, R.; Singh, D.; El-Kenaway, E.-S.M.; Ghoneim, S.S.M. Double Deep Q-Network Method for Energy Efficiency and Throughput in a UAV-Assisted Terrestrial Network. Comput. Syst. Sci. Eng. 2023, 46, 73–92. [Google Scholar] [CrossRef]
- Xu, X.; Chen, Q.; Mu, X.; Liu, Y.; Jiang, H. Graph-Embedded Multi-Agent Learning for Smart Reconfigurable THz MIMO-NOMA Networks. IEEE J. Sel. Areas Commun. 2022, 40, 259–275. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, C.-X.; Chang, H.; He, Y.; Bian, J. A Novel Non-Stationary 6G UAV Channel Model for Maritime Communications. IEEE J. Sel. Areas Commun. 2021, 39, 2992–3005. [Google Scholar] [CrossRef]
- Khawaja, W.; Guvenc, I.; Matolak, D.W.; Fiebig, U.; Schneckenburger, N. A Survey of Air-to-ground Propagation Channel Modeling for Unmanned Aerial Vehicles. IEEE Commun. Surv. Tutor. 2019, 21, 2361–2389. [Google Scholar] [CrossRef]
- Tran, T.A.; Sesay, A.B. A Generalized Linear Quasi-ML Decoder of OSTBCs for Wireless Communications over Time-Selective Fading Channels. IEEE Trans. Wirel. Commun. 2004, 3, 855–864. [Google Scholar] [CrossRef]
- Zhang, X.; Duan, L. Fast Deployment of UAV Networks for Optimal Wireless Coverage. IEEE Trans. Mob. Comput. 2019, 18, 588–601. [Google Scholar] [CrossRef]
- Kimura, T.; Ogura, M. Distributed Collaborative 3D-Deployment of UAV Base Stations for On-Demand Coverage. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 1748–1757. [Google Scholar] [CrossRef]
- Eledlebi, K.; Ruta, D.; Hildmann, H.; Saffre, F.; Alhammadi, Y.; Isakovic, A.F. Coverage and Energy Analysis of Mobile Sensor Nodes in Obstructed Noisy Indoor Environment: A Voronoi-Approach. IEEE Trans. Mob. Comput. 2022, 21, 2745–2760. [Google Scholar] [CrossRef]
- Jain, R.K.; Chiu, D.M.; Hawe, W.R. A Quantitative Measure of Fairness and Discrimination for Resource Allocation in Shared Computer Systems. In Proceedings of the DEC Research Report TR-301, Hudson, MA, USA, 26 September 1984. 38p. [Google Scholar]
- Littman, M.L. Markov Games as A Framework for Multi-Agent Reinforcement Learning. In Proceedings of the 11th International Conference Machine Learning, San Francisco, CA, USA, 10–13 July 1994; pp. 157–163. [Google Scholar]
- Sipper, M. A serial complexity measure of neural networks. In Proceedings of the IEEE International Conference on Neural Networks, San Francisco, CA, USA, 28 March–1 April 1993; pp. 962–966. [Google Scholar]
- Zhao, N.; Ye, Z.; Pei, Y.; Liang, Y.-C.; Niyato, D. Multi-Agent Deep Reinforcement Learning for Task Offloading in UAV-Assisted Mobile Edge Computing. IEEE Trans. Wirel. Commun. 2022, 21, 6949–6960. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the International Conference Learn Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Sivanandam, S.; Deepa, S. Introduction to Genetic Algorithms; Springer: Berlin/Heidelberg, Germany, 2008; pp. 15–37. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995. [Google Scholar]
- Zou, Y.; Chakrabarty, K. Sensor deployment and target localization based on virtual forces. In Proceedings of the the IEEE INFOCOM 2003, Twenty-Second Annual Joint Conference of the IEEE Computer and Communications Societies (IEEE Cat. No.03CH37428), San Francisco, CA, USA, 30 March–3 April 2003; Volume 2, pp. 1293–1303. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | UAV-Assisted USVs | UAV-Assisted Terrestrial Networks | UAV Role | FCC among USVs | DRL |
|---|---|---|---|---|---|
| [14,15,16,17,18] | × | × | × | Partial | × |
| [5,7,8,19,20,21,22,23,24] | √ | × | Relay/participant | × | DRL, RL, etc. |
| [25] | √ | × | Relay/participant | × | A distributed DRL framework |
| [26] | × | √ | Relay/participant | × | A distributed DRL framework |
| [9] | × | √ | Relay/participant | × | DDPG |
| [29] | × | √ | Relay/participant | × | MADDPG |
| [30] | × | √ | Relay/participant | × | MADDPG |
| [31] | × | √ | Relay/participant | × | DQN |
| [32] | × | √ | Relay/participant | × | DDQN |
| [33] | × | √ | Relay/participant | × | MADQN |
| Our framework | √ | × | On-demand/transient | √ | UST-MADRL |
| Parameters Configuration | Quantity |
|---|---|
| Noise power | −120 dBm |
| Channel power gain | −50 dB |
| Size of replay buffer | 10,000 |
| Size of mini-batch | 100 |
| Activation functions | ReLU |
| Discount factor γ | 0.96 |
| Actor’s learning rate η | Decaying from 0.0002 to 0.0000001 |
| Critic’s learning rate ζ | Decaying from 0.002 to 0.000001 |
| Reward discount factor γ | Augmenting from 0.8 to 0.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, J.; Dou, J.; Liu, J.; Wei, X.; Guo, Z. Multi-Agent Deep Reinforcement Learning Framework Strategized by Unmanned Aerial Vehicles for Multi-Vessel Full Communication Connection. Remote Sens. 2023, 15, 4059. https://doi.org/10.3390/rs15164059
Cao J, Dou J, Liu J, Wei X, Guo Z. Multi-Agent Deep Reinforcement Learning Framework Strategized by Unmanned Aerial Vehicles for Multi-Vessel Full Communication Connection. Remote Sensing. 2023; 15(16):4059. https://doi.org/10.3390/rs15164059
Chicago/Turabian StyleCao, Jiabao, Jinfeng Dou, Jilong Liu, Xuanning Wei, and Zhongwen Guo. 2023. "Multi-Agent Deep Reinforcement Learning Framework Strategized by Unmanned Aerial Vehicles for Multi-Vessel Full Communication Connection" Remote Sensing 15, no. 16: 4059. https://doi.org/10.3390/rs15164059
APA StyleCao, J., Dou, J., Liu, J., Wei, X., & Guo, Z. (2023). Multi-Agent Deep Reinforcement Learning Framework Strategized by Unmanned Aerial Vehicles for Multi-Vessel Full Communication Connection. Remote Sensing, 15(16), 4059. https://doi.org/10.3390/rs15164059