1. Introduction
Agile satellites have potential applications in various fields, such as agricultural census [
1], disaster relief [
2], environmental monitoring [
3], urban planning [
4], mapping [
5], and military reconnaissance. Due to the limited attitude maneuver ability of traditional earth-observation satellites (EOSs) and various constraints such as the visible time window, it is challenging for the mission planning system to schedule all tasks within a mission planning time range, and only one subset can be selected with its observation order planned [
6]. Agile satellites possess three-axis maneuverability, which enhances their flexibility and efficiency in processing remote sensing missions. On the other hand, the larger solution space of Agile Earth-Observation Satellite (AEOS) mission planning compared with that of EOSs considerably amplifies the planning complexity [
7]. The increasing number of remote sensing missions and the complexity of agile-satellite control create a challenge for agile-satellite mission planning [
6,
7]. Consequently, a reliable and efficient mission planning system is of great importance to fully utilize the potent observation capabilities of agile satellites.
Since the inception of the first comprehensive study on the AEOS scheduling problem proposed by Lemaître et al. in 2002 [
8], which proved to be NP-hard, the problem has experienced a significant surge in interest over the past two decades [
7]. Initially, exact algorithms were employed to tackle this problem, focusing on small-scale instances without considering satellite maneuvering. These algorithms, such as dynamic programming [
8], branch and bound [
9], and tree search [
10], provide an accurate solution for the given problem.
Owing to the explosion of the solution space, exact methods are impractical for larger-scale scenarios. Researchers have explored various heuristic and meta-heuristic algorithm approaches to accelerate the scheduling process of large-scale AEOS scenarios, including tabu algorithms [
11,
12], iterated local search algorithms [
13], genetic algorithms (GA) [
14,
15], and ant colony optimization algorithms [
16]. One of the most popular heuristic algorithms for solving Combinatorial Optimization Problems (COPs), including transportation and scheduling problems, is the Large Neighborhood Search (LNS) [
17]. The LNS framework minimizes problem objectives by iteratively removing and inserting solution segments using “destroy” and “repair” operators [
18,
19]. The operators of LNS are fixed, resulting in reduced search efficiency for more complex and dynamic problems [
20]. Additionally, when considering the implementation of large neighborhood-based heuristics, the computational time required to explore the large neighborhood becomes a primary trade-off [
21]. The Adaptive Large Neighborhood Search (ALNS) algorithm [
22,
23] improves upon the LNS algorithm by modifying the algorithmic framework, leading to enhanced efficiency and the ability to handle larger problem instances, thereby significantly reducing the search time for solutions. Liu et al. [
19] proposed applying ALNS to address the AEOS scheduling problem and emphasized the time-dependent transition time in terms of problem features. Additionally, various deep learning strategies have been proposed to enhance the search efficiency of ALNS approaches. Hottung et al. [
24] proposed a deep neural network model with an attention mechanism for repairing processes. Paulo et al. [
25] proposed combining machine learning and two-opt operators to learn a stochastic policy to improve the solutions sequentially. Nonetheless, the quality of the solutions provided by ALNS for large-scale problems is not guaranteed. The performance of ALNS operators is solely based on past experiences, and in practical scenarios, it may be necessary to preselect operators based on the specific problem characteristics [
21].
These approaches mentioned above have demonstrated satisfactory performance in small-sized EOS instances [
26]. However, in some actual applications, the aforementioned methods cannot be applied directly and effectively. In agile-satellite mission planning, attitude maneuvering introduces additional resources and time consumption, leading to increased constraints on satellite resources and planning time. Heuristic algorithms face challenges in optimizing resource utilization and solution search speed. As the scale of agile-satellite mission planning expands, heuristic and meta-heuristic methods struggle to balance efficiency and solution quality. Accordingly, the solution quality deteriorates significantly, and there is a risk of failing to find a feasible solution within the specified time constraints [
19].
Another category of approaches for solving planning problems is known as DRL. Compared with heuristic algorithms, DRL greatly improves the search speed of optimal solutions and the ability to solve large-scale problems [
27]. Recent research has demonstrated the effectiveness and excellent performance of DRL in solving agile-satellite mission planning problems: Wang et al. [
28] utilized the DRL framework in real-time scheduling of image satellites by maximizing a Dynamic and Stochastic Knapsack Problem and the total expected profit objective. Chen et al. [
29] proposed an end-to-end framework based on DRL, which views neural networks as complex heuristic methods constructed by observing reward signals and following feasible rules, and incorporates RNNs and attention mechanisms. Huang et al. [
30] used the deep deterministic policy gradient algorithm (DDPG) to solve the time-continuous satellite task-scheduling problem and employed graph clustering in the preprocessing phase. He et al. [
31] modeled the agile-satellite scheduling problem as a finite Markov decision process (MDP) and proposed a learning-based reinforcement method, which efficiently generates high profits for various scheduling problems using a Q-network guided by a trained value function. Despite some work being conducted for DRL-based mission planning, the results of DRL depend on the effectiveness of neural network model training, and the data utilization rates are relatively low [
32]. Compared with the traditional heuristic algorithm, it is more facile to converge to a non-optimal solution, and the solution quality of these DRL methods requires further improvement.
In this paper, we propose a satellite mission planning algorithm based on the dynamic destroy deep-reinforcement learning (D3RL) model, which combines the DRL framework with the LNS algorithm to enhance adaptability and computation efficiency while maintaining the quality of the solution. Specifically, a GAT-based D3RL model is designed to address the challenges of agile-satellite mission planning. First, based on the MDP, the Proximal Policy Optimization (PPO) algorithm [
33] is used to train the D3RL model. Later, we integrate the DRL strategy with the heuristic algorithm and apply the D3RL model to the adaptive destruction process of the LNS. Furthermore, the DRL method, which extends the application scope of the D3RL model, also demonstrates promising outcomes.
The following is a summary of the main contributions:
A D3RL model is designed for the AEOS scheduling problem, focusing on large-scale scenarios. The state, action, and reward function is clearly explained in MDP.
A GAT-based actor-network is established using the target clustering information. The clustering graph for the satellite mission is built using an adjacency matrix based on the constraints provided.
Two application methods for practical agile-satellite mission planning are proposed: the DRL method and the DRL-LNS method. The DRL method utilizes the D3RL model for direct inference, while an improved dynamic destroy operator based on the D3RL model is developed for the DRL-LNS.
Comparison experiments are implemented between our algorithms and other algorithms (GA, ALNS). The results show that the proposed methods have fewer iteration times to convergence and a higher task-scheduled rate than other traditional heuristic algorithms in large-scale scenarios. The DRL-LNS method outperforms other algorithms in Area instances, while the DRL method performs better in World scenarios.
The remaining sections of this study are structured as follows: In
Section 2, the problem description is introduced. In
Section 3, the modeling process of the D3RL model is presented in depth. The effectiveness of the suggested applications are verified through comparison experiments in
Section 4, and the conclusions are drawn in
Section 5.
2. Problem Description
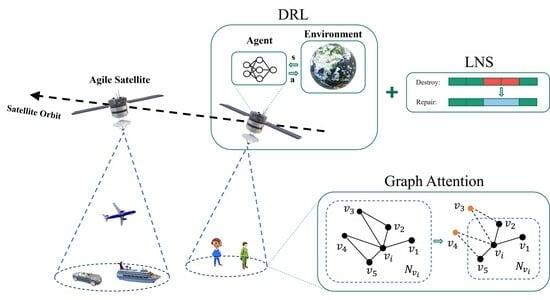
AEOS mission planning is an oversubscribed problem which requires a satellite to schedule more tasks than its capacity. As depicted in
Figure 1, agile satellites with three-axis maneuvering capabilities must schedule a considerable number of remote sensing missions within a limited time frame. Based on previous research, the general objectives and constraints of the AEOS schedule problem are widely discussed in Wang et al. [
7], Peng et al. [
13], and Liu et al. [
19]. Considering the constraints, the objective function of satellite mission planning is described as maximizing the total profit of all scheduled tasks. In this section, some problem assumptions and detailed mathematical formulations are set up for a specific scenario.
2.1. Problem Assumption
The mathematical formulation of agile-satellite mission planning in actual satellite remote sensing scenarios is highly complex due to the flexibility of satellite maneuvering, the diversity of satellite loads, and the complexity of remote sensing tasks. In this study, we focus solely on the task decision component of agile-satellite mission planning. To make this feasible, we make some reasonable simplifications and assumptions based on actual engineering backgrounds [
34]:
Each task can only be executed once, and the profit can be obtained when the task is scheduled.
The execution time windows of any two scheduled tasks cannot overlap and must be within the visible time window.
Satellite storage, power constraints, and image download processes are not considered. Resource problems are not the key factor for short-term mission planning [
6].
Most of the tasks are regular with equal profit.
Only the single-orbit scenario of a single satellite is taken into account.
Remark 1. This paper primarily addresses the normalized monitoring scenario of remote sensing satellites, where regular tasks constitute the majority of actual satellite remote sensing observation tasks, with only a small number of emergency tasks. In this context, the profit differences between regular tasks are not apparent, making the direct assignment of task priority based on profit, as some current studies do, unreasonable. To assess the efficiency of regular task planning, this paper introduces the task scheduled rate, which is defined in Section 4.3. Future research will delve into a detailed analysis of the profit function. 2.2. Variables
Define the task set: R = , where is the i-th task and n is the total number of target points. is the n-dimensional decision vector, where , . The task is selected to be completed when . and can be calculated using the known satellite orbit and target information. Within the selected visible time window , the satellite has the capability to detect targets either through maneuvers or directly within the field of view. The task-execution time window refers to the specific time during which a satellite task is executed, such as the period when an optical observation satellite takes photographs.
2.3. Mathematical Formulation
2.3.1. Constraint Conditions
Conflict constraint:
A satellite can only perform one mission per observation. There is no crossover between any two tasks, as the optical sensor cannot perform two observation tasks at the same time.
and
:
Task execution uniqueness constraint:
In this paper, we do not consider repetitive tasks. Each task can just be observed at most once in all satellite observation periods:
is the execution time window set for task . We define the as a binary decision variable indicating whether the j-th excution time window of associated with task is selected or not. It means that for each task we can choose only one execution time window to fulfill its observation.
Satellite-attitude maneuver time constraint:
The actual observation time of the task
must be within a visual time window of the task:
Then, we can obtain the satellite-attitude maneuver time constraint between
and
:
The transition time
, as defined in [
19], is approximated using a piecewise linear function. The time interval between two scheduled tasks must exceed the transition time required for the satellite attitude maneuver. In the subsequent specific experiments, the transition time is set as in [
35].
2.3.2. Optimization Objective
The specific observation time selection of the satellite is simplified, and the intermediate of the visible time window of the mission is temporarily set as the optimal observation time [
19]. This is attributed to the characteristics of agile-satellite observation, where the optimal imaging quality and observation angle can be achieved through observation at the intermediate of the visible time window of the mission.
If
is the dynamic selected, this introduces a joint problem involving mission planning and optimal control, which will be explored in future research. Then, the agile-satellite mission planning problem will become a constraint satisfaction integer programming problem. To maximize the total observation profit, more tasks will be scheduled. Hence, the objective function
f is designed to maximize the total profit by the sum of scheduled tasks. In this paper, we only consider the equal profit task, which means
.
Remark 2. Agile-satellite mission planning can be described as a multi-objective optimization problem which needs to determine the observation time, observation order, and optimizing satellite control at the same time [36]. In this study, we focus on addressing the decision-making problem of the observation order for large-scale satellite missions. 

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}