



D3CNNs: Dual Denoiser Driven Convolutional Neural Networks for Mixed Noise Removal in Remotely Sensed Images

 ,
,  ,
,  ,
,
Abstract
:1. Introduction
- According to the Bayes’ theorem, the estimation of x and s with the posterior distribution can be converted into the following equationwhere is a likelihood prior which can be presented aswhere is the -norm function. and are respectively the prior probabilities of x and s, which are used to obtain optimization solutions being closed to the actual values. With proper parameters and , the prior probability is written aswhile is defined aswhere and are different regularizations on x and s, respectively. By inserting Equations (3) to (5) into Equation (2), the posterior distribution is equivalent to
- With the usage of the logarithmic transformation, the optimization solution of Equation (6) is transferred from maximizing the posterior distribution to minimizing the energy function which is
- The optimization solution of model (7) is solved with the employment of ADMM or split Bregman by introducing auxiliary variables.
2. Related Works
- Sparsity-based priors: These methods viewed that the image especially the stripe is sparse, so different priors, such as gradient-based variation, dictionary-based learning, and low-rank recovery, are combined to constrain the models for pursuing the optimal approximate solution. For instance, Huang et al. [56] proposed a uniform mixed noise removal model by the employment of joint analysis and weighted synthesis sparsity priors (JAWS). Chang et al. [57] employed unidirectional total variation and sparse representation (UTVSR) to simultaneously destripe and denoise remote sensing images. Xiong et al. [58] proposed a spectral-spatial gradient regularized low-rank tensor factorization method for hyperspectral denoising. Zheng et al. [59] removed mixed noise in hyperspectral images via low-fibered-rank regularization. Liu et al. [60] used the global and local sparsity constraints for a unified model construction to simultaneously estimation intensity bias and remove stripe noise in noisy infrared images. Zeng et al. [61] proposed a hyperspectral image restoration model with global L spatial-spectral total variation regularized local low-rank tensor recovery. Xie et al. [62] denoised hyperspectral images via non-convex regularized low-rank and sparse matrix decomposition. Hu et al. [63] proposed a restoration method that can simultaneously remove Gaussian noise and stripes using adaptive anisotropy total variation and nuclear norms. Wang et al. [64] presented a Hybrid total variation model for hyperspectral image mixed noise removal and compressed sensing. Wang et al. [65] exploited nonconvex logarithmic penalty for hyperspectral image denoising. These methods pursued their exciting denoising performance at the cost of expensively computational complexity.
- Sparsity-based priors with joint of deep CNN denoiser prior: Recently, deep convolutional neural network (CNN) as a prior for a specialized task has been popular applied in various fileds, especially in image restoration, due to its fast speed and large modeling capacity. Such property had been induced as an image prior to solve the inverse problem of image restoration [66,67,68], and had a considerable advantage. Inspired by its encouraging performance, Huang et al. [69] exploited deep CNN prior with the combination of unidirectional variation prior (UV-DCNN) to simultaneously destriping and denoising optical remotely sensed images. Zeng et al. [70] used CNN denoiser prior regularized low-rank tensor recovery for hyperspectral image restoration. These unfolding image denoising methods interpreted a truncated unfolding optimization as an end-to-end trainable deep network and thus usually produced pleasing results with fewer iterations using additional training for each task [68].
- Discriminative learning prior: As the Gaussian white noise and the stripe noise are both additive, so there are also various CNN-based denoising methods proposed to obtain both the image and the stripe. For example, He et al. [71] proposed a deep-learning approach to correct single-image-based nonuniformity in uncooled long-wave infrared detectors. Chang et al. [72] introduced a deep convolutional neural network (DCNN), named as HSI-DeNet, for HSIs’ noise removal. Zhang et al. [73] employed a spatial-spectral gradient network to remove hybrid noise in hyperspectral image. Luo et al. [74] suggested a spatial–spectral constrained deep image prior (S2DIP), which simultaneously capitalize the high model representation ability brought by the CNN in an unsupervised manner and does not need any extra training data. Despite the effectiveness of these methods, the CNN models are pretrained and cannot be jointly optimized with other parameters.
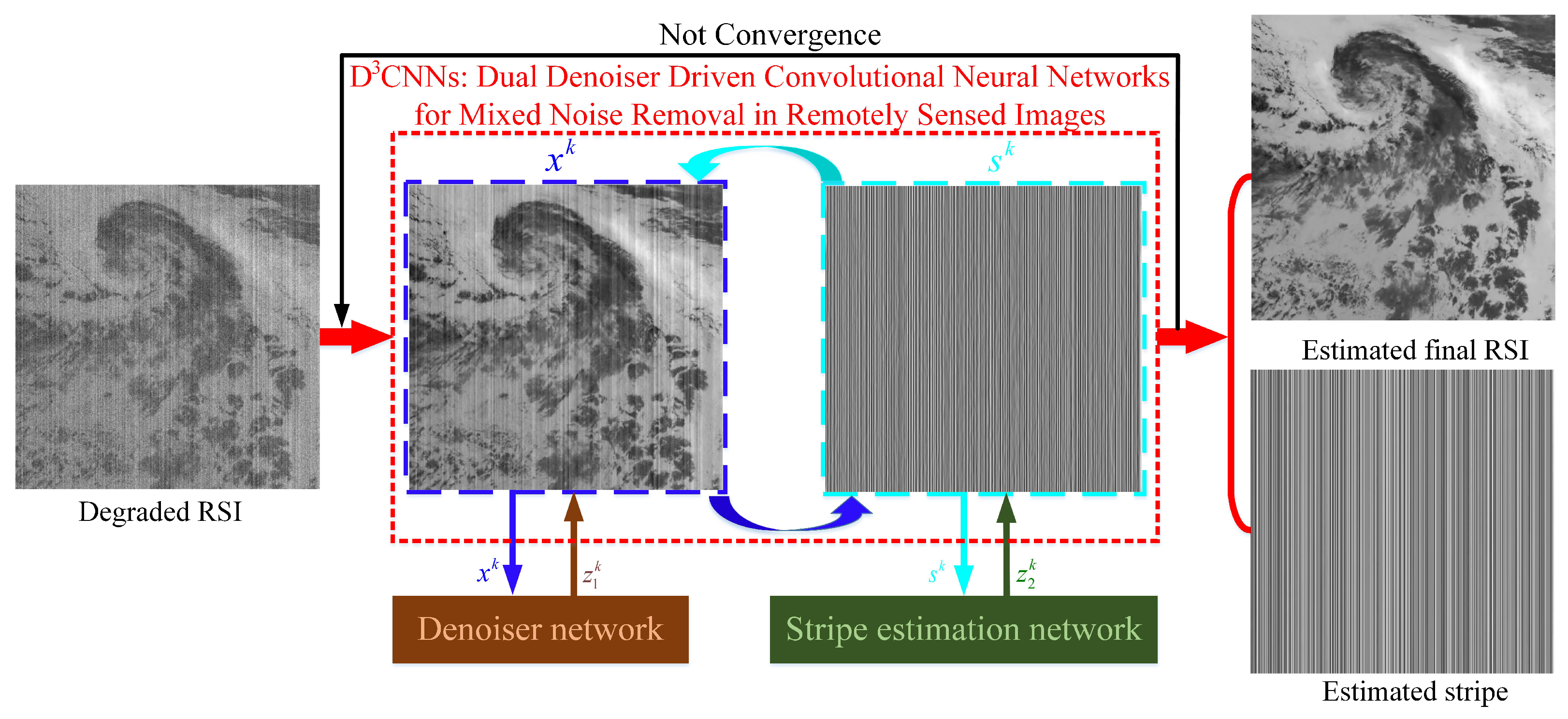
- A unified mixed noise removal (MNR) framework, named as Dual Denoiser Driven Convolutional Neural Networks (D3CNNs), is proposed by using the CNN based denoiser and striper priors.
- Two deep denoiser/striper priors, respectively trained by a highly flexible U-shape denoiser and an effective residual learning strategy, are plugged as two modular parts into a half quadratic splitting based iterative algorithm to solve the inverse problem.
- Quantitative and qualitative results of experiments on both synthetic and real-world images validate the effectiveness of the proposed mixed noise removal scheme and even outperforms other advanced denoising approaches.
3. Dual Denoiser Driven Convolutional Neural Networks
3.1. Half Quadratic Splitting (HQS) Algorithm
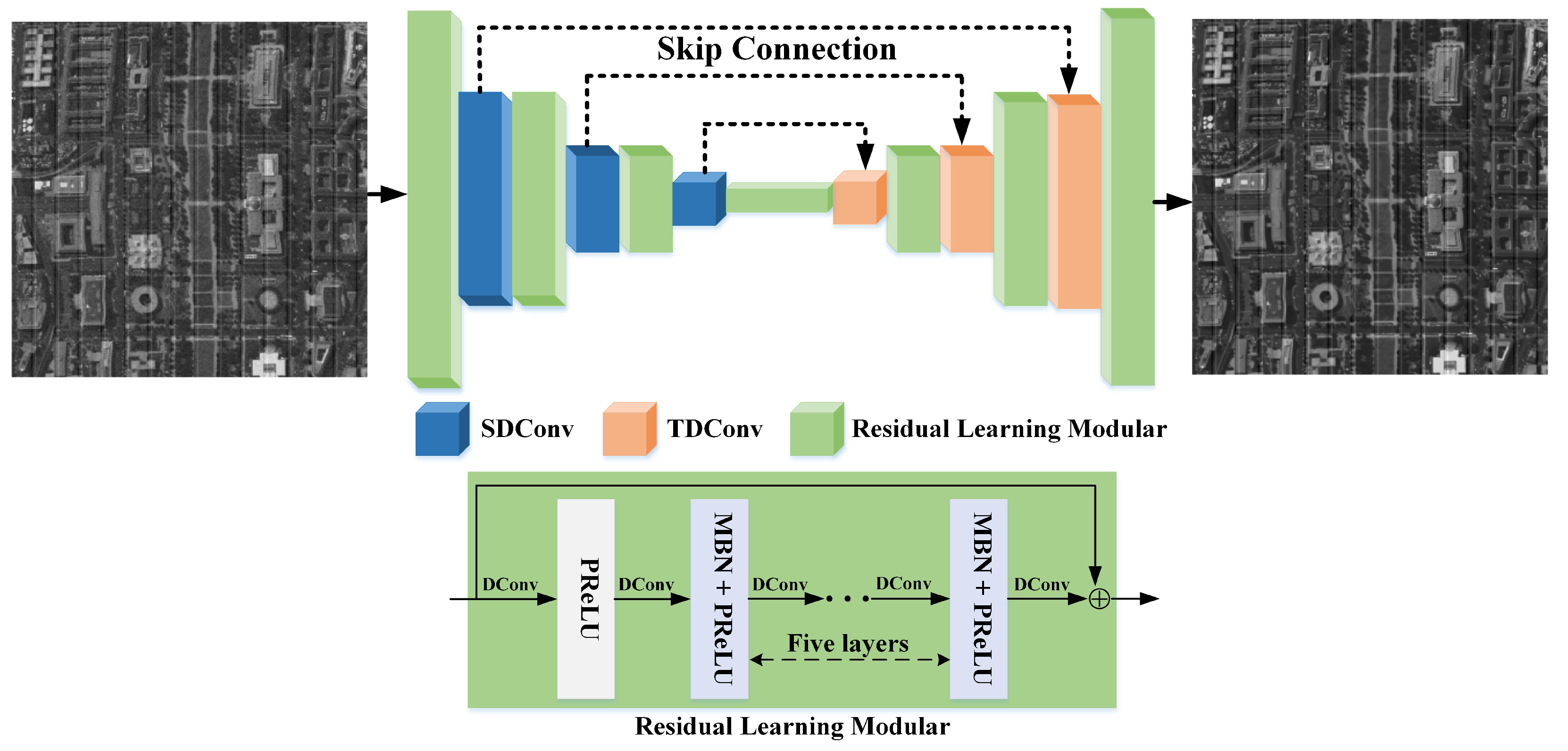
3.2. U-Shape Denoiser Network
3.3. Stripe Estimation Network
3.4. Loss Function
| Algorithm 1 The Optimization of Dual Denoiser Driven Convolutional Neural Networks for Remotely Sensed Image Restoration |
|
Initial Setting: Observed degraded image y, parameters and , iteration number K, initial noise level and , , and two pretrained networks (denoiser in Equation (19) and striper in Equation (20). while Convergence criterion Equations (24) and (25) or is not satisfied do 1: Computing using Equation (17); 2: Computing using Equation (18); 3: Calculating using Equation (19); 4: Calculating using Equation (20); 5: Updating k: . end while Output: Latent clean image and stripe . |
4. Experimental Results and Discussion
4.1. Experimental Preparation
4.1.1. Experimental Environment and Data
4.1.2. Experimental Parameters Setting
4.1.3. Compared Methods and Evaluation Indexes Selection
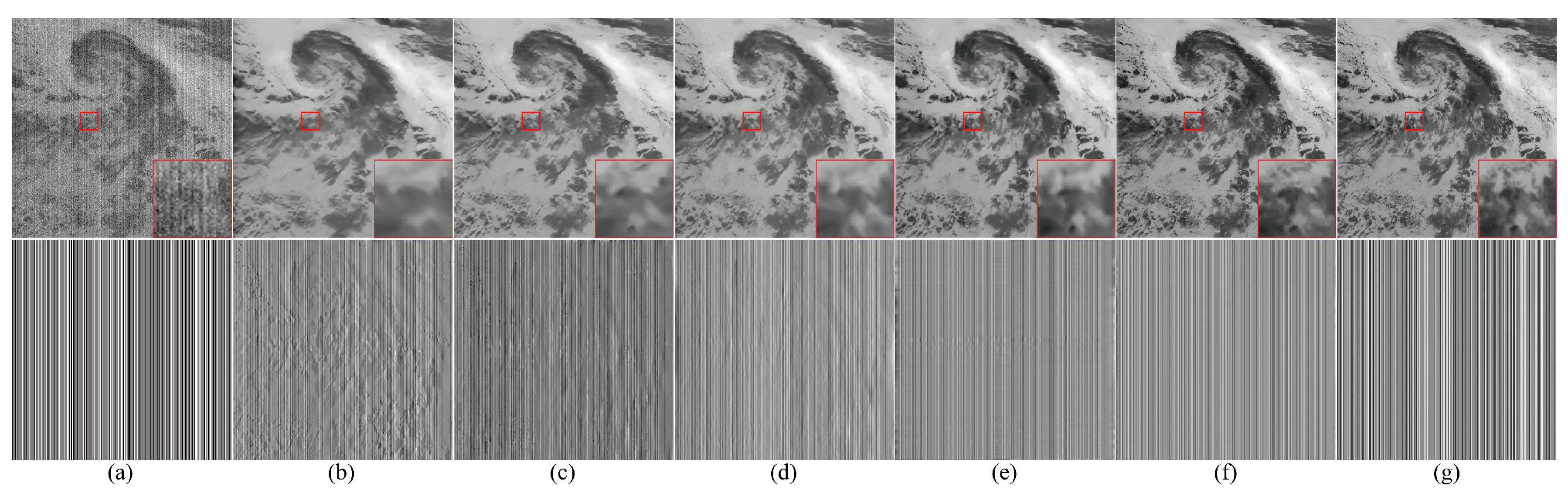
4.2. Discussion of Intermediate Results
4.3. Experiments on Synthetic Rsis
4.3.1. Qualitative Evaluation
4.3.2. Quantitative Assessment
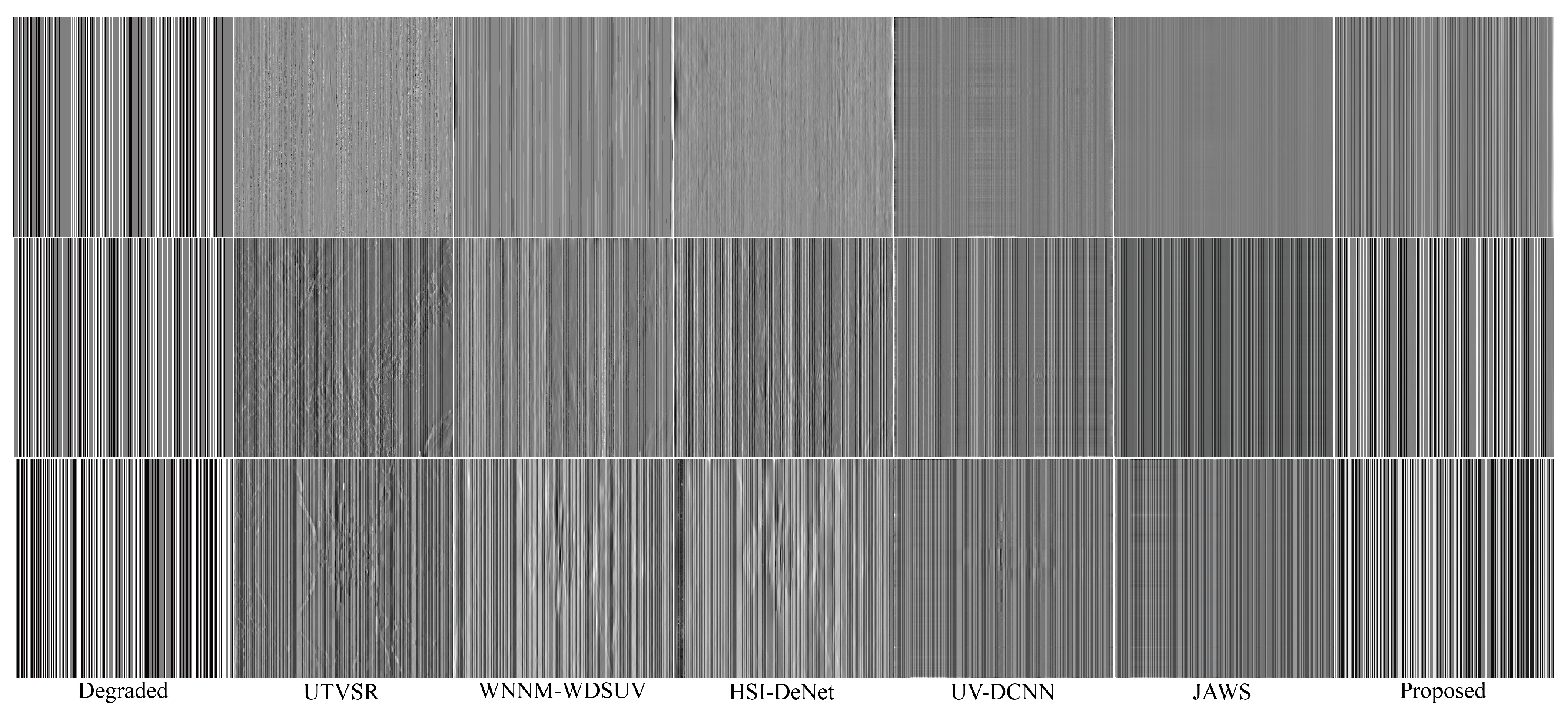
4.4. Applications to the Real-World Degraded Rsis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, Y.; Chen, W.; Zhang, Y.; Tao, C.; Xiao, R.; Tan, Y. Accurate cloud detection in high-resolution remote sensing imagery by weakly supervised deep learning. Remote Sens. Environ. 2020, 250, 112045. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Y.; Huang, X.; Zhu, H.; Ma, J. Large-scale remote sensing image retrieval by deep hashing neural networks. IEEE Trans. Geosci. Remote Sens. 2018, 56, 950–965. [Google Scholar] [CrossRef]
- Li, Y.; Kong, D.; Zhang, Y.; Tan, Y.; Chen, L. Robust deep alignment network with remote sensing knowledge graph for zero-shot and generalized zero-shot remote sensing image scene classification. ISPRS JPRS 2021, 179, 145–158. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, Y.; Zhang, Y.; Zhong, L.; Wang, J.; Chen, J. DKDFN: Domain knowledge-guided deep collaborative fusion network for multimodal unitemporal remote sensing land cover classification. ISPRS JPRS 2022, 186, 170–189. [Google Scholar] [CrossRef]
- Li, Y.; Chen, W.; Huang, X.; Gao, Z.; Li, S.; He, T.; Zhang, Y. Mfvnet: Deep adaptive fusion network with multiple field-of-views for remote sensing image semantic segmentation. Sci. China Inf. Sci. 2022. [Google Scholar] [CrossRef]
- Huang, Z.; Zhang, Y.; Li, Q.; Zhang, T.; Sang, N.; Hong, H. Progressive dual-domain filter for enhancing and denoising optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2018, 15, 759–763. [Google Scholar] [CrossRef]
- Chang, Y.; Chen, M.; Yan, L.; Zhao, X.; Li, Y.; Zhong, S. Toward universal stripe removal via wavelet-based deep convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2880–2897. [Google Scholar] [CrossRef]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Physica D 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Han, L.; Zhao, Y.; Lv, H.; Zhang, Y.; Liu, H.; Bi, G. Remote Sensing Image Denoising Based on Deep and Shallow Feature Fusion and Attention Mechanism. Remote Sens. 2022, 14, 1243. [Google Scholar] [CrossRef]
- Zhang, B.; Aziz, Y.; Wang, Z.; Zhuang, L.; Michael, K.N.; Gao, L. Hyperspectral Image Stripe Detection and Correction Using Gabor Filters and Subspace Representation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Sun, L.; He, C.; Zheng, Y.; Wu, Z.; Jeon, B. Tensor Cascaded-Rank Minimization in Subspace: A Unified Regime for Hyperspectral Image Low-Level Vision. IEEE Trans. Image Process. 2023, 32, 100–115. [Google Scholar] [CrossRef]
- Yu, Y.; Samaki, B.; Rashidi, M.; Mohammadi, M.; Nguyen, T.; Zhang, G. Vision-based concrete crack detection using a hybrid framework considering noise effect. J. Build. Eng. 2022, 61, 105246. [Google Scholar] [CrossRef]
- Syam, T.; Muthalif, A. Magnetorheological Elastomer based torsional vibration isolator for application in a prototype drilling shaft. J. Low Freq. Noise Vib. Act. Control 2022, 41, 676–700. [Google Scholar] [CrossRef]
- Chambolle, A. An algorithm for total variation minimization and applications. J. Math. Imag. Vis. 2004, 20, 89–97. [Google Scholar]
- Chan, T.F.; Esedoglu, S. Aspects of total variation regularized li function approximation. SIAM J. Appl. Math. 2005, 65, 1817–1837. [Google Scholar] [CrossRef] [Green Version]
- Osher, S.; Burger, M.; Goldfarb, D.; Xu, J.; Yin, W. An iterative regularization method for total variation-based image restoration. Multiscale Model. Simul. 2005, 4, 460–489. [Google Scholar] [CrossRef]
- Peyre, G.; Bougleux, S.; Cohen, L.D. Non-local regularization of inverse problems. Inverse Probl. Imaging 2011, 5, 511–530. [Google Scholar] [CrossRef]
- Condat, L. Semi-local total variation for regularization of inverse problems. In Proceedings of the 2014 22nd European Signal Processing Conference (EUSIPCO), Lisbon, Portugal, 1–5 September 2014; pp. 1806–1810. [Google Scholar]
- Jidesh, P.; Shivarama, H.K. Non-local total variation regularization models for image restoration. Comput. Electr. Eng. 2018, 67, 114–133. [Google Scholar] [CrossRef]
- Elad, M.; Aharon, M. Image denoising via sparse and redundant representations over learned dictionaries. IEEE Trans. Image Process. 2006, 15, 3736–3745. [Google Scholar] [CrossRef]
- Mairal, J.; Elad, M.; Sapiro, G. Sparse representation for color image restoration. IEEE Trans. Image Process. 2008, 17, 53–69. [Google Scholar] [CrossRef] [Green Version]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G.; Zisserman, A. Non-local sparse models for image restoration. In Proceedings of the IEEE 12th International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 2272–2279. [Google Scholar]
- Dong, W.; Zhang, L.; Shi, G.; Li, X. Nonlocally centralized sparse representation for image restoration. IEEE Trans. Image Process. 2013, 22, 1620–1630. [Google Scholar] [CrossRef] [PubMed]
- Dong, W.; Shi, G.; Ma, Y.; Li, X. Image restoration via simultaneous sparse coding: Where structured sparsity meets Gaussian scale mixture. Int. J. Comput. Vis. (IJCV) 2015, 114, 217–232. [Google Scholar] [CrossRef]
- Huang, Z.; Li, Q.; Zhang, T.; Sang, N.; Hong, H. Iterative weighted sparse representation for X-ray cardiovascular angiogram image denoising over learned dictionary. IET Image Process. 2018, 12, 254–261. [Google Scholar] [CrossRef]
- Gu, S.; Zhang, L.; Zuo, W.; Feng, X. Weighted nuclear norm minimization with application to image denoising. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2862–2869. [Google Scholar]
- Xie, Y.; Gu, S.; Liu, Y.; Zuo, W.; Zhang, W.; Zhang, L. Weighted schatten p-norm minimization for image denoising and background subtraction. IEEE Trans. Image Process. 2016, 25, 4842–4857. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Wang, Q.; Jin, J.; Shen, Y. Structure tensor total variation-regularized weighted nuclear norm minimization for hyperspectral image mixed denoising. Signal Process. 2017, 131, 202–219. [Google Scholar] [CrossRef]
- Huang, Z.; Li, Q.; Fang, H.; Zhang, T.; Sang, N. Iterative weighted nuclear norm for X-ray cardiovascular angiogram image denoising. Signal Image Video Process. 2017, 11, 1445–1452. [Google Scholar] [CrossRef]
- Huang, T.; Dong, W.; Xie, X.; Shi, G.; Bai, X. Mixed Noise Removal via Laplacian Scale Mixture Modeling and Nonlocal Low-Rank Approximation. IEEE Trans. Image Process. 2017, 26, 3171–3186. [Google Scholar] [CrossRef] [PubMed]
- Yao, S.; Chang, Y.; Qin, X.; Zhang, Y.; Zhang, T. Principal component dictionary-based patch grouping for image denoising. J. Vis. Commun. Image Represent. 2018, 50, 111–122. [Google Scholar] [CrossRef]
- Chen, Y.; Pock, T. Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1256–1272. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning deep CNN denoiser prior for image restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2808–2817. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. FFDNet: Toward a fast and flexible solution for CNN-based image denoising. IEEE Trans. Image Process. 2018, 27, 4608–4622. [Google Scholar] [CrossRef] [PubMed]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. MemNet: A persistent memory network for image restoration. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4549–4557. [Google Scholar]
- Scetbon, M.; Elad, M.; Milanfar, P. Deep K-SVD Denoising. IEEE Trans. Image Process. 2021, 30, 5944–5955. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Yong, H.; Zhang, L. Deep convolutional dictionary learning for image denoising. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 630–641. [Google Scholar]
- Carfantan, H.; Idier, J. Statistical linear destriping of satellite-based pushbroom-type images. IEEE Trans. Geosci. Remote Sens. 2010, 48, 1860–1872. [Google Scholar] [CrossRef]
- Fehrenbach, J.; Weiss, P.; Lorenzo, C. Variational algorithms to remove stationary noise: Applications to microscopy imaging. IEEE Trans. Image Process. 2012, 21, 860–1871. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Lu, X.; Shen, H.; Yuan, Q.; Jiao, Y.; Zhang, L. Stripe noise separation and removal in remote sensing images by consideration of the global sparsity and local variational properties. IEEE Trans. Image Process. 2016, 54, 3049–3060. [Google Scholar] [CrossRef]
- Liu, X.; Lu, X.; Shen, H.; Yuan, Q.; Zhang, L. Oblique stripe removal in remote sensing images via oriented variation. arXiv 2018, arXiv:1809.02043. [Google Scholar]
- Chang, Y.; Yan, L.; Wu, T.; Zhong, S. Remote sensing image stripe noise removal: From image decomposition perspective. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7018–7031. [Google Scholar] [CrossRef]
- Chang, Y.; Yan, L.; Zhong, S. Transformed low-rank model for line pattern noise removal. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1726–1734. [Google Scholar]
- Chang, Y.; Yan, L.; Chen, B.; Zhong, S.; Tian, Y. Hyperspectral image restoration: Where does the low-rank property exist. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6869–6884. [Google Scholar] [CrossRef]
- Chen, Y.; Huang, T.-Z.; Zhao, X.L.; Deng, L.J.; Huang, J. Stripe noise removal of remote sensing images by total variation regularization and group sparsity constraint. Remote Sens. 2017, 9, 559. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Huang, T.-Z.; Deng, L.J.; Zhao, X.-L.; Wang, M. Group sparsity based regularization model for remote sensing image stripe noise removal. Neurocomputing 2017, 267, 95–106. [Google Scholar] [CrossRef]
- Cao, W.; Chang, Y.; Han, G.; Li, J. Destriping remote sensing image via low-rank approximation and nonlocal total variation. IEEE Geosci. Remote Sens. Lett. 2018, 15, 848–852. [Google Scholar] [CrossRef]
- Song, Q.; Wang, Y.; Yan, X.; Gu, H. Remote sensing images stripe noise removal by double sparse regulation and region separation. Remote Sens. 2018, 10, 998. [Google Scholar] [CrossRef]
- Dhivya, R.; Prakash, R. Stripe noise separation and removal in remote sensing images. J. Comput. Theor. Nanosci. 2018, 15, 2724–2728. [Google Scholar] [CrossRef]
- Cui, H.; Jia, P.; Zhang, G.; Jiang, Y.; Li, L.; Wang, J.; Hao, X. Multiscale intensity propagation to remove multiplicative stripe noise from remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2308–2323. [Google Scholar] [CrossRef]
- Kuang, X.; Sui, X.; Chen, Q.; Gu, G. Single infrared image stripe noise removal using deep convolutional networks. IEEE Photonics J. 2017, 9, 1–13. [Google Scholar] [CrossRef]
- Xiao, P.; Guo, Y.; Zhuang, P. Removing stripe noise from infrared cloud images via deep convolutional networks. IEEE Photonics J. 2018, 10, 1–14. [Google Scholar] [CrossRef]
- Zhong, Y.; Li, W.; Wang, X.; Jin, S.; Zhang, L. Satellite-ground intergraded destriping network: A new perspective for eo-1 hyperion and chinese hyperspectral satellite datasets. Remote Sens. Environ. 2020, 237, 111416. [Google Scholar] [CrossRef]
- Song, J.; Jeong, H.-H.; Park, D.-S.; Kim, H.-H.; Seo, D.-C.; Ye, J.C. Unsupervised denoising for satellite imagery using wavelet directional cyclegan. IEEE Trans. Geosci. Remote Sens. 2020, 59, 6823–6839. [Google Scholar] [CrossRef]
- Huang, Z.; Zhang, Y.; Li, Q.; Li, X.; Zhang, T.; Sang, N.; Hong, H. Joint analysis and weighted synthesis sparsity priors for simultaneous denoising and destriping optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6958–6982. [Google Scholar] [CrossRef]
- Chang, Y.; Yan, L.; Fang, H.; Liu, H. Simultaneous destriping and denoising for remote sensing images with unidirectional total variation and sparse representation. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1051–1055. [Google Scholar] [CrossRef]
- Xiong, F.; Zhou, J.; Qian, Y. Hyperspectral restoration via L0 gradient regularized low-rank tensor factorization. IEEE Geosci. Remote Sens. Lett. 2019, 57, 10410–10425. [Google Scholar] [CrossRef]
- Zheng, Y.; Huang, T.; Zhao, X.; Jiang, T.; Ma, T.; Ji, T. Mixed noise removal in hyperspectral image via low-fibered-rank regularization. IEEE Trans. Geosci. Remote Sens. 2020, 58, 734–749. [Google Scholar] [CrossRef]
- Liu, L.; Xu, L.; Fang, H. Simultaneous intensity bias estimation and stripe noise removal in infrared images using the global and local sparsity constraints. IEEE Trans. Geosci. Remote Sens. 2020, 58, 1777–1789. [Google Scholar] [CrossRef]
- Zeng, H.; Xie, X.; Cui, H.; Yin, H.; Ning, J. Hyperspectral image restoration via global L1−2 spatial-spectral total variation regularized local low-rank tensor recovery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 3309–3325. [Google Scholar] [CrossRef]
- Xie, T.; Li, S.; Sun, B. Hyperspectral images denoising via nonconvex regularized low-rank and sparse matrix decomposition. IEEE Trans. Image Process. 2020, 29, 44–56. [Google Scholar] [CrossRef]
- Hu, T.; Li, W.; Liu, N.; Tao, R.; Zhang, F.; Scheunders, P. Hyperspectral image restoration using adaptive anisotropy total variation and nuclear norms. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1516–1533. [Google Scholar] [CrossRef]
- Wang, M.; Wang, Q.; Chanussot, J.; Hong, D. l0 − l1 Hybrid total variation regularization and its applications on hyperspectral image mixed noise removal and compressed sensing. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7695–7710. [Google Scholar] [CrossRef]
- Wang, S.; Zhu, Z.; Zhao, R.; Zhang, B. Hyperspectral image denoising via nonconvex logarithmic penalty. Math. Probl. Eng. 2021, 2021, 5535169. [Google Scholar] [CrossRef]
- Dong, W.; Zuo, W.; Zhang, D.; Zhang, L.; Yang, M.H. Simultaneous fidelity and regularization learning for image restoration. arXiv 2019, arXiv:1804.04522v4. [Google Scholar]
- Dong, W.; Wang, P.; Yin, W.; Shi, G.; Wu, F.; Lu, X. Denoising prior driven deep neural network for image restoration. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2019, 41, 2305–2318. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Li, Y.; Zuo, W.; Zhang, L.; Timofte, R. Plug-and-play image restoration with deep denoiser prior. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2021, 44, 6360–6376. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Zhang, Y.; Li, Q.; Li, Z.; Zhang, T.; Sang, N.; Xiong, S. Unidirectional variation and deep CNN denoiser priors for simultaneously destriping and denoising optical remote sensing images. Int. J. Remote Sens. 2019, 40, 5737–5748. [Google Scholar] [CrossRef]
- Zeng, H.; Xie, X.; Cui, H.; Yin, H.; Zhao, Y.; Ning, J. Hyperspectral image restoration via CNN denoiser prior regularized low-rank tensor recovery. Comput. Vis. Image Unders. 2020, 197–198, 103004. [Google Scholar] [CrossRef]
- He, Z.; Cao, Y.; Dong, Y.; Yang, J.; Cao, Y.; Tisse, C.-L. Single-image-based non-uniformity correction of uncooled long-wave infrared detectors: A deep-learning approach. Appl. Opt. 2018, 57, D155–D164. [Google Scholar] [CrossRef] [PubMed]
- Chang, Y.; Yan, L.; Fang, H.; Zhong, S.; Liao, W. HSI-DeNet: Hyperspectral image restoration via convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 57, 667–682. [Google Scholar] [CrossRef]
- Zhang, Q.; Yuan, Q.; Li, J.; Liu, X.; Shen, H.; Zhang, L. Hybrid noise removal in hyperspectral imagery with a spatial-spectral gradient network. IEEE Trans. Geos. Remote Sens. 2019, 57, 7317–7329. [Google Scholar] [CrossRef]
- Luo, Y.; Zhao, X.; Jiang, T.; Zheng, Y.; Chang, Y. Unsupervised hyperspectral mixed noise removal via spatial-spectral constrained deep image prior. arXiv 2021, arXiv:2008.09753. [Google Scholar] [CrossRef]
- Liu, H.; Fang, S.; Zhang, Z.; Li, D.; Lin, K.; Wang, J. MFDNet: Collaborative poses perception and matrix fisher distribution for head pose estimation. IEEE Trans. Multimed. 2021, 24, 2449–2460. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhang, Y.; Yuan, L.; Wang, Y.; Zhang, J. SAU-Net: Efficient 3D spine MRI segmentation using inter-slice attention. Proc. Mach. Learn. Res. 2020, 121, 903–913. [Google Scholar]
- Yong, H.; Huang, J.; Meng, D.; Hua, X.; Zhang, L. Momentum batch normalization for deep learning with small batch size. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 224–240. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vedaldi, A.; Lenc, K. MatConvNet: Convolutional neural networks for matlab. In Proceedings of the 23rd ACM Conference on Multimedia Conference, Brisbane, Australia, 26–30 October 2015; pp. 689–692. [Google Scholar]
- MODIS Data. Available online: https://modis.gsfc.nasa.gov/data/ (accessed on 30 January 2018).
- A Freeware Multispectral Image Data Analysis System. Available online: https://engineering.purdue.edu/~biehl/MultiSpec/hyperspectral.html (accessed on 30 January 2018).
- Gloabal Digital Product Sample. Available online: http://www.digitalglobe.com/product-samples (accessed on 30 January 2018).
- Tsuruoka, Y.; Tsujii, J.; Ananiadou, S. Stochastic gradient descent training for L1-regularized log-linear models with cumulative penalty. In Proceedings of the ACL 2009 the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; pp. 477–485. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Nichol, J.E.; Vohora, V. Noise over water surfaces in Landsat TM images. Int. J. Remote Sens. 2010, 25, 2087–2093. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a ‘completely blind’ image quality analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | STM1 | STM2 | STM3 | |||||||||
| UTVSR | 28.14 | 26.86 | 25.9 | 25.22 | 29.96 | 28.83 | 27.58 | 27.1 | 33.12 | 32.04 | 31.05 | 30.25 |
| WNNM-WDSUV | 28.82 | 27.52 | 26.62 | 25.94 | 30.91 | 29.63 | 28.75 | 28.09 | 34.55 | 33.42 | 32.61 | 31.98 |
| HSI-DeNet | 29.02 | 27.71 | 26.77 | 26.04 | 31.02 | 29.72 | 28.78 | 28.1 | 34.71 | 33.56 | 32.72 | 32.08 |
| UV-DCNN | 29.05 | 27.77 | 26.89 | 26.24 | 31.13 | 29.87 | 29 | 28.34 | 34.78 | 33.6 | 32.84 | 32.11 |
| JAWS | 29.24 | 27.86 | 26.93 | 26.25 | 31.21 | 29.93 | 29.03 | 28.36 | 34.86 | 33.71 | 32.93 | 32.28 |
| Proposed | 29.68 | 28.15 | 27.46 | 26.76 | 31.59 | 30.47 | 29.73 | 28.69 | 35.18 | 34.06 | 33.38 | 32.79 |
| Methods | SAM1 | SAM2 | SAM3 | |||||||||
| UTVSR | 28.67 | 27.14 | 25.98 | 25.21 | 28.46 | 27.13 | 26.02 | 25.29 | 28.12 | 26.92 | 26.11 | 25.27 |
| WNNM-WDSUV | 29.31 | 27.75 | 26.62 | 25.74 | 29.25 | 27.81 | 26.84 | 26.09 | 29.01 | 27.74 | 26.88 | 26.25 |
| HSI-DeNet | 29.24 | 27.77 | 26.68 | 25.82 | 29.36 | 27.98 | 26.95 | 26.14 | 29.17 | 27.88 | 26.98 | 26.29 |
| UV-DCNN | 29.47 | 28.01 | 26.89 | 26 | 29.45 | 28.11 | 27.14 | 26.4 | 29.31 | 27.97 | 27.13 | 26.5 |
| JAWS | 29.52 | 27.99 | 26.82 | 25.97 | 29.58 | 28.18 | 27.2 | 26.44 | 29.32 | 28.05 | 27.17 | 26.52 |
| Proposed | 29.75 | 28.64 | 27.33 | 26.47 | 30.02 | 28.83 | 27.91 | 27.08 | 29.84 | 28.68 | 27.79 | 27.01 |
| Methods | SWDCM | SWDCM | ||||||||||
| UTVSR | 28.53 | 27 | 25.68 | 24.8 | 31.03 | 29.71 | 28.85 | 28.33 | ||||
| WNNM-WDSUV | 29.44 | 27.76 | 26.51 | 25.53 | 32.41 | 30.96 | 29.87 | 29.03 | ||||
| HSI-DeNet | 29.5 | 27.91 | 26.72 | 25.75 | 32.61 | 31.2 | 30.06 | 29.16 | ||||
| UV-DCNN | 29.52 | 27.87 | 26.57 | 25.69 | 32.69 | 31.27 | 30.26 | 29.27 | ||||
| JAWS | 29.62 | 28.02 | 26.77 | 25.84 | 32.83 | 31.41 | 30.33 | 29.48 | ||||
| Proposed | 29.84 | 28.33 | 27.06 | 26.37 | 33.17 | 31.76 | 30.8 | 29.97 | ||||
| Methods | STM1 | STM2 | STM3 | |||||||||
| UTVSR | 0.7872 | 0.7251 | 0.6626 | 0.6205 | 0.815 | 0.7592 | 0.7118 | 0.6825 | 0.8766 | 0.8587 | 0.8482 | 0.8342 |
| WNNM-WDSUV | 0.8196 | 0.7748 | 0.7209 | 0.6842 | 0.8237 | 0.7734 | 0.7476 | 0.7149 | 0.8821 | 0.872 | 0.8567 | 0.8413 |
| HSI-DeNet | 0.8216 | 0.7843 | 0.7257 | 0.6861 | 0.832 | 0.7771 | 0.7471 | 0.7157 | 0.8826 | 0.8715 | 0.8559 | 0.8424 |
| UV-DCNN | 0.8466 | 0.7944 | 0.7318 | 0.6898 | 0.8433 | 0.782 | 0.7482 | 0.7179 | 0.8895 | 0.8728 | 0.8577 | 0.8426 |
| JAWS | 0.8472 | 0.8003 | 0.7356 | 0.6917 | 0.8482 | 0.7867 | 0.7488 | 0.7187 | 0.8919 | 0.8724 | 0.8585 | 0.8462 |
| Proposed | 0.8518 | 0.8126 | 0.7415 | 0.7172 | 0.8527 | 0.8037 | 0.7524 | 0.7318 | 0.9011 | 0.8829 | 0.8617 | 0.8534 |
| Methods | SAM1 | SAM2 | SAM3 | |||||||||
| UTVSR | 0.8908 | 0.8524 | 0.8216 | 0.7913 | 0.805 | 0.7249 | 0.6452 | 0.5886 | 0.748 | 0.6772 | 0.5981 | 0.5562 |
| WNNM-WDSUV | 0.8998 | 0.8662 | 0.8312 | 0.806 | 0.8127 | 0.7615 | 0.7094 | 0.6753 | 0.7846 | 0.7179 | 0.6661 | 0.6229 |
| HSI-DeNet | 0.905 | 0.8646 | 0.8335 | 0.8054 | 0.8225 | 0.7648 | 0.7137 | 0.6783 | 0.7763 | 0.7178 | 0.6673 | 0.6243 |
| UV-DCNN | 0.8996 | 0.8676 | 0.8309 | 0.8096 | 0.8266 | 0.7737 | 0.7168 | 0.6802 | 0.794 | 0.7196 | 0.6718 | 0.6277 |
| JAWS | 0.9064 | 0.8698 | 0.8334 | 0.8073 | 0.8272 | 0.7755 | 0.7155 | 0.6793 | 0.7992 | 0.7192 | 0.6728 | 0.6283 |
| Proposed | 0.9172 | 0.8813 | 0.8594 | 0.8216 | 0.8353 | 0.7962 | 0.7367 | 0.7015 | 0.8127 | 0.7533 | 0.7119 | 0.6527 |
| Methods | SWDCM | SWDCM | ||||||||||
| UTVSR | 0.8912 | 0.8241 | 0.7802 | 0.7384 | 0.861 | 0.8287 | 0.7807 | 0.7477 | ||||
| WNNM-WDSUV | 0.8937 | 0.8486 | 0.8094 | 0.7808 | 0.8645 | 0.83 | 0.7971 | 0.7725 | ||||
| HSI-DeNet | 0.9003 | 0.8525 | 0.8123 | 0.7832 | 0.8619 | 0.8319 | 0.7976 | 0.7743 | ||||
| UV-DCNN | 0.8978 | 0.8539 | 0.8139 | 0.7858 | 0.8651 | 0.8468 | 0.8066 | 0.7805 | ||||
| JAWS | 0.9014 | 0.8549 | 0.8145 | 0.7833 | 0.8647 | 0.8476 | 0.8079 | 0.7817 | ||||
| Proposed | 0.9153 | 0.8792 | 0.8386 | 0.8124 | 0.8878 | 0.8629 | 0.8237 | 0.8019 | ||||
| Image Size | Methods | |||||
|---|---|---|---|---|---|---|
| UTVSR | WNNM-WDSUV | HSI-DeNet | UV-DCNN | JAWS | Proposed | |
| 653.923 | 108.714 | 1.048/0.016 | 1.077/0.035 | 874.675 | 1.068/0.024 | |
| 2674.641 | 440.283 | 5.869/0.027 | 7.953/0.142 | 2937.424 | 6.667/0.073 | |
| Indexes | Methods | RAM1 | RAM2 | RAM3 | RTM1 | RTM2 | RTM3 | Urban |
|---|---|---|---|---|---|---|---|---|
| QM | UTVSR | 25.18 | 32.37 | 11.82 | 12.57 | 12.83 | 23.78 | 27.58. |
| WNNM-WDSUV | 25.47 | 32.69 | 12.24 | 13.08 | 13.26 | 24.33 | 28.81 | |
| HSI-DeNet | 26.39 | 33.97 | 12.89 | 13.67 | 13.81 | 24.85 | 30.49 | |
| UV-DCNN | 26.62 | 34.57 | 13.48 | 14.13 | 14.37 | 25.61 | 31.14 | |
| JAWS | 26.79 | 34.78 | 14.17 | 14.52 | 14.88 | 25.94 | 31.63 | |
| Proposed | 27.11 | 35.27 | 14.72 | 15.18 | 15.49 | 26.37 | 32.16 | |
| MICV | UTVSR | 35.72 | 33.26 | 38.19 | 37.54 | 36.47 | 36.79 | 29.46 |
| WNNM-WDSUV | 35.91 | 33.67 | 38.42 | 37.76 | 36.65 | 36.92 | 29.58 | |
| HSI-DeNet | 36.15 | 33.83 | 38.79 | 37.93 | 36.89 | 37.27 | 29.84 | |
| UV-DCNN | 36.29 | 34.08 | 38.94 | 38.17 | 37.09 | 37.55 | 30.09 | |
| JAWS | 36.67 | 34.41 | 39.18 | 38.54 | 37.51 | 37.86 | 30.57 | |
| Proposed | 36.86 | 34.74 | 39.49 | 38.82 | 37.74 | 38.28 | 31.07 | |
| MMRD | UTVSR | 0.45 | 0.67 | 0.051 | 0.058 | 0.062 | 0.36 | 0.57 |
| WNNM-WDSUV | 0.39 | 0.52 | 0.046 | 0.051 | 0.055 | 0.32 | 0.53 | |
| HSI-DeNet | 0.37 | 0.049 | 0.041 | 0.047 | 0.048 | 0.29 | 0.48 | |
| UV-DCNN | 0.33 | 0.041 | 0.037 | 0.042 | 0.043 | 0.27 | 0.44 | |
| JAWS | 0.29 | 0.036 | 0.031 | 0.036 | 0.038 | 0.22 | 0.35 | |
| Proposed | 0.21 | 0.026 | 0.022 | 0.027 | 0.029 | 0.19 | 0.27 | |
| NIQE | UTVSR | 7.03 | 7.37 | 4.18 | 4.22 | 4.26 | 6.73 | 7.19 |
| WNNM-WDSUV | 6.94 | 7.18 | 4.05 | 4.11 | 4.17 | 6.67 | 7.07 | |
| HSI-DeNet | 6.81 | 7.06 | 3.94 | 4.08 | 4.09 | 6.51 | 6.91 | |
| UV-DCNN | 6.67 | 6.84 | 3.78 | 3.83 | 3.85 | 6.17 | 6.39 | |
| JAWS | 6.46 | 6.61 | 3.62 | 3.67 | 3.71 | 5.95 | 6.08 | |
| Proposed | 6.23 | 6.33 | 3.28 | 3.36 | 3.39 | 5.28 | 5.62 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Zhu, Z.; Wang, Z.; Li, X.; Xu, B.; Zhang, Y.; Fang, H. D3CNNs: Dual Denoiser Driven Convolutional Neural Networks for Mixed Noise Removal in Remotely Sensed Images. Remote Sens. 2023, 15, 443. https://doi.org/10.3390/rs15020443
Huang Z, Zhu Z, Wang Z, Li X, Xu B, Zhang Y, Fang H. D3CNNs: Dual Denoiser Driven Convolutional Neural Networks for Mixed Noise Removal in Remotely Sensed Images. Remote Sensing. 2023; 15(2):443. https://doi.org/10.3390/rs15020443
Chicago/Turabian StyleHuang, Zhenghua, Zifan Zhu, Zhicheng Wang, Xi Li, Biyun Xu, Yaozong Zhang, and Hao Fang. 2023. "D3CNNs: Dual Denoiser Driven Convolutional Neural Networks for Mixed Noise Removal in Remotely Sensed Images" Remote Sensing 15, no. 2: 443. https://doi.org/10.3390/rs15020443
APA StyleHuang, Z., Zhu, Z., Wang, Z., Li, X., Xu, B., Zhang, Y., & Fang, H. (2023). D3CNNs: Dual Denoiser Driven Convolutional Neural Networks for Mixed Noise Removal in Remotely Sensed Images. Remote Sensing, 15(2), 443. https://doi.org/10.3390/rs15020443