



Deep Learning Methods for Semantic Segmentation in Remote Sensing with Small Data: A Survey

 , ,
, ,
Abstract
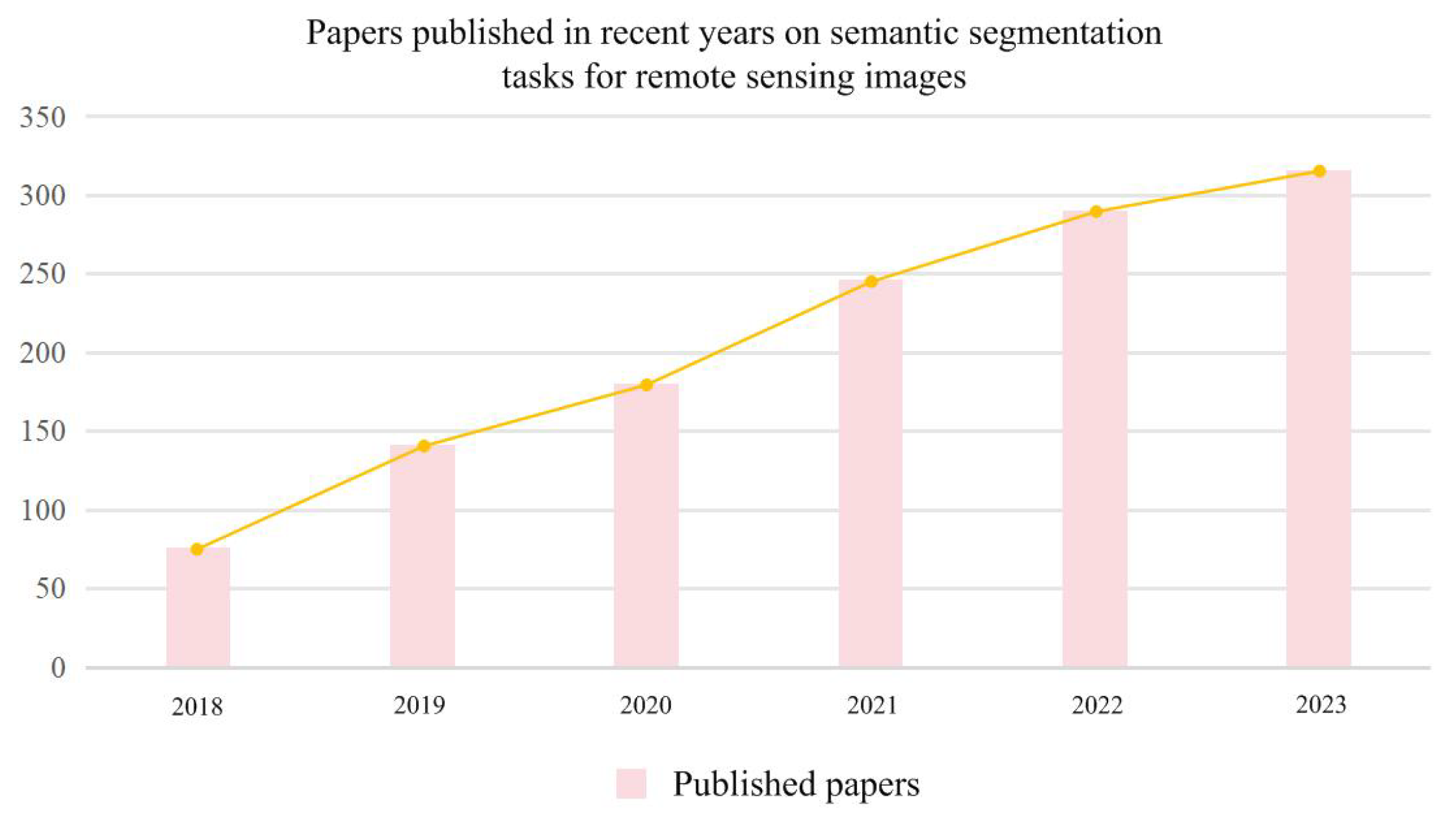
:1. Introduction
- (1)
- Self-supervised learning obtains features from the unlabeled samples themselves. The commonly used contrastive learning methods and masking image modeling (MIM) methods have achieved great results in relation to semantic segmentation tasks based on RSI.
- (2)
- (3)
- Weakly supervised learning is considered a suitable method to ease issues related to insufficient labeled samples, as it simplifies the labeled data. The pixel-level semantic segmentation task is accomplished by using point annotation, random-walk annotation or graffiti-based annotation, bounding boxes annotation, image-level annotation, and noisy labels.
- (4)
- Domain adaptation methods have been proposed to improve the generalization ability of the models. However, the style, category, and resolution of the RSIs of the feature targets differ remarkably between the source and target domains. The methods commonly used to solve these problems can be roughly categorized into discrepancy-based, adversarial-based, and pseudo label-based strategies.
- (5)
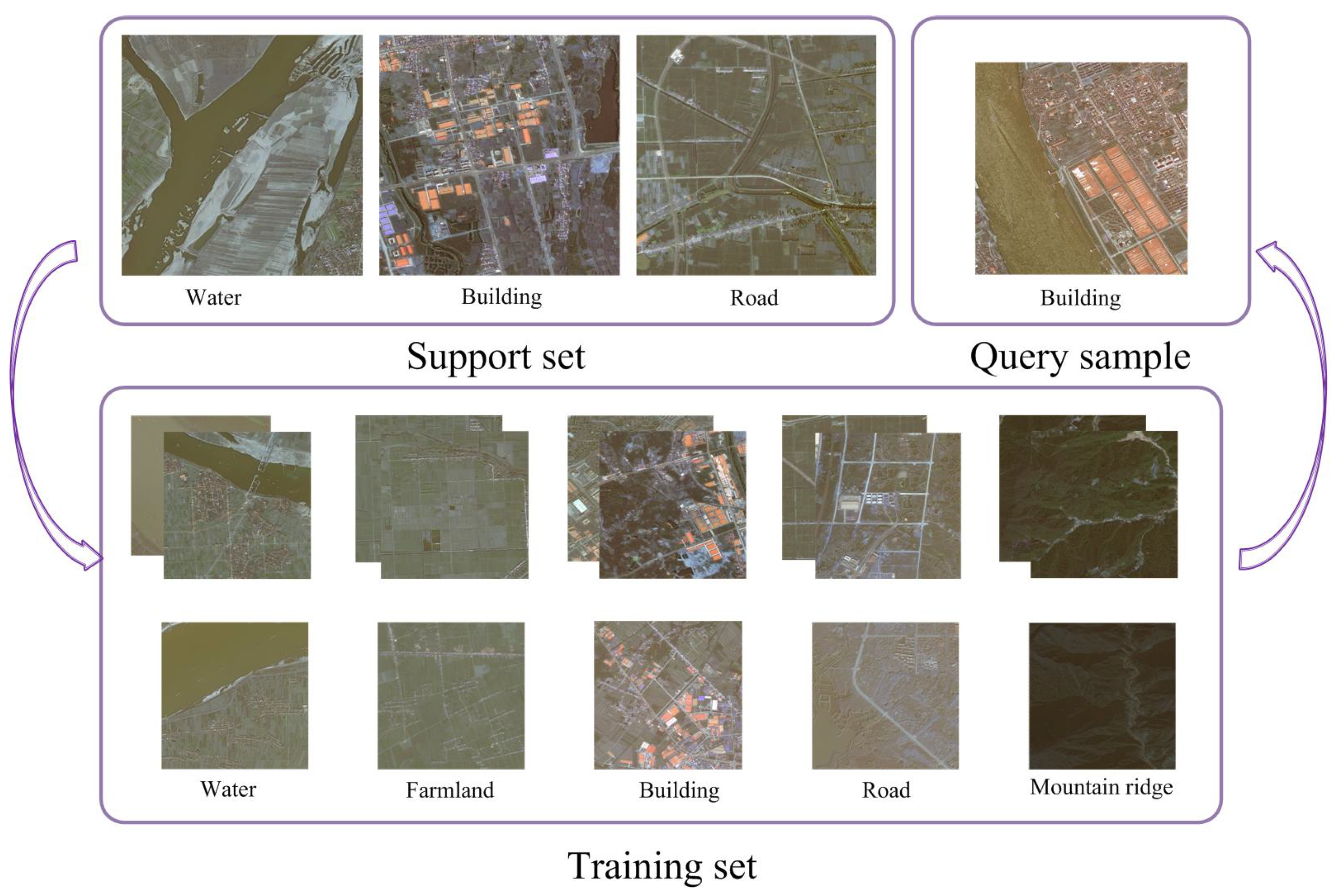
- The few-shot method uses only a small amount of data and learns their features. For example, representative features are learned to accomplish the semantic segmentation task using meta-learning methods. Alternatively, data-augmentation strategies are also frequently used in few-shot learning.
- (1)
- We specifically focus on RSIs to summarize the deep learning methods that are used to accomplish semantic segmentation.
- (2)
- This survey comprehensively studies the application of deep learning methods in the semantic segmentation of RSI, including self-supervised learning, semi-supervised learning, weakly supervised learning, cross-domain methodologies, and few-shot learning methods.
- (3)
- The foundation approaches in the supervised learning methods with small data and the currently popular methods that have recently been proposed are also described.
- (4)
- The crucial issues in the field of deep learning, including multi-modal fusion methods and prior-knowledge-constrained approaches, are summarized.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2. Supervised Learning Methods for RSI Semantic Segmentation
2.1. Single-Modal Methods
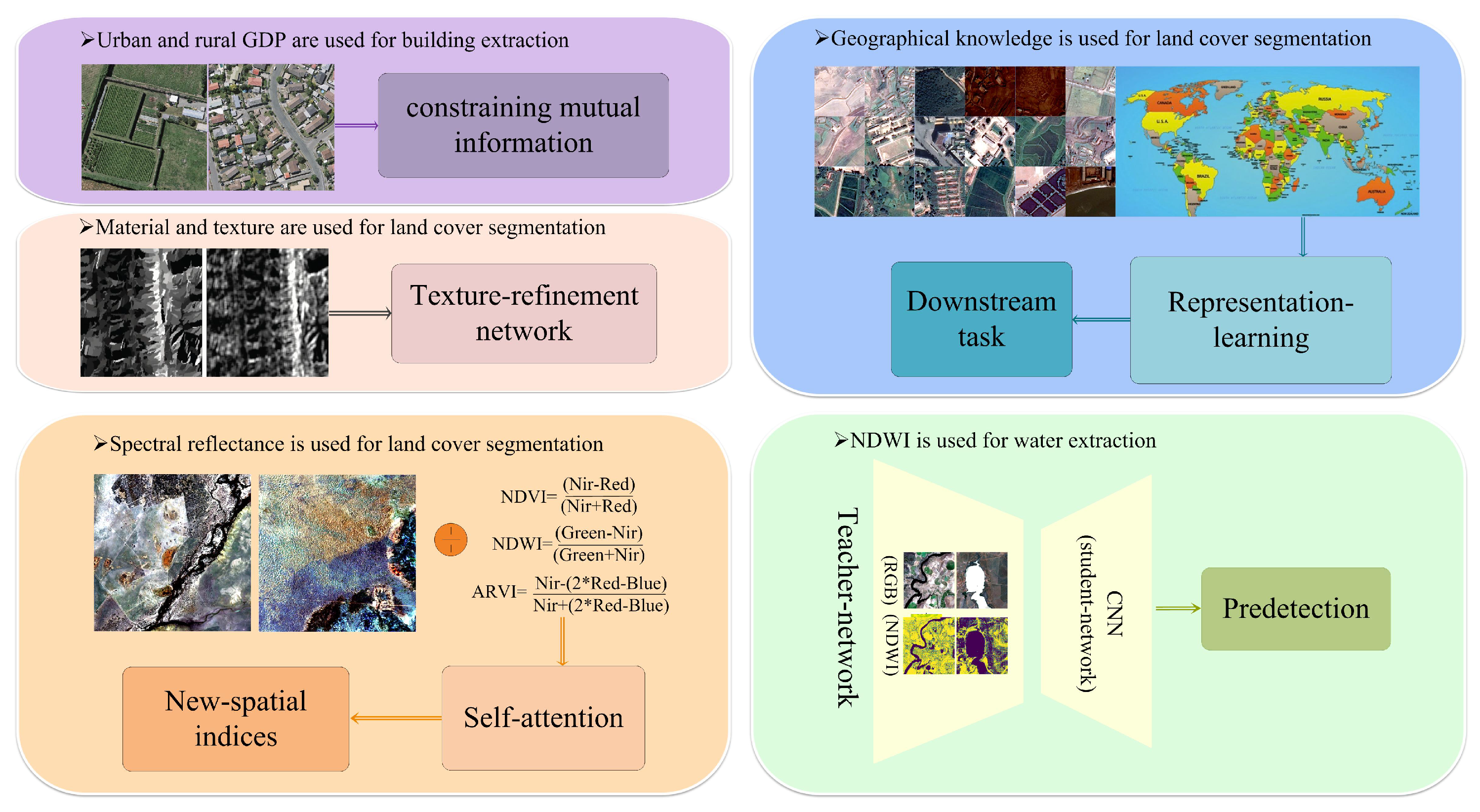
2.2. Multi-Modal Fusion Methods
2.3. Prior-Knowledge-Constrained Methods
3. Self-Supervised Learning Methods for RSI Semantic Segmentation
3.1. Commonly Used Self-Supervised Learning Models for Semantic Segmentation
3.1.1. Contrastive Learning Method
Popular Contrastive Learning Models for Semantic Segmentation
Contrastive Learning Method based on RSIs for Semantic Segmentation
- The background is rich and complex: High-spatial-resolution RSIs have different imaging conditions, seasonal variations, topographic variations, ground reflectance, imaging angles, lighting conditions, geographical locations, time stamps, and sensors. These factors mean that RSIs are data-rich [114].
- Global and local features are important: Overall differences occur in RSIs due to factors such as season, weather, and the sensor used. Consequently, it is important to focus on their global characteristics. To achieve pixel-level semantic segmentation of RSIs, it is necessary to obtain the local features [115].
- Spatial location information is important: RSIs have multiple objects, and the spatial location information between different objects is the most important for semantic segmentation tasks [116].
- Multi-modal data are required: RSIs acquired by different satellite- and aerial-imaging platforms have different resolutions, spectral bands, and revisitation rates. However, current remote sensing applications only use a fraction of the available multi-sensor, multi-channel RSIs. The methods using fused RSIs obtained by multi-sensor arrays have attracted large amounts of attention [117,118].
3.1.2. Masked Image Modeling Method
Popular Masked Image Modeling Method for Semantic Segmentation
Masked Image Modeling Method Based on RSIs for Semantic Segmentation
3.2. Self-Supervised Methods with Prior Knowledge Constraint
4. Semi-Supervised Learning Methods for RSI Semantic Segmentation

Popular Semi-Supervised Learning Models for Semantic Segmentation
Semi-Supervised Learning Models Based on RSIs for Semantic Segmentation
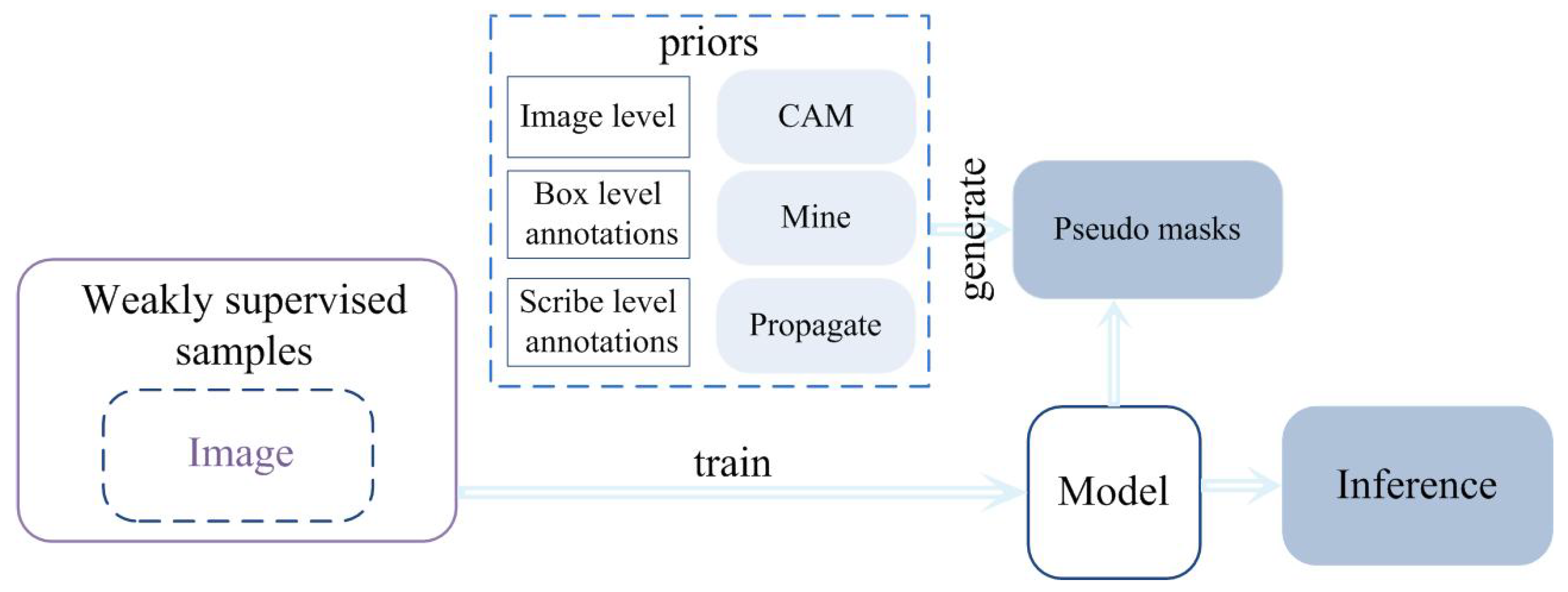
5. Weakly Supervised Learning Methods for RSI Semantic Segmentation
5.1. Weakly Supervised Learning Models
- Point annotation;
- Graffiti-based or random-walk annotation;
- Bounding boxes annotation;
- Image-level annotation.

5.1.1. Point Annotation
5.1.2. Graffiti-Based or Random-Walk Annotation
5.1.3. Bounding Box Annotation
5.1.4. Image-Level Annotation
5.2. Weakly Supervised Learning Methods with Prior Knowledge Constraint
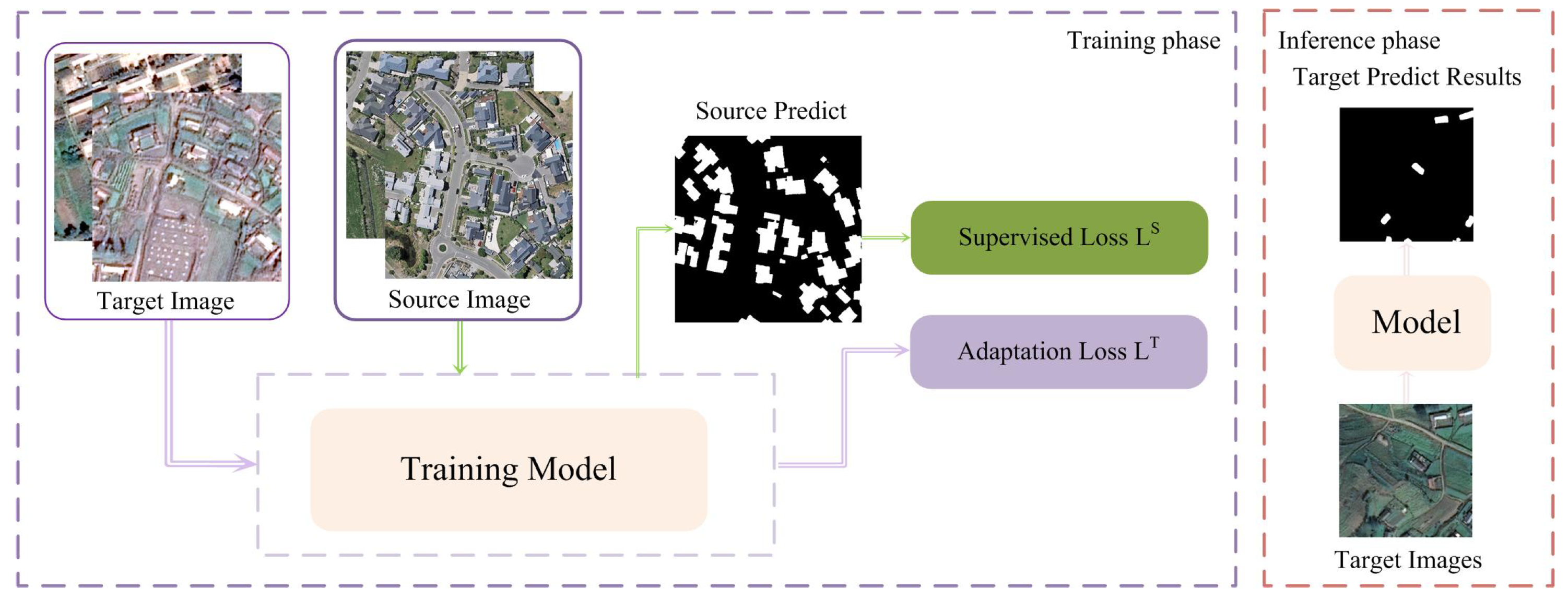
6. Domain Adaptation Methods for RSI Semantic Segmentation
- Discrepancy-based;
- Adversarial-based;
- Pseudo label-based.

6.1. Discrepancy-Based
6.2. Adversarial-Based
6.3. Pseudo Label-Based
7. Few-Shot Learning Methods for RSI Semantic Segmentation Methods
7.1. Data Augmentation Method
7.2. Prior-Knowledge-Based Models
- Metric learning: Metric learning is the method of learning the distance function of the data samples. Assuming two input samples (,) and (,), the distance between the two samples is solved using the distance function. Labels are assigned to the query image , and the distance between (,) and (,) can be computed [237].
7.2.1. Transfer Learning
7.2.2. Metric Learning
7.3. Meta Learning
7.4. Other Few-Shot Learning Methods
8. Outlook for The Future
8.1. Foundation Models
8.2. Cross-Domain Learning
8.3. Data Augmentation
8.4. World Model
9. Conclusions and Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote. Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Chen, K.; Liu, C.; Chen, H.; Zhang, H.; Li, W.; Zou, Z.; Shi, Z. RSPrompter: Learning to Prompt for Remote Sensing Instance Segmentation based on Visual Foundation Model. arXiv 2023, arXiv:2306.16269. [Google Scholar]
- Akiva, P.; Purri, M.; Leotta, M. Self-Supervised Material and Texture Representation Learning for Remote Sensing Tasks. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8193–8205. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network In Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2017, arXiv:1612.03144. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. arXiv 2017, arXiv:1612.01105. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. arXiv 2016, arXiv:1511.00561. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2018, arXiv:1608.06993. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding. arXiv 2018, arXiv:1807.10221. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.P.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. arXiv 2017, arXiv:1606.00915. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 833–851. [Google Scholar]
- Wu, G.; Guo, Z.; Shao, X.; Shibasaki, R. GEOSEG: A computer vision package for automatic building segmentation and outline extraction. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 158–161. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. arXiv 2019, arXiv:cs.CV/1902.09212. [Google Scholar]
- Zhu, Q.; Liao, C.; Hu, H.; Mei, X.; Li, H. MAP-Net: Multiple Attending Path Neural Network for Building Footprint Extraction From Remote Sensed Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6169–6181. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2020, arXiv:1905.11946. [Google Scholar]
- Zheng, Z.; Zhong, Y.; Wang, J.; Ma, A. Foreground-Aware Relation Network for Geospatial Object Segmentation in High Spatial Resolution Remote Sensing Imagery. arXiv 2020, arXiv:2011.09766. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Mehta, S.; Rastegari, M. MobileViT: Light-Weight, General-Purpose, and Mobile-Friendly Vision Transformer. arXiv 2022, arXiv:2110.02178. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. arXiv 2022, arXiv:2201.03545. [Google Scholar]
- Guo, M.H.; Lu, C.Z.; Liu, Z.N.; Cheng, M.M.; Hu, S.M. Visual Attention Network. arXiv 2022, arXiv:2202.09741. [Google Scholar] [CrossRef]
- Tao, C.; Qia, J.; Zhang, G.; Zhu, Q.; Lu, W.; Li, H. TOV: The Original Vision Model for Optical Remote Sensing Image Understanding via Self-Supervised Learning. arXiv 2022, arXiv:2204.04716. [Google Scholar] [CrossRef]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. arXiv 2017, arXiv:1707.02968. [Google Scholar]
- He, K.; Girshick, R.; Dollár, P. Rethinking ImageNet Pre-Training. arXiv 2018, arXiv:1811.08883. [Google Scholar]
- Shao, J.; Chen, S.; Li, Y.; Wang, K.; Yin, Z.; He, Y.; Teng, J.; Sun, Q.; Gao, M.; Liu, J.; et al. INTERN: A New Learning Paradigm Towards General Vision. arXiv 2022, arXiv:2111.08687. [Google Scholar]
- Wang, Y.; Wang, H.; Shen, Y.; Fei, J.; Li, W.; Jin, G.; Wu, L.; Zhao, R.; Le, X. Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 4238–4247. [Google Scholar] [CrossRef]
- Ahfock, D.; McLachlan, G.J. Semi-supervised learning of classifiers from a statistical perspective: A brief review. Econom. Stat. 2023, 26, 124–138. [Google Scholar] [CrossRef]
- Tao, C.; Qi, J.; Guo, M.; Zhu, Q.; Li, H. Self-Supervised Remote Sensing Feature Learning: Learning Paradigms, Challenges, and Future Works. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–26. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-Supervised Visual Feature Learning With Deep Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4037–4058. [Google Scholar] [CrossRef]
- Wang, Y.; Albrecht, C.M.; Braham, N.A.A.; Mou, L.; Zhu, X.X. Self-Supervised Learning in Remote Sensing: A review. IEEE Geosci. Remote Sens. Mag. 2022, 10, 213–247. [Google Scholar] [CrossRef]
- Ericsson, L.; Gouk, H.; Loy, C.C.; Hospedales, T.M. Self-Supervised Representation Learning: Introduction, advances, and challenges. IEEE Signal Process. Mag. 2022, 39, 42–62. [Google Scholar] [CrossRef]
- Sun, X.; Wang, B.; Wang, Z.; Li, H.; Li, H.; Fu, K. Research Progress on Few-Shot Learning for Remote Sensing Image Interpretation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2387–2402. [Google Scholar] [CrossRef]
- Märtens, M.; Izzo, D.; Krzic, A.; Cox, D. Super-resolution of PROBA-V images using convolutional neural networks. Astrodynamics 2019, 3, 387–402. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Li, X.; Zhang, G.; Cui, H.; Hou, S.; Wang, S.; Li, X.; Chen, Y.; Li, Z.; Zhang, L. MCANet: A joint semantic segmentation framework of optical and SAR images for land use classification. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102638. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Dai, D.; Yang, W. Satellite Image Classification via Two-Layer Sparse Coding With Biased Image Representation. IEEE Geosci. Remote Sens. Lett. 2011, 8, 173–176. [Google Scholar] [CrossRef]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep Learning Based Feature Selection for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Zhao, B.; Zhong, Y.; Xia, G.S.; Zhang, L. Dirichlet-derived multiple topic scene classification model for high spatial resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2015, 54, 2108–2123. [Google Scholar] [CrossRef]
- Basu, S.; Ganguly, S.; Mukhopadhyay, S.; DiBiano, R.; Karki, M.; Nemani, R. Deepsat: A learning framework for satellite imagery. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2015; pp. 1–10. [Google Scholar]
- Waqas Zamir, S.; Arora, A.; Gupta, A.; Khan, S.; Sun, G.; Shahbaz Khan, F.; Zhu, F.; Shao, L.; Xia, G.S.; Bai, X. isaid: A large-scale dataset for instance segmentation in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 28–37. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3213–3223. [Google Scholar]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate object localization in remote sensing images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Tong, X.; Xia, G.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Learning transferable deep models for land-use classification with high-resolution remote sensing images. arXiv 2018, arXiv:1807.05713. [Google Scholar]
- Mohajerani, S.; Krammer, T.A.; Saeedi, P. A Cloud Detection Algorithm for Remote Sensing Images Using Fully Convolutional Neural Networks. In Proceedings of the 2018 IEEE 20th International Workshop on Multimedia Signal Processing (MMSP), Vancouver, BC, Canada, 29–31 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Nigam, I.; Huang, C.; Ramanan, D. Ensemble knowledge transfer for semantic segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1499–1508. [Google Scholar]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1155–1167. [Google Scholar] [CrossRef]
- Li, H.; Jiang, H.; Gu, X.; Peng, J.; Li, W.; Hong, L.; Tao, C. CLRS: Continual Learning Benchmark for Remote Sensing Image Scene Classification. Sensors 2020, 20, 1226. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Y.; Zhu, Q.; Zhang, L. Scene classification based on the multifeature fusion probabilistic topic model for high spatial resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6207–6222. [Google Scholar] [CrossRef]
- Li, H.; Dou, X.; Tao, C.; Wu, Z.; Chen, J.; Peng, J.; Deng, M.; Zhao, L. RSI-CB: A Large-Scale Remote Sensing Image Classification Benchmark Using Crowdsourced Data. Sensors 2020, 20, 1594. [Google Scholar] [CrossRef] [PubMed]
- Penatti, O.A.; Nogueira, K.; Dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 44–51. [Google Scholar]
- Tasar, O.; Happy, S.L.; Tarabalka, Y.; Alliez, P. ColorMapGAN: Unsupervised Domain Adaptation for Semantic Segmentation Using Color Mapping Generative Adversarial Networks. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7178–7193. [Google Scholar] [CrossRef]
- Wrenninge, M.; Unger, J. Synscapes: A Photorealistic Synthetic Dataset for Street Scene Parsing. arXiv 2018, arXiv:1810.08705. [Google Scholar]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. PatternNet: A benchmark dataset for performance evaluation of remote sensing image retrieval. ISPRS J. Photogramm. Remote Sens. 2018, 145, 197–209. [Google Scholar] [CrossRef]
- Brown, C.F.; Brumby, S.P.; Guzder-Williams, B.; Birch, T.; Hyde, S.B.; Mazzariello, J.; Czerwinski, W.; Pasquarella, V.J.; Haertel, R.; Ilyushchenko, S.; et al. Dynamic World, Near real-time global 10 m land use land cover mapping. Sci. Data 2022, 9, 251. [Google Scholar] [CrossRef]
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation. arXiv 2022, arXiv:2110.08733. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–17209. [Google Scholar] [CrossRef]
- Volpi, M.; Ferrari, V. Semantic segmentation of urban scenes by learning local class interactions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Zhang, M.; Hu, X.; Zhao, L.; Lv, Y.; Luo, M.; Pang, S. Learning dual multi-scale manifold ranking for semantic segmentation of high-resolution images. Remote Sens. 2017, 9, 500. [Google Scholar] [CrossRef]
- Kemker, R.; Salvaggio, C.; Kanan, C. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J. Photogramm. Remote. Sens. 2018, 145, 60–77. [Google Scholar] [CrossRef]
- Schmitt, M.; Hughes, L.H.; Qiu, C.; Zhu, X.X. SEN12MS—A Curated Dataset of Georeferenced Multi-Spectral Sentinel-1/2 Imagery for Deep Learning and Data Fusion. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, IV-2/W7, 153–160. [Google Scholar] [CrossRef]
- Wu, X.; Shi, Z.; Zou, Z. A geographic information-driven method and a new large scale dataset for remote sensing cloud/snow detection. ISPRS J. Photogramm. Remote Sens. 2021, 174, 87–104. [Google Scholar] [CrossRef]
- Sumbul, G.; Charfuelan, M.; Demir, B.; Markl, V. Bigearthnet: A large-scale benchmark archive for remote sensing image understanding. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 5901–5904. [Google Scholar]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Y.; Lu, P.; Chen, Y.; Wang, G. Large-scale structure from motion with semantic constraints of aerial images. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Guangzhou, China, 23–26 November 2018; Springer: Cham, Switzerland, 2018; pp. 347–359. [Google Scholar]
- Gong, P.; Liu, H.; Zhang, M.; Li, C.; Wang, J.; Huang, H.; Clinton, N.; Ji, L.; Li, W.; Bai, Y.; et al. Stable classification with limited sample: Transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar] [CrossRef] [PubMed]
- Roscher, R.; Volpi, M.; Mallet, C.; Drees, L.; Wegner, J.D. Semcity Toulouse: A Benchmark for Building Instance Segmentation in Satellite Images. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, V-5-2020, 109–116. [Google Scholar] [CrossRef]
- Freeman, E.; Woodruff, S.D.; Worley, S.J.; Lubker, S.J.; Kent, E.C.; Angel, W.E.; Berry, D.I.; Brohan, P.; Eastman, R.; Gates, L.; et al. ICOADS Release 3.0: A major update to the historical marine climate record. Int. J. Climatol. 2017, 37, 2211–2232. [Google Scholar] [CrossRef]
- International Journal of Computer Vision. The PASCAL Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Bearman, A.; Russakovsky, O.; Ferrari, V.; Fei-Fei, L. What’s the point: Semantic segmentation with point supervision. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VII 14; Springer: Cham, Switzerland, 2016; pp. 549–565. [Google Scholar]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. ScribbleSup: Scribble-Supervised Convolutional Networks for Semantic Segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3159–3167. [Google Scholar] [CrossRef]
- Hariharan, B.; Arbeláez, P.; Bourdev, L.; Maji, S.; Malik, J. Semantic contours from inverse detectors. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 991–998. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Dai, J.; He, K.; Sun, J. BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Washington, DC, USA, 7–13 December 2015; pp. 1635–1643. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Workman, S.; Hadzic, A.; Rafique, M.U. Handling Image and Label Resolution Mismatch in Remote Sensing. In Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–7 January 2023; pp. 3698–3707. [Google Scholar] [CrossRef]
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. BRRNet: A Fully Convolutional Neural Network for Automatic Building Extraction from High-Resolution Remote Sensing Images. Remote Sens. 2020, 12, 1050. [Google Scholar] [CrossRef]
- Lin, Y.; Sun, H.; Liu, N.; Bian, Y.; Cen, J.; Zhou, H. Attention Guided Network for Salient Object Detection in Optical Remote Sensing Images. arXiv 2022, arXiv:2207.01755. [Google Scholar]
- Zhong, H.F.; Sun, Q.; Sun, H.M.; Jia, R.S. NT-Net: A Semantic Segmentation Network for Extracting Lake Water Bodies From Optical Remote Sensing Images Based on Transformer. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Yao, J.; Hong, D.; Gao, L.; Chanussot, J. Multimodal Remote Sensing Benchmark Datasets for Land Cover Classification. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 4807–4810. [Google Scholar] [CrossRef]
- Pan, X.; Gao, L.; Marinoni, A.; Zhang, B.; Yang, F.; Gamba, P. Semantic Labeling of High Resolution Aerial Imagery and LiDAR Data with Fine Segmentation Network. Remote Sens. 2018, 10, 743. [Google Scholar] [CrossRef]
- Deng, W.; Shi, Q.; Li, J. Attention-Gate-Based Encoder–Decoder Network for Automatical Building Extraction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2611–2620. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, X.; Xin, Q.; Sun, Y.; Zhang, P. Automatic building extraction from high-resolution aerial images and LiDAR data using gated residual refinement network. ISPRS J. Photogramm. Remote Sens. 2019, 151, 91–105. [Google Scholar] [CrossRef]
- Li, X.; Lei, L.; Kuang, G. Multi-Modal Fusion Architecture Search for Land Cover Classification Using Heterogeneous Remote Sensing Images. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 5997–6000. [Google Scholar] [CrossRef]
- Kang, J.; Wang, Z.; Zhu, R.; Xia, J.; Sun, X.; Fernandez-Beltran, R.; Plaza, A. DisOptNet: Distilling Semantic Knowledge From Optical Images for Weather-Independent Building Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Ding, L.; Tang, H.; Liu, Y.; Shi, Y.; Zhu, X.X.; Bruzzone, L. Adversarial Shape Learning for Building Extraction in VHR Remote Sensing Images. IEEE Trans. Image Process. 2022, 31, 678–690. [Google Scholar] [CrossRef]
- Xiong, Z.; Chen, S.; Wang, Y.; Mou, L.; Zhu, X.X. GAMUS: A Geometry-aware Multi-modal Semantic Segmentation Benchmark for Remote Sensing Data. arXiv 2023, arXiv:2305.14914. [Google Scholar]
- Xu, Z.; Xu, C.; Cui, Z.; Zheng, X.; Yang, J. CVNet: Contour Vibration Network for Building Extraction. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 1373–1381. [Google Scholar] [CrossRef]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Learning a Discriminative Feature Network for Semantic Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1857–1866. [Google Scholar] [CrossRef]
- Liao, C.; Hu, H.; Li, H.; Ge, X.; Chen, M.; Li, C.; Zhu, Q. Joint Learning of Contour and Structure for Boundary-Preserved Building Extraction. Remote Sens. 2021, 13, 1049. [Google Scholar] [CrossRef]
- Quan, Y.; Yu, A.; Cao, X.; Qiu, C.; Zhang, X.; Liu, B.; He, P. Building Extraction from Remote Sensing Images with DoG as Prior Constraint. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 6559–6570. [Google Scholar] [CrossRef]
- Muhtar, D.; Zhang, X.; Xiao, P.; Li, Z.; Gu, F. CMID: A Unified Self-Supervised Learning Framework for Remote Sensing Image Understanding. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–17. [Google Scholar] [CrossRef]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved Baselines with Momentum Contrastive Learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Misra, I.; van der Maaten, L. Self-Supervised Learning of Pretext-Invariant Representations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6706–6716. [Google Scholar] [CrossRef]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A Survey on Contrastive Self-Supervised Learning. Technologies 2021, 9, 2. [Google Scholar] [CrossRef]
- Sun, X.; Wang, P.; Lu, W.; Zhu, Z.; Lu, X.; He, Q.; Li, J.; Rong, X.; Yang, Z.; Chang, H.; et al. RingMo: A Remote Sensing Foundation Model with Masked Image Modeling. IEEE Trans. Geosci. Remote. Sens. 2022, 61, 1–22. [Google Scholar] [CrossRef]
- Yuan, Y.; Lin, L.; Liu, Q.; Hang, R.; Zhou, Z.G. SITS-Former: A pre-trained spatio-spectral-temporal representation model for Sentinel-2 time series classification. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102651. [Google Scholar] [CrossRef]
- Cong, Y.; Khanna, S.; Meng, C.; Liu, P.; Rozi, E.; He, Y.; Burke, M.; Lobell, D.B.; Ermon, S. SatMAE: Pre-training Transformers for Temporal and Multi-Spectral Satellite Imagery. arXiv 2023, arXiv:2207.08051. [Google Scholar]
- Scheibenreif, L.; Hanna, J.; Mommert, M.; Borth, D. Self-supervised Vision Transformers for Land-cover Segmentation and Classification. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 18–24 June 2022; pp. 1421–1430. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, F.; Hou, Z.; Mian, L.; Wang, Z.; Zhang, J.; Tang, J. Self-Supervised Learning: Generative or Contrastive. IEEE Trans. Knowl. Data Eng. 2023, 35, 857–876. [Google Scholar] [CrossRef]
- Wang, J. Self-Supervised Learning. 2021. Available online: https://zhuanlan.zhihu.com/ (accessed on 11 October 2023).
- Ayush, K.; Uzkent, B.; Meng, C.; Tanmay, K.; Burke, M.; Lobell, D.; Ermon, S. Geography-Aware Self-Supervised Learning. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 10161–10170. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G.E. A Simple Framework for Contrastive Learning of Visual Representations. arXiv 2020, arXiv:2002.05709. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9726–9735. [Google Scholar] [CrossRef]
- Grill, J.B.; Strub, F.; Altch’e, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.Á.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning. arXiv 2020, arXiv:2006.07733. [Google Scholar]
- Chen, X.; He, K. Exploring Simple Siamese Representation Learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 15745–15753. [Google Scholar] [CrossRef]
- Chen, Q.; Chen, Z.; Luo, W. Feature Transformation for Cross-domain Few-shot Remote Sensing Scene Classification. arXiv 2022, arXiv:2203.02270. [Google Scholar]
- Li, H.; Li, Y.; Zhang, G.; Liu, R.; Huang, H.; Zhu, Q.; Tao, C. Global and Local Contrastive Self-Supervised Learning for Semantic Segmentation of HR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Muhtar, D.; Zhang, X.; Xiao, P. Index Your Position: A Novel Self-Supervised Learning Method for Remote Sensing Images Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- M Rustowicz, R.; Cheong, R.; Wang, L.; Ermon, S.; Burke, M.; Lobell, D. Semantic segmentation of crop type in Africa: A novel dataset and analysis of deep learning methods. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 75–82. [Google Scholar]
- Reiche, J.; Hamunyela, E.; Verbesselt, J.; Hoekman, D.; Herold, M. Improving near-real time deforestation monitoring in tropical dry forests by combining dense Sentinel-1 time series with Landsat and ALOS-2 PALSAR-2. Remote Sens. Environ. 2018, 204, 147–161. [Google Scholar] [CrossRef]
- Hendrycks, D.; Mazeika, M.; Kadavath, S.; Song, D. Using Self-Supervised Learning Can Improve Model Robustness and Uncertainty. arXiv 2019, arXiv:1906.12340. [Google Scholar]
- Ghanbarzade, A.; Soleimani, D.H. Supervised and Contrastive Self-Supervised In-Domain Representation Learning for Dense Prediction Problems in Remote Sensing. arXiv 2023, arXiv:2301.12541. [Google Scholar]
- Jain, U.; Wilson, A.; Gulshan, V. Multimodal Contrastive Learning for Remote Sensing Tasks. arXiv 2022, arXiv:2209.02329. [Google Scholar]
- Jain, P.; Schoen-Phelan, B.; Ross, R. Self-Supervised Learning for Invariant Representations From Multi-Spectral and SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 7797–7808. [Google Scholar] [CrossRef]
- Chen, D.Y.; Peng, L.; Zhang, W.Y.; Wang, Y.D.; Yang, L.N. Research on Self-Supervised Building Information Extraction with High-Resolution Remote Sensing Images for Photovoltaic Potential Evaluation. Remote Sens. 2022, 14, 5350. [Google Scholar] [CrossRef]
- Xie, Z.; Lin, Y.; Yao, Z.; Zhang, Z.; Dai, Q.; Cao, Y.; Hu, H. Self-Supervised Learning with Swin Transformers. arXiv 2021, arXiv:2105.04553. [Google Scholar]
- Zhang, Z.; Wang, X.; Mei, X.; Tao, C.; Li, H. FALSE: False Negative Samples Aware Contrastive Learning for Semantic Segmentation of High-Resolution Remote Sensing Image. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Papadomanolaki, M.; Karantzalos, K.; Vakalopoulou, M. A Multi-Task Deep Learning Framework Coupling Semantic Segmentation and Image Reconstruction for Very High Resolution Imagery. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1069–1072. [Google Scholar] [CrossRef]
- Swope, A.M.; Rudelis, X.H.; Story, K.T. Representation Learning for Remote Sensing: An Unsupervised Sensor Fusion Approach. arXiv 2021, arXiv:2108.05094. [Google Scholar]
- Wang, X.; Zhang, R.; Shen, C.; Kong, T.; Li, L. Dense Contrastive Learning for Self-Supervised Visual Pre-Training. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3023–3032. [Google Scholar] [CrossRef]
- Wang, Y.; Albrecht, C.M.; Zhu, X.X. Self-Supervised Vision Transformers for Joint SAR-Optical Representation Learning. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 139–142. [Google Scholar] [CrossRef]
- Caron, M.; Touvron, H.; Misra, I.; Jegou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging Properties in Self-Supervised Vision Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 9630–9640. [Google Scholar] [CrossRef]
- Seneviratne, S.; Nice, K.A.; Wijnands, J.S.; Stevenson, M.; Thompson, J. Self-Supervision. Remote Sensing and Abstraction: Representation Learning Across 3 Million Locations. In Proceedings of the 2021 Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 29 November–1 December 2021; pp. 01–08. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, M.; Bruzzone, L. Incomplete Multimodal Learning for Remote Sensing Data Fusion. arXiv 2023, arXiv:2304.11381. [Google Scholar]
- Li, W.; Chen, H.; Shi, Z. Semantic Segmentation of Remote Sensing Images With Self-Supervised Multitask Representation Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6438–6450. [Google Scholar] [CrossRef]
- Li, C.L.; Sohn, K.; Yoon, J.; Pfister, T. CutPaste: Self-Supervised Learning for Anomaly Detection and Localization. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 9659–9669. [Google Scholar] [CrossRef]
- Tang, M.; Georgiou, K.; Qi, H.; Champion, C.; Bosch, M. Semantic Segmentation in Aerial Imagery Using Multi-level Contrastive Learning with Local Consistency. In Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikola, HI, USA, 2–7 January 2023; pp. 3787–3796. [Google Scholar] [CrossRef]
- Tian, Y.; Chen, X.; Ganguli, S. Understanding self-supervised Learning Dynamics without Contrastive Pairs. arXiv 2021, arXiv:2102.06810. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F. BEiT: BERT Pre-Training of Image Transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow Twins: Self-Supervised Learning via Redundancy Reduction. arXiv 2021, arXiv:2103.03230. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked Autoencoders Are Scalable Vision Learners. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 15979–15988. [Google Scholar] [CrossRef]
- Xie, Z.; Zhang, Z.; Cao, Y.; Lin, Y.; Bao, J.; Yao, Z.; Dai, Q.; Hu, H. SimMIM: A Simple Framework for Masked Image Modeling. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 9643–9653. [Google Scholar] [CrossRef]
- Peng, Z.; Dong, L.; Bao, H.; Ye, Q.; Wei, F. BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers. arXiv 2022, arXiv:2208.06366. [Google Scholar]
- Wang, W.; Bao, H.; Dong, L.; Bjorck, J.; Peng, Z.; Liu, Q.; Aggarwal, K.; Mohammed, O.K.; Singhal, S.; Som, S.; et al. Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks. arXiv 2022, arXiv:2208.10442. [Google Scholar]
- He, S.; Li, Q.; Liu, Y.; Wang, W. Semantic Segmentation of Remote Sensing Images with Self-Supervised Semantic-Aware Inpainting. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, Y.; Zhang, Z.; Luo, Q.; Yang, J. GSC-MIM: Global semantic integrated self-distilled complementary masked image model for remote sensing images scene classification. Front. Ecol. Evol. 2022, 10, 1083801. [Google Scholar] [CrossRef]
- Zhang, M.; Chunara, R. Fair contrastive pre-training for geographic image segmentation. arXiv 2023, arXiv:2211.08672. [Google Scholar]
- Deus, D. Integration of ALOS PALSAR and Landsat Data for Land Cover and Forest Mapping in Northern Tanzania. Land 2016, 5, 43. [Google Scholar] [CrossRef]
- Peña, F.J.; Hübinger, C.; Payberah, A.H.; Jaramillo, F. DeepAqua: Self-Supervised Semantic Segmentation of Wetlands from SAR Images using Knowledge Distillation. arXiv 2023, arXiv:2305.01698. [Google Scholar]
- Fan, Y.; Zeng, Q.; Mei, Z.; Hu, W. Semantic Segmentation for Mangrove Using Spectral Indices and Self-Attention Mechanism. In Proceedings of the 2022 7th International Conference on Signal and Image Processing (ICSIP), Suzhou, China, 20–22 July 2022; pp. 436–441. [Google Scholar] [CrossRef]
- Xie, Y.; Li, Z.; Bao, H.; Jia, X.; Xu, D.; Zhou, X.; Skakun, S. Auto-CM: Unsupervised deep learning for satellite imagery composition and cloud masking using spatio-temporal dynamics. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 14575–14583. [Google Scholar]
- Hays, J.; Efros, A.A. Large-Scale Image Geolocalization. In Multimodal Location Estimation of Videos and Images; Choi, J., Friedland, G., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 41–62. [Google Scholar] [CrossRef]
- Li, W.; Chen, K.; Chen, H.; Shi, Z. Geographical Knowledge-Driven Representation Learning for Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Song, Z.; Yang, X.; Xu, Z.; King, I. Graph-Based Semi-Supervised Learning: A Comprehensive Review. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–21. [Google Scholar] [CrossRef]
- Aromal, M.A.; Rasool, A. Semi Supervised Learning Using Graph Data Structure—A Review. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 894–899. [Google Scholar] [CrossRef]
- Ouali, Y.; Hudelot, C.; Tami, M. Semi-Supervised Semantic Segmentation with Cross-Consistency Training. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12671–12681. [Google Scholar] [CrossRef]
- Wang, C.; Tang, X.; Li, L.; Tian, B.; Zhou, Y.; Shi, J. IDN: Inner-class dense neighbours for semi-supervised learning-based remote sensing scene classification. Remote Sens. Lett. 2023, 14, 80–90. [Google Scholar] [CrossRef]
- Tong, R.; Li, P.; Gao, L.; Lang, X.; Miao, A.; Shen, X. A Novel Ellipsoidal Semisupervised Extreme Learning Machine Algorithm and Its Application in Wind Turbine Blade Icing Fault Detection. IEEE Trans. Instrum. Meas. 2022, 71, 1–16. [Google Scholar] [CrossRef]
- Im, D.J.; Taylor, G.W. Semisupervised Hyperspectral Image Classification via Neighborhood Graph Learning. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1913–1917. [Google Scholar] [CrossRef]
- Von Kügelgen, J.; Mey, A.; Loog, M.; Schölkopf, B. Semi-Supervised Learning, Causality and the Conditional Cluster Assumption. arXiv 2020, arXiv:1905.12081. [Google Scholar]
- Wang, Y.; Meng, Y.; Fu, Z.; Xue, H. Towards safe semi-supervised classification: Adjusted cluster assumption via clustering. Neural Process. Lett. 2017, 46, 1031–1042. [Google Scholar] [CrossRef]
- Zhang, W.; Feng, X.; Chen, Y. A Manifold Laplacian Regularized Semi-Supervised Sparse Image Classification Method with a Variant Trace Lasso Norm. IEEE Access 2020, 8, 97361–97369. [Google Scholar] [CrossRef]
- Iscen, A.; Tolias, G.; Avrithis, Y.; Chum, O. Label Propagation for Deep Semi-Supervised Learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5065–5074. [Google Scholar] [CrossRef]
- All in One Article! A Comprehensive Survey of Weakly Supervised Semantics/Instances/Panorama Segmentation. 2023. Available online: https://developer.aliyun.com/article/1142964 (accessed on 14 October 2023).
- Grandvalet, Y.; Bengio, Y. Semi-supervised learning by entropy minimization. Adv. Neural Inf. Process. Syst. 2004, 17, 529–536. [Google Scholar]
- Belkin, M.; Niyogi, P.; Sindhwani, V. Manifold regularization: A geometric framework for learning from labeled and unlabeled examples. J. Mach. Learn. Res. 2006, 7. [Google Scholar]
- Wang, J.; Ding, H.Q.C.; Chen, S.; He, C.; Luo, B. Semi-Supervised Remote Sensing Image Semantic Segmentation via Consistency Regularization and Average Update of Pseudo-Label. Remote Sens. 2020, 12, 3603. [Google Scholar] [CrossRef]
- Li, L.; Zhang, W.; Zhang, X.; Emam, M.; Jing, W. Semi-Supervised Remote Sensing Image Semantic Segmentation Method Based on Deep Learning. Electronics 2023, 12, 348. [Google Scholar] [CrossRef]
- Li, Q.; Shi, Y.; Zhu, X.X. Semi-Supervised Building Footprint Generation with Feature and Output Consistency Training. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, Y.; Li, Y.; Wan, Y.; Wen, F. Semi-Supervised Semantic Segmentation Network via Learning Consistency for Remote Sensing Land-Cover Classification. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, V-2-2020, 609–615. [Google Scholar] [CrossRef]
- He, Y.; Wang, J.; Liao, C.; Zhou, X.; Shan, B. MS4D-Net: Multitask-Based Semi-Supervised Semantic Segmentation Framework with Perturbed Dual Mean Teachers for Building Damage Assessment from High-Resolution Remote Sensing Imagery. Remote Sens. 2023, 15, 478. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, Y.; Li, Y.; Wan, Y.; Guo, H.; Zheng, Z.; Yang, K. Semi-Supervised Deep learning via Transformation Consistency Regularization for Remote Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 16, 5782–5796. [Google Scholar] [CrossRef]
- Wang, J.; Zhao, J.; Sun, H.; Lu, X.; Huang, J.; Wang, S.; Fang, G. Satellite Remote Sensing Identification of Discolored Standing Trees for Pine Wilt Disease Based on Semi-Supervised Deep Learning. Remote Sens. 2022, 14, 936. [Google Scholar] [CrossRef]
- Desai, S.; Ghose, D. Active Learning for Improved Semi-Supervised Semantic Segmentation in Satellite Images. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 1485–1495. [Google Scholar] [CrossRef]
- Zhang, L.; Lu, W.; Zhang, J.; Wang, H. A Semisupervised Convolution Neural Network for Partial Unlabeled Remote-Sensing Image Segmentation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Liang, C.; Cheng, B.; Xiao, B.; He, C.; Liu, X.; Jia, N.; Chen, J. Semi-/Weakly-Supervised Semantic Segmentation Method and Its Application for Coastal Aquaculture Areas Based on Multi-Source Remote Sensing Images—Taking the Fujian Coastal Area (Mainly Sanduo) as an Example. Remote Sens. 2021, 13, 1083. [Google Scholar] [CrossRef]
- Kerdegari, H.; Razaak, M.; Argyriou, V.; Remagnino, P. Urban scene segmentation using semi-supervised GAN. In Proceedings of the Image and Signal Processing for Remote Sensing XXV, Strasbourg, France, 9–11 September 2019; Bruzzone, L., Bovolo, F., Eds.; International Society for Optics and Photonics, SPIE: San Francisco, CA, USA, 2019; Volume 11155, p. 111551H. [Google Scholar] [CrossRef]
- Nie, W.; Gou, P.; Liu, Y.; Zhou, T.; Xu, N.; Wang, P.; Du, Q. A semi-supervised image segmentation method based on generative adversarial network. In Proceedings of the 2022 IEEE 10th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing China, 17–19 June 2022; Volume 10, pp. 1217–1223. [Google Scholar] [CrossRef]
- Wang, Y.; Tsai, Y.H.; Hung, W.C.; Ding, W.; Liu, S.; Yang, M.H. Semi-supervised Multi-task Learning for Semantics and Depth. In Proceedings of the 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2022; pp. 2663–2672. [Google Scholar]
- Chakravarthy, A.S.; Sinha, S.; Narang, P.; Mandal, M.; Chamola, V.; Yu, F.R. DroneSegNet: Robust Aerial Semantic Segmentation for UAV-Based IoT Applications. IEEE Trans. Veh. Technol. 2022, 71, 4277–4286. [Google Scholar] [CrossRef]
- Sun, X.; Shi, A.; Huang, H.; Mayer, H. BAS4Net: Boundary-aware semi-supervised semantic segmentation network for very high resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5398–5413. [Google Scholar] [CrossRef]
- Castillo-Navarro, J.; Saux, B.L.; Boulch, A.; Lefèvre, S. On Auxiliary Losses for Semi-Supervised Semantic Segmentation. In Proceedings of the ECML PKDD 2020: European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, Ghent, Belgium, 14–18 September 2020. [Google Scholar]
- Chendeb El Rai, M.; Giraldo, J.H.; Al-Saad, M.; Darweech, M.; Bouwmans, T. SemiSegSAR: A Semi-Supervised Segmentation Algorithm for Ship SAR Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Li, F.; Clausi, D.A.; Xu, L.; Wong, A. ST-IRGS: A Region-Based Self-Training Algorithm Applied to Hyperspectral Image Classification and Segmentation. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3–16. [Google Scholar] [CrossRef]
- Xie, D.; Yang, R.; Qiao, Y.; Zhang, J. Intelligent Identification of Landslide Based on Deep Semi-supervised Learning. In Proceedings of the 2022 5th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Chengdu, China, 19–21 August 2022; pp. 264–269. [Google Scholar] [CrossRef]
- Schmitt, M.; Prexl, J.; Ebel, P.; Liebel, L.; Zhu, X.X. Weakly Supervised Semantic Segmentation of Satellite Images for Land Cover Mapping—Challenges and Opportunities. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, V-3-2020, 795–802. [Google Scholar] [CrossRef]
- Lenczner, G.; Chan-Hon-Tong, A.; Luminari, N.; Le Saux, B. Weakly-Supervised Continual Learning for Class-Incremental Segmentation. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 4843–4846. [Google Scholar] [CrossRef]
- Zhu, X.; Xu, M.; Wu, M.; Zhang, C.; Zhang, B. Annotating Only at Definite Pixels: A Novel Weakly Supervised Semantic Segmentation Method for Sea Fog Recognition. In Proceedings of the 2022 IEEE International Conference on Visual Communications and Image Processing (VCIP), Suzhou, China, 13–16 December 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Lu, M.; Fang, L.; Li, M.; Zhang, B.; Zhang, Y.; Ghamisi, P. NFANet: A Novel Method for Weakly Supervised Water Extraction from High-Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, P.; Corpetti, T.; Zhao, L. WTS: A Weakly towards Strongly Supervised Learning Framework for Remote Sensing Land Cover Classification Using Segmentation Models. Remote Sens. 2021, 13, 394. [Google Scholar] [CrossRef]
- Vernaza, P.; Chandraker, M. Learning Random-Walk Label Propagation for Weakly-Supervised Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2953–2961. [Google Scholar] [CrossRef]
- Wei, Y.; Ji, S. Scribble-Based Weakly Supervised Deep Learning for Road Surface Extraction From Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Khoreva, A.; Benenson, R.; Omran, M.; Hein, M.; Schiele, B. Weakly Supervised Object Boundaries. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 183–192. [Google Scholar] [CrossRef]
- Rafique, M.U.; Jacobs, N. Weakly Supervised Building Segmentation from Aerial Images. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019. [Google Scholar]
- Oh, Y.; Kim, B.; Ham, B. Background-Aware Pooling and Noise-Aware Loss for Weakly-Supervised Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Li, Z.; Zhang, X.; Xiao, P.; Zheng, Z. On the Effectiveness of Weakly Supervised Semantic Segmentation for Building Extraction From High-Resolution Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3266–3281. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, H.; Yang, R.; Yao, G.; Xu, Q.; Zhang, X. A Novel Weakly Supervised Remote Sensing Landslide Semantic Segmentation Method: Combining CAM and cycleGAN Algorithms. Remote Sens. 2022, 14, 3650. [Google Scholar] [CrossRef]
- Xie, H.; Lin, S.F. A Weakly Supervised Defect Detection Based on Dual Path Networks and GMA-CAM. In Proceedings of the International Conference on Image and Graphics, Haikou, China, 6–8 August 2021. [Google Scholar]
- Saleh, F.S.; Aliakbarian, M.S.; Salzmann, M.; Petersson, L.; Alvarez, J.M. Bringing Background into the Foreground: Making All Classes Equal in Weakly-supervised Video Semantic Segmentation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Yan, X.; Shen, L.; Wang, J.; Deng, X.; Li, Z. MSG-SR-Net: A Weakly Supervised Network Integrating Multiscale Generation and Superpixel Refinement for Building Extraction From High-Resolution Remotely Sensed Imageries. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1012–1023. [Google Scholar] [CrossRef]
- He, W.; Jiang, Z.; Kriby, M.; Xie, Y.; Jia, X.; Yan, D.; Zhou, Y. Quantifying and Reducing Registration Uncertainty of Spatial Vector Labels on Earth Imagery. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 14–18 August 2022; KDD ’22, pp. 554–564. [Google Scholar] [CrossRef]
- Xu, J.; Schwing, A.G.; Urtasun, R. Learning to segment under various forms of weak supervision. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3781–3790. [Google Scholar] [CrossRef]
- Xia, W.; Zhong, N.; Geng, D.; Luo, L. A weakly supervised road extraction approach via deep convolutional nets based image segmentation. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 19–21 May 2017. [Google Scholar]
- Mazhar, S.; Sun, G.; Bilal, A.; Hassan, B.; Li, Y.; Zhang, J.; Lin, Y.; Khan, A.; Ahmed, R.; Hassan, T. AUnet: A Deep Learning Framework for Surface Water Channel Mapping Using Large-Coverage Remote Sensing Images and Sparse Scribble Annotations from OSM Data. Remote Sens. 2022, 14, 3283. [Google Scholar] [CrossRef]
- Moliner, E.; Romero, L.S.; Vilaplana, V. Weakly Supervised Semantic Segmentation For Remote Sensing Hyperspectral Imaging. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Dvořák, J.; Potůčková, M.; Treml, V. Weakly supervised learning for treeline ecotone classification based on aerial orthoimages and an ancillary dsm. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, V-3-2022, 33–38. [Google Scholar] [CrossRef]
- Robinson, C.; Malkin, K.; Hu, L.; Dilkina, B.; Jojic, N. Weakly Supervised Semantic Segmentation in the 2020 IEEE GRSS Data Fusion Contest. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020. [Google Scholar]
- Saleh, F.; Aliakbarian, M.S.; Salzmann, M.; Petersson, L.; Alvarez, J.M.; Gould, S. Incorporating Network Built-in Priors in Weakly-supervised Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1382–1396. [Google Scholar] [CrossRef]
- Han, Z.; Xiao, Z.; Yu, M. Weakly supervised semantic segmentation using fore-background priors. SPIE 2017, 10420, 1049–1056. [Google Scholar]
- Li, W.; Li, F.; Luo, Y.; Wang, P.; sun, J. Deep Domain Adaptive Object Detection: A Survey. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, Australia, 1–4 December 2020; pp. 1808–1813. [Google Scholar] [CrossRef]
- Gao, K.; Yu, A.; You, X.; Guo, W.; Li, K.; Huang, N. Integrating Multiple Sources Knowledge for Class Asymmetry Domain Adaptation Segmentation of Remote Sensing Images. arXiv 2023, arXiv:2305.09893. [Google Scholar]
- Hoyer, L.; Dai, D.; Wang, H.; Van Gool, L. MIC: Masked Image Consistency for Context-Enhanced Domain Adaptation. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 11721–11732. [Google Scholar] [CrossRef]
- Lu, X.; Gong, T.; Zheng, X. Multisource Compensation Network for Remote Sensing Cross-Domain Scene Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2504–2515. [Google Scholar] [CrossRef]
- Von Kügelgen, J.; Sharma, Y.; Gresele, L.; Brendel, W.; Schölkopf, B.; Besserve, M.; Locatello, F. Self-Supervised Learning with Data Augmentations Provably Isolates Content from Style. arXiv 2022, arXiv:2106.04619. [Google Scholar]
- Cheng, Y.; Wei, F.; Bao, J.; Chen, D.; Wen, F.; Zhang, W. Dual Path Learning for Domain Adaptation of Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 9062–9071. [Google Scholar] [CrossRef]
- Li, Z.; Xie, Y.; Jia, X.; Stuart, K.; Delaire, C.; Skakun, S. Point-to-Region Co-learning for Poverty Mapping at High Resolution Using Satellite Imagery. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–13 February 2023. [Google Scholar]
- Mateo-García, G.; Laparra, V.; López-Puigdollers, D.; Gómez-Chova, L. Cross-Sensor Adversarial Domain Adaptation of Landsat-8 and Proba-V Images for Cloud Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 747–761. [Google Scholar] [CrossRef]
- Banerjee, B.; Bovolo, F.; Bhattacharya, A.; Bruzzone, L.; Chaudhuri, S.; Buddhiraju, K.M. A Novel Graph-Matching-Based Approach for Domain Adaptation in Classification of Remote Sensing Image Pair. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4045–4062. [Google Scholar] [CrossRef]
- Cermelli, F.; Mancini, M.; Buló, S.R.; Ricci, E.; Caputo, B. Modeling the Background for Incremental and Weakly-Supervised Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 10099–10113. [Google Scholar] [CrossRef] [PubMed]
- Iqbal, J.; Ali, M. Weakly-supervised domain adaptation for built-up region segmentation in aerial and satellite imagery. ISPRS J. Photogramm. Remote Sens. 2020, 167, 263–275. [Google Scholar] [CrossRef]
- Xie, X.; Chen, J.; Li, Y.; Shen, L.; Ma, K.; Zheng, Y. Self-Supervised CycleGAN for Object-Preserving Image-to-Image Domain Adaptation. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Cham, Switzerland, 2020; pp. 498–513. [Google Scholar]
- Wen, S.; Tian, W.; Zhang, H.; Fan, S.; Li, X. Semantic Segmentation Using a GAN and a Weakly Supervised Method Based on Deep Transfer Learning. IEEE Access 2020, 8, 176480–176494. [Google Scholar] [CrossRef]
- Adayel, R.; Bazi, Y.; Alhichri, H.; Alajlan, N. Deep Open-Set Domain Adaptation for Cross-Scene Classification based on Adversarial Learning and Pareto Ranking. Remote Sens. 2020, 12, 1716. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, M.; Tao, R.; Li, W.; Liao, W.; Philips, W. Cross-Domain Classification of Multisource Remote Sensing Data Using Fractional Fusion and Spatial-Spectral Domain Adaptation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5721–5733. [Google Scholar] [CrossRef]
- Teng, W.; Wang, N.; Shi, H.; Liu, Y.; Wang, J. Classifier-Constrained Deep Adversarial Domain Adaptation for Cross-Domain Semisupervised Classification in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2020, 17, 789–793. [Google Scholar] [CrossRef]
- Deng, X.; Zhu, Y.; Tian, Y.; Newsam, S. Scale Aware Adaptation for Land-Cover Classification in Remote Sensing Imagery. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Virtual Conference, 5–9 January 2021; pp. 2159–2168. [Google Scholar] [CrossRef]
- Iqbal, J.; Ali, M. MLSL: Multi-Level Self-Supervised Learning for Domain Adaptation with Spatially Independent and Semantically Consistent Labeling. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 1853–1862. [Google Scholar] [CrossRef]
- Gao, K.; Yu, A.; You, X.; Qiu, C.; Liu, B. Prototype and Context-Enhanced Learning for Unsupervised Domain Adaptation Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Li, Y.; Shi, T.; Zhang, Y.; Chen, W.; Wang, Z.; Li, H. Learning deep semantic segmentation network under multiple weakly-supervised constraints for cross-domain remote sensing image semantic segmentation. ISPRS J. Photogramm. Remote Sens. 2021, 175, 20–33. [Google Scholar] [CrossRef]
- Chen, Y.; Wei, C.; Wang, D.; Ji, C.; Li, B. Semi-supervised contrastive learning for few-shot segmentation of remote sensing images. Remote Sens. 2022, 14, 4254. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Few-Shot Learning. 2021. Available online: https://blog.csdn.net/weixin_44211968/article/details/121314757 (accessed on 11 October 2023).
- Yu, X.; Wu, X.; Luo, C.; Ren, P. Deep learning in remote sensing scene classification: A data augmentation enhanced convolutional neural network framework. Gisci. Remote Sens. 2017, 54, 741–758. [Google Scholar] [CrossRef]
- Li, W.; Chen, C.; Zhang, M.; Li, H.; Du, Q. Data Augmentation for Hyperspectral Image Classification with Deep CNN. IEEE Geosci. Remote Sens. Lett. 2019, 16, 593–597. [Google Scholar] [CrossRef]
- Chen, X.; Kamata, S.I.; Zhou, W. Hyperspectral Image Classification Based on Multi-stage Vision Transformer with Stacked Samples. In Proceedings of the TENCON 2021—2021 IEEE Region 10 Conference (TENCON), Auckland, New Zealand, 7–10 December 2021; pp. 441–446. [Google Scholar] [CrossRef]
- Huang, L.; Chen, Y. Dual-Path Siamese CNN for Hyperspectral Image Classification With Limited Training Samples. IEEE Geosci. Remote Sens. Lett. 2021, 18, 518–522. [Google Scholar] [CrossRef]
- Ramirez Rochac, J.F.; Zhang, N.; Thompson, L.; Oladunni, T. A Data Augmentation-Assisted Deep Learning Model for High Dimensional and Highly Imbalanced Hyperspectral Imaging Data. In Proceedings of the 2019 9th International Conference on Information Science and Technology (ICIST), Kopaonik, Serbia, 10–13 March 2019; pp. 362–367. [Google Scholar] [CrossRef]
- Lv, F.; Liu, H.; Wang, Y.; Zhao, J.; Yang, G. Learning Unbiased Zero-Shot Semantic Segmentation Networks via Transductive Transfer. IEEE Signal Process. Lett. 2020, 27, 1640–1644. [Google Scholar] [CrossRef]
- Parnami, A.; Lee, M. Learning from Few Examples: A Summary of Approaches to Few-Shot Learning. arXiv 2022, arXiv:2203.04291. [Google Scholar]
- Koch, G.R. Siamese Neural Networks for One-Shot Image Recognition. Master’s Thesis, University of Toronto, Toronto, ON, Canada, 2015. [Google Scholar]
- Zhang, J.; Chen, Z.; Huang, J.; Zhuang, J.; Zhang, D. Few-Shot Domain Adaptation for Semantic Segmentation. In ACM TURC ’19; Proceedings of the ACM Turing Celebration Conference—Chengdu, China, 17–19 May 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Tuia, D.; Munoz-Mari, J.; Gomez-Chova, L.; Malo, J. Graph Matching for Adaptation in Remote Sensing. IEEE Trans. Geosci. Remote Sens. 2013, 51, 329–341. [Google Scholar] [CrossRef]
- Kim, D.; Kim, J.; Cho, S.; Luo, C.; Hong, S. Universal Few-shot Learning of Dense Prediction Tasks with Visual Token Matching. arXiv 2023, arXiv:2303.14969. [Google Scholar]
- Kwon, H.; Jeong, S.; Kim, S.; Sohn, K. Dual Prototypical Contrastive Learning for Few-Shot Semantic Segmentation. arXiv 2021, arXiv:2111.04982. [Google Scholar]
- Mao, Y.; Guo, Z.; LU, X.; Yuan, Z.; Guo, H. Bidirectional Feature Globalization for Few-shot Semantic Segmentation of 3D Point Cloud Scenes. In Proceedings of the 2022 International Conference on 3D Vision (3DV), Prague, Czech Republic, 12–15 September 2022; pp. 505–514. [Google Scholar] [CrossRef]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. Panet: Few-shot image semantic segmentation with prototype alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9197–9206. [Google Scholar]
- Wang, B.; Wang, Z.; Sun, X.; Wang, H.; Fu, K. DMML-Net: Deep Metametric Learning for Few-Shot Geographic Object Segmentation in Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Tang, H.; Li, Y.; Han, X.; Huang, Q.; Xie, W. A Spatial–Spectral Prototypical Network for Hyperspectral Remote Sensing Image. IEEE Geosci. Remote Sens. Lett. 2020, 17, 167–171. [Google Scholar] [CrossRef]
- Zhang, Y.; Sidibé, D.; Morel, O.; Meriaudeau, F. Incorporating Depth Information into Few-Shot Semantic Segmentation. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3582–3588. [Google Scholar] [CrossRef]
- Jiang, X.; Zhou, N.; Li, X. Few-Shot Segmentation of Remote Sensing Images Using Deep Metric Learning. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- P, G.; Verma, U. Texture based Prototypical Network for Few-Shot Semantic Segmentation of Forest Cover: Generalizing for Different Geographical Regions. arXiv 2022, arXiv:2203.15687. [Google Scholar]
- Wang, Z.; Jiang, Z.; Yuan, Y. Prototype Queue Learning for Multi-Class Few-Shot Semantic Segmentation. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 1721–1725. [Google Scholar] [CrossRef]
- Cheng, G.; Lang, C.; Han, J. Holistic Prototype Activation for Few-Shot Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 4650–4666. [Google Scholar] [CrossRef]
- Wu, Z.; Shi, X.; Lin, G.; Cai, J. Learning Meta-class Memory for Few-Shot Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 497–506. [Google Scholar] [CrossRef]
- Tian, P.; Wu, Z.; Qi, L.; Wang, L.; Shi, Y.; Gao, Y. Differentiable meta-learning model for few-shot semantic segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12087–12094. [Google Scholar]
- Xie, Y.; Chen, W.; He, E.; Jia, X.; Bao, H.; Zhou, X.; Ghosh, R.; Ravirathinam, P. Harnessing heterogeneity in space with statistically guided meta-learning. Knowl. Inf. Syst. 2023, 65, 2699–2729. [Google Scholar] [CrossRef]
- Chen, D.; Chen, Y.; Li, Y.; Mao, F.; He, Y.; Xue, H. Self-Supervised Learning for Few-Shot Image Classification. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 1745–1749. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, C.; Lin, G.; Han, J. Compositional prototype network with multi-view comparision for few-shot point cloud semantic segmentation. arXiv 2020, arXiv:2012.14255. [Google Scholar]
- Zhao, N.; Chua, T.S.; Lee, G.H. Few-shot 3d point cloud semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8873–8882. [Google Scholar]
- Rao, M.; Tang, P.; Zhang, Z. Spatial–Spectral Relation Network for Hyperspectral Image Classification with Limited Training Samples. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 5086–5100. [Google Scholar] [CrossRef]
- Kemker, R.; Luu, R.; Kanan, C. Low-Shot Learning for the Semantic Segmentation of Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6214–6223. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the Opportunities and Risks of Foundation Models. arXiv 2022, arXiv:2108.07258. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. arXiv 2021, arXiv:2103.00020. [Google Scholar]
- Kouw, W.M.; Loog, M. A Review of Domain Adaptation without Target Labels. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 766–785. [Google Scholar] [CrossRef]
- Toldo, M.; Maracani, A.; Michieli, U.; Zanuttigh, P. Unsupervised Domain Adaptation in Semantic Segmentation: A Review. Technologies 2020, 8, 35. [Google Scholar] [CrossRef]
- Zhao, S.; Yue, X.; Zhang, S.; Li, B.; Zhao, H.; Wu, B.; Krishna, R.; Gonzalez, J.E.; Sangiovanni-Vincentelli, A.L.; Seshia, S.A.; et al. A Review of Single-Source Deep Unsupervised Visual Domain Adaptation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 473–493. [Google Scholar] [CrossRef]
- Maharana, K.; Mondal, S.; Nemade, B. A review: Data pre-processing and data augmentation techniques. Glob. Transitions Proc. 2022, 3, 91–99. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, C.; Zheng, S.; Qiao, Y.; Li, C.; Zhang, M.; Dam, S.K.; Thwal, C.M.; Tun, Y.L.; Huy, L.L.; et al. A Complete Survey on Generative AI (AIGC): Is ChatGPT from GPT-4 to GPT-5 All You Need? arXiv 2023, arXiv:2303.11717. [Google Scholar]
- Xu, M.; Du, H.; Niyato, D.; Kang, J.; Xiong, Z.; Mao, S.; Han, Z.; Jamalipour, A.; Kim, D.I.; Xuemin.; et al. Unleashing the Power of Edge-Cloud Generative AI in Mobile Networks: A Survey of AIGC Services. arXiv 2023, arXiv:2303.16129. [Google Scholar]
- Cao, Y.; Li, S.; Liu, Y.; Yan, Z.; Dai, Y.; Yu, P.S.; Sun, L. A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT. arXiv 2023, arXiv:2303.04226. [Google Scholar]
- Sohl-Dickstein, J.; Weiss, E.A.; Maheswaranathan, N.; Ganguli, S. Deep Unsupervised Learning using Nonequilibrium Thermodynamics. arXiv 2015, arXiv:1503.03585. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion Models Beat GANs on Image Synthesis. arXiv 2021, arXiv:2105.05233. [Google Scholar]
- LeCun, Y. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Rev. 2022, 62. [Google Scholar]
- Ye, D.; Peng, J.; Li, H.; Bruzzone, L. Better Memorization, Better Recall: A Lifelong Learning Framework for Remote Sensing Image Scene Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]







| Time | Model | Method |
|---|---|---|
| 2015 | ResNet | • The first proposed residual network and it is an effective strategy to deepen the network hierarchy. |
| VGG | • Deepening networks with small convolutional kernels. | |
| GoogleLeNet | • Balancing complexity and performance with deeper network depth. | |
| DeepLabv1 | • Add CRF to complete the post-processing task and refine the pixel. | |
| FCN | • It is proposed to use convolutional layers instead of fully connected layers so that they can accomplish the task of semantic segmentation. | |
| UNet | • The purpose of fusing shallow features with deeper features is achieved by skipping connections. | |
| 2016 | SegNet | • The feature index of the encoder is put into the decoder to reduce the amount of computation. |
| DeepLabv2 | • Adding Atrous Convolution during upsampling to expand the field. | |
| 2017 | FPN | • Construct a pyramid structure that makes full use of multi-scale features and incorporates multiple resolution feature maps. |
| PSPNet | • Making the most of multi-scale information for rich semantic information. | |
| DeepLabv3 | • Construct ASPP module to fully capture contextual background information. | |
| 2018 | DenseNet | • Reduce overfitting by linking each feature map to all other feature maps through dense linking. |
| DeepLabv3+ | • Design simple and effective decoder structures, with a particular focus on edge information. | |
| GeoSeg | • The popular networks are encapsulated and provided the advantages and disadvantages of different network models for modification. | |
| 2019 | UPerNet | • A commonly used decoder structure, excellent implementation of how to extract global features, texture feature structure. |
| HRNet | • Progressively adding high-resolution to low-resolution sub-networks in order to form a network model where multiple stages are repeated for scale fusion. | |
| MAPNet | • Constructing parallel branches and integrating multiple resolution features. | |
| 2020 | EfficientNet | • By constructing the model with the highest combined depth, width, and resolution metrics, better feature extraction performance is achieved. |
| FarSeg | • The focus is on addressing the current situation of imbalance between background and foreground information by extracting the target object through foreground modeling while suppressing background information. | |
| 2021 | SwinTransformer | • An in-window self-attentive mechanism for passing information through a sliding window. |
| MobileViT | • A lightweight transformer structure is proposed to control the number of tokens for the purpose of acceleration. | |
| 2022 | VAN | • Combining the advantages of CNN and Transformer, focusing on both detailed information and global information. |
| ConvNext | • A CNN model and improvement on ResNet to achieve very good semantic segmentation results. | |
| 2023 | SAM | • Pre-training on large-scale datasets further improves the predictive power of the method. |
| CLIP | • Adding textual information to assist the model in learning semantic information to better accomplish the semantic segmentation. |
| Methods | Annotation Effort | Cross-Domain Generalization Capability Performance | Training Phase | Essentials of Model Learning |
|---|---|---|---|---|
| Self supervised | Low (Pre-training phase without labeled samples, small data is required in fine-tuning) | Better generalization capabilities through fine-tuning | Fine-tuning is a necessary step | Input a certain number of images per mini-batch |
| Semi supervised | Low (Partially labeled samples are required) | No cross-domain generalization capability | Fine-tuning is commonly used to obtain better quality | Input a certain number of images per mini-batch |
| Weakly supervised | Low (Incomplete, inexact and inaccurate labeled are commonly used) | No cross-domain generalization capability | Fine-tuning is commonly used to achieve better quality | Input a certain number of images per mini-batch |
| Few-shot | Low (A large number of labeled samples are required in up front) | Better generalization capabilities through fine-tuning | Fine-tuning is a necessary step | Task or episode |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, A.; Quan, Y.; Yu, R.; Guo, W.; Wang, X.; Hong, D.; Zhang, H.; Chen, J.; Hu, Q.; He, P. Deep Learning Methods for Semantic Segmentation in Remote Sensing with Small Data: A Survey. Remote Sens. 2023, 15, 4987. https://doi.org/10.3390/rs15204987
Yu A, Quan Y, Yu R, Guo W, Wang X, Hong D, Zhang H, Chen J, Hu Q, He P. Deep Learning Methods for Semantic Segmentation in Remote Sensing with Small Data: A Survey. Remote Sensing. 2023; 15(20):4987. https://doi.org/10.3390/rs15204987
Chicago/Turabian StyleYu, Anzhu, Yujun Quan, Ru Yu, Wenyue Guo, Xin Wang, Danyang Hong, Haodi Zhang, Junming Chen, Qingfeng Hu, and Peipei He. 2023. "Deep Learning Methods for Semantic Segmentation in Remote Sensing with Small Data: A Survey" Remote Sensing 15, no. 20: 4987. https://doi.org/10.3390/rs15204987
APA StyleYu, A., Quan, Y., Yu, R., Guo, W., Wang, X., Hong, D., Zhang, H., Chen, J., Hu, Q., & He, P. (2023). Deep Learning Methods for Semantic Segmentation in Remote Sensing with Small Data: A Survey. Remote Sensing, 15(20), 4987. https://doi.org/10.3390/rs15204987