
Unsupervised Nonlinear Hyperspectral Unmixing with Reduced Spectral Variability via Superpixel-Based Fisher Transformation


Abstract
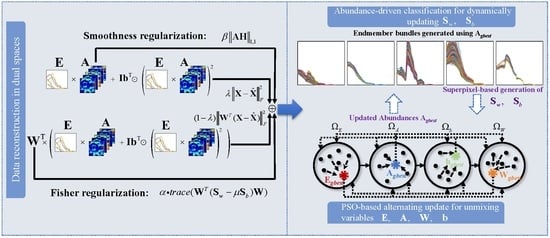
:
1. Introduction
- A superpixel-based Fisher transformation strategy is proposed to reduce the influence of spectral variability. In the transformed subspace, it enhances the similarity between pixels corresponding to the same class and enlarges the difference between pixels belonging to different classes. Within-class and between-class scatter matrices are generated based on superpixels according to abundance-driven dynamic coarse classification, which can effectively reduce the impact of global misclassification and retain the similarity of pixels in local spatial homogenous regions.
- The improved Fisher transformation is combined with the PPNM to address the nonlinear mixing effects and spectral variability simultaneously. Based on the PPNM, pixels are reconstructed in both the original spectral space and the weighted transformed subspace. With the incorporation of a projection matrix’s regularization term and a TV-based regularizer of abundances, a novel unsupervised nonlinear unmixing problem is formulated, which can be regarded as a general framework for handling spectral variability in unmixing.
- Considering the complexity of the formulated unmixing problem, a dimensional division-based PSO is extended to solve the unknown unmixing variables. More reliable and accurate unmixing results can be produced by the proposed method.
2. Related Works
2.1. LMM and PPNM
2.2. ELMM and SULoRA
2.3. Fisher Transformation
3. Proposed Method
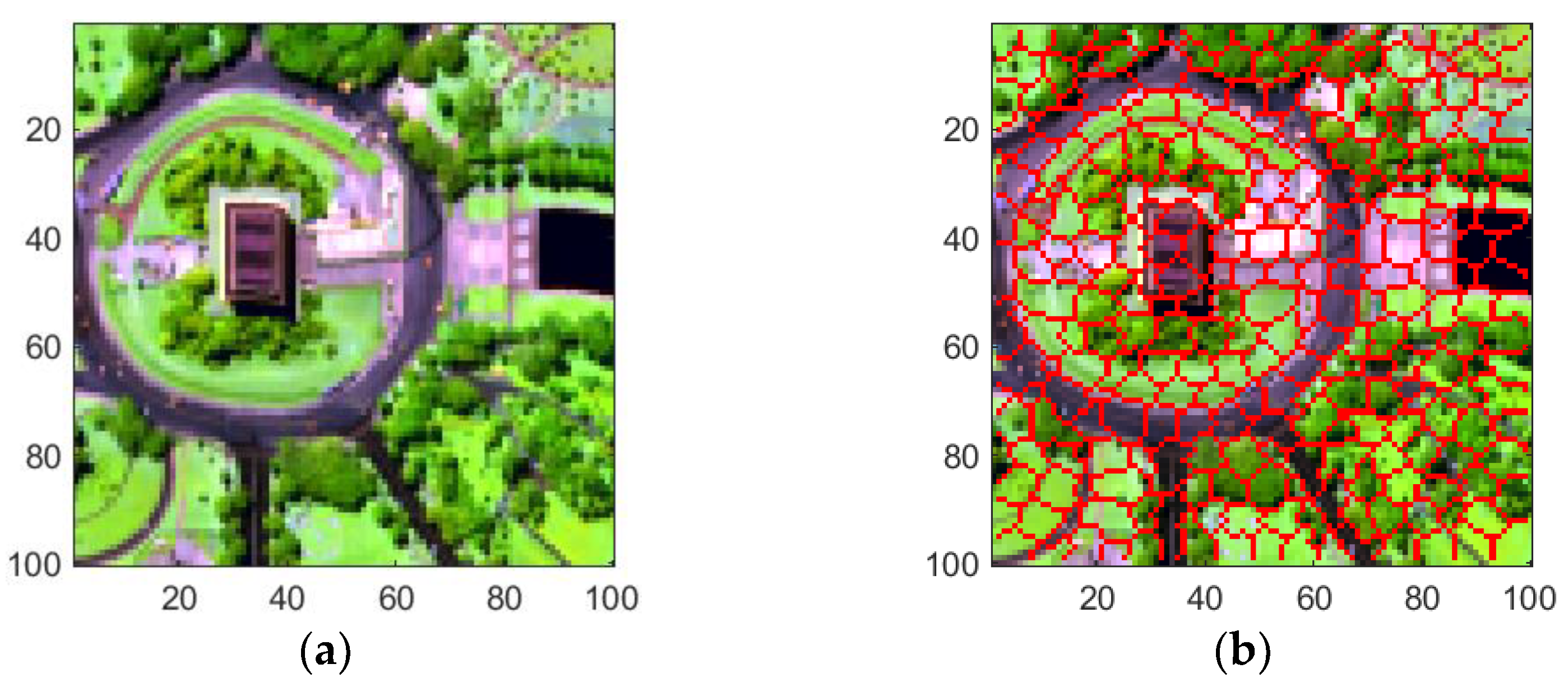
3.1. Superpixel-Based Fisher Transformation Using Abundance-Driven Dynamic Coarse Classification
3.2. Nonlinear Unmixing Accounting for Spectral Variability
- (1)
- Fisher Regularization term : The transformation matrix should satisfy the Fisher criterion, i.e.,where scatter matrices and are obtained by (10). in (12) guarantees that the transformation can reduce the differences between pixels of the same class and the similarities between different materials. In contrast to traditional Fisher transformation-based methods calculating in a preprocessing step, our proposed method trains it in an iterative unmixing process. Moreover, to facilitate the optimization of , (12) is rewritten as an approximate equivalent form [52,53]:where denotes the t th column vector of and is a small constant used to balance the contributions of and .
- (2)
- TV Smoothness Regularization term : In natural scenarios of hyperspectral data, the spatial distribution of land covers is often considered to be piecewise smooth, i.e., abundances of neighboring pixels in local homogeneous regions are similar. In this sense, the total variation (TV) regularization term [54] is further introduced to exploit the HSIs’ spatial information and improve the smoothness of estimated abundances, which can be formulated using:where is an operator utilized to calculate the differences between a given pixel and its four neighboring pixels (i.e., pixels on the top, bottom, left, and right). Notably, the settings of parameters , , and can depend on applications and the spatial-spectral structures of data for different observed scenarios.
3.3. Alternating Update of Unmixing Variables via Multi-Swarm PSO
| Algorithm 1: Fisher transformation-based unmixing algorithm via particle swarm optimization (FTUPSO) |
| Input: Hyperspectral image , parameters , , and . |
| Output: Endmember matrix , abundance matrix , transformation matrix , and bilinear parameter vector . Initialization: 1: Perform the SLIC method on to obtain superpixels. |
| 2: Generate four swarms, , , , and , and initialize the particles’ positions in the swarms and set the particle’s velocities as zeros, and determine the global best positions, , , , and ; . |
| 3: While, perform |
|
| End |
| 4: Output , , , and . |
4. Experiments and Results
4.1. Evaluation Metrics
4.2. Synthetic Data Experiments
- (1)
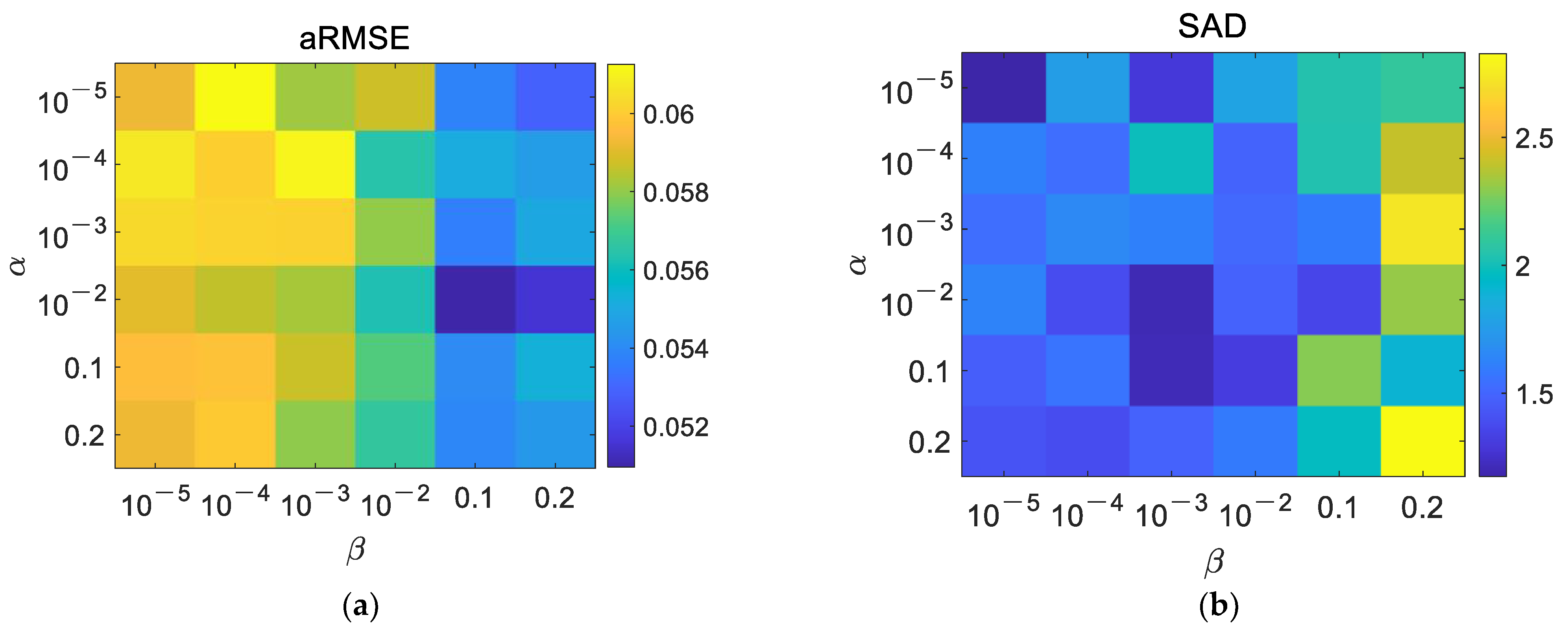
- Parameters’ Settings
- (2)
- Ablation Experimental Analysis
- (3)
- Noise Robustness Analysis
- (4)
- Sensitivity Analysis to the Number of Endmembers
- (5)
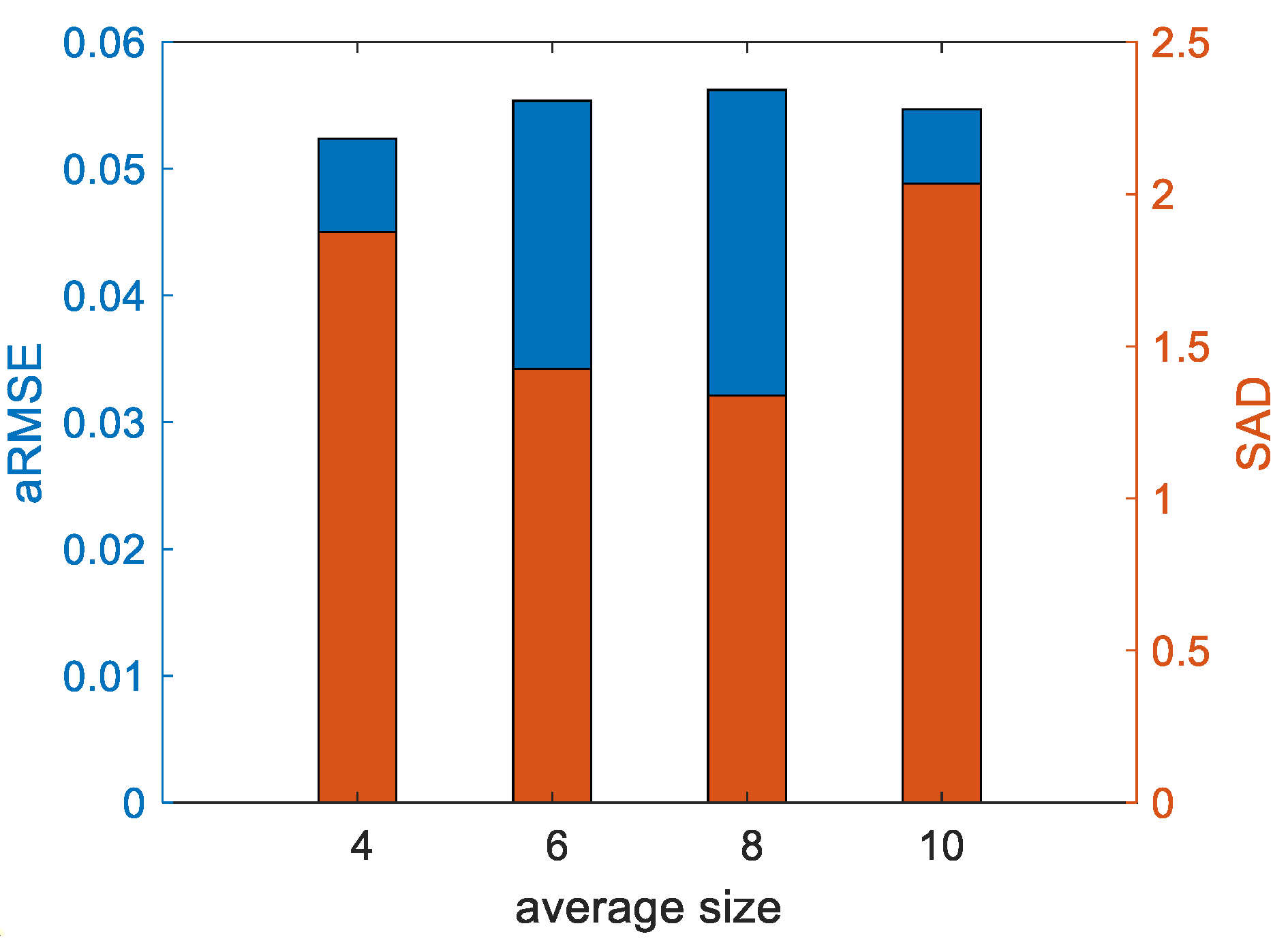
- Sensitivity Analysis to the Number of Pixels
- (6)
- Convergence Analysis and Time Cost Comparison
4.3. Real Hyperspectral Data Experiments
- (1)
- Washington DC Mall Dataset
- (2)
- Cuprite Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ying, J.; Shen, H.; Cao, S. Unaligned hyperspectral image fusion via registration and interpolation modeling. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5511114. [Google Scholar] [CrossRef]
- He, W.; Yokoya, N.; Yuan, X. Fast hyperspectral image recovery of dual-camera compressive hyperspectral imaging via non-iterative subspace-based fusion. IEEE Trans. Image Process. 2021, 30, 7170–7183. [Google Scholar] [CrossRef] [PubMed]
- Dong, W.; Zhou, C.; Wu, F.; Wu, J.; Shi, G.; Li, X. Model-guided deep hyperspectral image super-resolution. IEEE Trans. Image Process. 2021, 30, 5754–5768. [Google Scholar] [CrossRef] [PubMed]
- Song, M.; Yu, C.; Xie, H.; Chang, C.-I. Progressive band selection processing of hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1762–1766. [Google Scholar] [CrossRef]
- Shang, X.; Song, M.; Wang, Y.; Yu, C.; Yu, H.; Li, F.; Chang, C.-I. Target-constrained interference-minimized band selection for hyperspectral target detection. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6044–6064. [Google Scholar] [CrossRef]
- Keshava, N.; Mustard, J.F. Spectral unmixing. IEEE Signal Process. Mag. 2002, 19, 44–57. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Dobigeon, N.; Parente, M.; Du, Q.; Gader, P.; Chanussot, J. Hyperspectral unmixing overview: Geometrical, statistical, and sparse regression-based approaches. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2012, 5, 354–379. [Google Scholar] [CrossRef]
- Feng, X.; Li, H.; Li, J.; Du, Q.; Plaza, A.; Emery, W.J. Hyperspectral unmixing using sparsity-constrained deep nonnegative matrix factorization with total variation. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6245–6257. [Google Scholar] [CrossRef]
- Rathnayake, B.; Ekanayake, E.M.M.B.; Weerakoon, K.; Godaliyadda, G.M.R.I.; Ekanayake, M.P.B.; Herath, H.M.V.R. Graph-based blind hyperspectral unmixing via nonnegative matrix factorization. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6391–6409. [Google Scholar] [CrossRef]
- Dong, L.; Yuan, Y.; Lu, X. Spectral–spatial joint sparse NMF for hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2391–2402. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, G.; Li, F.; Deng, C.; Wang, S.; Plaza, A.; Li, J. Spectral-spatial hyperspectral unmixing using nonnegative matrix factorization. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5505713. [Google Scholar] [CrossRef]
- Heylen, R.; Gader, P. Nonlinear spectral unmixing with a linear mixture of intimate mixtures model. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1195–1199. [Google Scholar] [CrossRef]
- Halimi, A.; Altmann, Y.; Dobigeon, N.; Tourneret, J.-Y. Nonlinear unmixing of hyperspectral images using a generalized bilinear model. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4153–4162. [Google Scholar] [CrossRef]
- Altmann, Y.; Halimi, A.; Dobigeon, N.; Tourneret, J.Y. Supervised nonlinear spectral unmixing using a postnonlinear mixing model for hyperspectral imagery. IEEE Trans. Image Process. 2012, 21, 3017–3025. [Google Scholar] [CrossRef]
- Marinoni, A.; Gamba, P. A novel approach for efficient p-linear hyperspectral unmixing. IEEE J. Sel. Topics Signal Process. 2015, 9, 1156–1168. [Google Scholar] [CrossRef]
- Heylen, R.; Scheunders, P. A multilinear mixing model for nonlinear spectral unmixing. IEEE Trans. Geosci. Remote Sens. 2016, 54, 240–251. [Google Scholar] [CrossRef]
- Yang, B.; Wang, B. Band-wise nonlinear unmixing for hyperspectral imagery using an extended multilinear mixing model. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6747–6762. [Google Scholar] [CrossRef]
- Gu, J.; Yang, B.; Wang, B. Nonlinear unmixing for hyperspectral images via kernel-transformed bilinear mixing models. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5520313. [Google Scholar] [CrossRef]
- Li, C.; Li, J.; Sui, C.; Song, R.; Chen, X. Spatial-spectral nonlinear hyperspectral unmixing under complex noise. IEEE Sens. J. 2022, 22, 4338–4346. [Google Scholar] [CrossRef]
- Shahid, K.T.; Schizas, I.D. Unsupervised hyperspectral unmixing via nonlinear autoencoders. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5506513. [Google Scholar] [CrossRef]
- Su, Y.; Xu, X.; Li, J.; Qi, H.; Gamba, P.; Plaza, A. Deep autoencoders with multitask learning for bilinear hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8615–8629. [Google Scholar] [CrossRef]
- Zhao, M.; Wang, M.; Chen, J.; Rahardja, S. Hyperspectral unmixing for additive nonlinear models with a 3-D-CNN autoencoder network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5509415. [Google Scholar] [CrossRef]
- Rasti, B.; Koirala, B.; Scheunders, P. HapkeCNN: Blind nonlinear unmixing for intimate mixtures using hapke model and convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5536315. [Google Scholar] [CrossRef]
- Borsoi, R.A.; Imbiriba, T.; Bermudez, J.C.M.; Richard, C.; Chanussot, J.; Drumetz, L.; Tourneret, J.-Y.; Zare, A.; Jutten, C. Spectral variability in hyperspectral data unmixing: A comprehensive review. IEEE Geosci. Remote Sens. Mag. 2021, 9, 223–270. [Google Scholar] [CrossRef]
- Theiler, J.; Ziemann, A.; Matteoli, S.; Diani, M. Spectral variability of remotely sensed target materials: Causes, models, and strategies for mitigation and robust exploitation. IEEE Geosci. Remote Sens. Mag. 2019, 7, 8–30. [Google Scholar] [CrossRef]
- Zhang, C.; Ma, L.; Chen, J.; Rao, Y.; Zhou, Y.; Chen, X. Assessing the impact of endmember variability on linear spectral mixture analysis (LSMA): A theoretical and simulation analysis. Remote Sens. Environ. 2019, 235, 111471–111491. [Google Scholar] [CrossRef]
- Haavardsholm, T.V.; Skauli, T.; Kasen, I. A physics-based statistical signature model for hyperspectral target detection. In Proceedings of the 2007 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Barcelona, Spain, 23–28 July 2007; pp. 3198–3201. [Google Scholar]
- Cochrane, M.A. Using vegetation reflectance variability for species level classification of hyperspectral data. Int. J. Remote Sens. 2010, 21, 2075–2087. [Google Scholar] [CrossRef]
- Zhang, J.; Rivard, B.; Sánchez-Azofeifa, A.; Castro-Esau, K. Intra- and inter-class spectral variability of tropical tree species at la selva, costa rica: Implications for species identification using hydice imagery. Remote Sens. Environ. 2006, 105, 129–141. [Google Scholar] [CrossRef]
- Zare, A.; Ho, K.C. Endmember variability in hyperspectral analysis: Addressing spectral variability during spectral unmixing. IEEE Signal Process. Mag. 2014, 31, 95–104. [Google Scholar] [CrossRef]
- Roberts, D.A.; Gardner, M.; Church, R.; Ustin, S.; Scheer, G.; Green, R.O. Mapping chaparral in the Santa Monica Mountains using multiple endmember spectral mixture models. Remote Sens. Environ. 1998, 65, 267–279. [Google Scholar] [CrossRef]
- Heylen, R.; Zare, A.; Gader, P.; Scheunders, P. Hyperspectral unmixing with endmember variability via alternating angle minimization. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4983–4993. [Google Scholar] [CrossRef]
- Thouvenin, P.-A.; Dobigeon, N.; Tourneret, J.-Y. Hyperspectral unmixing with spectral variability using a perturbed linear mixing model. IEEE Trans. Signal Process. 2016, 64, 525–538. [Google Scholar] [CrossRef]
- Drumetz, L.; Veganzones, M.A.; Henrot, S.; Phlypo, R.; Chanussot, J.; Jutten, C. Blind hyperspectral unmixing using an extended linear mixing model to address spectral variability. IEEE Trans. Image Process. 2016, 25, 3890–3905. [Google Scholar] [CrossRef] [PubMed]
- Drumetz, L.; Chanussot, J.; Iwasaki, A. Endmembers as directional data for robust material variability retrieval in hyperspectral image unmixing. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 3404–3408. [Google Scholar]
- Borsoi, R.A.; Imbiriba, T.; Bermudez, J.C.M. A data dependent multiscale model for hyperspectral unmixing with spectral variability. IEEE Trans. Image Process. 2020, 29, 3638–3651. [Google Scholar] [CrossRef] [PubMed]
- Hong, D.; Yokoya, N.; Chanussot, J.; Zhu, X.X. An augmented linear mixing model to address spectral variability for hyperspectral unmixing. IEEE Trans. Image Process. 2018, 28, 1923–1938. [Google Scholar] [CrossRef]
- Hong, D.; Zhu, X.X. SULoRA: Subspace unmixing with low-rank attribute embedding for hyperspectral data analysis. IEEE J. Sel. Top. Signal Process. 2018, 12, 1351–1363. [Google Scholar] [CrossRef]
- Belhumeur, P.N.; Hespanha, J.P.; Kriegman, D.J. Eigenfaces vs. Fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef]
- Jin, J.; Wang, B.; Zhang, L. A novel approach based on fisher discriminant null space for decomposition of mixed pixels in hyperspectral imagery. IEEE Geosci. Remote Sens. Lett. 2010, 7, 699–703. [Google Scholar] [CrossRef]
- Liu, M.; Yang, W.; Chen, J.; Chen, X. An orthogonal fisher transformation-based unmixing method toward estimating fractional vegetation cover in semiarid areas. IEEE Geosci. Remote Sens. Lett. 2017, 14, 449–453. [Google Scholar] [CrossRef]
- Xu, F.; Cao, X.; Chen, X.; Somers, B. Mapping impervious surface fractions using automated fisher transformed unmixing. Remote Sens. Environ. 2019, 232, 111311–111324. [Google Scholar] [CrossRef]
- Zhao, M.; Shi, S.; Chen, J.; Dobigeon, N. A 3-D-CNN framework for hyperspectral unmixing with spectral variability. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5521914. [Google Scholar] [CrossRef]
- Shi, S.; Zhao, M.; Zhang, L.; Altmann, Y.; Chen, J. Probabilistic generative model for hyperspectral unmixing accounting for endmember variability. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5516915. [Google Scholar] [CrossRef]
- Shi, S.; Zhang, L.; Altmann, Y.; Chen, J. Deep generative model for spatial–spectral unmixing with multiple endmember priors. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5527214. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yao, J.; Yokoya, N.; Chanussot, J.; Heiden, U.; Zhang, B. Endmember-guided unmixing network (EGU-net): A general deep learning framework for self-supervised hyperspectral unmixing. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6518–6531. [Google Scholar] [CrossRef] [PubMed]
- Yang, B. Supervised nonlinear hyperspectral unmixing with automatic shadow compensation using multiswarm particle swarm optimization. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5529618. [Google Scholar] [CrossRef]
- Drumetz, L.; Chanussot, J.; Jutten, C. Spectral unmixing: A derivation of the extended linear mixing model from the hapke model. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1866–1870. [Google Scholar] [CrossRef]
- Yang, B.; Luo, W.; Wang, B. Constrained nonnegative matrix factorization based on particle swarm optimization for hyperspectral unmixing. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2017, 10, 3693–3710. [Google Scholar] [CrossRef]
- Chen, J.; Richard, C.; Honeine, P. Nonlinear estimation of material abundances in hyperspectral images with l1-norm spatial regularization. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2654–2665. [Google Scholar] [CrossRef]
- Wang, X.; Zhong, Y.; Zhang, L.; Xu, Y. Spatial group sparsity regularized nonnegative matrix factorization for hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6287–6304. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, G.; Pu, J.; Wang, X.; Wang, H. Orthogonal sparse linear discriminant analysis. Int. J. Syst. Sci. 2018, 49, 848–858. [Google Scholar] [CrossRef]
- Wen, J.; Fang, X.; Cui, J.; Fei, L.; Yan, K.; Chen, Y.; Xu, Y. Robust sparse linear discriminant analysis. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 390–403. [Google Scholar] [CrossRef]
- Iordache, M.-D.; Bioucas-Dias, J.M.; Plaza, A. Total variation spatial regularization for sparse hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2012, 50, 4484–4502. [Google Scholar] [CrossRef]
- Poli, R.; Kennedy, J.; Blackwell, T. Particle swarm optimization. Swarm Intell. 2007, 1, 33–57. [Google Scholar] [CrossRef]
- Tong, L.; Du, B.; Liu, R.; Zhang, L. An improved multiobjective discrete particle swarm optimization for hyperspectral endmember extraction. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7872–7882. [Google Scholar] [CrossRef]
- Miao, Y.; Yang, B. Multilevel reweighted sparse hyperspectral unmixing using superpixel segmentation and particle swarm optimization. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6013605. [Google Scholar] [CrossRef]
- Nascimento, J.M.P.; Dias, J.M.B. Vertex component analysis: A fast algorithm to unmix hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 898–910. [Google Scholar] [CrossRef]
- Heinz, D.C.; Chein, I.C. Fully constrained least squares linear spectral mixture analysis method for material quantification in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2001, 39, 529–545. [Google Scholar] [CrossRef]
- Zhuang, L.; Lin, C.-H.; Figueiredo, M.A.T.; Bioucas-Dias, J.M. Regularization parameter selection in minimum volume hyperspectral unmixing. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9858–9877. [Google Scholar] [CrossRef]
- Wei, Q.; Chen, M.; Tourneret, J.-Y.; Godsill, S. Unsupervised nonlinear spectral unmixing based on a multilinear mixing model. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4534–4544. [Google Scholar] [CrossRef]
- Eches, O.; Guillaume, M. A bilinear–bilinear nonnegative matrix factorization method for hyperspectral unmixing. IEEE Geosci. Remote Sens. Lett. 2014, 11, 778–782. [Google Scholar] [CrossRef]
- Drumetz, L.; Ehsandoust, B.; Chanussot, J.; Rivet, B.; Babaie-Zadeh, M.; Jutten, C. Relationships between nonlinear and space-variant linear models in hyperspectral image unmixing. IEEE Signal Process Lett. 2017, 24, 1567–1571. [Google Scholar] [CrossRef]
- Chang, C.I.; Du, Q. Estimation of number of spectrally distinct signal sources in hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2004, 42, 608–619. [Google Scholar] [CrossRef]
- Biggar, S.F.; Thome, K.J.; Wisniewski, W. Vicarious radiometric calibration of EO-1 sensors by reference to high-reflectance ground targets. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1174–1179. [Google Scholar] [CrossRef]
- Zhuang, L.; Ng, M.K.; Liu, Y. Cross-track illumination correction for hyperspectral pushbroom sensor images using low-rank and sparse representations. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5502117. [Google Scholar] [CrossRef]
- San, B.T.; Süzen, M.L. Evaluation of cross-track illumination in EO-1 Hyperion imagery for lithological mapping. Int. J. Remote Sens. 2011, 32, 7873–7889. [Google Scholar] [CrossRef]
- Datt, B.; McVicar, T.R.; Van Niel, T.G.; Jupp, D.L.B.; Pearlman, J.S. Preprocessing EO-1 Hyperion hyperspectral data to support the application of agricultural indexes. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1246–1259. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
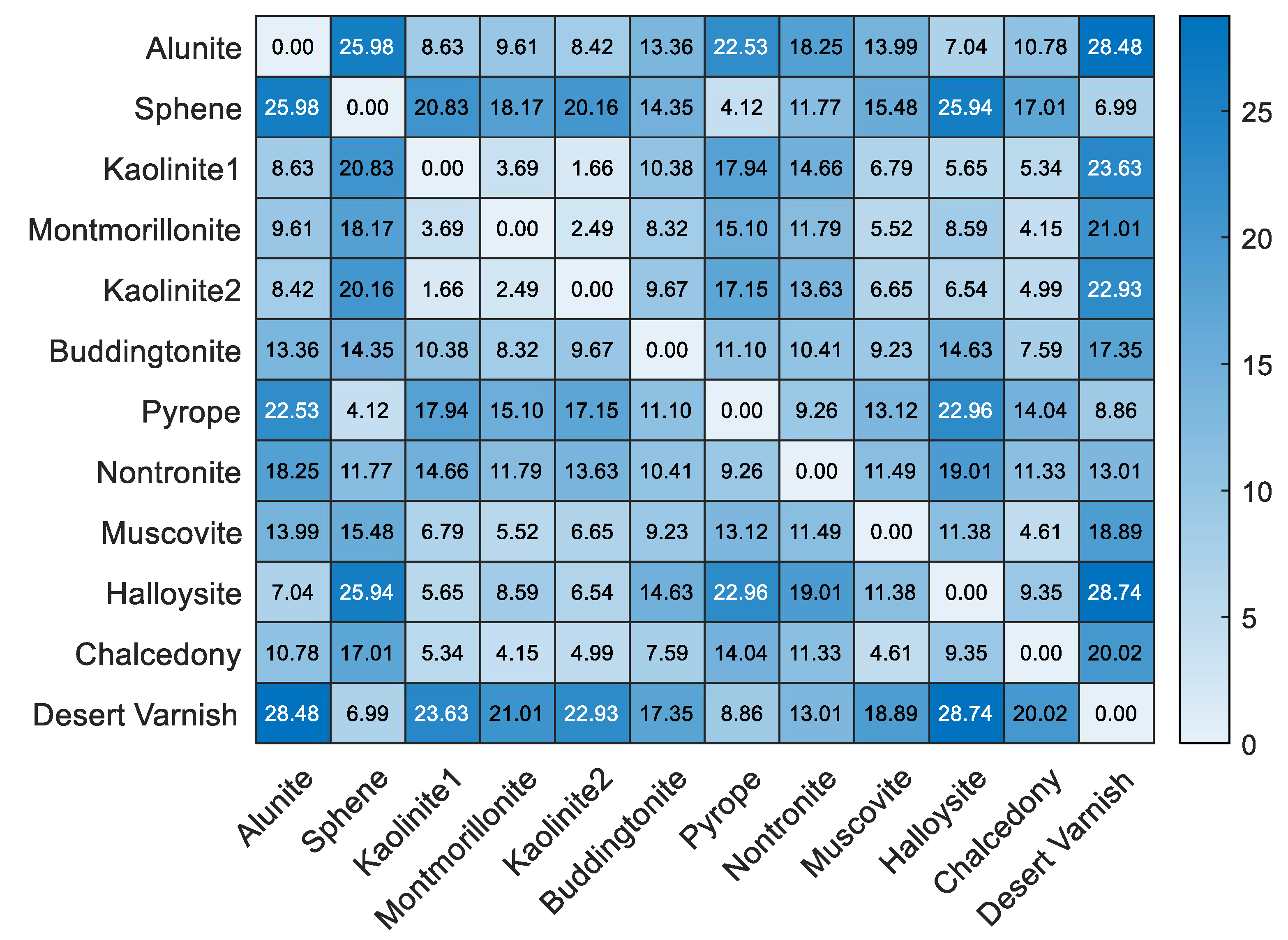{kind=link}
{kind=link}
{kind=link}
| Metrics | aRMSE | SAD |
|---|---|---|
| PSO | 0.0724 ± 0.0270 | 3.6999 ± 2.8524 |
| PSO + TV | 0.0675 ± 0.0244 | 3.1646 ± 2.4182 |
| PSO + TV + Fisher | 0.0551 ± 0.0160 | 2.5460 ± 2.0137 |
| PSO + TV + Fisher + Superpixel | 0.0529 ± 0.0100 | 1.7551 ± 0.6397 |
| SNR | 30 dB | 40 dB | 50 dB | |||
|---|---|---|---|---|---|---|
| aRMSE | SAD | aRMSE | SAD | aRMSE | SAD | |
| VCA + FCLS | 0.1235 ± 0.0277 | 5.0554 ± 1.0975 | 0.1175 ± 0.0250 | 4.8533 ± 0.2147 | 0.1273 ± 0.0294 | 5.3393 ± 0.8503 |
| NMF_QMV | 0.1136 ± 0.0104 | 10.0529 ± 2.1945 | 0.1120 ± 0.0105 | 10.3264 ± 1.5705 | 0.1145 ± 0.0087 | 10.6626 ± 2.1452 |
| SULoRA | 0.0876 ± 0.0200 | - | 0.0853 ± 0.0060 | - | 0.0956 ± 0.0220 | - |
| ELMM | 0.0858 ± 0.0231 | 4.9727 ± 1.0713 | 0.0720 ± 0.0046 | 4.7724 ± 0.2199 | 0.0872 ± 0.0230 | 5.2443 ± 0.8369 |
| PGMSU | 0.1150 ± 0.0132 | 2.9392 ± 0.4247 | 0.1174 ± 0.0100 | 2.8098 ± 0.6449 | 0.1171 ± 0.0127 | 2.8701 ± 0.6919 |
| PPNM-GDA | 0.1087 ± 0.0139 | - | 0.1035 ± 0.0082 | - | 0.1085 ± 0.0121 | - |
| MLMp | 0.0945 ± 0.0223 | 10.9429 ± 1.9940 | 0.0860 ± 0.0187 | 6.1948 ± 0.4053 | 0.0967 ± 0.0253 | 6.1932 ± 0.5542 |
| Fan_NMF | 0.1090 ± 0.0190 | 3.3978 ± 0.7028 | 0.1085 ± 0.0173 | 3.4620 ± 0.5106 | 0.1139 ± 0.0155 | 3.5118 ± 0.6926 |
| FTUPSO | 0.0646 ± 0.0174 | 2.4315 ± 1.0783 | 0.0553 ± 0.0113 | 1.9133 ± 0.6487 | 0.0668 ± 0.0183 | 2.8610 ± 1.5002 |
| Endmembers’ Numbers | 3 | 4 | 5 | |||
|---|---|---|---|---|---|---|
| aRMSE | SAD | aRMSE | SAD | aRMSE | SAD | |
| VCA + FCLS | 0.1175 ± 0.0250 | 4.8533 ± 0.2147 | 0.1182 ± 0.0127 | 4.7575 ± 0.3368 | 0.1349 ± 0.0251 | 4.6193 ± 0.4725 |
| NMF_QMV | 0.1120 ± 0.0105 | 10.3264 ± 1.5705 | 0.2208 ± 0.0305 | 11.8767 ± 8.7074 | 0.1533 ± 0.0173 | 4.6940 ± 2.0134 |
| SULoRA | 0.0853 ± 0.0060 | - | 0.0924 ± 0.0080 | - | 0.1028 ± 0.0219 | - |
| ELMM | 0.0720 ± 0.0046 | 4.7724 ± 0.2199 | 0.1138 ± 0.0159 | 4.6558 ± 0.3446 | 0.1048 ± 0.0130 | 4.5240 ± 0.4673 |
| PGMSU | 0.1174 ± 0.0100 | 2.8098 ± 0.6449 | 0.1516 ± 0.0180 | 4.4599 ± 0.8600 | 0.1587 ± 0.0115 | 5.7992 ± 0.7512 |
| PPNM-GDA | 0.1035 ± 0.0082 | - | 0.1019 ± 0.0071 | - | 0.0897 ± 0.0080 | - |
| MLMp | 0.0860 ± 0.0187 | 6.1948 ± 0.4053 | 0.1025 ± 0.0141 | 6.5597 ± 0.6135 | 0.1238 ± 0.0254 | 4.9190 ± 0.5242 |
| Fan_NMF | 0.1085 ± 0.0173 | 3.4620 ± 0.5106 | 0.0948 ± 0.0083 | 3.3640 ± 0.6885 | 0.1134 ± 0.0262 | 3.6232 ± 0.4499 |
| FTUPSO | 0.0553 ± 0.0113 | 1.9133 ± 0.6487 | 0.0845 ± 0.0102 | 3.2964 ± 0.5120 | 0.0877 ± 0.0108 | 2.9669 ± 0.6588 |
| Pixels’ Numbers | 32 | 48 | 64 | |||
|---|---|---|---|---|---|---|
| aRMSE | SAD | aRMSE | SAD | aRMSE | SAD | |
| VCA + FCLS | 0.1175 ± 0.0250 | 4.8533 ± 0.2147 | 0.1340 ± 0.0214 | 4.8910 ± 0.2676 | 0.1124 ± 0.0126 | 4.8456 ± 0.4261 |
| NMF_QMV | 0.1120 ± 0.0105 | 10.3264 ± 1.5705 | 0.1144 ± 0.0095 | 9.9620 ± 2.6018 | 0.1230 ± 0.0149 | 10.6720 ± 2.2458 |
| SULoRA | 0.0853 ± 0.0060 | - | 0.0930 ± 0.0061 | - | 0.0866 ± 0.0063 | - |
| ELMM | 0.0720 ± 0.0046 | 4.7724 ± 0.2199 | 0.0792 ± 0.0096 | 4.8209 ± 0.2769 | 0.0768 ± 0.0074 | 4.7691 ± 0.4242 |
| PGMSU | 0.1174 ± 0.0100 | 2.8098 ± 0.6449 | 0.1214 ± 0.0124 | 2.8836 ± 0.7589 | 0.1250 ± 0.0182 | 2.9379 ± 0.6014 |
| PPNM-GDA | 0.1035 ± 0.0082 | - | 0.1045 ± 0.0082 | - | 0.1006 ± 0.0050 | - |
| MLMp | 0.0860 ± 0.0187 | 6.1948 ± 0.4053 | 0.0991 ± 0.0149 | 5.9899 ± 0.3767 | 0.0836 ± 0.0110 | 6.3783 ± 0.7071 |
| Fan_NMF | 0.1085 ± 0.0173 | 3.4620 ± 0.5106 | 0.1238 ± 0.0138 | 3.7635 ± 0.7783 | 0.1034 ± 0.0119 | 3.6131 ± 0.6002 |
| FTUPSO | 0.0553 ± 0.0113 | 1.9133 ± 0.6487 | 0.0698 ± 0.0111 | 2.8147 ± 0.8162 | 0.0576 ± 0.0079 | 2.1379 ± 0.7995 |
| Execution Time | Number of Endmembers | Number of Pixels | ||||
|---|---|---|---|---|---|---|
| 3 | 4 | 5 | 32 | 48 | 64 | |
| VCA + FCLS | 0.0434 | 0.0470 | 0.0696 | 0.0326 | 0.0650 | 0.1220 |
| NMF_QMV | 0.2431 | 0.2881 | 0.3406 | 0.2606 | 0.4014 | 0.6931 |
| SULoRA | 0.3645 | 0.3920 | 0.3853 | 0.3746 | 0.5447 | 0.7816 |
| ELMM | 8.0922 | 14.6351 | 18.7209 | 8.0323 | 21.8451 | 31.3933 |
| PGMSU | 15.7060 | 14.5231 | 14.6889 | 14.1952 | 15.7322 | 17.5270 |
| PPNM-GDA | 1.7015 | 4.9834 | 6.2781 | 1.6025 | 3.4623 | 7.7735 |
| MLMp | 2.1957 | 12.3033 | 8.6232 | 2.0675 | 4.5887 | 4.8350 |
| Fan_NMF | 3.4285 | 2.1612 | 2.9618 | 3.6760 | 6.1072 | 20.9294 |
| FTUPSO | 110.7060 | 109.8231 | 100.7271 | 111.5885 | 238.9956 | 416.8989 |
| Metrics | Washington | Cuprite | ||||
|---|---|---|---|---|---|---|
| RE | SRE | Time | RE | SRE | Time | |
| VCA + FCLS | 0.0314 | 18.7345 | 0.7015 | 0.0082 | 33.0812 | 7.0573 |
| NMF_QMV | 0.0277 | 20.2062 | 1.6970 | 0.0440 | 19.1431 | 33.7064 |
| SULoRA | 0.0511 | 15.1141 | 0.7667 | 0.0981 | 13.3269 | 4.4248 |
| ELMM | 0.0047 | 35.5494 | 175.6399 | 0.0039 | 39.5010 | 770.7104 |
| PGMSU | 0.0096 | 29.4179 | 21.4256 | 0.0067 | 34.8311 | 60.6150 |
| PPNM-GDA | 0.0105 | 28.5890 | 63.4661 | 0.0059 | 35.8866 | 226.6430 |
| MLMp | 0.0121 | 27.4003 | 61.4246 | 0.0061 | 35.6612 | 53.2769 |
| Fan_NMF | 0.0090 | 29.9461 | 4.6028 | 0.0058 | 36.0014 | 84.9318 |
| FTUPSO | 0.0062 | 33.1701 | 762.0527 | 0.0039 | 39.5066 | 3484.3585 |
| Endmember | VCA | NMF_QMV | ELMM | PGMSU | MLMp | Fan_NMF | FTUPSO |
|---|---|---|---|---|---|---|---|
| Alunite | 5.0488 | 5.4230 | 5.0521 | 4.9842 | 5.0003 | 5.0614 | 3.8052 |
| Sphene | 3.4584 | 4.7743 | 3.4484 | 3.1775 | 3.5226 | 3.1221 | 4.4041 |
| Kaolinite1 | 10.3671 | 12.8995 | 10.3774 | 9.8591 | 10.5428 | 10.1228 | 12.6660 |
| Montmorillonite | 6.3181 | 7.0085 | 6.3290 | 9.0302 | 6.6698 | 6.8224 | 7.3845 |
| Kaolinite2 | 13.1916 | 10.3799 | 13.2048 | 15.8814 | 13.4972 | 12.8346 | 14.1055 |
| Buddingtonite | 6.2326 | 8.3854 | 6.2354 | 6.4710 | 6.2613 | 5.3374 | 6.5042 |
| Pyrope | 3.9504 | 7.3195 | 3.9129 | 2.6020 | 3.5621 | 3.4190 | 3.1795 |
| Nontronite | 5.1284 | 5.6919 | 5.1100 | 6.7004 | 5.0699 | 5.4248 | 4.9914 |
| Muscovite | 4.9336 | 5.7971 | 4.9339 | 7.7099 | 4.9387 | 4.9679 | 4.8148 |
| Halloysite | 19.2877 | 24.2131 | 19.2886 | 16.4654 | 19.2655 | 18.1978 | 19.8161 |
| Chalcedony | 7.7124 | 5.3233 | 7.7337 | 8.6724 | 7.9504 | 7.0210 | 8.5571 |
| Desert Varnish | 12.8298 | 11.5568 | 12.8295 | 13.0414 | 13.0119 | 13.6539 | 12.9964 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, Z.; Yang, B. Unsupervised Nonlinear Hyperspectral Unmixing with Reduced Spectral Variability via Superpixel-Based Fisher Transformation. Remote Sens. 2023, 15, 5028. https://doi.org/10.3390/rs15205028
Yin Z, Yang B. Unsupervised Nonlinear Hyperspectral Unmixing with Reduced Spectral Variability via Superpixel-Based Fisher Transformation. Remote Sensing. 2023; 15(20):5028. https://doi.org/10.3390/rs15205028
Chicago/Turabian StyleYin, Zhangqiang, and Bin Yang. 2023. "Unsupervised Nonlinear Hyperspectral Unmixing with Reduced Spectral Variability via Superpixel-Based Fisher Transformation" Remote Sensing 15, no. 20: 5028. https://doi.org/10.3390/rs15205028
APA StyleYin, Z., & Yang, B. (2023). Unsupervised Nonlinear Hyperspectral Unmixing with Reduced Spectral Variability via Superpixel-Based Fisher Transformation. Remote Sensing, 15(20), 5028. https://doi.org/10.3390/rs15205028