



Feature Relation Guided Cross-View Image Based Geo-Localization



Abstract
:1. Introduction
- (1)
- We propose a cross-view image based geo-localization method based on feature relation guidance. Feature position reweighting is guided by learning the location layout and spatial structure among the image features. Simultaneously, deformable convolution is introduced to reduce the geometric deformation of ground and aerial remote sensing images. This is the first cross-view image based geo-localization method that attempts to solve the effect of geometric distortion.
- (2)
- Multiscale contextual information extraction based on deformable convolution and a global relations jointly guided attention generation module is designed. The module extracts multiscale contextual information of images according to the deformable convolution with different convolution kernel sizes, simultaneously achieving relation mining between different feature nodes using global relations awareness, and guiding attention generation according to these two relations. Consequently, a feature descriptor jointly characterized by contextual information and global relations is obtained, which enhances the discriminability of the image features.
- (3)
- The method proposed in this study outperforms other methods of the same type on a public dataset and shows good accuracy results. We also attempt to study the practicality of cross-view image based geo-localization methods by testing several public algorithms on a self-built dataset.
2. Related Work
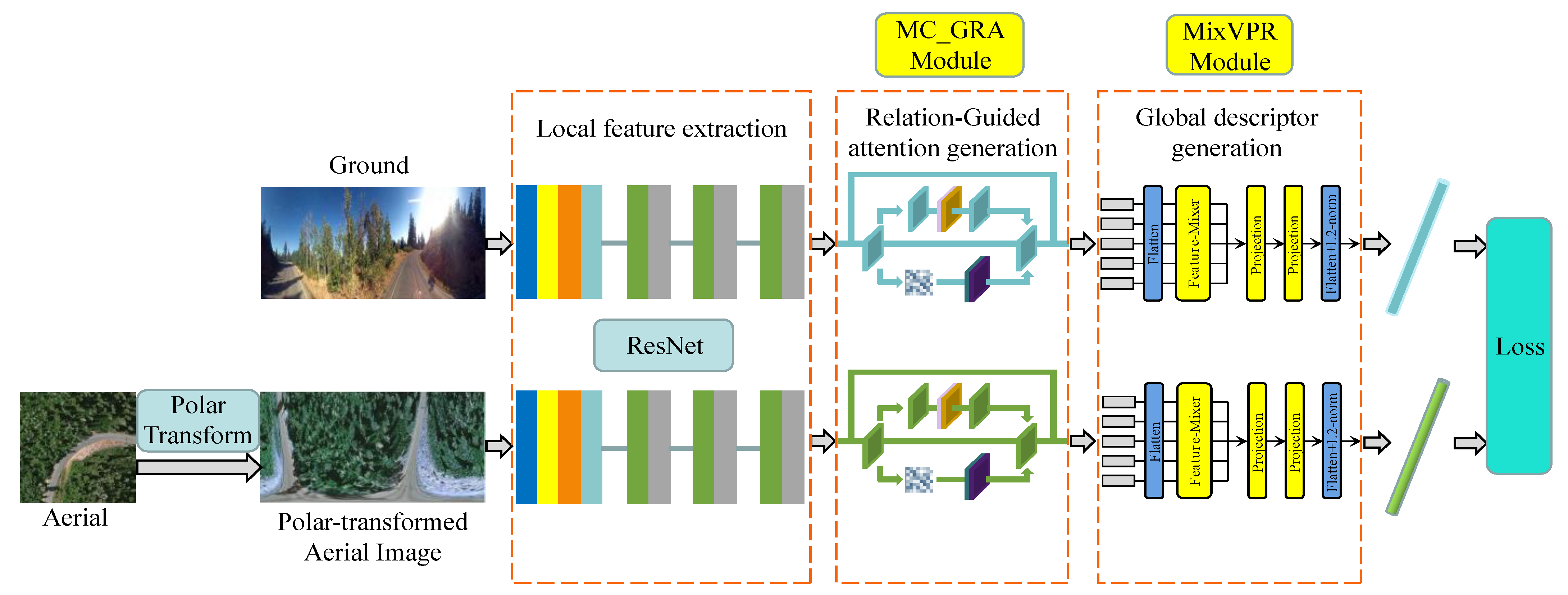
3. Methods
3.1. Polar Transform
3.2. Multiscale Contextual Information and Global Relations Jointly Guide the Attention Generation Module
3.2.1. Multiscale Contextual Information Extraction Based on Deformable Convolution
3.2.2. Global Relations Mining Module
3.2.3. Relation Guided Attention Generation
3.3. Feature Aggregation Strategy
3.4. Weighted Soft-Margin Triplet Loss
4. Experiments
4.1. Datasets
4.2. Experimental Details
4.3. Evaluation Metric
5. Experimental Results
5.1. Comparison with the Results of Other Related Methods
- (1)
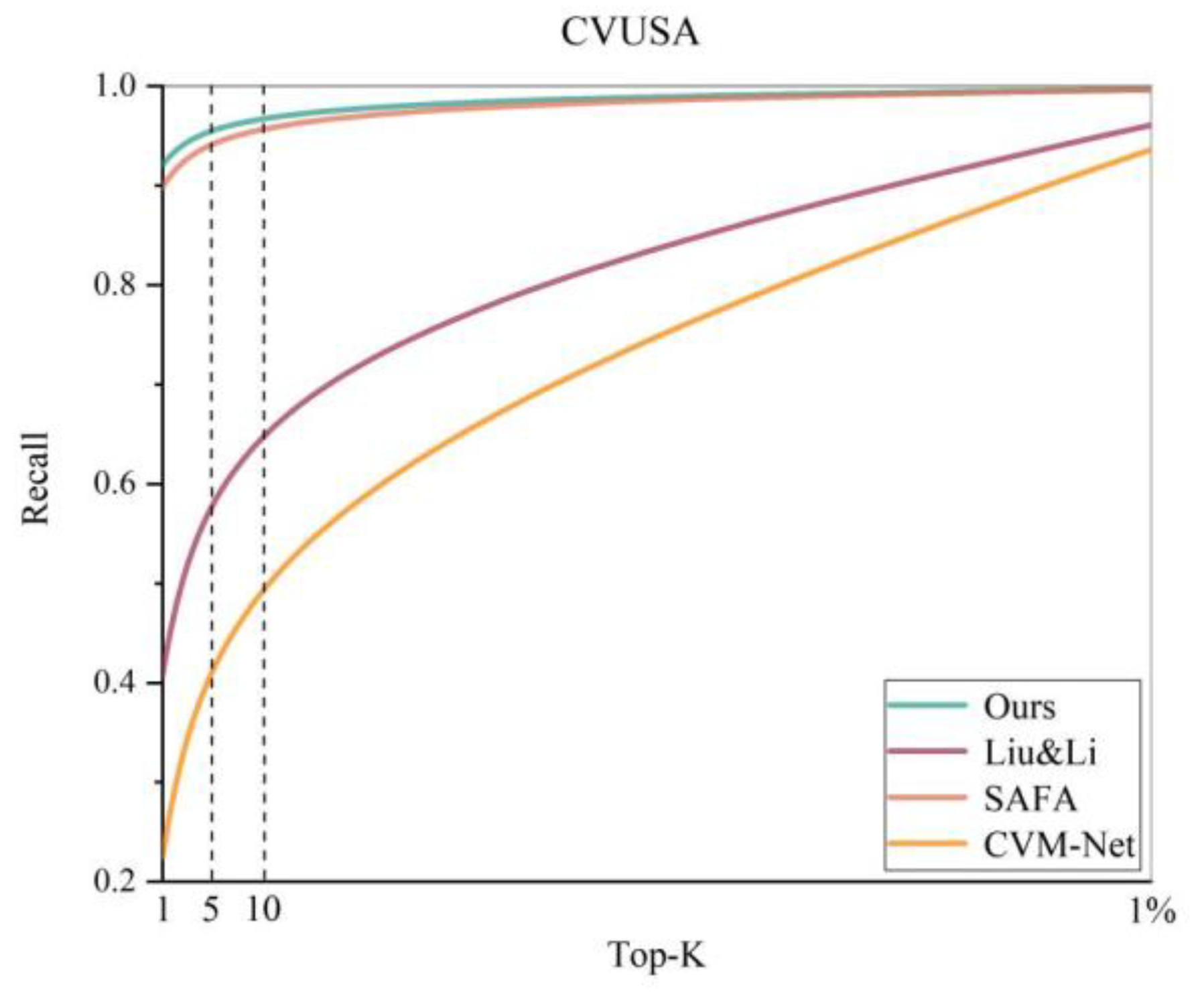
- Results in the CVUSA dataset: To prove the effectiveness of our proposed method, we utilized several classical algorithms to compare the experimental results in the CVUSA dataset. Among these, CVM-Net [17], as well as those in Workman et al. [36] and Liu and Li [3], are more basic cross-view image based geo-localization algorithms that focus on the construction of the feature extraction network, whereas the algorithm by Cai et al. [21] added a spatial attention mechanism, proving the beneficial role of the attention mechanism in the feature extraction process. However, SAFA [5], DSM [6], and SSA-Net [22] adopt the same polar transform strategy and the idea of an attention mechanism as in this study; therefore, the comparison of the results better highlights the superiority of the present method. The experimental results are listed in Table 1, and Figure 7 shows the complete recall@K plots of the experiments of these cross-view image based geo-localization algorithms. The results show that our algorithm achieves the best results in the top 1, top 5, and top 10 metrics, while the metric top 1% metric is on par with that of the DSM algorithm and slightly lower than that of the SSA-Net algorithm, which is the best in a comprehensive manner.
- (2)
- Results in the VIGOR dataset: As the ground-to-aerial image pairs in the VIGOR dataset are not strictly geo-coordinate center-aligned, the method based on polar transform may not be suitable for processing this dataset. Therefore, we designed two types of experiments for the algorithm based on polar transform processing and directly matched localization. The results are compared in Table 2. For the proposed algorithm, the accuracy of the algorithm with polar transform processing is 13% lower than that of the algorithm with direct image matching in the top 1 metric. However, compared with the SAFA algorithm, the accuracy of our algorithm exceeds its results in both cases, i.e., polar transform processing and directly matched localization. Compared with the official VIGOR algorithm, the accuracy of the proposed algorithm exceeds it in the two indicators, in the top 5 and top 10 metrics. The complete results of the recall@K plot are shown in Figure 8.
- (3)
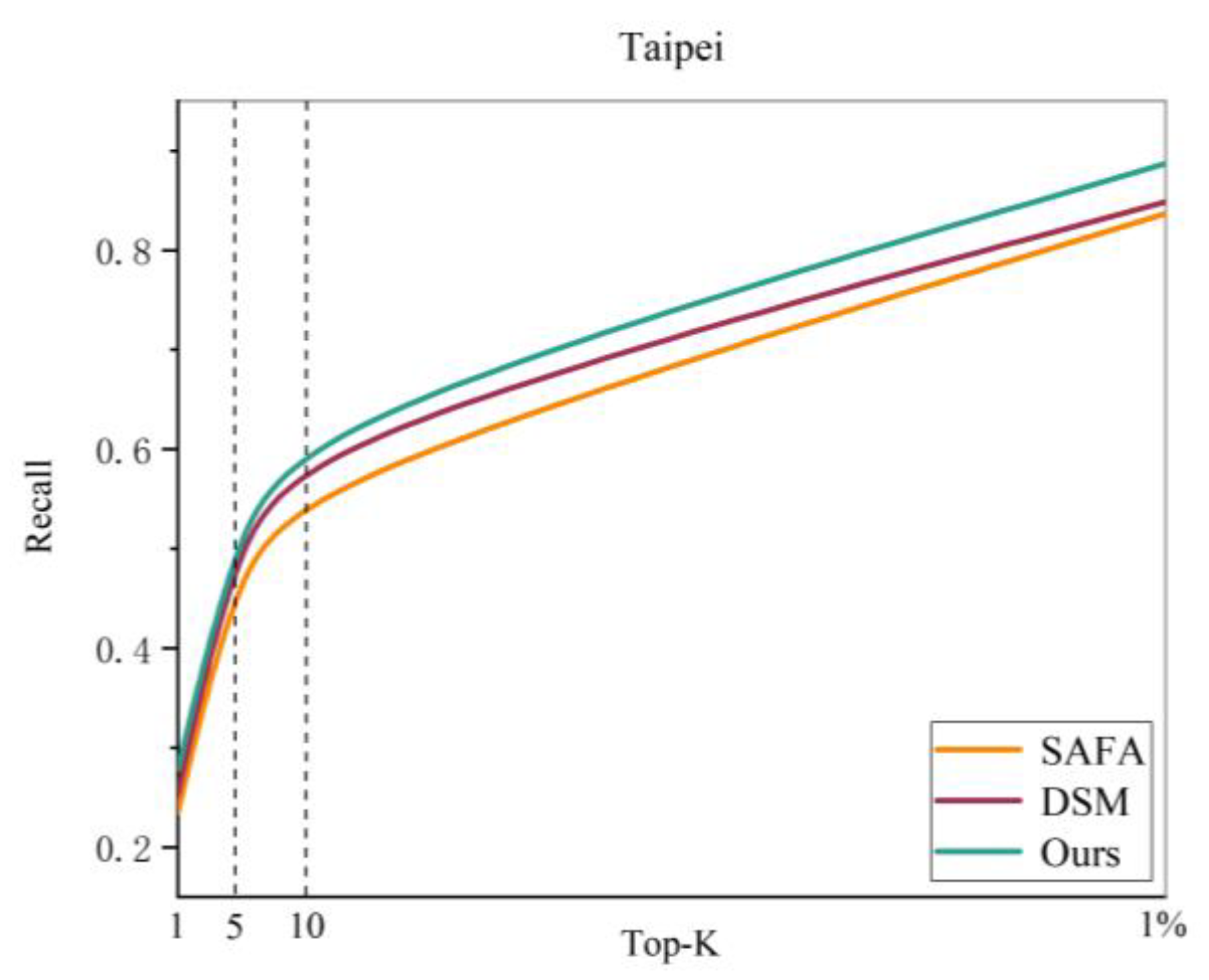
- Results in the Taipei dataset: To verify the practicability of the cross-view image based geo-localization methods, we used a self-built Taipei dataset for testing. The results of this method are compared with those of two widely recognized algorithms of the same type.
5.2. Ablation Experiments
- (1)
- Role of the MC_GRA module: To verify the function of our designed MC_GRA module, we used max pooling and the CBAM attention module to replace the MC_GRA module in the original method. For the case of fixed algorithm parameters, the ground panorama image and aerial remote sensing image from polar transform were used as the network inputs. The results obtained for the CVUSA and VIGOR datasets are listed in Table 4.
- (2)
- Role of deformable convolution: In this algorithm, we innovatively introduce deformable convolution to deal with the deformation caused by the panorama images imaging process and polar transform of the aerial remote sensing image. To verify the role of deformable convolution, we replaced the deformable convolution with a standard convolution of the same size in the MC_GRA module designed in this study, and conducted training and testing on two cross-view image datasets, CVUSA and VIGOR. The results are summarized in Table 5.
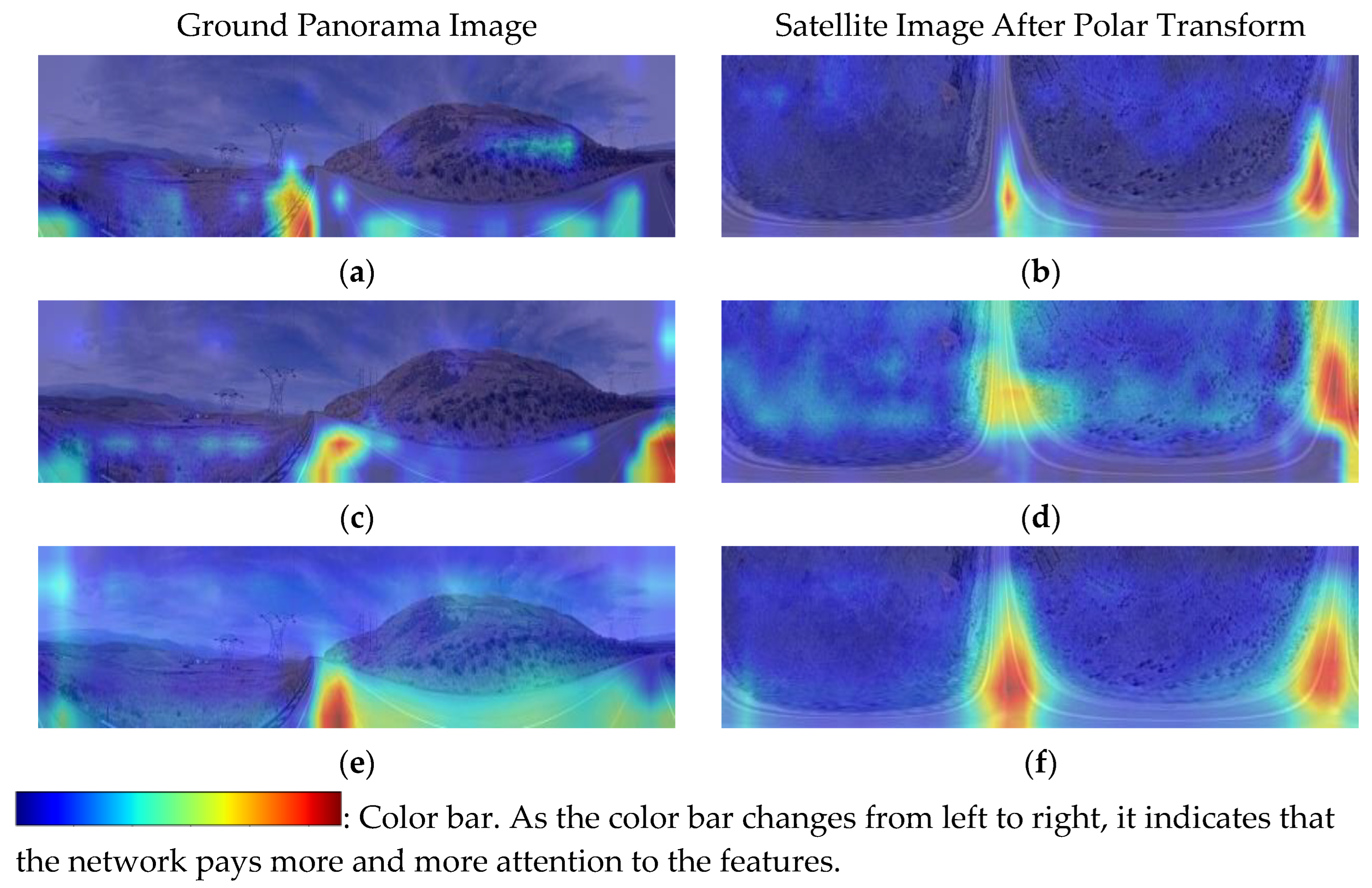
5.3. Visual of Attention
6. Discussion
6.1. Comparison with Other Methods in Different Datasets
6.2. Analysis of Ablation Experiments
6.3. Experimental Analysis of Heat Map Visualization
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MixVPR | Mixing for Visual Place Recognition |
| CVUSA | Cross-View dataset of the United States of America |
| CNN | Convolutional Neural Networks |
| NetVLAD | Vector of Locally Aggregated Descriptors Net |
| MC_GRA | Multiscale Context and Global Relations Attention Module |
| CBAM | Convolutional Block Attention Module |
| VIGOR | Cross-View Image Geo-Localization beyond One-to-One Retrieval |
| Grad-CAM | Gradient-Weighted Class Activation Mapping |
References
- McManus, C.; Churchill, W.; Maddern, W.; Stewart, A.D.; Newman, P. Shady Dealings: Robust, Long-Term Visual Localisation Using Illumination Invariance. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–5 June 2014; pp. 901–906. [Google Scholar]
- Lin, T.-Y.; Yin, C.; Belongie, S.; Hays, J. Learning Deep Representations for Ground-to-Aerial Geolocalization. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5007–5015. [Google Scholar]
- Liu, L.; Li, H. Lending Orientation to Neural Networks for Cross-View Geo-Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 20 June 2019; pp. 5617–5626. [Google Scholar] [CrossRef]
- Tian, Y.; Chen, C.; Shah, M. Cross-View Image Matching for Geo-Localization in Urban Environments. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1998–2006. [Google Scholar]
- Shi, Y.; Liu, L.; Yu, X.; Li, H. Spatial-Aware Feature Aggregation for Cross-View Image Based Geo-Localization. Adv. Neural Inf. Process. Syst. 2019, 32, 10090–10100. [Google Scholar]
- Shi, Y.; Yu, X.; Campbell, D.; Li, H. Where Am I Looking At? Joint Location and Orientation Estimation by Cross-View Matching. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4063–4071. [Google Scholar]
- Shi, Y.; Yu, X.; Liu, L.; Campbell, D.; Koniusz, P.; Li, H. Accurate 3-DoF Camera Geo-Localization via Ground-to-Satellite Image Matching. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2682–2697. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets v2: More Deformable, Better Results. In Proceeding of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9308–9316. [Google Scholar]
- Ali-Bey, A.; Chaib-Draa, B.; Giguere, P. MixVPR: Feature Mixing for Visual Place Recognition. In Proceedings of the 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023; pp. 2997–3006. [Google Scholar]
- Kim, H.J.; Dunn, E.; Frahm, J.-M. Predicting Good Features for Image Geo-Localization Using Per-Bundle VLAD. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1170–1178. [Google Scholar]
- Chen, D.M.; Baatz, G.; Koser, K.; Tsai, S.S.; Vedantham, R.; Pylvanainen, T.; Roimela, K.; Chen, X.; Bach, J.; Pollefeys, M.; et al. City-Scale Landmark Identification on Mobile Devices. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 737–744. [Google Scholar]
- Hutchison, D.; Kanade, T.; Kittler, J.; Kleinberg, J.M.; Mattern, F.; Mitchell, J.C.; Naor, M.; Nierstrasz, O.; Pandu Rangan, C.; Steffen, B.; et al. Accurate Image Localization Based on Google Maps Street View. In Computer Vision—ECCV 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6314, pp. 255–268. ISBN 978-3-642-15560-4. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Workman, S.; Jacobs, N. On the Location Dependence of Convolutional Neural Network Features. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 70–78. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning Deep Features for Scene Recognition Using Places Database. Adv. Neural Inf. Process. 2014, 27, 487–495. [Google Scholar]
- Hu, S.; Feng, M.; Nguyen, R.M.H.; Lee, G.H. CVM-Net: Cross-View Matching Network for Image-Based Ground-to-Aerial Geo-Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7258–7267. [Google Scholar]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5297–5307. [Google Scholar]
- Regmi, K.; Shah, M. Bridging the domain gap for ground-to-aerial image matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 470–479. [Google Scholar]
- Kim, H.J.; Dunn, E.; Frahm, J.-M. Learned Contextual Feature Reweighting for Image Geo-Localization. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3251–3260. [Google Scholar]
- Cai, S.; Guo, Y.; Khan, S.; Hu, J.; Wen, G. Ground-to-Aerial Image Geo-Localization with a Hard Exemplar Reweighting Triplet Loss. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8390–8399. [Google Scholar]
- Zhang, X.; Meng, X.; Yin, H.; Wang, Y.; Yue, Y.; Xing, Y.; Zhang, Y. SSA-Net: Spatial Scale Attention Network for Image-Based Geo-Localization. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Naushad, R.; Kaur, T.; Ghaderpour, E. Deep Transfer Learning for Land Use and Land Cover Classification: A Comparative Study. Sensors 2021, 21, 8083. [Google Scholar] [CrossRef] [PubMed]
- Wei, J.; Yue, W.; Li, M.; Gao, J. Mapping Human Perception of Urban Landscape from Street-View Images: A Deep-Learning Approach. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102886. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. ISBN 978-3-030-01233-5. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation 2019. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Zhang, Z.; Lan, C.; Zeng, W.; Jin, X.; Chen, Z. Relation-Aware Global Attention for Person Re-Identification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3183–3192. [Google Scholar]
- Zhou, S.; Wang, J.; Shi, R.; Hou, Q.; Gong, Y.; Zheng, N. Large Margin Learning in Set to Set Similarity Comparison for Person Re-Identification. IEEE Trans. Multimed. 2017, 20, 593–604. [Google Scholar] [CrossRef]
- Zhao, C.; Lv, X.; Zhang, Z.; Zuo, W.; Wu, J.; Miao, D. Deep Fusion Feature Representation Learning with Hard Mining Center-Triplet Loss for Person Re-Identification. IEEE Trans. Multimed. 2020, 22, 3180–3195. [Google Scholar] [CrossRef]
- Zhai, M.; Bessinger, Z.; Workman, S.; Jacobs, N. Predicting Ground-Level Scene Layout from Aerial Imagery. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4132–4140. [Google Scholar]
- Zhu, S.; Yang, T.; Chen, C. VIGOR: Cross-View Image Geo-Localization beyond One-to-One Retrieval. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 5316–5325. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kingma, D.P.; Lei, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Vo, N.N.; Hays, J. Localizing and Orienting Street Views Using Overhead Imagery. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 494–509. ISBN 978-3-319-46447-3. [Google Scholar]
- Shi, Y.; Yu, X.; Liu, L.; Zhang, T.; Li, H. Optimal Feature Transport for Cross-View Image Geo-Localization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11990–11997. [Google Scholar] [CrossRef]
- Workman, S.; Souvenir, R.; Jacobs, N. Wide-Area Image Geolocalization with Aerial Reference Imagery. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3961–3969. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | CVUSA | |||
|---|---|---|---|---|
| r@1 | r@5 | r@10 | r@1% | |
| Workman et al. [36] | - | - | - | 34.30 |
| CVM-Net [17] | 22.47 | 49.98 | 63.18 | 93.62 |
| Liu and Li [3] | 40.79 | 66.82 | 76.36 | 96.08 |
| Cai et al. [21] | - | - | - | 98.30 |
| SAFA [5] | 89.84 | 96.83 | 98.14 | 99.64 |
| SSA-Net [22] | 91.52 | 97.69 | 98.57 | 99.71 |
| DSM [6] | 91.96 | 97.50 | 98.54 | 99.67 |
| Ours | 92.08 | 97.70 | 98.66 | 99.67 |
| Method | VIGOR (Same-Area) | |||
|---|---|---|---|---|
| r@1 | r@5 | r@10 | r@1% | |
| Siamese-VGG | 18.69 | 43.64 | 55.36 | 97.55 |
| SAFA+Polar [5] | 24.13 | 45.58 | - | 95.26 |
| Ours+Polar | 27.54 | 51.16 | 60.88 | 96.78 |
| SAFA [5] | 33.93 | 58.42 | 68.12 | 98.24 |
| SAFA+Mining [31] | 38.02 | 62.87 | 71.12 | 97.63 |
| VIGOR [31] | 41.07 | 65.81 | 74.05 | 98.37 |
| Ours | 40.56 | 66.37 | 74.48 | 98.02 |
| Method | Taipei | |||
|---|---|---|---|---|
| r@1 | r@5 | r@10 | r@1% | |
| SAFA [5] | 23.51 | 47.50 | 57.43 | 83.69 |
| DSM [6] | 25.42 | 50.32 | 61.57 | 84.87 |
| Ours | 27.86 | 51.43 | 63.54 | 88.74 |
| Method | CVUSA | |||
| r@1 | r@5 | r@10 | r@1% | |
| Baseline | 59.18 | 80.80 | 87.20 | 97.83 |
| CBAM [23] | 88.12 | 96.21 | 97.67 | 99.50 |
| Ours | 92.08 | 97.70 | 98.66 | 99.67 |
| Method | VIGOR (Same Area) | |||
| r@1 | r@5 | r@10 | r@1% | |
| Baseline | 11.03 | 26.06 | 34.60 | 92.58 |
| CBAM [23] | 23.44 | 44.63 | 53.99 | 95.56 |
| Ours | 27.54 | 51.16 | 60.88 | 96.78 |
| Method | CVUSA | |||
| r@1 | r@5 | r@10 | r@1% | |
| MC_GRA (Standard convolution) | 90.17 | 97.02 | 98.08 | 99.63 |
| MC_GRA | 92.08 | 97.70 | 98.66 | 99.67 |
| Method | VIGOR (Same Area) | |||
| r@1 | r@5 | r@10 | r@1% | |
| MC_GRA (Standard convolution) | 25.24 | 50.47 | 60.35 | 96.72 |
| MC_GRA | 27.54 | 51.16 | 60.88 | 96.78 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, Q.; Lu, J.; Guo, H.; Liu, X.; Gong, Z.; Zhu, K.; Ping, Y. Feature Relation Guided Cross-View Image Based Geo-Localization. Remote Sens. 2023, 15, 5029. https://doi.org/10.3390/rs15205029
Hou Q, Lu J, Guo H, Liu X, Gong Z, Zhu K, Ping Y. Feature Relation Guided Cross-View Image Based Geo-Localization. Remote Sensing. 2023; 15(20):5029. https://doi.org/10.3390/rs15205029
Chicago/Turabian StyleHou, Qingfeng, Jun Lu, Haitao Guo, Xiangyun Liu, Zhihui Gong, Kun Zhu, and Yifan Ping. 2023. "Feature Relation Guided Cross-View Image Based Geo-Localization" Remote Sensing 15, no. 20: 5029. https://doi.org/10.3390/rs15205029
APA StyleHou, Q., Lu, J., Guo, H., Liu, X., Gong, Z., Zhu, K., & Ping, Y. (2023). Feature Relation Guided Cross-View Image Based Geo-Localization. Remote Sensing, 15(20), 5029. https://doi.org/10.3390/rs15205029