
BiTSRS: A Bi-Decoder Transformer Segmentor for High-Spatial-Resolution Remote Sensing Images




Abstract
:1. Introduction
- An improved transformer-based model is proposed that combines the Swin transformer and a bi-decoder structure to perform semantic segmentation of RS images. This new framework is capable of modeling both global and local representations while decoding coarse and fine features.
- For larger-scale RS images, an input transform module (ITM) is proposed to transform the inputs with large spatial scales to the ones with compatible scales for the Swin transformer. The ITM is designed to be a plug-and-play module, which can be easily implanted in the Swin transformer to make it more suitable for RS images.
- A novel bi-decoder structure was specifically designed to decode the features extracted by the Swin transformer encoder. With this bi-decoder structure, BiTSRS can decode the features in a larger receptive field without losing the deformations in detail.
- A more appropriate loss is considered to deal with the problems of complex background samples and class distribution of the segmentation process in the auxiliary FDCN decoder. Such loss is illustrated to be more effective in distinguishing the hard samples by introducing a focusing parameter.
2. Related Works
2.1. Semantic Segmentation of RS Images with CNNs
2.2. Semantic Segmentation of RS Images Using Transformer
3. Method
3.1. Input Transform Module
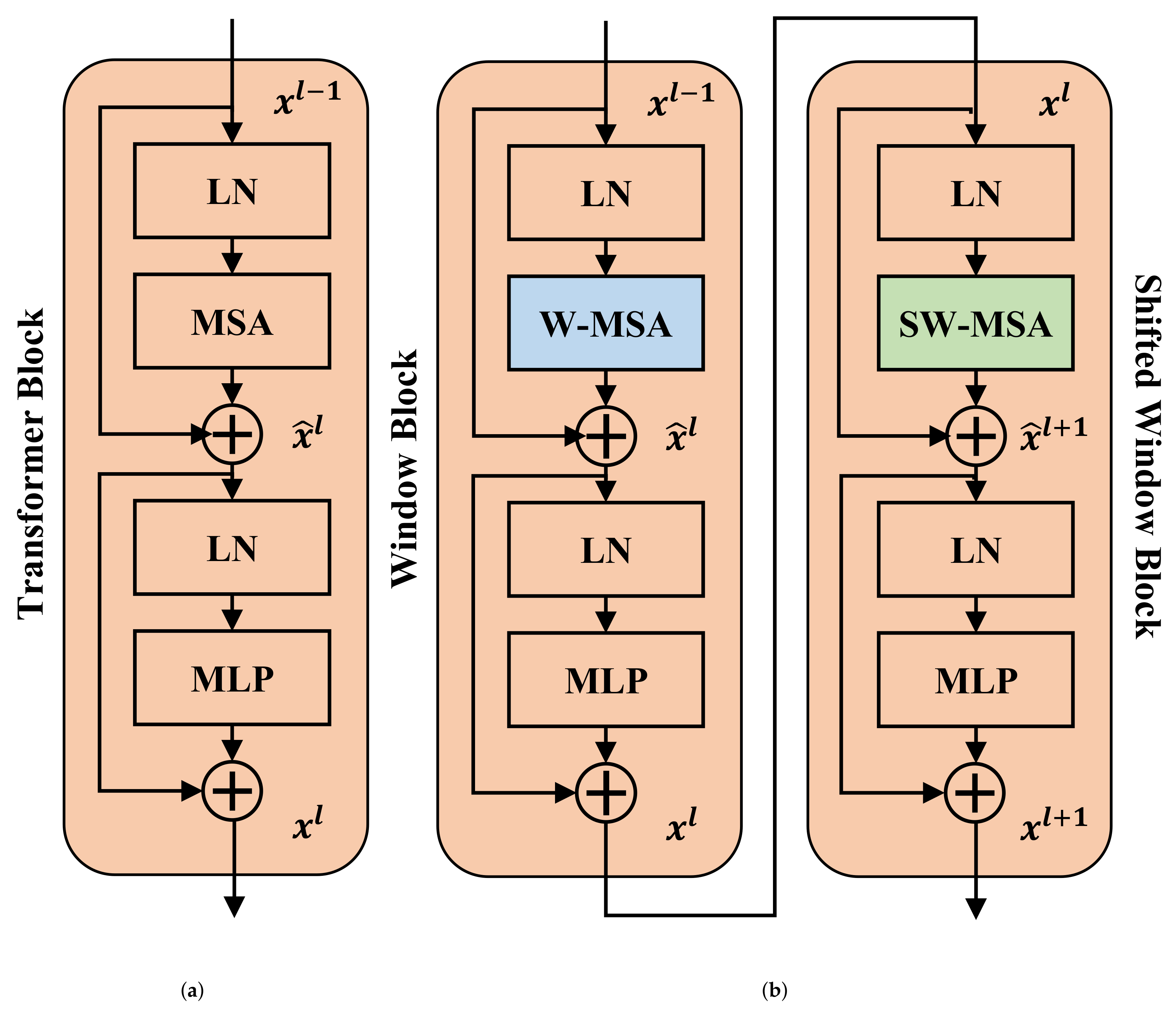
3.2. Swin Transformer Encoder
3.3. Dilated-Uper Decoder
3.4. Fully Deformable Convolutional Network
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Ablation Analysis
4.5. Comparison with Some State-of-the-Art Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Ren, Q.; Geng, J.; Ding, M.; Li, J. Efficient Patch-Wise Semantic Segmentation for Large-Scale Remote Sensing Images. Sensors 2018, 18, 3232. [Google Scholar] [CrossRef]
- Kampffmeyer, M.; Salberg, A.B.; Jenssen, R. Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Luo, H.; Chen, C.; Fang, L.; Khoshelham, K.; Shen, G. Ms-rrfsegnet: Multiscale regional relation feature segmentation network for semantic segmentation of urban scene point clouds. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8301–8315. [Google Scholar] [CrossRef]
- Khan, S.A.; Shi, Y.; Shahzad, M.; Zhu, X.X. FGCN: Deep Feature-based Graph Convolutional Network for Semantic Segmentation of Urban 3D Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar] [CrossRef]
- Zhao, J.; Zhou, Y.; Shi, B.; Yang, J.; Zhang, D.; Yao, R. Multi-stage fusion and multi-source attention network for multi-modal remote sensing image segmentation. ACM Trans. Intell. Syst. Technol. TIST 2021, 12, 1–20. [Google Scholar] [CrossRef]
- Bi, H.; Xu, L.; Cao, X.; Xue, Y.; Xu, Z. Polarimetric SAR image semantic segmentation with 3D discrete wavelet transform and Markov random field. IEEE Trans. Image Process. 2020, 29, 6601–6614. [Google Scholar] [CrossRef]
- Yin, G.; Verger, A.; Descals, A.; Filella, I.; Peñuelas, J. A broadband green-red vegetation index for monitoring gross primary production phenology. J. Remote Sens. 2022, 2022, 9764982. [Google Scholar] [CrossRef]
- Alemohammad, H.; Booth, K. LandCoverNet: A global benchmark land cover classification training dataset. arXiv 2020, arXiv:2012.03111. [Google Scholar]
- Tong, X.Y.; Xia, G.S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef]
- Chen, L.; Letu, H.; Fan, M.; Shang, H.; Tao, J.; Wu, L.; Zhang, Y.; Yu, C.; Gu, J.; Zhang, N.; et al. An Introduction to the Chinese High-Resolution Earth Observation System: Gaofen-1˜ 7 Civilian Satellites. J. Remote Sens. 2022, 2022, 9769536. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 3, 3349–3364. [Google Scholar] [CrossRef] [Green Version]
- Jiang, S.; Jiang, C.; Jiang, W. Efficient structure from motion for large-scale UAV images: A review and a comparison of SfM tools. ISPRS J. Photogramm. Remote Sens. 2020, 167, 230–251. [Google Scholar] [CrossRef]
- Hoeser, T.; Kuenzer, C. Object detection and image segmentation with deep learning on earth observation data: A review-part i: Evolution and recent trends. Remote Sens. 2020, 12, 1667. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Ma, M.; Mei, S.; Wan, S.; Wang, Z.; Hua, X.S.; Feng, D.D. Graph Convolutional Dictionary Selection With L2,p Norm for Video Summarization. IEEE Trans. Image Process. 2022, 31, 1789–1804. [Google Scholar] [CrossRef]
- Liu, H.; Li, W.; Xia, X.G.; Zhang, M.; Gao, C.Z.; Tao, R. Central attention network for hyperspectral imagery classification. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, W.; Zhang, M.; Wang, S.; Tao, R.; Du, Q. Graph Information Aggregation Cross-Domain Few-Shot Learning for Hyperspectral Image Classification. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Li, W.; Gao, Y.; Zhang, M.; Tao, R.; Du, Q. Asymmetric feature fusion network for hyperspectral and SAR image classification. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Ciresan, D.; Giusti, A.; Gambardella, L.; Schmidhuber, J. Deep neural networks segment neuronal membranes in electron microscopy images. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 25. [Google Scholar]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning Hierarchical Features for Scene Labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef]
- Ganin, Y.; Lempitsky, V.S. N4-Fields: Neural Network Nearest Neighbor Fields for Image Transforms. In Proceedings of the 12th Asian Conference on Computer Vision, Singapore, 1–5 November 2014. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, G.; Zhang, X.; Wang, Q.; Dai, F.; Gong, Y.; Zhu, K. Symmetrical dense-shortcut deep fully convolutional networks for semantic segmentation of very-high-resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1633–1644. [Google Scholar] [CrossRef]
- Sun, W.; Wang, R. Fully convolutional networks for semantic segmentation of very high resolution remotely sensed images combined with DSM. IEEE Geosci. Remote Sens. Lett. 2018, 15, 474–478. [Google Scholar] [CrossRef]
- Wu, Z.; Gao, Y.; Li, L.; Xue, J.; Li, Y. Semantic segmentation of high-resolution remote sensing images using fully convolutional network with adaptive threshold. Connect. Sci. 2019, 31, 169–184. [Google Scholar] [CrossRef]
- Liu, Y.; Zhu, Q.; Cao, F.; Chen, J.; Lu, G. High-resolution remote sensing image segmentation framework based on attention mechanism and adaptive weighting. ISPRS Int. J. Geo Inf. 2021, 10, 241. [Google Scholar] [CrossRef]
- Li, H.; Qiu, K.; Chen, L.; Mei, X.; Hong, L.; Tao, C. SCAttNet: Semantic Segmentation Network With Spatial and Channel Attention Mechanism for High-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2021, 18, 905–909. [Google Scholar] [CrossRef]
- Luo, Y.; Han, J.; Liu, Z.; Wang, M.; Xia, G.S. An Elliptic Centerness for Object Instance Segmentation in Aerial Images. J. Remote Sens. 2022, 2022, 9809505. [Google Scholar] [CrossRef]
- Negin, F.; Tabejamaat, M.; Fraisse, R.; Bremond, F. Transforming Temporal Embeddings to Keypoint Heatmaps for Detection of Tiny Vehicles in Wide Area Motion Imagery (WAMI) Sequences. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; pp. 1431–1440. [Google Scholar] [CrossRef]
- Motorcu, H.; Ates, H.F.; Ugurdag, H.F.; Gunturk, B.K. HM-Net: A Regression Network for Object Center Detection and Tracking on Wide Area Motion Imagery. IEEE Access 2022, 10, 1346–1359. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvt v2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; XU, C.; Wang, Y. Transformer in Transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. CvT: Introducing Convolutions to Vision Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar] [CrossRef]
- Mei, S.; Song, C.; Ma, M.; Xu, F. Hyperspectral Image Classification Using Group-Aware Hierarchical Transformer. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–4. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video Swin Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Gool, L.V.; Timofte, R. SwinIR: Image Restoration Using Swin Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar] [CrossRef]
- Xu, X.; Feng, Z.; Cao, C.; Li, M.; Wu, J.; Wu, Z.; Shang, Y.; Ye, S. An Improved Swin Transformer-Based Model for Remote Sensing Object Detection and Instance Segmentation. Remote Sens. 2021, 13, 4779. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin Transformer Embedding UNet for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Gao, L.; Liu, H.; Yang, M.; Chen, L.; Wan, Y.; Xiao, Z.; Qian, Y. STransFuse: Fusing Swin Transformer and Convolutional Neural Network for Remote Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10990–11003. [Google Scholar] [CrossRef]
- Zhang, C.; Jiang, W.S.; Zhang, Y.; Wang, W.; Zhao, Q.; Wang, C.J. Transformer and CNN Hybrid Deep Neural Network for Semantic Segmentation of Very-high-resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–20. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, W.; Zhang, T.; Yang, Z.; Li, J. Efficient transformer for remote sensing image segmentation. Remote Sens. 2021, 13, 3585. [Google Scholar] [CrossRef]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Du, S.; Du, S.; Liu, B.; Zhang, X. Incorporating DeepLabv3+ and object-based image analysis for semantic segmentation of very high resolution remote sensing images. Int. J. Digit. Earth 2021, 14, 357–378. [Google Scholar] [CrossRef]
- Mou, L.; Hua, Y.; Zhu, X.X. A Relation-Augmented Fully Convolutional Network for Semantic Segmentation in Aerial Scenes. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12408–12417. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhong, Y.; Wang, J.; Ma, A. Foreground-Aware Relation Network for Geospatial Object Segmentation in High Spatial Resolution Remote Sensing Imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Ding, L.; Tang, H.; Bruzzone, L. LANet: Local Attention Embedding to Improve the Semantic Segmentation of Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 426–435. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Zhang, C.; Su, J.; Atkinson, P.M. Multi-Attention-Network for Semantic Segmentation of Fine Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2020, 60, 1–3. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Ding, L.; Lin, D.; Lin, S.; Zhang, J.; Cui, X.; Wang, Y.; Tang, H.; Bruzzone, L. Looking Outside the Window: Wider-Context Transformer for the Semantic Segmentation of High-Resolution Remote Sensing Images. arXiv 2021, arXiv:2106.15754. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- ISPRS, Semantic Labeling Contest (2018). Available online: https://www.isprs.org/education/benchmarks/UrbanSemLab/default.aspx (accessed on 27 December 2022).
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. High-resolution aerial image labeling with convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7092–7103. [Google Scholar] [CrossRef]
- Mou, L.; Hua, Y.; Zhu, X.X. Relation matters: Relational context-aware fully convolutional network for semantic segmentation of high-resolution aerial images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7557–7569. [Google Scholar] [CrossRef]
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation. arXiv 2021, arXiv:2110.08733. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Mishra, P.; Sarawadekar, K. Polynomial learning rate policy with warm restart for deep neural network. In Proceedings of the TENCON 2019-2019 IEEE Region 10 Conference (TENCON), Kerala, India, 17–20 October 2019; pp. 2087–2092. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F. BEiT: BERT Pre-Training of Image Transformers. arXiv 2021, arXiv:2106.0825. [Google Scholar]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: An UNet-like Transformer for Efficient Semantic Segmentation of Remote Sensing Urban Scene Imagery. ISPRS J. Photogramm. Remote Sens. 2021, 190, 196–214. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prediction | |||
|---|---|---|---|
| Positive | Negative | ||
| Ground | Positive | TP | FN |
| Truth | Negative | FP | TN |
| Framework | IoU (%) | Evaluation Metrics | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Background | Building | Road | Water | Barren | Forest | Agricultural | mIoU (%) | mAcc (%) | |
| baseline with pr | 54.45 | 60.77 | 56.04 | 68.63 | 28.13 | 43.93 | 48.99 | 51.56 | 66.58 |
| baseline + ITM with pr | 54.43 | 61.56 | 58.19 | 73.32 | 32.38 | 43.99 | 51.86 | 53.68 | 66.86 |
| baseline | 53.4 | 45.08 | 48.61 | 57.13 | 24.41 | 42.71 | 51.43 | 46.11 | 59.55 |
| baseline + ITM | 52.24 | 51.34 | 51.2 | 65.98 | 21.29 | 40.44 | 51.24 | 47.67 | 60.76 |
| baseline with pr (1024) | 53.56 | 62.31 | 57.76 | 71.2 | 30.44 | 45.07 | 49.56 | 52.84 | 66.9 |
| baseline + ITM with pr (1024) | 54.81 | 66.97 | 57.65 | 73.01 | 33.32 | 44.93 | 54.93 | 55.09 | 67.63 |
| Adopted Designs | Evaluation Metrics | |||
|---|---|---|---|---|
| D-U Decoder | FDCN | Focal Loss | mIoU (%) | mAcc (%) |
| baseline with ITM | 47.67 | 60.76 | ||
| 🗸 | 48.4 | 61.34 | ||
| 🗸 | 48.26 | 62.32 | ||
| 🗸 | 48.53 | 60.61 | ||
| 🗸 | 🗸 | 48.77 | 62.28 | |
| 🗸 | 🗸 | 50.1 | 62.24 | |
| 🗸 | 🗸 | 49.44 | 62.26 | |
| 🗸 | 🗸 | 🗸 | 50.61 | 64.01 |
| Methods | IoU (%) | Evaluation Metrics | ||||||
|---|---|---|---|---|---|---|---|---|
| Impervious Surface | Building | Low Vegetation | Tree | Car | Clutter | mIoU (%) | mAcc (%) | |
| FCN [24] | 83.48 | 89.82 | 69.63 | 79.31 | 73.12 | 0.77 | 66.02 | 73.27 |
| U-net [25] | 77.16 | 81.44 | 59.44 | 73.11 | 42.86 | 2.66 | 56.11 | 64.46 |
| PSPNet [28] | 81.35 | 86.66 | 69.83 | 78.72 | 57.51 | 25.87 | 66.66 | 73.86 |
| DeepLabv3+ [27] | 77.43 | 85.1 | 61.13 | 73.44 | 54.59 | 33.5 | 64.2 | 72.63 |
| HRNet [11] | 79.2 | 85.85 | 64.76 | 74.04 | 53.68 | 24.84 | 63.73 | 72.82 |
| SETR [63] | 79.83 | 86.81 | 66.61 | 75.11 | 50.02 | 22.97 | 63.56 | 72.43 |
| BeiT [74] | 76.44 | 81.61 | 63.28 | 73.22 | 44.35 | 16.37 | 59.21 | 67.97 |
| UNetFormer [75] | 79.24 | 86.18 | 64.24 | 73.87 | 55.24 | 24.67 | 63.91 | 72.63 |
| SwinB-CNN [49] | 80.63 | 84.97 | 63.52 | 75.14 | 52.7 | 25.65 | 63.77 | 73.08 |
| STransFuse [48] | 78.97 | 84.27 | 65.35 | 74.69 | 62.79 | - | 66.66 | - |
| ST-UNet [47] | 82.74 | 87.11 | 68.82 | 78.18 | 57.62 | 29.15 | 67.27 | 74.81 |
| baseline [43] | 82.19 | 88.22 | 68.31 | 78.08 | 47.9 | 19.08 | 63.96 | 71.29 |
| BiTSRS | 83.17 | 87.99 | 67.32 | 77.64 | 64.58 | 36.98 | 69.61 | 77.76 |
| Methods | IoU (%) | Evaluation Metrics | ||||||
|---|---|---|---|---|---|---|---|---|
| Impervious Surface | Building | Low Vegetation | Tree | Car | Clutter | mIoU (%) | mAcc (%) | |
| FCN [24] | 84.38 | 90.14 | 70.93 | 72.79 | 91.3 | 28.46 | 73 | 81.51 |
| U-net [25] | 74.99 | 77.73 | 66.48 | 67.41 | 82.28 | 14.91 | 63.97 | 73.44 |
| PSPNet [28] | 82.34 | 88.58 | 70.22 | 69.55 | 87.58 | 33.82 | 72.02 | 82.04 |
| DeepLabv3+ [27] | 82.82 | 90.94 | 72.2 | 73.51 | 82.55 | 36.73 | 73.12 | 82.4 |
| HRNet [11] | 82.92 | 89.86 | 72.87 | 73.71 | 81.54 | 36.9 | 72.97 | 81.75 |
| SETR [63] | 80.73 | 89.46 | 71.11 | 72.49 | 71.82 | 34.76 | 70.06 | 79.33 |
| BeiT [74] | 75.86 | 81.75 | 66.65 | 61.71 | 75.41 | 25.62 | 64.5 | 75.43 |
| UNetFormer [75] | 81.49 | 88.86 | 70.72 | 72.49 | 78.68 | 34.95 | 71.2 | 80.35 |
| SwinB-CNN [49] | 80.03 | 86.51 | 69.35 | 73.05 | 87.19 | 34.22 | 71.73 | 81.86 |
| STransFuse [48] | 81.41 | 88.53 | 70.81 | 71.84 | 79.39 | - | 71.46 | - |
| ST-UNet [47] | 83.02 | 90.88 | 72.54 | 75.04 | 83.34 | 38.15 | 73.83 | 82.84 |
| baseline [43] | 83.34 | 88.55 | 73 | 73.88 | 85.35 | 30.38 | 72.42 | 80.41 |
| BiTSRS | 84.67 | 90.86 | 74.63 | 75.44 | 88.11 | 39.26 | 75.5 | 83.57 |
| Methods | IoU (%) | Evaluation Metrics | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Background | Building | Road | Water | Barren | Forest | Agricultural | mIoU (%) | mAcc (%) | |
| FCN [24] | 52.34 | 58.89 | 44.02 | 54.95 | 23.99 | 33.72 | 47.66 | 45.08 | 55.5 |
| U-net [25] | 51.7 | 54.28 | 51.06 | 62.11 | 18.19 | 36.32 | 50.05 | 46.24 | 57.79 |
| PSPNet [28] | 49.79 | 43.84 | 41.66 | 61.43 | 12.28 | 36.53 | 43.07 | 41.23 | 53.84 |
| DeepLabv3+ [27] | 50.97 | 60.68 | 51.76 | 52.3 | 28.87 | 36.01 | 48.8 | 47.05 | 58.87 |
| HRNet [11] | 52.32 | 54.31 | 53.28 | 69.05 | 19.71 | 38.59 | 53.54 | 48.68 | 61.0 |
| SETR [63] | 47.65 | 42.21 | 37.2 | 56.22 | 20.03 | 33.47 | 32.32 | 38.44 | 53.32 |
| BeiT [74] | 48.85 | 53.01 | 47.03 | 48.59 | 19.73 | 36.85 | 41.85 | 42.27 | 58.04 |
| UNetFormer [75] | 48.18 | 56.75 | 51.17 | 53.22 | 12.05 | 38.06 | 44.52 | 43.42 | 56.27 |
| SwinB-CNN [49] | 50.66 | 56.66 | 44.91 | 53.81 | 31.46 | 40.3 | 43.67 | 45.92 | 59.05 |
| ST-UNet [47] | 48.46 | 57.2 | 52.89 | 65.52 | 27.68 | 36.19 | 56.58 | 49.22 | 63.66 |
| baseline [43] | 53.4 | 45.08 | 48.61 | 57.13 | 24.41 | 42.71 | 51.43 | 46.11 | 59.55 |
| BiTSRS | 49.52 | 55.69 | 54.32 | 68.27 | 32.57 | 39.99 | 53.93 | 50.61 | 64.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Zhang, Y.; Wang, Y.; Mei, S. BiTSRS: A Bi-Decoder Transformer Segmentor for High-Spatial-Resolution Remote Sensing Images. Remote Sens. 2023, 15, 840. https://doi.org/10.3390/rs15030840
Liu Y, Zhang Y, Wang Y, Mei S. BiTSRS: A Bi-Decoder Transformer Segmentor for High-Spatial-Resolution Remote Sensing Images. Remote Sensing. 2023; 15(3):840. https://doi.org/10.3390/rs15030840
Chicago/Turabian StyleLiu, Yuheng, Yifan Zhang, Ye Wang, and Shaohui Mei. 2023. "BiTSRS: A Bi-Decoder Transformer Segmentor for High-Spatial-Resolution Remote Sensing Images" Remote Sensing 15, no. 3: 840. https://doi.org/10.3390/rs15030840
APA StyleLiu, Y., Zhang, Y., Wang, Y., & Mei, S. (2023). BiTSRS: A Bi-Decoder Transformer Segmentor for High-Spatial-Resolution Remote Sensing Images. Remote Sensing, 15(3), 840. https://doi.org/10.3390/rs15030840