
A Localization Algorithm Based on Global Descriptor and Dynamic Range Search


Abstract
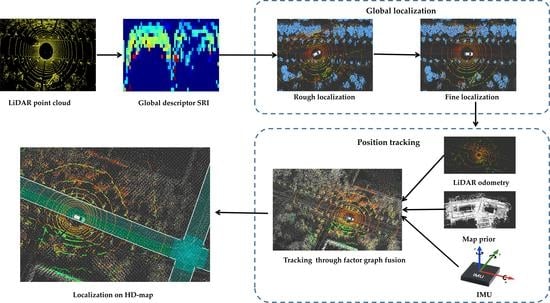
:
1. Introduction
- A global descriptor SRI is proposed from the idea of coordinate removal and de-centralization for reducing the coding differences caused by rotations and shifts between the current frame and the map keyframes;
- A global localization algorithm SRI-BBS is proposed based on the descriptor SRI, which dynamically selects the search range by the similarity between descriptors to improve the search efficiency and success rate of the algorithm;
- A tightly coupled factor graph model is introduced to fuse the multi-sensor information to achieve real-time and stable position tracking; a HD map engine is developed to realize lane-level localization.
2. Related Work
2.1. Global Localization
2.2. Position Tracking Algorithm
2.3. Motivation of Our Work
3. Methods
3.1. Global Descriptor SRI
3.2. SRI-BBS Global Localization Algorithm
3.2.1. Rough Localization
| Algorithm 1 Rough localization algorithm |
| Input: Current LiDAR scan , Map descriptors set , map keyframe position set . |
| Output: Rough localization result . |
| 1: Compute current LiDAR scan to descriptor by method mentioned in Section 3.1; 2: Compress map descriptors into vectors V by Formula (14); 3: Compress descriptor into vector by Formula (14); |
| 4: Use to build KDTree ; 5: candidate map descriptors that are most similar to are searched by KDTree ; 6: Find the most similar descriptor and its index among candidate descriptors through the similarity calculated by Formula (15); 7: Get the position of the map keyframe with index ; 8: . |
3.2.2. Fine Localization
| Algorithm 2 Fine localization algorithm |
| Input: Rough localization result , the similarity between the current frame descriptor and the most similar descriptor in the map descriptor set, the point cloud map . |
| Output: Fine localization result . |
| 1: Search range is calculated by Formula (21); 2: Convert point cloud map to 2d binary grid map by Formula (19); 3: Convert LiDAR scan to 2d binary grid map by Formula (19); 4: build three submaps in grid map by Formula (20); 5: ⟵ ; 6: Stack set to empty; 7: for = − ; < ; = + do 8: for = − ; < ; = + do 9: for = ; < 360; = + do; 10: Calculate the matching score under the poses in the lowest resolution submap, recorded as; 11: Push to stack ; 12: end for 13: end for 14: end for 15: Sort stack by score, the maximum score at the top; |
| 16: while is not empty do; 17: pop from the stack; 18: Current level on the submaps; 19: if .score > then 20: if equals 3 then 21: ⟵.score.\; 22: ⟵ and break; 23: else 24: Branch: calculate the scores of four positions adjacent to current position on the higher resolution submap, recorded as , , , ; 25: Push onto the stack C, sorted by score, the maximum score at the top; 26: end if 27: end if 28: end while 29: return . |
3.3. Position Tracking Algorithm
3.4. HD Map Localization
| Algorithm 3 lane-level localization algorithm |
| Input: |
| Localization position , lane sets of HD map |
| Output: |
| Current lane information |
| Algorithm: |
| 1: Begin: |
| 2: KDTree algorithm searches the m candidate lanes nearest to |
| 3: for each lane in candidate lanes do 4: is_in False |
| 5: for each edge in do |
| 6: if edge intersects the ray then |
| 7: is_in !is_in |
| 8: end if |
| 9: end for |
| 10: if is_in equals True then |
| 11: return the lane information of |
| 12: end if |
| 13: end for |
| 14: return not in any lane |
| 15: end begin. |
4. Experiments
4.1. Dataset Introduction
4.1.1. KITTI Dataset
4.1.2. JLU Campus Dataset
4.2. Global Localization Experiments
4.2.1. Ablation Experiments of Global Descriptor
4.2.2. Ablation Experiments of SRI-BBS Global Localization
4.2.3. Comparative Experiments of Global Localization
4.3. Position Tracking Experiments
4.3.1. Ablation Experiments of Position Tracking
4.3.2. Comparative Experiments of Position Tracking
4.4. Display of HD Map Localization Effect
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

Appendix B
References
- Zhu, Y.; Xue, B.; Zheng, L.; Huang, H.; Liu, M.; Fan, R. Real-time, environmentally-robust 3d lidar localization. In Proceedings of the 2019 IEEE International Conference on Imaging Systems and Techniques (IST), Abu Dhabi, United Arab Emirates, 9–10 December 2019; pp. 1–6. [Google Scholar]
- Li, S.; Li, L.; Lee, G.; Zhang, H. A hybrid search algorithm for swarm robots searching in an unknown environment. PLoS ONE 2014, 9, e111970. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.; Wei, X.; Chen, Y.; Zhang, T.; Hou, M.; Liu, Z. A Multi-Channel Descriptor for LiDAR-Based Loop Closure Detection and Its Application. Remote Sens. 2022, 14, 5877. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, F.; Li, H. An efficient method for cooperative multi-target localization in automotive radar. IEEE Signal Process. Lett. 2021, 29, 16–20. [Google Scholar] [CrossRef]
- Jia, T.; Wang, H.; Shen, X.; Jiang, Z.; He, K. Target localization based on structured total least squares with hybrid TDOA-AOA measurements. Signal Process. 2018, 143, 211–221. [Google Scholar] [CrossRef]
- Zhang, Y.; Ho, K. Multistatic moving object localization by a moving transmitter of unknown location and offset. IEEE Trans. Signal Process. 2020, 68, 4438–4453. [Google Scholar] [CrossRef]
- Wang, G.; Jiang, X.; Zhou, W.; Chen, Y.; Zhang, H. 3PCD-TP: A 3D Point Cloud Descriptor for Loop Closure Detection with Twice Projection. Remote Sens. 2023, 15, 82. [Google Scholar] [CrossRef]
- Yang, T.; Li, Y.; Zhao, C.; Yao, D.; Chen, G.; Sun, L.; Krajnik, T.; Yan, Z. 3D ToF LiDAR in Mobile Robotics: A Review. arXiv 2022, arXiv:2202.11025. [Google Scholar]
- Cop, K.P.; Borges, P.V.; Dubé, R. Delight: An efficient descriptor for global localisation using lidar intensities. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 3653–3660. [Google Scholar]
- Kim, G.; Kim, A. Scan context: Egocentric spatial descriptor for place recognition within 3d point cloud map. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4802–4809. [Google Scholar]
- Tombari, F.; Salti, S.; Stefano, L.D. Unique signatures of histograms for local surface description. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 356–369. [Google Scholar]
- Kaess, M.; Johannsson, H.; Roberts, R.; Ila, V.; Leonard, J.J.; Dellaert, F. iSAM2: Incremental smoothing and mapping using the Bayes tree. Int. J. Robot. Res. 2012, 31, 216–235. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- MacQueen, J. Classification and analysis of multivariate observations. In Proceedings of the 5th Berkeley Symp. Math. Statist. Probability, Berkeley, CA, USA, 21 June–18 July 1965; pp. 281–297. [Google Scholar]
- Sivic, J.; Zisserman, A. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the Computer Vision, IEEE International Conference on, Madison, WI, USA, 18–20 June 2003; p. 1470. [Google Scholar]
- Gálvez-López, D.; Tardos, J.D. Bags of binary words for fast place recognition in image sequences. IEEE Trans. Robot. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. Brief: Binary robust independent elementary features. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 778–792. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef] [Green Version]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. Epnp: An accurate o (n) solution to the pnp problem. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar] [CrossRef] [Green Version]
- Ratz, S.; Dymczyk, M.; Siegwart, R.; Dubé, R. Oneshot global localization: Instant lidar-visual pose estimation. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 5415–5421. [Google Scholar]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-time loop closure in 2D LIDAR SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar]
- Koide, K.; Miura, J.; Menegatti, E. A portable three-dimensional LIDAR-based system for long-term and wide-area people behavior measurement. Int. J. Adv. Robot. Syst. 2019, 16, 1729881419841532. [Google Scholar] [CrossRef]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar]
- Steder, B.; Ruhnke, M.; Grzonka, S.; Burgard, W. Place recognition in 3D scans using a combination of bag of words and point feature based relative pose estimation. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 1249–1255. [Google Scholar]
- Wang, H.; Wang, C.; Xie, L. Intensity scan context: Coding intensity and geometry relations for loop closure detection. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 2095–2101. [Google Scholar]
- Li, H.; Wang, X.; Hong, Z. M2DP: A novel 3D point cloud descriptor and its application in loop closure detection. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016. [Google Scholar]
- Shan, T.; Englot, B.; Duarte, F.; Ratti, C.; Rus, D. Robust Place Recognition using an Imaging Lidar. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 5469–5475. [Google Scholar]
- Wang, Y.; Dong, L.; Li, Y.; Zhang, H. Multitask feature learning approach for knowledge graph enhanced recommendations with RippleNet. PLoS ONE 2021, 16, e0251162. [Google Scholar] [CrossRef] [PubMed]
- Dubé, R.; Cramariuc, A.; Dugas, D.; Nieto, J.; Siegwart, R.; Cadena, C. SegMap: 3d segment mapping using data-driven descriptors. arXiv 2018, arXiv:1804.09557. [Google Scholar]
- Röhling, T.; Mack, J.; Schulz, D. A fast histogram-based similarity measure for detecting loop closures in 3-d lidar data. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 736–741. [Google Scholar]
- Magnusson, M.; Andreasson, H.; Nuchter, A.; Lilienthal, A.J. Appearance-based loop detection from 3D laser data using the normal distributions transform. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 23–28. [Google Scholar]
- Ding, X.; Wang, Y.; Li, D.; Tang, L.; Yin, H.; Xiong, R. Laser map aided visual inertial localization in changing environment. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 4794–4801. [Google Scholar]
- Wolcott, R.W.; Eustice, R.M. Visual localization within lidar maps for automated urban driving. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 176–183. [Google Scholar]
- Zhou, B.; Tang, Z.; Qian, K.; Fang, F.; Ma, X. A lidar odometry for outdoor mobile robots using ndt based scan matching in gps-denied environments. In Proceedings of the 2017 IEEE 7th Annual International Conference on CYBER Technology in Automation, Control, and Intel-ligent Systems (CYBER), Honolulu, HI, USA, 31 July–4 August 2017; pp. 1230–1235. [Google Scholar]
- Egger, P.; Borges, P.V.; Catt, G.; Pfrunder, A.; Siegwart, R.; Dubé, R. Posemap: Lifelong, multi-environment 3d lidar localization. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 3430–3437. [Google Scholar]
- Wan, G.; Yang, X.; Cai, R.; Li, H.; Zhou, Y.; Wang, H.; Song, S. Robust and precise vehicle localization based on multi-sensor fusion in diverse city scenes. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 4670–4677. [Google Scholar]
- Madyastha, V.; Ravindra, V.; Mallikarjunan, S.; Goyal, A. Extended Kalman filter vs. error state Kalman filter for aircraft attitude estimation. In Proceedings of the AIAA Guidance, Navigation, and Control Conference, Portland, OR, USA, 8–11 August 2011; p. 6615. [Google Scholar]
- Rozenberszki, D.; Majdik, A.L. LOL: Lidar-only odometry and localization in 3D point cloud maps. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 4379–4385. [Google Scholar]
- Zhang, J.; Singh, S. LOAM: Lidar odometry and mapping in real-time. In Proceedings of the Robotics: Science and Systems, Berkeley, CA, USA, 12–16 July 2014; pp. 1–9. [Google Scholar]
- Shan, T.; Englot, B.; Meyers, D.; Wang, W.; Ratti, C.; Rus, D. Lio-sam: Tightly-coupled lidar inertial odometry via smoothing and mapping. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020; pp. 5135–5142. [Google Scholar]
- Tang, H.; Liu, Z.; Zhao, S.; Lin, Y.; Lin, J.; Wang, H.; Han, S. Searching Efficient 3d architectures with sparse point-voxel convolution. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 685–702. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9297–9307. [Google Scholar]
- Schirra, S. How reliable are practical point-in-polygon strategies? In Proceedings of the European Symposium on Algorithms, Karlsruhe, Germany, 15–17 September 2008; pp. 744–755. [Google Scholar]




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1: car | 2: bicycle | 3: motorcycle | 4: truck |
| 5: other-vehicle | 6: person | 7: bicyclist | 8: motorcyclist |
| 9: road | 10: parking | 11: sidewalk | 12: other-ground |
| 13: building | 14: fence | 15: vegetation | 16: trunk |
| 17: terrain | 18: pole | 19: traffic-sign |
| Sequence | Scans | Trajectory Length (m) | Proportion of Frames Containing Dynamic Items |
|---|---|---|---|
| 00 | 4541 | 3722 | 32% |
| 01 | 1101 | 2588 | 13% |
| 02 | 4661 | 5067 | 26% |
| 04 | 271 | 403 | 16% |
| 05 | 2761 | 2206 | 24% |
| 06 | 1101 | 1220 | 17% |
| 07 | 1101 | 694 | 28% |
| 08 | 5171 | 2631 | 21% |
| 09 | 1591 | 1709 | 16% |
| 10 | 1201 | 919 | 12% |
| KITTI Dataset | JLU Campus Dataset | ||||
|---|---|---|---|---|---|
| Sequence | SC-BBS | Ours | Sequence | SC-BBS | Ours |
| 00 | 95.3% | 97.3% | JLU_01 | 90.3% | 98.7% |
| 01 | 88.2% | 91.6% | JLU_02 | 95.2% | 97.6% |
| 02 | 86.2% | 90.7% | JLU_03 | 94.6% | 99.4% |
| 04 | 95.1% | 86.2% | JLU_04 | 94.2% | 98.2% |
| 05 | 83.6% | 97.8% | JLU_05 | 90.5% | 97.8% |
| 06 | 86.6% | 98.8% | JLU_06 | 93.3% | 99.1% |
| 07 | 96.8% | 98.4% | JLU_07 | 92.4% | 97.4% |
| 08 | 96.5% | 96.9% | JLU_08 | 81.2% | 97.9% |
| 09 | 92.1% | 93.7% | JLU_09 | 86.7% | 86.0% |
| 10 | 86.6% | 87.4% | JLU_10 | 92.1% | 90.1% |
| Average | 90.7% | 93.9% | Average | 91.0% | 96.2% |
| KITTI Dataset | JLU Campus Dataset | ||||
|---|---|---|---|---|---|
| Sequence | SRI-STATIC | Ours | Sequence | SRI-STATIC | Ours |
| 00 | 4693 | 535 | JLU_01 | 4286 | 521 |
| 01 | 5782 | 582 | JLU_02 | 4597 | 593 |
| 02 | 4894 | 636 | JLU_03 | 5317 | 564 |
| 04 | 5217 | 488 | JLU_04 | 5188 | 492 |
| 05 | 5792 | 538 | JLU_05 | 4197 | 581 |
| 06 | 4831 | 543 | JLU_06 | 4731 | 539 |
| 07 | 4937 | 528 | JLU_07 | 5873 | 499 |
| 08 | 5274 | 615 | JLU_08 | 4258 | 521 |
| 09 | 5931 | 620 | JLU_09 | 4364 | 578 |
| 10 | 5241 | 539 | JLU_10 | 4821 | 565 |
| Average | 5259 | 562 | Average | 4763 | 545 |
| KITTI Dataset | JLU Campus Dataset | ||||
|---|---|---|---|---|---|
| Sequence | SRI-STATIC | Ours | Sequence | SRI-STATIC | Ours |
| 00 | 93.6% | 97.3% | JLU_01 | 92.4% | 98.7% |
| 01 | 91.5% | 91.6% | JLU_02 | 93.7% | 97.6% |
| 02 | 86.2% | 90.7% | JLU_03 | 91.6% | 99.4% |
| 04 | 95.1% | 86.2% | JLU_04 | 93.1% | 98.2% |
| 05 | 93.6% | 97.8% | JLU_05 | 90.7% | 97.8% |
| 06 | 92.4% | 98.8% | JLU_06 | 92.6% | 99.1% |
| 07 | 94.8% | 98.4% | JLU_07 | 91.3% | 97.4% |
| 08 | 92.1% | 96.9% | JLU_08 | 88.6% | 97.9% |
| 09 | 93.7% | 93.7% | JLU_09 | 86.7% | 86.0% |
| 10 | 84.2% | 87.4% | JLU_10 | 89.4% | 90.1% |
| Average | 91.7% | 93.9% | Average | 91.0% | 96.2% |
| KITTI Dataset | JLU Campus Dataset | ||||||
|---|---|---|---|---|---|---|---|
| Sequence | SC-NDT | HDL | Ours | Sequence | SC-NDT | HDL | Ours |
| 00 | 77.3% | 75.8% | 97.3% | JLU_01 | 47.5% | 95.3% | 98.7% |
| 01 | 74.0% | 79.5% | 91.6% | JLU_02 | 52.4% | 88.2% | 97.6% |
| 02 | 76.2% | 65.8% | 90.7% | JLU_03 | 49.5% | 86.2% | 99.4% |
| 04 | 84.9% | 86.8% | 86.2% | JLU_04 | 46.8% | 95.1% | 98.2% |
| 05 | 82.8% | 78.5% | 97.8% | JLU_05 | 53.6% | 83.6% | 97.8% |
| 06 | 68.1% | 83.6% | 98.8% | JLU_06 | 48.5% | 86.6% | 99.1% |
| 07 | 75.0% | 72.9% | 98.4% | JLU_07 | 50.3% | 96.8% | 97.4% |
| 08 | 63.8% | 76.7% | 96.9% | JLU_08 | 45.9% | 96.5% | 97.9% |
| 09 | 81.4% | 84.8% | 93.7% | JLU_09 | 43.7% | 92.1% | 86.0% |
| 10 | 76.3% | 89.3% | 87.4% | JLU_10 | 52.4% | 86.6% | 90.1% |
| Average | 76.0% | 79.4% | 93.9% | Average | 49.1% | 90.1% | 96.2% |
| KITTI Dataset | JLU Campus Dataset | ||||
|---|---|---|---|---|---|
| Sequence | No Factor Graph Model | Ours | Sequence | No Factor Graph Model | Ours |
| 0 | 0.316 | 0.224 | JLU_01 | 0.382 | 0.272 |
| 1 | 0.295 | 0.141 | JLU_02 | 0.261 | 0.14 |
| 2 | 0.342 | 0.281 | JLU_03 | 0.352 | 0.199 |
| 4 | 0.154 | 0.096 | JLU_04 | 0.247 | 0.218 |
| 5 | 0.231 | 0.141 | JLU_05 | 0.413 | 0.246 |
| 6 | 0.286 | 0.277 | JLU_06 | 0.196 | 0.178 |
| 7 | 0.273 | 0.266 | JLU_07 | 0.341 | 0.293 |
| 8 | 0.258 | 0.218 | JLU_08 | 0.472 | 0.352 |
| 9 | 0.225 | 0.151 | JLU_09 | 0.394 | 0.389 |
| 10 | 0.137 | 0.117 | JLU_10 | 0.286 | 0.264 |
| Average | 0.252 | 0.191 | Average | 0.334 | 0.253 |
| KITTI Dataset | JLU Campus Dataset | ||||||
|---|---|---|---|---|---|---|---|
| Sequence | NDT | HDL | Ours | Sequence | NDT | HDL | Ours |
| 00 | 0.232 | 0.256 | 0.224 | JLU_01 | 0.312 | 0.337 | 0.272 |
| 01 | 0.224 | 0.134 | 0.141 | JLU_02 | 0.156 | 0.148 | 0.140 |
| 02 | 0.264 | 0.585 | 0.281 | JLU_03 | 0.254 | 0.194 | 0.199 |
| 04 | 0.146 | 0.130 | 0.096 | JLU_04 | 0.328 | 0.353 | 0.218 |
| 05 | 0.170 | 0.180 | 0.141 | JLU_05 | 0.259 | 0.208 | 0.246 |
| 06 | 0.347 | 0.442 | 0.277 | JLU_06 | 0.215 | 0.185 | 0.178 |
| 07 | 0.270 | 0.268 | 0.266 | JLU_07 | 0.319 | 0.318 | 0.293 |
| 08 | 0.239 | 0.231 | 0.218 | JLU_08 | 0.588 | 0.420 | 0.352 |
| 09 | 0.199 | 0.152 | 0.151 | JLU_09 | 0.498 | 0.512 | 0.389 |
| 10 | 0.149 | 0.118 | 0.117 | JLU_10 | 0.329 | 0.274 | 0.264 |
| Average | 0.224 | 0.250 | 0.191 | Average | 0.325 | 0.295 | 0.253 |
| KITTI Dataset | JLU Campus Dataset | ||||||
|---|---|---|---|---|---|---|---|
| Sequence | NDT | HDL | Ours | Sequence | NDT | HDL | Ours |
| 00 | 50.38 | 48.96 | 48.76 | JLU_01 | 86.01 | 60.32 | 34.05 |
| 01 | 47.28 | 34.78 | 45.28 | JLU_02 | 87.43 | 54.46 | 30.58 |
| 02 | 44.21 | 45.32 | 37.57 | JLU_03 | 88.33 | 48.87 | 31.93 |
| 04 | 48.52 | 48.21 | 29.35 | JLU_04 | 84.53 | 52.45 | 27.95 |
| 05 | 49.74 | 52.46 | 27.43 | JLU_05 | 93.24 | 47.38 | 26.98 |
| 06 | 54.31 | 46.32 | 38.84 | JLU_06 | 92.15 | 53.25 | 33.65 |
| 07 | 46.72 | 43.64 | 30.72 | JLU_07 | 76.54 | 42.51 | 28.45 |
| 08 | 39.99 | 59.73 | 39.89 | JLU_08 | 89.71 | 62.23 | 34.54 |
| 09 | 42.34 | 47.34 | 33.46 | JLU_09 | 92.52 | 57.35 | 36.98 |
| 10 | 48.43 | 53.68 | 35.63 | JLU_10 | 85.38 | 45.43 | 30.25 |
| Average | 47.19 | 48.04 | 36.69 | Average | 87.58 | 52.42 | 31.53 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Wang, G.; Zhou, W.; Zhang, T.; Zhang, H. A Localization Algorithm Based on Global Descriptor and Dynamic Range Search. Remote Sens. 2023, 15, 1190. https://doi.org/10.3390/rs15051190
Chen Y, Wang G, Zhou W, Zhang T, Zhang H. A Localization Algorithm Based on Global Descriptor and Dynamic Range Search. Remote Sensing. 2023; 15(5):1190. https://doi.org/10.3390/rs15051190
Chicago/Turabian StyleChen, Yongzhe, Gang Wang, Wei Zhou, Tongzhou Zhang, and Hao Zhang. 2023. "A Localization Algorithm Based on Global Descriptor and Dynamic Range Search" Remote Sensing 15, no. 5: 1190. https://doi.org/10.3390/rs15051190
APA StyleChen, Y., Wang, G., Zhou, W., Zhang, T., & Zhang, H. (2023). A Localization Algorithm Based on Global Descriptor and Dynamic Range Search. Remote Sensing, 15(5), 1190. https://doi.org/10.3390/rs15051190