
A ViSAR Shadow-Detection Algorithm Based on LRSD Combined Trajectory Region Extraction

Abstract
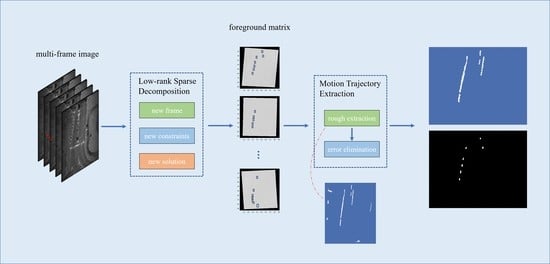
:
1. Introduction
2. Methodology
2.1. RPCA Theory of Video SAR
2.2. Improved LRSD Model
- (1)
- The moving target shadow occupies a certain number of pixels, presents a low gray-level distribution, and shows spatial and temporal continuous characteristics in the image. The norm in the RPCA model provides a relatively broad description of the low-rank characteristics of moving targets, but the noise and clutter in the image also have low-rank properties, which will seriously affect the matrix decomposition results. Considering the shadow-distribution characteristics of moving objects and the relative-motion characteristics between frames, a weighted total variation is used instead of the norm to constrain the foreground matrix. In other applications, the total variation function will bring a certain degree of smoothness. Here, it is assumed that the dynamic background is sparser than the smoothed foreground [18,19]. Objects that transform smoothly and have few sharp edges will have a low TV value, while sparse damage will have a very high TV value, so the total variation can be used as a sparse measure of the foreground target and the dynamic background. Equation (2) is a TV expression.
- (2)
- The applicability of the total variation is restricted by the assumptions, and the decomposition effect of the model decreases when the assumptions are incorrect. A new decomposition framework is constructed by introducing the dynamic background constraint items and correlation-suppression items. The former is used to independently divide the dynamic background space, and the latter makes the moving target and the dynamic background better distinguishable. The new model is as follows.
- (3)
- Due to the problem that the road edge is seriously affected by the actual decomposition effect, the Sobel edge operator is used to extract these interference areas. A global constraint composed of a mapping function is added to the model to eliminate the influence of this interference. The Sobel operator is a commonly used edge detection method. It is essentially based on the convolution of the image space domain and is supported by the theory of the first derivative operator of the image. This method has a fast processing speed and has a smoothing effect on noise. The extracted edges are smooth and continuous, making them more suitable for this extraction task. The final model is presented as follows.
2.3. Solution of the New Model
- Update .
- ii
- Update .
- iii
- Update .
| Algorithm 1. Proposed method |
| Input: Video frames |
| Construct matrix |
| Initialization:, , |
| while not converge do |
| Update , , via (24) |
| Update by performing iterations of (21) |
| Output: |
2.4. Motion-Track Region Extraction
3. Experiment
3.1. Performance Comparison Experiment of the Improved LRSD Model
3.2. Shadow Detection Experiment
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kim, S.H.; Fan, R.; Dominski, F. ViSAR: A 235 GHz radar for airborne applications. In Proceedings of the 2018 IEEE Radar Conference (RadarConf18), Oklahoma City, OK, USA, 23–27 April 2018; pp. 1549–1554. [Google Scholar] [CrossRef]
- Liu, F.; Antoniou, M.; Zeng, Z.; Cherniakov, M. Coherent change detection using passive GNSS-based BSAR: Experimental proof of concept. IEEE Trans. Geosci. Remote Sens. 2013, 51, 4544–4555. [Google Scholar] [CrossRef]
- Zhong, C.; Ding, J.; Zhang, Y. Joint Tracking of Moving Target in Single-Channel Video SAR. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5212718. [Google Scholar] [CrossRef]
- Raney, R.K. Synthetic aperture imaging radar and moving targets. IEEE Trans. Aerosp. Electron. Syst. 1971, AES-7, 499–505. [Google Scholar] [CrossRef]
- Chiu, S. A constant false alarm rate (CFAR) detector for RADARSAT-2 along-track interferometry. Can. J. Remote Sens. 2005, 31, 73–84. [Google Scholar] [CrossRef]
- Brennan, L.E.; Reed, L.S. Theory of adaptive radar. IEEE Trans. Aerosp. Electron. Syst. 1973, AES-9, 237–252. [Google Scholar] [CrossRef]
- Ding, J.; Zhong, C.; Wen, L.; Xu, Z. Joint detection of moving target in video synthetic aperture radar. J. Radars 2022, 11, 313–323. [Google Scholar]
- Jahangir, M. Moving target detection for synthetic aperture radar via shadow detection. In Proceedings of the IET International Conference on Radar Systems, Edinburgh, UK, 15–18 October 2007. [Google Scholar]
- Wang, H.; Chen, Z.; Zheng, S. Preliminary research of low-RCS moving target detection based on Ka-band video SAR. IEEE Geosci. Remote Sens. Lett. 2017, 14, 811–815. [Google Scholar] [CrossRef]
- Zhang, Y.; Mao, X.; Yan, H.; Zhu, D.; Hu, X. A novel approach to moving targets shadow detection in VideoSAR imagery sequence. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 606–609. [Google Scholar]
- Ding, J.; Wen, L.; Zhong, C.; Loffeld, O. Video SAR moving target indication using deep neural network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7194–7204. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, S.; Li, H.; Xu, Z. Shadow tracking of moving target based on CNN for video SAR system. In Proceedings of the IGARSS 2018–2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4399–4402. [Google Scholar]
- Zhang, H.; Liu, Z. Moving Target Shadow Detection Based on Deep Learning in Video SAR. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 4155–4158. [Google Scholar]
- Bao, J.; Zhang, X.; Zhang, T.; Xu, X. ShadowDeNet: A Moving Target Shadow Detection Network for Video SAR. Remote Sens. 2022, 14, 320. [Google Scholar] [CrossRef]
- Wright, J.; Ganesh, A.; Rao, S.; Peng, Y.; Ma, Y. Robust principal component analysis: Exact recovery of corrupted low-rank matrices via convex optimization. Adv. Neural Inf. Process. Syst. 2009, 22, 2080–2088. [Google Scholar]
- Zhang, Z.; Shen, W.; Lin, Y.; Hong, W. Single-channel circular SAR ground moving target detection based on LRSD and adaptive threshold detector. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Available online: https://www.sandia.gov/radar/pathfinder-radar-isr-and-synthetic-aperture-radar-sar-systems/video/ (accessed on 10 November 2022).
- Shijila, B.; Tom, A.J.; George, S.N. Moving object detection by low rank approximation and l1-TV regularization on RPCA framework. J. Vis. Commun. Image Represent. 2018, 56, 188–200. [Google Scholar] [CrossRef]
- Cao, X.; Yang, L.; Guo, X. Total variation regularized RPCA for irregularly moving object detection under dynamic background. IEEE Trans. Cybern. 2015, 46, 1014–1027. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Wu, J.; Huo, W.; Jiang, R.; Li, Z.; Yang, J.; Li, H. Target-oriented SAR imaging for SCR improvement via deep MF-ADMM-Net. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Vairalkar, M.K.; Nimbhorkar, S.U. Edge detection of images using Sobel operator. Int. J. Emerg. Technol. Adv. Eng. 2012, 2, 291–293. [Google Scholar]
- Mairal, J.; Jenatton, R.; Obozinski, G.; Bach, F. Network flow algorithms for structured sparsity. arXiv 2010, arXiv:1008.5209. [Google Scholar]
- Parikh, N. Proximal algorithms. Found. Trends Optim. 2014, 1, 127–239. [Google Scholar] [CrossRef]
- Moore, B.E.; Gao, C.; Nadakuditi, R.R. Panoramic robust PCA for foreground–background separation on noisy, free-motion camera video. IEEE Trans. Comput. Imaging 2019, 5, 195–211. [Google Scholar] [CrossRef] [Green Version]
- Cai, J.F.; Candès, E.J.; Shen, Z. A singular value thresholding algorithm for matrix completion. SIAM J. Optim. 2010, 20, 1956–1982. [Google Scholar] [CrossRef]
- Nadakuditi, R.R. OptShrink: An algorithm for improved low-rank signal matrix denoising by optimal, data-driven singular value shrinkage. IEEE Trans. Inf. Theory 2014, 60, 3002–3018. [Google Scholar] [CrossRef] [Green Version]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM 2011, 58, 1–37. [Google Scholar] [CrossRef]
- Zhou, Z.; Li, X.; Wright, J.; Candes, E.; Ma, Y. Stable principal component pursuit. In Proceedings of the 2010 IEEE International Symposium on Information Theory, Austin, TX, USA, 13–18 June 2010; pp. 1518–1522. [Google Scholar]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-sign detection and classification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2110–2118. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, Z.; Zheng, M.; Ren, Y. A ViSAR Shadow-Detection Algorithm Based on LRSD Combined Trajectory Region Extraction. Remote Sens. 2023, 15, 1542. https://doi.org/10.3390/rs15061542
Yin Z, Zheng M, Ren Y. A ViSAR Shadow-Detection Algorithm Based on LRSD Combined Trajectory Region Extraction. Remote Sensing. 2023; 15(6):1542. https://doi.org/10.3390/rs15061542
Chicago/Turabian StyleYin, Zhongzheng, Mingjie Zheng, and Yuwei Ren. 2023. "A ViSAR Shadow-Detection Algorithm Based on LRSD Combined Trajectory Region Extraction" Remote Sensing 15, no. 6: 1542. https://doi.org/10.3390/rs15061542
APA StyleYin, Z., Zheng, M., & Ren, Y. (2023). A ViSAR Shadow-Detection Algorithm Based on LRSD Combined Trajectory Region Extraction. Remote Sensing, 15(6), 1542. https://doi.org/10.3390/rs15061542