


A Low-Cost Deep Learning System to Characterize Asphalt Surface Deterioration



Abstract
:1. Introduction
1.1. Contributions
- A segmentation deep neural network, based on U-Net architecture, for identifying crack regions in images that was trained using five publicly available datasets.
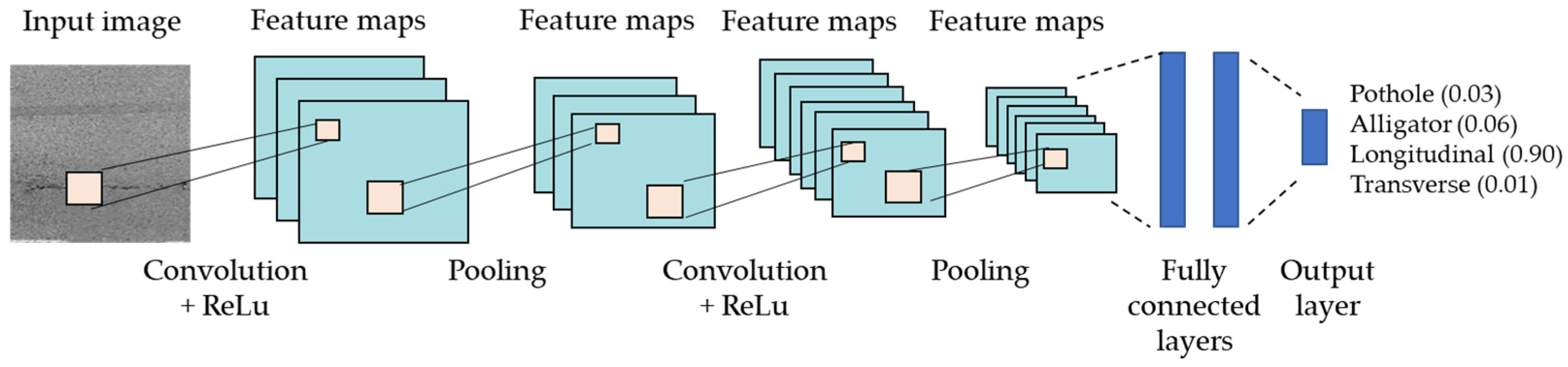
- A classification deep neural network used to classify detected cracks into one of four classes: (i) alligator; (ii) longitudinal; (iii) transverse; or (iv) non-crack.
- A system used to automatically estimate the percentage of cracking present in a road pavement segment to serve as an aid for experts in their maintenance planning.
- An anomaly detection method based on isolated cracking classifications that relates uncertainty to the proposed system results.
1.2. Related Work
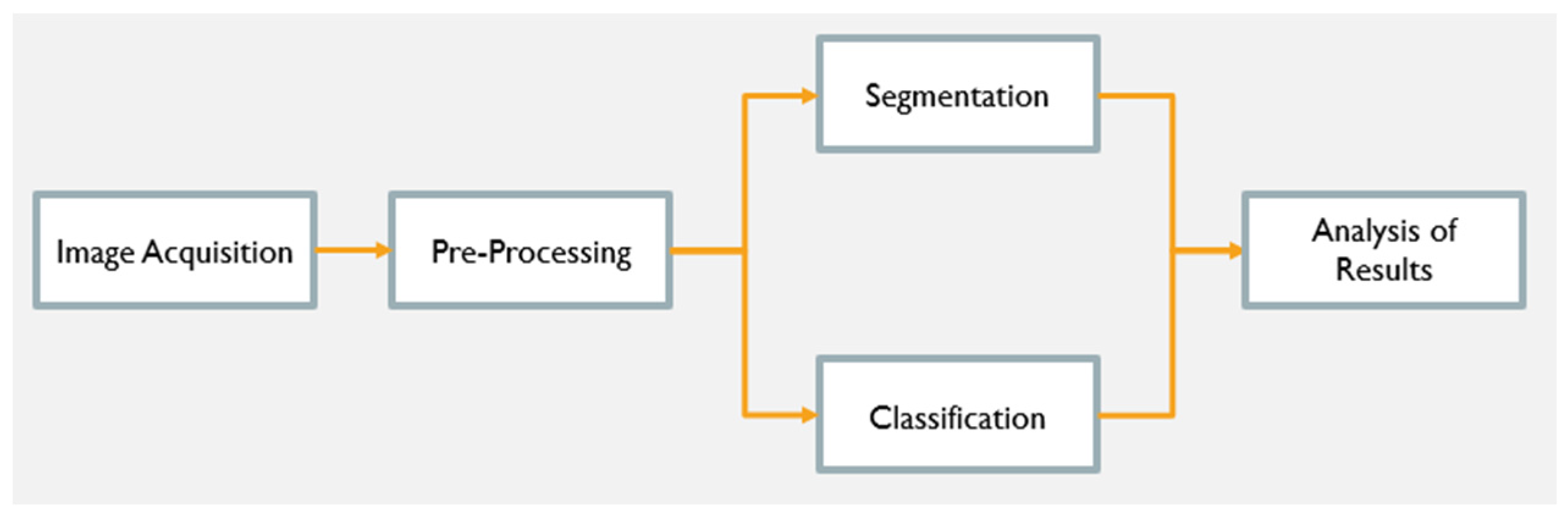
2. Materials and Methods
- Image Acquisition—This step deals with the acquisition of the road pavement images to be analyzed. A set of representative images was considered to create a dataset for usage along the development of the crack detection and classification system.
- Preprocessing—This step performs a set of image manipulations and transformations, notably for normalization purposes.
- Segmentation—This step creates an image map identifying which image pixels are affected by cracking.
- Classification—This step assigns a crack type classification for each detected crack.
- Analysis of Results—This step is responsible for combining the results produced by the segmentation and classification steps.
2.1. Image Acquisition
- Camera slant angle;
- Camera focal length;
- Camera frame rate;
- Camera resolution;
- Vehicle speed.
- CrackForest: Contains 118 crack images of a road pavement surface in Beijing that are 480 × 320 pixels in size. The sensor used was the camera of an iphone5 [27].
- AigleRN: Contains 38 pre-processed grayscale images of a road pavement surface in France. Half of these images are of size 991 × 462 pixels, and the other half are of size 311 × 462 pixels [28].
- CrackTree260: Contains 260 images of size 800 × 600 pixels, captured by an area-array camera under visible light illumination conditions [29].
- CRKWH100: Contains 100 images of a road pavement surface of size 512 × 512 pixels, captured by a line array camera under visible light illumination conditions [30].
- CrackLS315: Contains 315 images of size 512 × 512 pixels, captured by a line array camera under laser illumination [31].
2.2. Preprocessing
2.3. Segmentation
2.4. Classification
2.5. Crack Percentage and Analysis of Results
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mohan, A.; Poobal, S. Crack detection using image processing: A critical review and analysis. Alex. Eng. J. 2018, 57, 787–798. [Google Scholar] [CrossRef]
- Ouyang, A.; Luo, C.; Zhou, C. Surface distresses detection of pavement based on digital image processing. In Computer and Computing Technologies in Agriculture IV; Springer: Berlin/Heidelberg, Germany, 2011; pp. 368–375. [Google Scholar]
- Tecnofisil. Tecnofisil–Consultores de Engenharia. Available online: https://tecnofisil.pt/ (accessed on 21 July 2022).
- Oliveira, H.; Correia, P.L. Automatic Road Crack Detection and Characterization. IEEE Trans. Intell. Transp. Syst. 2013, 14, 155–168. [Google Scholar] [CrossRef]
- Cao, W.; Liu, Q.; He, Z. Review of Pavement Defect Detection Methods. IEEE Access 2020, 8, 14531–14544. [Google Scholar] [CrossRef]
- Waseem Khan, M. A Survey: Image Segmentation Techniques. Int. J. Future Comput. Commun. 2014, 3, 89–93. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, H.; Correia, P.L. Automatic road crack segmentation using entropy and image dynamic thresholding. In Proceedings of the 17th European Signal Processing Conference (EUSIPCO 2009), Glasgow, UK, 24–28 August 2009; pp. 622–626. [Google Scholar]
- Ayenu-Prah, A.; Attoh-Okine, N. Evaluating Pavement Cracks with Bidimensional Empirical Mode Decomposition. EURASIP J. Adv. Signal Process. 2008, 2008, 861701–861708. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Huang, N.E. A study of the characteristics of white noise using the empirical mode decomposition method. Phys. Eng. Sci. 2004, 460, 1597–1611. [Google Scholar] [CrossRef]
- Li, Q.; Zou, Q.; Zhang, D.; Mao, Q. FoSA: F* Seed-growing Approach for crack-line detection from pavement images. Image Vis. Comput. 2011, 29, 861–872. [Google Scholar] [CrossRef]
- Tarjan, R.E. Data Structures and Network Algorithms; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1983. [Google Scholar]
- Zhang, L.; Yang, F.; Daniel Zhang, Y.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Aslan, O.D.; Gultepe, E.; Ramaji, I.J.; Kermanshachi, S. Using Artifical Intelligence for Automating Pavement Condition Assessment. In Proceedings of the International Conference on Smart Infrastructure and Construction 2019 (ICSIC), Cambridge, UK, 8–10 July 2019; pp. 337–341. [Google Scholar]
- Anand, S.; Gupta, S.; Darbari, V.; Kohli, S. Crack-pot: Autonomous Road Crack and Pothole Detection. In Proceedings of the 2018 Digital Image Computing: Techniques and Applications (DICTA), Canberra, Australia, 10–13 December 2018; pp. 1–6. [Google Scholar]
- David Jenkins, M.; Carr, T.A.; Iglesias, M.I.; Buggy, T.; Morison, G. A Deep Convolutional Neural Network for Semantic Pixel-Wise Segmentation of Road and Pavement Surface Cracks. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 2120–2124. [Google Scholar]
- Kang, K.; Wang, X. Fully Convolutional Neural Networks for Crowd Segmentation. arXiv 2014, arXiv:1411.4464. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhang, K.; Zhang, Y.; Cheng, H.-D. CrackGAN: Pavement Crack Detection Using Partially Accurate Ground Truths Based on Generative Adversarial Learning. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1306–1319. [Google Scholar] [CrossRef]
- Liu, C.; Zhu, C.; Xia, X.; Zhao, J.; Long, H. FFEDN: Feature Fusion Encoder Decoder Network for Crack Detection. IEEE Trans. Intell. Transp. Syst. 2022, 23, 15546–15557. [Google Scholar] [CrossRef]
- Ma, D.; Fang, H.; Wang, N.; Zhang, C.; Dong, J.; Hu, H. Automatic Detection and Counting System for Pavement Cracks Based on PCGAN and YOLO-MF. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22166–22178. [Google Scholar] [CrossRef]
- Han, C.; Ma, T.; Huyan, J.; Huang, X.; Zhang, Y. CrackW-Net: A Novel Pavement Crack Image Segmentation Convolutional Neural Network. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22135–22144. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1525–1535. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- U-Net Architecture. Available online: https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/ (accessed on 23 July 2022).
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef] [Green Version]
- Camera Teledyne Lumenera lt16059h. Available online: https://www.znjtech.cn/resources/datasheets/teledyne-lumenera/lt16059h-datasheet.pdf (accessed on 23 July 2022).
- CrackForest Dataset. Available online: https://github.com/cuilimeng/CrackForest-dataset (accessed on 23 July 2022).
- AigleRN. Available online: http://telerobot.cs.tamu.edu/bridge/Datasets.html (accessed on 23 July 2022).
- CrackTree260. Dataset and Ground Truth. Available online: https://1drv.ms/f/s!AittnGm6vRKLyiQUk3ViLu8L9Wzb (accessed on 23 July 2022).
- CRKWH100. Dataset, Ground Truth. Available online: https://1drv.ms/f/s!AittnGm6vRKLglyfiCw_C6BDeFsP (accessed on 23 July 2022).
- CrackLS315. Dataset, Ground Truth. Available online: https://1drv.ms/u/s!AittnGm6vRKLg0HrFfJNhP2Ne1L5?e=WYbPvF (accessed on 23 July 2022).
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2000, 120, 122–125. [Google Scholar]
- TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. Available online: https://www.tensorflow.org/ (accessed on 23 July 2022).
- Keras: Deep Learning for Humans. Available online: https://github.com/fchollet/keras (accessed on 23 July 2022).
- Guo, P.; Zhang, W.; Li, X.; Zhang, W. Adaptive Online Mutual Learning Bi-Decoders for Video Object Segmentation. IEEE Trans. Image Process. 2022, 31, 7063–7077. [Google Scholar] [CrossRef] [PubMed]
- Kerdvibulvech, C. A methodology for hand and finger motion analysis using adaptive probabilistic models. J. Embed. Syst. 2014, 2014, 18. [Google Scholar] [CrossRef] [Green Version]
- Yang, F.; Yuan, X.; Ran, J.; Shu, W.; Zhao, Y.; Qin, A.; Gao, C. Accurate Instance Segmentation for Remote Sensing Images via Adaptive and Dynamic Feature Learning. Remote Sens. 2021, 13, 4774. [Google Scholar] [CrossRef]
- Bourouis, S. Adaptive variational model and learning-based SVM for medical image segmentation. In Proceedings of the ICPRAM 2015–4th International Conference on Pattern Recognition Applications and Methods, Lisbon, Portugal, 10–12 January 2015; pp. 149–156. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trial | Speed (km/h) | Frame Rate | Resolution | Overlapping Region (m) |
|---|---|---|---|---|
| 1 | 50 | 3 | 4864 × 3232 | 2/6.5 |
| 2, 3, 4 | 70 | 3 | 4864 × 3232 | not guaranteed |
| 5, 6 | 70 | 8 | 2432 × 1616 | 4.5/6.5 |
| 7, 8 | 90 | 8 | 2432 × 1616 | 3.5/6.5 |
| Speed (km/h) | Frame Rate (fps) | Time Lapse (ms) |
|---|---|---|
| 50 | 4.6 | 217 |
| 70 | 6.5 | 154 |
| 90 | 8 | 120 |
| Layer | Kernel | Activation Function | Output |
|---|---|---|---|
| Convolutional | 5 × 5 | ReLU | (512, 512, 64) |
| MaxPooling | 2 × 2 | - | (256, 256, 64) |
| Convolutional | 5 × 5 | ReLU | (256, 256, 128) |
| MaxPooling | 2 × 2 | - | (128, 128, 128) |
| Convolutional | 5 × 5 | ReLU | (128, 128, 256) |
| MaxPooling | 2 × 2 | - | (64, 64, 256) |
| GlobalMaxPooling | - | - | 256 |
| Dense | - | ReLU | 64 |
| Dense | - | Softmax | 4 |
| Severity | Description | Affected Area |
|---|---|---|
| Level 1 | Isolated but noticeable crack (<2 mm) | 0.5 m × affected length |
| Level 2 | Open and/or branched longitudinal or transverse cracks | 2 m × affected length |
| Level 3 | Alligator cracks | Road lane width × affected length |
| Label | Severity | Affected Area |
|---|---|---|
| Longitudinal | Level 2 | 2 m × 3 m |
| Transverse | Level 2 | 2 m × 3.5 m |
| Alligator | Level 3 | 3.5 m × 3 m |
| Non-crack | - | 0 |
| Label | Affected Area | Uncertainty (%) |
|---|---|---|
| Longitudinal | 2 m × 3 m | 1.7 |
| Transverse | 2 m × 3.5 m | 2 |
| Alligator | 3.5 m × 3 m | 3 |
| Non-crack | 0 | 0 |
| Road Segment [Start (m), End (m)] | FT 2 % | FT 3 % | Total % | S—Uncertainty (%) | S—Total with Uncertainty (%) | |||
|---|---|---|---|---|---|---|---|---|
| T | S | T | S | T | S | |||
| [75,900; 76,000] | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| [76,000; 76,100] | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| [76,200; 76,300] | 41 | 26 | 0 | 3 | 41 | 29 | 4.7 | [24.3; 33.7] |
| [76,300; 76,400] | 54 | 5.1 | 0 | 0 | 54 | 5.1 | 1.7 | [3.4; 6.8] |
| [76,400; 76,500] | 0 | 1.7 | 0 | 0 | 0 | 1.7 | 1.7 | [0; 3.4] |
| [76,500; 76,600] | 0 | 7.1 | 0 | 0 | 0 | 7.1 | 5.4 | [1.7; 12.5] |
| [76,600; 76,700] | 18 | 7.1 | 0 | 0 | 18 | 7.1 | 3.4 | [3.7; 10.5] |
| [76,700; 76,800] | 57 | 15.7 | 0 | 3 | 57 | 18.7 | 7.1 | [11.6; 25.8] |
| [76,900; 77,000] | 18 | 27.7 | 0 | 0 | 18 | 27.7 | 3.4 | [24.3; 31.1] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Inácio, D.; Oliveira, H.; Oliveira, P.; Correia, P. A Low-Cost Deep Learning System to Characterize Asphalt Surface Deterioration. Remote Sens. 2023, 15, 1701. https://doi.org/10.3390/rs15061701
Inácio D, Oliveira H, Oliveira P, Correia P. A Low-Cost Deep Learning System to Characterize Asphalt Surface Deterioration. Remote Sensing. 2023; 15(6):1701. https://doi.org/10.3390/rs15061701
Chicago/Turabian StyleInácio, Diogo, Henrique Oliveira, Pedro Oliveira, and Paulo Correia. 2023. "A Low-Cost Deep Learning System to Characterize Asphalt Surface Deterioration" Remote Sensing 15, no. 6: 1701. https://doi.org/10.3390/rs15061701
APA StyleInácio, D., Oliveira, H., Oliveira, P., & Correia, P. (2023). A Low-Cost Deep Learning System to Characterize Asphalt Surface Deterioration. Remote Sensing, 15(6), 1701. https://doi.org/10.3390/rs15061701