
Unsupervised Affinity Propagation Clustering Based Clutter Suppression and Target Detection Algorithm for Non-Side-Looking Airborne Radar





Abstract
:1. Introduction
2. Signal Model
3. The Proposed Algorithm
4. Simulation Results
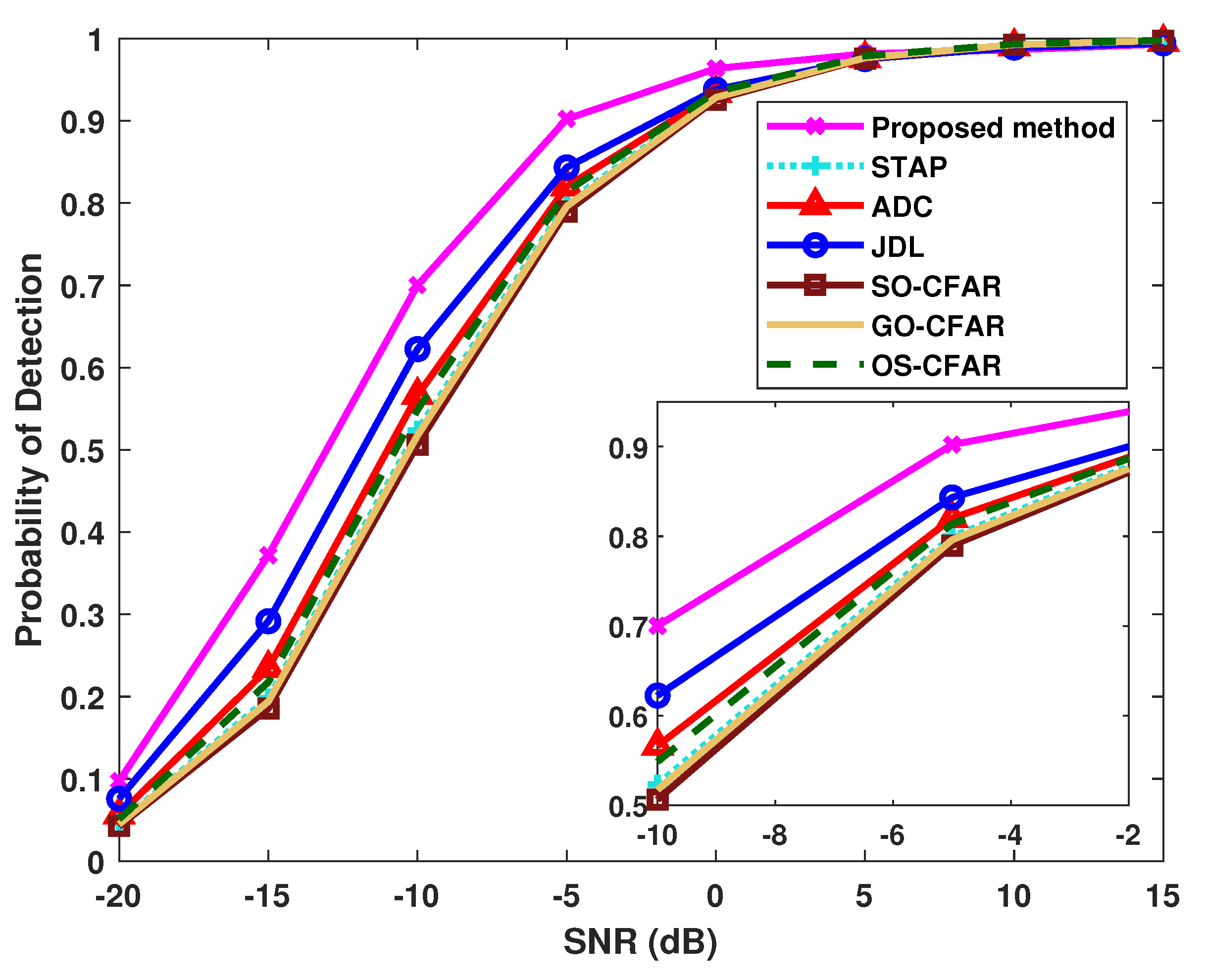
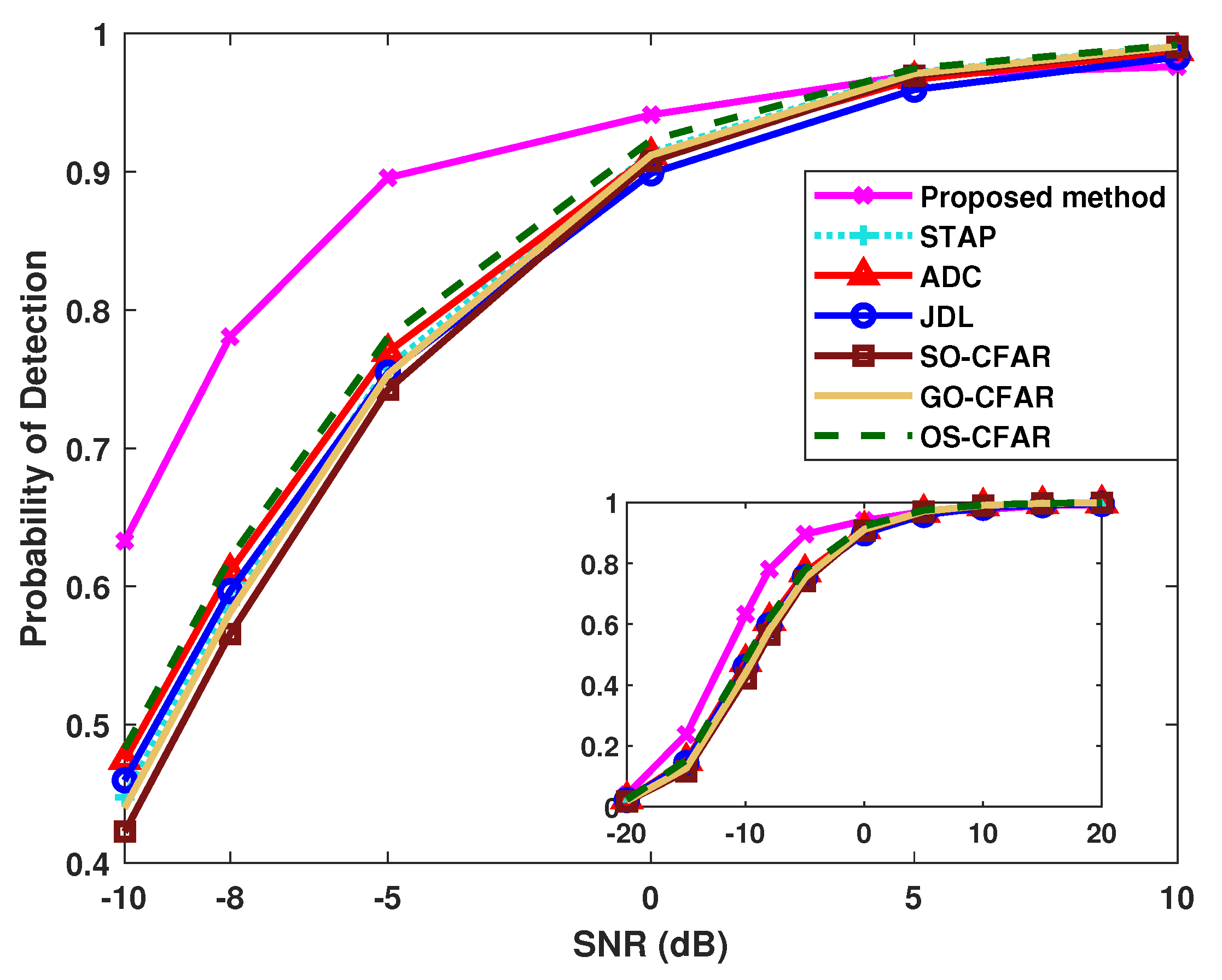
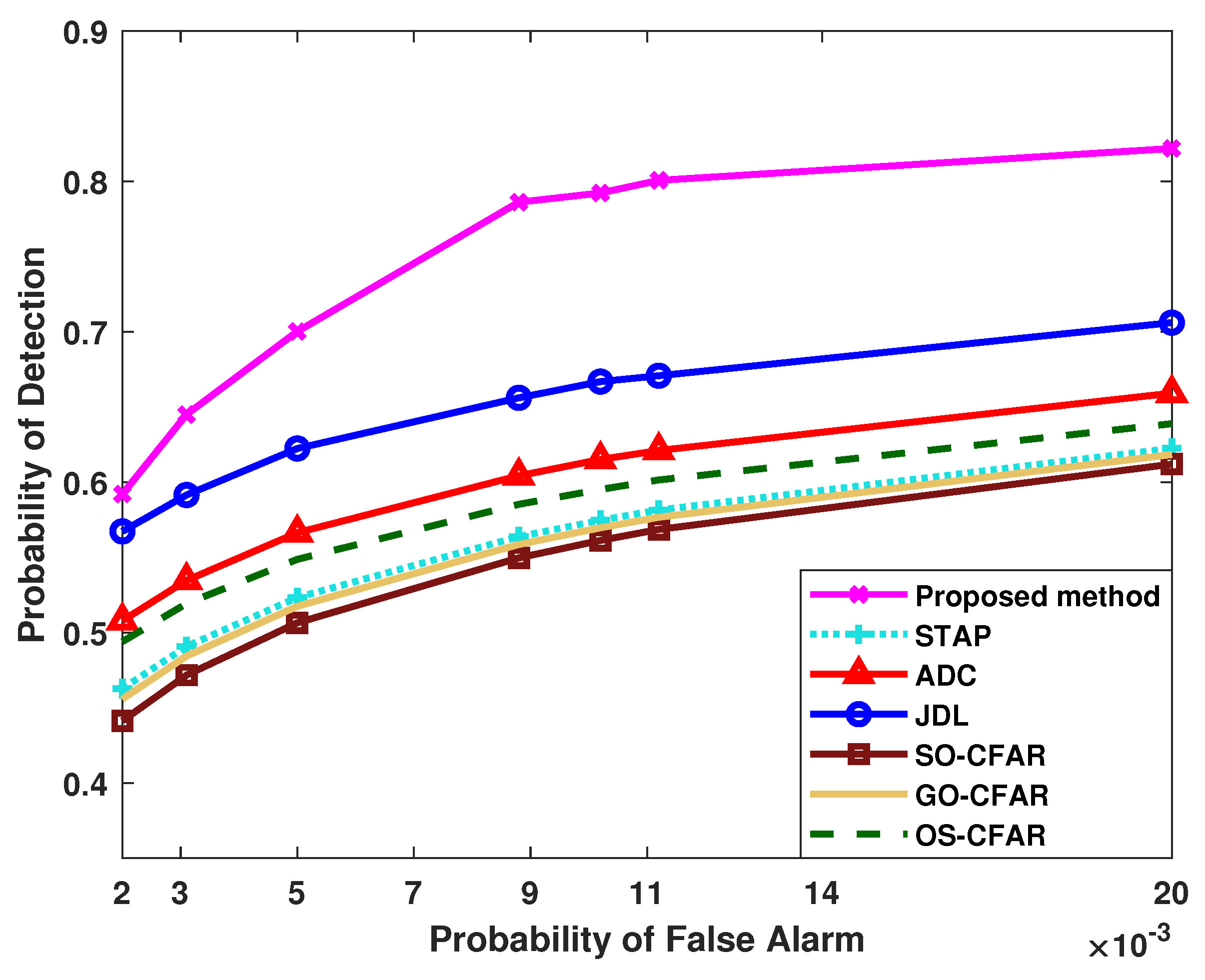
4.1. Results of the Probability of Detection
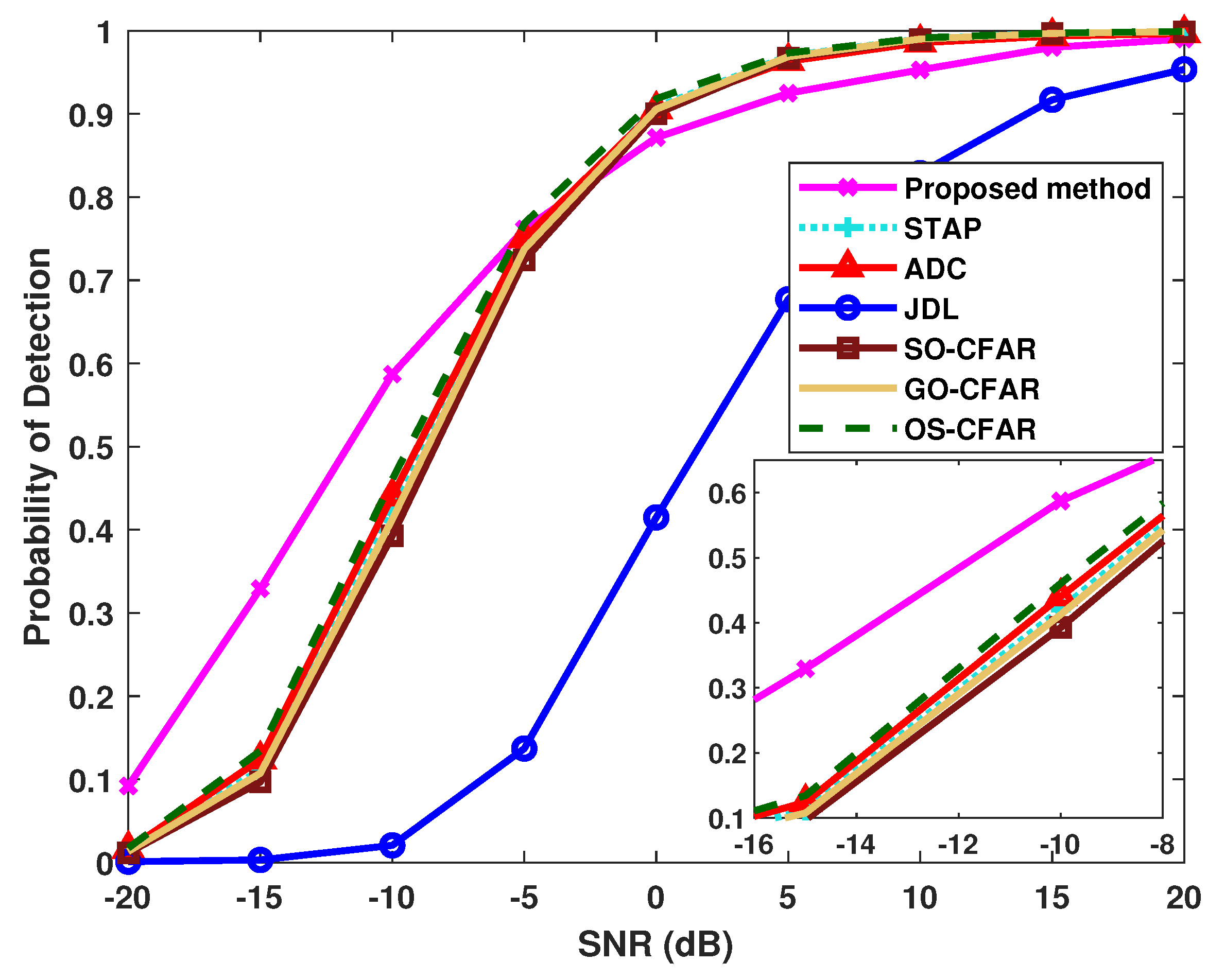
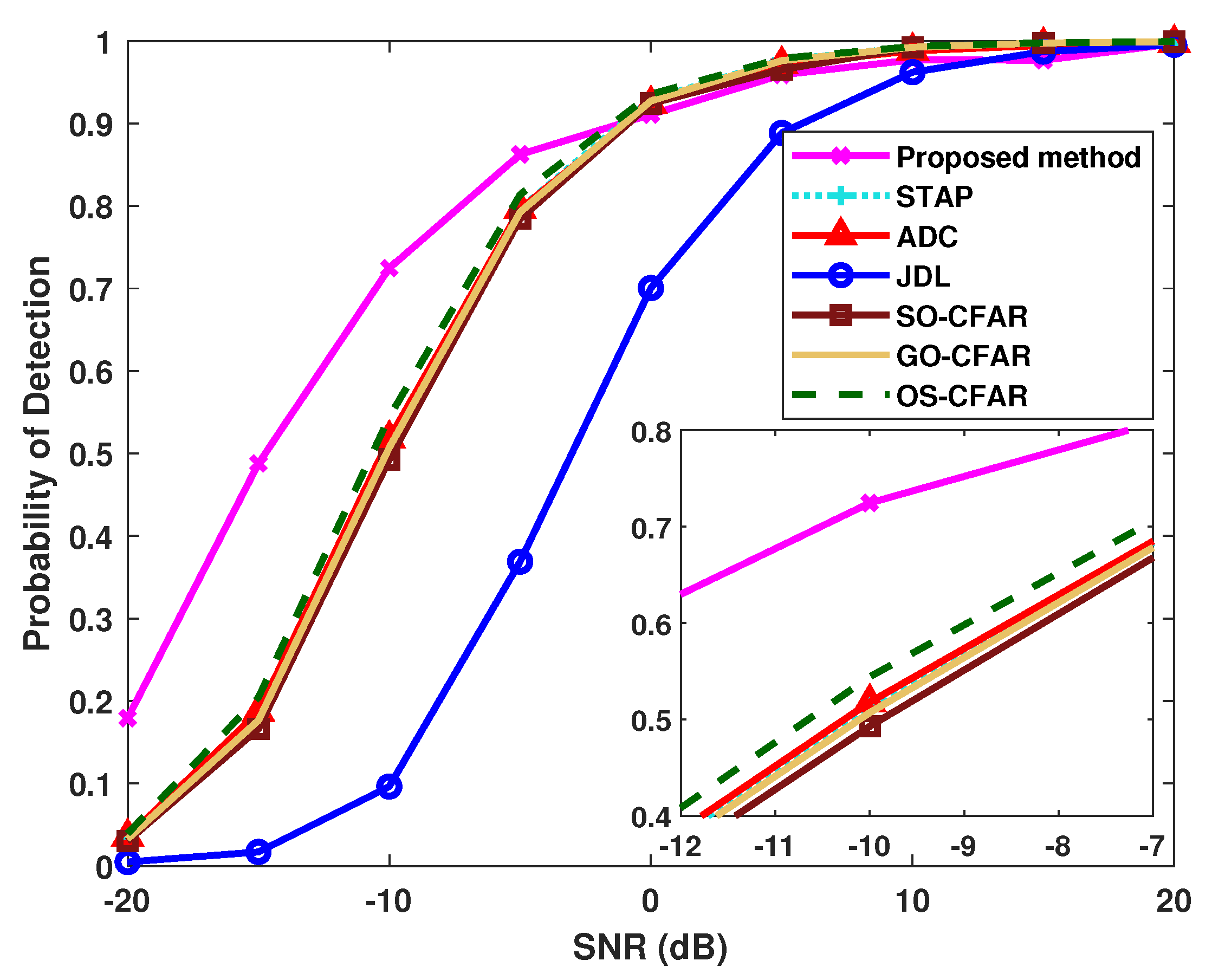
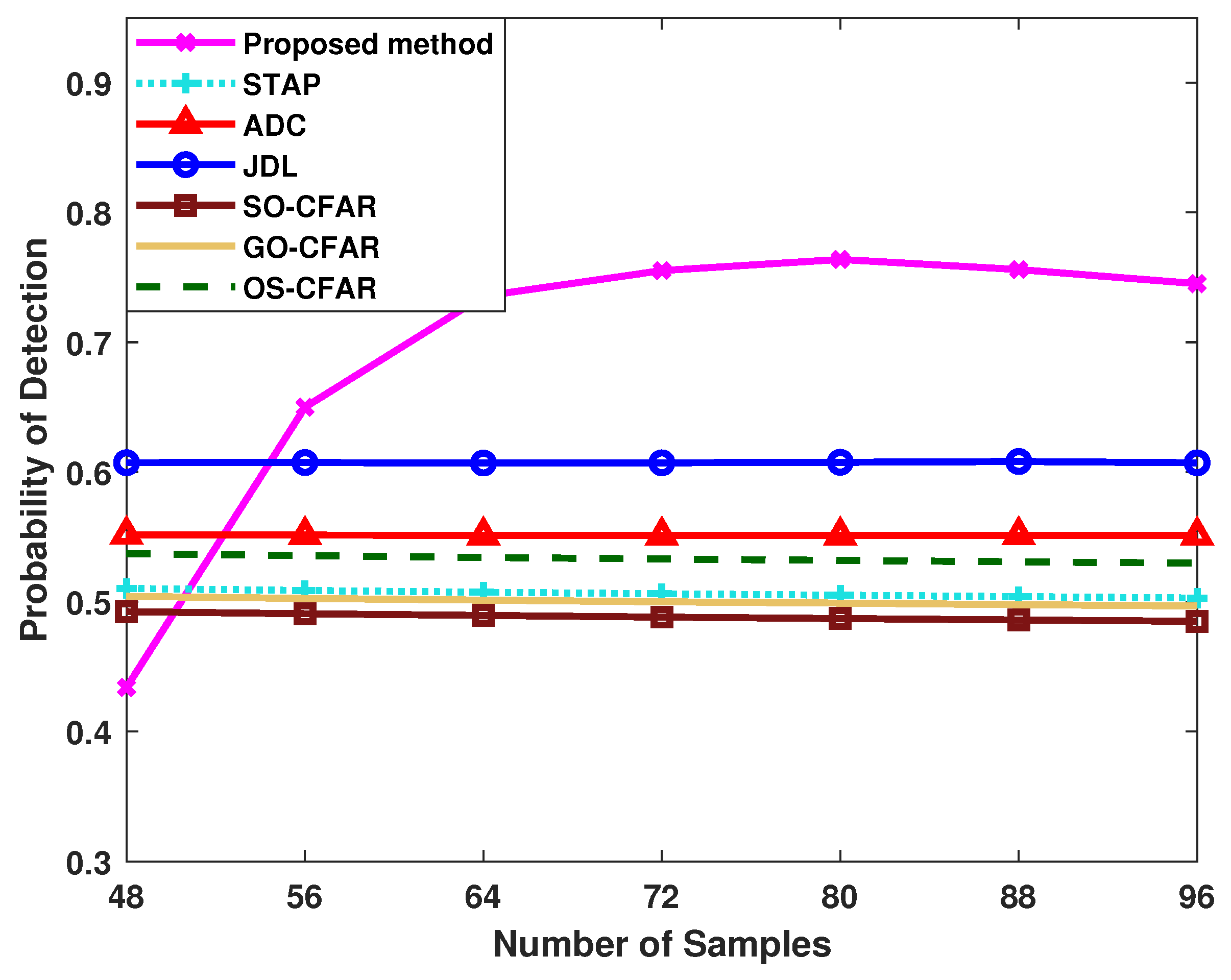
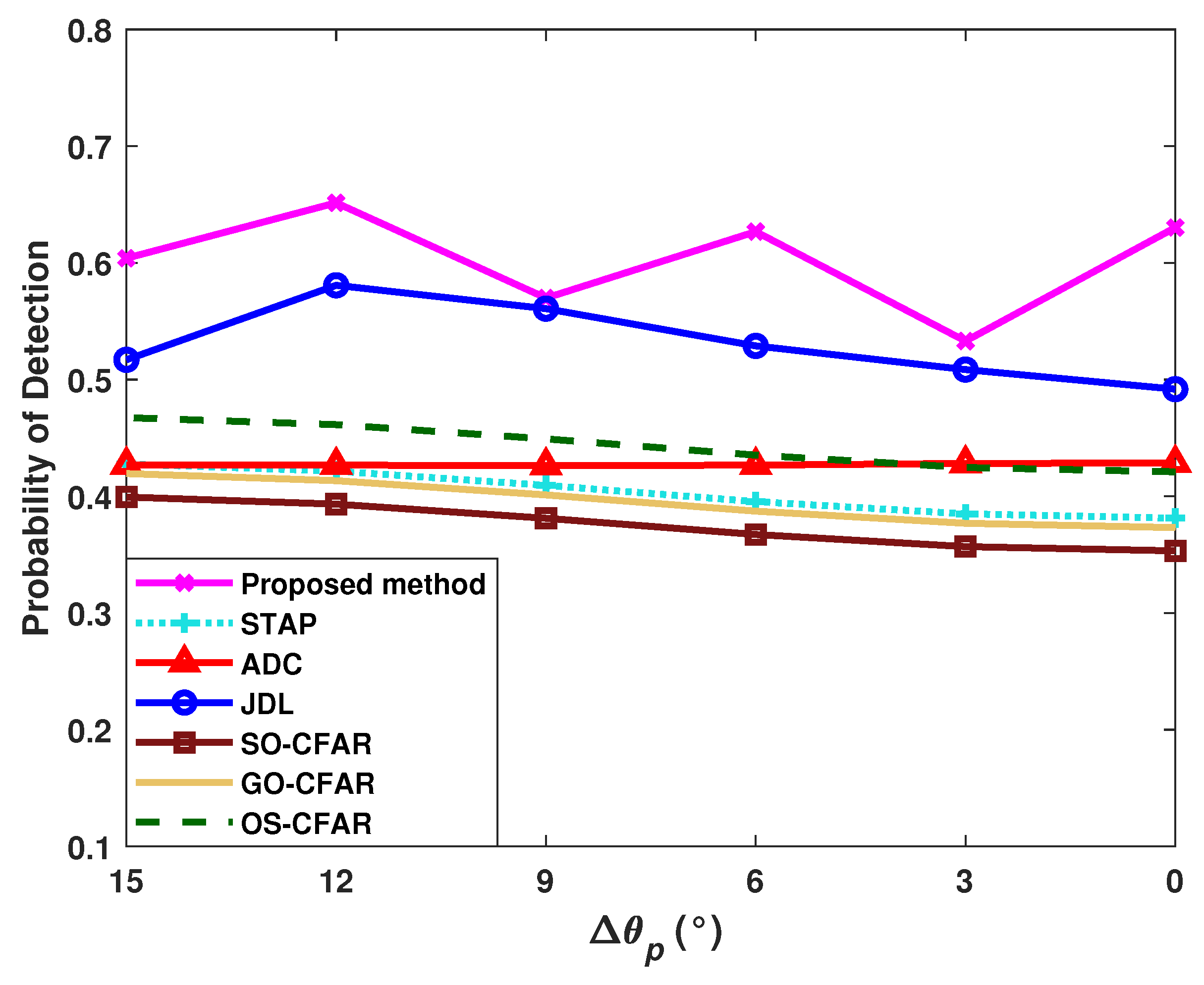
4.2. Influences of Sample Condition and Radar System Configuration
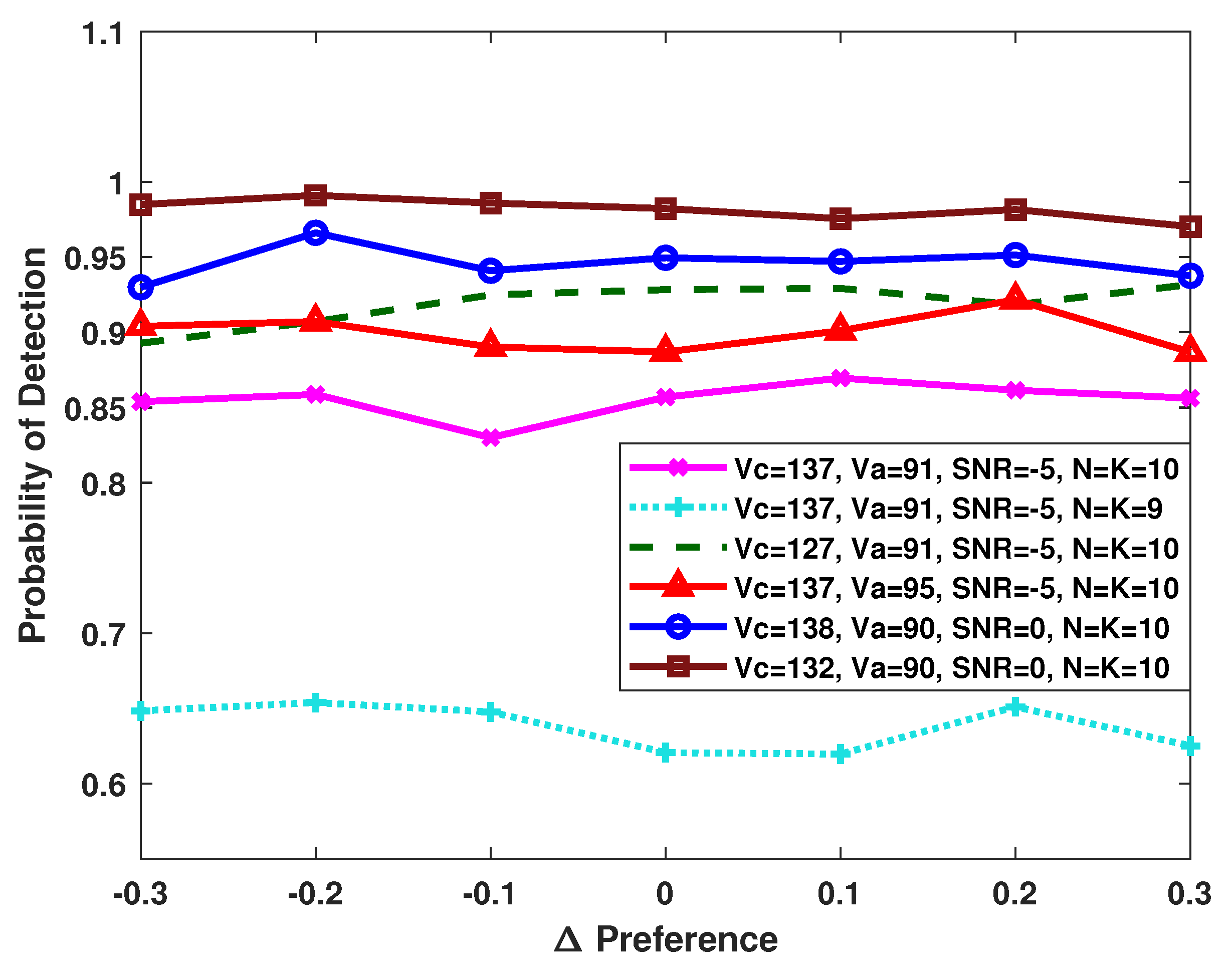
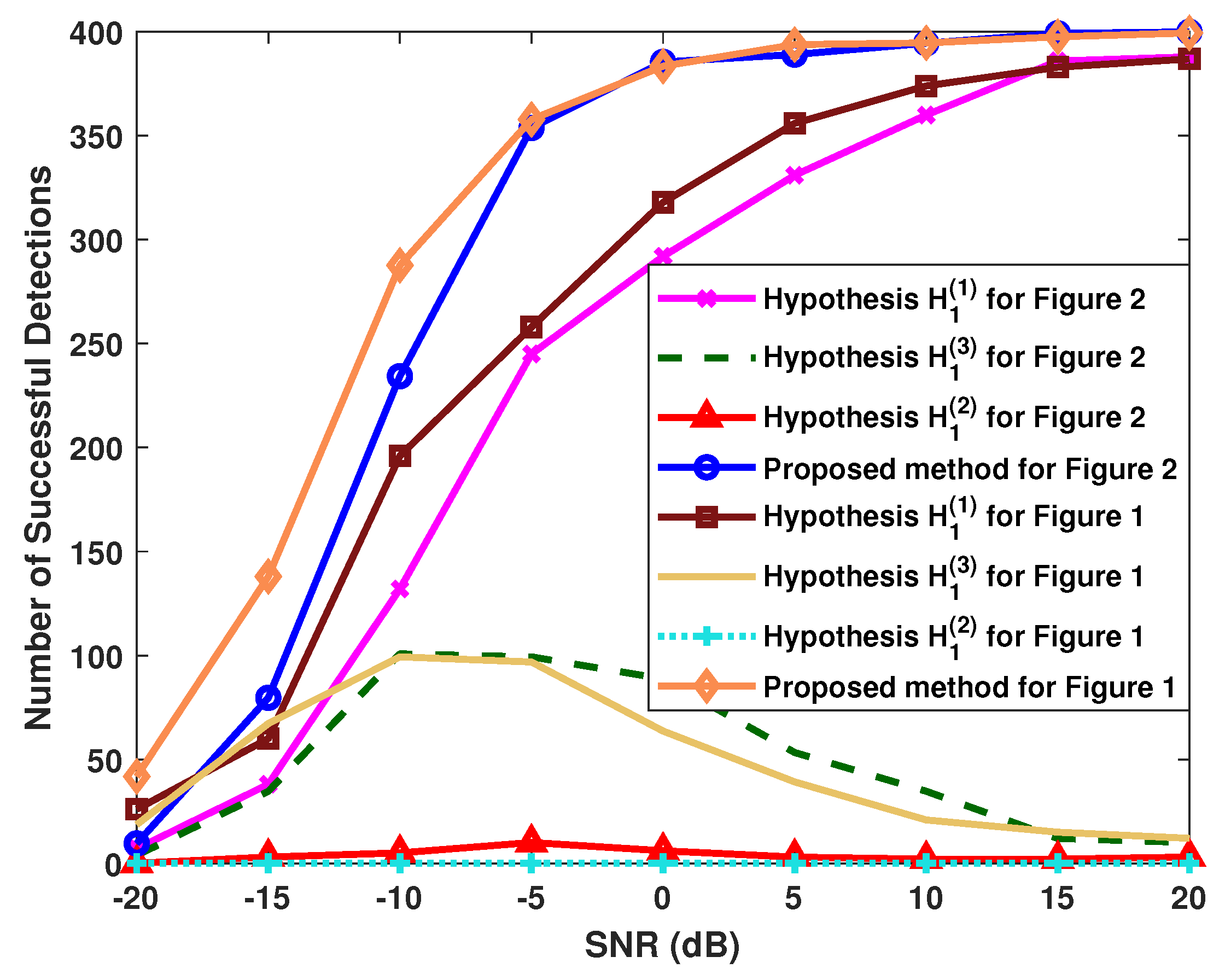
4.3. Influences of Parameters and Designed Hypotheses
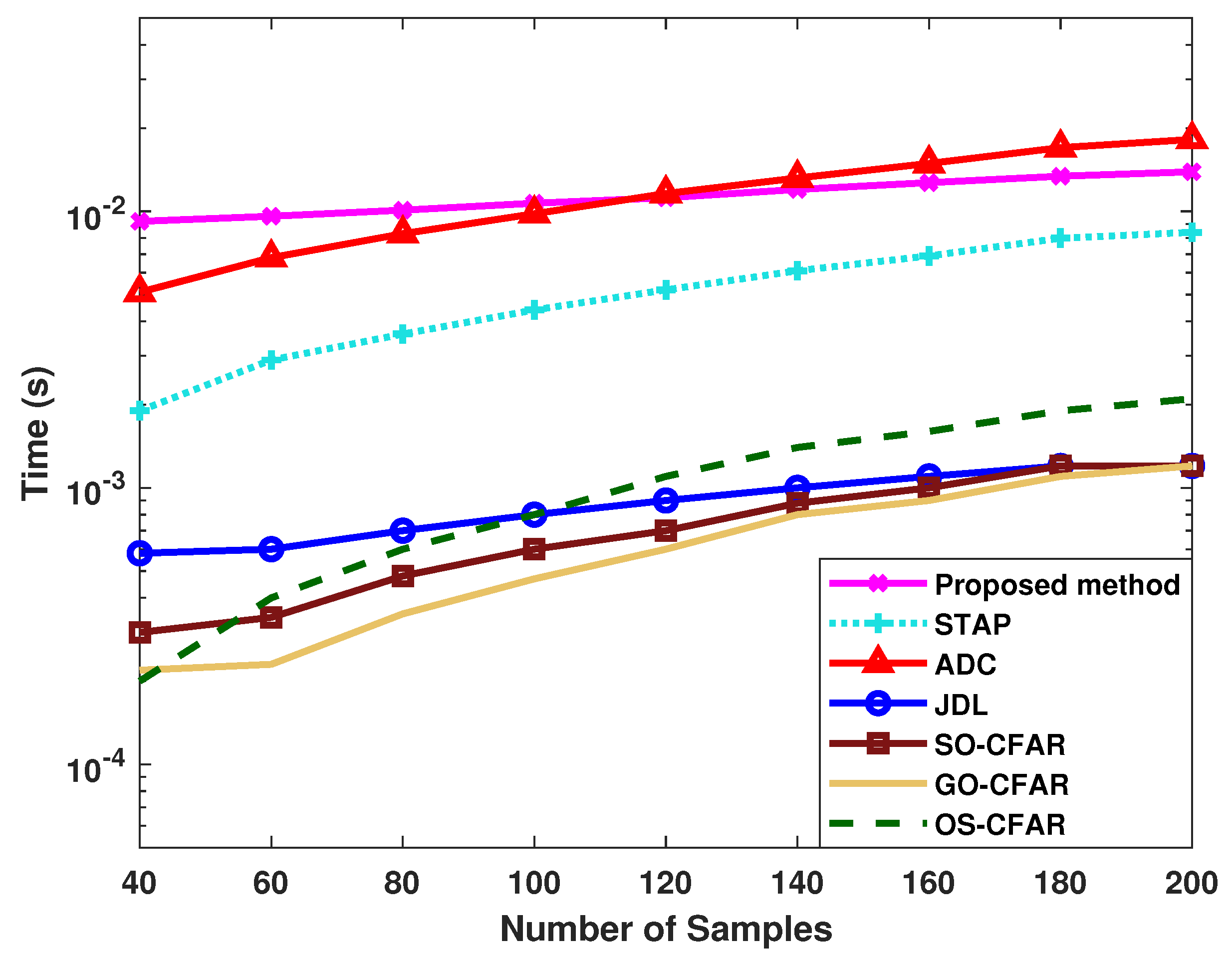
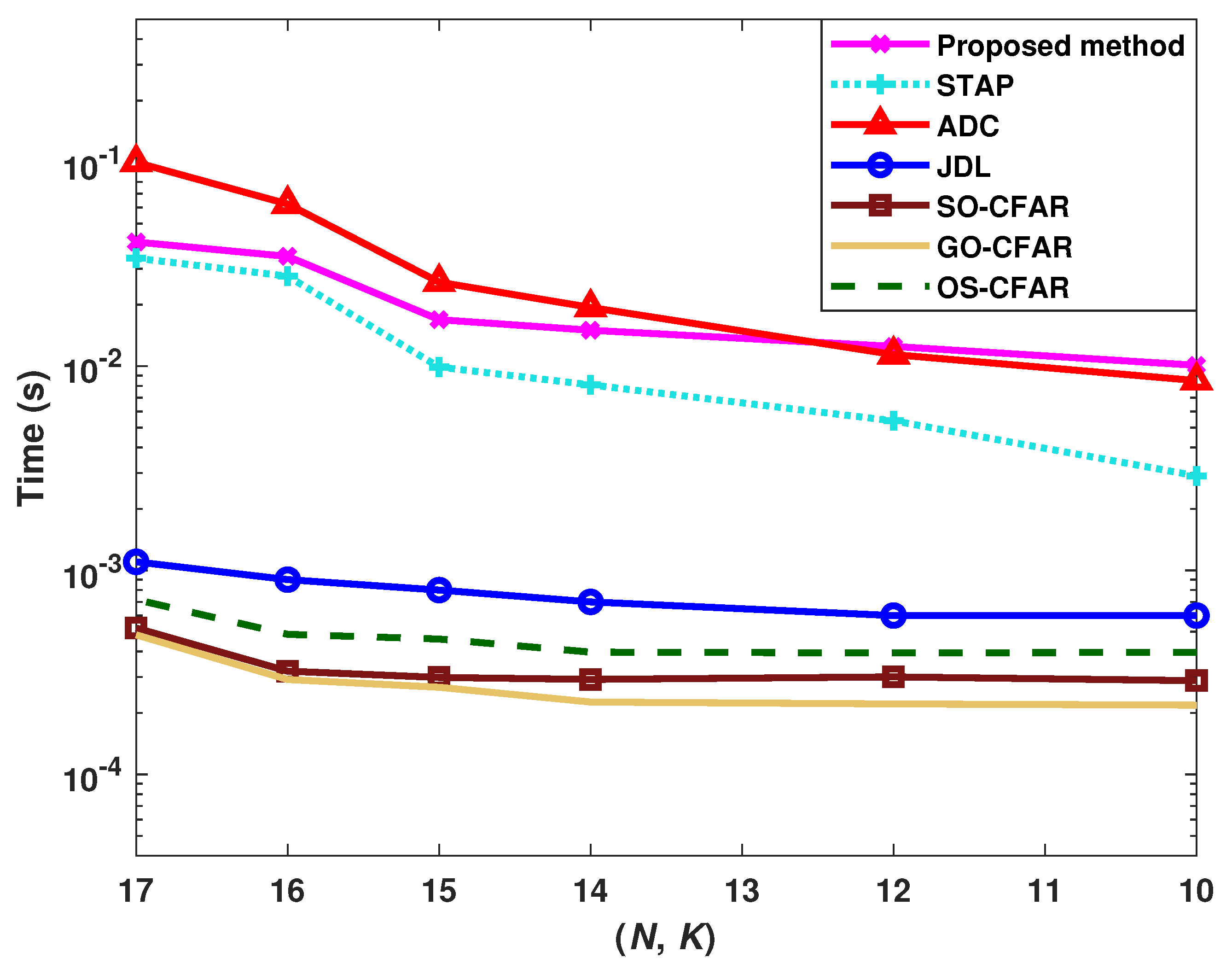
4.4. Computation Time of Different Methods
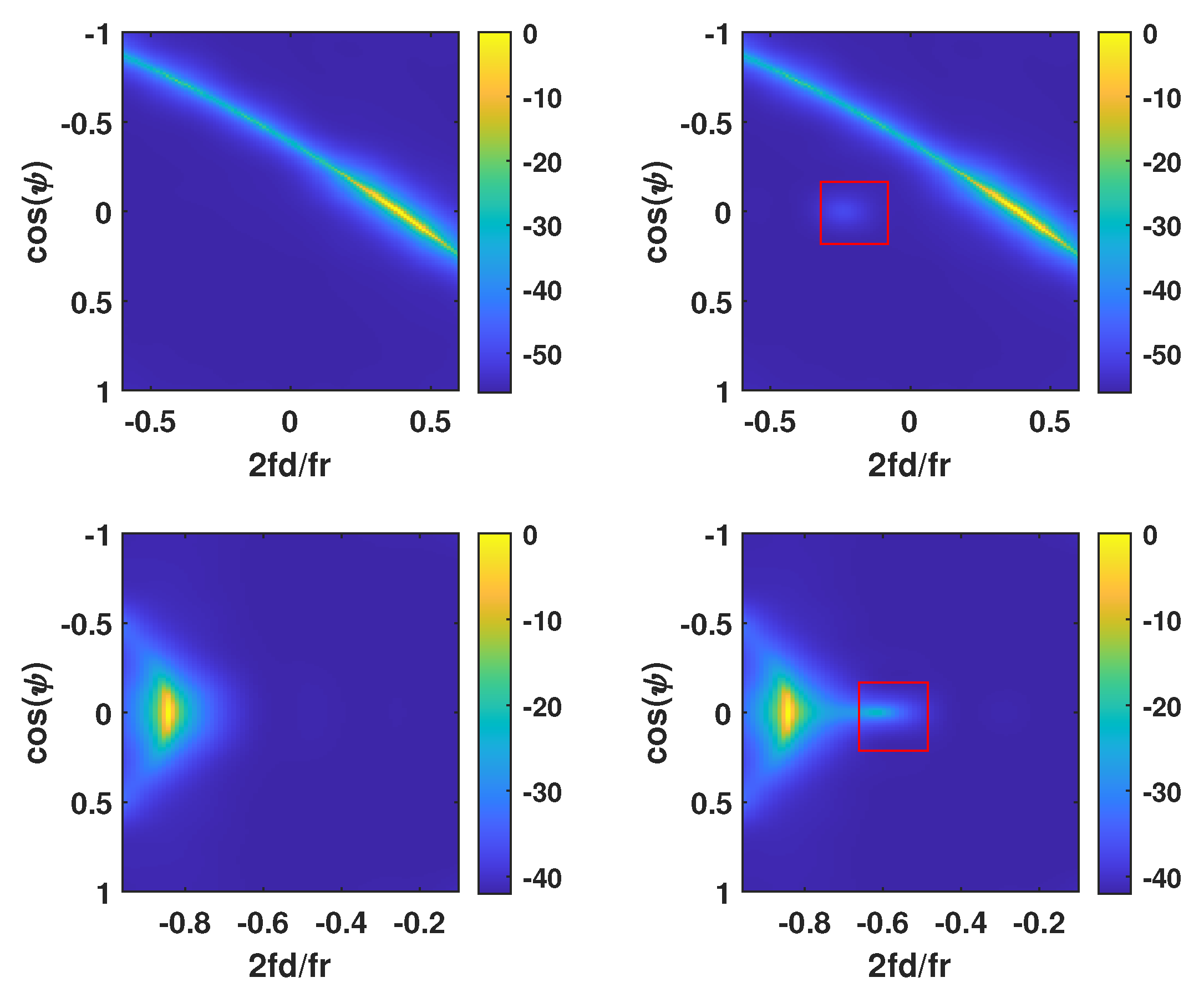
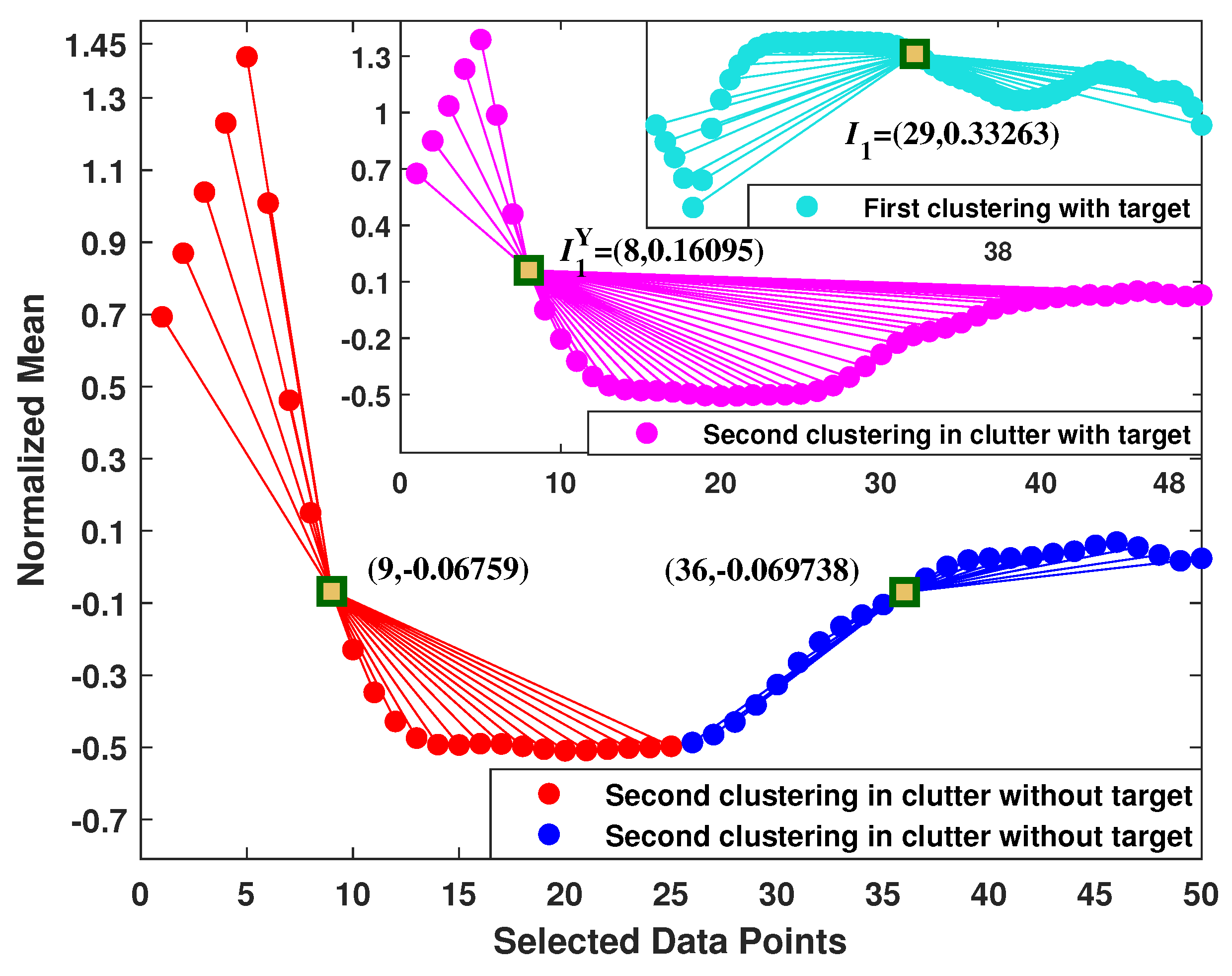
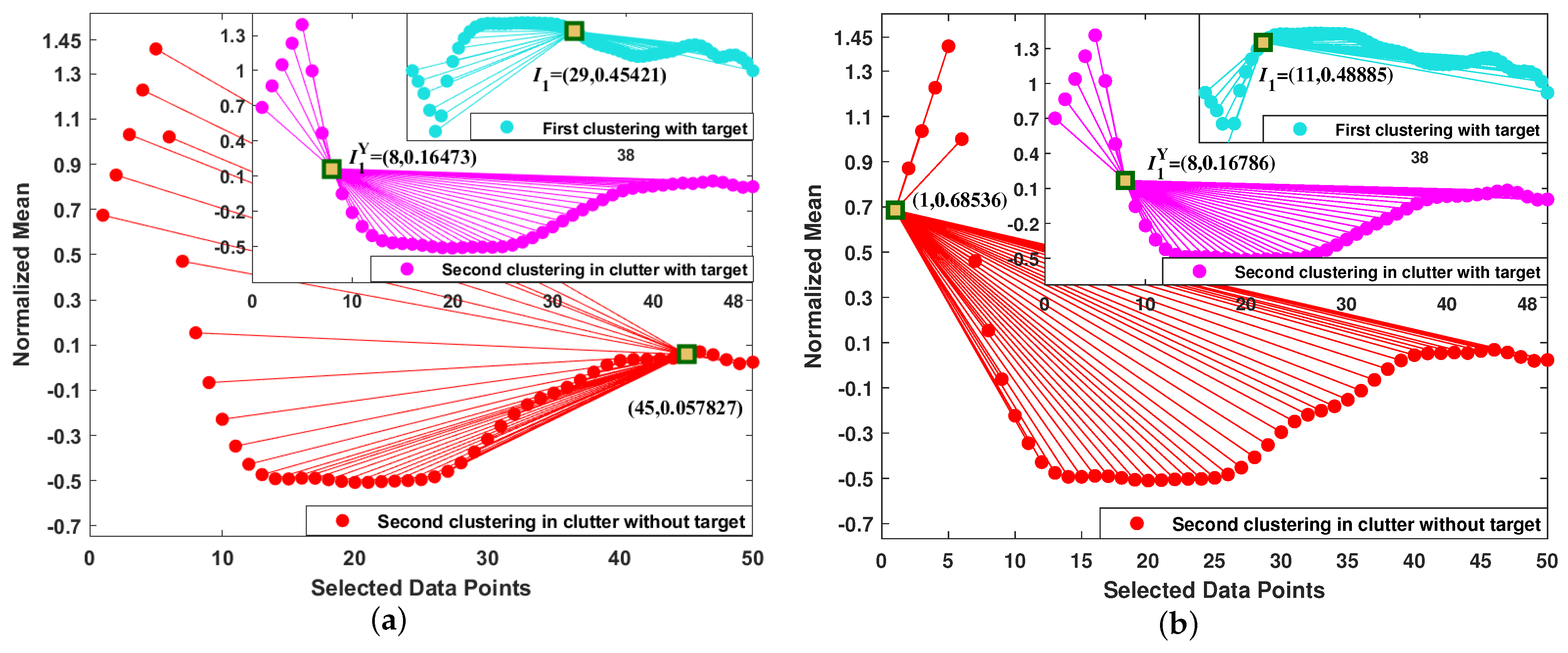
4.5. Visualization of the Formed Clusters
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gong, M.G.; Cao, Y.; Wu, Q.D. A Neighborhood-Based Ratio Approach for Change Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2012, 9, 307–311. [Google Scholar] [CrossRef]
- Kang, M.S.; Kim, K.T. Automatic SAR Image Registration via Tsallis Entropy and Iterative Search Process. IEEE Sens. J. 2020, 20, 7711–7720. [Google Scholar] [CrossRef]
- Hakim, W.L.; Achmad, A.R.; Eom, J.; Lee, C.W. Land Subsidence Measurement of Jakarta Coastal Area Using Time Series Interferometry with Sentinel-1 SAR Data. J. Coast. Res. 2020, 102, 75–81. [Google Scholar] [CrossRef]
- Ward, J. Space-Time Adaptive Processing for Airborne Radar; Technical Report; MIT Lincoln Laboratory: Lexington, KY, USA, 1998. [Google Scholar]
- Klemm, R. Principles of Space-Time Adaptive Processing; The Institution of Electrical Engineers: London, UK, 2002. [Google Scholar]
- Reed, I.S.; Mallett, J.D.; Brennan, L.E. Rapid convergence rate in adaptive arrays. IEEE Trans. Aerosp. Electron. Syst. 1974, AES-10, 853–863. [Google Scholar] [CrossRef]
- Lapierre, F.D.; Ries, P.; Verly, J.G. Foundation for mitigating range dependence in radar space-time adaptive processing. IET Radar Sonar Navig. 2009, 3, 18–29. [Google Scholar] [CrossRef] [Green Version]
- Lapierre, F.; Droogenbroeck, M.V.; Verly, J.G. New methods for handling the dependence of the clutter spectrum in non-sidelooking monostatic STAP radars. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Hong Kong, China, 6–10 April 2003; pp. 73–76. [Google Scholar]
- Lapierre, F.; Verly, J.G. Registration-based range dependence compensation for bistatic STAP radars. EURASIP J. Appl. Signal Process. 2005, 1, 85–98. [Google Scholar] [CrossRef] [Green Version]
- Lapierre, F.; Verly, J.G. Computationally-efficient range dependence compensation method for bistatic radar STAP. In Proceedings of the International Radar Conference, Arlington, VA, USA, 9–12 May 2005; pp. 714–719. [Google Scholar]
- Borsari, G.K. Mitigating effects on STAP processing caused by an inclined array. In Proceedings of the 1998 IEEE Radar Conference, Dallas, TX, USA, 12–13 May 1998; pp. 135–140. [Google Scholar]
- Kreyenkamp, O.; Klemm, R. Doppler compensation in forward-looking STAP radar. IEEE Proc. Radar Sonar Navig. 2001, 148, 253–258. [Google Scholar] [CrossRef]
- Himed, B.; Zhang, Y.; Hajjari, A. STAP with angle-Doppler compensation for bistatic airborne radars. In Proceedings of the IEEE Radar Conference, Long Beach, CA, USA, 22–25 April 2002; pp. 311–317. [Google Scholar]
- Pearson, F.; Borsari, G. Simulation and analysis of adaptive interference suppression for bistatic surveillance radars. In Proceedings of the Adaptive Sensor Array Process; LincoIn Laboratory: VIrkshop, MA, USA, 2001. [Google Scholar]
- Guerci, J.R.; Goldstein, J.S.; Reed, I.S. Optimal and adaptive reduced-rank STAP. IEEE Trans. Aerosp. Electron. Syst. 2000, 36, 647–663. [Google Scholar] [CrossRef]
- Liao, G.S.; Bao, Z.; Xu, Z.Y. A framework of rank-reduced space-time adaptive processing for airborne radar and its applications. Sci. China Ser. Technol. Sci. 1997, 40, 505–512. [Google Scholar] [CrossRef]
- Goldstein, J.S. Reduced rank adaptive filtering. IEEE Trans. Signal Process 1997, 45, 492–496. [Google Scholar] [CrossRef]
- Wang, Y.; Peng, Y. Space-time joint processing method for simultaneous clutter and jamming rejection in airborne radar. Electron. Lett. 1996, 32, 258. [Google Scholar] [CrossRef]
- Wang, W.L.; Liao, G.S.; Zhang, G.B. Improvement on the performance of the auxiliary channel STAP in the non-homogeneous environment. J. Xidian Univ. 2004, 20, 426–429. [Google Scholar]
- Gini, F.; Greco, M. Covariance matrix estimation for CFAR detection in correlated heavy tailed clutter. Signal Process. 2002, 82, 1847–1859. [Google Scholar] [CrossRef]
- Hammoudi, Z.; Soltani, F. Distributed CA-CFAR and OS-CFAR detection using fuzzy spaces and fuzzy fusion rules. IEE Proc.-Radar Sonar Navig. 2004, 15, 135–142. [Google Scholar] [CrossRef]
- Zaimbashi, A. An adaptive cell averaging-based CFAR detector for interfering targets and clutter-edge situations. Digit. Signal Process. 2014, 31, 59–68. [Google Scholar] [CrossRef]
- Trunk, G.V. Range resolution of targets using automatic detectors. IEEE Trans. Aerosp. Electron. Syst. 1978, 14, 750–755. [Google Scholar] [CrossRef]
- Gandhi, P.; Kassam, S. Analysis of CFAR processors in nonhomogeneous background. IEEE Trans. Aerosp. Electron. Syst. 1988, 24, 427–445. [Google Scholar] [CrossRef]
- Rohling, H. Radar CFAR thresholding in clutter and multiple target situations. IEEE Trans. Aerosp. Electron. Syst. 1983, 19, 608–621. [Google Scholar] [CrossRef]
- Wang, P.; Li, H.; Himed, B. A New Parametric GLRT for Multichannel Adaptive Signal Detection. IEEE Trans. Signal Process. 2010, 58, 317–325. [Google Scholar] [CrossRef]
- Liu, W.J.; Liu, J.; Hao, C.P.; Gao, Y.C.; Wang, Y.L. Multichannel adaptive signal detection: Basic theory and literature review. Sci. China Inf. Sci. 2022, 65, 121301. [Google Scholar] [CrossRef]
- Shi, B.; Hao, C.P.; Hou, C.H.; Ma, X.C.; Peng, C.Y. Parametric Rao test for multichannel adaptive detection of range-spread target in partially homogeneous environments. Signal Process. 2015, 108, 421–429. [Google Scholar] [CrossRef]
- Liao, L.Y.; Du, L.; Guo, Y.C. Semi-supervised SAR target detection based on an improved faster R-CNN. Remote Sens. 2022, 14, 143. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L.; Xu, M. Weakly Supervised Learning Based on Coupled Convolutional Neural Networks for Aircraft Detection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5553–5563. [Google Scholar] [CrossRef]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.; Zhang, J.; Li, D.; Zhang, X.; Guo, T. Adaptive affinity propagation clustering. Acta Autom. Sin. 2007, 33, 1242–1246. [Google Scholar]
- Liu, J.; Liao, G.S.; Xu, J.W.; Zhu, S.Q.; Juwono, F.J.; Zeng, C. Autoencoder neural network-based STAP algorithm for airborne radar with inadequate training samples. Remote Sens. 2022, 14, 6021. [Google Scholar] [CrossRef]
- Zou, B.; Wang, X.; Feng, W.; Zhu, H.; Lu, F. DU-CG-STAP method based on sparse recovery and unsupervised learning for airborne radar clutter suppression. Remote Sens. 2022, 14, 3472. [Google Scholar] [CrossRef]
- Duan, K.; Chen, H.; Xie, W.; Wang, Y. Deep learning for high-resolution estimation of clutter angle-Doppler spectrum in STAP. IET Radar Sonar Navig. 2022, 16, 193–207. [Google Scholar] [CrossRef]
- Zhu, H.; Feng, W.; Feng, C.; Zou, B.; Lu, F. Deep Unfolding Based Space-Time Adaptive Processing Method for Airborne Radar. J. Radars 2022, 11, 1–16. [Google Scholar]
- Xu, J.W.; Liao, G.S.; Huang, L.; Zhu, S.Q. Joint magnitude and phase constrained STAP approach. Digital Signal Process. 2015, 46, 32–40. [Google Scholar] [CrossRef]
- Cui, W.; Wang, T.; Wang, D.; Liu, C. An improved iterative reweighted STAP algorithm for airborne radar. Remote Sens. 2023, 15, 130. [Google Scholar] [CrossRef]
- Wang, D.; Wang, T.; Cui, W.; Liu, C. Adaptive support-driven sparse recovery STAP method with subspace penalty. Remote Sens. 2022, 14, 4463. [Google Scholar] [CrossRef]
- Ottersten, B.; Stoica, P.; Roy, R. Covariance matching estimation techniques for array signal processing applications. Digital Signal Process. 1998, 8, 185–210. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Liao, G.; Xu, J.; Zhu, S.; Zeng, C.; Juwono, F.H. Unsupervised Affinity Propagation Clustering Based Clutter Suppression and Target Detection Algorithm for Non-Side-Looking Airborne Radar. Remote Sens. 2023, 15, 2077. https://doi.org/10.3390/rs15082077
Liu J, Liao G, Xu J, Zhu S, Zeng C, Juwono FH. Unsupervised Affinity Propagation Clustering Based Clutter Suppression and Target Detection Algorithm for Non-Side-Looking Airborne Radar. Remote Sensing. 2023; 15(8):2077. https://doi.org/10.3390/rs15082077
Chicago/Turabian StyleLiu, Jing, Guisheng Liao, Jingwei Xu, Shengqi Zhu, Cao Zeng, and Filbert H. Juwono. 2023. "Unsupervised Affinity Propagation Clustering Based Clutter Suppression and Target Detection Algorithm for Non-Side-Looking Airborne Radar" Remote Sensing 15, no. 8: 2077. https://doi.org/10.3390/rs15082077
APA StyleLiu, J., Liao, G., Xu, J., Zhu, S., Zeng, C., & Juwono, F. H. (2023). Unsupervised Affinity Propagation Clustering Based Clutter Suppression and Target Detection Algorithm for Non-Side-Looking Airborne Radar. Remote Sensing, 15(8), 2077. https://doi.org/10.3390/rs15082077