3.3. Parameter Analysis and Experimental Setup
In this section, the experimental parameters of the proposed method and the comparison methods are performed. The parameters of the eight state-of-the-art comparison methods are set according to the suggestions of the authors or the performance in the . Specifically, in the RX method, there are no additional parameters that need to be set. In the CRD method, the sizes of the double window () are set to (7, 5), (7, 5), (25, 21), (9, 5), and (17, 5) on the five datasets of Bay Champagne, Pavia, MUUFLGulfport, SpecTIR, and WHU-Hi-River, respectively. In the 2S-GLRT method, the double window sizes are set to (17, 15), (21, 5), (25, 21), (9, 5), and (11, 7) on the five datasets. In the PCA-TLRSR method, the numbers of principle components are set to 15, 9, 17, 11, and 13 on the five datasets. In the GAED method, the weights and bias are randomly initialized. As suggested by the authors, on all five datasets, the window size c is set to 7, the learning rate is set to 0.4, the penalty coefficient is set to 1, the number of iterations is set to 300, and the dimension of the hidden layer is set to 25. In the Auto-AD methods, there are no uncertain parameters that need to be set. In the LREN method, the weights and bias are randomly initialized. The number of clusters and the size of hidden layer are set to 7 and 9 on all the datasets as suggested. The regularization parameters are set to 0.01, 0.01, 0.01, 1.0, and 1.0 on the five datasets, respectively. In the DeCNNAD method, the number of clusters is set to 9, 8, 8, 13, and 6 on the five datasets, respectively. The regularization parameters (, ) are set to (0.01, 0.01), (0.01, 0.01), (0.0001, 0.0001), (0.001, 0.01), and (0.01, 0.01) on the five datasets, respectively.
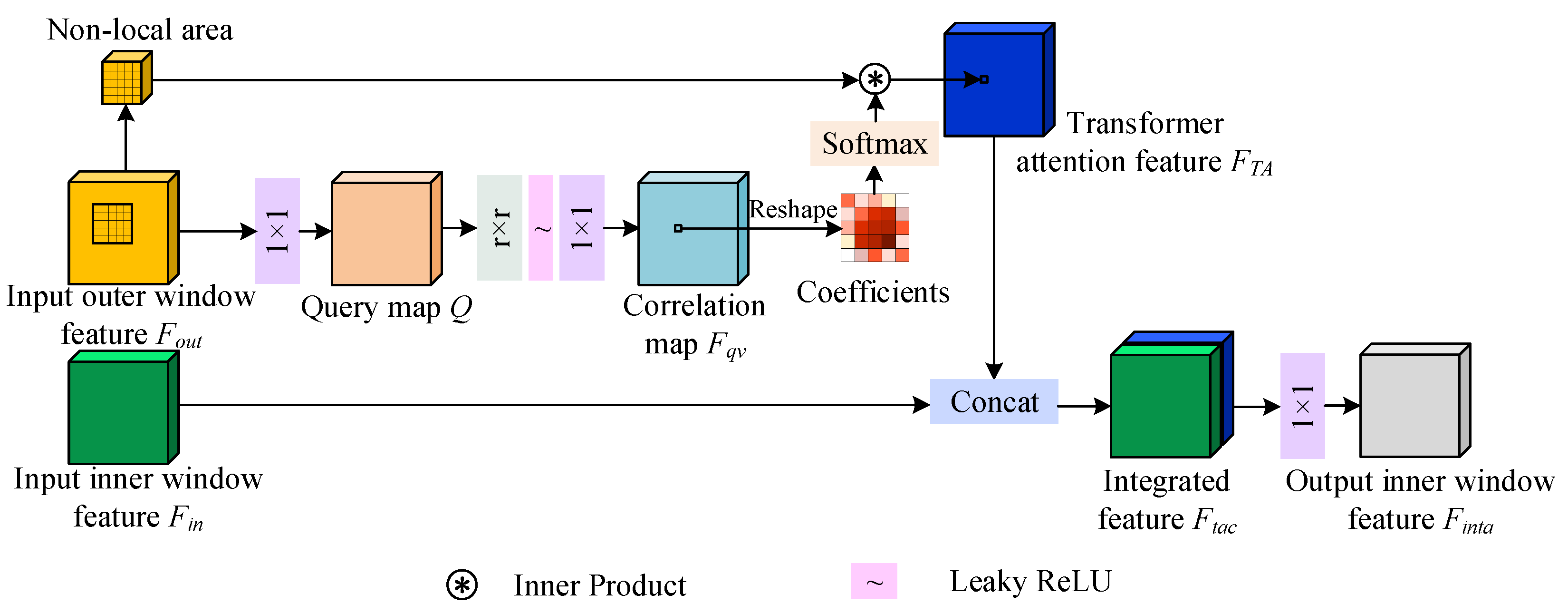
For the proposed method, before our experiments, the datasets are first normalized. The weights and bias are randomly initialized. The hyperparameters include learning rate , maximum training epochs , the number of epochs at which learning rate decays , and the factor by which learning rate decays . In our experiments, on all five datasets, , , , . The uncertain parameters include the number of base convolutional kernels and the number of group channels in the group convolution . In addition, the position of the local detail attention and local Transformer attention also influence the performance of the proposed method. Hence, we analyze the positions and of these two modules, where represents the position of the local detail attention and represents the position of the local Transformer attention. To analyze the stability of these parameters, some parameters are conducted by varying the parameters. Because the weights and bias are randomly initialized, the performance of different experiments will randomly change. So, to reduce the influence of random initialization, we fix the random seed on different datasets during the parameter analysis experiments. This ensures that the performance of the proposed method with different parameters is comparable.
We vary the value of the
in 2, 4, 8, 16, 32, 64, and 128. The value of the parameter
is varied in 1, 2, 4, and 8. The optimal results of the
and
are shown in
Figure 6. To constrain the size of the network, only one module is adopted for both the local detail attention and the local Transformer attention. We vary the values of the
and
in 1, 2, 3, which means that the position is after the first, second, or third convolution layer in the network, respectively. The optimal results of the
and
are shown in
Figure 7.
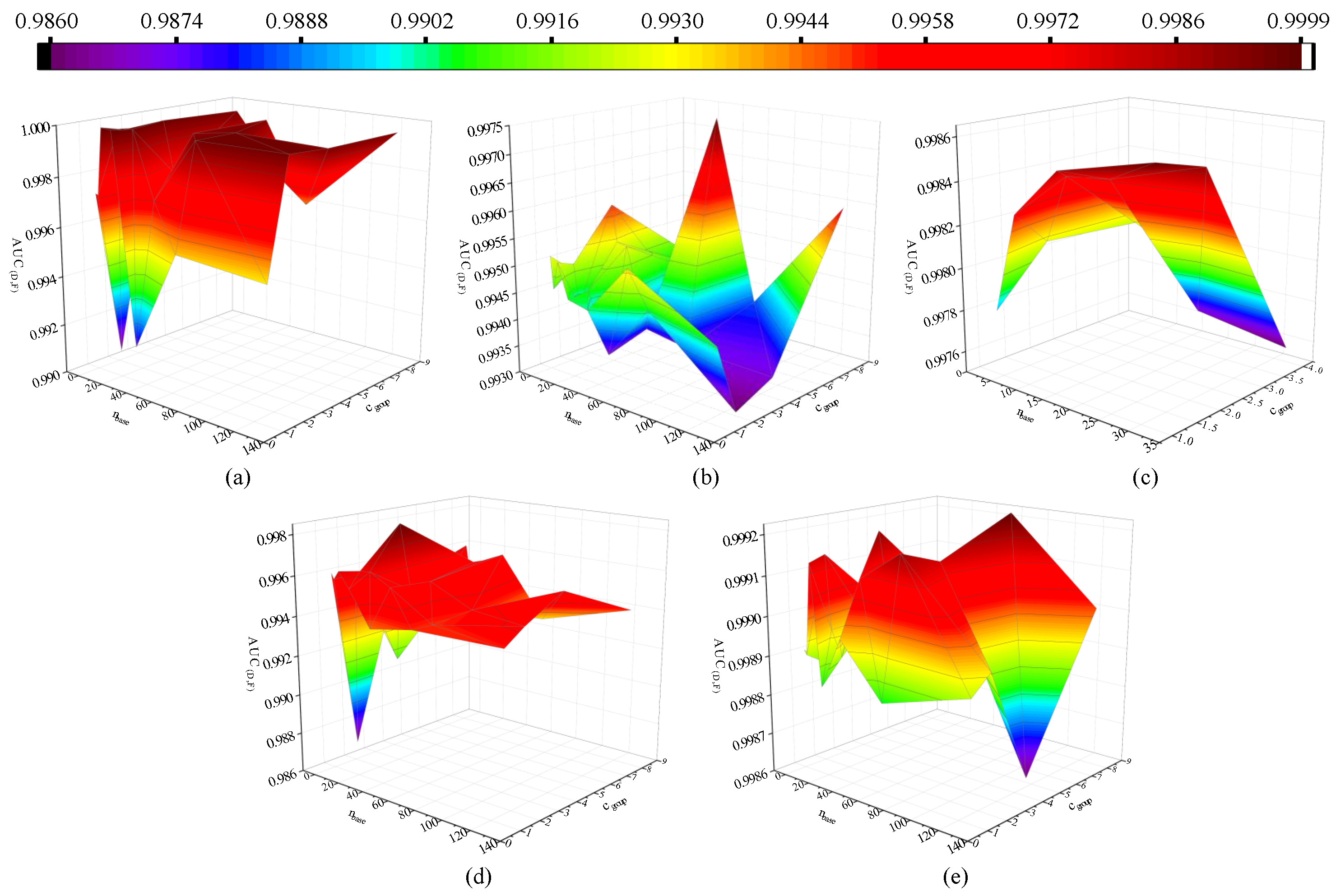
As shown in
Figure 6, the performance on the datasets of MUUFLGulfport and WHU-Hi-River is stable while changing the
and
. The
are concentrated above 0.9976 on these two datasets. The range of the
is about 0.0008 and 0.0006 on the datasets of MUUFLGulfport and WHU-Hi-River, respectively. On the datasets of Bay Champagne, Pavia, and WHU-Hi-River, the performance is unstable while changing the
and
. The range of the
is 0.0094, 0.0042, and 0.0110 on these three datasets, respectively. However, most
values of these three datasets are concentrated above 009935. According to the
performance, the parameters (
,
) are set to (8, 1), (32, 8), (32, 1), (8, 4), and (64, 8) on the datasets of Bay Champagne, Pavia, MUUFLGulfport, SpecTIR, and WHU-Hi-River, respectively.
As shown in
Figure 7, the performance on the five datasets is stable while changing the
and
. The
are concentrated above 0.9930. The range of the
is 0.0027, 0.0038, 0.0008, 0.0048, and 0.0096 on the five datasets, respectively. According to the
performance, the parameters (
,
) are set to (1, 3), (3, 3), (3, 2), (1, 2), and (1, 3) on the datasets of Bay Champagne, Pavia, MUUFLGulfport, SpecTIR, and WHU-Hi-River, respectively.
3.4. Experimental Results
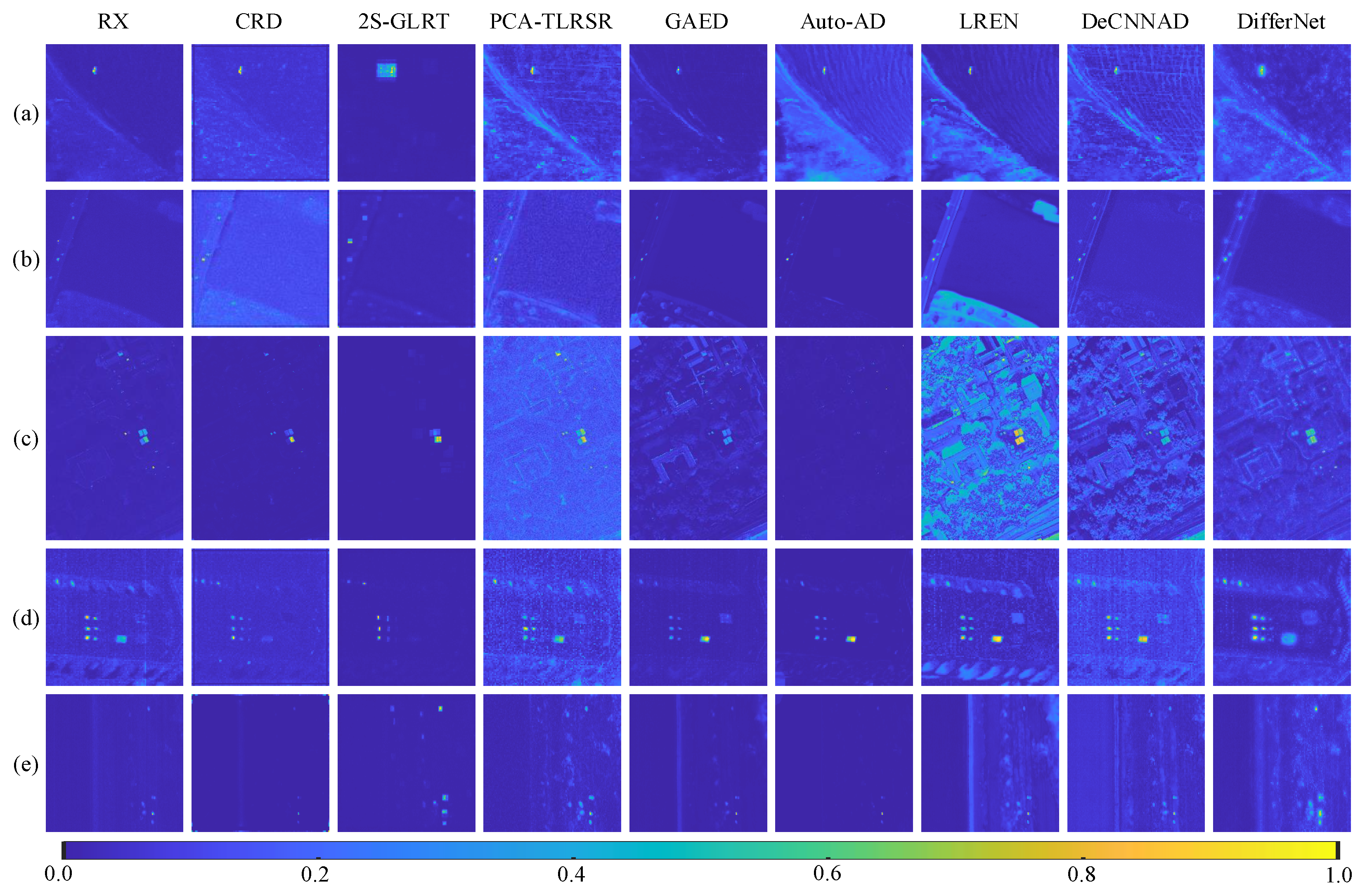
In this section, the detection performance of the proposed method is analyzed compared with eight state-of-the-art methods, including the RX, the CRD, the 2S-GLRT, the PCA-TLRSR, the GAED, the Auto-AD, the LREN, and the DeCNNAD. The detection results of these methods are shown in
Figure 8.
As shown in
Figure 8, in the results of the RX method, the background is relatively clean, but the anomaly targets are not completely detected. This is due to the common occurrence of spectral mixing in real datasets, resulting in spectral interference from background pixels around the targets. Such interference can impact the overall detection performance. Similar detection performance also exists in the results of CRD, GAED, and Auto-AD. In the results of 2S-GLRT, the contour information of the anomalies is lost. This is attributed to the fact that the features in the local inner window change slowly as the window slides across the HSI, causing block effects. In the results of the PCA-TLRSR method, there are some noises in the detection results. This is because that the low-rank and sparse decomposition theory is adopted in the PCA-TLRSR. The sparse matrix contains both anomalies and noises. As a result, it is hard for the PCA-TLRSR to distinguish the targets and noises. In the results of the LREN method, the background is clear. This is because this method constructs a global lowest rank dictionary. When the background is complex, the constructed dictionary is not comprehensive enough for the background, resulting in the inability to fully represent background components. This leads to insufficient background suppression. In the results of the DeCNNAD method, the background is clear and there are some noises in the results. This is because a denoiser is adopted in this method to obtain the background dictionary. The quality of the constructed dictionary depends on the performance of the denoiser. When the denoiser removes certain edges in the scene, the reconstructed background also loses these edges, leaving some background edges in the detection results. Furthermore, noises and anomalies are not distinguished in this method. This leads to some noises existing in the detection results.
Specifically, for the Bay Champagne dataset, the anomaly targets in the detection results of RX, GAED, Auto-AD, and LREN are not fully detected. The contours of the anomaly targets in the detection result of 2S-GLRT are lost. The background in the result of PCA-TLRSR is clear. The detection results of CRD and proposed DifferNet are satisfactory. For the Pavia dataset, the anomaly targets are not well separated from the background in the results of RX, CRD, GAED, Auto-AD, and DeCNNAD. The shape of the targets is lost in the result of 2S-GLRT. The distinctiveness between the anomalies and background is not significant in the result of PCA-TLRSR. The background in the result of LREN is clear. In the result of the proposed DifferNet, all the anomaly targets are highlighted compared with the background. For the dataset of MUUFLGulfport, the Auto-AD method fails to detect the anomaly targets. The background is suppressed in the results of the CRD and 2S-GLRT methods, but the anomaly targets are partially suppressed as well. In the results of the RX and PCA-TLRSR methods, the roof at the top of the scene is enhanced incorrectly. In the results of the GAED and DeCNNAD methods, the anomaly targets are not well distinguished from the background. The background is clear in the result of LREN. In the result of the proposed DifferNet method, the anomaly targets are well separated from the background. For the dataset of SpecTIR, the small targets are submerged in the background in the results of RX, CRD, 2S-GLRT, PCA-TLRSR, LREN, and DeCNNAD. There are some noises in the results of PCA-TLRSR and DeCNNAD. In the results of PCA-TLRSR, GAED, Auto-AD, LREN, and DeCNNAD, a square background in the middle of the scene is not suppressed. In the result of the proposed method, the detection performance is satisfactory. For the dataset of WHU-Hi-River, the anomaly targets are not well detected in the results of CRD, GAED, and Auto-AD. In the results of RX, LREN, and DeCNNAD, the distinction between the targets and background is not significant. The background is clear in the results of PCA-TLRSR, LREN, and DeCNNAD. The shape of the anomaly targets is changed in the result of 2S-GLRT. The proposed DifferNet obtains a satisfactory detection result. Overall, the proposed method obtains superior results on the five datasets compared with other state-of-the-art methods.
From the objective evaluation perspective, 3D ROC curves and AUC values are adopted to evaluate the performance of the methods. The 3D ROC curves (
,
,
) on different datasets are shown in
Figure 9. The curves of the proposed method marked in red are higher than those of the other methods on the datasets of Bay Champagne and WHU-Hi-River. On the other datasets, the curves of the proposed DifferNet are close to those of the other methods.
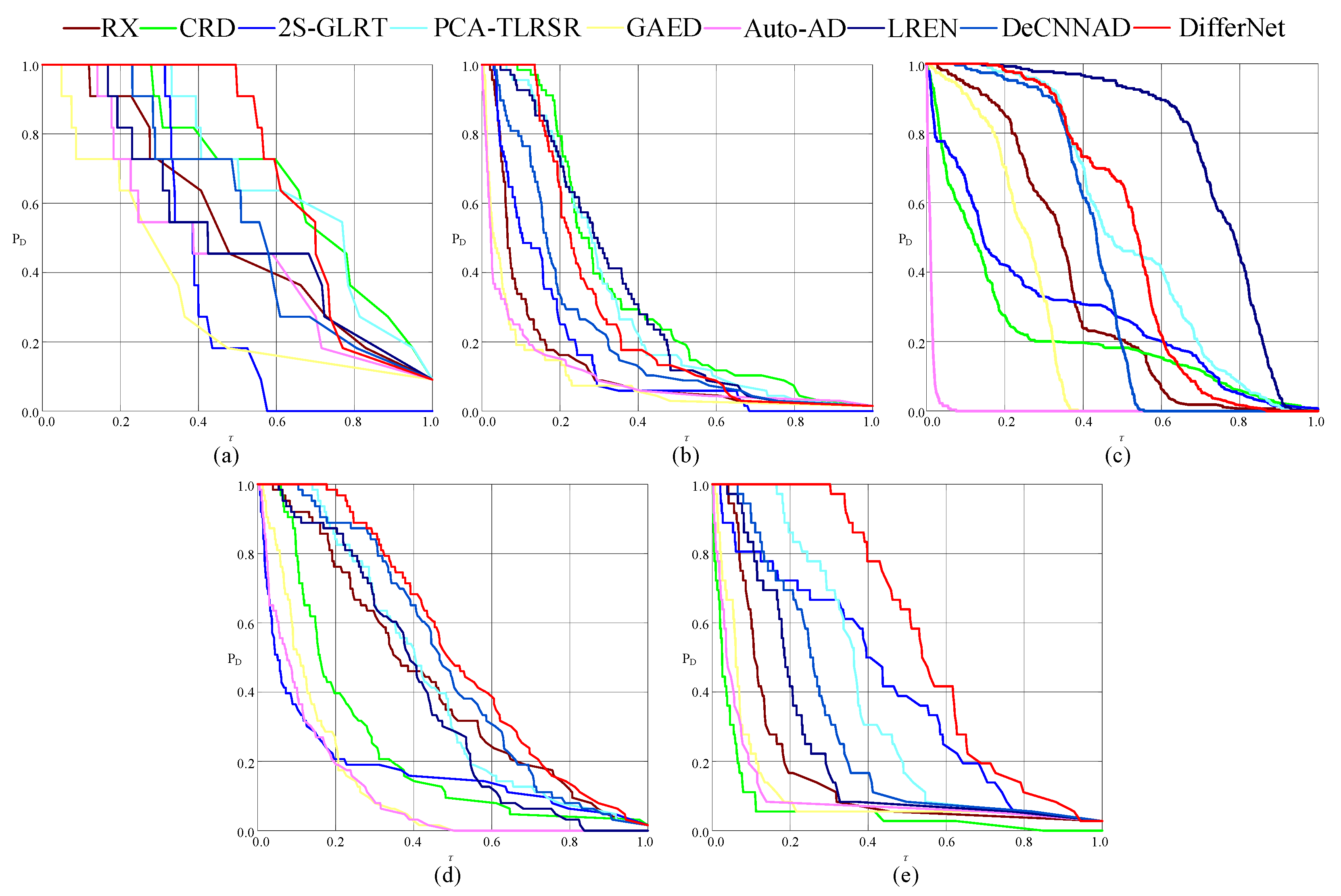
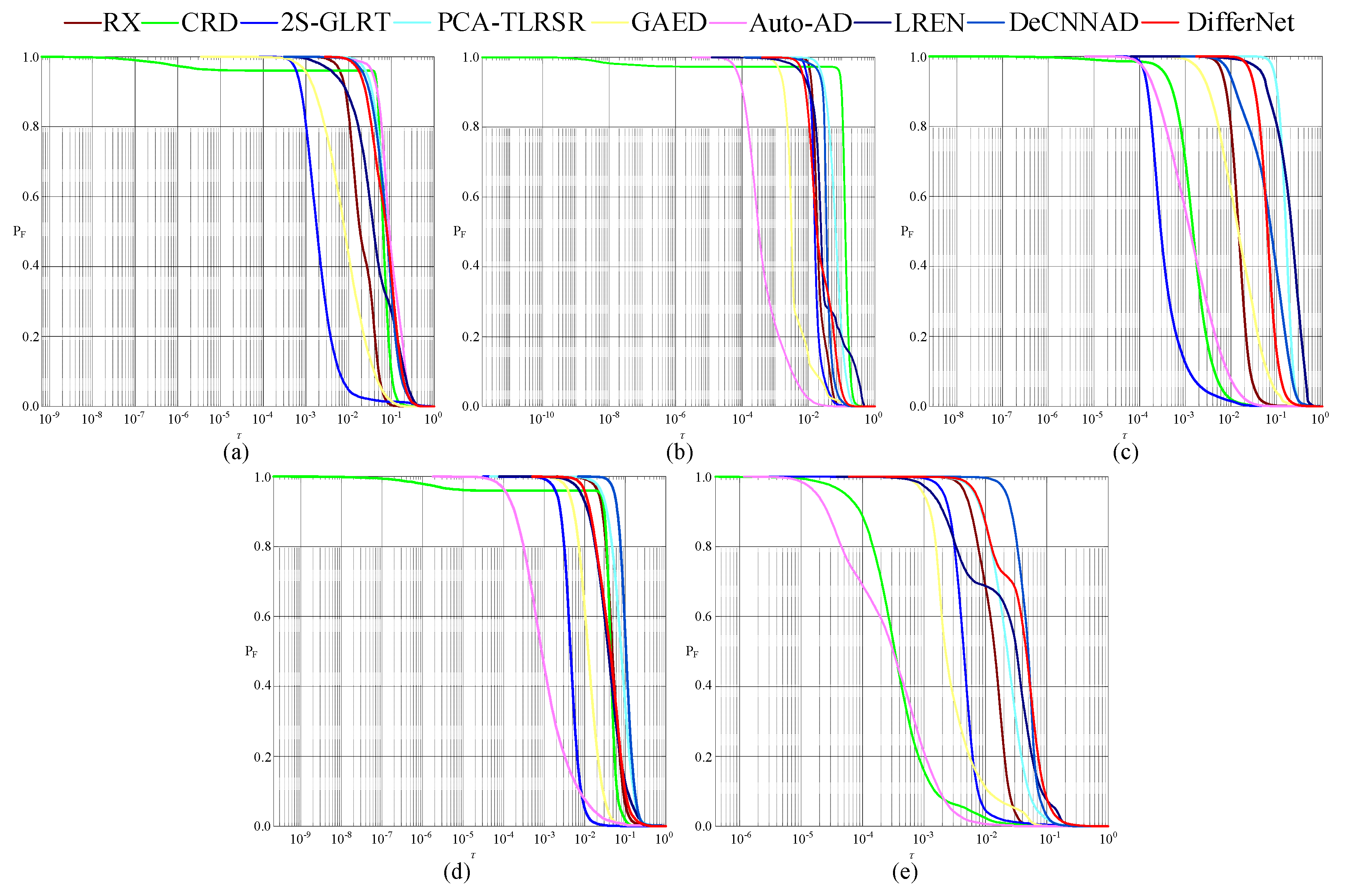
The 2D ROC curves (
,
) on different datasets are shown in
Figure 10. The corresponding
values are shown in
Table 1. As shown in
Figure 10, the (
,
) curves of the proposed DifferNet marked in red are higher than those of the other methods on the datasets of Bay Champagne, Pavia, SpecTIR, and WHU-Hi-River. On the dataset of MUUFLGulfport, the curves of the proposed method and comparison methods are mixed, but the curve of the proposed method is at the upper part of all the curves. In
Table 1, the best
values are in bold. The proposed method achieves the best
on all the datasets. This means that the proposed method achieves a high detection rate at a low false alarm rate. Compared with the second-best values, the
values of the proposed method are higher by 0.0001, 0.0105, 0.0006, 0.0110, and 0.0005 on the five datasets, respectively. Overall, the performance of the proposed method is excellent.
The 2D ROC curves (
,
) on different datasets are shown in
Figure 11. The corresponding
values are shown in
Table 2. As shown in
Figure 11, the (
,
) curves of the proposed DifferNet marked in red are higher than those of the other methods on the datasets of Bay Champagne, SpecTIR, and WHU-Hi-River. On the datasets of Pavia and MUUFLGulfport, the curves of the proposed method are not at the top of all the curves. However, the curves of the proposed method are at the upper part of all the curves. In
Table 2, the best
values are in bold. The proposed method achieves the best
values on the datasets of Bay Champagne, SpecTIR, and WHU-Hi-River, which are higher by 0.0108, 0.0425, and 0.1588 compared with the second-best values, respectively. On the datasets of Pavia and MUUFLGulfport, the CRD method and the LREN method achieve the best values, respectively. The best values on the two datasets are higher by 0.0603 and 0.2393 than that of the proposed method, respectively. As a result, the proposed DifferNet has a good detection rate compared with the other methods.
The 2D ROC curves (
,
) on different datasets are shown in
Figure 12. The corresponding
values are shown in
Table 3. As shown in
Figure 12, the (
,
) curves of the proposed DifferNet marked in red are mixed with those of the comparison methods on the five datasets, which are neither the highest nor the lowest. On the datasets of Bay Champagne and MUUFLGulfport, the curve of the 2S-GLRT is the lowest one among all the curves. On the datasets of Pavia and SpecTIR, the curve of the Auto-AD is lower than the other 2D ROC curves. On the dataset of WHU-Hi-River, the curves of CRD and Auto-AD are relatively lower than those of the other methods. In
Table 3, the best
values are in bold. On the datasets of Bay Champagne, MUUFLGulfport, and SpecTIR, the 2S-GLRT achieves the minimum
values of 0.0080, 0.0011, and 0.0052, which are lower by 0.0839, 0.0706, and 0.0477 than those of the proposed method. On the datasets of Pavia and WHU-Hi-River, the Auto-AD method achieves the minimum
values of 0.0013 and 0.0008, which are lower by 0.0326 and 0.0496 than those of the proposed method. The
values of the proposed method on the five datasets are between the maximum value and the minimum value, respectively. This means that the proposed method has a certain background suppression capability. Overall, the proposed DifferNet method obtains satisfactory and advanced detection results.
To evaluate the execution efficiency of all the methods, the time consumption of all the methods on the five datasets is evaluated. It is worth noting that Auto-AD, LREN, and the proposed method are implemented by Python 3. The rest of the methods are conducted using Matlab 2022b. All the methods are executed on a computer with an Intel Core
TM i9-12900H produced by Intel the United States, 16 GB RAM produced by Samsung South Korea, and NVDIA GeForce RTX 3060 Laptop GPU produced by Lenovo China. We measure the speed of the methods both with and without GPU acceleration separately. The time consumption results are shown in
Table 4, and the best values are in bold. The results show that the RX method has the fastest processing speed without GPU acceleration. With the acceleration of GPU, the DeCNNAD method achieves the best time performance on the dataset of MUUFLGulfport, and the Auto-AD method achieves the best time performance on the rest of the datasets. The time consumption is relatively high compared with other methods without GPU acceleration, and it has an acceptable running speed with GPU acceleration. In the future, we need to further optimize the DifferNet to improve efficiency and detection performance.
The initialization of weights and bias in the CNN directly affects the detection performance. To investigate the stability of the proposed method under different initialization conditions, we remove the fixed random seed and conduct 20 repeated experiments. We record the range of
values obtained, and the statistical results are shown in
Table 5.
As shown in
Table 5, the proposed method exhibits relatively low variance and range across 20 experiments. This means that the proposed method has good parameter stability.
To demonstrate the noise robustness of the proposed method, we conduct experiments by adding various types of noise to the original dataset. The added noises are the Gaussian noise with mean 0 and variance 0.01, salt and pepper noise with density 0.01, and uniform multiplicative noise with mean 0 and variance 0.01. The detection results are shown in
Figure 13 and
Table 6. To further illustrate the false alarm rates of these methods, we also calculate the false positive rate (FPR), while the detection rate is 0.9. The results are shown in
Table 7.
As shown in
Figure 13, the results of input without noises are the best detection results. When the Gaussian noises are added to the input datasets, the detection performance decreases. When the salt and pepper noises are added to the inputs, the detection results are slightly better than those of inputs with Gaussian noises. When the multiplicative noises are added to the inputs, the detection results are better than those of inputs with salt and pepper noises. Despite the interference of noises with the detection results, the anomaly targets can still be detected. In
Table 6, on the datasets of Bay Champagne, Pavia, and WHU-Hi-River, the performance of inputs with salt and pepper noises is better than inputs with the rest of the noises. On the datasets of MUUFLGulfport and SpecTIR, the performance of inputs with multiplicative noises is better than inputs with rest of the noises. The Gaussian noises have the greatest impact on the detection performance. In
Table 7, the FPR values of inputs without noise are low. With Gaussian noises, the FPR values increase significantly compared with other noises. The impact of salt and pepper noises and multiplicative noises on the FPR values is similar. As a result, Gaussian noise has a significant impact on the performance of the proposed method, while salt and pepper noise and multiplicative noise have relatively minor effects on the proposed method. The noise robustness of the proposed method is acceptable.
3.5. Ablation Analysis
In this section, the attention module effectiveness and the structure effectiveness are discussed.
To investigate the effectiveness of the attention module, the DifferNet without any attention and DifferNet with only one type of attention in different positions are compared with the proposed DifferNet. The
is adopted to evaluate the detection performance. The detection results of these methods are shown in
Figure 14. In
Figure 14,
denotes that the local Transformer attention (LTA) is added after the
i-th convolutional layer, and
denotes that the local detail attention (LDA) is added after the
i-th convolutional layer. Although the results of these methods are close to each other, background edges still remain in the results of DifferNet without attention and DifferNet with LTA. This means that the LDA module can preserve the background edges well so that the residual map contains few background edges. In addition, the anomaly targets are not complete and prominent in the results of DifferNet with LDA. This demonstrates that the LTA is capable of effectively focusing on the primary information within the local window. It can enhance the expressive ability of CNN, making our DifferNet model the background accurately. The corresponding
values are shown in
Table 8. The DifferNet with both LTA and LDA achieves the best values on the five datasets. The experimental results show that the LTA can improve the expressive ability of CNN and facilitate precise modeling of the background. The LDA can enhance the ability of the network to represent background edges. Both attention modules are effective in anomaly detection.
To further demonstrate the efficiency of the proposed LTA module, we assess the time consumption and storage occupancy in comparison to the traditional Transformer model. The evaluation is conducted on inputs with spatial sizes of
and
. The results are shown in
Table 9. The results show that the proposed LTA exhibits significant advantages over traditional Transformer in terms of both time consumption and spatial occupancy.
To investigate the effectiveness of the differential structure of the DifferNet, the network only with
convolution kernels and the network only with
convolution kernels are compared with the DifferNet without attention. The loss functions of these methods include a smooth L1 function. The
is adopted as the evaluation indicator. The detection results are shown in
Figure 15. The anomaly targets in the results of
convolution and
convolution are not prominent compared with the differential convolution. This means that the differential convolution is effective in preserving anomaly information. The
values are shown in
Table 10. The differential convolution achieves the best detection performance compared with standard
and
convolution. As such, the framework of the proposed method is effective and excellent in the anomaly detection field.
To further illustrate the effectiveness of differential convolution for anomaly detection, we apply the differential convolution (DC) to the Auto-AD method. Specifically, all the
convolutions are replaced by
and
convolutions, and the difference operation is adopted in the decoder part of the Auto-AD. The experimental results are shown in
Figure 16. The corresponding
values are shown in
Table 11.
As shown in
Figure 16, the background in the results of Auto-AD with DC is suppressed. The anomaly targets are highlighted on the five datasets. The performance of the Auto-AD with DC is better than that of Auto-AD. The AUC values in
Table 11 show that the differential convolution can improve the performance of Auto-AD on most of the datasets. These experiments demonstrate that the differential convolution is effective.



 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}