1. Introduction
Target detection technology has now become a key research direction in the analysis of synthetic aperture radar (SAR) images [
1]. SAR images, with their unique ability to provide high-quality data under all-weather conditions, as well as various lighting and weather conditions, play a vital role in multiple fields, such as environmental monitoring [
2], urban planning [
3], and military reconnaissance [
4]. However, researchers also face multiple challenges, including resource constraints [
5], complex application scenarios [
6], the diversity of interference [
7], and real-time requirements [
8].
To meet the complex needs of specific application scenarios, precise evaluation of model performance has become a key factor in improving task success rates [
9]. This evaluation involves quantifying a model’s performance in various scenarios, its ability to handle interference, its resource use efficiency, and the extent to which it meets real-time needs. Through this process, the suitability and efficiency of a model under specific conditions can be judged, thereby guiding targeted improvements. This not only helps to improve model performance but also promotes the development of SAR image target detection technology to meet the growing application demands.
However, despite research progress in the performance evaluation of SAR image target detection models, there is still much unexplored space in this field. Xiao et al. [
10] compared a model’s parameter quantity, AP value, accuracy, and recall rate when evaluating algorithm performance, validating the proposed algorithm’s advantages of high precision and light weight. Liu et al. [
11] performed performance evaluation and quantitative assessment on the camouflage effect of SAR images, conducting comparative experiments using detection accuracy, recall rate, and detection precision as evaluation standards and assessing the performance and camouflage effect of detection models. Wei et al. [
12] proposed an SAR image small-target detection model and evaluated its performance, including the model’s accuracy, the number of targets detected, the number of targets not detected, single-image detection time, and generalization ability. Yasir et al. [
13] proposed a multi-scale SAR image target detection model and evaluated its performance, including precision, accuracy, recall rate, F1 value, and FPS, and experimentally verified that the model improved the distinguishability and anti-interference ability of weak and small-scale target detection in SAR images. Ihmeida et al. [
14] mainly studied how to improve SAR image despeckling processing through deep learning technology in order to enhance the performance of change detection (CD), using evaluation metrics including overall accuracy (OA) and F1 score, demonstrating the effectiveness of the despeckling model in enhancing change detection performance.
Bouraya et al. [
15] conducted comparative experiments on the performance evaluation of various target detection algorithms for the COCO dataset, including AP, AP50, AP75, APS, APM, and APL, and designed a weighted scoring model (WSM) to evaluate these target detection algorithms. Bulut et al. [
16] evaluated lightweight target detection models, mainly for low latency requirements and resource-limited scenarios. The models evaluated include YOLOv5-Nano, YOLOX-Nano, YOLOX-Tiny, YOLOv6-Nano, YOLOv6-Tiny, and YOLOv7-Tiny, with evaluation metrics including memory usage, model parameter size, inference time, energy consumption, AP, etc. Stankovic et al. [
17] studied the performance evaluation of YOLO models used for the automatic detection of crops and weeds based on detection accuracy for evaluation. The results showed good training performance, reaching about 70% average precision in 100 training sessions. Among them, YOLOv5x performed the best among the studied models, with evaluation metrics including precision, recall rate, mAP0.5, mAP, the number of parameters, etc. Wang et al. [
18] evaluated and compared the performance of eight mainstream detection models in bird target detection tasks, using evaluation metrics including mAP, mAP50, mAP75, and FPS, finding that, compared to single-stage target detection models, two-stage target detection models have stronger robustness to changes in bird image foreground scaling and background interference. Heda et al. [
19] conducted human detection experiments, verifying the performance of different models in the YOLO family, showing that yolov5 performed best in terms of mAP accuracy, while YOLOv3 was the fastest but slightly less accurate, with evaluation metrics including precision, recall rate, mAP, and detection time.
Gallo et al. [
20] built a dataset of weeds and tested YOLOv7, assessing the model’s performance, including with respect to mAP50, recall rate, and accuracy; the experiment showed the potential of the YOLOv7 model in weed detection. Bergstrom et al. [
21] considered three main image quality factors—resolution, blur, and noise—and their relationship with the performance of deep learning-based target detection models, studying the impact of these image quality variables on the average precision (mAP) of target detection models, and they evaluated the performance of models trained only on high-quality images, as well as those fine-tuned on low-quality images. Additionally, the authors mapped the main image quality variables to terms used in the General Image-Quality Equation (GIQE)—namely, ground sample distance (GSD), relative edge response (RER), and signal-to-noise ratio (SNR)—and assessed the applicability of the GIQE function form to modeling target detector performance in the presence of significant image distortion. Gordienko et al. [
22] studied the performance of target detection on multimodal satellite images using the Vehicle Detection in Aerial Imagery (VEDAI) dataset, adopting the YOLO (You Only Look Once) framework, covering RGB, IR, and RGB + IR modalities, as well as different image sizes ranging from 128 × 128 to 1024 × 1024. The evaluation method included 10-fold cross-validation to ensure the model’s generalization ability, mainly relying on the average precision (mAP) metric, especially
[email protected] at an IoU (intersection over union) threshold of 0.5, as well as the mAP range from 0.5 to 0.95; this shows that through this hybrid approach, mAP can be significantly improved at specific image sizes, providing valuable data-driven insights into how to optimize target detection systems. Tarekegn et al. [
23] explored the application of deep learning in automatic image preprocessing and target detection, evaluating and comparing three state-of-the-art YOLO models, including YOLOv8, YOLOv7, and YOLOv5. A large number of experiments were conducted using publicly available underwater image datasets, with evaluation metrics including precision, recall rate, mAP50, mAP, FPS, model size, etc. Huo et al. [
24] addressed the weakly supervised target detection (WSOD) problem in remote sensing images, proposing a complementary detection network (CDN) and instance difficulty scoring (IDS) method. To evaluate model performance, researchers conducted experiments on the NWPU VHR-10.v2 and DIOR datasets, mainly using mean average precision (mAP) and correct localization (CorLoc) as evaluation metrics. Additionally, compared to existing fully supervised and weakly supervised target detection methods, the proposed method achieved significant improvements in mAP and CorLoc. Despite high computational complexity during training, the inference time was comparable to that yield by comparative methods, indicating good performance and feasibility in practical applications.
Pu et al. [
25] proposed an image-to-image translation-based cross-domain learning method for target detection tasks in synthetic aperture radar (SAR) images. To evaluate model performance, the researchers used a variety of standard evaluation metrics, including inception score (IS), Fréchet inception distance (FID), recall, precision, and mean average precision (mAP). The experimental results showed that, compared to traditional data augmentation methods, the proposed method achieved significant improvements in detection accuracy and reduced missed detection rates. Huang et al. [
26] proposed a CCDS–YOLO multi-category synthetic aperture radar (SAR) image target detection model. To evaluate model performance, the researchers conducted experiments on the filtered MSAR dataset, using comprehensive evaluation metrics including precision, recall, average precision (AP), mean average precision (mAP), etc. Hindarto et al. [
27] conducted a comprehensive evaluation of the performance of two popular deep learning algorithms, ConvDeconvNet and UNET, in underwater fish target detection. The researchers used datasets containing various fish species, considering factors such as detection accuracy, processing speed, and model complexity. The results showed that ConvDeconvNet performed superiorly in terms of detection accuracy, while UNET had a significant advantage in processing speed, making it a viable option for applications requiring real-time performance. The cited study also explored the trade-off between accuracy and speed and emphasized the importance of using diverse datasets for training and testing models, as this significantly affects the overall performance of a model. Hernandez et al. [
28] worked on model performance evaluation involving comparing the performance of five different deep learning target detection models in identifying shrapnel in ultrasound images. The evaluation metrics included mean average precision (mAP), intersection over union (IoU), and inference time. These researchers used a dataset containing over 16,000 ultrasound images for training and testing to determine which model maintained high accuracy while having the fastest inference speed. The results showed that the YOLOv7 tiny model performed best in terms of mAP and inference time and was, therefore, chosen as the most suitable model for this application. Tekin et al. [
29] studied the performance of small-target detection in regard to aerial images, especially under conditions of degraded image quality (such as noise, motion blur, and raindrops). These researchers used the YOLO series (YOLOv6, YOLOv7, and YOLOv8) target detection models and evaluated their performance on original, degraded, and MPRNet image-enhanced images. The evaluation metrics used included precision, recall, F1 score, and mean average precision (mAP). The experimental results showed that image enhancement significantly improved the quality of target detection for degraded images, especially for small targets. The YOLOv8 model performed best under these conditions.
Ma et al. [
30] provided a fair and comprehensive comparison platform for the field of image-based 3D target detection. These researchers built a modularly designed code library, devised robust training schemes, designed an error diagnostics toolbox, and discussed current methods. They conducted an in-depth analysis of the performance of current methods in different settings through these tools and discussed some open questions, such as the differences in conclusions on the KITTI-3D and nuScenes datasets. The evaluation metrics used included mean average precision (mAP), average precision (AP), and 3D IoU, based on different IoU thresholds. Additionally, they proposed the TIDE3D toolbox for the quantitative analysis of detailed features of detection models, including classification errors, localization errors, duplicate errors, background errors, missing errors, ranking errors, etc. Mora et al. [
31] evaluated several techniques for accurately extracting 3D object models, combining image-based deep learning target detection and point cloud segmentation. These researchers compared various existing techniques, including bounding box target detection, instance segmentation, and methods for estimating object masks within bounding boxes. They conducted qualitative and quantitative analyses of these techniques using multiple standards, including execution time, intersection over union (IoU), chamfer distance (CD), and the distance between point cloud centers. Liu et al. [
32] proposed a lightweight deep learning model named empty road detection (ERD), and in its evaluation, the researchers found that ERD could improve the frame processing rate of EfficientDet, SSD, and YOLOv5 by approximately 44%, 40%, and 10%, respectively. The evaluation metrics used included the model’s accuracy, recall rate, precision, F1 score, and latency with respect to the GPU and CPU. Additionally, the impact of ERD on the frame rate in videos with different proportions of empty frames was also analyzed. Alin et al. [
33] evaluated the effects of different data augmentation methods when using the YOLOv5 algorithm in drone target detection. These researchers applied 14 types of data augmentation techniques, including flipping, rotation, cropping, rotation, shearing, hue, blur, grayscale, saturation, brightness, exposure, noise, cropping, and mosaic. After measuring the precision–recall evaluation metrics for each type of data augmentation, the results showed that the mosaic augmentation type provided the highest precision–recall value of 0.993 in drone target detection, performing better than other augmentation types. This study indicates that appropriately selecting data augmentation techniques can significantly enhance target detection performance when using the YOLOv5 algorithm in drone target detection. Wang et al. [
34] evaluated the effectiveness of their proposed cross-modal knowledge distillation method (CoLD) in synthetic aperture radar (SAR) image target detection tasks. Specifically, the AP metric was used to assess the model’s overall performance at different IoU thresholds, while AP50 was employed to evaluate the model’s performance at IoU = 0.50; these two metrics collectively reflected the model’s accuracy and generalization ability. Topuz et al. [
35] evaluated the effectiveness of YOLO models (YOLOv3, YOLOv5, YOLOv7, and YOLOv8) in detecting mitotic cells in various types of cancer. The evaluation metrics used included intersection over union (IoU), F score (combining precision and recall), and mean average precision (mAP), focusing on their ability to accurately identify mitotic cells in histopathological images. YOLOv8 stood out as the most successful model, showcasing high recall values and robust performance across different cancer types, highlighting its potential in real-time clinical applications. Zihan et al. [
36] conducted a meta-analysis to comprehensively evaluate the performance of deep learning in vision-based road damage detection, particularly emphasizing the uncertainty calculation of F1 scores in evaluating deep learning model performance. The cited study used the Delta method to estimate the standard error of the reported F1 scores, thereby calculating the within-study variance, using random effects meta-analysis methods to synthesize the results of multiple studies, providing a comprehensive evaluation of the performance of deep learning models in road damage detection applications. Haimer et al. [
37] compared two state-of-the-art target detection models—YOLOv7 and YOLOv8—in terms of detecting potholes in road images. To evaluate these models’ performance, the researchers used multiple target detection metrics, including precision, recall, mean average precision (mAP), F1 score, accuracy, inference time, and confusion matrices. These metrics helped the researchers measure the models’ ability to correctly identify and locate targets (potholes) in images, as well as the models’ performance at different classification thresholds. Through these evaluations, the researchers were able to determine which model offered the best balance between speed and accuracy. Bakir et al. [
38] evaluated the robustness of YOLO object detection algorithms in detecting objects in noisy environments. These researchers created four case studies by injecting different proportions of Gaussian noise into the original image dataset to evaluate the YOLOv5 algorithm’s ability to detect objects in noisy images. The evaluation metrics used included the confusion matrix, recall, precision, F1 score, and mean average precision (mAP). The experimental results showed that as the proportion of injected noise increased, the performance of the YOLO algorithm gradually declined, especially when the noise ratio reached 100%, at which point performance significantly decreased, most objects could not be detected, and the detected object labels were also wrong. Mohd et al. [
39] evaluated and compared the performance of YOLOv5, YOLOv6, and YOLOv7 models in road defect detection and classification. The evaluation metrics used included the model’s training time,
[email protected] (mean average precision), accuracy, and inference speed. The experimental results showed that the YOLOv7 model performed best in terms of
[email protected] score, reaching 79.0%, and had the fastest inference speed, processing 255 test images in 0.47 min. Additionally, the cited paper explored the impact of different data augmentation techniques and evaluated the potential of inference and fine-tuning to enhance accuracy. Tummuri et al. [
40] evaluated the performance of YOLOv5 (You Look Only Once version 5) in electronic device classification. The evaluation metrics included precision, recall rate, F1 score, and mean average precision (mAP). The research results showed that YOLOv5 excelled in recognition accuracy, with a precision of 95.55%, a recall rate of 95.84%, an F1 score of 96.54%, and an mAP of 94.63%. Additionally, YOLOv5 performed excellently in real-time processing, being capable of processing images at a rate of 45 frames per second, and its mAP in real-time systems was more than twice that of other systems.
In summary, the current stage of target detection model performance evaluation has two main shortcomings: the limitations of single-dimensional evaluation and the lack of a comprehensive evaluation mechanism.
- (1)
The limitations of single-dimensional evaluation
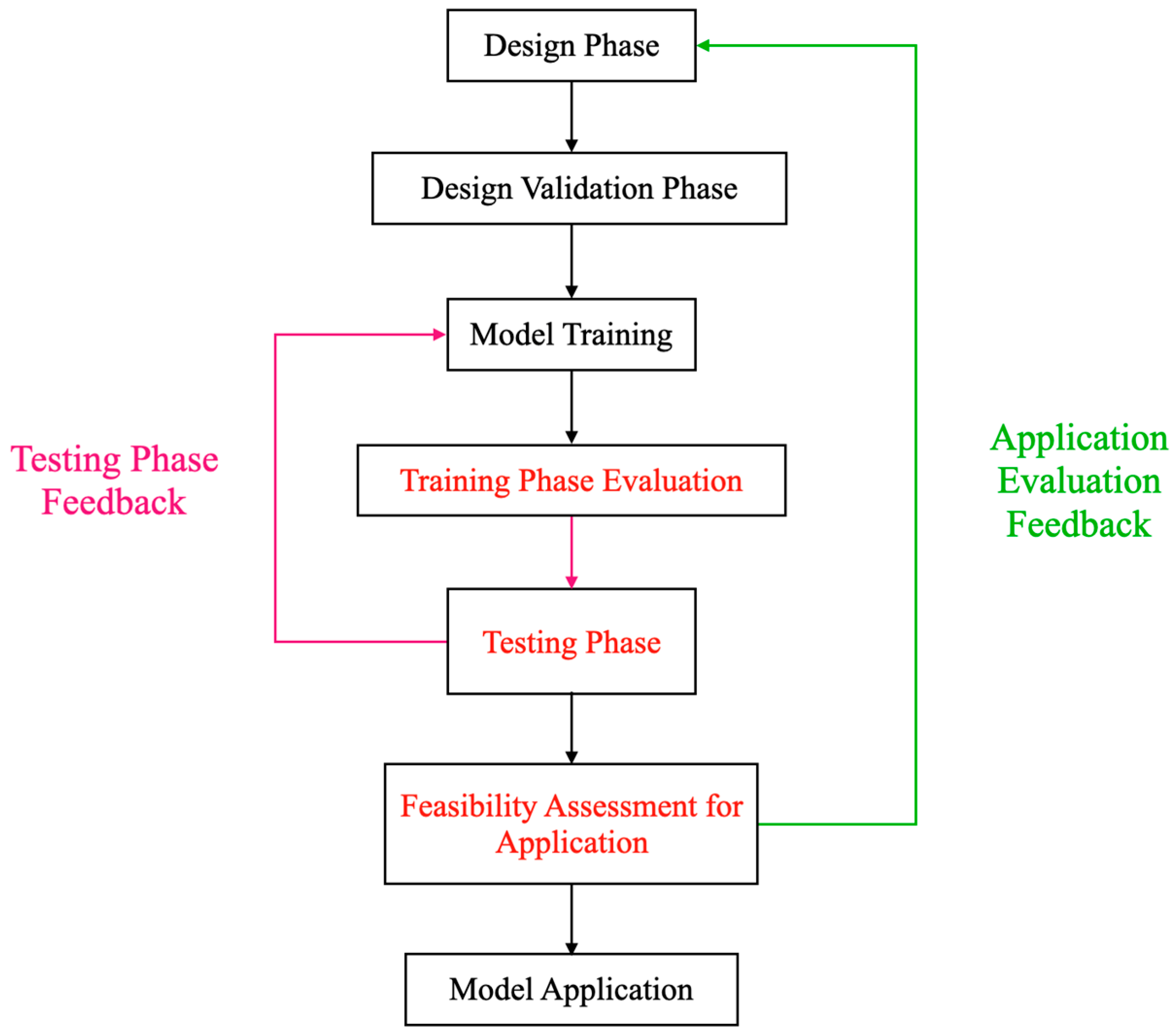
In the existing literature, the performance evaluation of target detection models is often limited to the testing phase, neglecting the model’s training and actual application process. This single-dimensional evaluation method fails to fully capture a model’s performance in actual deployment. Especially for SAR image processing, models face different challenges and performance requirements at the training, testing, and application stages. For example, a model may exhibit excellent accuracy during the testing phase but require significant computational resources during training or fail to effectively adapt to new data types and complex scenes when processing actual SAR images. Without single-stage evaluation, we cannot deeply understand the comprehensive performance and applicability of models when dealing with SAR image data.
- (2)
The lack of a comprehensive evaluation mechanism
Current evaluation methods often list multiple detection results simply, without providing a comprehensive evaluation of a model’s overall performance or an in-depth analysis of its applicability. The limitation of these methods is that although a model’s performance can be observed from multiple dimensions, there is a lack of a comprehensive performance evaluation system, making it difficult to guide model optimization and practical application decisions. In the field of SAR image applications, whether a model can adapt to different environmental conditions, its robustness in handling high data diversity, and its performance in terms of resource consumption and execution efficiency are key indicators for assessing whether it meets practical application needs. Without a comprehensive evaluation mechanism, it is difficult to fully evaluate the true value and potential application range of models in processing SAR images.
Therefore, to address the limitations of single-dimensional evaluation and the lack of a comprehensive evaluation mechanism in the field of target detection, this paper proposes a multi-dimensional evaluation method for deep learning models used in SAR image target detection. The contributions of this paper are as follows:
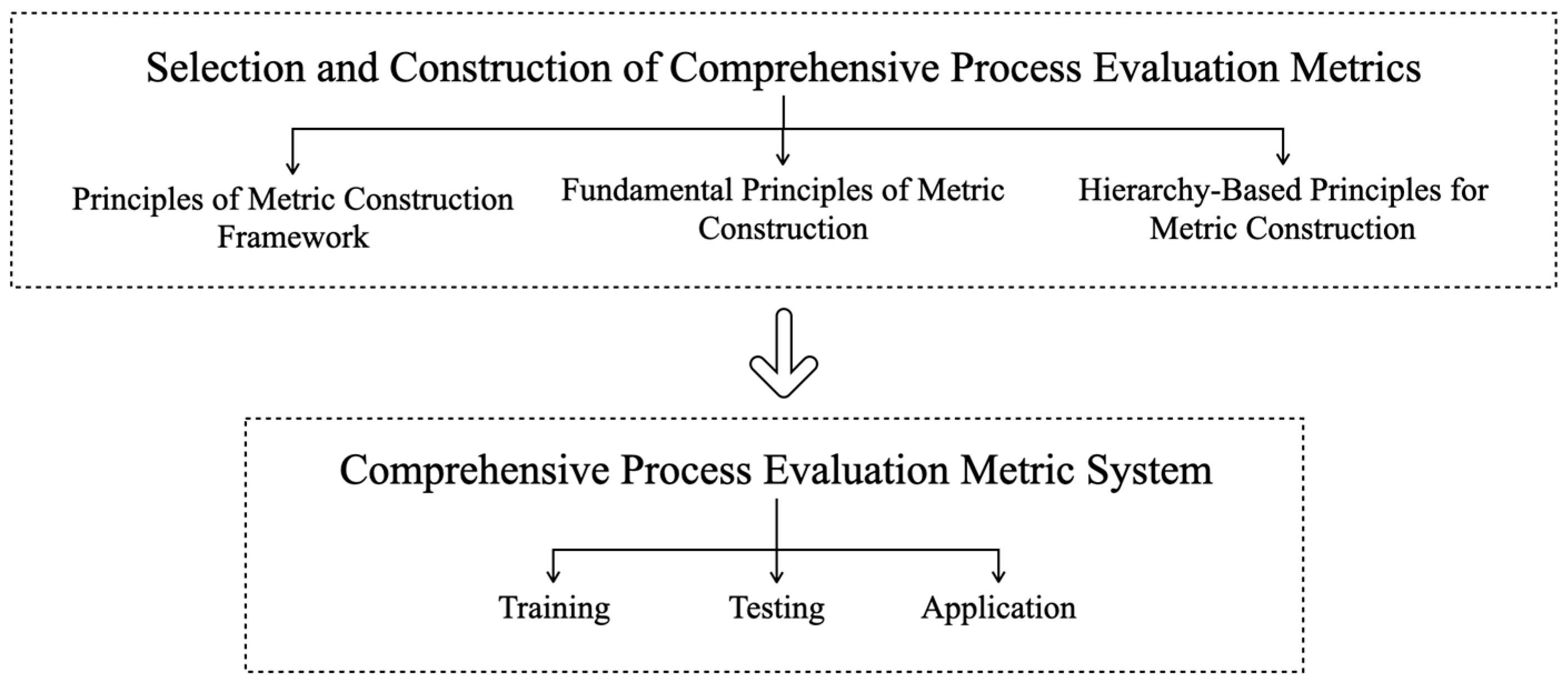
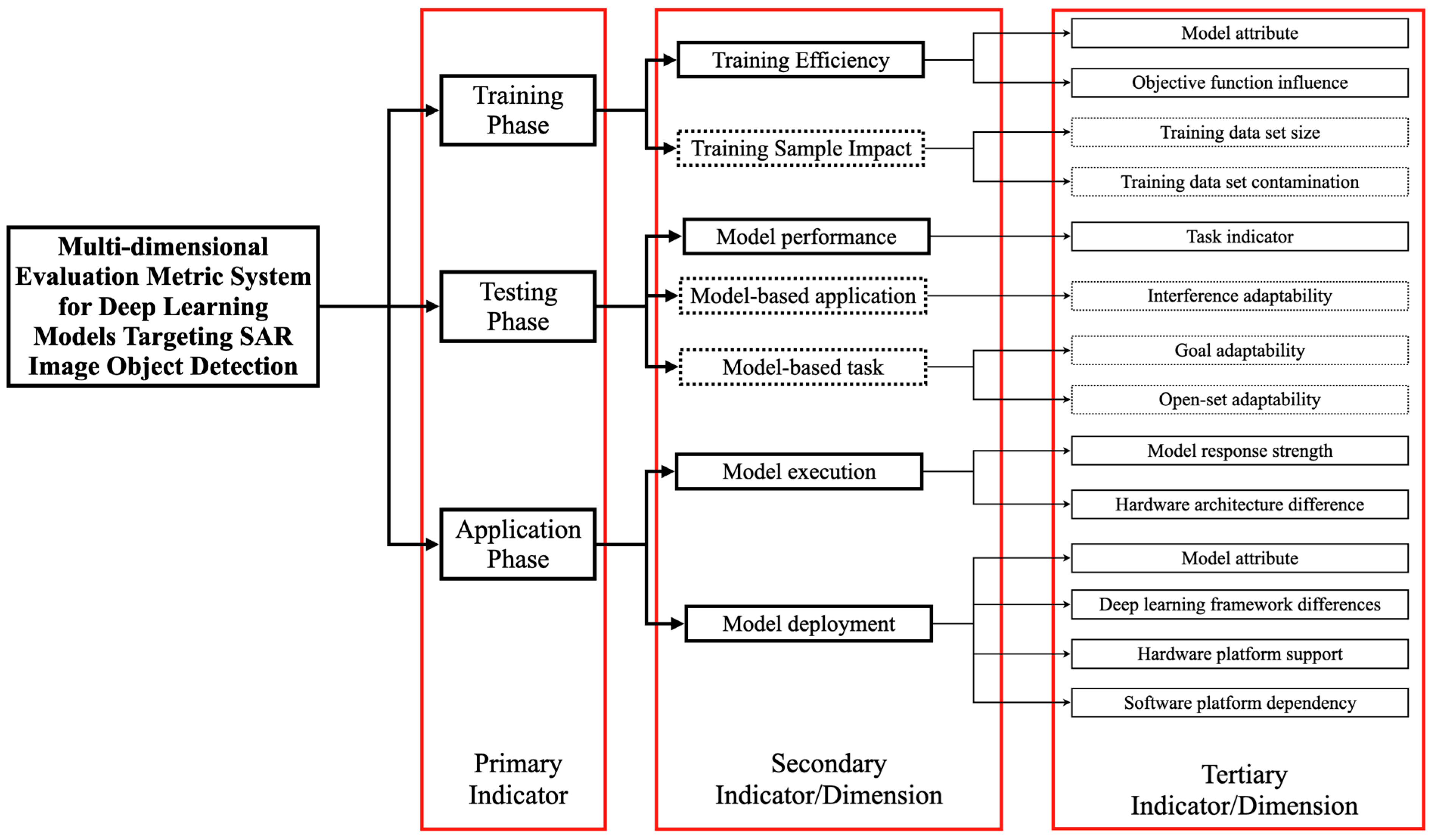
Proposing a multi-dimensional evaluation metric system for deep learning models in SAR image target detection, covering the training stage, testing stage, and application stage. The training stage includes training efficiency and training sample impact; the testing stage includes model performance, evaluation based on model application, and evaluation based on model tasks; and the application stage includes evaluation for model operation and model deployment.
Proposing a multi-indicator comprehensive evaluation method based on entropy weight correlation scaling, aimed at comprehensively evaluating multi-dimensional indicators, providing a mechanism for balanced and comprehensive evaluation of model performance.
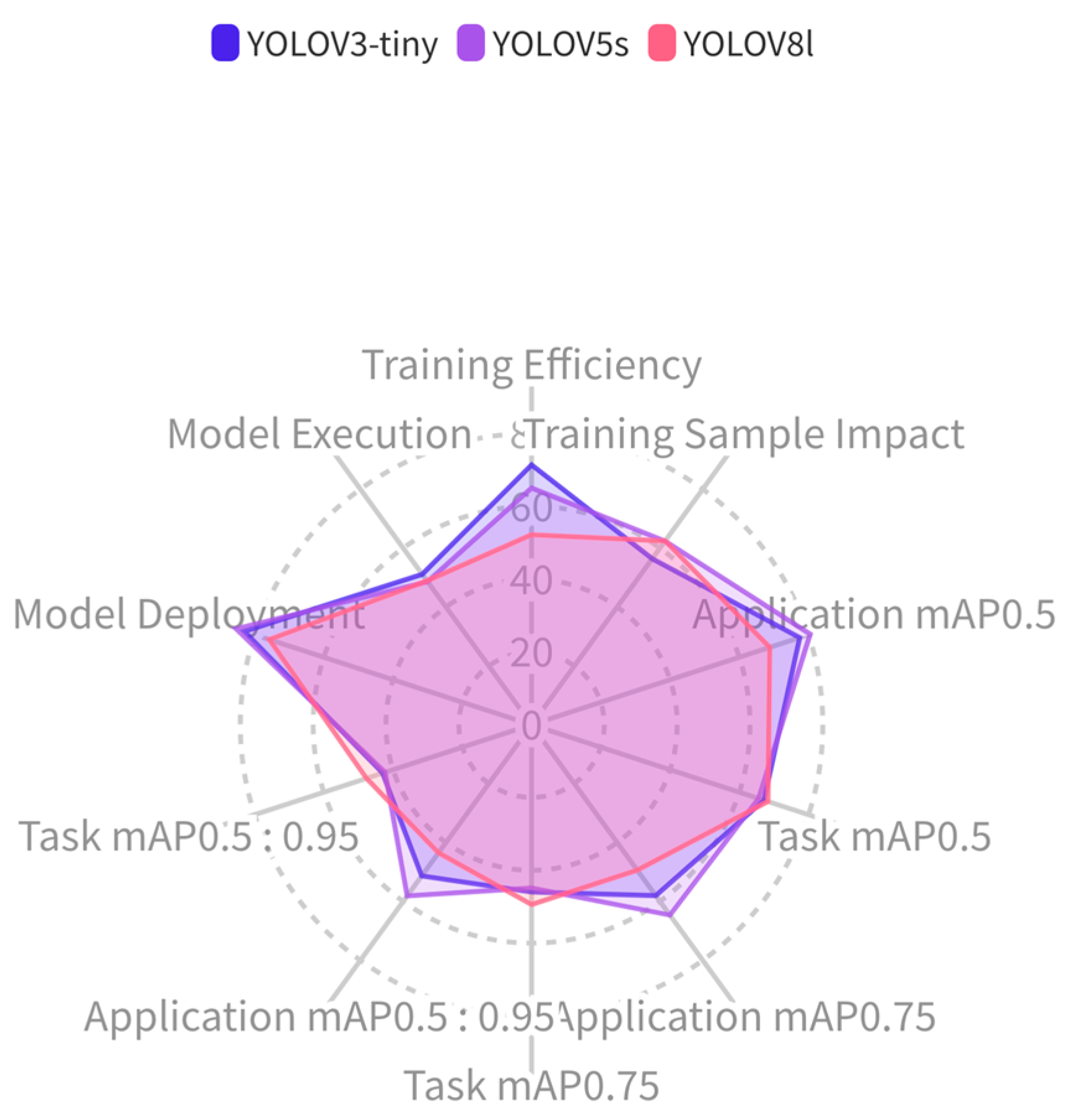
Constructing a multi-dimensional deep learning target detection performance profile, presenting the performance of target detection models in a multi-dimensional visual manner.
The remainder of this paper is organized as follows:
Section 2 introduces the multidimensional evaluation method for deep learning models aimed at SAR image target detection;
Section 3 introduces the multi-indicator comprehensive evaluation method based on entropy-weighted relevance scaling;
Section 4 presents the experiments and evaluation results of this paper; and the conclusions of this paper will be given in
Section 5.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




