
MRG-T: Mask-Relation-Guided Transformer for Remote Vision-Based Pedestrian Attribute Recognition in Aerial Imagery



Abstract
:1. Introduction
- We propose a novel Mask-Relation-Guided Transformer (MRG-T) framework to mitigate the information redundancy dilemma and model the three inter-region, inter-attribute, and region-attribute mapping relations simultaneously in a unified framework for remote vision-based PAR.
- We construct three modules, MRRM, MARM, and RAMM, to fully explore spatial relations of regions, semantic relations of attributes, and mapping of regions and attributes, respectively. The modules take advantage of the Transformer encoder architecture for its ability to capture long-distance dependencies from the global view.
- We present masked random patch training and attribute label masking strategies for MRRM and MARM, respectively, to conduct long-range dependency modeling of inter-region relations and inter-attribute relations efficiently. The beneficial effect of mask attention in the relational modeling method is proven through experiments.
- Our method performs favorably against state-of-the-art methods on three PAR datasets (PETA, PA-100K, and RAP) using the same backbone architecture. Moreover, we conduct model inference on a large aerial person imagery dataset PRAI-1581. Ablation experiments and visualization results are presented to demonstrate the capability of the proposed method in mask-relation-guided modeling.
2. Related Works
2.1. Pedestrian Attribute Recognition
2.2. Transformer Model and Mask-Attention Modeling
2.3. Pedestrian Attribute Recognition Based on Transformer
3. Proposed Method
3.1. Overall Architecture
3.2. Masked Region Relation Module (MRRM)
3.3. Masked Attribute Relation Module (MARM)
3.4. The Region and Attribute Mapping Module (RAMM)
3.5. Final Classification and Loss Function
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.3. Comparison with State-of-the-Art Methods
4.4. Ablation Studies
4.4.1. Effectiveness of MRG-T
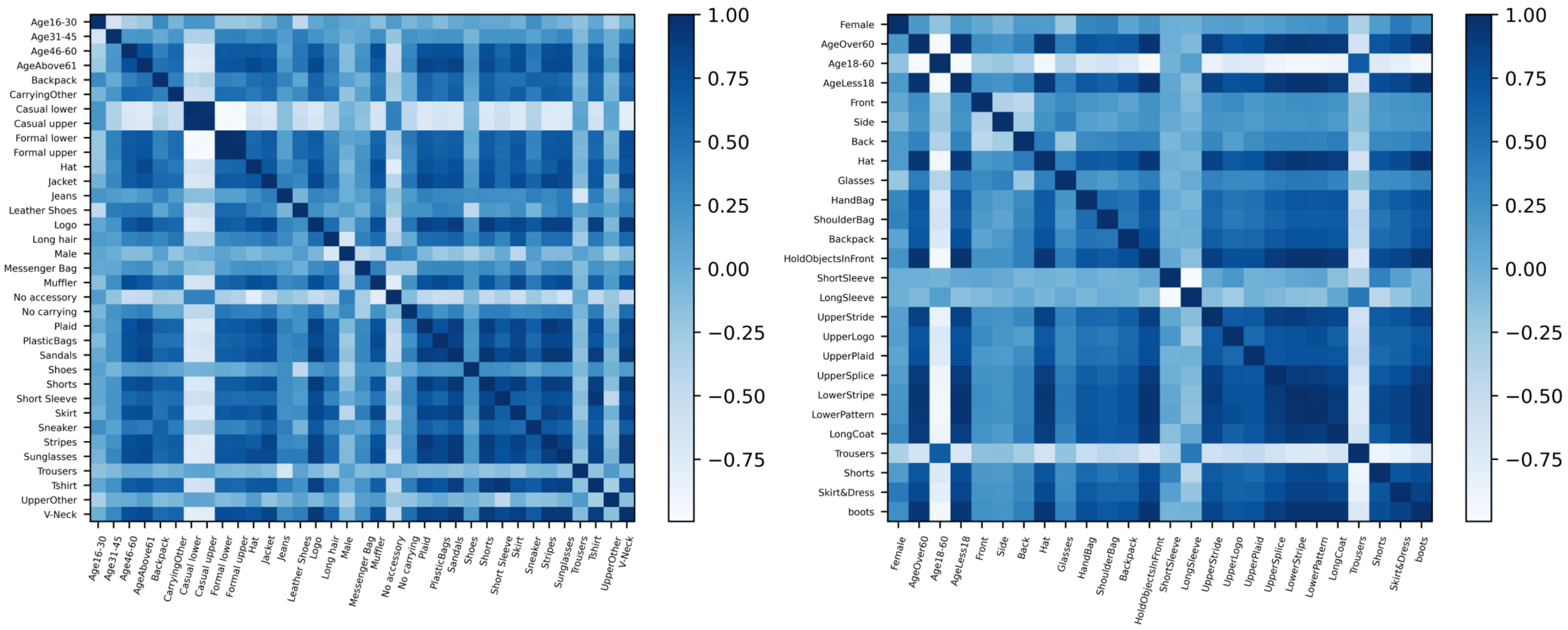
4.4.2. Benefit of Spatial Relations of Regions
4.4.3. Benefit of Semantic Relations of Attributes
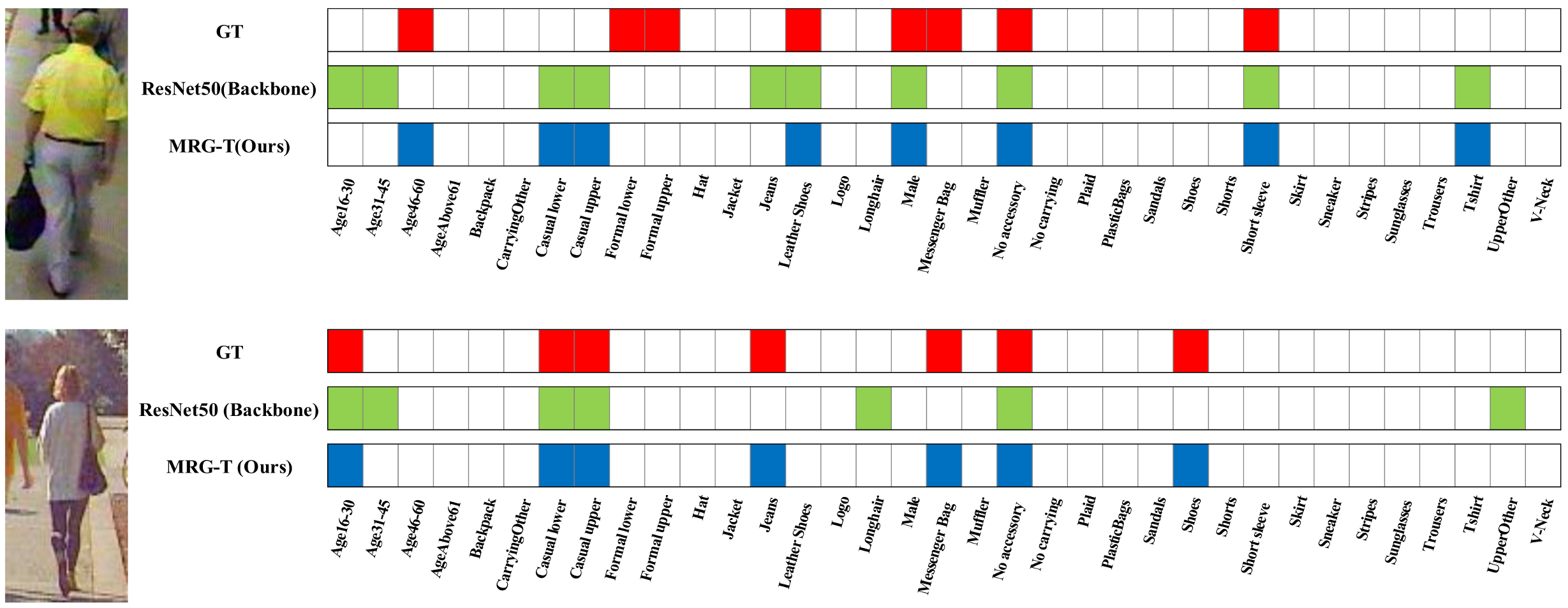
4.4.4. Mapping Visualizations of Regions and Attributes
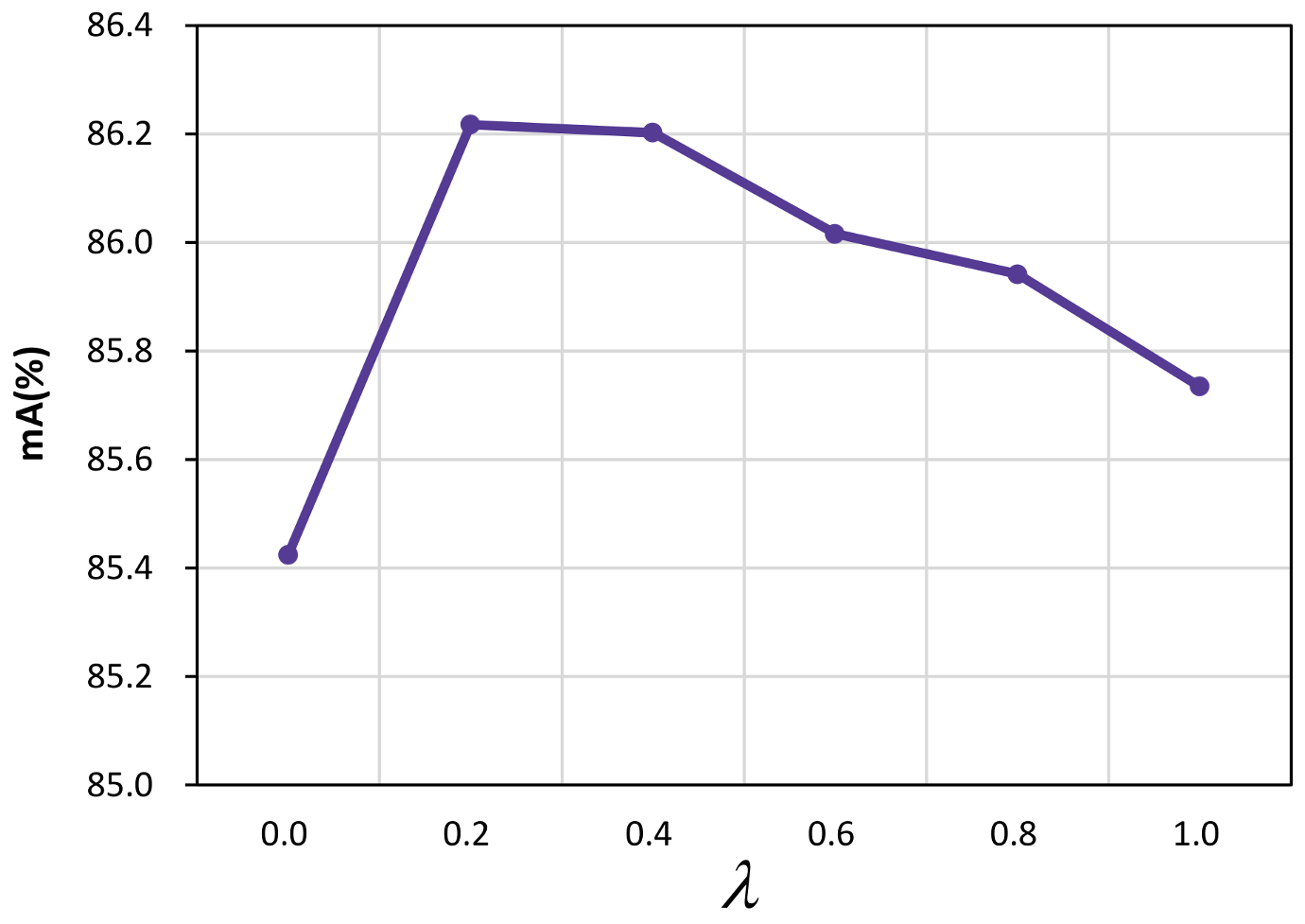
4.4.5. Settings Analysis of MRG-T
4.4.6. Ablation Studies on Aerial Image Dataset PRAI-1581
- : Use only visual features extracted by ResNet50 and label embeddings retrieved by an embedding layer.
- : Add visual mask-guided Transformer MRRM based on to model inter-region relations of images.
- : Add label mask-guided Transformer MARM based on to model inter-attribute relations of labels.
- : Add RAMM module to model region-attribute mapping relations.
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, X.; Zheng, S.; Yang, R.; Zheng, A.; Chen, Z.; Tang, J.; Luo, B. Pedestrian attribute recognition: A survey. Pattern Recognit. 2022, 121, 108220. [Google Scholar] [CrossRef]
- Schumann, A.; Stiefelhagen, R. Person re-identification by deep learning attribute-complementary information. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 20–28. [Google Scholar]
- Lin, Y.; Zheng, L.; Zheng, Z.; Wu, Y.; Hu, Z.; Yan, C.; Yang, Y. Improving person re-identification by attribute and identity learning. Pattern Recognit. 2019, 95, 151–161. [Google Scholar] [CrossRef]
- Zhu, Y.; Wang, T.; Zhu, S. Adaptive Multi-Pedestrian Tracking by Multi-Sensor: Track-to-Track Fusion Using Monocular 3D Detection and MMW Radar. Remote Sens. 2022, 14, 1837. [Google Scholar] [CrossRef]
- Zhang, S.; Huang, J.B.; Lim, J.; Gong, Y.; Wang, J.; Ahuja, N.; Yang, M.H. Tracking persons-of-interest via unsupervised representation adaptation. Int. J. Comput. Vision 2020, 128, 96–120. [Google Scholar] [CrossRef]
- Shi, Y.; Wei, Z.; Ling, H.; Wang, Z.; Shen, J.; Li, P. Person retrieval in surveillance videos via deep attribute mining and reasoning. IEEE Trans. Multimed. 2020, 23, 4376–4387. [Google Scholar] [CrossRef]
- Zhang, S.; Li, Y.; Mei, S. Exploring Uni-Modal Feature Learning on Entities and Relations for Remote Sensing Cross-Modal Text-Image Retrieval. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–17. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Zhao, R.; Lang, C.; Li, Z.; Liang, L.; Wei, L.; Feng, S.; Wang, T. Pedestrian attribute recognition based on attribute correlation. Multimed. Syst. 2022, 28, 1069–1081. [Google Scholar] [CrossRef]
- Zhao, X.; Sang, L.; Ding, G.; Guo, Y.; Jin, X. Grouping attribute recognition for pedestrian with joint recurrent learning. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; Volume 2018, pp. 3177–3183. [Google Scholar]
- Zhao, X.; Sang, L.; Ding, G.; Han, J.; Di, N.; Yan, C. Recurrent attention model for pedestrian attribute recognition. Proc. AAAI Conf. Artif. Intell. 2019, 33, 9275–9282. [Google Scholar] [CrossRef]
- Li, Y.; Gupta, A. Beyond grids: Learning graph representations for visual recognition. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Li, Q.; Zhao, X.; He, R.; Huang, K. Visual-semantic graph reasoning for pedestrian attribute recognition. Proc. AAAI Conf. Artif. Intell. 2019, 33, 8634–8641. [Google Scholar] [CrossRef]
- Tan, Z.; Yang, Y.; Wan, J.; Guo, G.; Li, S.Z. Relation-aware pedestrian attribute recognition with graph convolutional networks. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12055–12062. [Google Scholar] [CrossRef]
- Tang, Z.; Huang, J. DRFormer: Learning dual relations using Transformer for pedestrian attribute recognition. Neurocomputing 2022, 497, 159–169. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations, Online, 3–7 May 2021. [Google Scholar]
- Hu, H.; Zhou, G.T.; Deng, Z.; Liao, Z.; Mori, G. Learning structured inference neural networks with label relations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2960–2968. [Google Scholar]
- Wang, J.; Zhu, X.; Gong, S.; Li, W. Attribute recognition by joint recurrent learning of context and correlation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 531–540. [Google Scholar]
- Wu, J.; Huang, Y.; Gao, Z.; Hong, Y.; Zhao, J.; Du, X. Inter-Attribute awareness for pedestrian attribute recognition. Pattern Recognit. 2022, 131, 108865. [Google Scholar] [CrossRef]
- Li, D.; Chen, X.; Zhang, Z.; Huang, K. Pose guided deep model for pedestrian attribute recognition in surveillance scenarios. In Proceedings of the IEEE International Conference on Multimedia and Expo, San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Liu, P.; Liu, X.; Yan, J.; Shao, J. Localization guided learning for pedestrian attribute recognition. In Proceedings of the British Machine Vision Conference, Newcastle, UK, 3–6 September 2018; p. 142. [Google Scholar]
- Tang, C.; Sheng, L.; Zhang, Z.; Hu, X. Improving pedestrian attribute recognition with weakly-supervised multi-scale attribute-specific localization. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4997–5006. [Google Scholar]
- Sarafianos, N.; Xu, X.; Kakadiaris, I.A. Deep imbalanced attribute classification using visual attention aggregation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 680–697. [Google Scholar]
- Cheng, X.; Jia, M.; Wang, Q.; Zhang, J. A Simple Visual-Textual Baseline for Pedestrian Attribute Recognition. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6994–7004. [Google Scholar] [CrossRef]
- Wu, J.; Liu, H.; Jiang, J.; Qi, M.; Ren, B.; Li, X.; Wang, Y. Person attribute recognition by sequence contextual relation learning. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3398–3412. [Google Scholar] [CrossRef]
- Li, T.; Liu, J.; Zhang, W.; Ni, Y.; Wang, W.; Li, Z. Uav-human: A large benchmark for human behavior understanding with unmanned aerial vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 16266–16275. [Google Scholar]
- Cao, Y.; He, Z.; Wang, L.; Wang, W.; Yuan, Y.; Zhang, D.; Zhang, J.; Zhu, P.; Van Gool, L.; Han, J.; et al. VisDrone-DET2021: The vision meets drone object detection challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2847–2854. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and tracking meet drones challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7380–7399. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Zhang, Q.; Yang, Y.; Wei, X.; Wang, P.; Jiao, B.; Zhang, Y. Person re-identification in aerial imagery. IEEE Trans. Multimedia 2020, 23, 281–291. [Google Scholar] [CrossRef]
- Zhang, S.; Yang, Q.; Cheng, D.; Xing, Y.; Liang, G.; Wang, P.; Zhang, Y. Ground-to-Aerial Person Search: Benchmark Dataset and Approach. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 789–799. [Google Scholar]
- Akbari, Y.; Almaadeed, N.; Al-Maadeed, S.; Elharrouss, O. Applications, databases and open computer vision research from drone videos and images: A survey. Artif. Intell. Rev. 2021, 54, 3887–3938. [Google Scholar] [CrossRef]
- Zhu, J.; Liao, S.; Lei, Z.; Yi, D.; Li, S. Pedestrian attribute classification in surveillance: Database and evaluation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2–8 December 2013; pp. 331–338. [Google Scholar]
- Deng, Y.; Luo, P.; Loy, C.C.; Tang, X. Pedestrian attribute recognition at far distance. In Proceedings of the ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 789–792. [Google Scholar]
- Liu, X.; Zhao, H.; Tian, M.; Sheng, L.; Shao, J.; Yi, S.; Yan, J.; Wang, X. Hydraplus-net: Attentive deep features for pedestrian analysis. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 350–359. [Google Scholar]
- Tan, Z.; Yang, Y.; Wan, J.; Hang, H.; Guo, G.; Li, S.Z. Attention-based pedestrian attribute analysis. IEEE Trans. Image Process. 2019, 28, 6126–6140. [Google Scholar] [CrossRef]
- Li, D.; Chen, X.; Huang, K. Multi-attribute learning for pedestrian attribute recognition in surveillance scenarios. In Proceedings of the Asian Conference on Pattern Recognition, Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 111–115. [Google Scholar]
- Sarfraz, M.S.; Schumann, A.; Wang, Y.; Stiefelhagen, R. Deep view-sensitive pedestrian attribute inference in an end-to-end model. In Proceedings of the British Machine Vision Conference, London, UK, 4–7 September 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Tenney, I.; Das, D.; Pavlick, E. BERT rediscovers the classical NLP pipeline. In Proceedings of the Conference of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4593–4601. [Google Scholar]
- Tetko, I.V.; Karpov, P.; Van Deursen, R.; Godin, G. State-of-the-art augmented NLP transformer models for direct and single-step retrosynthesis. Nat. Commun. 2020, 11, 5575. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- He, S.; Luo, H.; Wang, P.; Wang, F.; Li, H.; Jiang, W. Transreid: Transformer-based Object Re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15013–15022. [Google Scholar]
- Ren, Z.; Gou, S.; Guo, Z.; Mao, S.; Li, R. A mask-guided transformer network with topic token for remote sensing image captioning. Remote Sens. 2022, 14, 2939. [Google Scholar] [CrossRef]
- Reedha, R.; Dericquebourg, E.; Canals, R.; Hafiane, A. Transformer neural network for weed and crop classification of high resolution UAV images. Remote Sens. 2022, 14, 592. [Google Scholar] [CrossRef]
- Liu, Y.; Liao, Y.; Lin, C.; Jia, Y.; Li, Z.; Yang, X. Object tracking in satellite videos based on correlation filter with multi-feature fusion and motion trajectory compensation. Remote Sens. 2022, 14, 777. [Google Scholar] [CrossRef]
- Xu, F.; Liu, J.; Song, Y.; Sun, H.; Wang, X. Multi-exposure image fusion techniques: A comprehensive review. Remote Sens. 2022, 14, 771. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Gabeur, V.; Sun, C.; Alahari, K.; Schmid, C. Multi-modal transformer for video retrieval. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 214–229. [Google Scholar]
- Cornia, M.; Stefanini, M.; Baraldi, L.; Cucchiara, R. Meshed-memory transformer for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10578–10587. [Google Scholar]
- Chen, S.; Hong, Z.; Liu, Y.; Xie, G.S.; Sun, B.; Li, H.; Peng, Q.; Lu, K.; You, X. Transzero: Attribute-guided transformer for zero-shot learning. Proc. AAAI Conf. Artif. Intell. 2022, 2, 3. [Google Scholar] [CrossRef]
- Wu, X.; Li, Y.; Long, J.; Zhang, S.; Wan, S.; Mei, S. A remote-vision-based safety helmet and harness monitoring system based on attribute knowledge modeling. Remote Sens. 2023, 15, 347. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 28 March 2024).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F. Beit: Bert pre-training of image transformers. In Proceedings of the International Conference on Learning Representations, Online, 25–29 April 2022. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Tao, H.; Duan, Q.; Lu, M.; Hu, Z. Learning discriminative feature representation with pixel-level supervision for forest smoke recognition. Pattern Recognit. 2023, 143, 109761. [Google Scholar] [CrossRef]
- Lin, T.; Joe, I. An Adaptive Masked Attention Mechanism to Act on the Local Text in a Global Context for Aspect-Based Sentiment Analysis. IEEE Access 2023, 11, 43055–43066. [Google Scholar] [CrossRef]
- Lee, G.; Cho, J. STDP-Net: Improved Pedestrian Attribute Recognition Using Swin Transformer and Semantic Self-Attention. IEEE Access 2022, 10, 82656–82667. [Google Scholar] [CrossRef]
- Fan, X.; Zhang, Y.; Lu, Y.; Wang, H. PARFormer: Transformer-based Multi-Task Network for Pedestrian Attribute Recognition. IEEE Trans. Circ. Syst. Video Technol. 2024, 33, 411–423. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Lanchantin, J.; Wang, T.; Ordonez, V.; Qi, Y. General multi-label image classification with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16478–16488. [Google Scholar]
- Li, D.; Zhang, Z.; Chen, X.; Huang, K. A richly annotated pedestrian dataset for person retrieval in real surveillance scenarios. IEEE Trans. Image Process. 2018, 28, 1575–1590. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Liu, Z.; Zhang, Z.; Li, D.; Zhang, P.; Shan, C. Dual-branch self-attention network for pedestrian attribute recognition. Pattern Recognit. Lett. 2022, 163, 112–120. [Google Scholar] [CrossRef]
- Jia, J.; Huang, H.; Chen, X.; Huang, K. Rethinking of pedestrian attribute recognition: A reliable evaluation under zero-shot pedestrian identity setting. arXiv 2021, arXiv:2107.03576. [Google Scholar]
- Jia, J.; Chen, X.; Huang, K. Spatial and semantic consistency regularizations for pedestrian attribute recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 962–971. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | PETA | PA100K | RAPv1 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mA | Acc | Prec | Rec | F1 | mA | Acc | Prec | Rec | F1 | mA | Acc | Prec | Rec | F1 | ||
| DeepMAR(ACPR15) [36] | CaffeNet | 82.89 | 75.07 | 83.68 | 83.14 | 83.41 | 72.70 | 70.39 | 82.24 | 80.42 | 81.32 | 73.79 | 62.02 | 74.92 | 76.21 | 75.56 |
| HPNet(ICCV17) [34] | InceptionNet | 81.77 | 76.13 | 84.92 | 83.24 | 84.07 | 74.21 | 72.19 | 82.97 | 82.09 | 82.53 | 76.12 | 65.39 | 77.33 | 78.79 | 78.05 |
| PGDM(ICME18) [20] | CaffeNet | 82.97 | 78.08 | 86.86 | 84.68 | 85.76 | 74.95 | 73.08 | 84.36 | 82.24 | 83.29 | 74.31 | 64.57 | 78.86 | 75.90 | 77.35 |
| MsVAA(ECCV18) [23] | ResNet50 | 84.35 | 78.69 | 87.27 | 85.51 | 86.09 | 80.10 | 76.98 | 86.26 | 85.62 | 85.50 | 79.75 | 65.74 | 77.69 | 78.99 | 77.93 |
| ALM(ICCV19) [22] | ResNet50 | 85.50 | 78.37 | 83.76 | 89.13 | 86.04 | 79.26 | 78.64 | 87.33 | 86.73 | 86.64 | 81.16 | 67.35 | 74.97 | 85.36 | 79.39 |
| Baseline(Arxiv21) [69] | ResNet50 | 84.42 | 78.13 | 86.88 | 85.08 | 85.97 | 80.38 | 78.58 | 87.09 | 87.01 | 87.05 | 80.32 | 67.28 | 79.04 | 79.89 | 79.46 |
| JRL(ICCV17) [18] | AlexNet | 85.67 | - | 86.03 | 85.34 | 85.42 | - | - | - | - | - | 77.81 | - | 78.11 | 78.98 | 78.58 |
| RC(AAAI19) [11] | Inception_v3 | 85.78 | - | 85.42 | 88.02 | 86.70 | - | - | - | - | - | 78.47 | - | 82.67 | 76.65 | 79.54 |
| RA(AAAI19) [11] | Inception_v3 | 86.11 | - | 84.69 | 88.51 | 86.56 | - | - | - | - | - | 81.16 | - | 79.45 | 79.23 | 79.34 |
| SCRL(CSVT20) [25] | ResNet50 | - | - | - | - | - | 80.6 | - | 88.7 | 84.9 | 86.8 | 81.9 | - | 82.4 | 81.9 | 82.1 |
| SSChard(ICCV21) [70] | ResNet50 | 85.92 | 78.53 | 86.31 | 86.23 | 85.96 | 81.02 | 78.42 | 86.39 | 87.55 | 86.55 | 82.14 | 68.16 | 77.87 | 82.88 | 79.87 |
| IAA-Caps(PR22) [19] | OSNet | 85.27 | 78.04 | 86.08 | 85.80 | 85.64 | 81.94 | 80.31 | 88.36 | 88.01 | 87.80 | 81.72 | 68.47 | 79.56 | 82.06 | 80.37 |
| VTB(CSVT22) [24] | ResNet50 | - | - | - | - | - | 81.02 | 80.89 | 87.88 | 89.30 | 88.21 | 81.43 | 69.21 | 78.22 | 83.99 | 80.63 |
| PARFormer(CSVT23) [61] | ResNet50 | - | - | - | - | - | 79.41 | 78.05 | 86.84 | 86.75 | 86.59 | - | - | - | - | - |
| MRG-T w/o mask (Ours) | ResNet50 | 85.42 | 79.69 | 87.47 | 87.46 | 86.93 | 80.35 | 79.02 | 86.75 | 88.31 | 86.12 | 80.02 | 67.41 | 75.54 | 85.36 | 79.94 |
| MRG-T(Ours) | ResNet50 | 86.22 | 79.86 | 86.53 | 89.51 | 87.09 | 81.24 | 79.92 | 87.91 | 89.61 | 86.66 | 82.10 | 69.16 | 77.67 | 86.48 | 80.41 |
| Component | mA | Acc | Prec | Rec | F1 |
|---|---|---|---|---|---|
| w/o MRRM | 85.83 | 79.45 | 86.21 | 88.72 | 86.64 |
| w MRRM | 86.22 | 79.86 | 86.53 | 89.51 | 87.09 |
| Component | mA | Acc | Prec | Rec | F1 |
|---|---|---|---|---|---|
| w/o MARM | 85.59 | 79.61 | 86.23 | 88.32 | 86.91 |
| w MARM | 86.22 | 79.86 | 86.53 | 89.51 | 87.09 |
| Masked Attribute Ratio | PETA | |||
|---|---|---|---|---|
| 25% | 50% | 75% | 100% | |
| MRG-T (Ours) | 85.88 | 85.90 | 86.22 | 85.68 |
| Method | Cos〈Longhair, Male〉 | Cos〈Longhair, Skirt〉 | Cos〈Casuallower, LeatherShoes〉 | Cos〈Formallower, LeatherShoes〉 | |
|---|---|---|---|---|---|
| MRRM | MARM | ||||
| - | - | −0.6578 | 0.6267 | −0.5138 | 0.5299 |
| - | ✓ | −0.6731 | 0.6476 | −0.5598 | 0.5711 |
| ✓ | ✓ | −0.6929 | 0.6998 | −0.5739 | 0.5925 |
| Ablation Model | Module | mA | ||
|---|---|---|---|---|
| MRRM | MARM | RAMM | ||
| 80.13 | ||||
| ✓ | 89.44 | |||
| ✓ | ✓ | 91.92 | ||
| ✓ | ✓ | ✓ | 93.27 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Li, Y.; Wu, X.; Chu, Z.; Li, L. MRG-T: Mask-Relation-Guided Transformer for Remote Vision-Based Pedestrian Attribute Recognition in Aerial Imagery. Remote Sens. 2024, 16, 1216. https://doi.org/10.3390/rs16071216
Zhang S, Li Y, Wu X, Chu Z, Li L. MRG-T: Mask-Relation-Guided Transformer for Remote Vision-Based Pedestrian Attribute Recognition in Aerial Imagery. Remote Sensing. 2024; 16(7):1216. https://doi.org/10.3390/rs16071216
Chicago/Turabian StyleZhang, Shun, Yupeng Li, Xiao Wu, Zunheng Chu, and Lingfei Li. 2024. "MRG-T: Mask-Relation-Guided Transformer for Remote Vision-Based Pedestrian Attribute Recognition in Aerial Imagery" Remote Sensing 16, no. 7: 1216. https://doi.org/10.3390/rs16071216
APA StyleZhang, S., Li, Y., Wu, X., Chu, Z., & Li, L. (2024). MRG-T: Mask-Relation-Guided Transformer for Remote Vision-Based Pedestrian Attribute Recognition in Aerial Imagery. Remote Sensing, 16(7), 1216. https://doi.org/10.3390/rs16071216