

A Bio-Inspired Visual Perception Transformer for Cross-Domain Semantic Segmentation of High-Resolution Remote Sensing Images

Abstract
:
1. Introduction
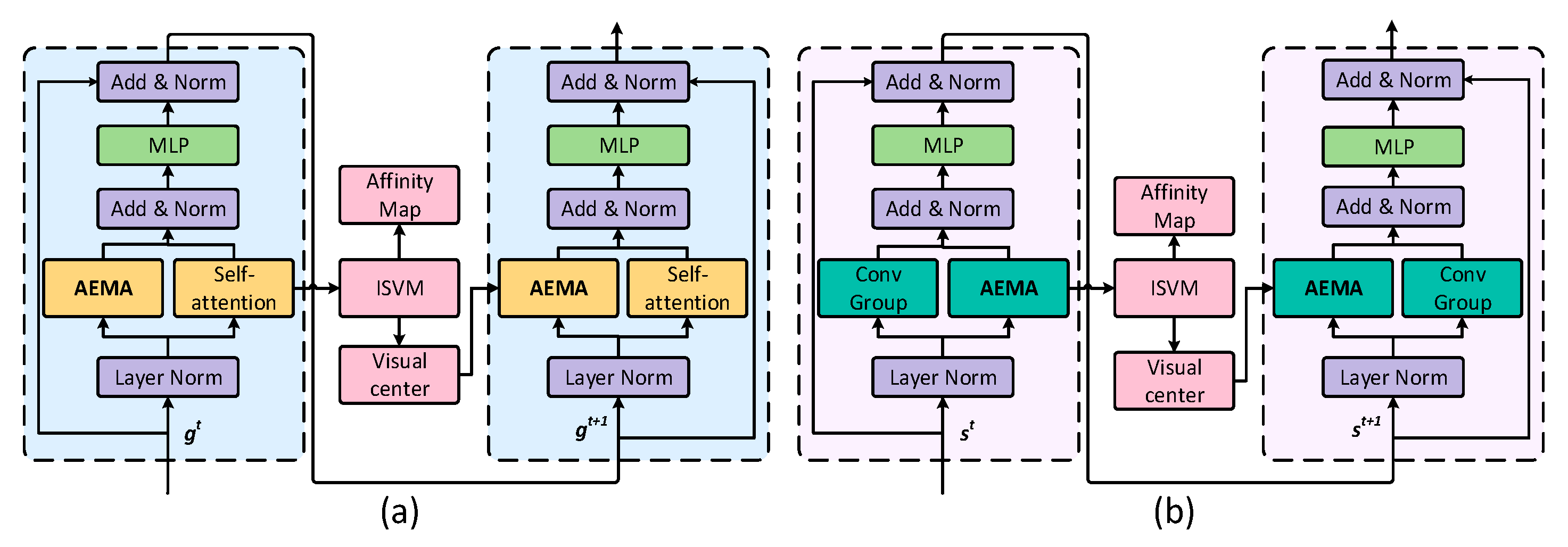
- We propose a gaze–saccade transformer with an eye movement attention strategy (GSV-Trans), which simulates the eye movement model by adding adaptive eye movement attention (AEMA) to the gaze and saccade models for semantic segmentation on high-resolution remote sensing images.
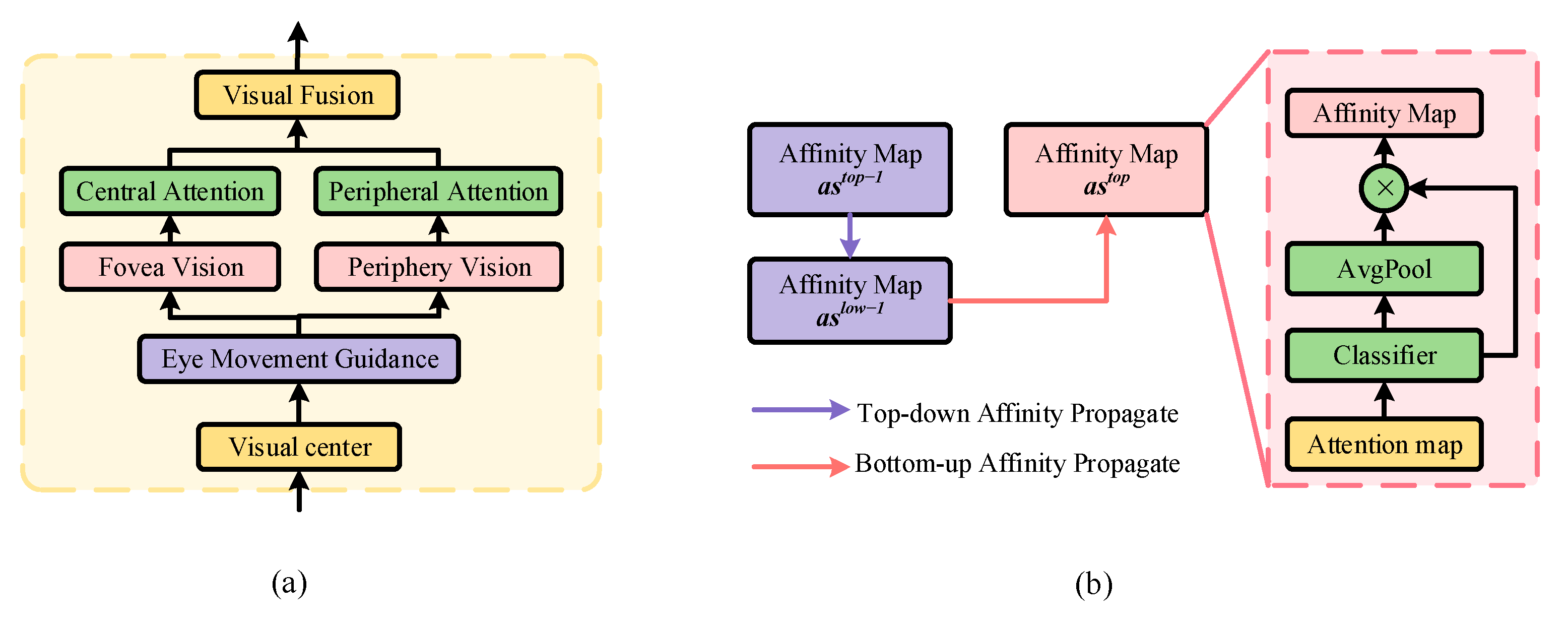
- We design an inter-layer short-term visual memory module (ISVM) capable of generating bidirectional inter-layer affinity for both top-down and bottom-up propagation. The ISVM module guides the visual perception window in calculating visual attention by simulating the spatiotemporal memory observed in human dynamic vision.
- We design a dual-branch pseudo-labeling strategy (DBPL) with pixel-level and category-level affinity constraints to enhance the model’s capability to extract domain-invariant features.
2. Related Work
2.1. Cross-Domain Semantic Segmentation Algorithm for Remote Sensing Images
2.2. Deep Learning Models Based on Eye Vision
3. Methodology
3.1. Gaze–Saccade Parallel Branches
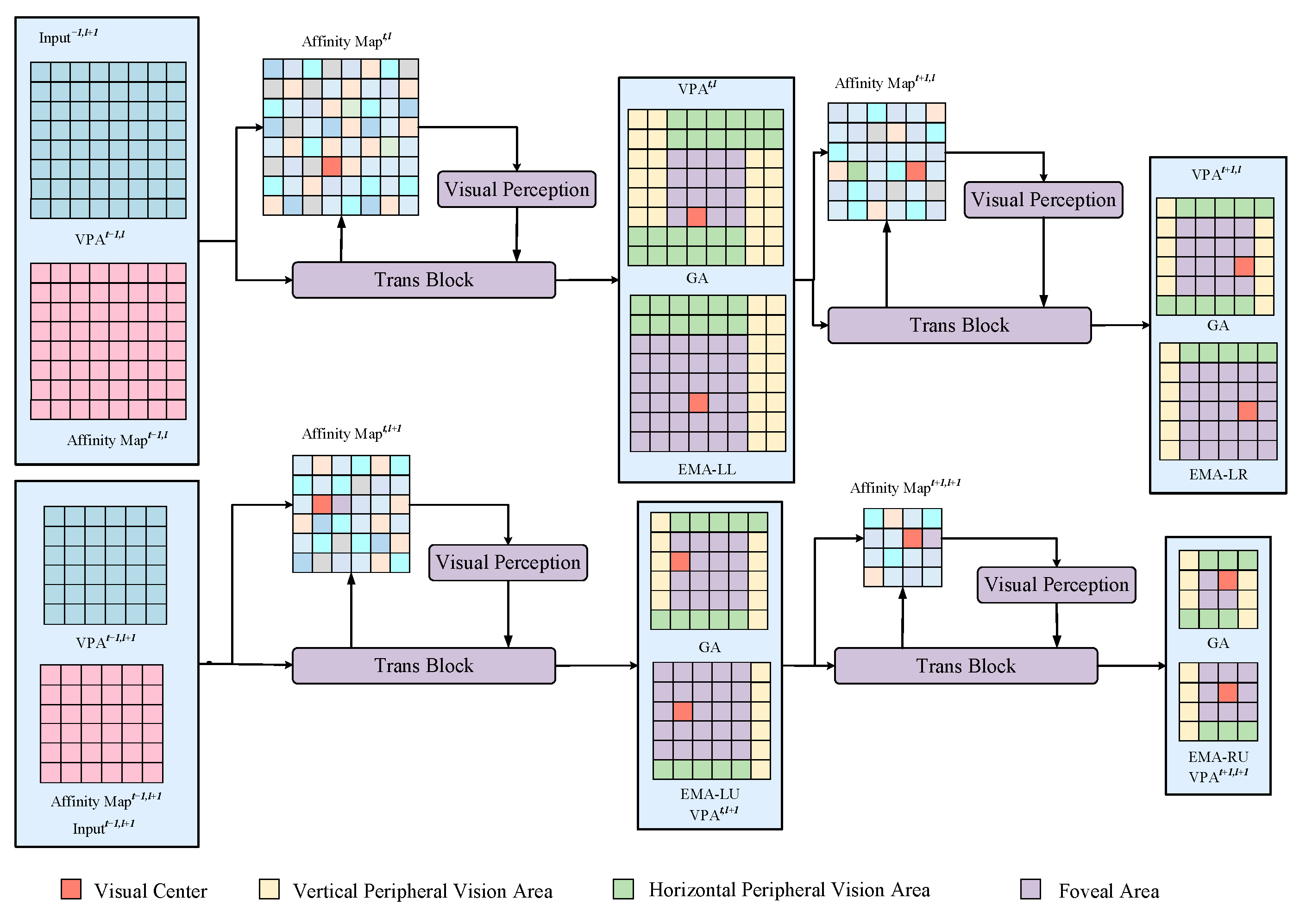
3.2. Visual Perception Attention
3.3. Inter-Layer Short-Term Visual Memory Module
3.4. Dual-Branch Pseudo-Label
| Algorithm 1: Training Process of GSV-Trans |
| Input: Samples with labels from the source domain, from the target domain, the training iterations , gaze branch , saccade branch , affinity net , and discriminator . Output: Prediction mask of , prediction mask of . For = 1 to Obtain attention map: , ,,. Obtain affinity map: , . Update and by Equations (1) and (2). Obtain pixel-level affinity pseudo-label and category-level affinity pseudo-label by Equations (3)–(6). Obtain pixel label by Equation (7). Compute pseudo-label loss by Equations (8) and (9): , . Updating and by minimizing . Updating by minimizing |
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Comparison Method and Implementation Details
4.3. Cross-Domain Semantic Segmentation Task from Potsdam-IRRG to Vaihingen
4.3.1. Ablation Study from Potsdam-IRRG to Vaihingen
4.3.2. Compare with Other Methods from Potsdam-IRRG to Vaihingen
4.4. Cross-Domain Semantic Segmentation Task from Vaihingen to Potsdam-IRRG
4.4.1. Ablation Study from Vaihingen to Potsdam-IRRG
4.4.2. Compare with Other Methods from Vaihingen to Potsdam-IRRG
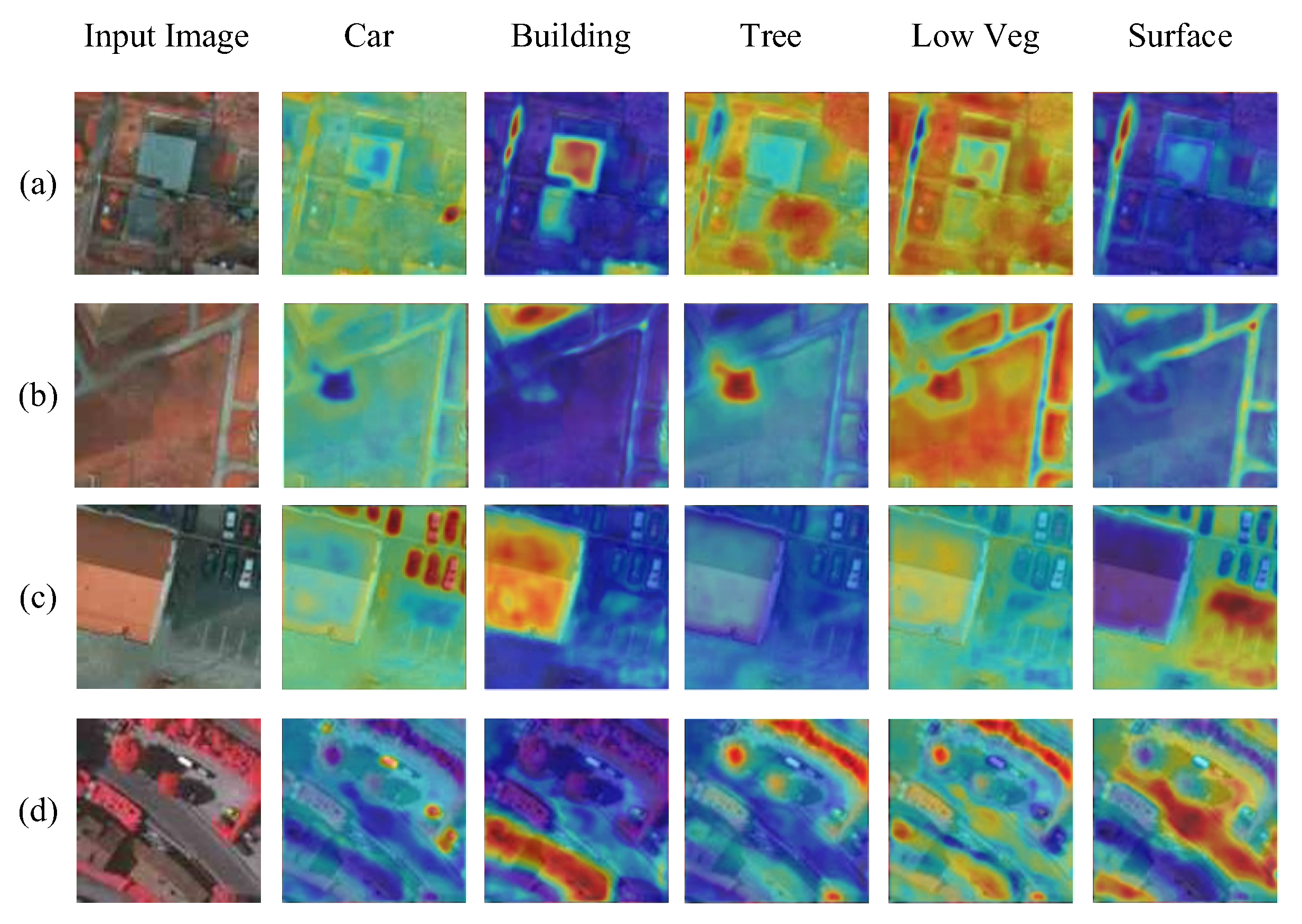
4.5. Affinity Map
4.6. Confusion Matrix
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Ullah, I.; Jian, M.; Hussain, S.; Lian, L.; Ali, Z.; Qureshi, I.; Guo, J.; Yin, Y. Global context-aware multi-scale features aggregative network for salient object detection. Neurocomputing 2021, 455, 139–153. [Google Scholar] [CrossRef]
- Lin, C.-Y.; Chiu, Y.-C.; Ng, H.-F.; Shih, T.K.; Lin, K.-H. Global-and-Local Context Network for Semantic Segmentation of Street View Images. Sensors 2020, 20, 2907. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Ouyang, S.; Zhang, Y. Combining deep learning and ontology reasoning for remote sensing image semantic segmentation. Knowl.-Based Syst. 2022, 243, 108469. [Google Scholar] [CrossRef]
- Liu, R.; Mi, L.; Chen, Z. AFNet: Adaptive Fusion Network for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7871–7886. [Google Scholar] [CrossRef]
- Wang, K.; Xu, C.; Li, G.; Zhang, Y.; Zheng, Y.; Sun, C. Combining convolutional neural networks and self-attention for fundus diseases identification. Sci. Rep. 2023, 13, 76. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6877–6886. [Google Scholar]
- Gao, H.; Liu, H.; Yang, M.; Chen, L.; Wan, Y.; Xiao, Z.; Qian, Y. STransFuse: Fusing SWIN Transformer and Convolutional Neural Network for Remote Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10990–11003. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin Transformer Embedding Unet for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408715. [Google Scholar] [CrossRef]
- Li, Y.; Shi, T.; Zhang, Y.; Chen, W.; Wang, Z.; Li, H. Learning deep semantic segmentation network under multiple weakly-supervised constraints for cross-domain remote sensing image semantic segmentation. ISPRS J. Photogramm. Remote Sens. 2021, 175, 20–33. [Google Scholar] [CrossRef]
- Xiao, T.; Liu, Y.; Huang, Y.; Li, M.; Yang, G. Enhancing Multiscale Representations With Transformer for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5605116. [Google Scholar] [CrossRef]
- Wei, X.; Zhou, X. FLDNet: A Foreground-Aware Network for Polyp Segmentation Leveraging Long-Distance Dependencies. In International Conference on Neural Information Processing; Springer Nature Singapore: Singapore, 2023; pp. 477–487. [Google Scholar]
- Song, P.; Li, J.; An, Z.; Fan, H.; Fan, L. CTMFNet: CNN and Transformer Multiscale Fusion Network of Remote Sensing Urban Scene Imagery. IEEE Trans. Geosci. Remote Sens. 2022, 61, 5900314. [Google Scholar] [CrossRef]
- Bai, L.; Du, S.; Zhang, X.; Wang, H.; Liu, B.; Ouyang, S. Domain Adaptation for Remote Sensing Image Semantic Segmentation: An Integrated Approach of Contrastive Learning and Adversarial Learning. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5628313. [Google Scholar] [CrossRef]
- Ni, H.; Liu, Q.; Guan, H.; Tang, H.; Chanussot, J. Category-Level Assignment for Cross-Domain Semantic Segmentation in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5608416. [Google Scholar] [CrossRef]
- Mo, Y.; Li, H.; Xiao, X.; Zhao, H.; Liu, X.; Zhan, J. Swin-Conv-Dspp and Global Local Transformer for Remote Sensing Image Semantic Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 5284–5296. [Google Scholar] [CrossRef]
- Yin, P.; Zhang, D.; Han, W.; Li, J.; Cheng, J. High-Resolution Remote Sensing Image Semantic Segmentation via Multiscale Context and Linear Self-Attention. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 9174–9185. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Advances in neural information processing systems. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Li, Y.; Yi, Z.; Wang, Y.; Zhang, L. Adaptive Context Transformer for Semisupervised Remote Sensing Image Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5621714. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Stewart, E.E.M.; Valsecchi, M.; Schütz, A.C. A review of interactions between peripheral and foveal vision. J. Vis. 2020, 20, 2. [Google Scholar] [CrossRef]
- McDowell, J.E.; Dyckman, K.A.; Austin, B.P.; Clementz, B.A. Neurophysiology and neuroanatomy of reflexive and volitional saccades: Evidence from studies of humans. Brain Cogn. 2008, 68, 255–270. [Google Scholar] [CrossRef]
- Jonnalagadda, A.; Wang, W.Y.; Manjunath, B.S.; Eckstein, M.P. Foveater: Foveated transformer for image classification. arXiv 2021, arXiv:2105.14173. [Google Scholar]
- Shi, Y.; Sun, M.; Wang, Y.; Wang, R.; Sun, H.; Chen, Z. EViT: An Eagle Vision Transformer with Bi-Fovea Self-Attention. arXiv 2023, arXiv:2310.06629. [Google Scholar]
- Shi, D. TransNeXt: Robust Foveal Visual Perception for Vision Transformers. arXiv 2023, arXiv:2311.17132. [Google Scholar]
- Pritchard, R.M. Stabilized Images on the Retina. Sci. Am. 1961, 204, 72–79. [Google Scholar] [CrossRef] [PubMed]
- Yan, L.; Fan, B.; Liu, H.; Huo, C.; Xiang, S.; Pan, C. Triplet adversarial domain adaptation for pixel-level classification of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3558–3573. [Google Scholar] [CrossRef]
- Saito, K.; Watanabe, K.; Ushiku, Y.; Harada, T. Maximum classifier discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3723–3732. [Google Scholar]
- Zhao, Y.; Guo, P.; Sun, Z.; Chen, X.; Gao, H. ResiDualGAN: Resize-Residual DualGAN for Cross-Domain Remote Sensing Images Semantic Segmentation. Remote Sens. 2023, 15, 1428. [Google Scholar] [CrossRef]
- Hoyer, L.; Dai, D.; Gool, L.V. Daformer: Improving network architectures and training strategies for domain-adaptive semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 9914–9925. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-like pure transformer for medical image segmentation. In European Conference on Computer Vision; Springer Nature Switzerland: Cham, Switzerland, 2022; pp. 205–218. [Google Scholar]
- Zhang, B.; Liu, L.; Phan, M.H.; Tian, Z.; Shen, C.; Liu, Y. SegViT v2: Exploring Efficient and Continual Semantic Segmentation with Plain Vision Transformers. Int. J. Comput. Vis. 2024, 132, 1126–1147. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GB | SB | ISVM | AEMA | DBPL | mIoU | mF1 |
|---|---|---|---|---|---|---|
| ✓ | 49.2 | 62.6 | ||||
| ✓ | ✓ | 52.1 | 64.6 | |||
| ✓ | ✓ | ✓ | 53.6 | 66.8 | ||
| ✓ | ✓ | ✓ | 53.8 | 67.1 | ||
| ✓ | ✓ | ✓ | ✓ | 54.5 | 67.5 | |
| ✓ | ✓ | ✓ | ✓ | 54.9 | 68.3 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 55.1 | 69.6 |
| Method | Car | Building | Tree | Low Veg | Surface | Avg | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | mIoU | mF1 | |
| Baseline | 7.2 | 24.5 | 42.1 | 51.4 | 35.6 | 50.1 | 23.1 | 46.1 | 26.8 | 33.2 | 26.9 | 41.1 |
| MCD | 16.7 | 34.6 | 56.1 | 69.6 | 46.2 | 68.1 | 30.3 | 49.4 | 57.8 | 72.3 | 41.4 | 58.8 |
| TriADA | 26.5 | 40.3 | 73.5 | 80.9 | 54.0 | 70.2 | 38.4 | 59.1 | 64.6 | 77.8 | 51.4 | 66.0 |
| ResiDualGAN | 28.1 | 42.8 | 73.5 | 80.5 | 54.2 | 71.7 | 40.7 | 57.2 | 64.1 | 76.5 | 52.1 | 65.6 |
| CIA-UDA | 28.5 | 44.0 | 72.9 | 78.2 | 53.8 | 70.8 | 39.5 | 58.2 | 65.8 | 77.2 | 52.3 | 65.7 |
| DAFormer | 28.7 | 44.5 | 73.1 | 80.7 | 54.1 | 71.2 | 39.8 | 58.6 | 63.5 | 76.0 | 51.8 | 66.2 |
| SWIN-Unet | 28.1 | 43.1 | 71.0 | 80.2 | 53.0 | 70.0 | 36.1 | 57.6 | 64.2 | 77.3 | 50.4 | 65.6 |
| SegVitv2 | 28.9 | 45.3 | 74.5 | 83.6 | 56.2 | 72..4 | 37.1 | 58.0 | 66.2 | 78.9 | 52.6 | 66.5 |
| GSV-Trans | 30.1 | 47.1 | 75.1 | 85.8 | 57.9 | 73.4 | 43.7 | 60.9 | 67.5 | 80.6 | 55.1 | 69.6 |
| GB | SB | ISVM | AEMA | DBPL | mIoU | mF1 |
|---|---|---|---|---|---|---|
| ✓ | 55.1 | 73.1 | ||||
| ✓ | ✓ | 57.1 | 74.6 | |||
| ✓ | ✓ | ✓ | 59.2 | 75.7 | ||
| ✓ | ✓ | ✓ | 62.4 | 76.1 | ||
| ✓ | ✓ | ✓ | ✓ | 63.5 | 77.3 | |
| ✓ | ✓ | ✓ | ✓ | 63.7 | 77.9 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 64.5 | 78.1 |
| Method | Car | Building | Tree | Low Veg | Surface | Avg | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | IoU | F1 | mIoU | mF1 | |
| Baseline | 40.1 | 52.5 | 44.3 | 53.1 | 20.9 | 44.6 | 29.5 | 46.2 | 40.8 | 60.2 | 35.1 | 51.3 |
| MCD | 41.4 | 55.1 | 42.8 | 50.3 | 35.6 | 56.2 | 43.7 | 58.2 | 53.7 | 66.7 | 43.4 | 57.7 |
| TriADA | 59.9 | 69.1 | 71.5 | 81.2 | 48.6 | 66.8 | 57.9 | 72.1 | 68.3 | 81.9 | 61.2 | 74.2 |
| ResiDualGAN | 58.7 | 68.5 | 72.9 | 82.9 | 46.9 | 65.1 | 53.2 | 67.9 | 61.7 | 77.1 | 58.7 | 72.3 |
| CIA-UDA | 57.5 | 67.6 | 71.3 | 82.8 | 47.6 | 66.2 | 55.3 | 68.0 | 65.1 | 78.5 | 59.4 | 72.6 |
| DAFormer | 58.6 | 69.9 | 71.2 | 82.5 | 47.4 | 66.3 | 56.6 | 69.9 | 67.1 | 81.7 | 60.2 | 74.1 |
| SWIN-Unet | 57.1 | 70.6 | 70.6 | 81.3 | 46.0 | 64.8 | 53.6 | 67.8 | 63.2 | 78.1 | 58.1 | 72.5 |
| SegVitv2 | 60.1 | 75.1 | 73.9 | 84.6 | 50.1 | 67.2 | 58.9 | 73.8 | 70.5 | 82.4 | 62.7 | 76.6 |
| GSV-Tran | 62.2 | 76.7 | 75.2 | 85.8 | 52.5 | 68.9 | 60.0 | 75.0 | 72.6 | 84.1 | 64.5 | 78.1 |
| Source Domain | Target Domain | Avg | |
|---|---|---|---|
| IoU | F1 | ||
| Vaihingen | Potsdam-RGB | 65.2 | 79.6 |
| Potsdam-RGB | Vaihingen | 56.8 | 70.2 |
| Potsdam-IRRG | Vaihingen | 55.1 | 69.6 |
| Vaihingen | Potsdam-IRRG | 64.5 | 78.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Wang, H.; Jing, Y.; Yang, X.; Chu, J. A Bio-Inspired Visual Perception Transformer for Cross-Domain Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2024, 16, 1514. https://doi.org/10.3390/rs16091514
Wang X, Wang H, Jing Y, Yang X, Chu J. A Bio-Inspired Visual Perception Transformer for Cross-Domain Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sensing. 2024; 16(9):1514. https://doi.org/10.3390/rs16091514
Chicago/Turabian StyleWang, Xinyao, Haitao Wang, Yuqian Jing, Xianming Yang, and Jianbo Chu. 2024. "A Bio-Inspired Visual Perception Transformer for Cross-Domain Semantic Segmentation of High-Resolution Remote Sensing Images" Remote Sensing 16, no. 9: 1514. https://doi.org/10.3390/rs16091514
APA StyleWang, X., Wang, H., Jing, Y., Yang, X., & Chu, J. (2024). A Bio-Inspired Visual Perception Transformer for Cross-Domain Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sensing, 16(9), 1514. https://doi.org/10.3390/rs16091514